
DeepMind menciptakan algoritma yang benar-benar luar biasa yang mampu mencapai apa yang tidak dapat dicapai oleh sistem mesin sebelumnya. Secara khusus, jaringan saraf
AlphaGo mampu mengalahkan pemain terbaik di dunia. Menurut para ahli, sekarang kemampuan sistem telah tumbuh sedemikian rupa sehingga bahkan tidak masuk akal untuk mencoba mengalahkannya - hasilnya sudah ditentukan sebelumnya.
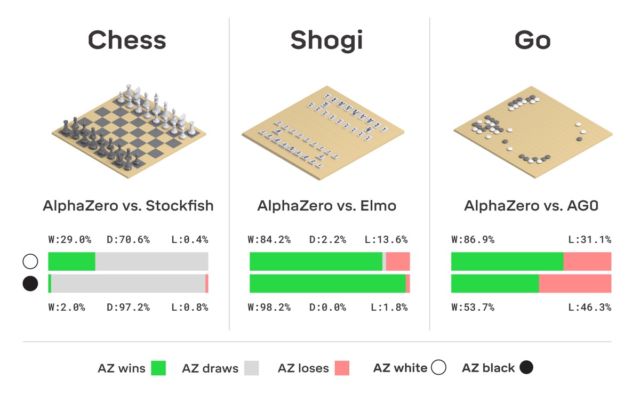
Meskipun demikian, perusahaan tidak berhenti sampai di situ, tetapi terus bekerja. Berkat penelitian karyawannya, versi AlphaGo yang lebih baik, yang disebut AlphaZero, lahir. Seperti yang ditunjukkan dalam judul, sistem itu sendiri dapat belajar bagaimana memainkan tiga game logis sekaligus - catur, shogi, dan go.
Perbedaan antara versi baru dan semua yang sebelumnya
adalah bahwa sistem itu sendiri mempelajari hampir semuanya. Dia mulai dari awal dan dengan cepat belajar memainkan ketiga game dengan sempurna. Tidak ada yang membantu AlphaZero - sistem "mendapatkan semuanya dengan sendirinya".
Catur dimasukkan dalam set, lebih tepatnya, menurut tradisi - tidak ada yang sulit untuk mengajarkan komputer cara bermain catur, tidak. Untuk pertama kalinya, sebuah sistem komputer dibawa ke permainan di tahun 1950-an. Kemudian, sudah di tahun 60-an, program
Mac Hack IV dibuat, yang mulai mengalahkan pesaing manusia. Seiring waktu, program catur berangsur-angsur membaik, dan pada tahun 1997 IBM mengembangkan "Chess Computer" Deep Blue, yang berhasil mengalahkan Grandmaster dan Juara Dunia Garry Kasparov.
Seperti yang dia tunjukkan, saat ini banyak aplikasi pada smartphone bermain catur lebih baik daripada Deep Blue. Setelah mencapai kesempurnaan dalam penciptaan sistem yang dapat bermain catur, para pengembang mulai membuat versi baru dari pesaing komputer manusia - khususnya, mereka berhasil mengajarkan komputer untuk bermain go. Sebelumnya, game ini dengan sejarah seribu tahun dianggap sebagai salah satu yang paling tidak dapat diakses oleh "pemahaman" komputer. Tetapi waktu telah berubah. Seperti disebutkan di atas, AlphaGo mencapai tingkat penguasaan permainan go yang begitu tinggi sehingga seseorang tidak berdiri di dekatnya.
Omong-omong, tahun ini AlphaGo menerima pembaruan, berkat jaringan saraf sekarang dapat mempelajari berbagai strategi untuk bermain tanpa campur tangan manusia. Bermain dengan dirinya sendiri berulang kali, AlphaGo membaik. Ini adalah jenis sistem pelatihan yang menggunakan "keturunan" AlphaGo - jaringan saraf AlphaZero. Hanya dalam tiga hari, ia mencapai tingkat penguasaan di Go sedemikian rupa sehingga ia mengalahkan versi asli AlphaGo dengan skor 100 hingga 0. Satu-satunya hal yang diterima sistem pada awalnya adalah aturan mainnya.
Tidak ada fiksi di sini, DeepMind menggunakan sistem pembelajaran mesin penguatan yang terkenal. Komputer berusaha untuk menang, karena untuk setiap kemenangan menerima hadiah (poin). Selain itu, AlphaZero kehilangan jutaan kombinasi dalam proses pembelajaran. AlphaZero hanya menghabiskan 0,4 detik untuk salah menghitung langkah selanjutnya dan menilai probabilitas menang. Adapun AlphaGo dari versi aslinya, jaringan saraf terdiri dari dua elemen, dua jaringan saraf - satu menentukan langkah selanjutnya yang mungkin, dan yang kedua menghitung probabilitas.
Untuk mencapai tingkat master di Go AlphaZero, Anda perlu "menggulir" sekitar 4,5 juta game saat bermain dengan diri sendiri. Tapi AlphaGo membutuhkan 30 juta game.
Perlu dicatat bahwa AlphaZero diciptakan khusus untuk bermain go. Perusahaan tidak melupakan ini. Tapi selain pergi, sistem ini dapat belajar dan dua permainan lainnya, yang disebutkan di atas. Sistem yang digunakan adalah pembelajaran mesin yang sama dengan penguatan. Perlu dicatat bahwa AlphaZero hanya bekerja dengan tugas-tugas yang memiliki sejumlah solusi. Sistem juga membutuhkan model lingkungan (virtual).
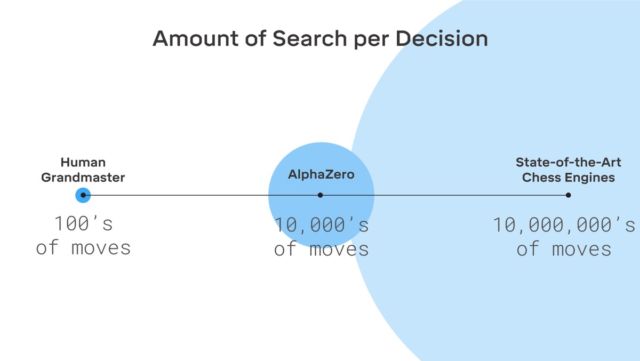
Menariknya, Kasparov sendiri percaya bahwa seseorang dapat memperoleh banyak hal dari sistem seperti AlphaGo - Anda dapat belajar banyak dari mereka.
Saat ini, para pengembang dihadapkan dengan tugas mengajar komputer untuk bermain poker lebih baik daripada orang-orang lain, dan juga menciptakan sistem yang dapat mengalahkan setiap pelaku olahraga dalam pertarungan yang adil. Bagaimanapun, jelas bahwa jaringan saraf dan AI mampu banyak.