Struktur internal kamus dengan Python tidak terbatas pada bucket dan hashing pribadi saja. Ini adalah dunia yang luar biasa dari kunci bersama, caching hash, DKIX_DUMMY dan perbandingan cepat, yang dapat dilakukan bahkan lebih cepat (dengan biaya bug dengan perkiraan probabilitas 2 ^ -64).
Jika Anda tidak tahu jumlah elemen dalam kamus yang baru saja Anda buat, berapa banyak memori yang dihabiskan untuk setiap elemen, mengapa sekarang (CPython 3.6 dan seterusnya) kamus diimplementasikan dalam dua array dan bagaimana kaitannya dengan menjaga urutan penyisipan, atau Anda hanya tidak menonton presentasi oleh Raymond Hettinger “Modern Python Kamus Sebuah pertemuan selusin ide-ide besar. " Selamat datang
Namun, orang-orang yang terbiasa dengan kuliah juga dapat menemukan beberapa rincian dan informasi baru, dan untuk pendatang baru yang tidak terbiasa dengan ember dan hashing tertutup, artikel ini juga akan menarik.
Kamus di CPython ada di mana-mana, kelas, variabel global, parameter kwarg didasarkan pada mereka,
penerjemah menciptakan ribuan kamus , bahkan jika Anda sendiri tidak menambahkan tanda kurung kurawal ke skrip Anda. Tetapi untuk mengatasi banyak masalah yang diterapkan, kamus juga digunakan, tidak mengherankan bahwa penerapannya terus meningkat dan semakin tumbuh menjadi berbagai trik.
Implementasi dasar kamus (via Hashmap)
Jika Anda terbiasa dengan pekerjaan Hashmap standar dan hashing pribadi, Anda dapat melanjutkan ke bab berikutnya.
Gagasan yang mendasari kamus sederhana: jika kita memiliki array di mana objek dengan ukuran yang sama disimpan, maka kita dengan mudah mendapatkan akses ke objek yang diinginkan, mengetahui indeks.
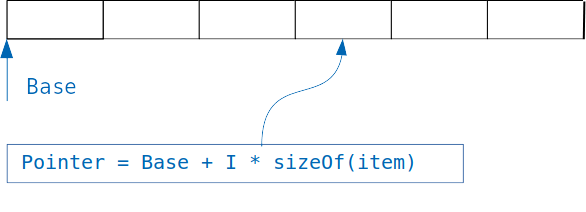
Kami cukup menambahkan indeks dikalikan dengan ukuran objek ke offset array, dan kami mendapatkan alamat objek yang diinginkan.
Tetapi bagaimana jika kita ingin mengatur pencarian bukan dengan indeks integer, tetapi dengan variabel jenis lain, misalnya, untuk menemukan pengguna di alamat email mereka?
Dalam hal array sederhana, kita harus melihat mail dari semua pengguna dalam array dan membandingkannya dengan pencarian, pendekatan ini disebut pencarian linear dan, jelas, itu jauh lebih lambat daripada mengakses objek dengan indeks.
Pencarian linear dapat dipercepat secara signifikan jika kami membatasi ukuran area di mana Anda ingin mencari. Ini biasanya dicapai dengan mengambil sisa
hash . Bidang yang dicari adalah kuncinya.
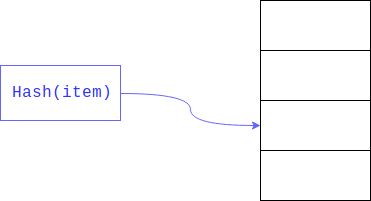
Akibatnya, pencarian linier dilakukan bukan pada seluruh array besar, tetapi sepanjang bagiannya.
Tetapi bagaimana jika sudah ada elemen di sana? Ini bisa sangat baik terjadi, karena tidak ada yang menjamin bahwa residu dari membagi hash akan menjadi unik (seperti hash itu sendiri). Dalam hal ini, objek akan ditempatkan pada indeks berikutnya, jika sibuk, itu akan bergeser oleh indeks lain dan seterusnya sampai menemukan yang bebas. Saat mengambil item, semua kunci dengan hash yang sama akan dilihat.
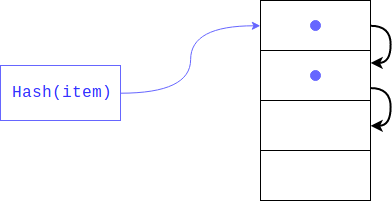
Jenis hashing ini disebut pribadi. Jika ada beberapa sel bebas dalam kamus, maka pencarian seperti itu mengancam untuk berubah menjadi linear, jadi kita akan kehilangan semua kemenangan yang diciptakan kamus, untuk menghindari ini penerjemah membuat array tetap diisi 1/2 - 2/3. Jika tidak ada cukup sel bebas, array baru dibuat dua kali lebih besar dari yang sebelumnya dan elemen dari yang lama ditransfer ke yang baru sekaligus.
Apa yang harus dilakukan jika item telah dihapus? Dalam hal ini, sel kosong terbentuk dalam array dan algoritma pencarian dengan kunci tidak dapat membedakan, sel ini kosong karena elemen dengan hash seperti itu tidak ada dalam kamus, atau karena itu dihapus. Untuk menghindari kehilangan data selama penghapusan, sel ditandai dengan bendera khusus (DKIX_DUMMY). Jika bendera ini ditemukan selama pencarian elemen, pencarian berlanjut, sel dianggap sibuk, jika dimasukkan, sel akan ditimpa.
Fitur Implementasi dalam Python
Setiap elemen kamus harus berisi tautan ke objek dan kunci target. Kunci harus disimpan untuk pemrosesan tabrakan, objek - untuk alasan yang jelas. Karena kunci dan objek dapat dari jenis dan ukuran apa pun, kami tidak dapat menyimpannya secara langsung dalam struktur, mereka terletak di memori dinamis, dan tautan ke mereka disimpan dalam struktur item daftar. Artinya, ukuran satu elemen harus sama dengan ukuran minimum dua pointer (16 byte pada sistem 64-bit). Namun, juru bahasa juga menyimpan hash, ini dilakukan agar tidak menghitung ulang dengan setiap peningkatan ukuran kamus. Alih-alih menghitung hash dari masing-masing kunci dengan cara baru dan mengambil sisa pembagian dengan jumlah ember, penerjemah hanya membaca nilai yang sudah disimpan. Tetapi, bagaimana jika objek kunci diubah? Dalam hal ini, hash harus dihitung ulang dan nilai yang disimpan akan salah? Situasi seperti itu tidak mungkin, karena tipe yang bisa berubah tidak bisa menjadi kunci kamus.
Struktur elemen kamus didefinisikan sebagai berikut:
typedef struct { Py_hash_t me_hash;
Ukuran minimum kamus dinyatakan oleh konstanta PyDict_MINSIZE, yaitu 8. Pengembang memutuskan bahwa ini adalah ukuran optimal untuk menghindari pemborosan memori yang tidak perlu untuk menyimpan nilai kosong dan waktu untuk ekspansi dinamis array. Jadi, ketika membuat kamus (hingga versi 3.6), Anda memerlukan minimal 8 elemen dalam kamus * 24 byte dalam struktur = 192 byte (ini tidak memperhitungkan bidang yang tersisa: biaya variabel kamus itu sendiri, penghitung jumlah elemen, dll.)
Kamus juga digunakan untuk mengimplementasikan bidang kelas khusus. Python memungkinkan Anda untuk secara dinamis mengubah jumlah atribut, dinamika ini tidak memerlukan biaya tambahan, karena menambahkan / menghapus atribut pada dasarnya setara dengan operasi yang sesuai pada kamus. Namun, sebagian kecil program menggunakan fungsi ini, sebagian besar terbatas pada bidang yang dideklarasikan dalam __init__. Tetapi setiap objek harus menyimpan kamusnya sendiri, dengan kunci dan hashnya, meskipun fakta bahwa mereka bertepatan dengan objek lain. Perbaikan logis di sini adalah penyimpanan kunci bersama hanya di satu tempat, yang persis seperti yang diterapkan dalam
PEP 412 - Kamus Berbagi Kunci . Kemampuan untuk mengubah kamus secara dinamis tidak hilang: jika urutan atau jumlah kunci diubah, kamus diubah dari kunci yang membagi menjadi yang biasa.
Untuk menghindari tabrakan, "pemuatan" maksimum kamus adalah 2/3 dari ukuran array saat ini.
#define USABLE_FRACTION(n) (((n) << 1)/3)
Dengan demikian, ekstensi pertama akan terjadi ketika elemen ke-6 ditambahkan.
Array ternyata cukup kosong, selama operasi program, dari setengah hingga sepertiga sel tetap kosong, yang mengarah pada peningkatan konsumsi memori. Untuk menghindari batasan ini dan, jika mungkin, hanya menyimpan data yang diperlukan,
tingkat abstraksi array baru ditambahkan.
Alih-alih menyimpan array jarang, misalnya:
d = {'timmy': 'red', 'barry': 'green', 'guido': 'blue'}
Dimulai dengan versi 3.6, kamus disusun sebagai berikut:
indices = [None, 1, None, None, None, 0, None, 2] entries = [[-9092791511155847987, 'timmy', 'red'], [-8522787127447073495, 'barry', 'green'], [-6480567542315338377, 'guido', 'blue']]
Yaitu hanya catatan yang benar-benar diperlukan yang disimpan, mereka dikeluarkan dari tabel hash dalam array yang terpisah, dan hanya indeks dari catatan yang sesuai disimpan di tabel hash. Jika awalnya array mengambil 192 byte, sekarang hanya 80 (3 * 24-byte untuk setiap record + 8 byte untuk indeks). Kompresi mencapai 58%. [2]
Ukuran elemen dalam indeks juga berubah secara dinamis, awalnya itu sama dengan satu byte, yaitu seluruh array dapat ditempatkan dalam satu register, ketika indeks mulai masuk ke dalam 8 bit, kemudian elemen tersebut meluas menjadi 16 bit, kemudian elemen itu meluas menjadi 16, kemudian menjadi 32 bit. Ada konstanta khusus DKIX_EMPTY dan DKIX_DUMMY untuk item yang kosong dan dihapus, masing-masing, indeks ekspansi ke 16 byte terjadi ketika ada lebih dari 127 item dalam kamus.
Objek baru ditambahkan ke entri, yaitu, ketika memperluas kamus, tidak perlu memindahkannya, Anda hanya perlu menambah ukuran indeks dan memenuhi sampai melimpahi indeks.
Ketika mengulangi kamus, array indeks tidak diperlukan, elemen dikembalikan secara berurutan dari entri, karena elemen ditambahkan setiap kali ke akhir entri, kamus secara otomatis menyimpan urutan kemunculan elemen. Jadi, selain mengurangi memori yang diperlukan untuk menyimpan kamus, kami menerima ekspansi dinamis yang lebih cepat dan pelestarian urutan tombol. Mengurangi memori memang bagus, tetapi pada saat yang sama dapat meningkatkan kinerja, karena memungkinkan lebih banyak catatan untuk masuk ke cache prosesor.
Pengembang CPython sangat menyukai implementasi ini sehingga kamus sekarang diminta untuk mempertahankan urutan penyisipan berdasarkan spesifikasi. Jika sebelumnya urutan kamus ditentukan, mis. itu secara ketat didefinisikan oleh hash dan tidak berubah dari awal hingga awal, kemudian sedikit keacakan ditambahkan sehingga kunci akan berbeda setiap kali, sekarang kunci kamus diperlukan untuk mempertahankan pesanan. Berapa banyak ini diperlukan, dan apa yang harus dilakukan jika implementasi kamus yang lebih efektif muncul tetapi tidak mempertahankan urutan penyisipan, tidak jelas.
Namun, ada permintaan untuk menerapkan mekanisme untuk menjaga deklarasi atribut di
kelas dan di
kwarg , dan implementasi ini memungkinkan Anda untuk menutup masalah ini tanpa mekanisme khusus.
Begini tampilannya dalam
kode CPython :
struct _dictkeysobject { Py_ssize_t dk_refcnt; Py_ssize_t dk_size; dict_lookup_func dk_lookup; Py_ssize_t dk_usable; Py_ssize_t dk_nentries; char dk_indices[]; };
Tetapi iterasi lebih rumit daripada yang Anda bayangkan, ada mekanisme verifikasi tambahan bahwa kamus tidak berubah selama iterasi, salah satunya adalah versi 64-bit
dari kamus yang menyimpan setiap kamus.
Akhirnya, kami mempertimbangkan mekanisme untuk menyelesaikan tabrakan. Masalahnya, dalam python, nilai hash mudah diprediksi:
>>>[hash(i) for i in range(4)] [0, 1, 2, 3]
Dan karena ketika membuat kamus dari hash ini, sisa pembagian diambil, lalu, pada kenyataannya, mereka menentukan ke ember mana catatan akan menuju, hanya beberapa bit terakhir dari kunci (jika bilangan bulat). Anda dapat membayangkan situasi di mana kami memiliki banyak objek "ingin" masuk ke keranjang tetangga, dalam hal ini Anda harus melihat banyak objek yang tidak pada tempatnya saat mencari. Untuk mengurangi jumlah tabrakan dan meningkatkan jumlah bit yang menentukan ke ember mana catatan akan pergi, mekanisme berikut ini diterapkan:
perturb adalah variabel integer yang diinisialisasi oleh hash. Perlu dicatat bahwa dalam kasus sejumlah besar tabrakan, diatur ulang ke nol dan indeks berikut dihitung dengan rumus:
j = (5 * j + 1) % n
Saat mengekstraksi elemen dari kamus, pencarian yang sama dilakukan: indeks slot di mana elemen harus ditempatkan dihitung, jika slot kosong, pengecualian "nilai tidak ditemukan" dilemparkan. Jika ada nilai dalam slot ini, Anda perlu memeriksa bahwa kuncinya cocok dengan yang Anda cari, ini mungkin tidak mungkin jika terjadi tabrakan. Namun, kuncinya dapat berupa hampir semua objek, termasuk yang operasi perbandingannya membutuhkan waktu cukup lama. Untuk menghindari operasi perbandingan yang panjang, beberapa trik digunakan dengan Python:
pertama, pointer dibandingkan, jika pointer kunci dari objek yang diinginkan sama dengan pointer dari objek yang sedang dicari, yaitu, mereka menunjuk ke area memori yang sama, maka perbandingan segera mengembalikan true. Tapi itu belum semuanya. Seperti yang Anda ketahui, objek yang sama harus memiliki hash yang sama, yang berarti bahwa objek dengan hash yang berbeda tidak sama. Setelah memeriksa pointer, hash diperiksa, jika tidak sama, false akan dikembalikan. Dan hanya jika hash sama, perbandingan yang jujur akan dipanggil.
Apa kemungkinan hasil seperti itu? Tentang 2 ^ -64, tentu saja, karena mudah diprediksi nilai hash, Anda dapat dengan mudah mengambil contoh seperti itu, tetapi dalam kenyataannya, verifikasi ini tidak sering sampai seberapa banyak? Raymond Hettinger mengumpulkan interpreter dengan mengubah operasi perbandingan terakhir dengan true return sederhana. Yaitu penerjemah menganggap objek sama jika hashnya sama. Kemudian ia menetapkan tes otomatis dari banyak proyek populer pada juru bahasa ini, yang berakhir dengan sukses. Mungkin aneh untuk menganggap objek dengan hash yang sama sama, tidak untuk tambahan memeriksa isinya, dan bergantung sepenuhnya pada hash saja, tetapi Anda melakukan ini secara teratur ketika menggunakan protokol git atau torrent. Mereka menganggap file (blok file) sama jika hash mereka sama, yang mungkin menyebabkan kesalahan, tetapi pembuatnya (dan kita semua) berharap perlu dicatat, tanpa alasan, bahwa kemungkinan tabrakan sangat kecil.
Sekarang Anda akhirnya harus memahami struktur kamus, yang terlihat seperti ini:
typedef struct { PyObject_HEAD Py_ssize_t ma_used; uint64_t ma_version_tag; PyDictKeysObject *ma_keys; PyObject **ma_values; } PyDictObject;
Perubahan di masa depan
Pada bab sebelumnya, kami mempertimbangkan apa yang telah diterapkan dan dapat digunakan oleh semua orang dalam pekerjaan mereka, tetapi perbaikannya, tentu saja, tidak terbatas pada: rencana untuk versi 3.8 termasuk
dukungan untuk kamus terbalik . Memang, tidak ada yang mencegah, bukan iterasi dari awal array elemen dan peningkatan indeks, mulai dari akhir dan penurunan indeks.
Bahan tambahan
Untuk perendaman yang lebih dalam dalam topik ini, disarankan untuk membiasakan diri dengan materi-materi berikut:
- Rekam laporan di awal artikel
- Proposal untuk implementasi kamus baru
- Kode Sumber Kamus dalam CPython