Pernahkah Anda memperhatikan bagaimana ceruk pasar, setelah menjadi populer, menarik pemasar dari perdagangan keamanan informasi dalam ketakutan? Mereka meyakinkan Anda bahwa jika terjadi serangan cyber, perusahaan tidak akan dapat mengatasi tugas apa pun untuk menanggapi insiden tersebut. Dan di sini, tentu saja, penyihir baik hati muncul - penyedia layanan yang siap untuk jumlah tertentu untuk menyelamatkan pelanggan dari segala kerumitan dan kebutuhan untuk membuat keputusan. Kami menjelaskan mengapa pendekatan semacam itu bisa berbahaya tidak hanya untuk dompet, tetapi juga untuk tingkat keamanan perusahaan, manfaat praktis apa yang dapat diberikan oleh keterlibatan penyedia layanan dan keputusan apa yang harus selalu tetap berada dalam area tanggung jawab pelanggan.

Pertama-tama, kita akan membahas terminologi. Ketika datang ke manajemen insiden, orang sering mendengar dua singkatan, SOC dan CSIRT, yang pentingnya penting untuk dipahami untuk menghindari manipulasi pemasaran.
SOC (pusat operasi keamanan) - unit yang didedikasikan untuk tugas-tugas operasional keamanan informasi. Paling sering, ketika berbicara tentang fungsi SOC, orang berarti memantau dan mengidentifikasi insiden. Namun, biasanya ruang lingkup tanggung jawab SOC mencakup tugas yang terkait dengan proses keamanan informasi, termasuk menanggapi dan menghilangkan konsekuensi dari insiden, kegiatan metodologis untuk meningkatkan infrastruktur TI dan meningkatkan tingkat keamanan perusahaan. Pada saat yang sama, SOC cukup sering adalah unit staf independen, termasuk spesialis dari berbagai profil.
CSIRT (tim respons insiden keamanan siber) - kelompok / tim sementara atau unit yang bertanggung jawab untuk merespons insiden yang muncul. CSIRT biasanya memiliki tulang punggung permanen, yang terdiri dari profesional keamanan informasi, administrator SZI dan sekelompok forensik. Namun, komposisi akhir tim dalam setiap kasus ditentukan oleh vektor ancaman dan dapat ditambahkan oleh layanan TI, pemilik sistem bisnis, dan bahkan manajemen perusahaan dengan layanan PR (untuk menyamakan latar belakang negatif di media).
Terlepas dari kenyataan bahwa dalam kegiatannya CSIRT paling sering dipandu oleh standar NIST, yang mencakup siklus manajemen insiden penuh, saat ini penekanan dalam ruang pemasaran lebih sering ditempatkan pada kegiatan respons, menolak fungsi ini untuk SOC dan membandingkan kedua istilah ini.
Apakah konsep SOC lebih luas dalam kaitannya dengan CSIRT? Menurut saya, ya. Dalam kegiatannya, SOC tidak terbatas pada insiden, ia dapat bergantung pada data intelijen dunia maya, prakiraan, dan analisis tingkat keamanan organisasi dan mencakup tugas keamanan yang lebih luas.
Tetapi kembali ke standar NIST, sebagai salah satu pendekatan paling populer yang menggambarkan prosedur dan fase manajemen insiden. Prosedur umum standar NIST SP 800-61 adalah sebagai berikut:
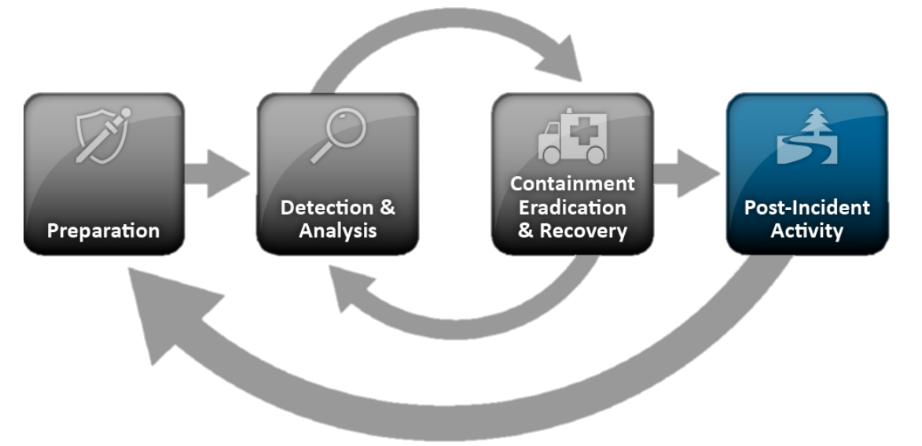
- Persiapan:
- Menciptakan infrastruktur teknis yang diperlukan untuk menangani insiden
- Buat aturan deteksi insiden
- Identifikasi dan analisis insiden:
- Pemantauan dan identifikasi
- Analisis insiden
- Prioritas
- Peringatan
- Lokalisasi, netralisasi, dan pemulihan:
- Pelokalan insiden
- Pengumpulan, penyimpanan, dan dokumentasi tanda-tanda kejadian
- Mitigasi bencana
- Pemulihan pasca insiden
- Kegiatan metodis:
- Ringkasan insiden
- Isi Basis Pengetahuan + Intelijen Ancaman
- Langkah-langkah organisasi dan teknis
Terlepas dari kenyataan bahwa standar NIST didedikasikan untuk Respon Insiden, bagian penting dari respons ditempati oleh bagian "Deteksi dan analisis insiden", yang sebenarnya menggambarkan tugas klasik pemantauan dan pemrosesan insiden. Mengapa mereka diberi perhatian seperti itu? Untuk menjawab pertanyaan, mari kita lihat lebih dekat pada masing-masing blok ini.
Persiapan
Tugas mengidentifikasi insiden dimulai dengan penciptaan dan "pendaratan" model ancaman dan model penyusup pada aturan untuk mengidentifikasi insiden. Anda dapat mendeteksi insiden dengan menganalisis peristiwa keamanan informasi (log) dari berbagai alat perlindungan informasi, komponen infrastruktur TI, sistem aplikasi, elemen sistem teknologi (ACS) dan sumber daya informasi lainnya. Tentu saja, Anda dapat melakukan ini secara manual, dengan skrip, laporan, tetapi untuk deteksi real-time yang efektif dari insiden keamanan informasi, solusi khusus masih diperlukan.
Sistem SIEM datang untuk menyelamatkan di sini, tetapi operasi mereka tidak kurang dari analisis log mentah, dan pada setiap tahap, dari menghubungkan sumber ke membuat aturan insiden. Kesulitan terkait dengan fakta bahwa peristiwa yang berasal dari sumber yang berbeda harus memiliki penampilan yang seragam, dan parameter utama acara harus dipetakan ke dalam bidang acara yang sama di SIEM, terlepas dari kelas / produsen sistem atau perangkat keras.
Aturan untuk mendeteksi insiden, daftar indikator kompromi, tren ancaman dunia maya membentuk apa yang disebut "konten" SIEM. Ini harus melakukan tugas mengumpulkan profil jaringan dan aktivitas pengguna, mengumpulkan statistik tentang peristiwa dari berbagai jenis, dan mengidentifikasi insiden keamanan informasi yang khas. Logika untuk memicu aturan untuk mendeteksi insiden harus mempertimbangkan infrastruktur dan proses bisnis tertentu dari perusahaan tertentu.
Karena tidak ada infrastruktur standar perusahaan dan proses bisnis yang terjadi di dalamnya, sehingga tidak ada konten terpadu dari sistem SIEM. Oleh karena itu, semua perubahan dalam infrastruktur TI perusahaan harus tercermin secara tepat waktu baik dalam pengaturan dan penyetelan peralatan keamanan, dan dalam SIEM. Jika sistem dikonfigurasikan hanya satu kali, pada awal penyediaan layanan, atau diperbarui setahun sekali, ini mengurangi kemungkinan mendeteksi insiden militer dan berhasil menyaring positif palsu beberapa kali.
Dengan demikian, pengaturan fitur keamanan, menghubungkan sumber ke sistem SIEM, dan mengadaptasi konten SIEM adalah tugas terpenting dalam menanggapi insiden, pangkalan yang tanpanya mustahil untuk melanjutkan. Lagi pula, jika insiden itu tidak direkam tepat waktu dan tidak melalui fase identifikasi dan analisis, kita tidak lagi berbicara tentang respons apa pun, kita hanya dapat bekerja dengan konsekuensinya.
Deteksi dan analisis insiden
Layanan pemantauan harus bekerja dengan insiden dalam mode real-time sekitar jam dan tujuh hari seminggu. Aturan ini, seperti dasar-dasar keselamatan, ditulis dalam darah: sekitar setengah dari serangan cyber kritis dimulai pada malam hari, sangat sering pada hari Jumat (ini adalah kasus, misalnya, dengan virus ransomware WannaCry). Jika Anda tidak mengambil langkah-langkah perlindungan dalam satu jam pertama, maka itu sudah bisa sangat terlambat. Dalam hal ini, cukup transfer semua insiden yang direkam ke langkah berikutnya yang dijelaskan dalam standar NIST, mis. ke tahap lokalisasi, itu tidak praktis, dan inilah sebabnya:
- Untuk mendapatkan informasi tambahan tentang apa yang terjadi atau untuk menyaring positif palsu lebih mudah dan lebih benar pada tahap analisis, daripada lokalisasi kejadian tersebut. Ini memungkinkan Anda untuk meminimalkan jumlah insiden yang dirujuk ke tahap selanjutnya dari proses Respon Insiden, di mana spesialis tingkat yang lebih tinggi harus dilibatkan dalam pertimbangannya - manajer manajemen insiden, tim respons, sistem TI, dan administrator SIS. Lebih logis untuk membangun proses sedemikian rupa agar tidak meningkatkan setiap hal sepele, termasuk positif palsu, ke tingkat CISO.
- Respons dan "penindasan" dari suatu insiden selalu membawa risiko bisnis. Menanggapi suatu insiden dapat mencakup pekerjaan untuk memblokir akses mencurigakan, mengisolasi tuan rumah, dan meningkatkan ke tingkat kepemimpinan. Dalam hal false positive, masing-masing langkah ini akan secara langsung mempengaruhi ketersediaan elemen infrastruktur dan memaksa tim manajemen insiden untuk "memadamkan" eskalasi mereka sendiri untuk waktu yang lama dengan laporan dan memo multi-halaman.
Biasanya, insinyur lini pertama bekerja dalam layanan pemantauan 24/7, yang secara langsung terlibat dalam pemrosesan potensi insiden yang dicatat oleh sistem SIEM. Jumlah insiden semacam itu dapat mencapai beberapa ribu per hari (sekali lagi - apalagi sampai pada tahap lokalisasi?), Tetapi, untungnya, sebagian besar dari mereka cocok dengan pola-pola terkenal. Oleh karena itu, untuk meningkatkan kecepatan pemrosesan mereka, Anda dapat menggunakan skrip dan instruksi yang langkah demi langkah menjelaskan tindakan yang diperlukan.
Ini adalah praktik yang sudah terbukti yang memungkinkan pengurangan beban pada baris 2 dan baris 3 analis - mereka hanya akan ditransfer insiden yang tidak sesuai dengan skrip yang ada. Jika tidak, eskalasi insiden pada garis pemantauan kedua dan ketiga akan mencapai 80%, atau pada baris pertama perlu menempatkan spesialis mahal dengan keahlian tinggi dan periode pelatihan yang panjang.
Dengan demikian, selain karyawan lini pertama, diperlukan analis dan arsitek yang akan membuat skrip dan instruksi, melatih spesialis lini pertama, membuat konten dalam SIEM, menghubungkan sumber, mempertahankan pengoperasian dan mengintegrasikan SIEM dengan sistem kelas IRP, CMDB, dan banyak lagi.
Tugas pemantauan yang penting adalah pencarian, pemrosesan, dan implementasi berbagai database reputasi, laporan APT, buletin, dan langganan dalam sistem SIEM, yang pada akhirnya berubah menjadi indikator kompromi (IoC). Merekalah yang memungkinkan untuk mengidentifikasi serangan rahasia oleh penyerang di infrastruktur, malware yang tidak terdeteksi oleh vendor antivirus, dan banyak lagi. Namun, seperti menghubungkan sumber acara ke sistem SIEM, menambahkan semua informasi ini tentang ancaman terlebih dahulu membutuhkan penyelesaian sejumlah tugas:
- Otomatis menambahkan indikator
- Penilaian penerapan dan relevansi mereka
- Prioritas dan penghitungan informasi yang usang
- Dan yang paling penting - pemahaman tentang cara perlindungan yang Anda bisa dapatkan informasi untuk memverifikasi indikator ini. Jika semuanya cukup sederhana dengan yang jaringan - memeriksa firewall dan proksi, maka dengan yang host lebih sulit - dengan apa yang harus dibandingkan hash, bagaimana pada semua host untuk memeriksa proses yang sedang berjalan, cabang registri, dan file yang ditulis ke hard drive?
Di atas, saya menyentuh hanya sebagian dari aspek proses pemantauan dan analisis insiden yang harus dihadapi perusahaan mana pun yang membangun proses respons insiden. Menurut pendapat saya, ini adalah tugas yang paling penting dalam keseluruhan proses, tetapi mari kita beralih dan beralih ke unit kerja dengan insiden keamanan informasi yang telah direkam dan dianalisis.
Lokalisasi, netralisasi, dan pemulihan
Blok ini, menurut beberapa pakar keamanan informasi, adalah yang menentukan perbedaan antara tim pemantauan dan tim respons insiden. Mari kita melihat lebih dekat apa yang dimasukkan NIST ke dalamnya.
Pelokalan insiden
Menurut NIST, tugas utama dalam proses lokalisasi insiden adalah mengembangkan strategi, yaitu menentukan langkah-langkah untuk mencegah penyebaran insiden dalam infrastruktur perusahaan. Kompleks langkah-langkah ini dapat mencakup berbagai tindakan - mengisolasi host yang terlibat dalam insiden di tingkat jaringan, mengganti mode operasi alat perlindungan informasi dan bahkan menghentikan proses bisnis perusahaan untuk meminimalkan kerusakan akibat insiden tersebut. Sebenarnya, strategi adalah buku pedoman, yang terdiri dari matriks tindakan tergantung pada jenis insiden.
Implementasi dari tindakan ini dapat berhubungan dengan bidang tanggung jawab dari pergeseran dukungan teknis TI, pemilik dan administrator sistem (termasuk sistem bisnis), perusahaan kontraktor pihak ketiga, dan layanan keamanan informasi. Tindakan dapat dilakukan secara manual, oleh komponen EDR, dan bahkan skrip yang ditulis sendiri digunakan oleh perintah.
Karena keputusan yang dibuat pada tahap ini dapat secara langsung mempengaruhi proses bisnis perusahaan, keputusan untuk menerapkan strategi khusus dalam sebagian besar kasus tetap menjadi tugas manajer keamanan informasi internal (sering melibatkan pemilik sistem bisnis), dan
tugas ini tidak dapat di-outsourcing-kan. perusahaan . Peran penyedia layanan keamanan informasi dalam melokalisasi insiden dikurangi menjadi aplikasi operasional dari strategi yang dipilih oleh pelanggan.
Pengumpulan, penyimpanan, dan dokumentasi tanda-tanda kejadian
Setelah langkah-langkah operasional telah diambil untuk melokalisasi kejadian itu, penyelidikan menyeluruh harus dilakukan, mengumpulkan semua informasi untuk menilai sejauh mana. Tugas ini dibagi menjadi dua subtugas:
- Mentransfer input tambahan ke tim pemantauan, menghubungkan sumber-sumber tambahan peristiwa keamanan informasi yang terlibat dalam insiden tersebut ke sistem pengumpulan dan analisis acara.
- Menghubungkan tim forensik untuk menganalisis gambar hard disk, menganalisis dump memori, sampel malware, dan alat yang digunakan oleh penjahat cyber dalam insiden ini.
Seseorang juga harus ditunjuk untuk mengoordinasikan kegiatan semua unit dalam kerangka investigasi insiden. Spesialis ini harus memiliki wewenang dan kontak dari semua staf yang terlibat dalam penyelidikan. Bisakah karyawan kontraktor melakukan peran ini? Lebih mungkin tidak daripada ya. Lebih logis untuk mempercayakan peran ini ke spesialis atau kepala layanan keamanan informasi pelanggan.
Mitigasi bencana
Setelah menerima gambaran lengkap dari insiden tersebut dari berbagai departemen, koordinator mengembangkan langkah-langkah untuk menghilangkan konsekuensi dari insiden tersebut. Prosedur ini dapat meliputi:
- Penghapusan indikator yang diidentifikasi kompromi dan jejak keberadaan malware / penyusup.
- "Memuat ulang" host yang terinfeksi dan mengubah kata sandi pengguna.
- Menginstal pembaruan terbaru dan mengembangkan langkah-langkah kompensasi untuk menghilangkan kerentanan kritis yang digunakan dalam serangan itu.
- Mengubah profil keamanan GIS.
- Kontrol atas kelengkapan tindakan yang dilakukan oleh unit yang terlibat dan tidak adanya kompromi ulang sistem oleh pengganggu.
Ketika mengembangkan langkah-langkah, kami sarankan agar koordinator berkonsultasi dengan unit khusus yang bertanggung jawab untuk sistem tertentu, administrator sistem keamanan informasi, kelompok forensik, dan layanan pemantauan insiden IS. Tetapi, sekali lagi, keputusan akhir tentang penerapan langkah-langkah tertentu diambil oleh koordinator kelompok analisis insiden.
Pemulihan pasca insiden
Pada bagian ini, NIST sebenarnya berbicara tentang tugas-tugas departemen TI dan layanan operasi sistem bisnis. Semua pekerjaan dikurangi untuk memulihkan dan memverifikasi kinerja sistem TI dan proses bisnis perusahaan. Tidak masuk akal untuk membahas hal ini, karena sebagian besar perusahaan dihadapkan pada solusi dari masalah ini, jika bukan karena insiden keamanan informasi, maka setidaknya setelah kegagalan yang terjadi secara berkala bahkan di instalasi sistem yang paling stabil dan toleran terhadap kesalahan.
Kegiatan metodis
Bagian keempat dari metodologi Respon Insiden didedikasikan untuk mengatasi bug dan meningkatkan teknologi keamanan perusahaan.
Untuk persiapan laporan insiden, mengisi basis pengetahuan dan TI, sebagai aturan, tim forensik bertanggung jawab dalam hubungannya dengan layanan pemantauan. Jika strategi lokalisasi tidak dikembangkan pada saat kejadian ini, tulisannya termasuk dalam blok ini.
Nah, jelas bahwa poin yang sangat penting dalam menangani bug adalah mengembangkan strategi untuk mencegah insiden serupa di masa depan:
- Mengubah arsitektur infrastruktur TI dan GIS yang ada.
- Pengenalan alat keamanan informasi baru.
- Pengantar proses manajemen patch dan pemantauan insiden keamanan informasi (jika tidak ada).
- Koreksi proses bisnis perusahaan.
- Penambahan staf di departemen keamanan informasi.
- Perubahan otoritas keamanan informasi karyawan.
Peran Penyedia Layanan
Dengan demikian, kemungkinan partisipasi penyedia layanan dalam berbagai tahap respon insiden dapat direpresentasikan dalam bentuk matriks:
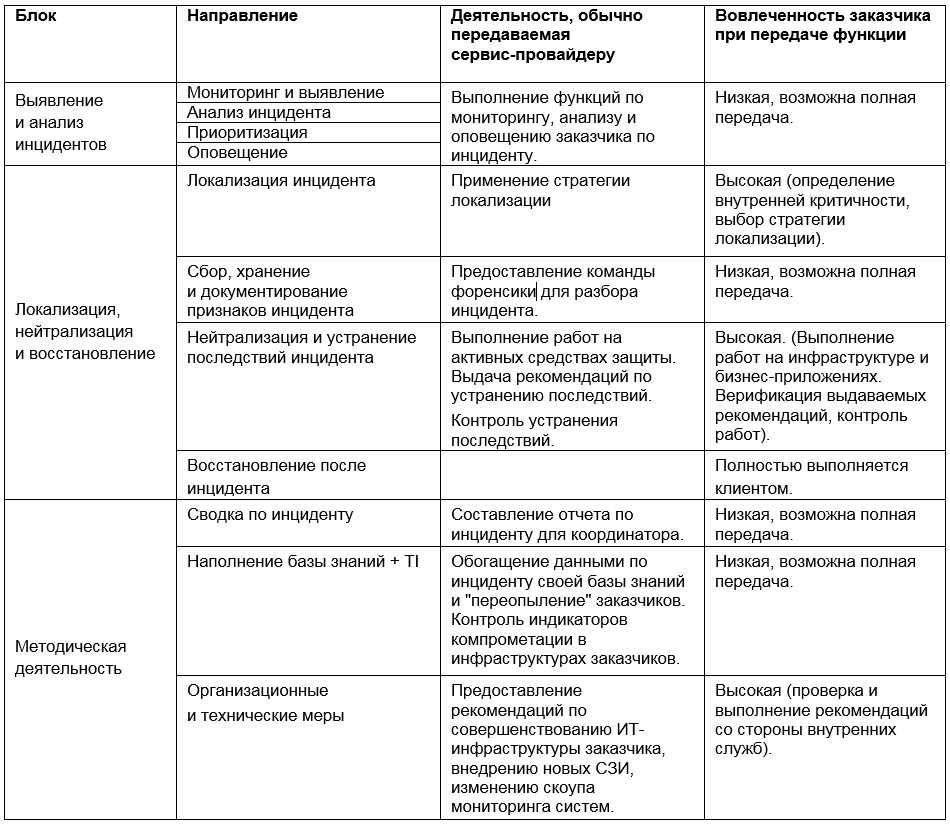
Pilihan alat dan pendekatan untuk manajemen insiden adalah salah satu tugas paling sulit dari keamanan informasi. Godaan untuk memercayai janji-janji penyedia layanan dan memberikannya semua fungsi bisa menjadi besar, tetapi kami menyarankan penilaian yang baik terhadap situasi dan keseimbangan antara penggunaan sumber daya internal dan eksternal - demi kepentingan efisiensi ekonomi dan proses.