
Melanjutkan artikel kami dengan instruksi praktis tentang cara membuat hidup lebih mudah dalam pekerjaan sehari-hari dengan Kubernetes, kami berbicara tentang dua cerita dari dunia operasi: alokasi node individu untuk tugas-tugas tertentu dan konfigurasi php-fpm (atau server aplikasi lain) untuk beban berat. Seperti sebelumnya, solusi yang dijelaskan di sini tidak mengklaim sebagai yang ideal, tetapi ditawarkan sebagai titik awal untuk kasus spesifik Anda dan dasar untuk refleksi. Pertanyaan dan perbaikan dalam komentar dipersilahkan!
1. Alokasi masing-masing node untuk tugas tertentu
Kami meningkatkan cluster Kubernetes di server virtual, cloud, atau server bare metal. Jika Anda menginstal semua perangkat lunak sistem dan aplikasi klien pada node yang sama, kemungkinan akan ada masalah:
- aplikasi klien tiba-tiba akan mulai "bocor" dari memori, meskipun batasnya sangat tinggi;
- permintaan satu kali yang kompleks untuk loghouse, Prometheus atau Ingress * mengarah ke OOM, akibatnya aplikasi klien menderita;
- kebocoran memori karena bug dalam perangkat lunak sistem membunuh aplikasi klien, meskipun komponen mungkin tidak terhubung secara logis satu sama lain.
* Di antara hal-hal lain, itu relevan untuk versi Ingress yang lebih lama, ketika karena banyaknya koneksi websocket dan pemuatan ulang nginx yang terus-menerus, muncul "proses nginx gantung", yang berjumlah ribuan dan menghabiskan banyak sumber daya.Kasus sebenarnya adalah dengan pemasangan Prometheus dengan sejumlah besar metrik, di mana ketika melihat dasbor "berat", di mana sejumlah besar wadah aplikasi disajikan, dari masing-masing grafik yang diambil, konsumsi memori dengan cepat tumbuh hingga ~ 15 GB. Akibatnya, pembunuh OOM dapat "datang" pada sistem host dan mulai membunuh layanan lain, yang pada gilirannya menyebabkan "perilaku aplikasi yang tidak dapat dipahami dalam cluster". Dan karena beban CPU yang tinggi pada aplikasi klien, mudah untuk mendapatkan waktu pemrosesan kueri Ingress yang tidak stabil ...
Solusi dengan cepat muncul dengan sendirinya: perlu mengalokasikan masing-masing mesin untuk tugas yang berbeda. Kami telah mengidentifikasi 3 jenis utama kelompok tugas:
- Front , tempat kami hanya memasukkan Ingress, untuk memastikan bahwa tidak ada layanan lain yang dapat memengaruhi waktu pemrosesan permintaan;
- Node sistem tempat kami menyebarkan VPN , loghouse , Prometheus , Dashboard, CoreDNS, dll.;
- Node untuk aplikasi - pada kenyataannya, di mana aplikasi klien diluncurkan. Mereka juga dapat dialokasikan untuk lingkungan atau fungsi: dev, prod, perf, ...
Solusi
Bagaimana kita menerapkan ini? Sangat sederhana: dua mekanisme Kubernet asli. Yang pertama adalah
nodeSelector untuk memilih node yang diinginkan di mana aplikasi harus pergi, yang didasarkan pada label yang
dipasang pada setiap node.
Katakanlah kita memiliki simpul
kube-system-1 . Kami menambahkan label tambahan untuk itu:
$ kubectl label node kube-system-1 node-role/monitoring=
... dan dalam
Deployment , yang harus diluncurkan ke simpul ini, kami menulis:
nodeSelector: node-role/monitoring: ""
Mekanisme kedua adalah
noda dan toleransi . Dengan bantuannya, kami secara eksplisit menunjukkan bahwa pada mesin ini hanya wadah yang dapat diluncurkan yang memiliki toleransi terhadap noda ini.
Misalnya, ada mesin
kube-frontend-1 di mana kita hanya akan menggulung Ingress. Tambahkan noda ke simpul ini:
$ kubectl taint node kube-frontend-1 node-role/frontend="":NoExecute
... dan di
Deployment kami membuat toleransi:
tolerations: - effect: NoExecute key: node-role/frontend
Dalam kasus kops, masing-masing grup instance dapat dibuat untuk kebutuhan yang sama:
$ kops create ig --name cluster_name IG_NAME
... dan Anda mendapatkan sesuatu seperti grup contoh ini config in kops:
apiVersion: kops/v1alpha2 kind: InstanceGroup metadata: creationTimestamp: 2017-12-07T09:24:49Z labels: dedicated: monitoring kops.k8s.io/cluster: k-dev.k8s name: monitoring spec: image: kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-01-14 machineType: m4.4xlarge maxSize: 2 minSize: 2 nodeLabels: dedicated: monitoring role: Node subnets: - eu-central-1c taints: - dedicated=monitoring:NoSchedule
Dengan demikian, simpul dari grup instance ini akan secara otomatis menambahkan label dan noda tambahan.
2. Mengkonfigurasi php-fpm untuk beban berat
Ada berbagai macam server yang digunakan untuk menjalankan aplikasi web: php-fpm, gunicorn dan sejenisnya. Penggunaannya dalam Kubernetes berarti bahwa ada beberapa hal yang harus selalu Anda pikirkan:
- Kita perlu memahami kira-kira berapa banyak pekerja yang bersedia kita alokasikan dalam php-fpm di setiap wadah. Misalnya, kami dapat mengalokasikan 10 pekerja untuk memproses permintaan yang masuk, mengalokasikan lebih sedikit sumber daya untuk pod dan skala menggunakan jumlah pod - ini adalah praktik yang baik. Contoh lain adalah mengalokasikan 500 pekerja untuk setiap pod dan memiliki 2-3 pod seperti itu dalam produksi ... tapi ini ide yang sangat buruk.
- Tes hidup / kesiapan diperlukan untuk memverifikasi operasi yang benar dari masing-masing pod dan jika pod macet karena masalah jaringan atau karena akses database (mungkin ada pilihan dan alasan Anda). Dalam situasi seperti itu, Anda harus membuat ulang pod yang bermasalah.
- Penting untuk secara eksplisit mendaftarkan permintaan dan membatasi sumber daya untuk setiap wadah sehingga aplikasi tidak "mengalir" dan tidak mulai membahayakan semua layanan di server ini.
Solusi
Sayangnya,
tidak ada peluru perak yang membantu Anda segera memahami berapa banyak sumber daya (CPU, RAM) aplikasi mungkin perlu. Pilihan yang memungkinkan adalah mengawasi konsumsi sumber daya dan setiap kali memilih nilai optimal. Untuk menghindari kill'ov OOM yang tidak dapat dibenarkan dan pembatasan CPU, yang sangat memengaruhi layanan, Anda dapat menawarkan:
- tambahkan tes liness / readiness yang benar sehingga kita dapat mengatakan dengan pasti bahwa wadah ini berfungsi dengan benar. Kemungkinan besar itu akan menjadi halaman layanan yang memeriksa ketersediaan semua elemen infrastruktur (diperlukan untuk aplikasi untuk bekerja di pod) dan mengembalikan 200 kode respons OK;
- pilih dengan benar jumlah pekerja yang akan memproses permintaan, dan sebarkan dengan benar.
Sebagai contoh, kami memiliki 10 pod yang terdiri dari dua kontainer: nginx (untuk mengirim statika dan permintaan proxy ke backend) dan php-fpm (sebenarnya backend, yang memproses halaman dinamis). Kumpulan php-fpm dikonfigurasikan untuk jumlah pekerja statis (10). Dengan demikian, dalam satuan waktu, kami dapat memproses 100 permintaan aktif ke backend. Biarkan setiap permintaan diproses oleh PHP dalam 1 detik.
Apa yang terjadi jika 1 permintaan lagi tiba di satu pod tertentu, di mana 10 permintaan sedang diproses secara aktif sekarang? PHP tidak akan dapat memprosesnya dan Ingress akan mengirimkannya untuk mencoba lagi ke pod berikutnya jika permintaan GET. Jika ada permintaan POST, itu akan mengembalikan kesalahan.
Dan jika kita memperhitungkan bahwa selama pemrosesan semua 10 permintaan, cek dari kubelet (penyelidikan lives) akan tiba, itu akan gagal dan Kubernetes akan mulai berpikir bahwa ada sesuatu yang salah dengan wadah ini, dan akan membunuhnya. Dalam hal ini, semua permintaan yang diproses saat ini akan berakhir dengan kesalahan (!) Dan pada saat restart wadah itu akan jatuh tidak seimbang, yang akan memerlukan peningkatan permintaan untuk semua backend lainnya.
Jelas
Misalkan kita memiliki 2 pod yang masing-masing memiliki 10 pekerja php-fpm dikonfigurasi. Berikut adalah grafik yang menampilkan informasi selama "downtime", yaitu ketika satu-satunya yang meminta php-fpm adalah eksportir php-fpm (kami masing-masing memiliki satu pekerja aktif):
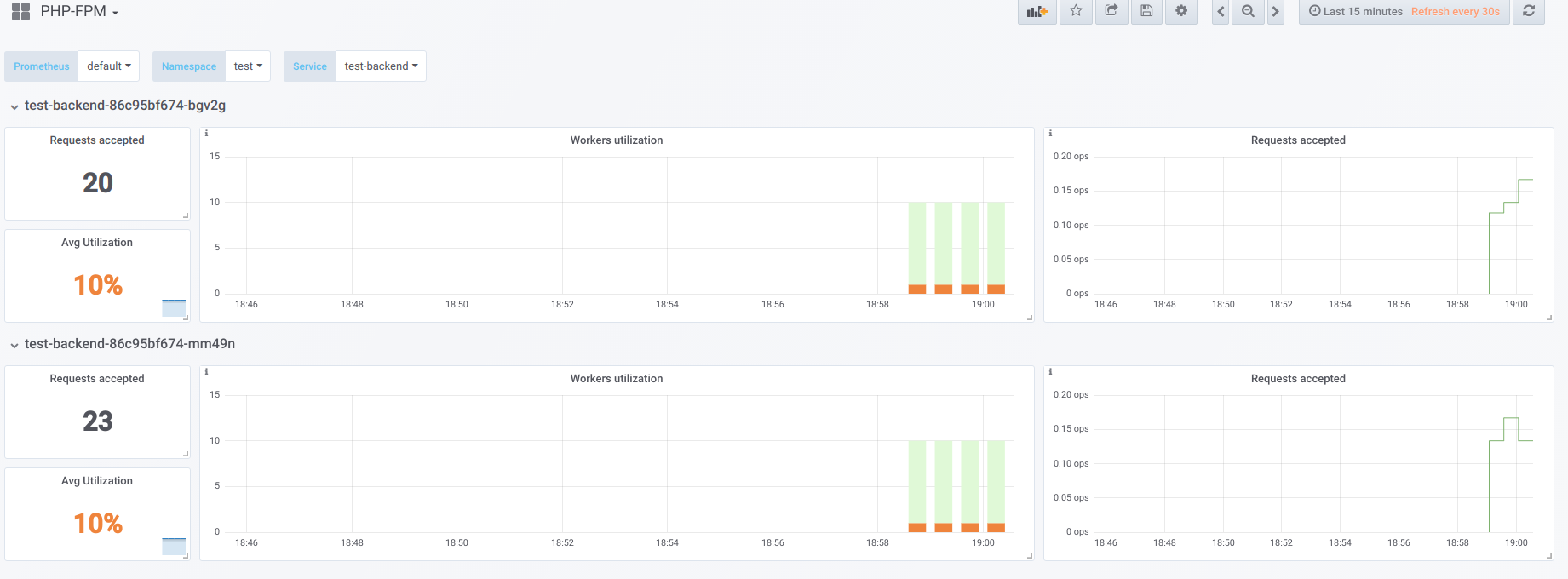
Sekarang mulai boot dengan concurrency 19:
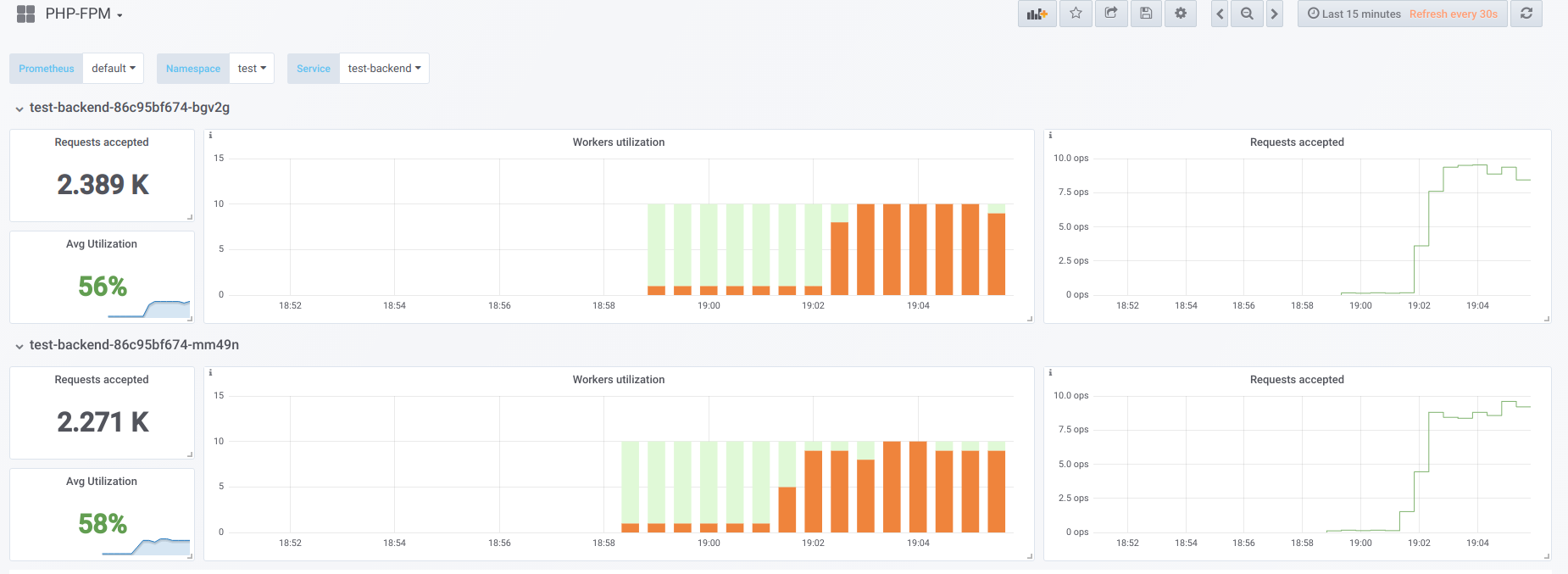
Sekarang mari kita coba untuk membuat konkurensi lebih tinggi dari yang dapat kita tangani (20) ... katakanlah 23. Kemudian semua pekerja php-fpm sibuk memproses permintaan klien:

Vorkers tidak lagi cukup untuk memproses sampel liveness, jadi kami melihat gambar ini di dashboard Kubernetes (atau
describe pod ):

Sekarang, ketika salah satu pod reboot,
efek longsoran terjadi : permintaan mulai jatuh pada pod kedua, yang juga tidak dapat memprosesnya, karena itu kami menerima sejumlah besar kesalahan dari klien. Setelah kumpulan semua wadah penuh, meningkatkan layanan menjadi bermasalah - ini hanya dimungkinkan dengan peningkatan tajam dalam jumlah polong atau pekerja.
Opsi pertama
Dalam sebuah wadah dengan PHP, Anda bisa mengonfigurasi 2 kumpulan fpm: satu untuk memproses permintaan klien, yang lain untuk memeriksa “survivability” kontainer. Kemudian pada wadah nginx Anda perlu melakukan konfigurasi serupa:
upstream backend { server 127.0.0.1:9000 max_fails=0; } upstream backend-status { server 127.0.0.1:9001 max_fails=0; }
Yang tersisa adalah mengirim sampel liveness untuk diproses ke hulu yang disebut
backend-status .
Sekarang setelah penyelidikan liveness diproses secara terpisah, kesalahan masih akan terjadi pada beberapa klien, tetapi setidaknya tidak ada masalah yang terkait dengan me-restart pod dan memutus seluruh klien. Dengan demikian, kami akan sangat mengurangi jumlah kesalahan, bahkan jika backend kami tidak dapat mengatasi beban saat ini.
Opsi ini, tentu saja, lebih baik daripada tidak sama sekali, tetapi juga buruk karena sesuatu dapat terjadi pada kumpulan utama, yang kita tidak akan tahu tentang menggunakan tes liveness.
Opsi kedua
Anda juga dapat menggunakan modul nginx yang tidak terlalu populer yang disebut
nginx-limit-upstream . Kemudian di PHP kita akan menentukan 11 pekerja, dan dalam wadah dengan nginx kita akan membuat konfigurasi yang sama:
limit_upstream_zone limit 32m; upstream backend { server 127.0.0.1:9000 max_fails=0; limit_upstream_conn limit=10 zone=limit backlog=10 timeout=5s; } upstream backend-status { server 127.0.0.1:9000 max_fails=0; }
Pada level frontend, nginx akan membatasi jumlah permintaan yang akan dikirim ke backend (10). Hal yang menarik adalah bahwa backlog khusus dibuat: jika permintaan ke-11 untuk nginx berasal dari klien, dan nginx melihat bahwa kumpulan php-fpm sedang sibuk, maka permintaan ini ditempatkan di backlog selama 5 detik. Jika, selama waktu ini, php-fpm tidak dibebaskan, maka baru Ingress yang akan bertindak, yang akan mencoba kembali permintaan ke pod lain. Ini memperhalus gambar, karena kita akan selalu memiliki 1 pekerja PHP gratis untuk memproses sampel liveness - kita dapat menghindari efek longsoran salju.
Pikiran lain
Untuk opsi yang lebih fleksibel dan indah untuk memecahkan masalah ini, ada baiknya mencari ke arah
Utusan dan analognya.
Secara umum, agar Prometheus memiliki pekerjaan yang jelas bagi para pekerja, yang pada gilirannya akan membantu menemukan masalah dengan cepat (dan memberi tahu tentang itu), saya sangat menyarankan agar
eksportir siap pakai untuk mengkonversi data dari perangkat lunak ke format Prometheus.
PS
Lainnya dari siklus tips & trik K8:
Baca juga di blog kami: