Kami di X5 memproses banyak data dalam sistem ERP. Diyakini bahwa tidak ada orang lain yang memproses kami dalam SAP ERP dan SAP BW di Rusia. Tetapi ada titik lain - jumlah operasi dan beban pada sistem ini meningkat dengan cepat. Selama 3 tahun kami "berjuang" untuk kinerja kelas berat ERP kami, mendapat banyak kerucut, dan metode apa yang mereka tangani, kami katakan di bawah potongan.

ERP X5
Sekarang X5 mengoperasikan lebih dari 13.000 toko. Sebagian besar proses bisnis masing-masing melalui sistem ERP tunggal. Setiap toko dapat memiliki 3.000 hingga 30.000 produk, karena ini menciptakan masalah dengan beban pada sistem, karena proses perhitungan ulang harga secara berkala melewatinya sesuai dengan promosi dan persyaratan legislatif dan perhitungan pengisian kembali persediaan. Semua ini sangat penting, dan jika tidak dihitung dalam waktu barang mana dalam jumlah berapa yang harus dikirim ke toko besok atau berapa harga pada barang, pembeli tidak akan menemukan apa yang mereka cari di rak atau tidak akan dapat membeli barang dengan harga promosi saat ini persediaan. Secara umum, selain akuntansi untuk transaksi keuangan, sistem ERP bertanggung jawab banyak dalam kehidupan sehari-hari setiap toko.
Sedikit karakteristik kinerja sistem ERP. Arsitekturnya klasik, tiga tingkat dengan elemen berorientasi layanan: di atas kami memiliki lebih dari 5.000 pelanggan tebal dan terabyte arus informasi dari toko dan pusat distribusi, di lapisan aplikasi - SAP ABAP dengan lebih dari 10.000 proses dan, akhirnya, Oracle Database dengan lebih dari 100 TB data. Setiap proses ABAP adalah mesin virtual bersyarat yang menjalankan logika bisnis ABAP dengan dialek DBSL dan SQL, caching, manajemen memori, ORM, dll. Setiap hari kami mendapatkan lebih dari 15 Tb perubahan dalam log basis data. Level beban adalah 500.000 permintaan per detik.
Arsitektur ini adalah lingkungan yang heterogen. Masing-masing komponen adalah lintas-platform, kita dapat memindahkannya ke platform yang berbeda, pilih yang optimal, dll.
Fakta bahwa sistem ERP di bawah beban 24 jam sehari, 365 hari setahun menambah bahan bakar ke api. Ketersediaan - 99,9% dari waktu sepanjang tahun. Beban dibagi menjadi profil siang dan malam dan pemeliharaan rumah di waktu luang.
Tapi itu belum semuanya. Sistem memiliki siklus rilis yang ketat dan ketat. Ini membawa lebih dari 2.000 perubahan batch per tahun. Ini mungkin satu tombol baru, dan perubahan serius dalam logika aplikasi bisnis.

Sebagai hasilnya, ini adalah sistem yang besar dan sangat sarat muatan, tetapi pada saat yang sama stabil, dapat diprediksi dan siap tumbuh yang dapat menampung puluhan ribu toko. Tapi itu tidak selalu terjadi.
2014. Titik Bifurkasi
Untuk menyelami materi praktis, Anda harus kembali ke 2014. Lalu ada tugas yang paling sulit untuk mengoptimalkan sistem. Ada sekitar 5.000 toko.
Sistem pada waktu itu berada dalam kondisi sedemikian rupa sehingga sebagian besar proses kritis tidak dapat diskalakan dan tidak cukup menanggapi meningkatnya beban (yaitu, penampilan toko dan barang baru). Selain itu, dua tahun sebelumnya, Hi-End yang mahal dibeli, dan untuk beberapa waktu upgrade bukan bagian dari rencana kami. Selain itu, proses dalam ERP sudah di ambang melanggar SLA. Vendor menyimpulkan bahwa beban pada sistem tidak dapat diskalakan. Tidak ada yang tahu jika dia bisa menahan setidaknya + 10% dari peningkatan beban. Dan direncanakan untuk membuka toko dua kali lebih banyak dalam waktu tiga tahun.
Tidak mungkin memberi makan sistem ERP dengan besi baru, dan itu tidak akan membantu. Oleh karena itu, pertama-tama, kami memutuskan untuk memasukkan teknik optimasi perangkat lunak dalam siklus rilis dan mengikuti aturan: pertumbuhan beban linier dalam proporsi terhadap pertumbuhan driver beban adalah kunci untuk kemampuan prediksi dan skalabilitas.
Apa teknik pengoptimalannya? Ini adalah proses siklus, dibagi menjadi beberapa tahap:
- pemantauan (mengidentifikasi kemacetan dalam sistem dan mengidentifikasi konsumen atas sumber daya)
- analisis (pembuatan profil proses konsumen, identifikasi struktur dengan efek terbesar dan non-linear pada beban)
- pengembangan (mengurangi pengaruh struktur pada beban, mencapai beban linier)
- pengujian di lingkungan penilaian kualitas atau implementasi di lingkungan yang produktif
Selanjutnya, siklus itu diulang.
Dalam prosesnya, kami menyadari bahwa alat pemantauan saat ini tidak memungkinkan kami untuk dengan cepat mengidentifikasi konsumen top, untuk mengidentifikasi hambatan dan proses yang membutuhkan sumber daya. Karena itu, untuk mempercepat, kami mencoba alat pencarian elastis dan Grafana. Untuk melakukan ini, mereka secara mandiri mengembangkan pengumpul yang, dari alat pemantauan standar di Oracle / SAP / AIX / Linux, mentransfer metrik ke pencarian elastis dan memungkinkan pemantauan waktu nyata kesehatan sistem. Selain itu, mereka memperkaya pemantauan dengan metrik khusus mereka, misalnya, waktu respons dan throughput komponen SAP tertentu atau tata letak profil pemuatan untuk proses bisnis.
Kode dan optimasi proses
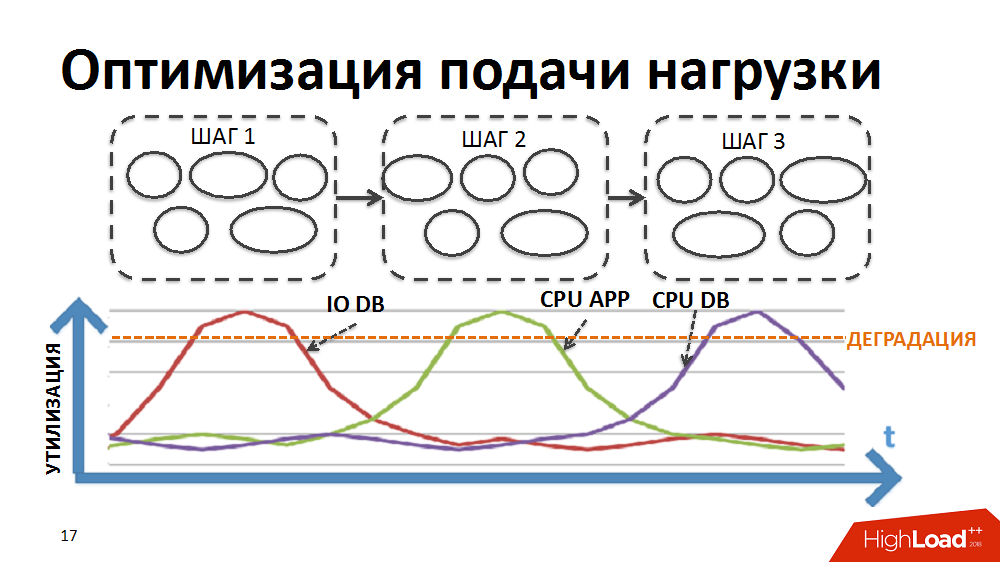
Pertama-tama, untuk efek kemacetan yang lebih rendah pada kecepatan, mereka memastikan pasokan beban yang lebih lancar ke sistem.
Sebagian besar proses bisnis dalam sistem ERP kami, misalnya, seperti penetapan harga reguler atau perencanaan untuk pengisian kembali persediaan, merupakan pemrosesan bertahap langkah demi langkah dari sejumlah besar data (untuk semua barang dan semua toko). Untuk mengimplementasikan pemrosesan dalam rangka tugas-tugas sulit tersebut, pada suatu waktu kami mengembangkan dispatcher pemrosesan paralel-paralel kami sendiri (selanjutnya disebut sebagai penjadwal beban). Dalam hal ini, dalam bentuk paket, langkah pemrosesan yang dilakukan secara terpisah untuk toko terpisah disajikan.
Awalnya, logika penjadwal adalah sedemikian rupa sehingga pertama paket dari tahap pemrosesan pertama dieksekusi untuk semua toko, kemudian paket dari tahap kedua, dll. Artinya, sistem secara bersamaan melakukan proses yang menciptakan jenis beban yang sama dan menyebabkan degradasi sumber daya tertentu (input / output ke database atau CPU pada server aplikasi, dll.).
Kami menulis ulang logika penjadwal sehingga rantai paket dibentuk secara terpisah untuk setiap toko dan prioritas meluncurkan paket baru dibangun bukan secara bertahap, tetapi oleh toko.
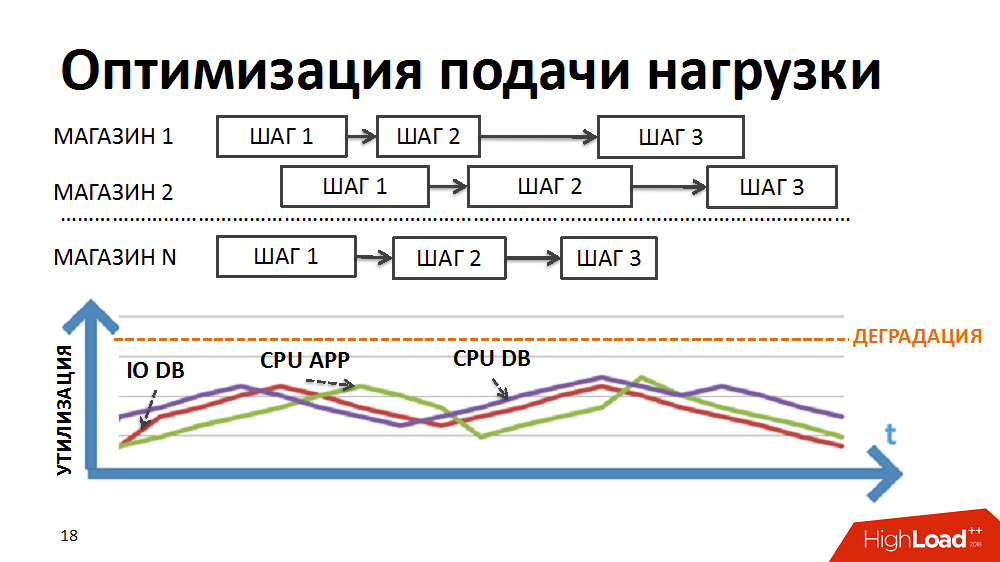
Karena durasi paket yang berbeda untuk toko yang berbeda dan sejumlah besar proses yang dijalankan secara bersamaan dalam rangka tugas penjadwal beban, kami telah mencapai eksekusi simultan dari proses heterogen, pemuatan beban yang lebih lancar dan penghapusan beberapa hambatan.
Kemudian mereka mulai mengoptimalkan desain individual. Setiap paket individu ditinjau, diprofilkan, dan dirakit desain yang tidak optimal dan pendekatan yang diterapkan untuk mengoptimalkannya. Selanjutnya, pendekatan ini dimasukkan dalam peraturan pengembang untuk mencegah pertumbuhan beban yang tidak diinginkan selama pengembangan sistem. Beberapa di antaranya:
- beban berlebihan pada CPU dari server aplikasi (Sering dihasilkan oleh algoritma non-linear dalam kode program, misalnya, pencarian linear lama yang baik dalam loop atau algoritma non-linear untuk menemukan persimpangan set elemen yang tidak teratur, dll.) Itu diperlakukan dengan mengganti dengan algoritma linier: mengganti pencarian linear dalam loop dengan biner; untuk mencari persimpangan set, kami menggunakan algoritma linier, elemen pra-pemesanan, dll.)
- panggilan yang identik ke database dengan kondisi yang sama dalam proses yang sama sering menyebabkan pemanfaatan CPU yang berlebihan dari basis data (itu diperlakukan dengan caching hasil sampel pertama dalam memori program atau pada tingkat server aplikasi dan menggunakan data cache untuk sampel berikutnya)
- sering bergabung dengan permintaan (lebih baik untuk mengeksekusinya, tentu saja, di tingkat basis data, tetapi kadang-kadang kami membiarkan diri kami untuk membaginya menjadi sampel sederhana, yang hasilnya di-cache, dan mentransfer logika pengeleman ke aplikasi. Itu adalah kasus di mana lebih baik menghangatkan server aplikasi, dan bukan database. )
- permintaan bergabung yang banyak menghasilkan banyak I / O
Tentang yang terakhir lebih terinci. Dalam hal ini, model data diterjemahkan ke dalam bentuk yang kurang normal. Contoh klasik adalah pemilihan dokumen akuntansi untuk tanggal tertentu untuk setiap toko. Banyak karyawan yang memintanya. Tabel master (tabel heading) menyimpan tanggal dokumen, dalam tabel posisi - toko dan barang. Pertanyaan paling umum adalah pemilihan semua dokumen untuk toko tertentu untuk tanggal tertentu. Dengan permintaan ini, filter berdasarkan tanggal pada tabel tajuk memberikan 500 ribu catatan, filter menurut toko - jumlah yang sama. Pada saat yang sama, setelah menempel pada toko terpisah untuk tanggal yang tepat, kami memiliki jangka waktu 3 ribu. Tidak masalah dari tabel mana kita mulai memfilter dan menempelkan data, kita selalu mendapatkan banyak I / O yang tidak diinginkan.
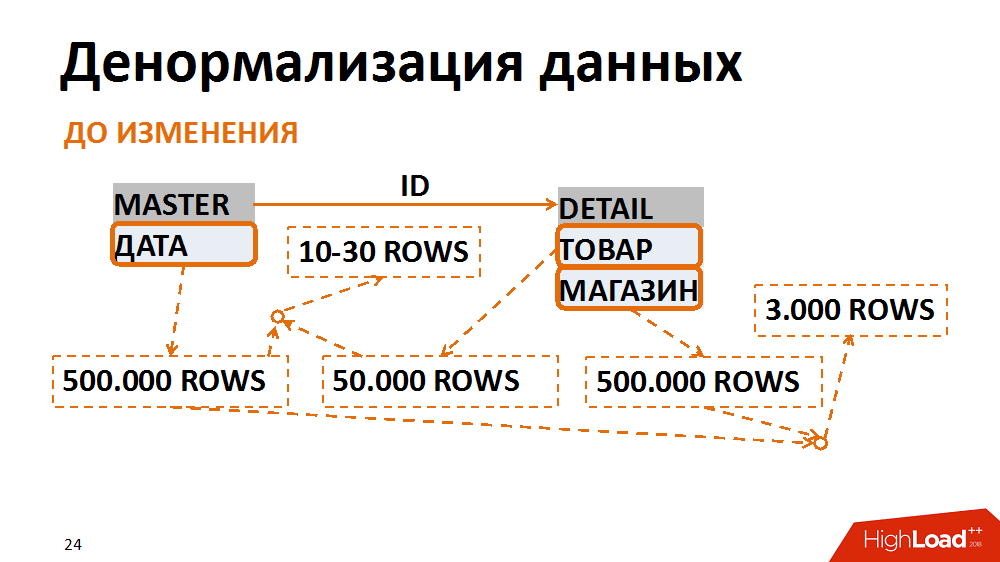
Ini dapat dihindari dengan menyajikan data dalam bentuk yang kurang normal. Dalam satu kasus, bidang tanggal digandakan dalam tabel posisi, itu diisi saat membuat dokumen, indeks dikumpulkan untuk pencarian cepat, dan mereka sudah disaring sesuai dengan tabel posisi. Jadi, setelah mengorbankan biaya overhead yang tidak signifikan untuk menyimpan bidang dan indeks baru, kami telah mengurangi jumlah operasi input / output yang dihasilkan oleh kueri bermasalah beberapa kali.

2015. Masalah satu layanan
Selama satu setengah tahun, kami melakukan pekerjaan yang baik untuk mengoptimalkan sistem, itu menjadi lebih dapat diprediksi. Meskipun demikian, rencana untuk menggandakan jumlah toko tetap relevan, sehingga tantangan tetap kami hadapi.
Di tengah perjalanan kami menemui berbagai hambatan. Sebagai contoh, pada akhir 2015, mereka menyadari bahwa mereka telah beristirahat dalam kinerja satu layanan inti platform. Ini adalah layanan kunci logis SAP ABAP. Karena itu, sistem jelas tidak akan tahan terhadap pertumbuhan beban. Kerugian uang besar tampak di cakrawala.
Untuk memperjelas, tugas layanan adalah untuk membawa transaksionalitas logis ke tingkat server aplikasi. Di ABAP, satu transaksi dapat melalui beberapa langkah pada alur kerja yang berbeda. Agar transaksi selesai, ada layanan kunci dan mekanisme terkait. Operasi mengunci dan membuka kunci di dalamnya terjadi dengan cepat, tetapi bersifat atomik, tidak dapat dipisahkan. Ada masalah dengan I / O sinkron.
Layanan dipercepat sedikit setelah pengembang SAP merilis tambalan khusus, kami beralih layanan ke perangkat keras lain dan bekerja pada pengaturan sistem, tetapi ini masih belum cukup. Langit-langit layanan paspor sekitar 7 ribu operasi per detik, dan untuk waktu yang lama kami sudah membutuhkan 10 ribu.
Setelah uji beban sintetis, ditemukan bahwa degradasi bersifat non-linier dan kami tetap pada batas kinerja layanan di atas yang mana degradasi yang tidak dapat diterima dari seluruh sistem ERP dimanifestasikan. Panggilan berulang ke pengembang hanya memberikan vonis mengecewakan - layanan ini berfungsi dengan benar, kami hanya membutuhkan terlalu banyak dalam arsitektur solusi saat ini. Bahkan jika kita segera berusaha untuk memperbaiki seluruh arsitektur solusi, kita perlu beberapa bulan untuk mempertahankan operabilitas sistem saat ini.
Salah satu opsi pertama untuk mencoba memperpanjang umur layanan kunci adalah untuk mempercepat I / O dan menulis ke sistem file. Apa? Eksperimen dengan alternatif untuk AIX. Ditransfer layanan ke Linux pada mesin-Power paling kuat, dan memenangkan banyak waktu respon. Layanan dengan sistem file yang dihidupkan berperilaku sama seperti pada Aix dengan yang dinonaktifkan. Kemudian kami mentransfer kode ini ke salah satu blade x86_64 dan mendapatkan kurva kinerja yang bahkan lebih landai daripada sebelumnya. Itu terlihat lucu.
Dapat diasumsikan bahwa pengembang pada AIX dan Linux melakukan sesuatu yang berbeda pada pengujian terakhir, tetapi arsitektur prosesor juga memiliki efek di sini.
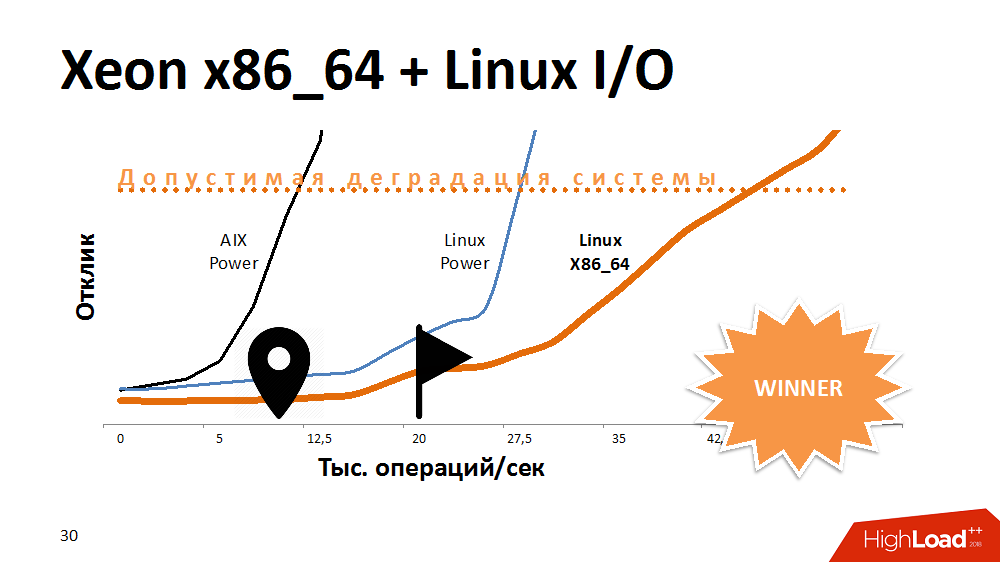
Apa kesimpulannya? Beberapa platform ideal untuk database multi-threaded, memberikan kinerja dan toleransi kesalahan, tetapi prosesor pada arsitektur yang berbeda dapat mengatasi tugas-tugas spesifik dengan lebih baik. Jika pada awal membangun solusi untuk meninggalkan lintas platform, Anda dapat kehilangan ruang untuk bermanuver di masa depan.
Namun demikian, kami menemukan masalah ini dan layanan mulai bekerja 3-4 kali lebih cepat, yang cukup untuk pertumbuhan yang sangat lama.
2016. DB CPU Bottleneck
Secara harfiah enam bulan kemudian, masalah eksotis mulai dirasakan dengan CPU pada database. Tampak jelas bahwa dengan peningkatan beban, konsumsi sumber daya prosesor meningkat. Tetapi SysTime mulai mengambil sebagian besar dari itu, dan jelas ada masalah di kernel. Mereka mulai memahami, melakukan uji beban sintetis dan menyadari bahwa throughput kami adalah 300 ribu operasi per detik, yaitu miliar permintaan per jam, dan kemudian degradasi.
Akibatnya, kami sampai pada kesimpulan bahwa permintaan sempurna adalah permintaan yang tidak ada. Kami memperluas teknik optimisasi kami dengan pendekatan baru dan melakukan audit sistem ERP: kami mulai mencari pertanyaan, misalnya, dengan efisiensi rendah (100 ribu pilihan - sebagai hasil dari 100 baris atau 0 pada umumnya) - untuk diulang. Jika permintaan "kosong" tidak dapat dihapus, maka biarkan masuk ke "cache negatif", jika sesuai. Jika banyak permintaan untuk data produk yang sama diproses secara paralel, maka biarkan mereka menyiksa server aplikasi, dan bukan database, kami menyimpannya. Kami juga "memperbesar" sejumlah besar permintaan tunggal yang sering pada kunci dalam kerangka kerja satu proses, menggantinya dengan pilihan yang lebih jarang pada bagian kunci. Atau, misalnya, untuk mendistribusikan beban dalam rantai pemrosesan, langkah-langkah yang berbeda dapat dilakukan pada server aplikasi yang berbeda. Ini bagus, tetapi pada tahap yang berbeda mereka dapat menanyakan hal yang sama dari pangkalan. Kemudian biarkan langkah pertama setelah memulai aplikasi cache bagian dari permintaan, dan itu tetap di sana untuk menyelesaikan sisa rantai.

Dengan bantuan trik semacam itu, kami menang sedikit di mana-mana, tetapi pada akhirnya kami dengan serius menurunkan pangkalan. Sistem menjadi hidup. Sementara itu, kami turun ke Aix.
Eksperimen lain mengungkapkan bahwa ada plafon kinerja - 300.000 panggilan DataBase yang telah disebutkan per detik. Akar masalahnya adalah kinerja antarmuka jaringan, yang memiliki langit-langit - sekitar 300 ribu paket per detik dalam satu arah. Ketika langit-langit semakin dekat, waktu panggilan sistem tumbuh. Ternyata kemudian, itu juga merupakan warisan dari tumpukan jaringan kernel AIX.
Secara umum, kami tidak pernah memiliki masalah dengan latensi, inti dari jaringan itu produktif, semua kabel dirakit menjadi saluran besar yang tidak bisa dihancurkan pada satu antarmuka. Kami membuat solusi: kami membagi seluruh jaringan antara server aplikasi dan database menjadi kelompok-kelompok pada antarmuka yang berbeda. Akibatnya, setiap kelompok server aplikasi berkomunikasi dengan database melalui antarmuka yang terpisah. Kinerja maksimum setiap antarmuka sedikit berkurang, tetapi secara total kami melakukan overclock jaringan ke 1 juta paket per detik dalam satu arah.
Dan prinsip "Permintaan terbaik adalah yang tidak ada" ditambahkan ke Talmud untuk pengembang, sehingga ini diperhitungkan saat menulis kode.
2017. Langsung untuk ditingkatkan
Nah, tahap terakhir pemulihan sistem kami, berlalu pada 2017. Yang tersisa hanyalah hidup sedikit sampai upgrade dan itu perlu untuk memegang SLA untuk apa-apa. Kode dioptimalkan, tetapi kami melihat bahwa semakin tinggi beban pada basis data CPU, semakin lambat proses kerjanya, meskipun margin pemanfaatannya 10-20%. Awalnya, diperkirakan 100% dua kali lipat 50%. Dan ketika ada cadangan 10-20%, ini adalah 10-20%. Bahkan, pada beban di atas 67-80%, durasi tugas nonlinier meningkat, yaitu Hukum Amdahl bekerja. Sistem memiliki batas paralelisasi dan ketika terlampaui, dengan keterlibatan semakin banyak prosesor dalam pekerjaan, kinerja setiap prosesor individu menurun.
Pada saat itu, kami menggunakan 125 prosesor fisik, atau 500 prosesor logis, mempertimbangkan multithreading di tingkat AIX. Apa yang akan Anda sarankan? Tingkatkan? Bahkan sebelum akhir koordinasinya, perlu untuk bertahan selama beberapa bulan dan tidak menjatuhkan SLA.
Pada titik tertentu, mereka menyadari bahwa metrik pemanfaatan prosesor tradisional bukan merupakan indikasi bagi kami - mereka tidak menunjukkan awal sebenarnya degradasi. Untuk penilaian realistis terhadap kesehatan sistem, kami mulai menggunakan metrik terintegrasi - hasil uji sintetik sebagai metrik untuk kinerja prosesor basis data. Sekali semenit mereka melakukan tes sintetis, mengukur durasinya dan menampilkan metrik ini di monitor kami. Dan mereka bereaksi jika metrik naik di atas titik kritis yang dinyatakan. Kami menahan beban perencana beban kami sedikit sehingga tetap berada di area "torsi maksimum" dari database.
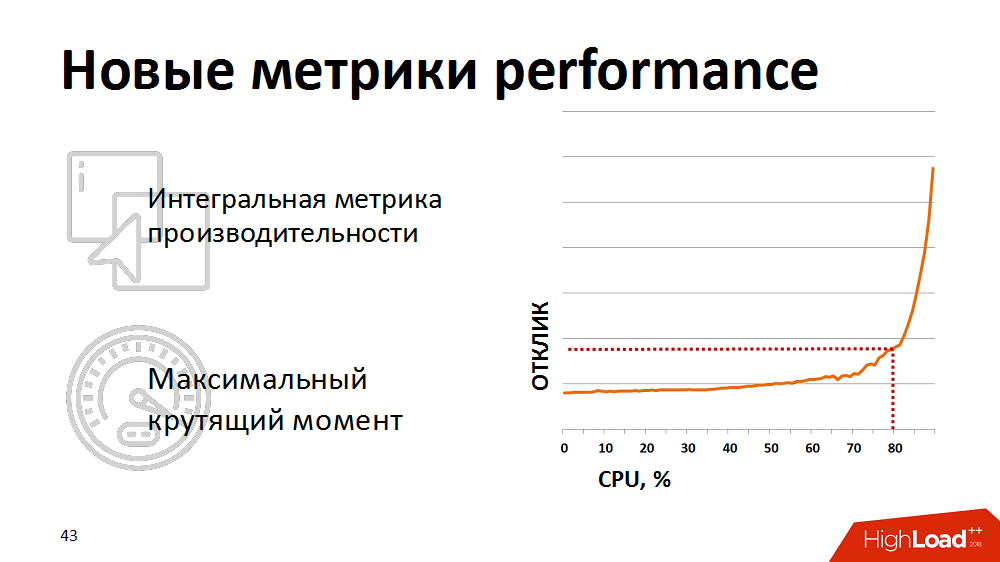
Namun, kontrol manual tidak efektif, dan kami lelah bangun di malam hari. Kemudian kami menulis ulang perencana muat sehingga ia mendapat umpan balik tentang metrik kinerja saat ini. Jika metrik melampaui ambang kuning (lihat gambar), perencanaan paket prioritas rendah dibekukan dan hanya proses kritis bisnis yang mendapat prioritas. Dengan demikian, secara otomatis kami dapat mengontrol intensitas beban dan sumber daya digunakan secara efisien. Dan hal yang paling menarik adalah bahwa menjaga sistem tetap dalam 80% dari beban, dalam zona torsi maksimum yang sama, kami akhirnya mendapatkan pengurangan dalam total waktu untuk menjalankan proses bisnis, karena setiap utas mulai bekerja lebih cepat.
Beberapa tips untuk mereka yang bekerja dengan ERP yang sangat dimuat
- Sangat penting untuk memantau kinerja sistem pada awal proyek, terutama dengan metrik mereka sendiri.
- Pastikan peningkatan linier dalam beban sebanding dengan peningkatan jumlah driver beban (dalam kasus kami, mereka adalah barang dan toko).
- Hilangkan konstruksi non-linear dalam kode, gunakan caching untuk menghilangkan query database yang identik.
- Jika Anda perlu mentransfer beban dari CPU basis data ke CPU server aplikasi, maka Anda dapat menggunakan memecah permintaan bergabung menjadi sampel sederhana.
- Untuk semua optimisasi, ingat bahwa permintaan cepat itu baik, dan permintaan cepat dan sering terkadang buruk.
- Cobalah untuk selalu menyelidiki dan memanfaatkan lingkungan solusi yang heterogen.
- Seiring dengan metrik kinerja tradisional, gunakan metrik terintegrasi yang secara unik mengidentifikasi degradasi; Dengan menggunakan metrik ini, tentukan zona "torsi maksimum" dari sistem Anda.
- Menyediakan alat perencanaan beban dengan mekanisme untuk memantau metrik kinerja saat ini dan mengelola laju aliran beban untuk menggunakan sumber daya sistem secara efisien
Kami berterima kasih kepada penyelenggara Highload atas kesempatan untuk berbagi pengalaman ini tidak hanya di Habré, tetapi juga di panggung acara terbesar pada sistem yang sarat muatan.
Dmitry Tsvetkov, Alexander Lishchuk, pakar SAP di # ITX5Omong-omong, # ITX5 mencari konsultan SAP.