Pernahkah Anda diminta untuk menghitung jumlah sesuatu berdasarkan data dalam basis data untuk bulan lalu, mengelompokkan hasil berdasarkan beberapa nilai dan memecahnya berdasarkan hari / jam?
Jika ya - maka Anda sudah membayangkan bahwa Anda harus menulis sesuatu seperti ini, hanya saja lebih buruk
SELECT hour(datetime), somename, count(*), sum(somemetric) from table where datetime > :monthAgo group by 1, 2 order by 1 desc, 2
Dari waktu ke waktu, berbagai permintaan seperti itu mulai muncul, dan jika Anda bertahan dan membantu sekali, sayangnya, permohonan akan datang di masa depan.
Tetapi permintaan seperti itu buruk karena mereka mengkonsumsi sumber daya sistem dengan baik pada saat runtime, dan mungkin ada begitu banyak data sehingga bahkan replika untuk permintaan tersebut akan sangat disayangkan (dan waktunya).
Tetapi bagaimana jika saya mengatakan bahwa secara langsung dalam PostgreSQL Anda dapat membuat pandangan bahwa dengan cepat hanya akan mempertimbangkan data yang masuk baru dalam permintaan yang mirip langsung, seperti di atas?
Jadi - dapat melakukan ekstensi PipelineDB
Demo dari situs mereka cara kerjanya PipelineDB sebelumnya merupakan proyek yang terpisah, tetapi sekarang tersedia sebagai ekstensi untuk PG 10.1 dan lebih tinggi.
Dan meskipun peluang yang disediakan telah lama ada di produk lain yang dirancang khusus untuk mengumpulkan metrik waktu nyata, PipelineDB memiliki nilai tambah yang signifikan: ambang masuk yang lebih rendah untuk pengembang yang sudah tahu SQL).
Mungkin bagi sebagian orang itu tidak penting. Secara pribadi, saya tidak terlalu malas untuk mencoba segala sesuatu yang tampaknya cocok untuk menyelesaikan masalah tertentu, tetapi saya tidak akan segera pindah untuk menggunakan satu solusi baru untuk semua kasus. Oleh karena itu, dalam artikel ini saya tidak mendesak untuk meninggalkan semuanya dan menginstal PipelineDB segera, ini hanya gambaran umum dari fungsi utama, seperti hal itu sepertinya membuatku penasaran.
Jadi, secara umum, mereka memiliki dokumentasi yang baik, tetapi saya ingin berbagi pengalaman saya tentang bagaimana mencoba bisnis ini dalam praktik dan membawa hasilnya ke Grafana.
Agar tidak membuang sampah ke mesin lokal, saya mengerahkan semuanya di buruh pelabuhan.
Gambar yang digunakan:
postgres:latest ,
grafana/grafanaInstal PipelineDB pada Postgres
Pada mesin dengan postgres, jalankan secara berurutan:
apt updateapt install curlcurl -s http://download.pipelinedb.com/apt.sh | bashapt install pipelinedb-postgresql-11cd /var/lib/postgresql/data- Buka file
postgresql.conf di editor mana pun - Temukan kunci
shared_preload_libraries , batalkan komentar dan atur nilai pipelinedb max_worker_processes diatur ke 128 (dok rekomendasi)- Reboot server
Membuat aliran dan tampilan di PipelineDB
Setelah reboot pg - perhatikan log sehingga ada hal seperti itu - Basis data tempat kami akan bekerja:
CREATE DATABASE testpipe; - Membuat ekstensi:
CREATE EXTENSION pipelinedb; - Sekarang hal yang paling menarik adalah membuat aliran. Di dalamnya Anda perlu menambahkan data untuk diproses lebih lanjut:
CREATE FOREIGN TABLE flow_stream ( dtmsk timestamp without time zone, action text, duration smallint ) SERVER pipelinedb;
Faktanya, ini sangat mirip dengan membuat tabel biasa, Anda tidak bisa hanya mendapatkan data dari aliran ini dengan pilihan sederhana - Anda perlu melihat - sebenarnya cara membuatnya:
CREATE VIEW viewflow WITH (ttl = '3 month', ttl_column = 'm') AS select minute(dtmsk) m, action, count(*), avg(duration)::smallint, min(duration), max(duration) from flow_stream group by 1, 2;
Mereka disebut Tampilan Kontinu dan default untuk terwujud, yaitu dengan pelestarian negara.
WITH melewati parameter tambahan.
Dalam kasus saya, ttl = '3 month' berarti Anda hanya perlu menyimpan data selama 3 bulan terakhir, dan mengambil tanggal / waktu dari kolom M Proses reaper latar belakang reaper data yang sudah usang dan menghapusnya.
Bagi mereka yang tidak tahu, fungsi minute mengembalikan tanggal / waktu tanpa detik. Dengan demikian, semua peristiwa yang terjadi dalam satu menit akan memiliki waktu yang sama sebagai hasil agregasi. - Pandangan seperti itu hampir berupa tabel, karena indeks berdasarkan tanggal untuk pengambilan sampel akan bermanfaat jika banyak data disimpan
create index on viewflow (m desc, action);
Menggunakan PipelineDB
Ingat: masukkan data ke dalam aliran, dan baca dari tampilan berlangganan itu
insert into flow_stream VALUES (now(), 'act1', 21); insert into flow_stream VALUES (now(), 'act2', 33); select * from viewflow order by m desc, action limit 4; select now()
Saya menjalankan permintaan secara manual Pertama saya melihat bagaimana data berubah pada menit ke-46
Begitu yang ke-47 datang, yang sebelumnya berhenti memperbarui dan menit saat ini mulai berdetak.
Jika Anda memperhatikan rencana kueri, Anda bisa melihat tabel asli dengan data
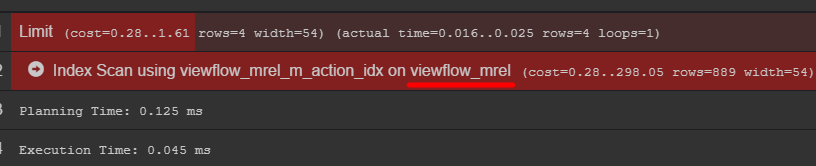
Saya sarankan pergi ke sana dan mencari tahu bagaimana data Anda sebenarnya disimpan
C # Event Generator using Npgsql; using System; using System.Threading; namespace PipelineDbLogGenerator { class Program { private static Random _rnd = new Random(); private static string[] _actions = new string[] { "foo", "bar", "yep", "goal", "ano" }; static void Main(string[] args) { var connString = "Host=localhost;port=5432;Username=postgres;Database=testpipe"; using (var conn = new NpgsqlConnection(connString)) { conn.Open(); while (true) { var dt = DateTime.UtcNow; using (var cmd = new NpgsqlCommand()) { var act = GetAction(); cmd.Connection = conn; cmd.CommandText = "INSERT INTO flow_stream VALUES (@dtmsk, @action, @duration)"; cmd.Parameters.AddWithValue("dtmsk", dt); cmd.Parameters.AddWithValue("action", act); cmd.Parameters.AddWithValue("duration", GetDuration(act)); var res = cmd.ExecuteNonQuery(); Console.WriteLine($"{res} {dt}"); } Thread.Sleep(_rnd.Next(50, 230)); } } } private static int GetDuration(string act) { var c = 0; for (int i = 0; i < act.Length; i++) { c += act[i]; } return _rnd.Next(c); } private static string GetAction() { return _actions[_rnd.Next(_actions.Length)]; } } }
Kesimpulan di Grafana
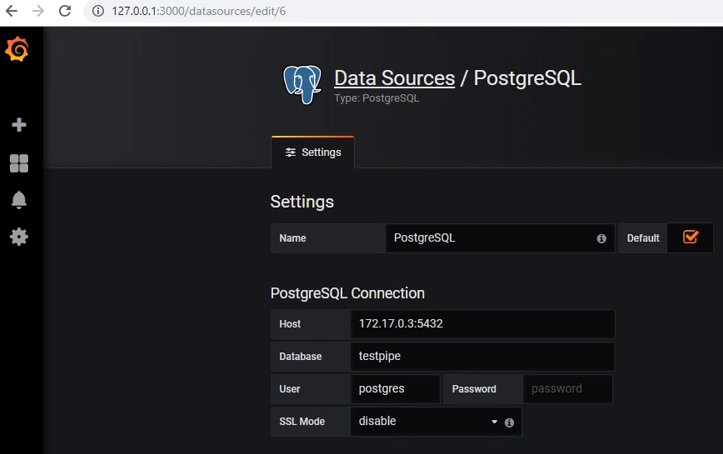
Untuk mendapatkan data dari postgres, Anda perlu menambahkan sumber data yang sesuai:
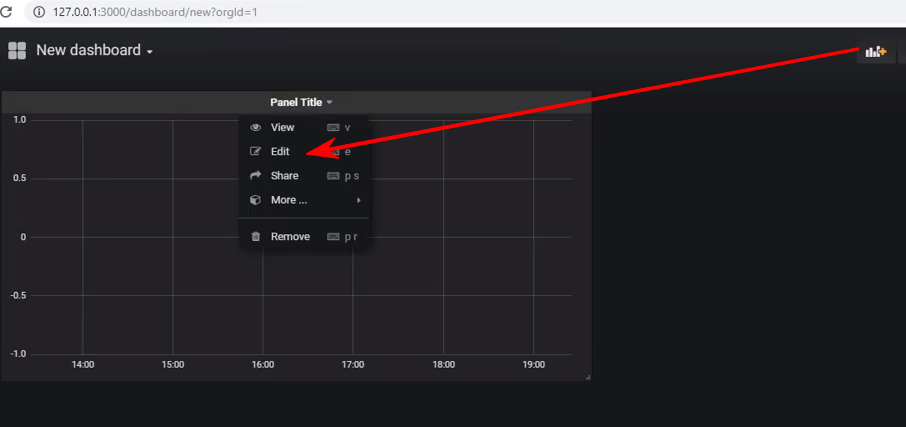
Buat dasbor baru dan tambahkan panel tipe Grafik ke dalamnya, dan setelah itu Anda perlu mengedit panel:
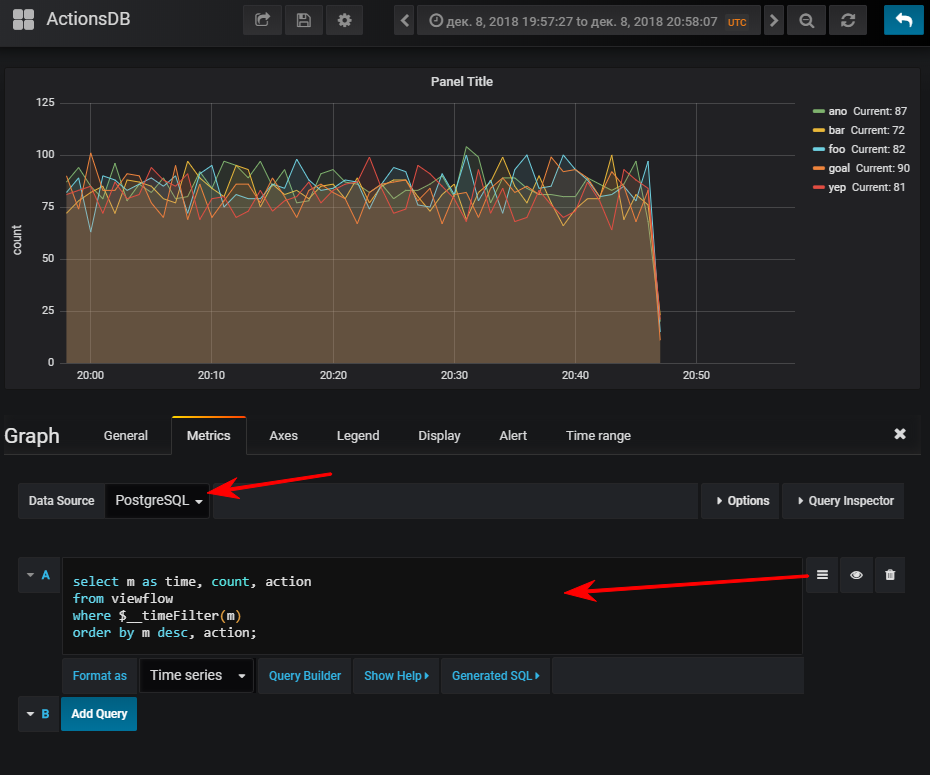
Berikutnya - pilih sumber data, beralih ke mode penulisan sql-query dan masukkan ini:
select m as time,
Dan kemudian Anda mendapatkan jadwal normal, tentu saja, jika Anda memulai generator acara
FYI: memiliki indeks bisa sangat penting. Meskipun penggunaannya tergantung pada volume tabel yang dihasilkan. Jika Anda berencana untuk menyimpan sejumlah kecil baris dalam waktu sedikit, dapat dengan mudah berubah bahwa pemindaian seq akan lebih murah, dan indeks hanya akan menambah ekstra. memuat saat memperbarui nilai
Beberapa tampilan dapat berlangganan satu aliran.
Misalkan saya ingin melihat berapa banyak metode api yang dilakukan oleh persentil
CREATE VIEW viewflow_per WITH (ttl = '3 d', ttl_column = 'm') AS select minute(dtmsk) m, action, percentile_cont(0.50) WITHIN GROUP (ORDER BY duration)::smallint p50, percentile_cont(0.95) WITHIN GROUP (ORDER BY duration)::smallint p95, percentile_cont(0.99) WITHIN GROUP (ORDER BY duration)::smallint p99 from flow_stream group by 1, 2; create index on viewflow_per (m desc);
Saya melakukan trik yang sama dengan grafana dan mendapatkan: Total
Secara umum, masalahnya bekerja, itu berperilaku baik, tanpa keluhan. Meski berada di bawah buruh pelabuhan, mengunduh basis data demo mereka di arsip (2,3 GB) ternyata agak lama.
Saya ingin mencatat - saya tidak melakukan tes stres.
Dokumentasi resmiMungkin menarik