Tantangan
Salah satu tugas besar aplikasi untuk menyimpan dan menganalisis pembelian adalah untuk mencari produk yang identik atau sangat dekat dalam database, yang berisi nama produk yang bervariasi dan tidak dapat dipahami yang diperoleh dari tanda terima. Ada dua jenis permintaan input:
- Nama spesifik dengan singkatan, yang hanya dapat dipahami oleh kasir di supermarket lokal, atau pembeli yang keranjingan.
- Kueri bahasa alami yang dimasukkan oleh pengguna dalam string pencarian.
Permintaan jenis pertama, sebagai aturan, berasal dari produk dalam cek itu sendiri, ketika pengguna perlu menemukan produk yang lebih murah. Tugas kami adalah memilih analog produk yang paling mirip dari cek di toko-toko lain di dekatnya. Penting untuk memilih merek produk yang paling tepat dan, jika mungkin, volume.
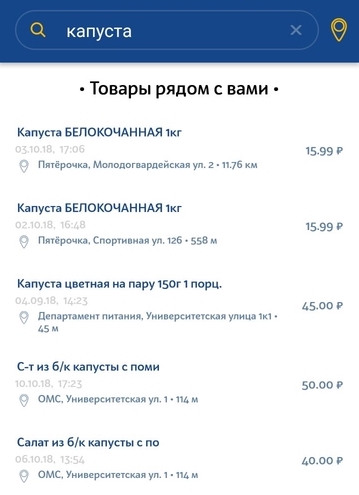
Jenis permintaan kedua adalah permintaan pengguna sederhana untuk mencari produk tertentu di toko terdekat. Permintaan dapat berupa deskripsi produk yang sangat umum dan tidak unik. Mungkin ada sedikit penyimpangan dari permintaan. Misalnya, jika pengguna mencari susu 3,2%, dan dalam database kami hanya 2,5% susu, maka kami masih ingin menunjukkan setidaknya hasil ini.
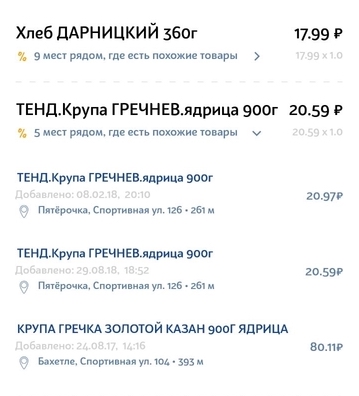
Fitur dataset - masalah yang harus dipecahkan
Informasi dalam tanda terima produk jauh dari ideal. Ini memiliki banyak singkatan tidak selalu jelas, kesalahan tata bahasa, kesalahan ketik, berbagai terjemahan, huruf Latin di tengah-tengah alfabet Cyrillic dan set karakter yang masuk akal hanya untuk organisasi internal di toko tertentu.
Misalnya, pure bayi apel-pisang dengan keju cottage dapat dengan mudah ditulis pada cek seperti ini:

Tentang teknologi
Elasticsearch adalah teknologi yang cukup populer dan terjangkau untuk mengimplementasikan pencarian. Ini adalah mesin pencari API JSON REST menggunakan Lucene dan ditulis dalam Java. Keunggulan utama Elastic adalah kecepatan, skalabilitas, dan toleransi kesalahan. Mesin serupa digunakan untuk pencarian kompleks dalam basis data dokumen. Misalnya, pencarian dengan mempertimbangkan morfologi bahasa atau pencarian berdasarkan koordinat geografis.
Petunjuk untuk eksperimen dan peningkatan
Untuk memahami bagaimana Anda dapat meningkatkan pencarian Anda, Anda perlu mengurai sistem pencarian menjadi komponen khusus komponennya. Untuk kasus kami, struktur sistem terlihat seperti ini.
- String input untuk pencarian melewati analyzer, yang dengan cara tertentu memecah string menjadi token - unit pencarian yang mencari di antara data yang juga disimpan sebagai token.
- Lalu ada pencarian langsung untuk token ini untuk setiap dokumen di database yang ada. Setelah menemukan token dalam dokumen tertentu (yang juga disajikan dalam database sebagai satu set token), relevansinya dihitung menurut model Kesamaan yang dipilih (kami akan menyebutnya Model Relevansi). Ini bisa berupa TF / IDF sederhana (Frekuensi Istilah - Frekuensi Dokumen Balik), atau bisa juga model yang lebih kompleks atau spesifik lainnya.
- Pada tahap berikutnya, jumlah poin yang dicetak oleh masing-masing token individu dikumpulkan dengan cara tertentu. Parameter agregasi diatur oleh semantik kueri. Contoh agregasi tersebut dapat berupa bobot tambahan untuk token tertentu (nilai tambah), ketentuan untuk keberadaan token wajib, dll. Hasil dari tahap ini adalah Skor - penilaian akhir dari relevansi dokumen tertentu dari database relatif terhadap permintaan awal.

Tiga komponen yang dapat dikonfigurasi secara terpisah dapat dibedakan dari perangkat pencarian, di mana masing-masingnya Anda dapat menyoroti cara dan metode peningkatan Anda sendiri.
- Analisis
- Model kesamaan
- Peningkatan waktu permintaan
Selanjutnya, kami akan mempertimbangkan setiap komponen secara individual dan menganalisis pengaturan parameter khusus yang membantu meningkatkan pencarian dalam hal nama produk.
Peningkatan waktu permintaan
Untuk memahami apa yang dapat kami tingkatkan dalam permintaan, kami memberikan contoh permintaan awal.
{ "query": { "multi_match": { "query": " 105", "type": "most_fields", "fields": ["name"], "minimum_should_match": "70%" } }, “size”: 100, “min_score”: 15 }
Kami menggunakan tipe kueri most_fields, karena kami memperkirakan perlunya kombinasi beberapa analis untuk bidang "nama produk". Jenis kueri ini memungkinkan Anda untuk menggabungkan hasil pencarian untuk atribut yang berbeda dari objek yang berisi teks yang sama, dianalisis dengan cara yang berbeda. Alternatif untuk pendekatan ini adalah dengan menggunakan kueri best_fields atau cross_fields, tetapi mereka tidak cocok untuk kasus kami, karena pencarian dihitung di antara berbagai atribut objek (misalnya: nama dan deskripsi). Kita dihadapkan dengan tugas memperhitungkan berbagai aspek dari satu atribut - nama produk.
Apa yang bisa dikonfigurasi:
- Kombinasi tertimbang dari berbagai analisis.
Awalnya, semua elemen pencarian memiliki bobot yang sama - dan karenanya, memiliki kepentingan yang sama. Ini dapat diubah dengan menambahkan parameter 'boost', yang mengambil nilai numerik. Jika parameter lebih besar dari 1, elemen pencarian akan memiliki dampak yang lebih besar pada hasil, masing-masing, kurang dari 1 - kurang. - Pemisahan analisis menjadi 'harus' dan 'harus'.
Yaitu, analisis tertentu harus sesuai, dan beberapa bersifat opsional, yaitu tidak cukup. Dalam kasus kami, penganalisis angka dapat menjadi contoh manfaat pemisahan semacam itu. Jika hanya nomor yang cocok dengan nama produk dalam permintaan dan nama produk dalam database, maka ini bukan kondisi yang cukup untuk kesetaraannya. Kami tidak ingin melihat produk seperti itu sebagai hasilnya. Pada saat yang sama, jika permintaannya adalah "krim 10%", maka kami ingin semua krim dengan lemak 10% memiliki keunggulan besar dibandingkan krim dengan lemak 20%. - Parameter minimum_should_match. Berapa banyak token yang harus cocok dengan permintaan dan dokumen dari database? Parameter ini bekerja bersama dengan jenis permintaan kami (most_fields) dan memeriksa jumlah minimum token yang cocok untuk setiap bidang (dalam kasus kami, untuk setiap penganalisa).
- Parameter Min_score. Dokumen penyaringan ambang batas dengan poin yang tidak mencukupi. Tangkapannya adalah tidak ada kecepatan maksimum yang diketahui. Skor yang dihasilkan tergantung pada permintaan spesifik dan pada basis data dokumen tertentu. Kadang-kadang bisa 150, dan kadang-kadang 2, tetapi kedua nilai ini akan berarti bahwa objek dari database relevan dengan permintaan. Kami tidak dapat membandingkan skor hasil kueri yang berbeda.
- Konstan
Setelah pemantauan yang cukup dari nilai akhir kecepatan untuk permintaan yang berbeda, Anda dapat mengidentifikasi batas perkiraan, setelah itu untuk sebagian besar permintaan hasilnya menjadi tidak pantas. Ini adalah keputusan yang paling mudah, tetapi juga yang paling bodoh, yang mengarah pada pencarian berkualitas rendah. - Cobalah untuk menganalisis skor yang diperoleh untuk permintaan tertentu setelah melakukan pencarian dengan minimum atau nol min_score.
Idenya adalah bahwa setelah beberapa saat, Anda dapat mengamati lompatan tajam ke arah penurunan kecepatan. Tetap hanya untuk menentukan lompatan ini agar berhenti tepat waktu. Pendekatan semacam itu akan bekerja dengan baik pada pertanyaan serupa:
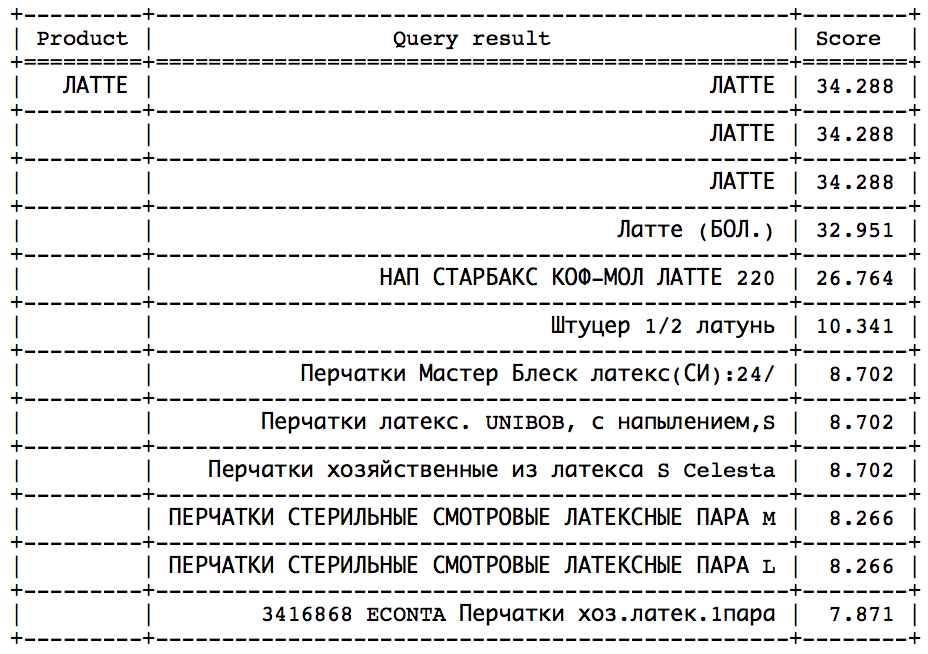
Lompatan ini dapat ditemukan dengan metode statistik. Namun, sayangnya, tidak dalam semua permintaan lompatan ini ada dan mudah diidentifikasi. - Hitung kecepatan ideal dan atur min_score sebagai fraksi tertentu dari ideal, yang dapat dilakukan dengan dua cara:
- Dari uraian terperinci dari perhitungan yang disediakan oleh Elastis sendiri ketika mengatur menjelaskan: parameter benar. Ini adalah tugas yang sulit, membutuhkan pemahaman menyeluruh tentang arsitektur permintaan dan algoritma komputasi yang digunakan oleh Elastic.
- Dengan sedikit trik. Kami menerima permintaan, menambahkan produk baru ke database kami dengan nama yang sama, melakukan pencarian dan mendapatkan kecepatan maksimum. Karena akan ada kecocokan 100% dalam nama, nilai yang dihasilkan akan ideal. Pendekatan inilah yang kami gunakan dalam sistem kami, karena kekhawatiran tentang tingginya biaya operasi ini sehubungan dengan waktu belum dikonfirmasi.
- Ubah algoritma penilaian, yang bertanggung jawab atas nilai relevansi akhir. Ini mungkin mempertimbangkan jarak ke toko (memberi lebih banyak poin ke produk yang lebih dekat), harga produk (memberikan lebih banyak poin ke produk dengan harga yang paling memungkinkan), dll.
Analisis
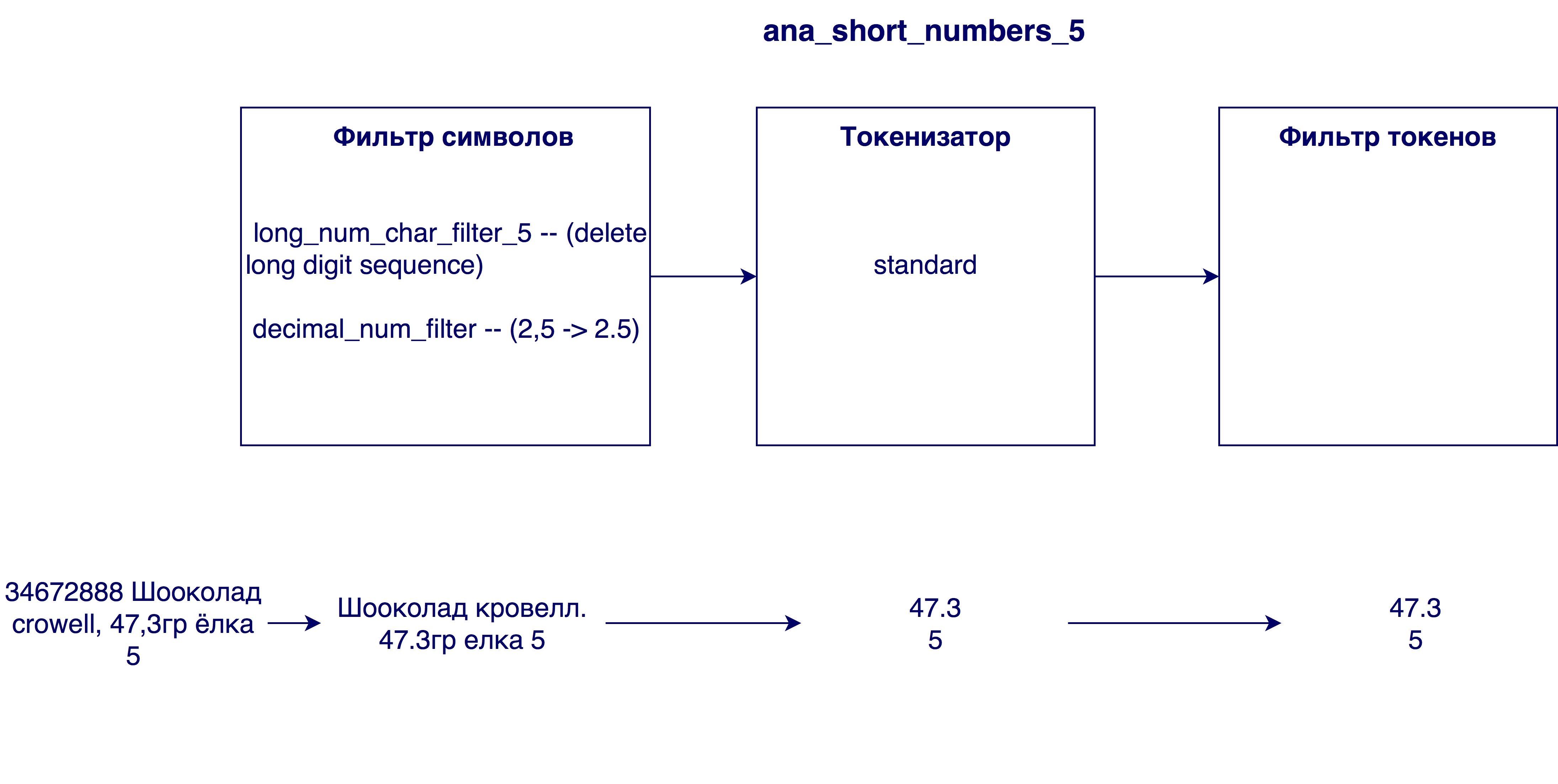
Penganalisa menganalisis string input dalam tiga tahap dan token output pada output - unit pencarian:

Pertama, perubahan terjadi pada level karakter string. Ini bisa mengganti, menghapus, atau menambahkan karakter ke string. Kemudian tokenizer mulai digunakan, yang dirancang untuk membagi string menjadi token. Token standar membagi string menjadi token sesuai dengan tanda baca. Pada langkah terakhir, token yang diterima difilter dan diproses.
Pertimbangkan variasi langkah apa yang bermanfaat dalam kasus kami.
Filter Char
- Menurut spesifikasi bahasa Rusia, akan berguna untuk memproses karakter seperti th dan e dan menggantinya dengan dan dan e, masing-masing.
- Lakukan transliterasi - transfer karakter satu tulisan dengan karakter tulisan lain. Dalam kasus kami, ini adalah pemrosesan nama yang ditulis dalam bahasa Latin atau dicampur dengan kedua huruf. Transliterasi dapat diimplementasikan menggunakan plug-in ( ICU Analysis Plugin ) sebagai filter token (yaitu, ia memproses bukan string asli, tetapi token terakhir). Kami memutuskan untuk menulis transliterasi kami, karena kami tidak cukup senang dengan algoritma di plugin. Idenya adalah untuk menggantikan kejadian set empat karakter (misalnya, "SHCH => u"), kemudian kejadian tiga karakter, dll. Urutan di mana filter simbol digunakan adalah penting karena hasilnya akan tergantung pada urutan.
- Ganti bahasa Latin c, dikelilingi oleh bahasa Cyrillic, dengan huruf Rusia. Kebutuhan untuk ini diidentifikasi setelah menganalisis nama-nama dalam database - sangat banyak nama dalam Cyrillic termasuk Latin c, yang berarti cyrillic c. Ketika seolah-olah nama tersebut sepenuhnya dalam bahasa Latin, maka Latin C berarti Cyrillic k atau c. Oleh karena itu, sebelum transliterasi, perlu untuk mengganti karakter c.
- Menghapus angka terlalu besar dari nama. Terkadang dalam nama produk ada nomor identifikasi internal (mis. 3387522 K.T. Maslo podsoln.raf. 0.9l), yang tidak memiliki arti dalam kasus umum.
- Mengganti koma dengan titik. Mengapa ini dibutuhkan? Sehingga angka-angkanya, misalnya, kandungan lemak susu 3.2 dan 3.2, adalah setara
Tokenizer
- Tokenizer standar - memisahkan garis sesuai dengan ruang dan tanda baca (misalnya, "twix extra 2" -> "twix", "extra", "2")
- EdgeNGram tokenizer - membagi setiap kata menjadi token dengan panjang tertentu (biasanya rentang angka), dimulai dengan karakter pertama (misalnya, untuk N = [3, 6]: "twix extra 2" -> "twee", "tweak", "Twix", "ex", "ext", "ext", "extra")
- Tokenizer untuk angka - memilih hanya angka dari string dengan mencari ekspresi reguler (mis., “Twix extra 2 4.5” -> “2”, “4.5”)
Filter tanda
- Filter huruf kecil
- Filter Stamming - melakukan algoritma stamming untuk setiap token. Berasal adalah untuk menentukan bentuk awal kata (misalnya, "beras" -> "beras")
- Analisis fonetik. Hal ini diperlukan untuk meminimalkan pengaruh kesalahan ketik dan berbagai cara penulisan kata yang sama pada hasil pencarian. Tabel menunjukkan berbagai algoritma yang tersedia untuk analisis fonetik dan hasil kerjanya dalam kasus-kasus bermasalah. Dalam kasus pertama (Shampoo / champagne / champignon / champignon) kesuksesan ditentukan oleh generasi pengkodean yang berbeda, sisanya - sama.

Model kesamaan
Model relevansi diperlukan untuk menentukan sejauh mana kebetulan satu token mempengaruhi relevansi objek dari database sehubungan dengan permintaan. Misalkan jika token dalam permintaan dan produk dari database cocok - ini tentu saja tidak buruk, tetapi ia mengatakan sedikit tentang kesesuaian produk dengan permintaan. Dengan demikian, kebetulan dari token yang berbeda membawa nilai yang berbeda. Untuk mempertimbangkan hal ini, diperlukan suatu model relevansi. Elastis menyediakan banyak model berbeda. Jika Anda benar-benar memahaminya, maka Anda dapat memilih model yang sangat spesifik dan cocok untuk kasus tertentu. Pilihannya dapat didasarkan pada jumlah kata yang sering digunakan (seperti token yang sama untuk), penilaian tentang pentingnya token panjang (lebih lama berarti lebih baik? Lebih buruk? Tidak masalah?), Hasil apa yang ingin kita lihat di bagian akhir, dll. Contoh model yang diusulkan dalam Elastic dapat berupa TF-IDF (model paling sederhana dan paling mudah dipahami), Okapi BM25 (TF-IDF yang disempurnakan, model default), Divergensi dari keacakan, Divergensi dari independensi, dll. Setiap model juga memiliki opsi yang dapat disesuaikan. Setelah beberapa percobaan dengan model, model default Okapi BM25 menunjukkan hasil terbaik, tetapi dengan parameter yang berbeda dari yang telah ditentukan.
Menggunakan kategori
Selama bekerja dengan pencarian, informasi tambahan yang sangat penting tentang produk - kategorinya - menjadi tersedia. Anda dapat membaca lebih lanjut tentang bagaimana kami menerapkan kategorisasi dalam artikel tersebut. Seperti yang saya pahami, saya makan banyak permen, atau klasifikasi barang dengan memeriksa aplikasi . Sampai saat itu, kami mendasarkan pencarian kami hanya pada perbandingan nama produk, sekarang menjadi mungkin untuk membandingkan kategori permintaan dan produk dalam database.
Opsi yang memungkinkan untuk menggunakan informasi ini adalah kecocokan wajib dalam bidang kategori (diformat sebagai filter hasil), keuntungan tambahan dalam bentuk poin untuk barang dengan kategori yang sama (seperti dalam kasus angka) dan menyortir hasil berdasarkan kategori (pencocokan pertama, lalu yang lainnya). Untuk kasus kami, opsi terakhir bekerja paling baik. Ini karena algoritma kategorisasi kami terlalu bagus untuk menggunakan metode kedua, dan tidak cukup baik untuk menggunakan metode pertama. Kami cukup percaya diri dalam algoritme dan menginginkan pencocokan kategori menjadi keuntungan besar. Dalam hal menambahkan poin tambahan ke kecepatan (metode kedua), barang dengan kategori yang sama akan naik daftar, tetapi masih akan kehilangan beberapa barang yang lebih cocok dengan nama. Namun, metode pertama juga tidak cocok untuk kita, karena kesalahan dalam kategorisasi masih dimungkinkan. Terkadang permintaan mungkin mengandung informasi yang tidak cukup untuk menentukan kategori dengan benar, atau ada terlalu sedikit produk dalam kategori ini dalam radius langsung dari pengguna. Dalam hal ini, kami masih ingin menampilkan hasil dengan kategori yang berbeda, tetapi masih relevan dengan nama produk.
Metode kedua juga baik karena tidak "merusak" kecepatan produk sebagai hasil pencarian, dan memungkinkan Anda untuk terus menggunakan kecepatan minimum yang dihitung tanpa hambatan.
Implementasi spesifik dari pengurutan dapat dilihat dalam permintaan akhir.
Model akhir
Pemilihan model pencarian akhir termasuk generasi berbagai mesin pencari, penilaian dan perbandingan mereka. Paling sering, perbandingan didasarkan pada salah satu parameter. Misalkan dalam satu kasus tertentu kita perlu menghitung ukuran terbaik untuk tokenizer edgeNgram (yaitu, memilih rentang N yang paling efektif). Untuk melakukan ini, kami membuat mesin pencari yang sama dengan hanya satu perbedaan ukuran kisaran ini. Setelah itu, dimungkinkan untuk menentukan nilai terbaik untuk parameter ini.
Model dievaluasi menggunakan metrik nDCG (normalized discounted kumulative gain), metrik untuk menilai kualitas peringkat. Kueri yang telah ditentukan dikirim ke setiap model pencarian, setelah itu nDCG metrik dihitung berdasarkan hasil pencarian yang diterima.
Analisis yang memasuki model akhir:



Model default (Okapi - BM25) dengan parameter b = 0,5 dipilih sebagai model relevansi. Nilai standarnya adalah 0,75. Parameter ini menunjukkan sejauh mana panjang nama produk menormalkan variabel tf (frekuensi). Jumlah yang lebih kecil dalam kasus kami berfungsi lebih baik, karena nama panjang sangat sering tidak memengaruhi signifikansi satu kata. Artinya, kata "cokelat" dalam nama "cokelat dengan hazelnut hancur dalam paket 25 buah" tidak kehilangan nilainya dari kenyataan bahwa nama itu cukup panjang.
Kueri akhir terlihat seperti ini:
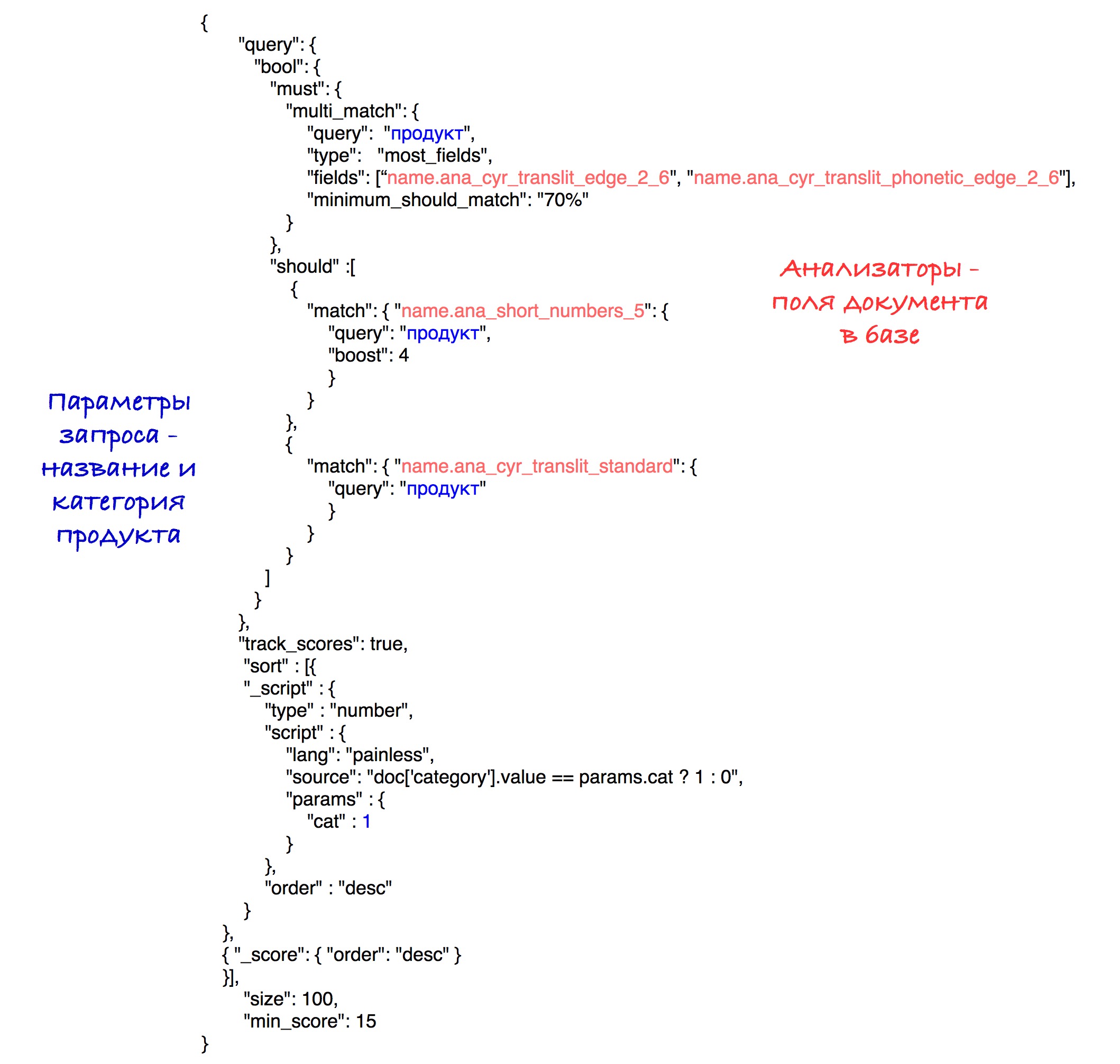
Secara eksperimental, kombinasi terbaik dari analisis dan bobot terungkap.
Sebagai hasil penyortiran, produk dengan kategori yang sama pergi ke awal hasil, dan kemudian semua yang lain. Penyortiran berdasarkan jumlah titik (kecepatan) disimpan dalam setiap subset.
Untuk kesederhanaan, ambang batas untuk kecepatan diatur ke 15 dalam permintaan ini, meskipun dalam sistem kami, kami menggunakan parameter terhitung yang dijelaskan sebelumnya.
Di masa depan
Ada pemikiran untuk meningkatkan pencarian dengan memecahkan salah satu masalah paling memalukan dalam algoritma kami, yaitu adanya sejuta dan satu cara berbeda untuk mempersingkat kata 5 huruf. Ini bisa diselesaikan dengan pemrosesan awal nama untuk mengungkapkan singkatan. Salah satu cara untuk mengatasinya adalah dengan mencoba membandingkan nama yang disingkat dari basis data kami dengan salah satu nama dari basis data dengan nama lengkap yang "benar". Keputusan ini memenuhi hambatan yang pasti, tetapi tampaknya perubahan yang menjanjikan.