Membuat tiket dalam manajemen proyek dan sistem pelacakan tugas, masing-masing dari kita senang melihat perkiraan persyaratan keputusan atas banding kami.
Saat menerima aliran tiket masuk, seseorang / tim perlu mengaturnya dalam prioritas dan waktu, yang akan diperlukan untuk menyelesaikan setiap banding.
Semua ini memungkinkan Anda untuk merencanakan waktu Anda lebih efektif untuk kedua belah pihak.
Di bawah potongan, saya akan berbicara tentang bagaimana saya menganalisis dan melatih model ML yang memprediksi waktu yang dibutuhkan untuk menyelesaikan tiket yang dikeluarkan untuk tim kami.
Saya sendiri bekerja untuk posisi SRE di sebuah tim bernama LAB. Kami menerima panggilan dari kedua pengembang dan QA mengenai penerapan lingkungan pengujian baru, pembaruan mereka ke versi rilis terbaru, solusi untuk berbagai masalah yang muncul, dan banyak lagi. Tugas-tugas ini cukup heterogen dan, secara logis, membutuhkan waktu yang berbeda untuk diselesaikan. Ada tim kami selama beberapa tahun dan selama waktu ini basis permintaan yang baik berhasil terkumpul. Saya memutuskan untuk menganalisis pangkalan ini dan atas dasar itu, dengan bantuan pembelajaran mesin, membuat model yang akan menangani prediksi waktu penutupan yang memungkinkan dari sebuah banding (tiket).
Namun, dalam pekerjaan kami, kami menggunakan JIRA, model yang saya sajikan dalam artikel ini tidak memiliki tautan ke produk tertentu - bukan masalah untuk mendapatkan informasi yang diperlukan dari basis data apa pun.
Jadi, mari kita beralih dari kata-kata ke perbuatan.
Analisis data awal
Kami memuat semua yang kami butuhkan dan menampilkan versi paket yang digunakan.
Kode sumberimport warnings warnings.simplefilter('ignore') %matplotlib inline import matplotlib.pyplot as plt import pandas as pd import numpy as np import datetime from nltk.corpus import stopwords from sklearn.model_selection import train_test_split from sklearn.metrics import mean_absolute_error, mean_squared_error from sklearn.neighbors import KNeighborsRegressor from sklearn.linear_model import LinearRegression from datetime import time, date for package in [pd, np, matplotlib, sklearn, nltk]: print(package.__name__, 'version:', package.__version__)
pandas version: 0.23.4 numpy version: 1.15.0 matplotlib version: 2.2.2 sklearn version: 0.19.2 nltk version: 3.3
Unduh data dari file csv. Ini berisi informasi tentang tiket yang ditutup selama 1,5 tahun terakhir. Sebelum menulis data ke file, mereka sedikit diproses terlebih dahulu. Misalnya, koma dan titik telah dihapus dari bidang teks dengan deskripsi. Namun, ini hanya pemrosesan awal dan di masa depan teks akan dihapus lebih lanjut.
Mari kita lihat apa yang ada di kumpulan data kami. Secara total, 10783 tiket masuk ke dalamnya.
Penjelasan Lapangan| Dibuat | Tanggal dan waktu pembuatan tiket |
| Terselesaikan | Tanggal dan waktu penutupan tiket |
| Resolution_time | Jumlah menit yang berlalu antara membuat dan menutup tiket. Ini dianggap sebagai waktu kalender, karena perusahaan memiliki kantor di berbagai negara, bekerja di zona waktu yang berbeda dan tidak ada waktu tetap untuk seluruh departemen. |
| Engineer_N | Nama "kode" insinyur (agar tidak secara tidak sengaja memberikan informasi pribadi atau rahasia di masa depan, akan ada banyak data "dikodekan" dalam artikel, yang sebenarnya hanya diganti nama). Bidang-bidang ini berisi jumlah tiket dalam mode “sedang berlangsung” pada saat penerimaan masing-masing tiket pada tanggal yang ditentukan. Saya akan membahas bidang-bidang ini secara terpisah menjelang akhir artikel, karena mereka layak mendapat perhatian ekstra. |
| Ditugaskan | Karyawan yang terlibat dalam menyelesaikan masalah. |
| Jenis Issue_type | Jenis tiket. |
| Lingkungan | Nama lingkungan kerja pengetesan untuk tiket yang dibuat (itu bisa berarti lingkungan tertentu atau lokasi secara keseluruhan, misalnya, pusat data). |
| Prioritas | Prioritas tiket. |
| Jenis pekerjaan | Jenis pekerjaan yang diharapkan untuk tiket ini (menambah atau menghapus server, memperbarui lingkungan, bekerja dengan pemantauan, dll.) |
| Deskripsi | Deskripsi |
| Ringkasan | Judul tiket. |
| Pengamat | Jumlah orang yang "menonton" tiket, mis. mereka menerima pemberitahuan email untuk setiap aktivitas di tiket. |
| Voting | Jumlah orang yang "memilih" tiket, dengan demikian menunjukkan kepentingannya dan minat mereka terhadap tiket tersebut. |
| Reporter | Orang yang mengeluarkan tiket. |
| Engineer_N_vacation | Apakah sang insinyur sedang berlibur pada saat mengeluarkan tiket. |
df.info()
<class 'pandas.core.frame.DataFrame'> Index: 10783 entries, ENV-36273 to ENV-49164 Data columns (total 37 columns): Created 10783 non-null object Resolved 10783 non-null object Resolution_time 10783 non-null int64 engineer_1 10783 non-null int64 engineer_2 10783 non-null int64 engineer_3 10783 non-null int64 engineer_4 10783 non-null int64 engineer_5 10783 non-null int64 engineer_6 10783 non-null int64 engineer_7 10783 non-null int64 engineer_8 10783 non-null int64 engineer_9 10783 non-null int64 engineer_10 10783 non-null int64 engineer_11 10783 non-null int64 engineer_12 10783 non-null int64 Assignee 10783 non-null object Issue_type 10783 non-null object Environment 10771 non-null object Priority 10783 non-null object Worktype 7273 non-null object Description 10263 non-null object Summary 10783 non-null object Watchers 10783 non-null int64 Votes 10783 non-null int64 Reporter 10783 non-null object engineer_1_vacation 10783 non-null int64 engineer_2_vacation 10783 non-null int64 engineer_3_vacation 10783 non-null int64 engineer_4_vacation 10783 non-null int64 engineer_5_vacation 10783 non-null int64 engineer_6_vacation 10783 non-null int64 engineer_7_vacation 10783 non-null int64 engineer_8_vacation 10783 non-null int64 engineer_9_vacation 10783 non-null int64 engineer_10_vacation 10783 non-null int64 engineer_11_vacation 10783 non-null int64 engineer_12_vacation 10783 non-null int64 dtypes: float64(12), int64(15), object(10) memory usage: 3.1+ MB
Secara total, kami memiliki 10 bidang "objek" (yaitu, berisi nilai teks) dan 27 bidang numerik.
Pertama-tama, segera cari emisi dalam data kami. Seperti yang Anda lihat, ada tiket seperti itu di mana waktu keputusan diperkirakan dalam jutaan menit. Ini jelas bukan informasi yang relevan, data tersebut hanya akan mengganggu pembangunan model. Mereka sampai di sini, karena pengumpulan data dari JIRA dilakukan oleh kueri di bidang Diselesaikan, dan bukan Dibuat. Karenanya, tiket-tiket yang ditutup dalam 1,5 tahun terakhir tiba di sini, tetapi bisa saja dibuka jauh lebih awal. Sudah waktunya untuk menyingkirkan mereka. Kami akan membuang tiket yang dibuat sebelum 1 Juni 2017. Kami akan memiliki 9493 tiket tersisa.
Adapun alasannya - saya pikir dalam setiap proyek Anda dapat dengan mudah menemukan permintaan yang telah berkeliaran cukup lama karena berbagai keadaan dan seringkali ditutup bukan dengan menyelesaikan masalah itu sendiri, tetapi dengan "berakhirnya undang-undang pembatasan".
Kode sumber df[['Created', 'Resolved', 'Resolution_time']].sort_values('Resolution_time', ascending=False).head()

Kode sumber df = df[df['Created'] >= '2017-06-01 00:00:00'] print(df.shape)
(9493, 33)
Jadi, mari kita mulai melihat apa yang menurut kami menarik dalam data kami. Untuk memulai, mari cari tahu yang paling sederhana - lingkungan paling populer di antara tiket kami, "reporter" paling aktif dan sejenisnya.
Kode sumber df.describe(include=['object'])

Kode sumber df['Environment'].value_counts().head(10)
Environment_104 442 ALL 368 Location02 367 Environment_99 342 Location03 342 Environment_31 322 Environment_14 254 Environment_1 232 Environment_87 227 Location01 202 Name: Environment, dtype: int64
Kode sumber df['Reporter'].value_counts().head()
Reporter_16 388 Reporter_97 199 Reporter_04 147 Reporter_110 145 Reporter_133 138 Name: Reporter, dtype: int64
Kode sumber df['Worktype'].value_counts()
Support 2482 Infrastructure 1655 Update environment 1138 Monitoring 388 QA 300 Numbers 110 Create environment 95 Tools 62 Delete environment 24 Name: Worktype, dtype: int64
Kode sumber df['Priority'].value_counts().plot(kind='bar', figsize=(12,7), rot=0, fontsize=14, title=' ');
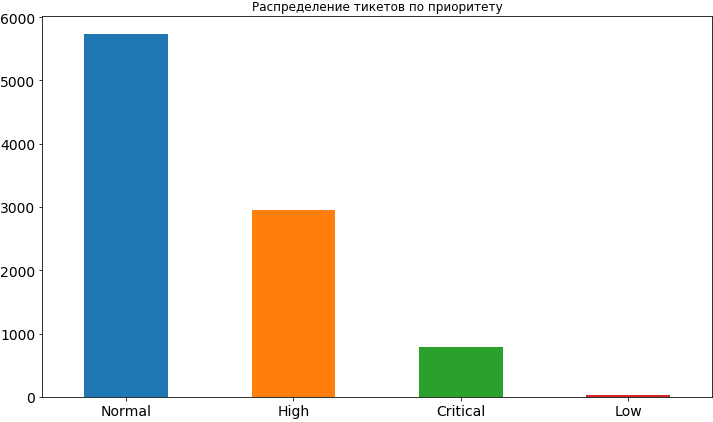
Ya, sesuatu yang sudah kita pelajari. Paling sering, prioritas untuk tiket adalah normal, sekitar 2 kali lebih tinggi dan bahkan kurang kritis. Sangat jarang ada prioritas rendah, tampaknya orang takut untuk mengeksposnya, percaya bahwa dalam kasus ini akan menggantung untuk waktu yang lama dalam antrian dan waktu untuk keputusannya mungkin tertunda. Kemudian, ketika kita sudah akan membangun model dan menganalisis hasilnya, kita akan melihat bahwa ketakutan seperti itu mungkin tidak berdasar, karena prioritas rendah benar-benar memengaruhi kerangka waktu untuk tugas dan, tentu saja, tidak ke arah percepatan.
Dari kolom untuk lingkungan yang paling populer dan reporter yang paling aktif, kami melihat bahwa Reporter_16 memiliki margin yang lebar, dan Environment_104 menjadi yang pertama di lingkungan tersebut. Bahkan jika Anda belum menebak, saya akan memberi tahu Anda sedikit rahasia - reporter ini berasal dari tim yang bekerja di lingkungan khusus ini.
Mari kita lihat seperti apa lingkungan dari tiket paling kritis ini.
Kode sumber df[df['Priority'] == 'Critical']['Environment'].value_counts().index[0]
'Environment_91'
Sekarang kami akan mencetak informasi tentang berapa banyak tiket dengan prioritas berbeda berasal dari lingkungan "kritis" yang sama.
Kode sumber df[df['Environment'] == df[df['Priority'] == 'Critical']['Environment'].value_counts().index[0]]['Priority'].value_counts()
High 62 Critical 57 Normal 46 Name: Priority, dtype: int64
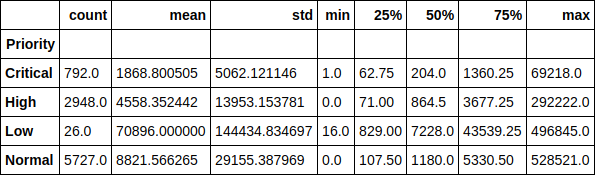
Mari kita lihat waktu pelaksanaan tiket dalam konteks prioritas. Sebagai contoh, sangat menyenangkan untuk memperhatikan bahwa waktu tempuh rata-rata tiket dengan prioritas rendah adalah lebih dari 70 ribu menit (hampir 1,5 bulan). Ketergantungan waktu eksekusi tiket pada prioritasnya juga mudah dilacak.
Kode sumber df.groupby(['Priority'])['Resolution_time'].describe()
Atau di sini sebagai grafik, nilai median. Seperti yang Anda lihat, gambarnya tidak banyak berubah, oleh karena itu, emisi tidak terlalu mempengaruhi distribusi.
Kode sumber df.groupby(['Priority'])['Resolution_time'].median().sort_values().plot(kind='bar', figsize=(12,7), rot=0, fontsize=14);

Sekarang mari kita lihat waktu solusi tiket rata-rata untuk masing-masing insinyur, tergantung pada berapa banyak tiket yang dimiliki insinyur pada waktu itu. Faktanya, grafik-grafik ini, yang mengejutkan saya, tidak menunjukkan satu gambar pun. Untuk beberapa orang, waktu eksekusi meningkat karena tiket saat ini dalam pekerjaan meningkat, sedangkan untuk beberapa hubungan ini adalah sebaliknya. Bagi sebagian orang, kecanduan sama sekali tidak dapat dilacak.
Namun, melihat ke depan lagi, saya akan mengatakan bahwa kehadiran fitur ini dalam dataset meningkatkan akurasi model lebih dari 2 kali dan pasti ada efek pada waktu eksekusi. Kami tidak melihatnya. Dan model melihat.
Kode sumber engineers = [i.replace('_vacation', '') for i in df.columns if 'vacation' in i] cols = 2 rows = int(len(engineers) / cols) fig, axes = plt.subplots(nrows=rows, ncols=cols, figsize=(16,24)) for i in range(rows): for j in range(cols): df.groupby(engineers[i * cols + j])['Resolution_time'].mean().plot(kind='bar', rot=0, ax=axes[i, j]).set_xlabel('Engineer_' + str(i * cols + j + 1)) del cols, rows, fig, axes
Gambar panjang sebagai hasilnya Mari kita membuat matriks kecil interaksi berpasangan dari fitur berikut: waktu solusi tiket, jumlah suara dan jumlah pengamat. Dengan bonus diagonal, kami memiliki distribusi setiap atribut.
Dari yang menarik, orang bisa melihat ketergantungan mengurangi waktu solusi tiket pada semakin banyak pengamat. Terlihat juga bahwa orang tidak terlalu aktif dalam menggunakan suara.
Kode sumber pd.scatter_matrix(df[['Resolution_time', 'Watchers', 'Votes']], figsize=(15, 15), diagonal='hist');
Jadi, kami melakukan analisis awal kecil data, melihat ketergantungan yang ada antara atribut target, yang merupakan waktu yang dibutuhkan untuk menyelesaikan tiket, dan tanda-tanda seperti jumlah suara untuk tiket, jumlah "pengamat" di belakangnya dan prioritasnya. Kami melanjutkan.
Membangun model. Tanda-tanda bangunan
Inilah saatnya untuk beralih membangun model itu sendiri. Tapi pertama-tama, kita perlu membawa fitur kita ke dalam bentuk yang dapat dimengerti oleh model. Yaitu menguraikan tanda-tanda kategorikal menjadi vektor jarang dan menyingkirkan kelebihan. Misalnya, kita tidak perlu bidang dengan waktu tiket dibuat dan ditutup dalam model, serta bidang yang Ditugaskan, karena kami akhirnya akan menggunakan model ini untuk memprediksi waktu pelaksanaan tiket yang belum ditetapkan kepada siapa pun ("terbunuh").
Tanda target, seperti yang baru saja saya sebutkan, adalah waktu untuk menyelesaikan masalah bagi kami, jadi kami menganggapnya sebagai vektor terpisah dan juga menghapusnya dari kumpulan data umum. Selain itu, beberapa bidang kosong karena fakta bahwa wartawan tidak selalu mengisi bidang deskripsi saat mengeluarkan tiket. Dalam kasus ini, panda menetapkan nilainya ke NaN, kami hanya menggantinya dengan string kosong.
Kode sumber y = df['Resolution_time'] df.drop(['Created', 'Resolved', 'Resolution_time', 'Assignee'], axis=1, inplace=True) df['Description'].fillna('', inplace=True) df['Summary'].fillna('', inplace=True)
Kami menguraikan tanda-tanda kategorikal menjadi vektor jarang (Pengodean satu-panas ). Sampai kami menyentuh bidang dengan deskripsi dan daftar isi tiket. Kami akan menggunakannya sedikit berbeda. Beberapa nama reporter berisi [X]. Jadi JIRA menandai karyawan tidak aktif yang tidak lagi bekerja di perusahaan. Saya memutuskan untuk meninggalkan mereka di antara tanda-tanda, meskipun dimungkinkan untuk menghapus data dari mereka, karena di masa depan, ketika menggunakan model, kita tidak akan melihat tiket dari karyawan ini.
Kode sumber def create_df(dic, feature_list): out = pd.DataFrame(dic) out = pd.concat([out, pd.get_dummies(out[feature_list])], axis = 1) out.drop(feature_list, axis = 1, inplace = True) return out X = create_df(df, df.columns[df.dtypes == 'object'].drop(['Description', 'Summary'])) X.columns = X.columns.str.replace(' \[X\]', '')
Dan sekarang kita akan berurusan dengan bidang deskripsi di tiket. Kami akan bekerja dengannya dalam salah satu cara yang mungkin paling sederhana - kami akan mengumpulkan semua kata yang digunakan dalam tiket kami, menghitung yang paling populer di antara mereka, membuang kata-kata "ekstra" - kata-kata yang jelas tidak dapat mempengaruhi hasilnya, seperti, misalnya, kata "tolong" (tolong - semua komunikasi di JIRA dilakukan secara ketat dalam bahasa Inggris), yang merupakan yang paling populer. Ya, ini orang-orang sopan kami.
Kami juga menghapus " kata-kata berhenti ", menurut perpustakaan nltk, dan lebih jelas menghapus teks dari karakter yang tidak perlu. Biarkan saya mengingatkan Anda bahwa ini adalah hal paling sederhana yang dapat dilakukan dengan teks. Kami tidak " mencap " kata-kata, Anda juga dapat menghitung N-gram kata yang paling populer, tetapi kami akan membatasi diri untuk itu.
Kode sumber all_words = np.concatenate(df['Description'].apply(lambda s: s.split()).values) stop_words = stopwords.words('english') stop_words.extend(['please', 'hi', '-', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '(', ')', '=', '{', '}']) stop_words.extend(['h3', '+', '-', '@', '!', '#', '$', '%', '^', '&', '*', '(for', 'output)']) stop_symbols = ['=>', '|', '[', ']', '#', '*', '\\', '/', '->', '>', '<', '&'] words_series = pd.Series(list(all_words)) del all_words words_series = words_series[~words_series.isin(stop_words)] for symbol in stop_symbols: words_series = words_series[~words_series.str.contains(symbol, regex=False, na=False)]
Setelah semua ini, kami mendapatkan objek panda. Seri berisi semua kata yang digunakan. Mari kita lihat yang paling populer dari mereka dan ambil 50 pertama dari daftar untuk digunakan sebagai tanda. Untuk setiap tiket, kita akan melihat apakah kata ini digunakan dalam deskripsi, dan jika demikian, maka letakkan 1 di kolom yang sesuai, jika tidak 0.
Kode sumber usefull_words = list(words_series.value_counts().head(50).index) print(usefull_words[0:10])
['error', 'account', 'info', 'call', '{code}', 'behavior', 'array', 'update', 'env', 'actual']
Sekarang dalam kumpulan data umum kami, kami akan membuat kolom terpisah untuk kata-kata yang telah kami pilih. Pada ini, Anda dapat menyingkirkan bidang deskripsi itu sendiri.
Kode sumber for word in usefull_words: X['Description_' + word] = X['Description'].str.contains(word).astype('int64') X.drop('Description', axis=1, inplace=True)
Kami akan melakukan hal yang sama untuk bidang judul tiket.
Kode sumber all_words = np.concatenate(df['Summary'].apply(lambda s: s.split()).values) words_series = pd.Series(list(all_words)) del all_words words_series = words_series[~words_series.isin(stop_words)] for symbol in stop_symbols: words_series = words_series[~words_series.str.contains(symbol, regex=False, na=False)] usefull_words = list(words_series.value_counts().head(50).index) for word in usefull_words: X['Summary_' + word] = X['Summary'].str.contains(word).astype('int64') X.drop('Summary', axis=1, inplace=True)
Mari kita lihat apa yang kita dapatkan di matriks fitur X dan vektor respons y.
((9493, 1114), (9493,))
Sekarang kita akan membagi data ini menjadi sampel pelatihan (pelatihan) dan sampel uji dalam rasio persentase 75/25. Total kami memiliki 7119 contoh yang akan kami latih, dan 2374 di mana kami akan mengevaluasi model kami. Dan dimensi matriks atribut kami meningkat menjadi 1114 karena peletakan tanda-tanda kategorikal.
Kode sumber X_train, X_holdout, y_train, y_holdout = train_test_split(X, y, test_size=0.25, random_state=17) print(X_train.shape, X_holdout.shape)
((7119, 1114), (2374, 1114))
Kami melatih model.
Regresi linier
Mari kita mulai dengan model paling ringan dan paling akurat (paling tidak diharapkan) - regresi linier. Kami akan mengevaluasi baik dengan akurasi pada data pelatihan, dan oleh sampel tertunda (ketidaksepakatan) - data bahwa model tidak melihat.
Dalam kasus regresi linier, model lebih atau kurang dapat diterima menunjukkan dirinya pada data pelatihan, tetapi akurasi pada sampel yang tertunda sangat rendah. Bahkan jauh lebih buruk daripada memprediksi rata-rata yang biasa untuk semua tiket.
Di sini Anda perlu istirahat sejenak dan memberi tahu bagaimana model mengevaluasi kualitas menggunakan metode skornya.
Penilaian dilakukan dengan koefisien determinasi :
Dimana Apakah hasilnya diprediksi oleh model a - nilai rata-rata untuk seluruh sampel.
Kami tidak akan terlalu memikirkan koefisien sekarang. Kami hanya mencatat bahwa itu tidak sepenuhnya mencerminkan keakuratan model yang menarik minat kami. Oleh karena itu, pada saat yang sama, kami akan menggunakan Mean Absolute Error (MAE) untuk mengevaluasi dan mengandalkannya.
Kode sumber lr = LinearRegression() lr.fit(X_train, y_train) print('R^2 train:', lr.score(X_train, y_train)) print('R^2 test:', lr.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(lr.predict(X_train), y_train)) print('MAE test', mean_absolute_error(lr.predict(X_holdout), y_holdout))
R^2 train: 0.3884389470220214 R^2 test: -6.652435243123196e+17 MAE train: 8503.67256637168 MAE test: 1710257520060.8154
Peningkatan Gradien
Nah, di mana tanpa itu, tanpa meningkatkan gradien? Mari kita coba latih modelnya dan lihat apa yang terjadi. Kami akan menggunakan XGBoost terkenal untuk ini. Mari kita mulai dengan pengaturan hyperparameter standar.
Kode sumber import xgboost xgb = xgboost.XGBRegressor() xgb.fit(X_train, y_train) print('R^2 train:', xgb.score(X_train, y_train)) print('R^2 test:', xgb.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(xgb.predict(X_train), y_train)) print('MAE test', mean_absolute_error(xgb.predict(X_holdout), y_holdout))
R^2 train: 0.5138516547636054 R^2 test: 0.12965507684512545 MAE train: 7108.165167471887 MAE test: 8343.433260957032
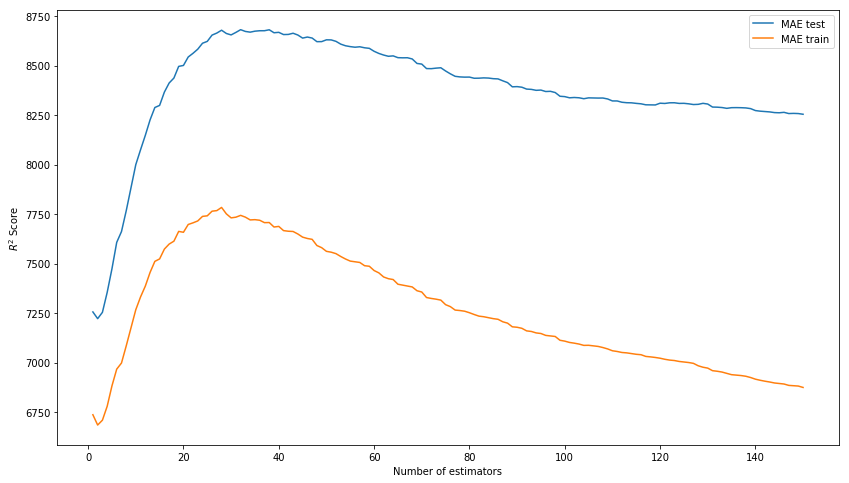
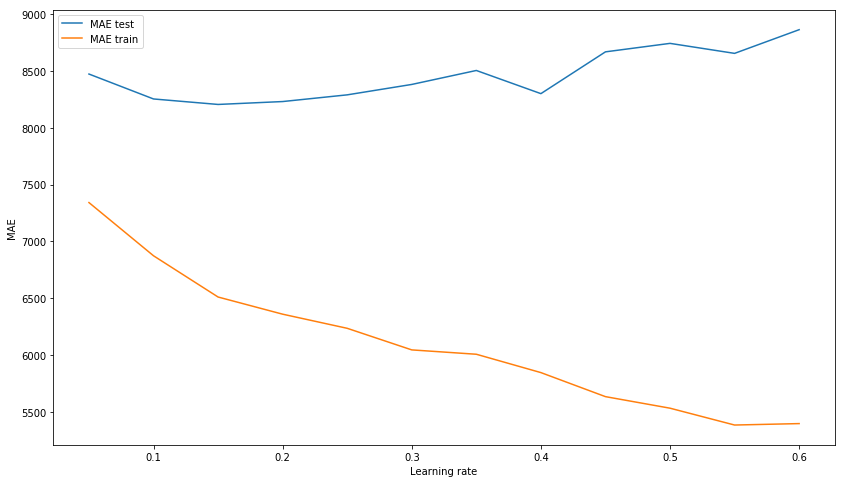
Hasilnya di luar kotak tidak lagi buruk. Mari kita coba memodelkan model dengan memilih hyperparameters: n_estimators, learning_rate dan max_depth. Sebagai hasilnya, kami memikirkan nilai 150, 0,1, dan 3, masing-masing, sebagai menunjukkan hasil terbaik pada sampel uji dengan tidak adanya overtraining model pada data pelatihan.
Kami memilih n_estimators* Alih-alih R ^ 2 Skor dalam gambar harus MAE.
xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(1,151) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Number of estimators') plt.ylabel('$R^2 Score$') plt.legend(loc='best') plt.show();
Kami memilih learning_rate xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(0.05, 0.65, 0.05) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Learning rate') plt.ylabel('MAE') plt.legend(loc='best') plt.show();
Kami memilih max_depth xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(1, 11) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=0.1, max_depth=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Maximum depth') plt.ylabel('MAE') plt.legend(loc='best') plt.show();

Sekarang kita akan melatih model dengan hyperparameters yang dipilih.
Kode sumber xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=0.1, max_depth=3) xgb.fit(X_train, y_train) print('R^2 train:', xgb.score(X_train, y_train)) print('R^2 test:', xgb.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(xgb.predict(X_train), y_train)) print('MAE test', mean_absolute_error(xgb.predict(X_holdout), y_holdout))
R^2 train: 0.6745967150462303 R^2 test: 0.15415143189670344 MAE train: 6328.384400466232 MAE test: 8217.07897417256
Hasil akhir dengan parameter yang dipilih dan pentingnya fitur visualisasi - pentingnya tanda sesuai dengan model. Yang pertama adalah jumlah pengamat tiket, tapi kemudian 4 insinyur langsung pergi. Dengan demikian, waktu kerja tiket bisa sangat dipengaruhi oleh pekerjaan seorang insinyur. Dan logis bahwa waktu luang beberapa di antara mereka lebih penting. Setidaknya karena tim memiliki insinyur senior dan menengah (kami tidak memiliki junior di tim). Ngomong-ngomong, lagi-lagi secara rahasia, insinyur di tempat pertama (bar oranye) benar-benar salah satu yang paling berpengalaman di antara seluruh tim. Selain itu, keempat insinyur ini memiliki awalan senior di posisi mereka. Ternyata model itu sekali lagi mengkonfirmasi ini.
Kode sumber features_df = pd.DataFrame(data=xgb.feature_importances_.reshape(1, -1), columns=X.columns).sort_values(axis=1, by=[0], ascending=False) features_df.loc[0][0:10].plot(kind='bar', figsize=(16, 8), rot=75, fontsize=14);
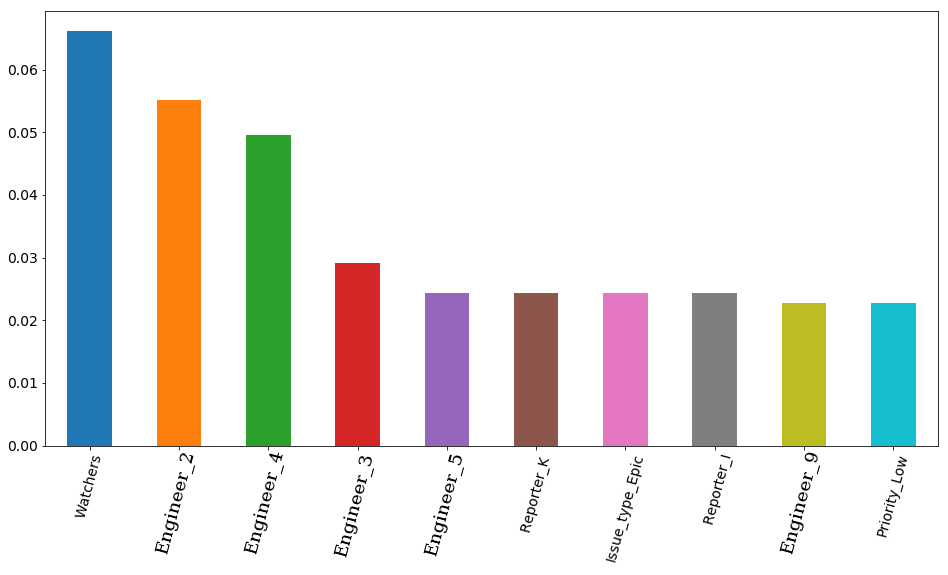
Jaringan saraf
Tetapi kami tidak akan berhenti pada satu peningkatan gradien dan mencoba untuk melatih jaringan saraf, lebih tepatnya perceptron Multilayer, jaringan saraf distribusi langsung yang sepenuhnya terhubung. Kali ini kita tidak akan memulai dengan pengaturan standar hyperparameters, seperti di perpustakaan sklearn, yang akan kita gunakan, secara default hanya ada satu lapisan tersembunyi dengan 100 neuron dan selama pelatihan model memberikan peringatan tentang ketidaksepakatan untuk iterasi standar 200. Kami segera menggunakan 3 lapisan tersembunyi dengan 300, 200 dan 100 neuron, masing-masing.
Sebagai hasilnya, kami melihat bahwa model tersebut tidak terlalu terlatih pada sampel pelatihan, yang, bagaimanapun, tidak mencegahnya menunjukkan hasil yang layak pada sampel uji. Hasil ini sedikit lebih rendah daripada hasil peningkatan gradien.
Kode sumber from sklearn.neural_network import MLPRegressor nn = MLPRegressor(random_state=17, hidden_layer_sizes=(300, 200 ,100), alpha=0.03, learning_rate='adaptive', learning_rate_init=0.0005, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) print('R^2 train:', nn.score(X_train, y_train)) print('R^2 test:', nn.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(nn.predict(X_train), y_train)) print('MAE test', mean_absolute_error(nn.predict(X_holdout), y_holdout))
R^2 train: 0.9771443840549647 R^2 test: -0.15166596239118246 MAE train: 1627.3212161350423 MAE test: 8816.204561947616
Mari kita lihat apa yang dapat kita capai dengan mencoba memilih arsitektur terbaik dari jaringan kita. , , 200 , , . .
plt.figure(figsize=(14, 8)) for i in [(500,), (750,), (1000,), (500,500)]: nn = MLPRegressor(random_state=17, hidden_layer_sizes=i, alpha=0.03, learning_rate='adaptive', learning_rate_init=0.0005, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) plt.plot(nn.loss_curve_, label=str(i)); plt.xlabel('Iterations') plt.ylabel('MSE') plt.legend(loc='best') plt.show()

. 3 10 .
plt.figure(figsize=(14, 8)) for i in [(500,300,100), (80, 60, 60, 60, 40, 40, 40, 40, 20, 10), (80, 60, 60, 40, 40, 40, 20, 10), (150, 100, 80, 60, 40, 40, 20, 10), (200, 100, 100, 100, 80, 80, 80, 40, 20), (80, 40, 20, 20, 10, 5), (300, 250, 200, 100, 80, 80, 80, 40, 20)]: nn = MLPRegressor(random_state=17, hidden_layer_sizes=i, alpha=0.03, learning_rate='adaptive', learning_rate_init=0.001, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) plt.plot(nn.loss_curve_, label=str(i)); plt.xlabel('Iterations') plt.ylabel('MSE') plt.legend(loc='best') plt.show()
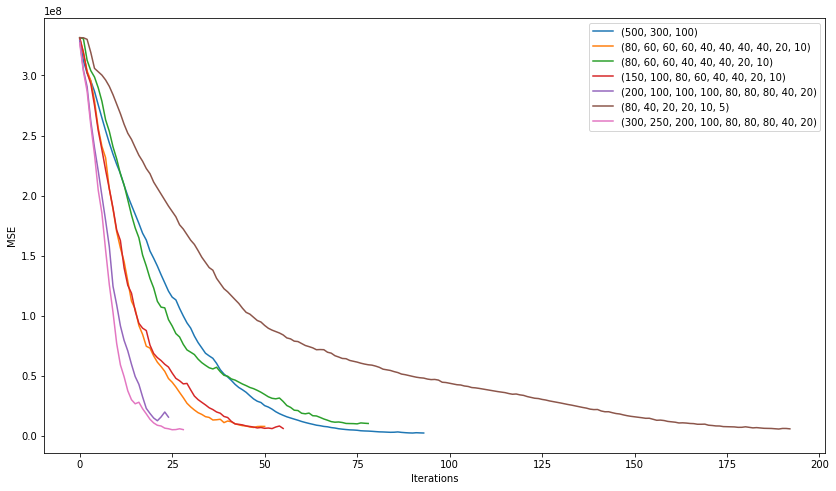
"" (200, 100, 100, 100, 80, 80, 80, 40, 20) :
2506
7351
, , . learning rate .
nn = MLPRegressor(random_state=17, hidden_layer_sizes=(200, 100, 100, 100, 80, 80, 80, 40, 20), alpha=0.1, learning_rate='adaptive', learning_rate_init=0.007, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) print('R^2 train:', nn.score(X_train, y_train)) print('R^2 test:', nn.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(nn.predict(X_train), y_train)) print('MAE test', mean_absolute_error(nn.predict(X_holdout), y_holdout))
R^2 train: 0.836204705204337 R^2 test: 0.15858607391959356 MAE train: 4075.8553476632796 MAE test: 7530.502826043687
, . , . , , .
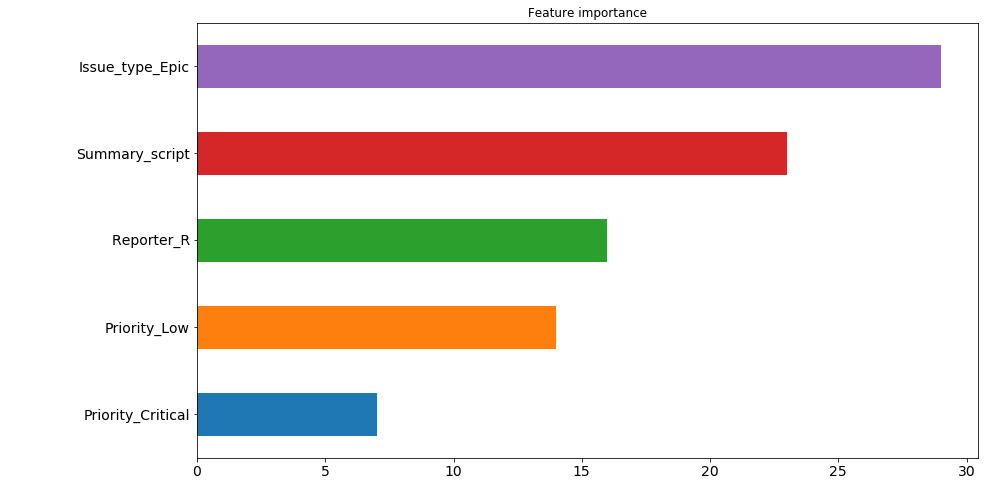
. : ( , 200 ). , "" . , 30 200 , issue type: Epic . , .. , , , , . 4 5 . , . , .
— 9 , . , , , .
pd.Series([X_train.columns[abs(nn.coefs_[0][:,i]).argmax()] for i in range(nn.hidden_layer_sizes[0])]).value_counts().head(5).sort_values().plot(kind='barh', title='Feature importance', fontsize=14, figsize=(14,8));
. Mengapa 7530 8217. (7530 + 8217) / 2 = 7873, , , ? , . , . , 7526.
, kaggle . , , .
nn_predict = nn.predict(X_holdout) xgb_predict = xgb.predict(X_holdout) print('NN MSE:', mean_squared_error(nn_predict, y_holdout)) print('XGB MSE:', mean_squared_error(xgb_predict, y_holdout)) print('Ensemble:', mean_squared_error((nn_predict + xgb_predict) / 2, y_holdout)) print('NN MAE:', mean_absolute_error(nn_predict, y_holdout)) print('XGB MSE:', mean_absolute_error(xgb_predict, y_holdout)) print('Ensemble:', mean_absolute_error((nn_predict + xgb_predict) / 2, y_holdout))
NN MSE: 628107316.262393 XGB MSE: 631417733.4224195 Ensemble: 593516226.8298339 NN MAE: 7530.502826043687 XGB MSE: 8217.07897417256 Ensemble: 7526.763569558157
? 7500 . Yaitu 5 . . . , .
( ):
((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values(ascending=False).head(10).values
[469132.30504392, 454064.03521379, 252946.87342439, 251786.22682697, 224012.59016987, 15671.21520735, 13201.12440327, 203548.46460229, 172427.32150665, 171088.75543224]
. , .
df.loc[((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values(ascending=False).head(10).index][['Issue_type', 'Priority', 'Worktype', 'Summary', 'Watchers']]
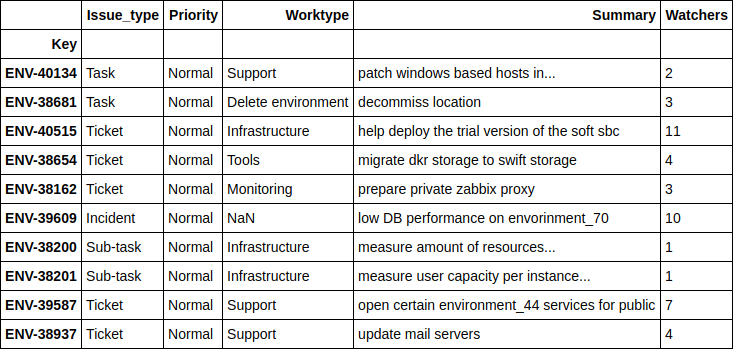
, - , . 4 .
, .
print(((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values().head(10).values) df.loc[((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values().head(10).index][['Issue_type', 'Priority', 'Worktype', 'Summary', 'Watchers']]
[ 1.24606014, 2.6723969, 4.51969139, 10.04159236, 11.14335444, 14.4951508, 16.51012874, 17.78445744, 21.56106258, 24.78219295]
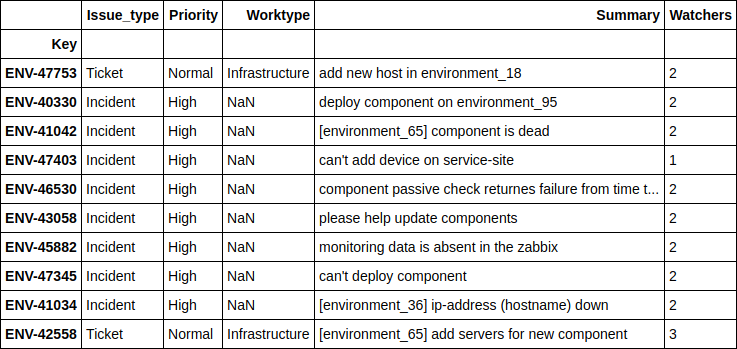
, , - , - . , , , .
Engineer
, 'Engineer', , , ? .
, 2 . , , , , . , , , "" , ( ) , , , . , " ", .
, . , , 12 , ( JQL JIRA):
assignee was engineer_N during (ticket_creation_date) and status was "In Progress"
10783 * 12 = 129396 , … . , , , .. 5 .
, , , , 2 . .
. SLO , .
, , ( : - , - , - ) , .