Kemarin saya menerima surat dari siswa kelas sepuluh dari Siberia yang ingin menjadi pengembang mikroprosesor. Dia sudah mendapatkan beberapa hasil di bidang ini - dia menambahkan instruksi multiplikasi ke prosesor schoolPSI yang paling sederhana, disintesiskan untuk Intel FPGA MAX10 FPGA, menentukan frekuensi maksimum dan peningkatan produktivitas program sederhana. Dia melakukan semua ini pada awalnya di desa Burmistrovo, Novosibirsk Region, dan kemudian di sebuah konferensi di Tomsk.
Sekarang Dasha Krivoruchko (itulah nama siswa kelas sepuluh) pindah untuk tinggal di sekolah asrama Moskow dan bertanya kepada saya apa lagi yang harus ia rancang. Saya berpikir bahwa pada tahap ini dalam karirnya, dia harus merancang akselerator perangkat keras untuk jaringan saraf berdasarkan pada susunan sistolik untuk perkalian matriks. Gunakan bahasa deskripsi perangkat keras Verilog dan Intel FPGA FPGA, tetapi bukan MAX10 yang murah, tetapi sesuatu yang lebih mahal untuk mengakomodasi susunan sistolik yang besar.
Setelah itu, bandingkan kinerja solusi perangkat keras dengan program yang berjalan pada prosesor schoolMIPS, serta dengan program Python yang berjalan di komputer desktop. Sebagai uji kasus, gunakan pengakuan angka dari matriks kecil.

Sebenarnya, semua bagian dari latihan ini telah dikembangkan oleh orang-orang yang berbeda, tetapi intinya adalah untuk menjadikan ini sebagai latihan tunggal yang terdokumentasi, yang kemudian dapat digunakan sebagai dasar untuk kursus online dan untuk kompetisi praktis:
1) eNano, departemen pendidikan RUSNANO, yang sebelumnya menyelenggarakan seminar Charles Danchek tentang desain elektronik modern (rute RTL-ke-GDSII) untuk siswa dan saat ini sedang mengerjakan kursus online semacam ini (merancang perangkat keras pada tingkat transfer register + jaringan saraf) tertarik kursus ringan untuk siswa tingkat lanjut. Di sini Charles dan saya ada di kantor mereka:

2) Basis Olimpiade mungkin tertarik pada
Olimpiade NTI , yang saya bahas beberapa minggu yang lalu di Moskow. Untuk contoh seperti itu, peserta dalam olimpiade dapat menambahkan perangkat keras untuk berbagai fungsi aktivasi. Berikut adalah rekan-rekan dari Olimpiade NTI:

Jadi jika Dasha mengembangkan ini, dia secara teoritis bisa memperkenalkan akseleratornya yang dijelaskan dengan baik di RUSNANO dan di Olimpiade NTI. Saya pikir itu akan bermanfaat untuk administrasi sekolahnya - itu dapat ditampilkan di TV atau dikirim ke kontes Intel FPGA secara umum. Berikut adalah
beberapa orang Rusia dari St. Petersburg di final kontes FPGA Intel di Santa Clara, California :

Sekarang mari kita bicara tentang sisi teknis dari proyek ini. Gagasan akselerator massa sistolik dijelaskan dalam sebuah artikel yang diterjemahkan oleh editor Habra Vyacheslav Golovanov
SLY_G Mengapa TPU begitu cocok untuk pembelajaran yang mendalam?Ini adalah apa yang tampak seperti grafik jaringan saraf arus data untuk memudahkan pengenalan:

Elemen komputasi primitif yang melakukan perkalian dan penambahan:

Struktur elemen-elemen yang sangat tersusun dalam pipa, susunan sistolik ini untuk perkalian matriks adalah:

Di Internet ada banyak kode di Verilog dan VHDL dengan penerapan array sistolik, misalnya, kode berada di
bawah posting blog ini :

module top(clk,reset,a1,a2,a3,b1,b2,b3,c1,c2,c3,c4,c5,c6,c7,c8,c9); parameter data_size=8; input wire clk,reset; input wire [data_size-1:0] a1,a2,a3,b1,b2,b3; output wire [2*data_size:0] c1,c2,c3,c4,c5,c6,c7,c8,c9; wire [data_size-1:0] a12,a23,a45,a56,a78,a89,b14,b25,b36,b47,b58,b69; pe pe1 (.clk(clk), .reset(reset), .in_a(a1), .in_b(b1), .out_a(a12), .out_b(b14), .out_c(c1)); pe pe2 (.clk(clk), .reset(reset), .in_a(a12), .in_b(b2), .out_a(a23), .out_b(b25), .out_c(c2)); pe pe3 (.clk(clk), .reset(reset), .in_a(a23), .in_b(b3), .out_a(), .out_b(b36), .out_c(c3)); pe pe4 (.clk(clk), .reset(reset), .in_a(a2), .in_b(b14), .out_a(a45), .out_b(b47), .out_c(c4)); pe pe5 (.clk(clk), .reset(reset), .in_a(a45), .in_b(b25), .out_a(a56), .out_b(b58), .out_c(c5)); pe pe6 (.clk(clk), .reset(reset), .in_a(a56), .in_b(b36), .out_a(), .out_b(b69), .out_c(c6)); pe pe7 (.clk(clk), .reset(reset), .in_a(a3), .in_b(b47), .out_a(a78), .out_b(), .out_c(c7)); pe pe8 (.clk(clk), .reset(reset), .in_a(a78), .in_b(b58), .out_a(a89), .out_b(), .out_c(c8)); pe pe9 (.clk(clk), .reset(reset), .in_a(a89), .in_b(b69), .out_a(), .out_b(), .out_c(c9)); endmodule module pe(clk,reset,in_a,in_b,out_a,out_b,out_c); parameter data_size=8; input wire reset,clk; input wire [data_size-1:0] in_a,in_b; output reg [2*data_size:0] out_c; output reg [data_size-1:0] out_a,out_b; always @(posedge clk)begin if(reset) begin out_a<=0; out_b<=0; out_c<=0; end else begin out_c<=out_c+in_a*in_b; out_a<=in_a; out_b<=in_b; end end endmodule
Saya perhatikan bahwa kode ini tidak dioptimalkan dan umumnya kikuk (dan bahkan ditulis secara tidak profesional - sumber dalam posting menggunakan tugas blok di @ (posedge clk) - saya memperbaikinya). Dasha misalnya dapat menggunakan Verilog menghasilkan konstruk untuk kode yang lebih elegan.
Selain dua realisasi ekstrem dari jaringan saraf (pada prosesor dan pada susunan sistolik), Dasha dapat mempertimbangkan opsi lain yang lebih cepat dari prosesor, tetapi tidak begitu rakus seperti penggandaan susunan sistolik. Benar, ini lebih mungkin bukan untuk anak sekolah, tetapi untuk siswa.
Salah satu opsi adalah perangkat pelaksana dengan sejumlah besar blok fungsi yang beroperasi secara paralel, seperti pada prosesor Out-of-Order:

Pilihan lain adalah apa yang disebut Coarse Grained Reconfigurable Array - sebuah matriks elemen kuasi-prosesor, yang masing-masing memiliki program kecil. Elemen prosesor ini idealnya mirip dengan sel FPGA / FPGA, tetapi tidak beroperasi dengan sinyal individual, tetapi dengan kelompok bit / angka pada bus dan register - lihat
laporan langsung dari kelahiran pemain utama dalam perangkat keras AI, yang mempercepat TensorFlow dan bersaing dengan NVidia " .
Sekarang surat asli dari Dasha:
Selamat siang, Yuri.
Pada 2017, saya belajar di sekolah Anda di LSHUP di bengkel Anda dan pada Oktober 2017 saya berpartisipasi dalam konferensi di Tomsk pada Oktober tahun yang sama dengan pekerjaan yang ditujukan untuk menanamkan unit multiplikasi dalam prosesor SchooolMIPS.
Saya ingin melanjutkan pekerjaan ini sekarang. Saat ini, saya berhasil mendapatkan izin di sekolah untuk mengambil topik ini sebagai kursus kecil. Apakah Anda memiliki kesempatan untuk membantu saya dengan kelanjutan pekerjaan ini?
PS Karena pekerjaan dilakukan dalam format tertentu, diperlukan penulisan pengantar dan tinjauan pustaka dari topik tersebut. Mohon saran sumber-sumber dari mana Anda dapat mengambil informasi tentang sejarah perkembangan topik ini, tentang filosofi arsitektur, dll., Jika Anda memiliki sumber daya seperti itu dalam pikiran.
Ditambah lagi, saat ini saya tinggal di Moskow di sekolah asrama, mungkin lebih mudah untuk berinteraksi.
Salam
Daria Krivoruchko.
Dasha mengajar Verilog dan mendaftar desain tingkat dengan bantuan saya dan buku
"Sirkuit Digital dan Arsitektur Komputer" oleh David Harris dan Sarah Harris . Namun, jika Anda seorang anak sekolah / sekolah dan ingin memahami konsep dasar pada tingkat yang sangat sederhana, maka bagi Anda penerbit DMK-Press telah merilis
terjemahan bahasa Rusia dari manga Jepang 2013 tentang sirkuit digital yang dibuat oleh Amano Hideharu dan Meguro Koji. Terlepas dari bentuk presentasi yang sembrono, buku ini dengan benar memperkenalkan elemen logis dan pemicu-D,
dan kemudian mengikat ini ke FPGA :
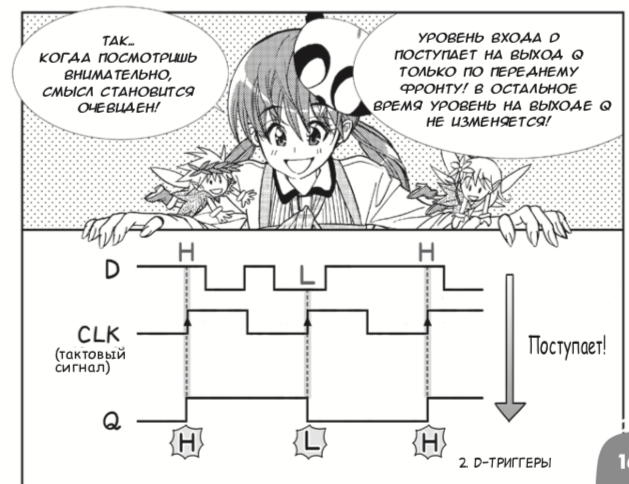
Inilah yang tampak seperti
Sekolah Musim Panas untuk Pemrogram Muda di Wilayah Novosibirsk, tempat Dasha mempelajari Verilog, FPGAs, metodologi pengembangan transfer register (Register Transfer Level - RTL):


Dan inilah pidato Dasha di konferensi di Tomsk bersama dengan siswa kelas sepuluh lainnya, Arseniy Chegodaev:
Setelah pembicaraan Dasha dengan saya dan jilbab Stanislav
Zhelnio , pencipta utama prosesor prosesor pendidikan schoolMIPS untuk implementasi pada FPGA:

Proyek schoolMIPS dilengkapi dengan dokumentasi di
https://github.com/MIPSfpga/schoolMIPS . Dalam konfigurasi paling sederhana dari inti prosesor pelatihan ini, hanya ada 300 garis di Verilog, sementara di inti tertanam industri dari kelas menengah ada sekitar 300 ribu garis. Namun demikian, Dasha dapat merasakan seperti apa karya para desainer di industri, yang mengubah dekoder dan perangkat pelaksana dengan cara yang sama ketika mereka menambahkan instruksi baru ke prosesor:
Sebagai kesimpulan, kami menyajikan foto-foto dekan Universitas Samara Ilya Kudryavtsev, yang tertarik untuk membuat sekolah musim panas dan olimpiade dengan prosesor FPGA untuk pelamar masa depan:

Dan foto karyawan MIET Zelenograd yang sudah merencanakan sekolah musim panas tahun depan:

Baik bahan dari RUSNANO, dan bahan yang mungkin dari Olimpiade NTI, serta prestasi yang telah dicapai selama beberapa tahun terakhir dalam penerapan FPGA dan mikroarsitektur dalam program MIEM HSE, Universitas Negeri Moskow dan
Kazan Innopolis, harus berjalan dengan baik di satu tempat dan di tempat lain.