
17 miliar acara, 60 juta sesi pengguna, dan sejumlah besar tanggal virtual terjadi di Badoo setiap hari. Setiap acara disimpan dengan rapi dalam database relasional untuk analisis selanjutnya dalam SQL dan seterusnya.
Basis data transaksional terdistribusi modern dengan puluhan terabyte data - keajaiban teknik yang nyata. Tetapi SQL, sebagai perwujudan aljabar relasional dalam sebagian besar implementasi standar, belum memungkinkan kami untuk merumuskan pertanyaan dalam hal tupel yang dipesan.
Dalam artikel terakhir dalam seri pada mesin virtual , saya akan berbicara tentang pendekatan alternatif untuk menemukan sesi yang menarik - mesin ekspresi reguler ( Pig Match ), yang didefinisikan untuk urutan kejadian.
Mesin virtual, bytecode, dan kompiler sudah termasuk gratis!
Bagian Satu, Pengantar
Bagian Dua, Mengoptimalkan
Bagian Tiga, diterapkan (saat ini)
Tentang acara dan sesi
Misalkan kita sudah memiliki gudang data yang memungkinkan Anda untuk dengan cepat dan berurutan melihat acara dari setiap sesi pengguna.
Kami ingin menemukan sesi dengan permintaan seperti "hitung semua sesi di mana ada acara yang ditentukan selanjutnya", "temukan bagian dari sesi yang dijelaskan oleh pola tertentu", "kembalikan bagian sesi yang terjadi setelah pola yang diberikan" atau "hitung berapa banyak sesi yang mencapai bagian tertentu templat. " Ini dapat berguna untuk berbagai jenis analisis: mencari sesi yang mencurigakan, analisis saluran, dll.
Entri yang diinginkan bagaimanapun harus dijelaskan. Dalam bentuknya yang paling sederhana, tugas ini mirip dengan menemukan substring dalam teks; kami ingin memiliki alat yang lebih kuat - ekspresi reguler. Implementasi modern dari mesin ekspresi reguler paling sering menggunakan (coba tebak!) Mesin virtual.
Pembuatan mesin virtual kecil untuk sesi pencocokan dengan ekspresi reguler akan dibahas di bawah ini. Tapi pertama-tama, kami akan mengklarifikasi definisi.
Suatu peristiwa terdiri dari jenis peristiwa, waktu, konteks, dan satu set atribut yang spesifik untuk setiap jenis.
Jenis dan konteks setiap peristiwa adalah bilangan bulat dari daftar yang telah ditentukan. Jika semuanya jelas dengan jenis acara, maka konteksnya, misalnya, jumlah layar tempat peristiwa yang diberikan terjadi.
Atribut peristiwa adalah bilangan bulat arbitrer yang artinya ditentukan oleh jenis peristiwa. Suatu peristiwa mungkin tidak memiliki atribut, atau mungkin ada beberapa.
Sesi adalah urutan peristiwa yang diurutkan berdasarkan waktu.
Tapi mari kita turun ke bisnis. Dengungan itu, seperti kata mereka, mereda, dan aku naik ke atas panggung.
Bandingkan di selembar kertas
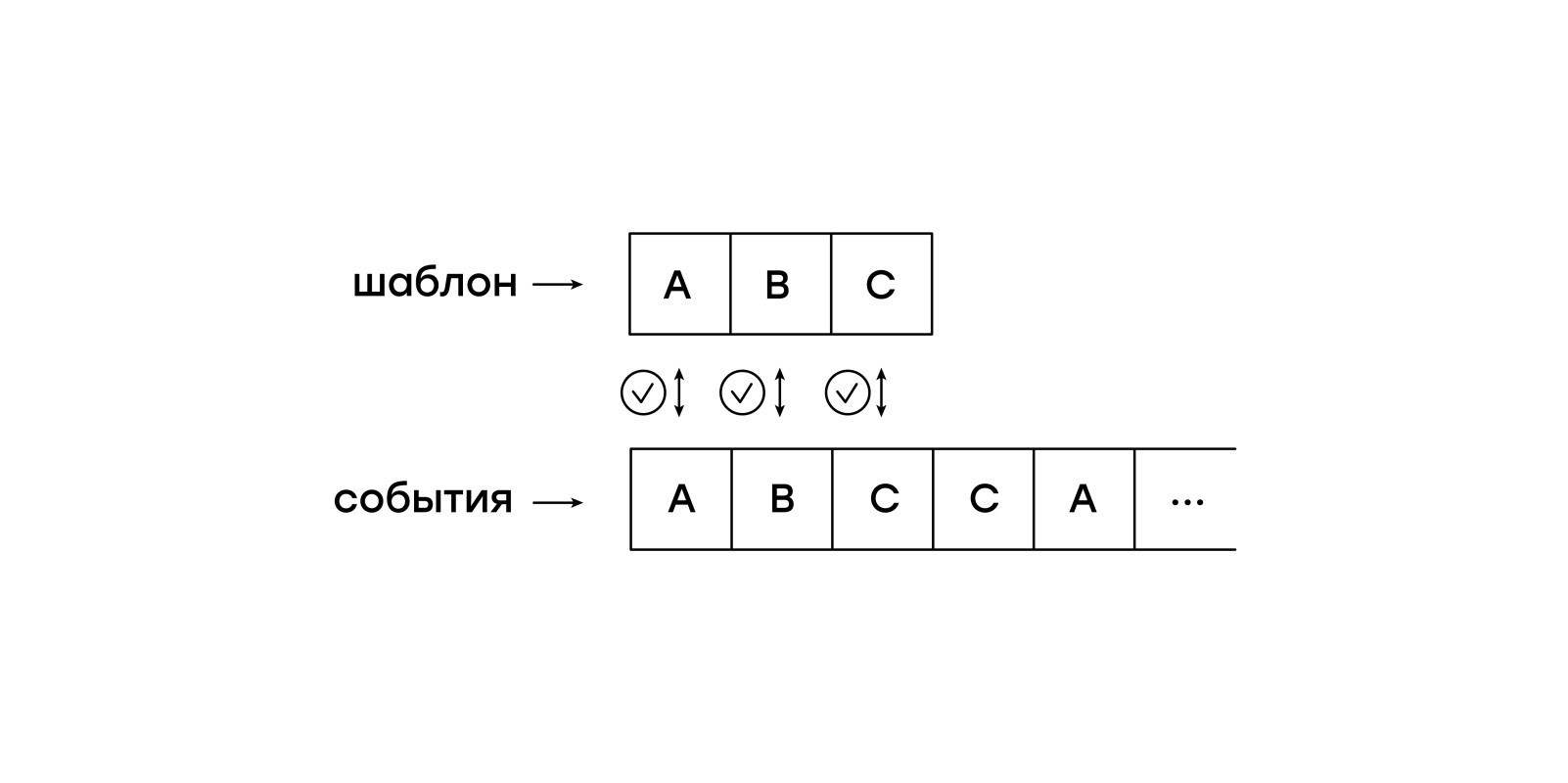
Fitur dari mesin virtual ini adalah kepasifan sehubungan dengan peristiwa input. Kami tidak ingin menyimpan seluruh sesi dalam memori dan memungkinkan mesin virtual untuk beralih secara independen dari satu acara ke acara lainnya. Sebagai gantinya, kami akan memberi makan acara dari sesi ke mesin virtual satu per satu.
Mari mendefinisikan fungsi antarmuka:
matcher *matcher_create(uint8_t *bytecode); match_result matcher_accept(matcher *m, uint32_t event); void matcher_destroy(matcher *matcher);
Jika semuanya jelas dengan fungsi matcher_create dan matcher_destroy, maka matcher_accept layak dikomentari. Fungsi matcher_accept menerima mesin virtual dan peristiwa berikutnya (32 bit, di mana 16 bit untuk jenis acara dan 16 bit untuk konteks), dan mengembalikan kode yang menjelaskan apa yang harus dilakukan oleh kode pengguna selanjutnya:
typedef enum match_result {
Opcode mesin virtual:
typedef enum matcher_opcode {
Loop utama mesin virtual:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP() \ (*m->ip++) #define NEXT_ARG() \ ((void)(m->ip += 2), (m->ip[-2] << 8) + m->ip[-1]) for (;;) { uint8_t instruction = NEXT_OP(); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(); if (event_name(next_event) != name) return MATCH_FAIL; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(); if (event_screen(next_event) != screen) return MATCH_FAIL; break; } case OP_NEXT:{ return MATCH_NEXT; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } #undef NEXT_OP #undef NEXT_ARG }
Dalam versi sederhana ini, mesin virtual kami secara berurutan cocok dengan pola yang dijelaskan oleh bytecode dengan peristiwa yang masuk. Dengan demikian, ini bukan perbandingan singkat dari awalan dua baris: templat yang diinginkan dan jalur input.
Awalan adalah awalan, tetapi kami ingin menemukan pola yang diinginkan tidak hanya di awal, tetapi juga di tempat sewenang-wenang dalam sesi. Solusi naif adalah memulai kembali pencocokan dari setiap acara sesi. Tapi ini menyiratkan tampilan ganda dari masing-masing peristiwa dan makan bayi algoritmik.
Contoh dari artikel pertama dalam seri, pada dasarnya, mensimulasikan memulai kembali pertandingan menggunakan rollback (pengulangan bahasa Inggris). Kode dalam contoh terlihat, tentu saja, lebih ramping daripada yang diberikan di sini, tetapi masalahnya belum hilang: masing-masing acara harus diperiksa berkali-kali.
Anda tidak bisa hidup seperti itu.
Aku, aku lagi dan aku lagi

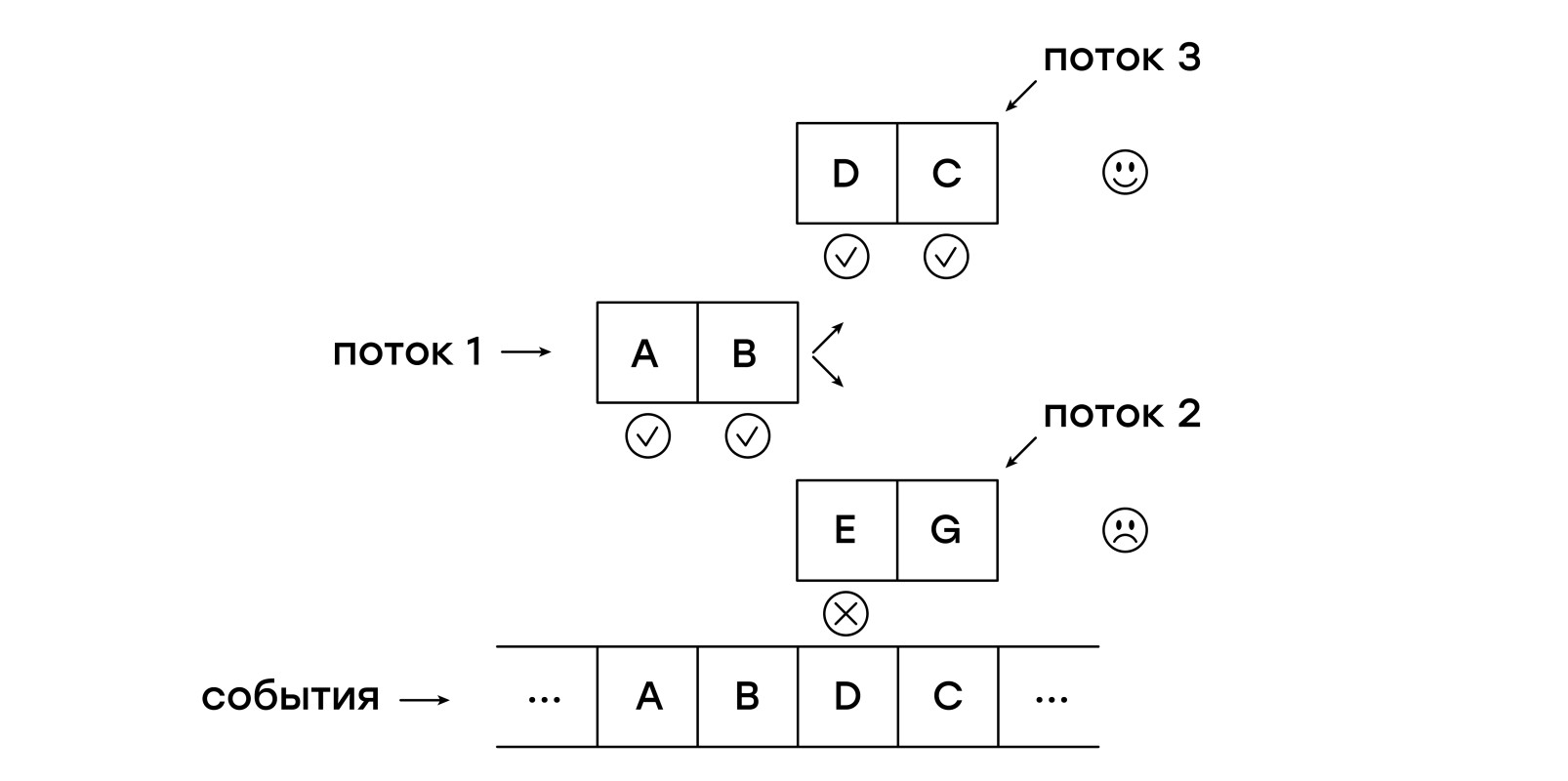
Sekali lagi marilah kita menguraikan masalah: kita harus mencocokkan templat dengan peristiwa yang masuk, mulai dari masing-masing peristiwa yang memulai perbandingan baru. Jadi mengapa kita tidak melakukan itu saja? Biarkan mesin virtual berjalan pada acara yang masuk dalam beberapa utas!
Untuk melakukan ini, kita perlu mendapatkan entitas baru - aliran. Setiap utas menyimpan satu penunjuk - ke instruksi saat ini:
typedef struct matcher_thread { uint8_t *ip; } matcher_thread;
Tentu, sekarang di mesin virtual itu sendiri kita tidak akan menyimpan pointer eksplisit. Itu akan diganti oleh dua daftar utas (lebih banyak tentangnya di bawah):
typedef struct matcher { uint8_t *bytecode; matcher_thread current_threads[MAX_THREAD_NUM]; uint8_t current_thread_num; matcher_thread next_threads[MAX_THREAD_NUM]; uint8_t next_thread_num; } matcher;
Dan inilah loop utama yang diperbarui:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP(thread) \ (*(thread).ip++) #define NEXT_ARG(thread) \ ((void)((thread).ip += 2), ((thread).ip[-2] << 8) + (thread).ip[-1]) /* - */ add_current_thread(m, initial_thread(m)); // for (size_t thread_i = 0; thread_i < m->current_thread_num; thread_i++ ) { matcher_thread current_thread = m->current_threads[thread_i]; bool thread_done = false; while (!thread_done) { uint8_t instruction = NEXT_OP(current_thread); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(current_thread); // , , // next_threads, if (event_name(next_event) != name) thread_done = true; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(current_thread); if (event_screen(next_event) != screen) thread_done = true; break; } case OP_NEXT:{ // , .. // next_threads add_next_thread(m, current_thread); thread_done = true; break; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } } /* , */ swap_current_and_next(m); return MATCH_NEXT; #undef NEXT_OP #undef NEXT_ARG }
Pada setiap acara yang diterima, pertama-tama kita menambahkan utas baru ke daftar current_threads, memeriksa templat dari awal, setelah itu kita mulai melintasi daftar current_threads, mengikuti setiap penunjuk dengan mengikuti instruksi.
Jika instruksi NEXT ditemukan, maka utas ditempatkan dalam daftar next_threads, yaitu, ia menunggu acara berikutnya diterima.
Jika pola utas tidak cocok dengan acara yang diterima, maka utas seperti itu tidak ditambahkan ke daftar next_threads.
Instruksi MATCH segera keluar dari fungsi, melaporkan kode kembali yang polanya cocok dengan sesi.
Setelah selesai merangkak dari daftar aliran, daftar saat ini dan selanjutnya ditukar.
Sebenarnya itu saja. Kita dapat mengatakan bahwa kita benar-benar melakukan apa yang kita inginkan: pada saat yang sama kita memeriksa beberapa templat, meluncurkan satu proses pencocokan baru untuk setiap acara sesi.
Banyak Identitas dan Cabang di Templat
Mencari templat yang menggambarkan urutan kejadian linear, tentu saja, berguna, tetapi kami ingin mendapatkan ekspresi reguler yang lengkap. Dan aliran yang kita buat pada tahap sebelumnya juga berguna di sini.
Misalkan kita ingin menemukan urutan dua atau tiga peristiwa yang menarik bagi kita, sesuatu seperti ekspresi reguler pada baris: "a? Bc". Dalam urutan ini, simbol "a" adalah opsional. Bagaimana cara mengekspresikannya dalam bytecode? Mudah!
Kita dapat memulai dua utas, satu utas untuk setiap kasus: dengan simbol "a" dan tanpa itu. Untuk melakukan ini, kami memperkenalkan instruksi tambahan (dari addr1 jenis SPLIT, addr2), yang memulai dua utas dari alamat yang ditentukan. Selain SPLIT, JUMP juga berguna bagi kami, yang hanya melanjutkan eksekusi dengan instruksi yang ditentukan dalam argumen langsung:
typedef enum matcher_opcode { OP_ABORT, OP_NAME, OP_SCREEN, OP_NEXT,
Pengulangan itu sendiri dan petunjuk lainnya tidak berubah - kami hanya memperkenalkan dua penangan baru:
Perhatikan bahwa instruksi menambahkan utas ke daftar saat ini, yaitu, mereka terus bekerja dalam konteks acara saat ini. Thread di mana cabang terjadi tidak masuk ke daftar utas berikut.
Hal yang paling mengejutkan dalam mesin virtual ekspresi reguler ini adalah bahwa utas kami dan pasangan instruksi ini cukup untuk mengekspresikan hampir semua konstruksi yang diterima secara umum saat mencocokkan string.
Ekspresi reguler pada acara
Sekarang kita memiliki mesin dan alat virtual yang sesuai untuk itu, kita sebenarnya dapat menangani sintaks untuk ekspresi reguler kita.
Pencatatan opcode secara manual untuk program yang lebih serius dengan cepat hilang. Terakhir kali saya tidak melakukan parser lengkap, tetapi pengguna true-grue menunjukkan kemampuan perpustakaan raddsl- nya menggunakan bahasa mini PigletC sebagai contoh . Saya sangat terkesan dengan singkatnya kode sehingga dengan bantuan raddsl saya menulis sebuah kompiler kecil ekspresi reguler string dalam seratus atau dua ratus dalam Python. Kompiler dan instruksi penggunaannya ada di GitHub. Hasil kompiler dalam bahasa assembly dipahami oleh utilitas yang membaca dua file (sebuah program untuk mesin virtual dan daftar acara sesi untuk verifikasi).
Untuk memulainya, kami membatasi diri pada jenis dan konteks acara. Jenis acara dilambangkan dengan satu angka; jika Anda perlu menentukan konteks, tentukan melalui titik dua. Contoh paling sederhana:
> python regexp/regexp.py "13" # , 13 NEXT NAME 13 MATCH
Sekarang contoh dengan konteks:
python regexp/regexp.py "13:12" # 13, 12 NEXT NAME 13 SCREEN 12 MATCH
Acara yang berturut-turut harus dipisahkan entah bagaimana (misalnya, oleh spasi):
> python regexp/regexp.py "13 11 10:9" 08:40:52 NEXT NAME 13 NEXT NAME 11 NEXT NAME 10 SCREEN 9 MATCH
Template lebih menarik:
> python regexp/regexp.py "12|13" SPLIT L0 L1 L0: NEXT NAME 12 JUMP L2 L1: NEXT NAME 13 L2: MATCH
Perhatikan garis yang diakhiri dengan tanda titik dua. Ini adalah tag. Instruksi SPLIT membuat dua utas yang melanjutkan eksekusi dari label L0 dan L1, dan JUMP pada akhir cabang pertama dari eksekusi cukup melanjutkan ke akhir cabang.
Anda dapat memilih antara rantai ekspresi lebih benar dengan mengelompokkan berikutnya dalam tanda kurung:
> python regexp/regexp.py "(1 2 3)|4" SPLIT L0 L1 L0: NEXT NAME 1 NEXT NAME 2 NEXT NAME 3 JUMP L2 L1: NEXT NAME 4 L2: MATCH
Peristiwa sewenang-wenang ditunjukkan oleh sebuah titik:
> python regexp/regexp.py ". 1" NEXT NEXT NAME 1 MATCH
Jika kami ingin menunjukkan bahwa selanjutnya adalah opsional, maka kami memberikan tanda tanya setelahnya:
> python regexp/regexp.py "1 2 3? 4" NEXT NAME 1 NEXT NAME 2 SPLIT L0 L1 L0: NEXT NAME 3 L1: NEXT NAME 4 MATCH
Tentu saja, beberapa pengulangan reguler (plus atau tanda bintang) juga umum dalam ekspresi reguler:
> python regexp/regexp.py "1+ 2" L0: NEXT NAME 1 SPLIT L0 L1 L1: NEXT NAME 2 MATCH
Di sini kita cukup menjalankan instruksi SPLIT berkali-kali, memulai utas baru pada setiap siklus.
Demikian pula dengan tanda bintang:
> python regexp/regexp.py "1* 2" L0: SPLIT L1 L2 L1: NEXT NAME 1 JUMP L0 L2: NEXT NAME 2 MATCH

Perspektif
Ekstensi lain ke mesin virtual yang dijelaskan mungkin berguna.
Misalnya, dapat dengan mudah diperluas dengan memeriksa atribut acara. Untuk sistem nyata, saya kira menggunakan sintaksis seperti "1: 2 {3: 4, 5:> 3}", yang berarti: event 1 dalam konteks 2 dengan atribut 3 memiliki nilai 4 dan nilai atribut 5 lebih besar dari 3. Atribut di sini Anda bisa meneruskannya dalam array ke fungsi matcher_accept.
Jika Anda juga melewatkan interval waktu antara peristiwa ke matcher_accept, maka Anda dapat menambahkan sintaks ke bahasa templat yang memungkinkan Anda untuk melewatkan waktu di antara acara: "1 mindelta (120) 2", yang berarti: peristiwa 1, maka intervalnya setidaknya 120 detik, peristiwa 2 Dikombinasikan dengan mempertahankan urutan, ini memungkinkan Anda untuk mengumpulkan informasi tentang perilaku pengguna antara dua peristiwa berikutnya.
Hal-hal berguna lainnya yang relatif mudah ditambahkan adalah: menjaga urutan ekspresi reguler, memisahkan tanda bintang dan operator tanda plus dan serakah, dan sebagainya. Dalam hal teori automata, mesin virtual kami adalah robot hingga nondeterministic, untuk implementasi yang tidak sulit untuk melakukan hal-hal seperti itu.
Kesimpulan
Sistem kami dikembangkan untuk antarmuka pengguna yang cepat, oleh karena itu mesin penyimpanan sesi ditulis sendiri dan dioptimalkan secara khusus untuk bagian melalui semua sesi. Semua milyaran peristiwa yang dipecah dalam sesi diperiksa terhadap pola dalam hitungan detik pada satu server.
Jika kecepatannya tidak terlalu penting bagi Anda, maka sistem yang serupa dapat dirancang sebagai ekstensi untuk beberapa sistem penyimpanan data yang lebih standar seperti database relasional tradisional atau sistem file terdistribusi.
By the way, dalam versi terbaru dari standar SQL fitur yang mirip dengan yang dijelaskan dalam artikel telah muncul, dan database individu ( Oracle dan Vertica ) telah menerapkannya. Yandex ClickHouse, pada gilirannya, mengimplementasikan bahasa seperti SQL-nya sendiri, tetapi juga memiliki fungsi yang serupa .
Mengalihkan perhatian dari kejadian dan ekspresi reguler, saya ingin mengulangi bahwa penerapan mesin virtual jauh lebih luas daripada yang terlihat pada pandangan pertama. Teknik ini cocok dan banyak digunakan dalam semua kasus ketika ada kebutuhan untuk secara jelas membedakan antara primitif bahwa mesin sistem memahami dan subsistem "depan", yaitu, misalnya, beberapa DSL atau bahasa pemrograman.
Ini menyimpulkan serangkaian artikel tentang berbagai penggunaan penerjemah bytecode dan mesin virtual. Saya harap para pembaca Habr menyukai serial ini dan, tentu saja, saya akan dengan senang hati menjawab pertanyaan apa pun tentang topik ini.
Penerjemah bytecode untuk bahasa pemrograman adalah topik khusus, dan hanya ada sedikit literatur tentangnya. Secara pribadi, saya menyukai buku Ian Craig , Virtual Machines, meskipun tidak menggambarkan implementasi penerjemah sebagai mesin abstrak - model matematika yang mendasari berbagai bahasa pemrograman.
Dalam arti yang lebih luas, buku lain dikhususkan untuk mesin virtual - "Mesin Virtual: Platform Fleksibel untuk Sistem dan Proses" ("Mesin Virtual: Platform Serbaguna untuk Sistem dan Proses"). Ini adalah pengantar berbagai aplikasi virtualisasi, yang mencakup virtualisasi bahasa, proses, dan arsitektur komputer secara umum.
Aspek praktis dari pengembangan mesin ekspresi reguler jarang dibahas dalam literatur kompiler populer. Pig Match dan contoh dari artikel pertama didasarkan pada ide-ide dari serangkaian artikel yang luar biasa dari Russ Cox, salah satu pengembang mesin Google RE2.
Teori ekspresi reguler disajikan dalam semua buku teks akademik tentang kompiler. Merupakan kebiasaan untuk merujuk pada "Buku Naga" yang terkenal, tetapi saya akan merekomendasikan mulai dengan tautan di atas.
Saat mengerjakan artikel ini, saya pertama kali menggunakan sistem yang menarik untuk pengembangan kompiler cepat untuk Python raddsl , yang menjadi milik pengguna true-grue (terima kasih, Peter!). Jika Anda dihadapkan dengan tugas membuat prototipe bahasa atau dengan cepat mengembangkan semacam DSL, Anda harus memperhatikannya.