Mari kita buat prototipe reinforcement learning agent (RL) yang akan menguasai keterampilan perdagangan.
Mengingat bahwa implementasi prototipe berfungsi dalam bahasa R, saya mendorong pengguna R dan programmer untuk mendekati ide-ide yang disajikan dalam artikel ini.
Ini adalah terjemahan dari artikel bahasa Inggris saya:
Dapatkah Reinforcement Learning Trade Stock? Implementasi dalam R.Saya ingin memperingatkan para pemburu kode bahwa dalam catatan ini hanya ada kode untuk jaringan saraf yang diadaptasi untuk R.Jika saya tidak membedakan diri saya dalam bahasa Rusia yang baik, tunjukkan kesalahan (teks disiapkan dengan bantuan penerjemah otomatis).
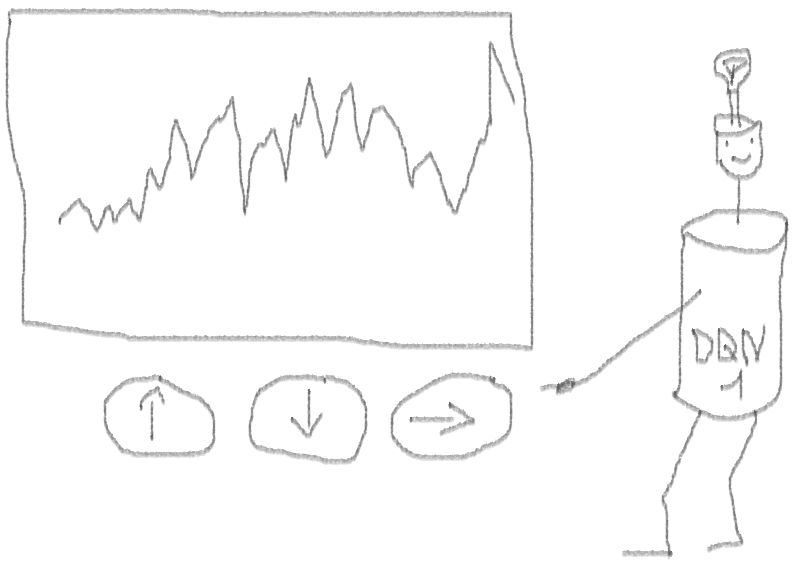
Pengantar masalah
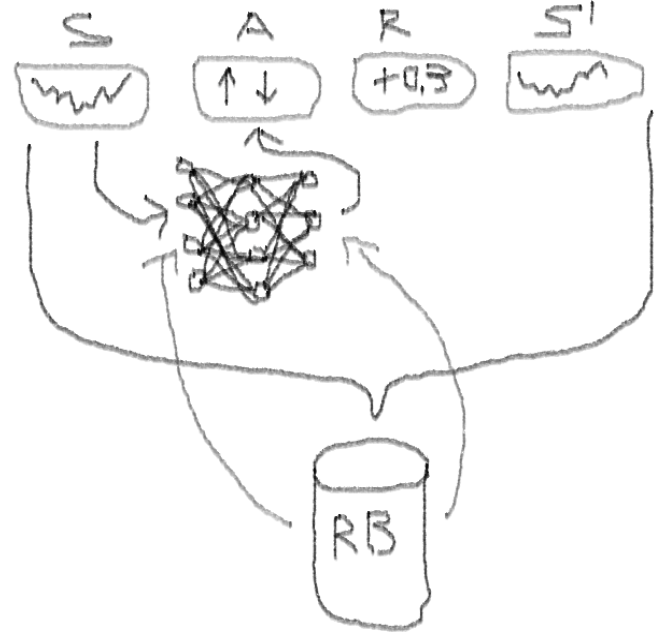
Saya menyarankan Anda untuk mulai menyelami topik ini dengan artikel ini:
DeepMindDia akan memperkenalkan Anda dengan gagasan untuk menggunakan Deep Q-Network (DQN) untuk memperkirakan fungsi nilai yang sangat penting dalam proses pengambilan keputusan Markov.
Saya juga merekomendasikan untuk masuk lebih jauh ke dalam matematika menggunakan cetakan buku ini oleh Richard S. Sutton dan Andrew J. Barto:
Reinforcement LearningDi bawah ini saya akan menyajikan versi diperpanjang dari DQN asli, yang mencakup lebih banyak ide yang membantu algoritma secara cepat dan efisien menyatu, yaitu:
Deep Double Duel Noisy NN dengan pemilihan prioritas dari buffer pemutaran pengalaman.
Apa yang membuat pendekatan ini lebih baik daripada DQN klasik?
- Ganda: ada dua jaringan, satu di antaranya dilatih, dan yang lainnya mengevaluasi nilai Q berikut
- Duel: Ada neuron yang jelas menghargai dan menguntungkan
- Bising: ada matriks kebisingan yang diterapkan pada bobot lapisan menengah, di mana rata-rata dan standar deviasi adalah bobot yang terlatih
- Prioritas pengambilan sampel: kumpulan pengamatan dari buffer pemutaran berisi contoh, yang karenanya pelatihan fungsi sebelumnya menghasilkan residu besar yang dapat disimpan dalam larik bantu.
Nah, bagaimana dengan perdagangan yang dilakukan oleh agen DQN? Ini adalah topik yang menarik.
Ada alasan mengapa ini menarik:
- Kebebasan mutlak untuk memilih representasi status, tindakan, penghargaan, dan arsitektur NN. Anda dapat memperkaya ruang masuk dengan segala sesuatu yang Anda anggap layak untuk dicoba, dari berita hingga saham dan indeks lainnya.
- Korespondensi dari logika perdagangan dengan logika pembelajaran penguatan adalah bahwa: agen melakukan tindakan diskrit (atau berkelanjutan), jarang dihargai (setelah transaksi ditutup atau periode berakhir), lingkungan dapat diamati sebagian dan mungkin berisi informasi tentang langkah-langkah selanjutnya, perdagangan adalah permainan episodik.
- Anda dapat membandingkan hasil DQN dengan beberapa tolok ukur, seperti indeks dan sistem perdagangan teknis.
- Agen dapat terus mempelajari informasi baru dan, dengan demikian, beradaptasi dengan aturan permainan yang berubah.
Agar tidak merentangkan materi, lihat kode NN ini, yang ingin saya bagikan, karena ini adalah salah satu bagian misterius dari seluruh proyek.
Kode R untuk jaringan neural nilai menggunakan Keras untuk membangun agen RL kami
Saya menggunakan sumber ini untuk mengadaptasi kode Python untuk bagian derau jaringan:
github repoJaringan saraf ini terlihat seperti ini:
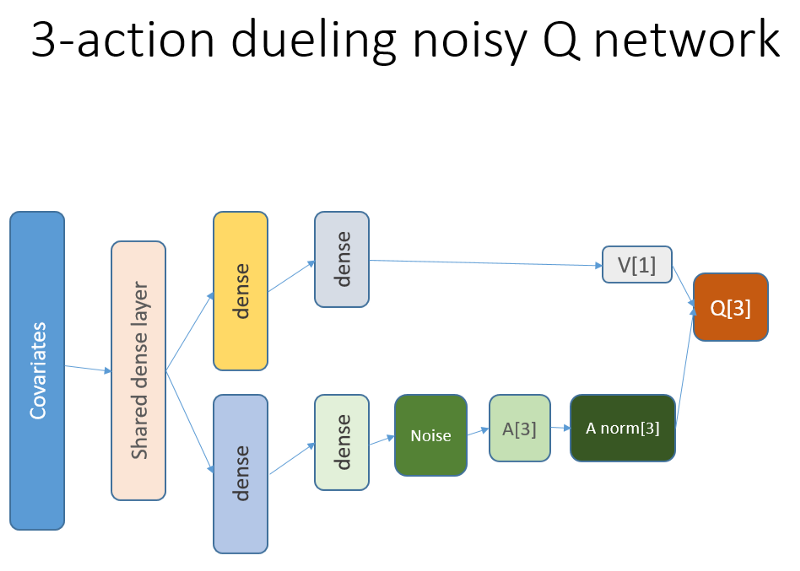
Ingatlah bahwa dalam arsitektur duel kita menggunakan persamaan (persamaan 1):
Q = A '+ V, di mana
A '= A - rata-rata (A);
Q = nilai tindakan negara;
V = nilai negara;
A = keuntungan.
Variabel lain dalam kode berbicara sendiri. Selain itu, arsitektur ini hanya baik untuk tugas tertentu, jadi jangan anggap remeh.
Sisa kode kemungkinan besar akan cukup umum untuk dipublikasikan, dan akan menarik bagi programmer untuk menulisnya sendiri.
Dan sekarang - percobaan. Pengujian pekerjaan agen dilakukan di kotak pasir, jauh dari kenyataan perdagangan di pasar langsung, dengan broker nyata.
Fase I
Kami menjalankan agen kami terhadap dataset sintetis. Biaya transaksi kami adalah 0,5:
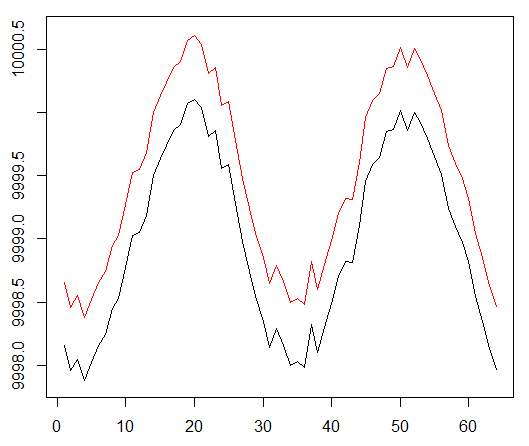
Hasilnya luar biasa. Rata-rata imbalan episodik maksimum dalam percobaan ini
harus 1,5.
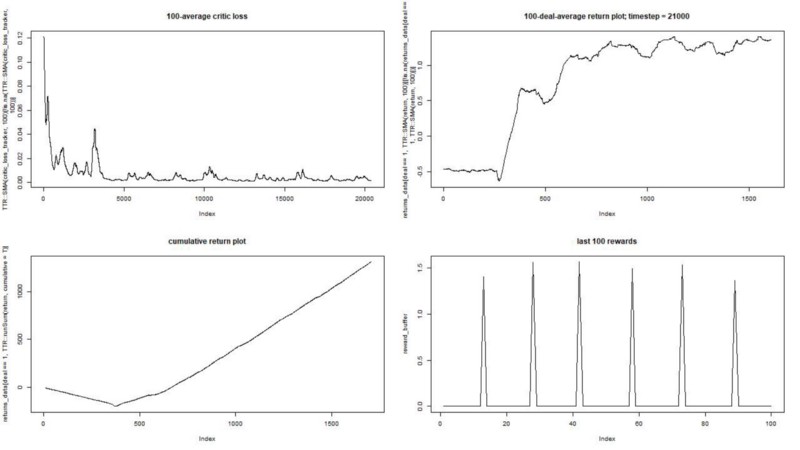
Kita melihat: kehilangan kritik (yang disebut jaringan nilai dalam pendekatan aktor-kritik), hadiah rata-rata untuk sebuah episode, akumulasi hadiah, contoh hadiah baru-baru ini.
Fase II
Kami mengajari agen kami simbol saham yang dipilih secara sewenang-wenang yang menunjukkan perilaku menarik: awal yang datar, pertumbuhan yang cepat di tengah dan akhir yang suram. Dalam kit pelatihan kami sekitar 4300 hari. Biaya transaksi ditetapkan pada 0,1 dolar AS (sengaja rendah); Hadiahnya adalah Laba / Rugi USD setelah menutup kesepakatan untuk membeli / menjual 1,0 saham.
Sumber:
finance.yahoo.com/quote/algn?ltr=1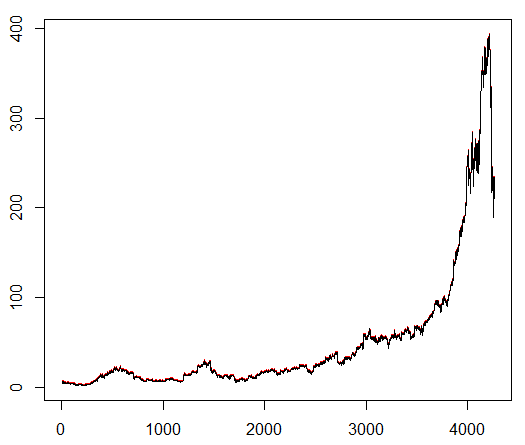 NASDAQ: ALGN
NASDAQ: ALGNSetelah menetapkan beberapa parameter (membiarkan arsitektur NN tetap sama), kami sampai pada hasil berikut:

Ternyata tidak buruk, karena pada akhirnya agen belajar untuk mendapat untung dengan menekan tiga tombol di konsolnya.
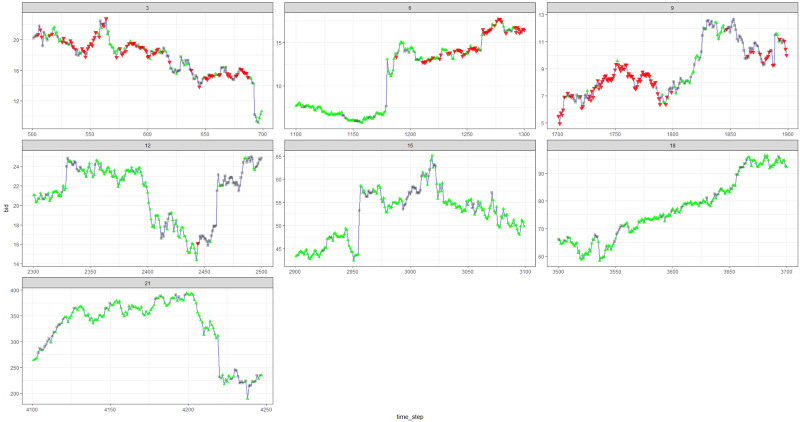 spidol merah = jual, spidol hijau = beli, spidol abu-abu = tidak melakukan apa-apa.
spidol merah = jual, spidol hijau = beli, spidol abu-abu = tidak melakukan apa-apa.Harap dicatat bahwa pada puncaknya, hadiah rata-rata per episode melebihi nilai transaksi realistis yang dapat ditemui dalam perdagangan nyata.
Sangat disayangkan bahwa saham jatuh seperti orang gila karena berita buruk ...
Pengamatan penutup
Berdagang dengan RL tidak hanya sulit, tetapi juga bermanfaat. Ketika robot Anda melakukannya lebih baik daripada Anda, saatnya untuk menghabiskan waktu pribadi Anda untuk mendapatkan pendidikan dan kesehatan.
Saya harap ini adalah perjalanan yang menarik untuk Anda. Jika Anda menyukai cerita ini, lambaikan tangan. Jika ada banyak minat, saya dapat melanjutkan dan menunjukkan kepada Anda bagaimana metode gradien kebijakan bekerja menggunakan bahasa R dan API Keras.
Saya juga ingin mengucapkan terima kasih kepada teman-teman saya yang tertarik pada jaringan saraf untuk saran mereka.
Jika Anda masih memiliki pertanyaan, saya selalu di sini.