
Setiap hari, satu setengah juta orang mencari Ozon untuk berbagai produk, dan untuk masing-masing layanan harus memilih yang serupa (jika penyedot debu masih membutuhkan yang lebih kuat) atau yang terkait (jika baterai diperlukan untuk bernyanyi dinosaurus). Ketika ada terlalu banyak jenis produk, model Word2Vec membantu menyelesaikan masalah. Kami memahami cara kerjanya dan cara membuat representasi vektor untuk objek yang berubah-ubah.
Motivasi
Untuk membangun dan melatih model, kami menggunakan teknik embedding, standar untuk pembelajaran mesin, ketika setiap objek berubah menjadi vektor dengan panjang tetap, dan vektor dekat sesuai dengan objek dekat. Hampir semua model yang dikenal mensyaratkan bahwa input data memiliki panjang yang tetap, dan satu set vektor adalah cara mudah untuk membawanya ke formulir ini.
Salah satu metode penyematan pertama adalah word2vec. Kami mengadaptasi metode ini untuk tugas kami, kami menggunakan produk sebagai kata-kata, dan sesi pengguna sebagai kalimat. Jika semuanya jelas bagi Anda, jangan ragu untuk membalik-balik hasilnya.
Selanjutnya saya akan berbicara tentang arsitektur model dan cara kerjanya. Karena kita berurusan dengan barang, kita perlu belajar bagaimana membangun deskripsi mereka sehingga, di satu sisi, berisi informasi yang cukup, dan di sisi lain, dapat dimengerti untuk algoritma pembelajaran mesin.
Di situs web, setiap produk memiliki kartu. Ini terdiri dari judul, deskripsi teks, spesifikasi dan foto. Juga tersedia untuk kami, ada data tentang interaksi pengguna dengan produk: pandangan, penambahan ke keranjang atau favorit disimpan dalam log.
Ada dua cara yang berbeda secara mendasar untuk membangun deskripsi vektor suatu produk:
- Menggunakan konten - jaringan saraf konvolusional untuk mengekstraksi fitur dari foto, jaringan berulang atau sekumpulan kata untuk menganalisis deskripsi teks;
- penggunaan data pada interaksi pengguna dengan produk: produk apa dan seberapa sering mereka terlihat / ditambahkan ke keranjang bersama dengan data.
Kami akan fokus pada metode kedua.
Data untuk Model Prod2Vec
Pertama, mari kita cari tahu data apa yang kita gunakan. Kami memiliki semua klik pengguna di situs yang kami miliki, mereka dapat dibagi menjadi sesi pengguna - urutan klik dengan interval tidak lebih dari 30 menit antara klik yang berdekatan. Untuk melatih model, kami menggunakan data dari sekitar 100 juta sesi pengguna, di mana masing-masing kami hanya tertarik untuk melihat dan menambahkan produk ke keranjang.
Contoh sesi pengguna nyata:

Setiap produk dalam sesi sesuai dengan konteksnya - semua produk yang ditambahkan pengguna ke keranjang di sesi ini, serta produk yang dilihat dengan ini. Model prod2vec didasarkan pada asumsi bahwa produk serupa paling sering memiliki konteks yang sama.
Sebagai contoh:

Jadi, jika asumsi itu benar, maka, misalnya, kasus untuk model telepon yang sama akan memiliki konteks yang sama (telepon yang sama). Kami akan menguji hipotesis ini dengan membuat vektor produk.
Model Prod2Vec
Ketika kami memperkenalkan konsep produk dan konteksnya, kami menggambarkan model itu sendiri. Ini adalah jaringan saraf dengan dua lapisan yang terhubung sepenuhnya. Jumlah input dari lapisan pertama sama dengan jumlah produk yang ingin kita buat vektor. Setiap produk di pintu masuk akan dikodekan oleh vektor nol dengan satu unit - tempat produk ini dalam kamus.
Jumlah neuron pada output lapisan pertama sama dengan dimensi vektor yang ingin kita dapatkan, misalnya 64. Pada output lapisan terakhir, sekali lagi, ada sejumlah neuron yang sama dengan jumlah barang.

Kami akan melatih model untuk memprediksi konteks, mengetahui produk. Arsitektur ini disebut Skip-gram (alternatifnya adalah CBOW, di mana kami memperkirakan produk sesuai dengan konteksnya). Selama pelatihan, barang dikirim ke pintu masuk, barang diharapkan menjadi output dari konteksnya (vektor nol dengan unit di tempat yang sesuai).
Intinya, ini adalah klasifikasi multiklass, dan cross entropy loss dapat digunakan untuk melatih model. Untuk satu pasangan kata-kata dari konteksnya, ditulis sebagai berikut:
L=−pc+ log sumVi=1exp(pi)
dimana pc - prediksi jaringan untuk produk dari konteks, V - jumlah total barang pi - prediksi jaringan untuk produk i .
Setelah melatih model, kita dapat membuang lapisan kedua - tidak diperlukan untuk mendapatkan vektor. Matriks bobot lapisan pertama (ukuran jumlah barang x 64) adalah kamus vektor barang. Setiap produk sesuai dengan satu baris matriks dengan panjang 64 - ini adalah vektor yang sesuai dengan produk, yang dapat digunakan dalam algoritma lain.
Tetapi prosedur ini tidak berfungsi untuk sejumlah besar produk. Dan kita memilikinya, ingat, satu setengah juta.
Mengapa Prod2Vec Tidak Bekerja
- Fungsi kerugian mengandung banyak operasi pengambilan eksponen - ini adalah komputasi yang panjang dan tidak stabil.
- Akibatnya, gradien dipertimbangkan untuk semua bobot jaringan - dan mungkin ada puluhan juta.
Untuk mengatasi masalah ini, metode pengambilan sampel negatif cocok, dengan menggunakan yang kami ajarkan jaringan tidak hanya untuk memprediksi konteks untuk produk, tetapi juga mengajarkan untuk tidak memprediksi produk yang tidak tepat dalam konteks. Untuk melakukan ini, kita perlu membuat contoh negatif - untuk setiap produk, pilih yang tidak perlu diprediksi untuk itu. Dan di sini ketersediaan sejumlah besar barang membantu kami. Ketika memilih pasangan acak untuk suatu produk, kami memiliki probabilitas yang sangat kecil bahwa itu akan menjadi produk dari konteksnya.
Akibatnya, untuk setiap produk dalam konteks, kami secara acak menghasilkan 5-10 produk yang tidak termasuk dalam konteks. Selain itu, barang tidak diambil sampelnya dengan distribusi yang seragam, tetapi sesuai dengan frekuensi kemunculannya.
Fungsi kerugian sekarang mirip dengan yang digunakan dalam klasifikasi biner. Untuk satu pasangan kata-kata, dari konteksnya, terlihat seperti ini:
L=− log sigma(uTwOvwI)− sumwn log sigma(−uTwnvwI)
Dalam notasi ini uwO menunjukkan kolom matriks berat lapisan kedua yang sesuai dengan produk dari konteks, uwn - sama untuk produk yang dipilih secara acak, vwI - baris matriks bobot dari lapisan pertama yang sesuai dengan produk utama (ini persis vektor yang kami bangun untuk itu). Fungsi sigma(x)= frac11+exp(−x) .
Perbedaan dari versi sebelumnya adalah bahwa kita tidak perlu memperbarui semua bobot jaringan pada setiap iterasi, kita hanya perlu memperbarui yang sesuai dengan sejumlah kecil produk (produk pertama adalah yang kita prediksi, sisanya adalah produk dari konteksnya atau dipilih secara acak ) Pada saat yang sama, kami menyingkirkan sejumlah besar tangkapan eksponensial di setiap iterasi.
Teknik lain, yang pada gilirannya meningkatkan kualitas model yang dihasilkan, adalah subsampling. Dalam hal ini, kami sengaja mengambil barang yang kurang sering ditemukan untuk pelatihan guna mendapatkan hasil terbaik untuk barang langka.
Hasil
Produk Terkait
Jadi, kami belajar cara mendapatkan vektor untuk barang, sekarang kami perlu memeriksa kecukupan dan penerapan model kami.
Gambar berikut menunjukkan produk dan tetangga terdekatnya dalam ukuran kedekatan kosinus.
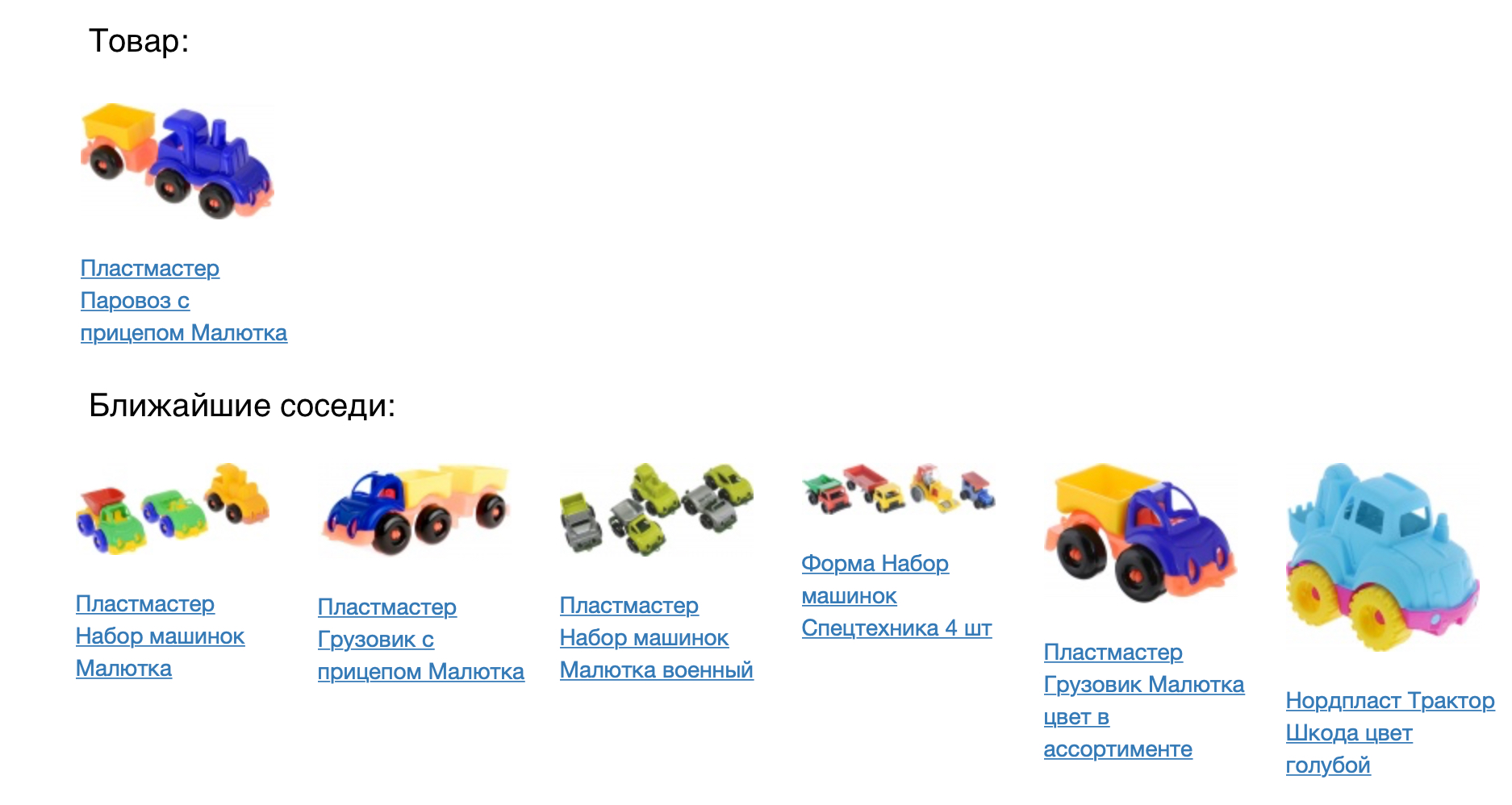
Hasilnya terlihat bagus, tetapi Anda perlu memeriksa secara numerik seberapa baik model kami. Untuk melakukan ini, kami menerapkannya pada tugas rekomendasi produk. Untuk setiap produk, kami sarankan datang dalam ruang vektor yang dibangun. Kami membandingkan model prod2vec dengan yang lebih sederhana, berdasarkan statistik pandangan bersama dan menambahkan item ke keranjang. Untuk setiap produk dalam sesi, daftar 7 rekomendasi diambil. Kombinasi dari semua produk yang direkomendasikan dalam sesi dibandingkan dengan apa yang sebenarnya ditambahkan seseorang ke keranjang. Menggunakan prod2vec, di lebih dari 40% sesi kami merekomendasikan setidaknya satu produk, yang kemudian ditambahkan ke keranjang. Sebagai perbandingan, algoritma yang lebih sederhana menunjukkan kualitas 34%.
Deskripsi vektor yang dihasilkan memungkinkan kita tidak hanya untuk mencari yang terdekat (yang dapat dilakukan dengan model yang lebih sederhana, walaupun dengan kualitas yang lebih buruk). Kita dapat mempertimbangkan efek samping menarik apa yang dapat ditunjukkan dengan menggunakan model kami.
Aritmatika vektor
Untuk menggambarkan bahwa vektor membawa arti sebenarnya dari barang, kita dapat mencoba menggunakan aritmatika vektor untuk mereka. Seperti dalam contoh buku teks di word2vec (raja - pria + wanita = ratu), kita dapat misalnya bertanya pada diri sendiri produk mana yang kira-kira berjarak sama dengan printer dengan kantong debu dari penyedot debu. Akal sehat menyatakan bahwa itu harus semacam bahan habis pakai, yaitu kartrid. Model kami dapat menangkap pola-pola tersebut:

Visualisasi ruang produk
Untuk lebih memahami hasilnya, kita dapat memvisualisasikan ruang vektor barang di pesawat, mengurangi dimensi menjadi dua (dalam contoh ini, kami menggunakan t-SNE).

Terlihat jelas bahwa produk-produk terkait membentuk kluster. Misalnya, cluster dengan tekstil untuk kamar tidur, pakaian pria dan wanita, sepatu terlihat jelas. Sekali lagi, kami mencatat bahwa model ini dibangun hanya atas dasar sejarah interaksi pengguna dengan barang, kami tidak menggunakan kesamaan gambar atau deskripsi teks saat pelatihan.
Dari ilustrasi ruang Anda juga dapat melihat bagaimana, menggunakan model, Anda dapat memilih aksesori untuk barang. Untuk melakukan ini, Anda perlu mengambil barang dari cluster terdekat, misalnya, merekomendasikan barang olahraga untuk T-shirt, dan topi untuk sweater hangat.
Paket
Kami sekarang memperkenalkan model prod2vec dalam produksi untuk menghitung rekomendasi produk. Selain itu, vektor yang diperoleh dapat digunakan sebagai fitur untuk algoritme pembelajaran mesin lainnya yang digunakan oleh tim kami (memperkirakan permintaan barang, menentukan peringkat dalam pencarian dan katalog, rekomendasi pribadi).
Di masa mendatang, kami berencana untuk mengimplementasikan embeddings yang diterima di situs secara real-time. Untuk semua barang yang dilihat, yang berikutnya akan berada di sesi, yang akan langsung tercermin dalam pengiriman yang dipersonalisasi. Kami juga berencana untuk mengintegrasikan analisis gambar dan analisis kesamaan sesuai dengan deskripsi vektor ke dalam model kami, yang akan sangat meningkatkan kualitas vektor yang dihasilkan.
Jika Anda tahu cara terbaik untuk melakukan ini (atau membuat ulang) - kunjungi untuk mengunjungi (dan bahkan pekerjaan yang lebih baik).
Referensi:
- Mikolov, Tomas, dkk. "Representasi kata dan frasa yang didistribusikan serta komposisionalitasnya." Kemajuan dalam sistem pemrosesan informasi saraf. 2013
- Grbovic, Mihajlo, dkk. "E-commerce di kotak masuk Anda: Rekomendasi produk pada skala." Prosiding Konferensi Internasional ACM SIGKDD ke-21 tentang Penemuan Pengetahuan dan Penambangan Data. ACM, 2015.
- Grbovic, Mihajlo, dan Haibin Cheng. "Personalisasi Real-time menggunakan Peringkat Pernikahan untuk Pencarian di Airbnb." Prosiding Konferensi Internasional ACM SIGKDD ke-24 tentang Penemuan Pengetahuan & Penambangan Data. ACM, 2018.