Kami ingin berbagi kisah yang terjadi di salah satu proyek kami untuk Tahun Baru. Inti dari proyek ini adalah mengotomatiskan pekerjaan dokter di lembaga medis. Selama kunjungan pasien, dokter menulis informasi ke perekam, kemudian audio ditranskripsikan. Setelah proses transkripsi - mis. mengubah rekaman audio menjadi teks - dokumen medis dibentuk sesuai dengan standar yang relevan dan dikirim kembali ke klinik, dari mana rekaman audio berasal, di mana dokter pengirim menerimanya, memeriksa dan menyetujuinya. Setelah melewati pemeriksaan wajib, dokumen dikirim ke pasien akhir.
Semua lembaga medis yang menggunakan produk secara kondisional dapat dibagi menjadi dua kelompok besar:
- Hosting di pusat data klien kami, yang bertanggung jawab penuh atas fungsionalitas aplikasi, baik untuk perangkat lunak maupun perangkat keras. Misalnya, jika ruang disk habis, atau tidak ada kinerja server yang cukup pada CPU;
- Diinstal sendiri: mereka menempatkan semua peralatan langsung di rumah dan bertanggung jawab atas kinerjanya sendiri. Klien kami memberi mereka aplikasi dan dukungannya.
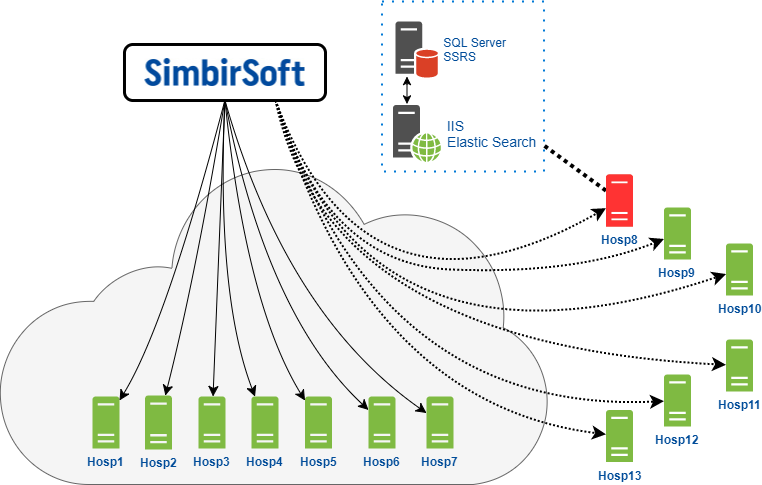
Ini adalah cara tim kami berinteraksi dengan server akhir yang dihosting langsung di cloud klien kami.

Kami memiliki akses ke server ini untuk melakukan semua pekerjaan dan pemeliharaan terjadwal yang diperlukan.
Grup kedua - klien yang di-host-sendiri - untuk mereka, cloud klien bertindak sebagai gateway yang melaluinya kami terhubung ke server ini. Dalam hal ini, kami memiliki hak terbatas, seringkali kami tidak dapat melakukan operasi apa pun karena pengaturan keamanan. Kami terhubung ke server melalui RDP, Remote Desktop Protocol pada OS Windows. Secara alami, ini semua bekerja melalui VPN.
Harus diingat bahwa setiap server yang diwakili dalam diagram sebenarnya adalah kombinasi dari server aplikasi dan server database. Pada server database, masing-masing, MS SQL Server DBMS dan layanan pelaporan SSR diinstal. Selain itu, versi MSSQL Server berbeda di semua klinik: 2008, 2012, 2014. Selain versi itu sendiri, Paket Layanan dan tambalan yang berbeda diinstal di mana-mana. Secara umum, kebun binatang lengkap.
Di server aplikasi kami telah menginstal server web IIS dan ElasticSearch. ElasticSearch adalah mesin pencari yang juga mengimplementasikan pencarian teks lengkap.
Esensi utama dalam hal produk kami adalah "pekerjaan". Pekerjaan adalah entitas abstrak yang menghubungkan semua informasi yang terkait dengan penerimaan pasien tertentu. Informasi ini meliputi:
- data tentang dokter;
- data pasien;
- data tentang kunjungan;
- file audio (pidato dokter);
- dokumen (beberapa versi);
- riwayat pemrosesan pekerjaan;
- informasi cabang, dll.
Diagram ini menunjukkan skema database yang disederhanakan dari mana Anda dapat melihat hubungan antara tabel utama. Ini hanya bagian dasar, pada kenyataannya, database memiliki lebih dari 200 tabel.

Sedikit tentang klinik tempat kejadian itu terjadi:
- 1500-2000 pekerjaan per hari;
- 1000+ pengguna aktif (dokter + sekretaris);
- Diinangi sendiri.
DB:
- Ukuran: 800+ Gb (750K + karya, 2M + dokumen);
- DBMS: MS SQL Server 2008 R2;
- Model Pemulihan: Sederhana.
Di sini saya ingin membuat sedikit penjelasan. Ada 3 model pemulihan di SQL Server: sederhana, log-massal, dan penuh. Saya tidak akan berbicara tentang yang ketiga sekarang, saya akan menjelaskan tentang yang pertama dan yang kedua. Perbedaan utama adalah bahwa dalam model sederhana kami tidak menyimpan riwayat transaksi dalam log - segera setelah transaksi dilakukan, catatan dari log transaksi akan dihapus. Saat menggunakan mode pemulihan penuh, seluruh riwayat perubahan data disimpan dalam log transaksi. Apa yang ini berikan pada kita? Jika terjadi situasi yang tidak terduga, ketika kita perlu memutar kembali basis data dari cadangan, kita dapat kembali tidak hanya ke cadangan tertentu, tetapi dapat kembali ke titik waktu tertentu, hingga ke transaksi tertentu, mis., Kami telah menyimpan dalam cadangan, tidak hanya keadaan tertentu dari database pada saat cadangan, tetapi juga ada seluruh sejarah perubahan data.
Saya pikir itu tidak layak menjelaskan bahwa mode sederhana hanya digunakan dalam pengembangan, pada server pengujian dan penggunaannya dalam produksi tidak dapat diterima. Tidak mungkin sama sekali.
Tetapi klinik, tampaknya, memiliki pemikiran sendiri tentang hal ini;)
Mulai
Beberapa hari kemudian Tahun Baru, semua orang bersiap untuk liburan, membeli hadiah, menghias pohon Natal, menghabiskan pesta perusahaan dan menunggu akhir pekan yang panjang.
22 Desember (Jumat) 1 hari
14:31 Klien mengatakan bahwa ia tidak menerima laporan harian berikutnya. Laporan tiba melalui pos dua kali sehari sesuai jadwal, diperlukan untuk mengontrol pengiriman data ke sistem integrasi eksternal, yang tidak terlalu kritis.
Mungkin ada beberapa alasan:
- Masalah dengan SMTP, surat-surat tidak disampaikan (mereka mengubah kata sandi, misalnya, dan mereka tidak memberi tahu siapa pun);
- Masalah di sisi server dari laporan;
- Sesuatu terjadi pada basis data.
16:03 Klinik terkadang mengubah kata sandi menjadi SMTP, tanpa memperingatkan siapa pun tentang hal itu, oleh karena itu, setelah menyelesaikan tugas saat ini, kami dengan tenang memeriksa laporan secara manual dengan meluncurkannya melalui antarmuka web - kami mendapatkan kesalahan yang menunjukkan masalah dalam database.
Contoh kesalahan yang kami terima saat memulai laporan.
SQL Server detected a logical consistency-based I/O error: incorrect checksum (expected: 0x9876641f; actual: 0xa3255fbf). It occurred during a read of page (1:876) in database ID 7 at offset 0x000000006d8000 in file 'D:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\ServerLive.mdf'.
Ini menunjukkan bahwa database memiliki halaman yang rusak. Kami memiliki sedikit rasa cemas.
20:53 Untuk menilai tingkat kerusakan, kami menjalankan pemeriksaan basis data menggunakan perintah
DBCC CHECKDB khusus. Tergantung pada ukuran kerusakannya, perintah tes dapat memakan waktu cukup lama, jadi kami menjalankan perintah di malam hari. Di sini kita beruntung bahwa ini terjadi pada hari Jumat sore, yaitu, kita memiliki setidaknya semua hari libur untuk menyelesaikan masalah ini.
Pada saat itu, situasinya adalah sebagai berikut:
23 Desember (Sabtu) hari ke-2
10:02 Di pagi hari, kami menemukan bahwa memeriksa basis data dengan CHECKDB adalah disket - ini disebabkan oleh kurangnya ruang diska bebas, karena selama proses verifikasi, basis data tempdb sementara aktif digunakan, dan pada titik tertentu ruang disk kosong habis.
Oleh karena itu, kami memutuskan daripada memeriksa seluruh database untuk segera meluncurkan pemindaian tabel. Untuk melakukan ini, gunakan perintah
DBCC CHECKTABLE .
10:46 Kami memutuskan untuk memulai dengan tabel JobHistory, yang mungkin rusak, karena itu yang digunakan untuk menghasilkan laporan. Tabel ini, sesuai namanya, mempertahankan sejarah semua karya, mis., Transisi kerja antar tahap.
Jalankan
DBCC CHECKTABLE ('dbo.JobHistory') .
Memeriksa tabel ini mengungkapkan tabel yang rusak dalam database, yang pada prinsipnya diharapkan.
12:00 Saat ini, jika basis data menggunakan model pemulihan penuh, kami dapat memulihkan halaman yang rusak dari cadangan, dan semuanya akan berakhir, tetapi basis data kami berada dalam mode sederhana. Oleh karena itu, satu-satunya pilihan untuk memperbaiki kerusakan tetap menjalankan perintah yang sama dengan parameter khusus
REPAIR_ALLOW_DATA_LOSS . Ini dapat menyebabkan hilangnya data.
Kita mulai. Pemeriksaan lagi diakhiri dengan kesalahan - kami mendapatkan kesalahan bahwa pemulihan tabel ini tidak mungkin sampai tabel terkait dipulihkan. Tabel riwayat mengacu pada tabel kerja (Pekerjaan) oleh kunci asing, oleh karena itu, kami menyimpulkan bahwa ada juga kerusakan di tabel kerja utama (Pekerjaan).
13:30 Langkah selanjutnya adalah memeriksa tabel Pekerjaan, pada saat yang sama - kami berharap bahwa kerusakan ada dalam indeks, dan bukan dalam data. Dalam hal ini, cukup bagi kita untuk membangun kembali indeks untuk pemulihan data.
17:33 Setelah beberapa saat, kami menemukan bahwa server kami tidak tersedia melalui RDP. Mungkin dimatikan, cek tidak selesai, pekerjaan ditangguhkan. Kami memberi tahu klinik bahwa server tidak tersedia, tolong angkat.
Kecemasan ringan mengambil bentuk yang sangat spesifik.
24 Desember (Minggu) hari ke-3
14:31 Menjelang makan malam, server dinaikkan, kami menjalankan kembali pemeriksaan tabel Jobs.
DBCC CHECKTABLE ('dbo.Jobs')16:05 Verifikasi tidak selesai, server tidak tersedia. Lagi
Setelah beberapa waktu, server tidak tersedia lagi, sebelum kami berhasil menyelesaikan memeriksa tabel. Pada titik ini, layanan TI klinik melakukan serangkaian pemeriksaan server. Kami menunggu selesainya pekerjaan.
Karena liburan, komunikasi antara kami dan klien lambat - kami mengharapkan jawaban atas pertanyaan selama beberapa jam.
25 Desember (Senin - Natal) hari ke-4
16:00 Hari berikutnya server dinaikkan, klien memiliki Natal, dan kami kembali mulai memeriksa tabel, tetapi kali ini kami mengecualikan indeks dari pemindaian, dan kami hanya meninggalkan pemeriksaan data. Dan setelah beberapa waktu server tidak tersedia lagi.
Apa yang sedang terjadi
Pada saat ini, pikiran mulai merayap masuk, bahwa ini bukan hanya kebetulan, dan ada kecurigaan bahwa itu bisa menjadi kerusakan pada tingkat besi (hard disk jatuh). Kami berasumsi bahwa ada sektor buruk pada disk dan ketika pemindaian mencoba membaca data dari sektor ini, sistem macet. Kami memberi tahu klien kami tentang asumsi kami.
Klien menjalankan pemeriksaan disk pada mesin host.
17:19 Klinik IT service melaporkan bahwa file mesin virtual rusak - ini buruk! (
Kami belum bisa bekerja, dan kami sedang menunggu sinyal ketika mereka memperbaiki masalah dan kami dapat melanjutkan pekerjaan kami.
26 Desember (Selasa) Hari 5
14:05 Layanan klinik TI meluncurkan proses pemulihan disk lainnya. Kami diberitahu bahwa kami dapat menjalankan CHECKTABLE secara paralel untuk memeriksa tabel. Kami memulai pengujian lagi - mesin virtual mogok lagi, kami memberi tahu klien bahwa file mesin virtual masih rusak.
Hari-hari ini, semua komunikasi dengan pelanggan sangat lambat dengan jeda waktu yang sangat besar karena liburan.
27 Desember (Rabu) Hari 6
14:00 Kami memulai pemeriksaan disk menggunakan Windows -
checkdisk di dalam mesin virtual - tidak ada masalah yang terdeteksi.
Basis data berada dalam mode Sederhana, sehingga kemungkinan memperbaiki basis data saat ini dengan alat DBMS cenderung nol, karena kami tidak dapat memulihkan halaman yang rusak secara individual.
Kami mulai mempertimbangkan opsi untuk memutar kembali dan memulihkan basis data dari cadangan.
Kami memeriksa cadangan basis data dan menemukan bahwa cadangan tersebut tidak dibuat menggunakan sarana DBMS, cadangan terakhir adalah pada tahun 2014, mis. Tidak ada cadangan dari database. Mengapa mereka tidak melakukannya adalah masalah terpisah, merupakan tanggung jawab klinik untuk memastikan pengoperasian dan keamanan basis data.
Ada kemungkinan besar bahwa itu tidak akan berfungsi untuk mengembalikan database saat ini, kami mulai mempertimbangkan opsi lain untuk rollback.
Mari kita bahas lebih rinci tentang situasi dengan cadangan di klinik.
Situasi dengan cadangan:
- Tidak ada cadangan basis data (!!!)
- Tidak ada snapshot dari mesin virtual (!?)
- Tetapi ada cadangan disk (full + inc)
Basis data ada di disk D, masing-masing, mereka melakukan backup penuh mingguan dan backup inkremental harian.
- setiap Jumat pukul 20:00 cadangan penuh
- cadangan tambahan setiap hari
- ada cadangan lengkap dari tanggal 15 dan 22
- ada cadangan harian hingga tanggal 21
Yaitu pada prinsipnya, kita dapat kembali ke keadaan sebelum masalah terjadi.
Kami sedang menunggu pembaruan dari klinik untuk memulai rollback database dari cadangan.
Pada saat yang sama, klinik mengirimkan permintaan kepada pemasok besi (HP) bertanda “mendesak”.
28 Desember (Kamis) Hari 7
13:13 Klinik Layanan TI mulai menyiapkan mesin virtual baru, seperti Tidak mungkin untuk memperbaiki kerusakan pada file mesin virtual lama.
19:09 Mesin virtual baru tersedia dengan SQL Server diinstal.
Langkah selanjutnya adalah mengembalikan database dari cadangan disk. Untuk memulainya, kami memutuskan untuk kembali ke hari ke-22, jika masalahnya masih ada, kemudian kembali ke tanggal 21, 20, dan seterusnya, hingga kami tiba di kondisi kerja.
Itu adalah hari ke-28 di halaman, kami berada di pesta perusahaan, dan di sini mereka memberi tahu kami bahwa klinik memiliki masalah dengan memulihkan cadangan, karena CADANGAN KOSONG!
Inilah beritanya!
Saat mengembalikan cadangan drive D dari tanggal 21, ternyata kosong, seperti yang lainnya. Backup shredder langsung diperoleh - mereka tampaknya ada di sana, tetapi pada saat yang sama mereka tidak. Tidak sepenuhnya jelas bagaimana ini terjadi sama sekali, tetapi, sejauh yang dapat kami pahami, intinya adalah ruang disk tidak mencukupi untuk menyimpan cadangan disk. Mereka mengalokasikan 500 Gb cadangan untuk penyimpanan, tetapi pada saat kejadian, database sudah berbobot 800 Gb, oleh karena itu, pada prinsipnya, cadangan tidak dapat berhasil. Yaitu backup secara teratur dilakukan sesuai dengan jadwal, tetapi karena kurangnya ruang, mereka berakhir dengan kesalahan dan, karenanya, kosong, dan layanan TI klinik tidak memiliki ide untuk memeriksa bahwa semuanya baik-baik saja dengan mereka. Jangan lakukan itu.
29 Desember (Jumat) Hari 8
13:11 Diskusi tindakan selanjutnya. Opsi yang memungkinkan:
- Mencoba untuk menyalin file basis data (.ldf + .two file) - peluang keberhasilan sangat rendah;
- Mencoba membuat cadangan basis data sekali lagi sangat kecil peluangnya;
- Konfigurasikan replikasi - dapat berfungsi.
Drive 1 Tb dialokasikan pada server baru, yang jelas tidak cukup jika kita mencoba membuat cadangan dan memulihkannya, karena dalam kasus terburuk, tanpa kompresi, cadangan akan mengambil ruang sebanyak database asli, mis. 800 Gb.
Silakan tambahkan tempat di server baru dan lanjutkan menyalin file database.
Database dibuat di server baru dan skema database dipulihkan - ini akan memungkinkan setidaknya memproses pekerjaan baru. Klinik setidaknya akan dapat menerima pasien baru menggunakan sistem seperti itu.
14:36 Karenanya, kami melanjutkan ke opsi nomor satu, meskipun kami tidak berharap banyak kesuksesan.
Hentikan SQL Server, mulai menyalin file data (mdf) dan log (ldf).
16:13 Setelah setengah dari file log, itu berhasil disalin (48 Gb), dan 50 GB file data sudah disalin (795 dari 846 GB tersisa). Pada kecepatan ini, akan dibutuhkan sekitar 12 jam untuk menyelesaikan salinan.
16:30 Server database lama dimatikan saat menyalin file, yang sangat diharapkan.
17:09 Oleh karena itu, kita beralih ke opsi berikutnya - mengatur replikasi, sementara kita dapat menentukan data apa yang akan direplikasi, yaitu, pertama-tama kita dapat mengecualikan tabel yang sengaja rusak dan terlebih dahulu menyalin data yang tidak rusak, dan kemudian mentransfer tabel yang bermasalah di beberapa bagian. Tetapi opsi ini, sayangnya, tidak berfungsi dengan baik, karena kami bahkan tidak dapat membuat publikasi dengan tabel tertentu karena kerusakan basis data.
Kami juga mempertimbangkan opsi transfer data.
20:01 Sebagai hasilnya, kami mulai hanya mentransfer data dari yang lama ke server baru dengan mengimpor dan mengekspor dalam urutan prioritas.
21:35 Pertama, data paling kritis, lalu arsip dan kurang kritis (~ 300 GB). Dalam gelombang ekspor pertama, kurang dari 300 GB data tetap ada. Tabel Dokumen (300GB) juga dikecualikan. Kami memulai proses penyalinan di malam hari.
30 Desember (Sabtu) Hari 9
15:00 Kami terus mentransfer data. Tabel Pekerjaan tidak tersedia sama sekali. Sebagian besar tabel disalin saat ini.
Tapi tanpa
Jobs, itu semua tidak berguna, karena itu adalah tautan utama antara semua data dan memberi mereka makna dan nilai dari sudut pandang bisnis. Tanpa itu, kita hanya memiliki dataset yang berbeda yang tidak bisa kita gunakan.
Juga, pada titik ini, pemulihan skema basis data telah selesai.
Konsekuensi dari kejadian tersebut:Pada titik ini, kami memiliki banyak kehilangan data langsung.
Yaitu secara formal, kami memiliki beberapa data dalam basis data, tetapi, pada kenyataannya, tidak ada cara untuk menggunakan atau menghubungkannya, sehingga kami dapat berbicara tentang hilangnya data secara lengkap.
Kehilangan data pada lebih dari 750.000 penerimaan pasien.
Ini sungguh menyedihkan!
- Ini merupakan pukulan besar bagi reputasi klien kami, yang dapat berubah menjadi masalah besar bagi mereka dalam bisnis ketika membuat kontrak baru dan menemukan pelanggan baru.
- Kehilangan begitu banyak data untuk klinik dapat menyebabkan masalah serius dan denda, karena Ini adalah data rahasia yang mengandung kerahasiaan medis dan, dalam arti harfiah, tergantung pada kehidupan orang.
Kami mulai berpikir apa yang bisa kami lakukan dalam situasi ini. Mereka mulai memilah-milah sistem dengan tulang untuk menemukan petunjuk.
15:16 Menganalisis semua aspek sistem, kami memahami bahwa kami dapat mencoba mengekstraksi data yang hilang dari indeks ElasticSearch. Masalahnya adalah bahwa karena konfigurasi yang salah dari indeks ElasticSearch, itu tidak hanya menyimpan bidang di mana pencarian teks lengkap dilakukan, tetapi secara umum semuanya, yaitu, sebenarnya ada salinan lengkap dari data dan kita secara teoritis dapat mengekstrak data dari sana tentang karya dan mengembalikannya ke database kami. Diharapkan bahwa data akan tetap dapat dipulihkan.
Bug di mana Anda bisa meletakkan monumen!
 18:00
18:00 Utilitas ditulis dengan cepat untuk mengekstraksi data, dan setelah beberapa jam kami memastikan bahwa pendekatannya berhasil dan data dapat dipulihkan.
20:00 Pemulihan pekerjaan dari ElasticSearch dengan bantuan utilitas tertulis telah dimulai. Pendekatan berhasil, kita dapat mengembalikan data pada pekerjaan. Secara paralel, kami mulai mengekstraksi versi terbaru dokumen untuk setiap pekerjaan.
31 Desember (Minggu - Tahun Baru) Hari 10
14:09 Pada malam hari, 188 811 karya dipulihkan.
20:13 Melihat kesuksesan kami, klinik memutuskan untuk menunda transfer server ke layanan HP untuk memberi kami waktu untuk mengekstrak data maksimum dari server lama.
Dengan berita seperti itu, kami merayakan Tahun Baru))
01 Januari (Senin) 11 hari
11:23 Bersiap untuk memulai sistem setelah kejadian:
- IIS yang dikonfigurasi ulang pada server Aplikasi;
- mengkonfigurasi ulang semua layanan yang diperlukan untuk bekerja dengan server database baru;
- pemicu, prosedur tersimpan, fungsi dipulihkan.
14:28 Kemudian mereka mulai menyalin tabel dokumen, yang dilewati karena ukurannya yang besar selama transfer awal.
- Server DB lama dimatikan lagi. Jelas, tabel Dokumen juga rusak, dengan itu semua informasi pasien disimpan. Untungnya, itu tidak sepenuhnya rusak, kami dapat membuat permintaan untuk itu, dan ketika permintaan kepada kami mengembalikan catatan yang rusak, pada saat itu server crash dan dimatikan. Kami dapat mengekstrak beberapa data.
Oleh karena itu, kami memberi sinyal kepada klien, mereka meningkatkan server, dan secara paralel kami terus menyiapkan database baru untuk peluncuran sistem.
18:01 Pemulihan semua kendala integritas setelah transfer bagian utama data.
22:02 Pemulihan pembatasan selesai. Kami hanya mentransfer data mentah ke maksimum. Kehadiran kendala integritas akan sangat menyulitkan tugas kami.
02 Januari (Selasa) Hari 12
05:52 Server DB lama dimatikan lagi saat menyalin dokumen. Dia segera diangkat sehingga kita dapat terus bekerja.
09:00 Sangat mungkin untuk memulihkan kumpulan sekitar 200.000 dokumen (sekitar 20%)
Kami mulai menggunakan metode pemulihan yang berbeda: mengurutkan berdasarkan kolom yang berbeda untuk mendapatkan data dari akhir atau awal tabel, hingga kami menemukan beberapa bagian tabel yang rusak.
13:42 Mulai menyalin karya arsip di meja - untungnya, tidak rusak.
17:08 Memulihkan semua karya kearsipan (491.380 lembar).
Sistem siap diluncurkan: pengguna dapat membuat dan memproses pekerjaan baru.
Sayangnya, karena kerusakan sebagian pada tabel dokumen, Anda tidak bisa hanya mentransfer semua data dari itu, seperti halnya dengan tabel lainnya, karena meja rusak sebagian. Karenanya, saat mencoba mengambil semua data, permintaan macet saat mencoba membaca halaman yang rusak. Oleh karena itu, kami mengekstrak data secara langsung menggunakan berbagai jenis dan ukuran sampel:
- Menyortir berdasarkan bidang yang berbeda (ID, DateTime);
- Sortir naik, turun;
- Bekerja dengan kelompok garis kecil (1000, 100);
- Mengambil pekerjaan berdasarkan ID.
03 Januari (Rabu) Hari 13
08:58 Melanjutkan proses pengembalian dokumen. Dokumen dipulihkan hanya untuk pekerjaan aktif dan tidak lengkap. Pada titik ini, 1000 bekerja (aktif) tanpa dokumen.
11:38 Memigrasi semua Pekerjaan SQL
13:17 5 berfungsi tanpa dokumen, 231 tidak berfungsi, tetapi ada file audio, Anda perlu melakukan sinkronisasi ulang.
04 Januari (Kamis) Hari 14
Pemulihan manual dan verifikasi pekerjaan yang tersisa telah dimulai.
Sistem bekerja, memonitor dan memperbaiki kesalahan secara online.
05 Januari (Jumat) Hari 15
Laporkan migrasi ke SSR yang direncanakan.
Transfer ke server baru tidak dimungkinkan, karena klinik menginstal versi SQL Server yang lebih lama dan itu tidak akan berfungsi untuk mentransfer database dari server lama.
Opsi:
- Tingkatkan SQL Server dari 2008 ke 2008 R2;
- Konfigurasikan semuanya dari awal.
Diputuskan untuk menunggu pembaruan SQL Server.
09:21 Latar belakang pemulihan dokumen untuk pekerjaan yang diselesaikan telah dimulai - prosesnya panjang dan akan memakan waktu beberapa hari.
13:28 Perubahan prioritas restorasi dokumen oleh departemen.
18:18 Klinik memberi akses ke SMTP, pengaturan surat
Hasil:
- Hampir semua data dipulihkan (hanya 5 pekerjaan yang hilang);
- Rekomendasi tentang pemeliharaan basis data dikeluarkan untuk mencegah situasi seperti itu;
- Cadangan basis data dikonfigurasikan menggunakan SQL Server;
- Pemantauan tambahan cadangan di pihak kami, peringatan jika terjadi kegagalan.