Di Rostelecom, kami menggunakan Hadoop untuk menyimpan dan memproses data yang diunduh dari berbagai sumber menggunakan aplikasi java. Kami sekarang telah pindah ke versi baru hadoop dengan Kerberos Authentication. Saat pindah, saya menemui sejumlah masalah, termasuk penggunaan API BENANG. Pekerjaan Hadoop dengan Otentikasi Kerberos layak mendapatkan artikel terpisah, tetapi dalam artikel ini kita akan berbicara tentang debugging Hadoop MapReduce.

Saat menjalankan tugas di gugus, memulai debugger menjadi rumit oleh fakta bahwa kita tidak tahu simpul mana yang akan memproses bagian input data ini atau itu, dan kami tidak dapat mengkonfigurasi debugger kami sebelumnya.
Anda dapat menggunakan
System.out.println("message") teruji waktu. Tetapi bagaimana cara menganalisis output
System.out.println("message") tersebar di node-node ini?
Kami dapat menampilkan pesan ke aliran kesalahan standar. Semua yang ditulis dalam stdout atau stderr,
dikirim ke file log yang sesuai, yang dapat ditemukan pada halaman web informasi tugas yang diperluas atau dalam file log.
Kami juga dapat menyertakan alat debugging dalam kode kami, memperbarui pesan status tugas, dan menggunakan penghitung khusus untuk membantu kami memahami skala bencana.
Aplikasi Hadoop MapReduce dapat di-debug dalam ketiga mode di mana Hadoop dapat bekerja:
- mandiri
- mode pseudo-distributed
- sepenuhnya terdistribusi
Secara lebih rinci kita akan fokus pada dua yang pertama.
Mode pseudo-didistribusikan
Mode pseudo-distributed digunakan untuk mensimulasikan sebuah cluster nyata. Dan itu dapat digunakan untuk pengujian di lingkungan sedekat mungkin dengan produktif. Dalam mode ini, semua daemon Hadoop akan bekerja pada satu simpul!
Jika Anda memiliki server dev atau kotak pasir lainnya (misalnya, Mesin Virtual dengan lingkungan pengembangan yang disesuaikan, seperti Hortonworks Sanbox dengan HDP), maka Anda dapat men-debug program kontrol menggunakan alat debugging jarak jauh.
Untuk memulai debugging, Anda perlu mengatur nilai variabel lingkungan:
YARN_OPTS . Berikut ini adalah contohnya. Untuk kenyamanan, Anda dapat membuat file startWordCount.sh dan menambahkan parameter yang diperlukan untuk meluncurkan aplikasi.
Sekarang, jalankan skrip
`./startWordCount.sh` , kita akan melihat pesan
Listening for transport dt_socket at address: 6000
Masih mengkonfigurasi IDE untuk debugging jarak jauh. Saya menggunakan IDEA intellij. Buka menu Run -> Edit Configurations ... Tambahkan konfigurasi
Remote baru.
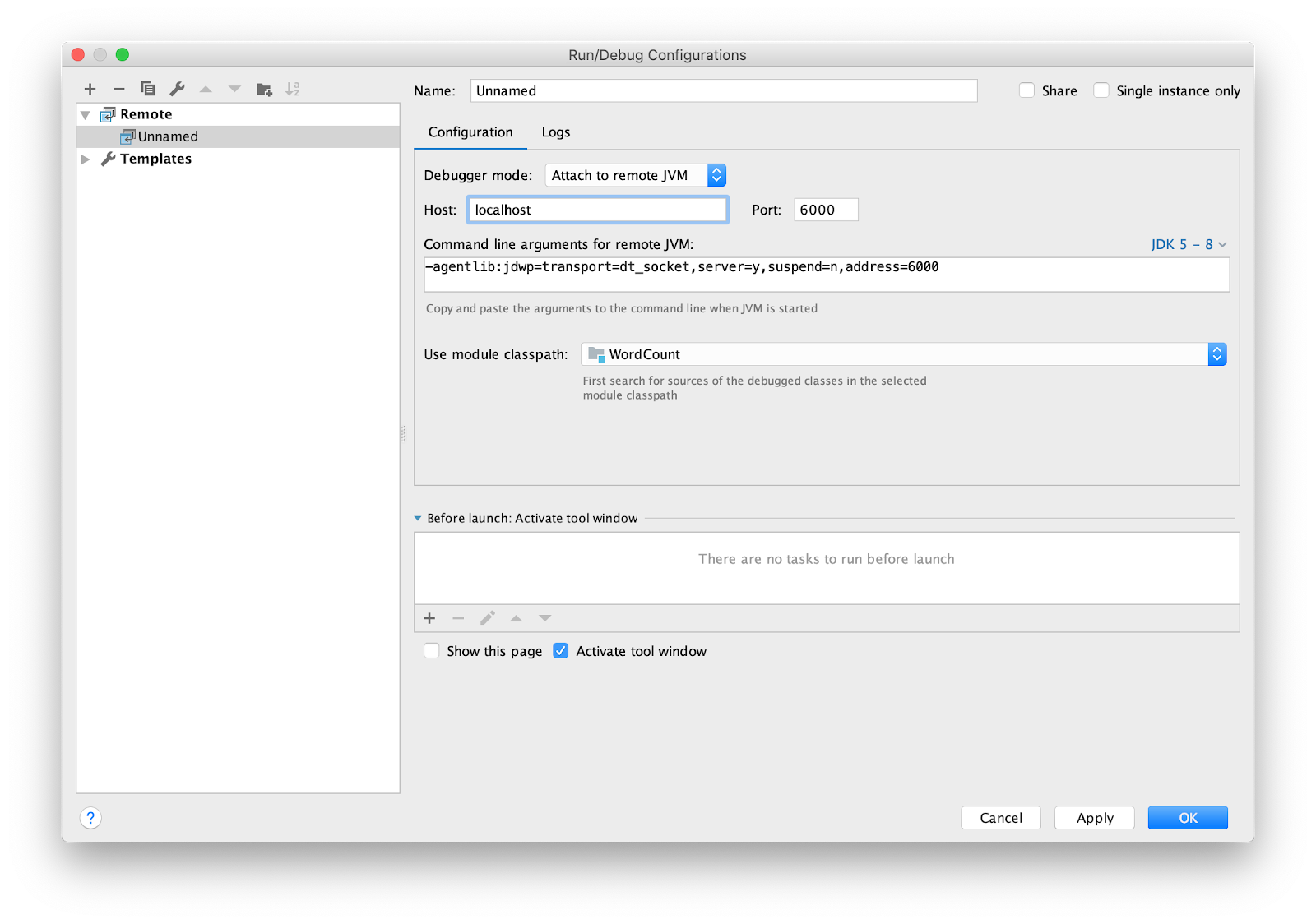
Atur breakpoint ke main dan jalankan.
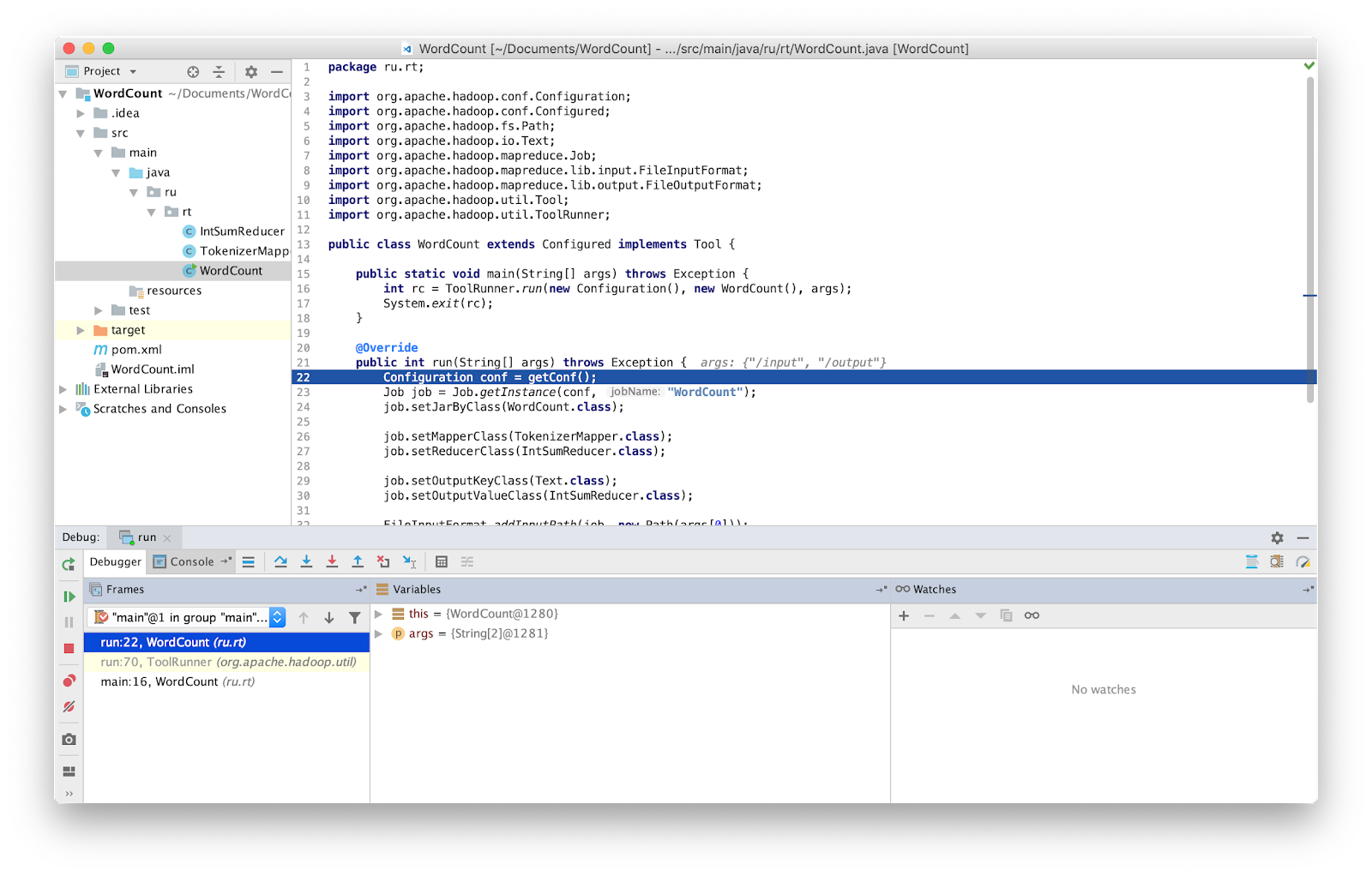
Itu dia, sekarang kita bisa men-debug program seperti biasa.
PERHATIAN Anda harus memastikan bahwa Anda bekerja dengan versi terbaru dari kode sumber. Jika tidak, maka Anda mungkin memiliki perbedaan pada baris di mana debugger berhenti.
Dalam versi Hadoop sebelumnya, kelas khusus disediakan yang memungkinkan Anda untuk memulai kembali tugas yang gagal - isolationRunner. Data yang menyebabkan kegagalan disimpan ke disk di alamat yang ditentukan dalam variabel lingkungan Hadoop mapred.local.dir. Sayangnya, dalam versi terbaru Hadoop, kelas ini tidak lagi disediakan.
Standalone (awal lokal)
Standalone adalah mode standar di mana Hadoop bekerja. Sangat cocok untuk debugging di mana HDFS tidak digunakan. Dengan debugging seperti itu, Anda dapat menggunakan input dan output melalui sistem file lokal. Mode mandiri biasanya merupakan mode Hadoop tercepat karena menggunakan sistem file lokal untuk semua data input dan output.
Seperti yang disebutkan sebelumnya, Anda dapat menyuntikkan alat debugging ke dalam kode Anda, seperti penghitung. Penghitung ditentukan oleh Java
enum . Nama enumerasi menentukan nama grup, dan bidang enumerasi menentukan nama-nama penghitung. Penghitung dapat berguna untuk mengevaluasi masalah,
dan dapat digunakan sebagai tambahan untuk debug output.
Deklarasi dan penggunaan konter:
package ru.rt.example; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private Text word = new Text(); enum Word { TOTAL_WORD_COUNT, } @Override public void map(LongWritable key, Text value, Context context) { String[] stringArr = value.toString().split("\\s+"); for (String str : stringArr) { word.set(str); context.getCounter(Word.TOTAL_WORD_COUNT).increment(1); } } } }
Untuk menambah penghitung, gunakan metode
increment(1) .
... context.getCounter(Word.TOTAL_WORD_COUNT).increment(1); ...
Setelah MapReduce selesai dengan sukses, tugas menampilkan penghitung di akhir.
Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 ru.rt.example.Map$Word TOTAL_WORD_COUNT=655
Data yang salah dapat berupa output ke stderr atau stdout, atau untuk menulis output ke hdfs menggunakan kelas
MultipleOutputs untuk analisis lebih lanjut. Data yang diterima dapat dikirim ke input aplikasi dalam mode mandiri atau saat menulis unit test.
Hadoop memiliki perpustakaan MRUnit, yang digunakan bersama dengan kerangka kerja pengujian (mis. JUnit). Saat menulis unit test, kami memverifikasi bahwa fungsi menghasilkan hasil yang diharapkan pada output. Kami menggunakan kelas MapDriver dari paket MRUnit, di properti yang kami atur kelas yang diuji. Untuk melakukan ini, gunakan metode
withMapper() , nilai input
withInputValue() dan hasil yang diharapkan
withOutput() atau
withMultiOutput() jika beberapa output digunakan.
Ini tes kami.
package ru.rt.example; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mrunit.mapreduce.MapDriver; import org.apache.hadoop.mrunit.types.Pair; import org.junit.Before; import org.junit.Test; import java.io.IOException; public class TestWordCount { private MapDriver<Object, Text, Text, IntWritable> mapDriver; @Before public void setUp() { Map mapper = new Map(); mapDriver.setMapper(mapper) } @Test public void mapperTest() throws IOException { mapDriver.withInput(new LongWritable(0), new Text("msg1")); mapDriver.withOutput(new Pair<Text, IntWritable>(new Text("msg1"), new IntWritable(1))); mapDriver.runTest(); } }
Mode terdistribusi penuh
Seperti namanya, ini adalah mode di mana semua kekuatan Hadoop digunakan. Program MapReduce yang diluncurkan dapat berjalan di 1000 server. Selalu sulit untuk men-debug program MapReduce, karena Anda memiliki Mappers yang berjalan pada mesin yang berbeda dengan data input yang berbeda.
Kesimpulan
Ternyata, pengujian MapReduce tidak semudah kelihatannya pada pandangan pertama.
Untuk menghemat waktu mencari kesalahan di MapReduce, saya menggunakan semua metode yang tercantum di atas dan saya menyarankan semua orang untuk menerapkannya juga. Ini sangat berguna dalam kasus instalasi besar, seperti yang bekerja di Rostelecom.