Halo lagi!
Pada bulan Desember, kami akan memulai pelatihan untuk kelompok
Data Scientist berikutnya, sehingga ada lebih banyak pelajaran terbuka dan kegiatan lainnya. Sebagai contoh, beberapa hari yang lalu, sebuah webinar diadakan dengan nama panjang "Feature Engineering pada contoh dataset Titanic klasik". Itu dilakukan oleh
Alexander Sizov , pengembang berpengalaman, Ph.D., seorang ahli dalam pembelajaran Machine / Deep, dan peserta dalam berbagai proyek internasional komersial terkait dengan kecerdasan buatan dan analisis data.
Pelajaran terbuka memakan waktu sekitar satu setengah jam. Selama webinar, guru berbicara tentang memilih fitur, mengubah data sumber (pengkodean, penskalaan), mengatur parameter, melatih model, dan banyak lagi. Selama pelajaran, para peserta ditunjukkan sebuah Notebook Jupyter. Untuk bekerja, kami menggunakan data terbuka dari platform
Kaggle (
set data klasik tentang Titanic, yang darinya banyak orang mulai mengenal Data Science). Di bawah ini kami menawarkan video dan transkrip acara sebelumnya, dan di
sini Anda dapat mengambil presentasi dan kode di laptop Jupiter.
Pemilihan Fitur
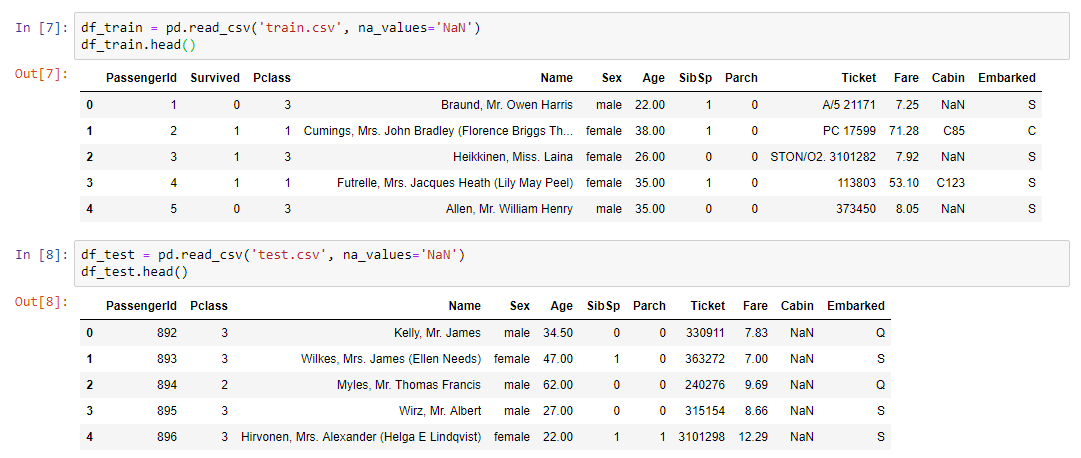
Tema itu dipilih, meski klasik, tetapi masih sedikit suram. Secara khusus, perlu untuk memecahkan masalah klasifikasi biner dan untuk memprediksi dari data yang tersedia apakah penumpang akan selamat atau tidak. Data itu sendiri dibagi menjadi dua sampel Pelatihan dan Tes. Variabel kunci adalah Kelangsungan Hidup (selamat / tidak selamat; 0 = Tidak, 1 = Ya).
Input data pelatihan:
- kelas tiket
- umur dan jenis kelamin penumpang;
- status perkawinan (apakah ada kerabat di atas kapal);
- harga tiket;
- nomor kabin;
- pelabuhan embarkasi.
Seperti yang Anda lihat, jenis-jenis variabel berbeda: numerik, teks. Dari kaleidoskop ini, perlu untuk membentuk dataset untuk pelatihan model yang akan datang.
Kami merangkum:
- train.csv - set pelatihan - set data pelatihan. Jawabannya diketahui di dalamnya - survival - tanda biner 0 (tidak bertahan) / 1 (selamat);
- test.csv - test set - set data uji. Jawabannya tidak diketahui. Ini adalah sampel untuk dikirim ke platform kaggle untuk menghitung metrik kualitas model;
- gender_submission.csv adalah contoh format data yang akan dikirim ke kaggle.
Algoritma kerja
- Pekerjaan berlangsung secara bertahap:
- Analisis data dari train.csv.
- Menangani nilai yang hilang.
- Scaling.
- Pengkodean fitur kategorikal.
- Membangun model dan memilih parameter, memilih model terbaik pada data yang dikonversi dari train.csv.
- Fiksasi dan model metode transformasi.
- Menerapkan konversi yang sama ke test.csv menggunakan pipeline.
- Penerapan model pada test.csv.
- Menyimpan file hasil aplikasi dalam format yang sama seperti di gender_submission.csv.
- Mengirim hasil ke platform kaggle.
Bagian praktis dari webinarHal pertama yang perlu dilakukan adalah membaca dataset dan menampilkan data kami di layar:
Untuk analisis data, perpustakaan profiling sedikit diketahui, tetapi agak berguna digunakan:
pandas_profiling.ProfileReport(df_train)Lebih lanjut tentang profilPerpustakaan ini melakukan semua yang dapat dilakukan secara apriori tanpa mengetahui detail tentang data. Misalnya, menampilkan statistik pada data (berapa banyak variabel dan jenisnya, berapa baris, nilai yang hilang, dll.). Selain itu, statistik terpisah untuk setiap variabel diberikan dengan minimum dan maksimum, grafik distribusi dan parameter lainnya.
Seperti yang Anda ketahui, untuk membuat model yang baik, Anda perlu mempelajari proses yang kami coba simulasikan, dan memahami apa saja atribut utama. Selain itu, jauh dari selalu dalam data kami ada segala yang dibutuhkan, dan, lebih tepatnya, hampir tidak pernah di dalamnya ada segala yang diperlukan, sepenuhnya menentukan dan menentukan proses kami. Sebagai aturan, kita selalu perlu menggabungkan sesuatu, mungkin menambahkan fitur tambahan yang tidak disajikan dalam dataset (misalnya, ramalan cuaca). Ini untuk memahami proses yang kita butuhkan analisis data, yang dapat dilakukan dengan menggunakan perpustakaan profil.
Nilai yang HilangLangkah selanjutnya adalah memecahkan masalah nilai yang hilang, karena dalam kebanyakan kasus data tidak sepenuhnya terisi.
Solusi berikut tersedia untuk masalah ini:
- hapus baris dengan nilai yang hilang (perlu diingat bahwa Anda dapat kehilangan beberapa nilai penting);
- hapus tanda (relevan jika ada terlalu sedikit data di dalamnya);
- ganti nilai yang hilang dengan sesuatu yang lain (median, rata-rata ...).
Contoh konversi sederhana menggunakan metode fillna, yang menetapkan nilai-nilai variabel median hanya sel-sel yang tidak diisi:

Selain itu, guru menunjukkan contoh menggunakan Imputer dan pipa.
Penskalaan FiturPengoperasian model dan keputusan akhir tergantung pada skala fitur. Faktanya adalah bahwa itu bukan fakta bahwa fitur apa pun yang memiliki skala lebih besar lebih penting daripada fitur yang memiliki skala lebih kecil. Itu sebabnya model perlu mengirimkan fitur yang diskalakan secara identik, yaitu, memiliki bobot yang sama untuk model.
Ada beberapa teknik penskalaan yang berbeda, namun, format pelajaran terbuka memungkinkan kami untuk mempertimbangkan hanya dua di antaranya secara lebih rinci:
 Kombinasi Fitur
Kombinasi FiturKombinasi fitur yang ada menggunakan operasi aritmatika (jumlah, perkalian, pembagian) memungkinkan Anda untuk mendapatkan fitur apa pun yang membuat model lebih efisien. Ini tidak selalu berhasil, dan kami tidak tahu kombinasi mana yang akan memberikan efek yang diinginkan, tetapi latihan menunjukkan bahwa masuk akal untuk mencoba. Lebih mudah untuk menerapkan transformasi fitur menggunakan pipa.
CodingJadi, kami memiliki data dari berbagai jenis: numerik dan teks. Saat ini, sebagian besar model di pasar tidak dapat berfungsi dengan data teks. Akibatnya, semua tanda kategorikal (tekstual) harus dikonversi ke representasi numerik, yang digunakan untuk pengkodean.
Pengkodean label . Ini adalah mekanisme yang diimplementasikan dalam kerangka banyak perpustakaan yang dapat dipanggil dan diterapkan:

Pengkodean label memberikan pengidentifikasi unik untuk setiap nilai unik. Minus - kami memperkenalkan pemesanan ke variabel tertentu yang tidak dipesan, yang tidak baik.
OneHotEncoder. Nilai unik dari variabel teks diperluas dalam bentuk kolom yang ditambahkan ke data sumber, di mana setiap kolom adalah variabel biner dalam bentuk 0 dan 1. Pendekatan ini bebas dari kelemahan pengkodean Label, tetapi memiliki minusnya sendiri: jika ada banyak nilai unik, kami menambahkan terlalu banyak kolom dan dalam beberapa kasus metode ini tidak dapat diterapkan (dataset tumbuh terlalu banyak).
Pelatihan modelSetelah melakukan langkah-langkah di atas, pipa terakhir dikompilasi dengan satu set semua operasi yang diperlukan. Sekarang cukup untuk mengambil dataset sumber dan menerapkan pipeline yang dihasilkan untuk data ini menggunakan operasi fit_transform:
x_train = vec.fit_transform(df_train)Hasilnya, kami mendapatkan dataset x_train, yang siap digunakan dalam model. Satu-satunya hal yang harus dilakukan adalah memisahkan nilai variabel target kami sehingga kami dapat melakukan pelatihan.
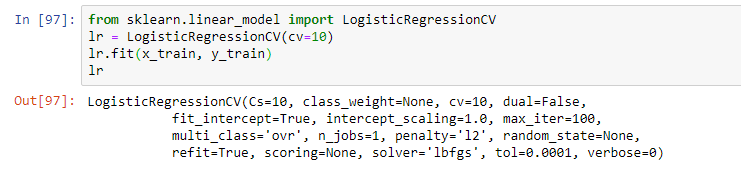
Selanjutnya, pilih model. Sebagai bagian dari webinar, guru mengusulkan regresi logistik sederhana. Model dilatih menggunakan operasi fit, menghasilkan model dalam bentuk regresi logistik dengan parameter tertentu:
Namun, dalam praktiknya, beberapa model biasanya digunakan yang tampaknya paling efektif. Dan solusi terakhir sering merupakan kombinasi dari model-model ini menggunakan teknik penumpukan dan pendekatan lain untuk model ansambel (menggunakan beberapa model dalam model hybrid yang sama).
Setelah pelatihan, model dapat diterapkan pada data uji, mengevaluasi kualitasnya dalam kerangka beberapa metrik. Dalam kasus kami, kualitas dalam akurasi_score adalah 0,8:

Ini berarti bahwa pada data yang diperoleh variabel diprediksi dengan benar dalam 80% kasus. Setelah menerima hasil pelatihan, kami dapat meningkatkan model (jika akurasi tidak memuaskan), atau melanjutkan langsung ke perkiraan.
Ini adalah topik utama dari pelajaran, tetapi guru berbicara lebih detail tentang fitur model dalam tugas yang berbeda dan menjawab pertanyaan dari hadirin. Jadi, jika Anda tidak ingin ketinggalan apa pun, tonton webinar lengkapnya jika Anda tertarik dengan topik ini.
Seperti biasa, kami menunggu komentar dan pertanyaan Anda yang dapat Anda tinggalkan di sini atau meminta mereka ke
Alexander dengan pergi kepadanya pada
hari terbuka.