Hari ini di situs asing bertema tentang Big Data Anda dapat menemukan penyebutan alat yang relatif baru untuk ekosistem Hadoop sebagai Apache NiFi. Ini adalah alat ETL open source modern. Arsitektur terdistribusi untuk pemuatan paralel yang cepat dan pemrosesan data, sejumlah besar plug-in untuk sumber dan transformasi, versi konfigurasi hanyalah sebagian dari kelebihannya. Dengan semua kekuatannya, NiFi tetap cukup mudah digunakan.
Kami di Rostelecom berusaha mengembangkan kerja dengan Hadoop, jadi kami telah mencoba dan menghargai keunggulan Apache NiFi dibandingkan solusi lain. Dalam artikel ini saya akan memberi tahu Anda bagaimana alat ini menarik kami dan bagaimana kami menggunakannya.
Latar belakang
Belum lama berselang, kami dihadapkan pada pilihan solusi untuk memuat data dari sumber eksternal ke dalam cluster Hadoop. Untuk waktu yang lama, kami menggunakan
Apache Flume untuk memecahkan masalah seperti itu. Tidak ada keluhan tentang Flume secara keseluruhan, kecuali beberapa poin yang tidak cocok untuk kami.
Hal pertama yang kami, sebagai administrator, tidak suka adalah menulis konfigurasi Flume untuk melakukan unduhan sepele berikutnya tidak dapat dipercayakan kepada pengembang atau analis yang tidak terbenam dalam seluk-beluk alat ini. Menghubungkan setiap sumber baru diperlukan intervensi wajib dari tim administrasi.
Poin kedua adalah toleransi kesalahan dan penskalaan. Untuk unduhan berat, misalnya, melalui syslog, perlu mengkonfigurasi beberapa agen Flume dan mengatur penyeimbang di depannya. Semua ini kemudian harus dipantau dan dipulihkan dalam hal terjadi kegagalan.
Ketiga , Flume tidak mengizinkan mengunduh data dari berbagai DBMS dan bekerja dengan beberapa protokol lain di luar kotak. Tentu saja, di hamparan jaringan yang luas, Anda dapat menemukan cara untuk membuat Flume bekerja dengan Oracle atau SFTP, tetapi mendukung sepeda seperti itu sama sekali tidak menyenangkan. Untuk memuat data dari Oracle yang sama, kami harus menggunakan alat lain -
Apache Sqoop .
Terus terang, pada dasarnya saya adalah orang yang malas, dan saya tidak ingin mendukung kebun binatang solusi sama sekali. Dan saya tidak suka bahwa semua pekerjaan ini harus dilakukan sendiri.
Tentu saja ada solusi yang sangat kuat di pasar ETL-tools yang dapat bekerja dengan Hadoop. Ini termasuk Informatica, IBM Datastage, SAS, dan Pentaho Data Integration. Ini adalah yang paling sering didengar dari rekan kerja di bengkel dan yang pertama kali muncul di benak Anda. Omong-omong, kami menggunakan IBM DataStage untuk ETL pada solusi dari kelas Gudang Data. Tetapi itu terjadi secara historis bahwa tim kami tidak dapat menggunakan DataStage untuk unduhan di Hadoop. Sekali lagi, kami tidak memerlukan kekuatan penuh solusi tingkat ini untuk melakukan konversi dan unduhan data yang cukup sederhana. Apa yang kami butuhkan adalah solusi dengan dinamika pengembangan yang baik, dapat bekerja dengan banyak protokol dan memiliki antarmuka yang nyaman dan intuitif yang tidak hanya dapat ditangani oleh administrator yang mengerti semua seluk beluknya, tetapi juga pengembang dengan analis, yang sering kali bagi kami pelanggan dari data itu sendiri.
Seperti yang Anda lihat dari judulnya, kami memecahkan masalah di atas dengan Apache NiFi.
Apa itu Apache NiFi?
Nama NiFi berasal dari "Niagara Files." Proyek ini dikembangkan oleh Badan Keamanan Nasional AS selama delapan tahun, dan pada November 2014 kode sumbernya dibuka dan dipindahkan ke Yayasan Perangkat Lunak Apache sebagai bagian dari
Program Transfer Teknologi NSA .
NiFi adalah alat ETL / ELT open source yang dapat bekerja dengan banyak sistem, dan tidak hanya kelas Big Data dan Data Warehouse. Berikut adalah beberapa di antaranya: HDFS, Hive, HBase, Solr, Cassandra, MongoDB, ElastcSearch, Kafka, RabbitMQ, Syslog, HTTPS, SFTP. Anda dapat melihat daftar lengkap di
dokumentasi resmi.
Bekerja dengan DBMS spesifik diimplementasikan dengan menambahkan driver JDBC yang sesuai. Ada API untuk menulis modul Anda sebagai penerima atau pengonversi data tambahan. Contohnya dapat ditemukan di
sini dan di
sini .
Fitur utama
NiFi menggunakan antarmuka web untuk membuat DataFlow. Seorang analis yang baru-baru ini mulai bekerja dengan Hadoop, pengembang, dan admin berjanggut akan mengatasinya. Dua yang terakhir dapat berinteraksi tidak hanya dengan "persegi panjang dan panah", tetapi juga dengan
REST API untuk mengumpulkan statistik, memantau dan mengelola komponen DataFlow.
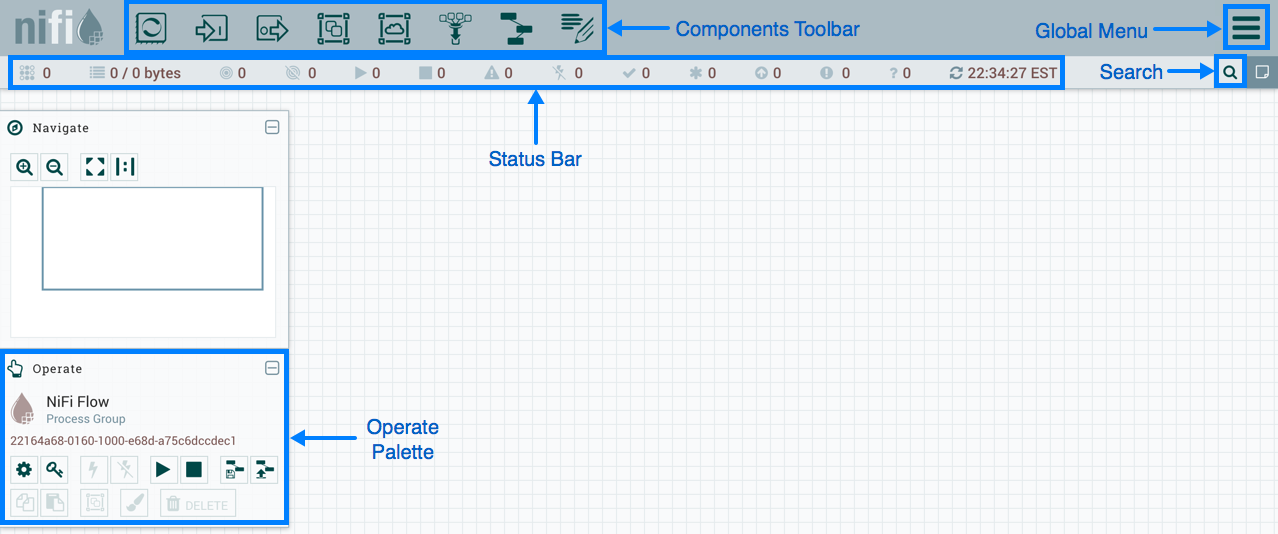 Manajemen Berbasis Web NiFi
Manajemen Berbasis Web NiFiDi bawah ini saya akan menunjukkan beberapa contoh DataFlow untuk melakukan beberapa operasi umum.
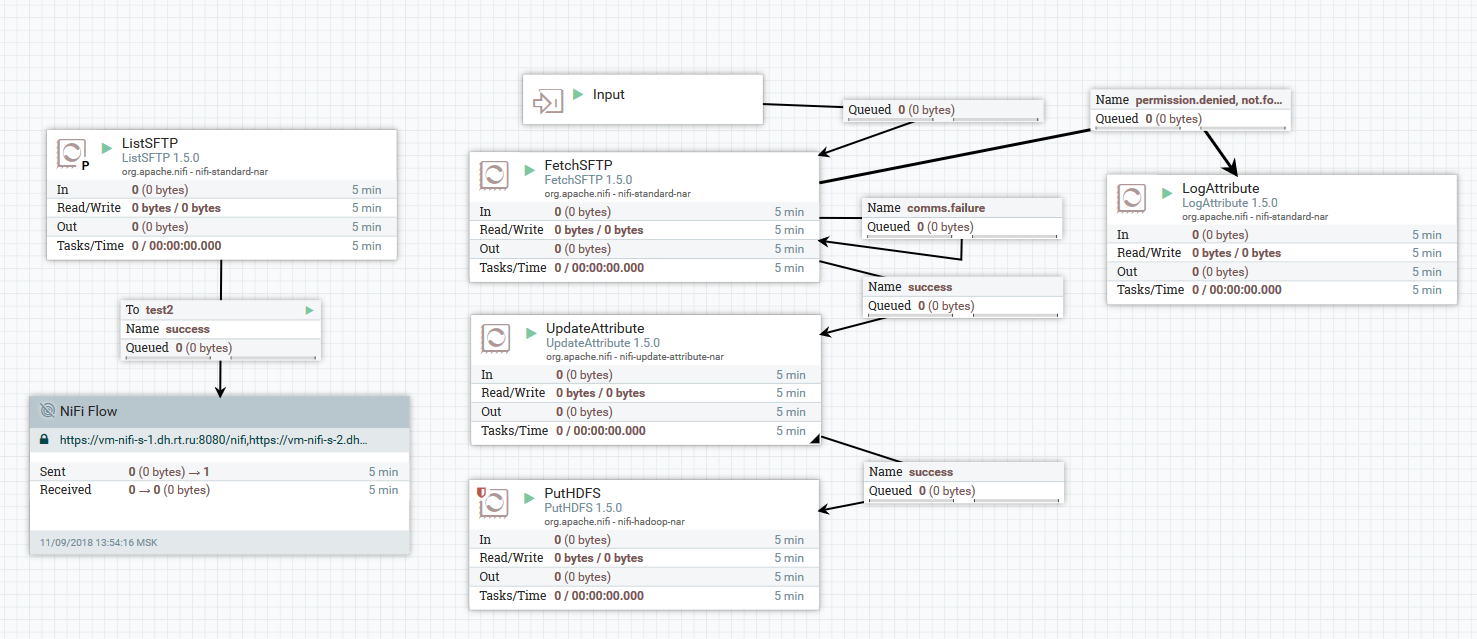 Contoh mengunduh file dari server SFTP ke HDFS
Contoh mengunduh file dari server SFTP ke HDFSDalam contoh ini, prosesor ListSFTP melakukan daftar file di server jauh. Hasil dari daftar ini digunakan untuk memuat file paralel oleh semua node cluster oleh prosesor FetchSFTP. Setelah itu, atribut ditambahkan ke setiap file, diperoleh dengan menguraikan namanya, yang kemudian digunakan oleh prosesor PutHDFS saat menulis file ke direktori akhir.
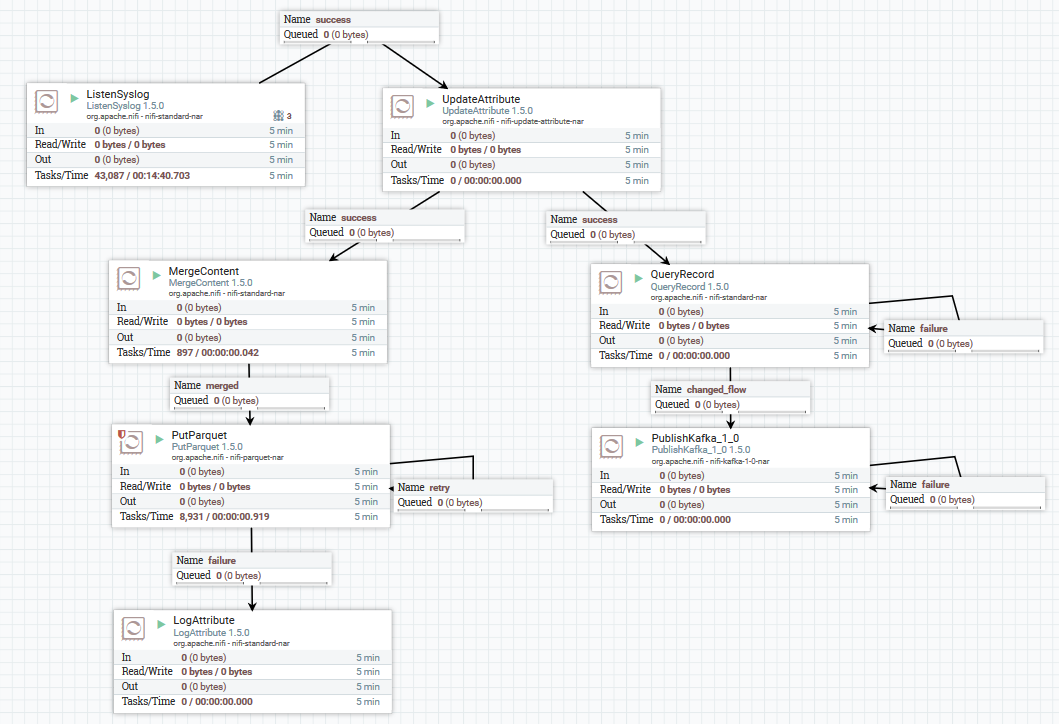 Contoh mengunduh data syslog di Kafka dan HDFS
Contoh mengunduh data syslog di Kafka dan HDFSDi sini, menggunakan prosesor ListenSyslog, kita mendapatkan aliran pesan input. Setelah itu, atribut tentang waktu kedatangan mereka di NiFi dan nama skema di Avro Schema Registry ditambahkan ke setiap grup pesan. Selanjutnya, cabang pertama dikirim ke input prosesor QueryRecord, yang, berdasarkan skema yang ditentukan, membaca data dan mem-parsingnya menggunakan SQL, dan kemudian mengirimkannya ke Kafka. Cabang kedua dikirim ke prosesor MergeContent, yang mengumpulkan data selama 10 menit, dan kemudian memberikannya ke prosesor berikutnya untuk konversi ke format Parket dan merekam ke HDFS.
Berikut ini adalah contoh bagaimana Anda bisa mendesain DataFlow:
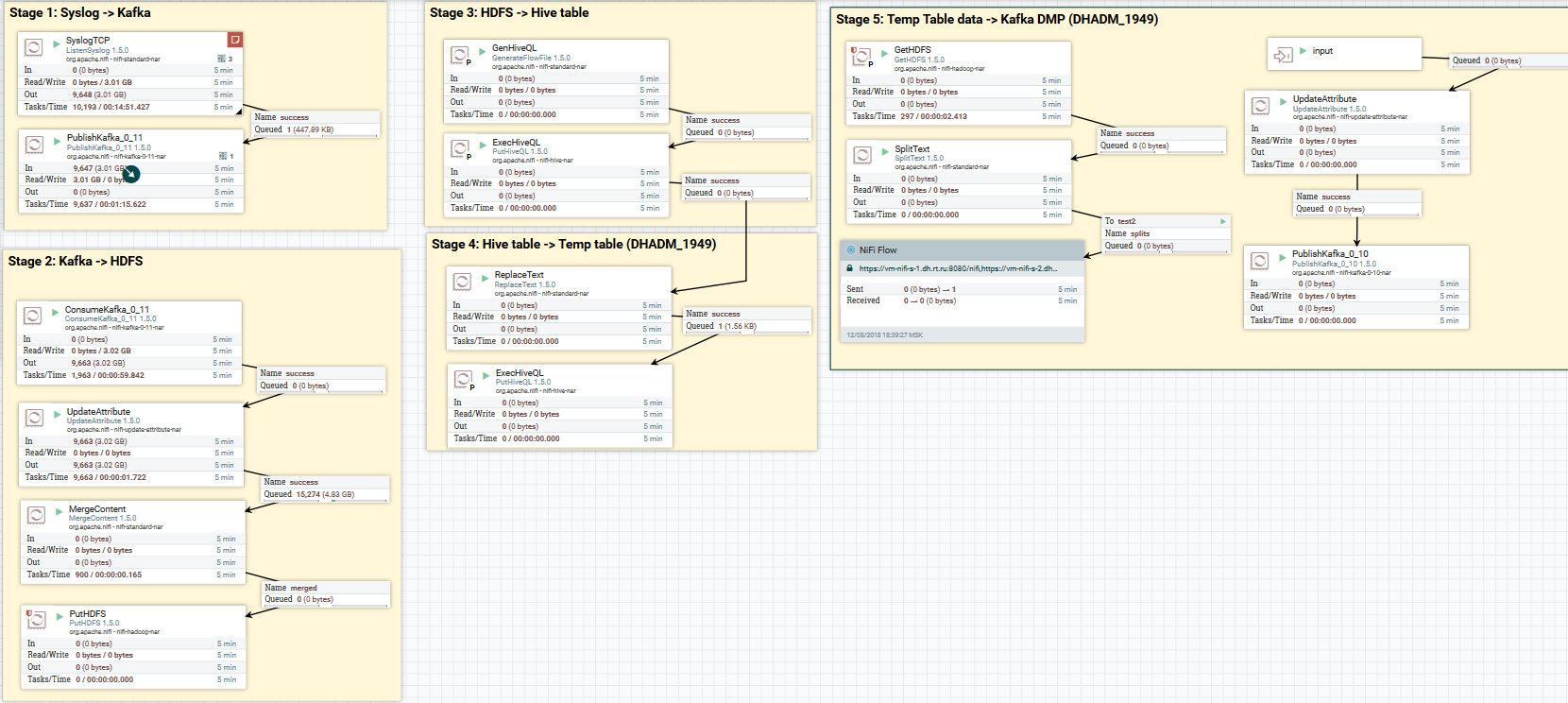 Unduh data syslog ke Kafka dan HDFS. Menghapus data di Hive
Unduh data syslog ke Kafka dan HDFS. Menghapus data di HiveSekarang tentang konversi data. NiFi memungkinkan Anda mem-parsing data dengan data biasa, menjalankan SQL di dalamnya, memfilter dan menambahkan bidang, dan mengonversi satu format data ke yang lain. Ini juga memiliki bahasa ekspresi sendiri, kaya akan berbagai operator dan fungsi bawaan. Dengan itu, Anda dapat menambahkan variabel dan atribut ke data, membandingkan dan menghitung nilai, menggunakannya nanti dalam pembentukan berbagai parameter, seperti jalur untuk menulis ke HDFS atau SQL-query di Hive. Baca lebih lanjut di
sini .
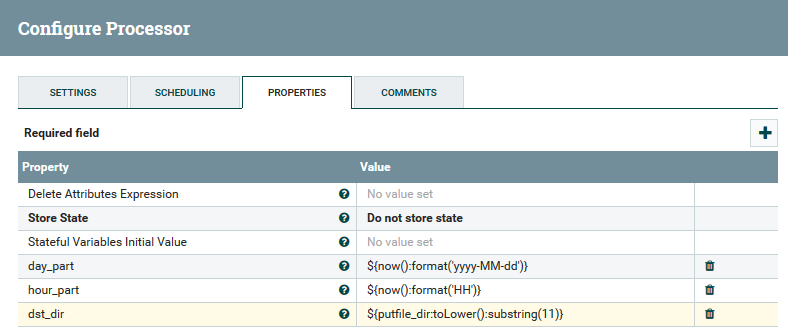 Contoh menggunakan variabel dan fungsi dalam prosesor UpdateAttribute
Contoh menggunakan variabel dan fungsi dalam prosesor UpdateAttributePengguna dapat melacak jalur penuh data, mengamati perubahan konten dan atributnya.
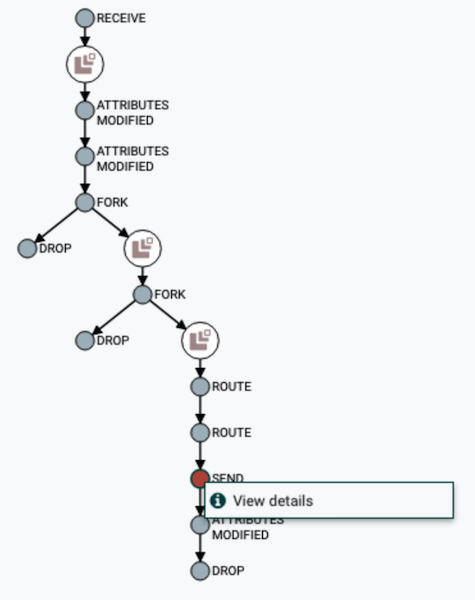 Visualisasi rantai DataFlow
Visualisasi rantai DataFlow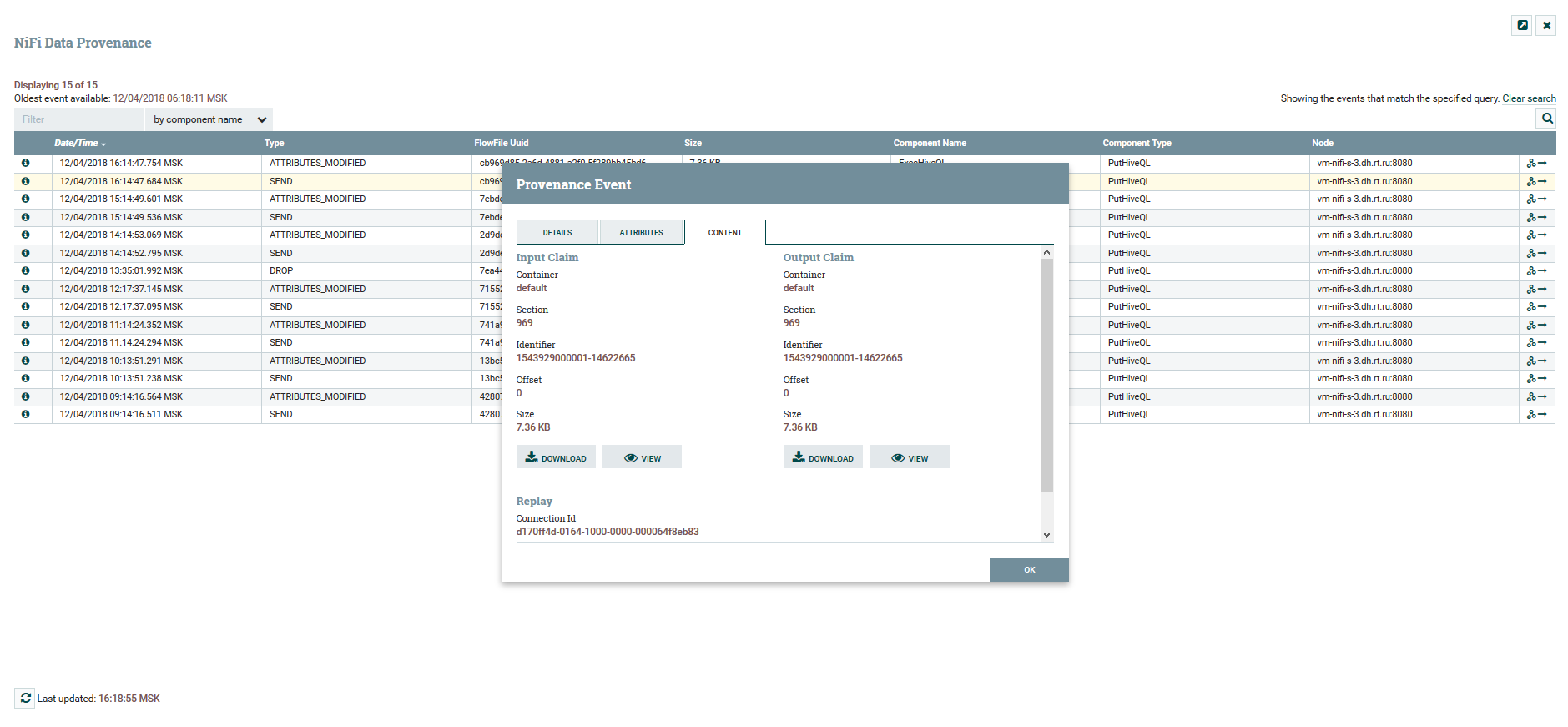 Lihat atribut konten dan data
Lihat atribut konten dan dataUntuk versi DataFlow ada layanan
Registry NiFi terpisah. Dengan mengaturnya, Anda mendapatkan kemampuan untuk mengelola perubahan. Anda dapat menjalankan perubahan lokal, memutar kembali, atau mengunduh versi sebelumnya.
 Menu Kontrol Versi
Menu Kontrol VersiDi NiFi, Anda dapat mengontrol akses ke antarmuka web dan pemisahan hak pengguna. Mekanisme otentikasi berikut saat ini didukung:
- Berbasis Sertifikat
- Berdasarkan nama pengguna dan kata sandi melalui LDAP dan Kerberos
- Melalui Apache Knox
- Melalui OpenID Connect
Penggunaan simultan beberapa mekanisme sekaligus tidak didukung. Untuk mengotorisasi pengguna dalam sistem, FileUserGroupProvider dan LdapUserGroupProvider digunakan. Baca lebih lanjut tentang ini di
sini .
Seperti yang saya katakan, NiFi dapat bekerja dalam mode cluster. Ini memberikan toleransi kesalahan dan memungkinkan penskalaan beban horizontal. Tidak ada master node yang diperbaiki secara statis. Sebaliknya,
Apache Zookeeper memilih satu simpul sebagai koordinator dan satu simpul sebagai primer. Koordinator menerima informasi tentang status mereka dari node lain dan bertanggung jawab untuk koneksi dan pemutusan mereka dari cluster.
Primer-simpul digunakan untuk memulai prosesor terisolasi, yang seharusnya tidak berjalan di semua node secara bersamaan.
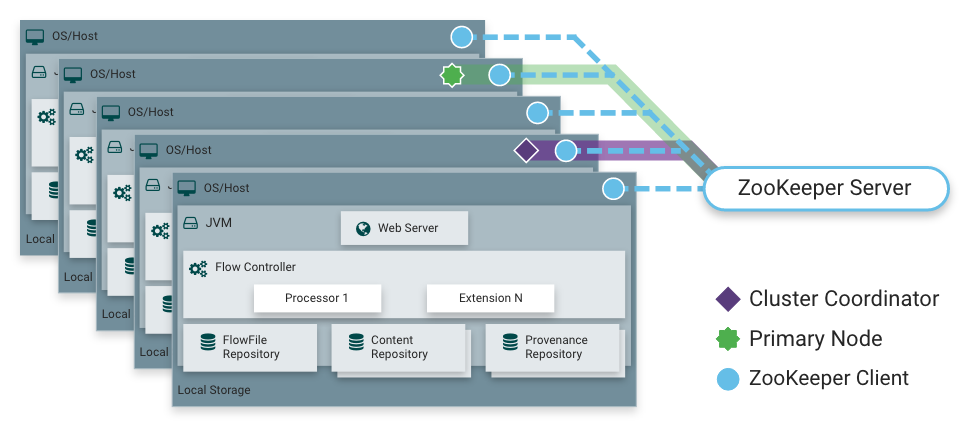 Operasi NiFi dalam sebuah cluster
Operasi NiFi dalam sebuah cluster Memuat distribusi dengan node cluster menggunakan prosesor PutHDFS sebagai contoh
Memuat distribusi dengan node cluster menggunakan prosesor PutHDFS sebagai contohPenjelasan Singkat tentang Arsitektur dan Komponen NiFi
 Arsitektur Instansi NiFi
Arsitektur Instansi NiFiNiFi didasarkan pada konsep "Flow Based Programming" (
FBP ). Berikut adalah konsep dan komponen dasar yang dihadapi setiap pengguna:
FlowFile - entitas yang mewakili objek dengan konten dari nol atau lebih byte dan atribut yang sesuai. Ini bisa berupa data itu sendiri (misalnya, aliran pesan Kafka), atau hasil prosesor (PutSQL, misalnya), yang tidak berisi data seperti itu, tetapi hanya atribut yang dihasilkan sebagai hasil dari kueri. Atribut adalah metadata FlowFile.
FlowFile Processor adalah esensi yang melakukan pekerjaan dasar di NiFi. Prosesor, sebagai suatu peraturan, memiliki satu atau beberapa fungsi untuk bekerja dengan FlowFile: membuat, membaca / menulis dan mengubah konten, membaca / menulis / mengubah atribut, perutean. Sebagai contoh, prosesor ListenSyslog menerima data menggunakan protokol syslog, membuat FlowFiles dengan atribut syslog.version, syslog.hostname, syslog.sender dan lainnya. Prosesor RouteOnAttribute membaca atribut input FlowFile dan memutuskan untuk mengalihkannya ke koneksi yang sesuai dengan prosesor lain, tergantung pada nilai atribut.
Connection - menyediakan koneksi flowFile dan transfer antara berbagai prosesor dan beberapa entitas NiFi lainnya. Koneksi membuat FlowFile dalam antrian, dan kemudian meneruskannya ke rantai. Anda dapat mengonfigurasi bagaimana FlowFiles dipilih dari antrian, masa pakainya, jumlah maksimum dan ukuran maksimum semua objek dalam antrian.
Grup Proses - satu set prosesor, koneksi mereka dan elemen DataFlow lainnya. Ini adalah mekanisme untuk mengatur banyak komponen menjadi satu struktur logis. Membantu menyederhanakan pemahaman tentang DataFlow. Input / Output Port digunakan untuk menerima dan mengirim data dari Grup Proses. Baca lebih lanjut tentang penggunaannya di
sini .
Repositori FlowFile adalah tempat NiFi menyimpan semua informasi yang diketahuinya tentang setiap FlowFile yang ada dalam sistem.
Content Repository - repositori tempat konten semua FlowFiles berada, mis. data yang dikirimkan itu sendiri.
Provenance Repository - Berisi cerita tentang masing-masing FlowFile. Setiap kali ketika suatu peristiwa terjadi dengan FlowFile (pembuatan, perubahan, dll.), Informasi yang sesuai dimasukkan ke dalam repositori ini.
Server Web - menyediakan antarmuka web dan API REST.
Kesimpulan
Dengan NiFi, Rostelecom mampu meningkatkan mekanisme pengiriman data ke Data Lake di Hadoop. Secara umum, seluruh proses menjadi lebih mudah dan dapat diandalkan. Hari ini, saya dapat dengan yakin mengatakan bahwa NiFi sangat bagus untuk mengunduh ke Hadoop. Kami tidak memiliki masalah dalam operasinya.
Omong-omong, NiFi adalah bagian dari distribusi Arus Data Hortonworks dan secara aktif dikembangkan oleh Hortonworks sendiri. Ia juga memiliki sub proyek Apache MiNiFi yang menarik, yang memungkinkan Anda mengumpulkan data dari berbagai perangkat dan mengintegrasikannya ke dalam DataFlow di dalam NiFi.
Informasi Tambahan Tentang NiFi
Mungkin itu saja. Terima kasih atas perhatiannya. Tulis di komentar jika Anda memiliki pertanyaan. Saya akan menjawabnya dengan senang hati.