Kuintet adalah cara untuk merekam potongan atom data yang menunjukkan perannya dalam kehidupan kita. Kuintet dapat menggambarkan data apa pun, sementara masing-masing berisi informasi lengkap tentang diri Anda dan tentang hubungan dengan kuintet lain. Ini mewakili istilah domain, terlepas dari platform yang digunakan. Tugasnya adalah menyederhanakan penyimpanan data dan meningkatkan visibilitas presentasi.

Saya akan berbicara tentang pendekatan baru untuk menyimpan dan memproses informasi dan berbagi pemikiran saya tentang menciptakan platform pengembangan dalam paradigma baru ini.
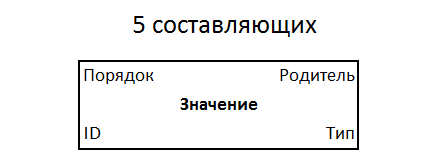
Kuintet memiliki properti: tipe, nilai, orangtua, urutan antar saudara. Dengan pengenal, hanya 5 komponen yang diperoleh. Ini adalah bentuk perekaman informasi universal yang paling sederhana, standar baru yang berpotensi cocok untuk semua orang. Quintet disimpan dalam sistem file dari struktur tunggal, dalam bidang informasi yang diindeks secara monoton terus menerus.
Untuk mencatat informasi, ada sejumlah standar, pendekatan dan aturan, yang pengetahuannya diperlukan untuk bekerja dengan catatan-catatan ini. Standar dijelaskan secara terpisah dan tidak secara langsung berhubungan dengan data. Dalam kasus kuintet, dengan mengambil salah satu dari itu, Anda dapat memperoleh informasi yang relevan tentang sifat, sifat, dan aturan bekerja dengan bidang subjeknya. Standarnya seragam dan tidak berubah untuk semua area. Kuintet disembunyikan dari pengguna - metadata dan data tersedia baginya dalam bentuk yang umum bagi banyak orang.
Kuintet bukan hanya informasi, tetapi juga perintah yang dapat dieksekusi. Namun yang terpenting, itu adalah data yang Anda ingin simpan, rekam, dan ambil. Karena dalam kasus kami mereka langsung ditangani, terhubung dan diindeks, kami akan menyimpannya dalam semacam database. Untuk menguji prototipe sistem penyimpanan data kuintet, misalnya, kami menggunakan database relasional biasa.
Struktur kuintet
Ide utama artikel ini adalah mengganti tipe mesin dengan istilah manusia dan mengganti variabel dengan objek. Bukan oleh objek yang memerlukan konstruktor, destruktor, antarmuka, dan pengumpul sampah, tetapi oleh unit informasi kristal murni yang dioperasikan oleh pelanggan. Artinya, jika pelanggan mengatakan "Aplikasi", maka untuk menyimpan
esensi informasi ini di media tidak akan membutuhkan keahlian seorang programmer.
Berguna untuk memusatkan perhatian pengguna hanya pada nilai objek, dan jenisnya, induknya, urutan (di antara yang sederajat dalam subordinasi) dan pengidentifikasi harus jelas dari konteks atau hanya disembunyikan. Ini berarti bahwa
pengguna sama sekali tidak tahu tentang kuintet , ia hanya menetapkan tugasnya, memastikan bahwa itu diterima dengan benar, dan kemudian memulai pelaksanaannya.
Konsep dasar
Ada satu set tipe data yang dapat dipahami siapa saja: string, angka, file, teks, tanggal, dan sebagainya. Set sederhana seperti itu cukup memadai untuk merumuskan masalah, dan untuk "pemrograman" itu dan jenis yang diperlukan untuk implementasinya. Tipe dasar yang diwakili oleh kuintet mungkin terlihat seperti ini:

Dalam hal ini, beberapa komponen kuintet tidak digunakan, dan ia digunakan sebagai tipe dasar. Ini membuat inti sistem lebih mudah dinavigasi saat bernavigasi di metadata.
Latar belakang
Karena kesenjangan analitis antara pengguna dan pemrogram, deformasi konsep yang signifikan terjadi pada tahap pengaturan masalah. Sikap meremehkan, tidak bisa dipahami, dan inisiatif yang tidak diminta sering mengubah pemikiran pelanggan yang sederhana dan mudah dipahami menjadi campuran yang mustahil secara logis, dilihat dari sudut pandang pengguna.

Transfer pengetahuan harus terjadi tanpa kehilangan atau distorsi. Selain itu, di masa depan, ketika mengatur penyimpanan pengetahuan ini, perlu untuk menyingkirkan pembatasan yang diberlakukan oleh sistem manajemen data yang dipilih.
Cara menyimpan data
Sebagai aturan, ada banyak database di server, masing-masing berisi deskripsi struktur entitas dengan set atribut tertentu - data yang saling berhubungan. Mereka disimpan dalam urutan tertentu, idealnya optimal untuk pengambilan sampel.
Sistem penyimpanan informasi yang diusulkan adalah kompromi antara berbagai metode terkenal: kolom, string dan NoSQL. Ini dirancang untuk menyelesaikan tugas-tugas yang biasanya dilakukan oleh salah satu metode ini.
Sebagai contoh, teori dasar kolom terlihat indah: kita hanya membaca kolom yang diinginkan, dan tidak semua baris catatan secara keseluruhan. Namun, dalam praktiknya, kecil kemungkinannya bahwa data akan ditempatkan di media sehingga dapat diterapkan ke berbagai bagian analisis. Perhatikan bahwa atribut dan metrik analitik dapat ditambahkan dan dihapus, terkadang lebih cepat daripada kita dapat membangun kembali ekonomi kolom ini. Belum lagi fakta bahwa data dalam database dapat disesuaikan, yang juga akan melanggar keindahan rencana pengambilan sampel karena fragmentasi yang tak terhindarkan.
Metadata
Kami memperkenalkan konsep - istilah - untuk menggambarkan objek yang kami operasikan: entitas, properti, permintaan, file, dll. Kami akan mendefinisikan semua istilah yang kami gunakan di area subjek kami. Dan dengan bantuan mereka, kami akan menggambarkan semua entitas yang memiliki perincian, termasuk dalam bentuk hubungan antar entitas. Misalnya, alat peraga - tautan ke entri direktori status. Istilah ini ditulis dalam kuintet data.
Seperangkat uraian istilah adalah metadata yang mendefinisikan struktur tabel dan bidang dalam database biasa. Misalnya, ada struktur data berikut: aplikasi dari tanggal yang memiliki konten (teks aplikasi) dan Status, di mana peserta dalam proses produksi menambahkan komentar yang menunjukkan tanggal. Dalam konstruktor database tradisional, akan terlihat seperti ini:

Karena kami memutuskan untuk menyembunyikan dari pengguna semua detail yang tidak penting, seperti ID yang mengikat, misalnya, skema akan agak disederhanakan: menyebutkan ID dihapus dan nama entitas dan nilai-nilai kunci mereka digabungkan.
Pengguna "menggambar" tugas: permintaan dari tanggal hari ini yang memiliki status (nilai referensi) dan Anda dapat menambahkan komentar yang menunjukkan tanggal:

Sekarang kita melihat 6 bidang data yang berbeda, bukan 9, dan keseluruhan skema menawarkan kita untuk membaca dan memahami 7 kata, bukannya 13. Meskipun ini jauh dari hal utama, tentu saja.
Berikut adalah kuintet yang dihasilkan oleh inti kontrol untuk menggambarkan struktur ini:

Penjelasan menggantikan nilai kuintet yang disorot dalam warna abu-abu disediakan untuk kejelasan. Bidang-bidang ini tidak diisi karena semua informasi yang diperlukan ditentukan secara unik oleh komponen yang tersisa.
Lihat bagaimana kuintet terkait Data pengguna
Pertimbangkan menyimpan kumpulan data seperti itu untuk tugas di atas:

Data itu sendiri disimpan dalam kuintet sesuai dengan struktur yang mengindikasikan keanggotaan dalam istilah tertentu dalam bentuk set seperti itu:
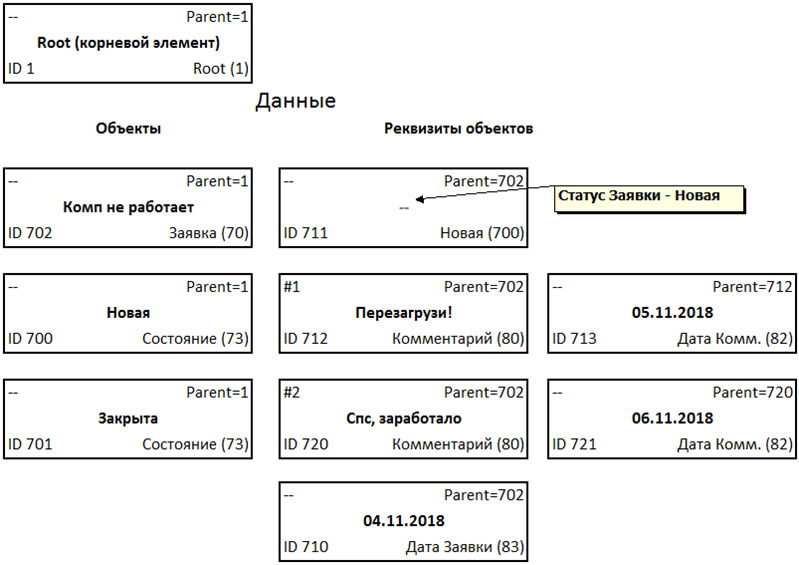
Kami melihat struktur hierarki yang akrab yang disimpan menggunakan metode Daftar Adjacency alias.
Performa
Contoh di atas sangat sederhana, tetapi apa yang akan terjadi ketika strukturnya ribuan kali lebih kompleks dan data akan menjadi gigabytes?
Kami akan membutuhkan:
- Struktur hierarkis yang dipertimbangkan di atas adalah 1 pc.
- B-tree untuk pencarian berdasarkan ID, induk dan tipe - 3 pcs.
Dengan demikian, semua catatan dalam basis data kami akan diindeks, termasuk data dan metadata. Pengindeksan seperti itu diperlukan untuk menjaga properti dari basis data relasional - alat paling sederhana dan paling populer. Indeks induk sebenarnya komposit (ID induk + tipe). Indeks berdasarkan tipe juga komposit (tipe + nilai) untuk pencarian cepat objek dari tipe tertentu.
Metadata memungkinkan kita untuk menyingkirkan rekursi: misalnya, untuk menemukan semua detail objek yang diberikan, kita menggunakan indeks dengan ID induk. Jika Anda perlu mencari objek dari tipe tertentu, maka indeks dengan tipe ID digunakan. Tipe adalah analog dari nama tabel dan bidang dalam DBMS relasional.

Dalam kasus apa pun, kami tidak memindai seluruh kumpulan data, dan bahkan dengan sejumlah besar nilai jenis apa pun, nilai yang diinginkan dapat ditemukan dalam sejumlah kecil langkah.
Dasar untuk platform pengembangan
Dalam dirinya sendiri, basis data semacam itu tidak mencukupi untuk pemrograman aplikasi, dan tidak lengkap, seperti yang mereka katakan, menurut Turing. Tapi kita tidak berbicara di sini hanya tentang database, tetapi mencoba untuk mencakup semua aspek: objek, antara lain, algoritma kontrol sewenang-wenang yang dapat diluncurkan, dan mereka akan bekerja
Akibatnya, alih-alih struktur basis data yang kompleks dan kode sumber algoritma kontrol yang disimpan secara terpisah, kami mendapatkan bidang informasi yang seragam, dibatasi oleh volume medium dan ditandai dengan metadata. Data itu sendiri disajikan kepada pengguna dengan cara yang ia mengerti - struktur area subjek dan entri yang sesuai di dalamnya. Pengguna secara sewenang-wenang mengubah struktur dan data, termasuk membuat operasi massal dengannya.
Kami belum menemukan sesuatu yang baru: semua data sudah disimpan dalam sistem file dan pencarian di dalamnya dilakukan dengan menggunakan B-tree, dalam sistem file, dalam database. Kami hanya mengatur ulang penyajian data untuk membuatnya lebih mudah dan lebih visual untuk bekerja dengannya.
Untuk bekerja dengan representasi data ini, Anda akan memerlukan inti yang sangat kompak - mesin basis data kami adalah urutan besarnya lebih kecil dari BIOS komputer, dan, oleh karena itu, dapat dibuat jika tidak di perangkat keras, maka setidaknya secepat dan secepat dijilat mungkin. Demi alasan keamanan, ini juga hanya baca.
Menambahkan kelas baru ke perakitan .Net tercinta saya, kita dapat mengamati hilangnya 200-300 MB RAM hanya untuk deskripsi kelas ini. Megabita ini tidak akan masuk ke dalam cache dari level yang benar, menyebabkan sistem menjadi berantakan dengan konsekuensi selanjutnya. Situasi serupa dengan Java. Menggambarkan kelas yang sama dengan kuintet akan memakan waktu puluhan atau ratusan byte, karena kelas hanya menggunakan trik primitif untuk bekerja dengan data yang sudah akrab dengan kernel.
Cara menangani berbagai format: RDBMS, NoSQL, basis kolomPendekatan yang dijelaskan mencakup dua bidang utama: RDBMS dan NoSQL. Ketika memecahkan masalah yang memanfaatkan basis data kolom, kita perlu memberi tahu kernel bahwa objek tertentu harus disimpan, dengan mempertimbangkan optimalisasi pengambilan sampel massal dari nilai-nilai dari tipe data tertentu (istilah kita). Jadi kernel akan dapat menempatkan data pada disk dengan cara yang paling menguntungkan.
Jadi, untuk basis kolom, kita dapat secara signifikan menghemat ruang yang ditempati oleh kuintet: gunakan hanya satu atau dua komponennya untuk menyimpan data yang bermanfaat, bukan lima, dan juga gunakan indeks hanya untuk menunjukkan awal rantai data. Dalam banyak kasus, hanya indeks yang akan digunakan untuk sampel dari basis kolom analog kami, tanpa perlu mengakses data tabel itu sendiri.
Perlu dicatat bahwa ide tersebut tidak menetapkan tujuan untuk mengumpulkan semua perkembangan lanjutan dari ketiga jenis database ini. Sebaliknya, mesin dari sistem baru akan dikurangi sebanyak mungkin, hanya mewujudkan fungsi minimum yang diperlukan - segala sesuatu yang mencakup permintaan DDL dan DML dalam konsep yang dijelaskan di sini.
Paradigma pemrograman
Menggunakan pendekatan yang dideskripsikan tidak terbatas hanya pada kuintet, tetapi juga mempromosikan paradigma yang berbeda dari yang digunakan oleh para programmer. Alih-alih bahasa imperatif, deklaratif, atau objek, bahasa query diusulkan sebagai lebih akrab bagi manusia dan memungkinkan kita untuk mengatur tugas langsung ke komputer, melewati programmer dan lapisan yang tidak bisa ditembus dari lingkungan pengembangan yang ada.
Tentu saja, penerjemah dari bahasa pengguna gratis ke bahasa persyaratan yang jelas masih diperlukan dalam banyak kasus.Topik ini akan dijelaskan lebih rinci dalam artikel terpisah dengan contoh dan perkembangan yang ada.
Jadi, singkatnya, ini berfungsi sebagai berikut:
- Kami pernah menjelaskan dengan quintet tipe data primitif: string, angka, file, teks, dan lainnya, dan juga melatih kernel untuk bekerja dengannya. Pelatihan dikurangi menjadi penyajian data yang benar dan implementasi operasi sederhana dengan mereka.
- Sekarang kami jelaskan dalam istilah pengguna kuintet (tipe data) - dalam bentuk metadata. Deskripsi datang untuk menentukan tipe data primitif untuk setiap tipe pengguna dan menentukan subordinasi.
- Masukkan kuintet data sesuai dengan struktur yang ditentukan oleh metadata. Setiap kuintet data berisi tautan ke tipe dan induknya, yang memungkinkan Anda untuk dengan cepat menemukannya di gudang data.
- Tugas-tugas inti turun untuk mengambil data dan melakukan operasi sederhana dengan mereka untuk menerapkan algoritma rumit yang dijelaskan oleh pengguna.
- Pengguna mengelola data dan algoritma menggunakan antarmuka visual yang secara visual menghadirkan yang pertama dan kedua.
Turing kelengkapan seluruh sistem dipastikan dengan perwujudan persyaratan dasar: kernel dapat melakukan operasi sekuensial, cabang kondisional, memproses set data dan berhenti bekerja ketika hasil tertentu tercapai.
Bagi seseorang, manfaatnya adalah kesederhanaan persepsi, misalnya, daripada mendeklarasikan siklus yang melibatkan variabel
for (i=0; i<length(A); i++) if A[i] meets a condition do something with A[i]
konstruksi yang lebih ramah-manusia digunakan, seperti
with every A, that match a condition, do something
Kami bermimpi untuk abstrak dari seluk-beluk tingkat rendah menerapkan sistem informasi: loop, konstruktor, fungsi, manifes, perpustakaan - semua ini memakan terlalu banyak ruang di otak seorang programmer, menyisakan sedikit ruang untuk kerja kreatif dan pengembangan.
Scaling
Aplikasi modern tidak dapat dibayangkan tanpa penskalaan: diperlukan kemampuan tak terbatas untuk memperluas kapasitas pemuatan sistem informasi. Dalam pendekatan yang dideskripsikan, mengingat kesederhanaan ekstrem dari organisasi data, penskalaan ternyata diatur tidak lebih rumit daripada dalam arsitektur yang ada.
Dalam contoh di atas dengan aplikasi, Anda dapat memisahkan mereka, misalnya, dengan ID mereka, membuat generasi ID dengan byte tinggi tetap untuk server yang berbeda. Artinya, ketika menggunakan 32 bit untuk penyimpanan ID, dua-tiga-empat atau lebih bit yang paling signifikan, sesuai kebutuhan, akan menunjukkan server tempat penyimpanan aplikasi ini. Dengan demikian, setiap server akan memiliki kumpulan ID sendiri.
Inti dari satu server dapat berfungsi secara independen dari server lain, tanpa mengetahui apa pun tentang mereka. Saat membuat aplikasi, itu akan diberikan prioritas tinggi ke server dengan jumlah ID minimum yang digunakan, memastikan distribusi beban yang seragam.
Dengan serangkaian kemungkinan variasi permintaan dan respons yang terbatas dengan satu organisasi data, Anda akan memerlukan operator yang cukup kompak yang mendistribusikan permintaan di seluruh server dan mengumpulkan hasilnya.