Trolling matematika adalah apa yang akan saya bicarakan. Ini bukan beberapa trik peretas yang fashionable, melainkan ini adalah ekspresi artistik, teknologi cerdas yang lucu sehingga orang menganggap Anda bodoh. Sekarang saya akan memeriksa apakah laporan saya siap untuk ditampilkan di layar. Segalanya tampak berjalan baik, jadi saya bisa memperkenalkan diri.

Nama saya Frank Tu, dieja frank ^ 2 dan @franksquared di Twitter, karena Twitter juga memiliki beberapa jenis spammer bernama "frank 2". Saya mencoba menerapkan rekayasa sosial kepada mereka sehingga mereka menghapus akunnya, karena secara teknis itu adalah spam dan saya memiliki hak untuk menyingkirkannya sebagai klon saya. Tetapi ternyata, jika Anda memperlakukan mereka dengan jujur, mereka tidak membalas, karena meskipun permintaan saya untuk menghapus akun spammer, mereka tidak melakukan apa-apa dengan itu, jadi saya mengirim Twitter sialan ini ke neraka.
Banyak orang mengenali saya dengan topi saya. Saya bekerja di grup regional DefCon DC949 dan DC310. Saya juga bekerja dengan Rapid7, tetapi saya tidak bisa membicarakannya di sini tanpa menggunakan bahasa kotor, dan manajer saya tidak ingin saya bersumpah. Jadi, saya menyiapkan kinerja ini untuk DefCon dan saya akan memenuhi tenggat waktu 15 menit, meskipun ini adalah topik yang agak rumit. Ini pada dasarnya adalah presentasi standar yang berfokus pada rekayasa terbalik dan hal-hal lucu terkait.
Saat membahas topik ini di Twitter, dua kubu terbentuk. Seorang lelaki berkata, "Saya tidak tahu apa yang dibicarakan, sialan ini, tapi ini luar biasa!" Orang kedua dari Reddit melihat slide saya dan kesal karena tautan ke hal-hal yang tidak terkait dengan topik, saya marah karena topik yang serius seperti itu tidak sepenuhnya dibahas, jadi saya berharap presentasi saya memiliki "lebih banyak konten dan lebih sedikit sampah".

Karena itu, saya ingin fokus pada kutipan ini. Bukan masalah pribadi, kawan dari Reddit - Saya mengatakan ini tidak hanya jika dia hadir di ruangan ini, tetapi juga karena itu adalah kritik yang adil. Karena percakapan yang tidak mengandung cukup konten bermanfaat adalah pembicaraan kosong.
Topik pembicaraan saya adalah rutin standar untuk peretas, tetapi bagi saya tampaknya para pembicara biasanya tidak mencoba menyajikan informasi mereka dengan cara yang menghibur, bahkan jika mungkin, lebih menyukai kesimpulan yang kering dan terkebiri. "Ini IP, ini ESP, ini bagaimana kamu bisa melakukan exploit, ini" zero day "ku, sekarang bertepuk tangan!" - dan semua orang bertepuk tangan.
Terima kasih atas tepuk tangan, saya menghargainya! Menurut saya ada banyak hal menarik dalam materi saya, jadi pantas untuk dinyatakan dengan cara yang agak menghibur, yang akan saya coba lakukan.
Anda akan melihat sikap yang sangat dangkal terhadap ilmu komputer dan humor yang benar-benar kekanak-kanakan, jadi saya harap Anda menghargai apa yang akan saya tunjukkan di sini. Maaf jika Anda datang ke sini mencari percakapan serius.
Pada slide Anda melihat analisis ilmiah dari laporan terakhir saya membandingkan bagian dari pendekatan yang sepenuhnya ilmiah dan bagian dari "obat" yang menyediakan keamanan komputer.

Anda melihat bahwa ada lebih banyak "obat-obatan", tetapi Anda tidak perlu khawatir, sekarang bagian ilmu pengetahuan telah sedikit meningkat.

Jadi, beberapa waktu yang lalu, teman saya Merlin, duduk di sini di garis depan, menulis bot yang luar biasa berdasarkan pada skrip IRC Python, yang hanya menempati satu baris.
Ini adalah latihan yang sangat luar biasa untuk mempelajari pemrograman fungsional, yang sangat menyenangkan untuk dipusingkan. Anda cukup menambahkan satu fungsi ke fungsi lainnya dan mendapatkan kombinasi dari semua fungsi yang berbeda, dan semua ini digambarkan di layar sebagai gelombang pelangi, secara umum, ini adalah salah satu hal paling bodoh yang dapat Anda lakukan.
Saya pikir jika Anda menerapkan prinsip ini ke file biner? Saya tidak tahu dari mana ide ini berasal, tetapi ternyata luar biasa! Namun, saya ingin mengklarifikasi beberapa konsep dasar.
Ada kemungkinan bahwa guru matematika Anda menyajikan fungsi-fungsi ini jauh lebih rumit daripada yang sebenarnya.

Jadi, rumus f (x) sangat sederhana artinya, ia berfungsi seperti fungsi biasa. Anda memiliki X, Anda memiliki input, dan kemudian Anda mendapatkan X 7 kali, dan itu sama dengan nilai Anda. Dengan Python Anda dapat membuat suatu fungsi (lambda x: x * 7). Jika Anda ingin bekerja dengan Java - Maaf, saya harap Anda tidak ingin melakukan ini - maka Anda dapat melakukan sesuatu seperti:
public static int multiplyBySevenAndReturn(Integer x) { return x * 7; }
Anda tahu, fungsi matematika bahkan bisa jauh lebih rumit, tetapi hanya itu yang perlu kita ketahui tentang mereka saat ini.
Jika Anda melihat perakitan kode, Anda akan melihat bahwa instruksi JMP dan CALL tidak terikat dengan nilai tertentu, mereka bekerja dengan offset. Jika Anda menggunakan debugger, Anda dapat melihat bahwa JMP00401000 lebih seperti instruksi untuk "melompat beberapa byte ke depan" daripada instruksi khusus untuk melompat 5 atau 10 byte. Hal yang sama berlaku untuk fungsi CALL, kecuali itu mendorong sejumlah hal ke stack Anda. Pengecualian adalah kasus ketika Anda "menempel" alamat ke register, yaitu, Anda mengakses alamat tertentu. Segala sesuatu terjadi di sini dengan cara yang sangat berbeda. Setelah Anda mengaitkan alamat ke register dan melakukan sesuatu seperti CALL EAX, fungsi mengakses nilai spesifik di EAX. Hal yang sama berlaku untuk CALL [EAX] atau JMP [EAX] - itu hanya referensi EAX dan pergi ke alamat itu. Saat menggunakan debugger, Anda mungkin tidak dapat menentukan alamat spesifik mana yang diakses oleh CALL. Ini bisa menjadi masalah, jadi Anda harus mengetahui hal ini.
Mari kita lihat fitur lompatan pendek JMP PENDEK. Ini adalah instruksi khusus dalam arsitektur x86 yang memungkinkan Anda untuk menggunakan offset 1 byte alih-alih 4 byte, yang mengurangi ruang memori yang digunakan. Ini akan menjadi masalah nanti untuk semua manipulasi yang akan terjadi dengan instruksi individual. Penting untuk diingat bahwa JMP SHORT memiliki kisaran 256 byte. Namun, tidak ada yang namanya PANGGILAN PANGGILAN.

Sekarang pertimbangkan ilmu sihir komputer. Di tengah-tengah membuat slide ini, saya menyadari bahwa sebenarnya Anda dapat mendefinisikan perakitan sebagai ruang nol, yaitu, secara teknis tidak ada ruang kosong di antara setiap instruksi. Jika Anda melihat instruksi individual, Anda akan melihat bahwa masing-masing dieksekusi satu demi satu instruksi. Secara teknis, ini dapat ditafsirkan sebagai lompatan tanpa syarat ke instruksi berikutnya. Ini memberi kami ruang di antara setiap instruksi perakitan, sementara setiap instruksi terkait dengan lompatan tanpa syarat.
Jika Anda melihat contoh perakitan ini, omong-omong, ini adalah hal-hal yang sangat sederhana yang saya sarankan dekode dengan ASCII, jadi ini hanya seperangkat instruksi reguler.
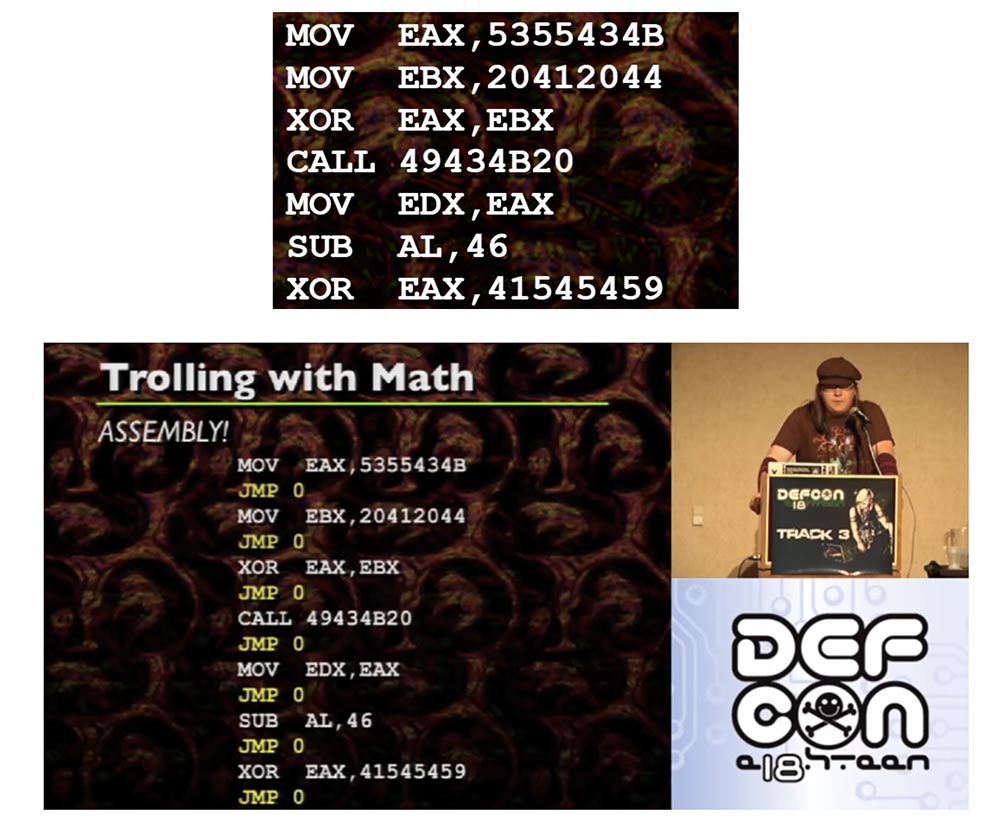
JMP 0s yang terletak di antara setiap instruksi adalah lompatan tanpa syarat yang biasanya tidak Anda lihat. Mereka saling mengikuti setelah setiap instruksi. Oleh karena itu, dimungkinkan untuk menempatkan setiap instruksi perakitan individual di lokasi memori yang arbitrer jika dan hanya jika setiap instruksi unit disertai dengan lompatan tanpa syarat ke instruksi berikutnya. Karena jika Anda mentransfer unit dan Anda perlu menggunakan kode yang sama seperti sebelumnya, Anda harus melampirkan lompatan tanpa syarat ke setiap instruksi.
Mari kita lihat lebih jauh. Array satu dimensi secara teknis dapat diartikan sebagai array dua dimensi, hanya membutuhkan sedikit matematika, baris atau sesuatu seperti itu, saya tidak akan mengatakannya dengan pasti, tetapi itu tidak terlalu sulit. Ini memberi kita kesempatan untuk menginterpretasikan lokasi dalam memori dalam bentuk kisi (x, y). Dalam kombinasi dengan interpretasi ruang kosong antara instruksi sebagai lompatan tanpa syarat yang dapat saling terkait, kita dapat secara harfiah menggambar instruksi. Ini luar biasa!
Untuk menerapkan ini dalam praktik, Anda perlu melakukan langkah-langkah berikut:
- bongkar setiap instruksi untuk mengetahui apa kode itu;
- Alokasikan tempat di memori yang jauh lebih besar dari ukuran set instruksi Saya biasanya memesan 10 kali lebih banyak memori daripada ukuran kode;
- untuk setiap instruksi, tentukan f (x);
- atur setiap instruksi ke lokasi yang sesuai (x, y) dalam memori;
- lampirkan lompatan tanpa syarat ke instruksi;
- tandai memori sebagai executable dan jalankan kodenya.
Sayangnya, banyak pertanyaan muncul di sini. Ini seperti dengan gravitasi, yang hanya bekerja dalam teori, tetapi dalam praktiknya kita melihat hal yang sama sekali berbeda. Karena pada kenyataannya x86 mengirim ke neraka instruksi JMP Anda, instruksi CALL, mengubah kode referensi-diri Anda, kode modifikasi diri yang menggunakan iterasi.

Mari kita mulai dengan instruksi JMP. Karena instruksi JMP bias, ketika ditempatkan di tempat yang sewenang-wenang, mereka tidak lagi menunjuk ke tempat Anda pikir mereka seharusnya menunjuk. JMP SINGKAT menemukan diri mereka dalam posisi yang sama. Secara tidak sengaja ditempatkan oleh fungsi Anda (x, y), mereka tidak akan menunjukkan apa yang Anda andalkan. Tetapi tidak seperti JMP panjang, JMP pendek lebih mudah untuk diperbaiki, terutama jika Anda berurusan dengan array satu dimensi. SHORT JMP mudah dikonversi ke JMP biasa, tetapi kemudian Anda harus mencari tahu apa yang telah menjadi offset baru.
Bekerja dengan JMP berbasis register masih sakit kepala, dan karena mereka membutuhkan offset yang ketat dan dapat dihitung pada saat runtime, tidak ada cara mudah untuk mengetahui ke mana mereka pergi. Untuk secara otomatis mendeteksi setiap register, Anda perlu menggunakan banyak pengetahuan dari teori kompilasi. Saat runtime, mungkin ada pointer fungsi, pointer kelas, dan sejenisnya. Benar, jika Anda tidak ingin melakukan pekerjaan ekstra untuk melakukan semua ini, maka Anda tidak dapat melakukannya. Fungsi f (x) bekerja dalam kode asli tidak seanggun di atas kertas. Jika Anda ingin melakukannya dengan benar, Anda harus melakukan banyak pekerjaan.
Untuk mendefinisikan pointer kelas dan hal-hal seperti itu, Anda perlu menyulap dengan C dan C ++. Sebelum menyimpan, selama pembongkaran, konversikan JMP PENDEK Anda menjadi JMP biasa, karena Anda harus berurusan dengan bias, itu cukup sederhana.
Mencoba menghitung perpindahan aktual adalah sakit kepala yang sangat besar. Semua instruksi yang Anda temukan memiliki offset yang akan bergerak ketika kode bergerak, dan harus dihitung ulang. Ini berarti bahwa Anda harus mengikuti instruksi dan ke mana mereka bergerak sebagai tujuan. Sulit bagi saya untuk menjelaskan kepada Anda tentang slide, tetapi sebuah contoh bagaimana mencapai ini ada di CD dengan bahan-bahan dari konferensi ini.
Setelah Anda menempatkan semua instruksi, ganti offset lama dengan offset baru. Jika Anda tidak merusak perpindahan, maka semuanya akan beres. Sekarang setelah Anda siap, ada peluang nyata untuk mengimplementasikan ide di tingkat tertinggi. Untuk melakukan ini, Anda perlu:
- membongkar instruksi;
- menyiapkan buffer memori;
- inisialisasi konstanta yang tersedia f (x);
- iterate over f (x) dan pointer data tertentu, yang menurutnya kode Anda akan ditulis saat melacak instruksi sialan;
- Tetapkan instruksi untuk indeks yang dibuat yang sesuai;
- memperbaiki semua lompatan bersyarat;
- tandai partisi memori baru sebagai executable;
- jalankan kode.
Jika Anda menempatkan hal-hal yang benar di tempat mereka, maka kita mendapatkan hal-hal aneh - semuanya kacau, instruksi melompat ke tempat-tempat memori yang tidak jelas, dan semua ini terlihat sangat mempesona.

Apakah semua ini memiliki arti praktis atau hanya kinerja sirkus? Nilai yang diterapkan dari transformasi tersebut adalah sebagai berikut. Mengisolasi instruksi rakitan dan beberapa langkah untuk menghitung f (x) memungkinkan kami untuk menempatkan instruksi rakitan ini di mana saja di buffer tanpa interaksi pengguna. Untuk membingungkan jalur eksekusi kode, yang harus Anda lakukan adalah menulis fungsi dan pointer secara matematis di assembler, memilihnya secara acak.
Ini sangat menyederhanakan teknik pengkodean polimorfik. Alih-alih menulis kode setiap kali memanipulasi kode Anda dengan cara tertentu, Anda dapat menulis serangkaian fungsi yang secara acak menentukan posisi kode Anda, lalu memilih fungsi-fungsi ini secara acak, dll.
Anti-reverse tidak sekeren dan segar seperti teknik anti-debugging.
Anti-konversi bukan tentang seberapa banyak kesenangan yang Anda dapatkan dari membuatnya tidak mungkin menggunakan IDA, dan bukan tentang seberapa banyak Anda akan merusak komputer Reverser dengan gambar-gambar GNAA Last Measure, meskipun sangat menyenangkan. Anti-pembalikan berarti menjadi seorang brengsek, karena jika Anda, seperti bajingan terakhir, mendapatkan Reverser, seorang pria yang melanggar perlindungan sistem yang berbeda, ia hanya akan marah, kirim program jahat ini ke neraka dan pergi.
Sementara itu, Anda akan dapat menjual semua bot Anda ke jaringan bisnis Rusia, karena dengan perangkat lunak Anda, Anda "menurunkan" semua yang terlibat dalam rekayasa balik. Semua orang tahu bagaimana menemukan teknik anti-debugging di Google, tetapi mereka tidak akan menemukan solusi untuk masalah yang timbul dari hal-hal kreatif di sana. Anti-revolver paling kreatif akan membuat reverters melepaskan jari mereka dari keyboard dan meninggalkan lubang seukuran kepalan tangan di dinding. Pembalik akan mendidih dengan marah, mereka tidak akan mengerti apa yang Anda lakukan, karena kode Anda mengacaukan segalanya.
Ini adalah semacam permainan saraf, hal psikologis, jika Anda kreatif dalam masalah ini dan membuat anti-reverse yang benar-benar memukau, Anda bisa bangga karenanya. Tetapi Anda tahu bahwa sebenarnya, Anda hanya berusaha mendorong mereka menjauh dari kode Anda.
Jadi apa yang akan saya lakukan? Saya akan mengambil fungsi kebingungan dan membingungkan mereka. Kemudian saya akan menggunakan versi kedua dari kebingungan fungsi-fungsi terjerat dan menerapkan kebingungan lagi. Jadi, mari kita tarik kodenya. Ini adalah contoh dari trolling matematis, yang saya ambil sebagai contoh.
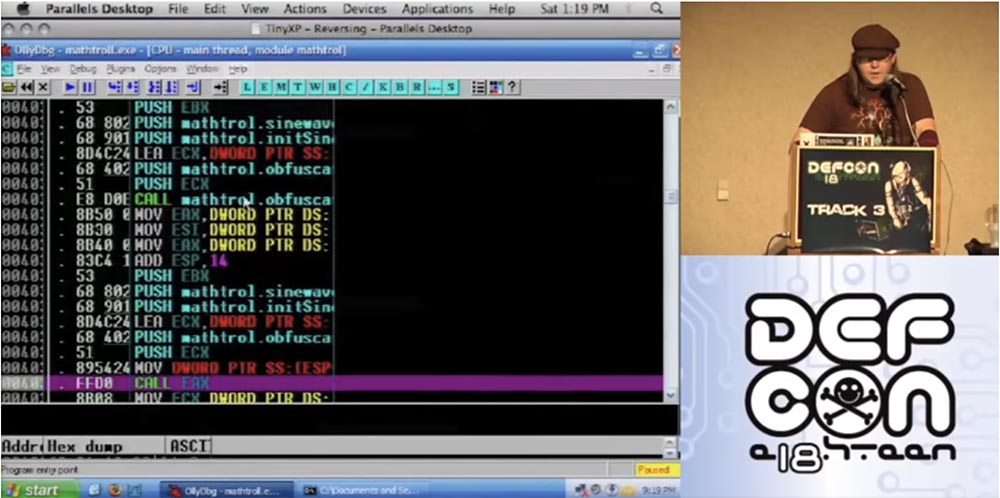
Jadi, saya memasukkan perintah "confuse by formula" di jendela yang terbuka.
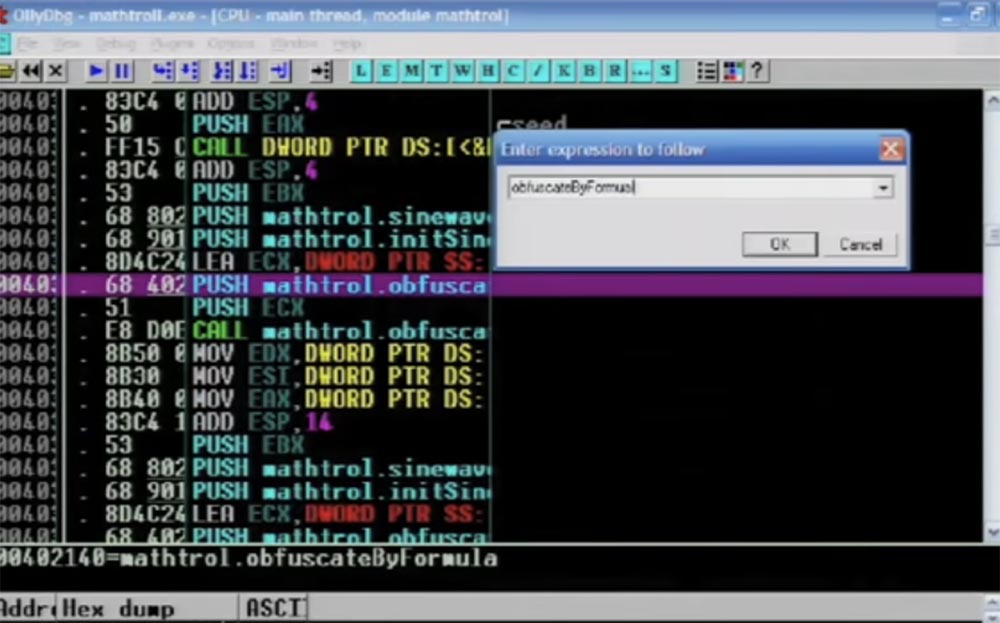
Selanjutnya, Anda melihat instruksi perakitan yang melakukan tugasnya. Perhatikan bahwa saya menggunakan C ++ di sini, meskipun pada kesempatan sekecil apa pun saya mencoba untuk menghindarinya.
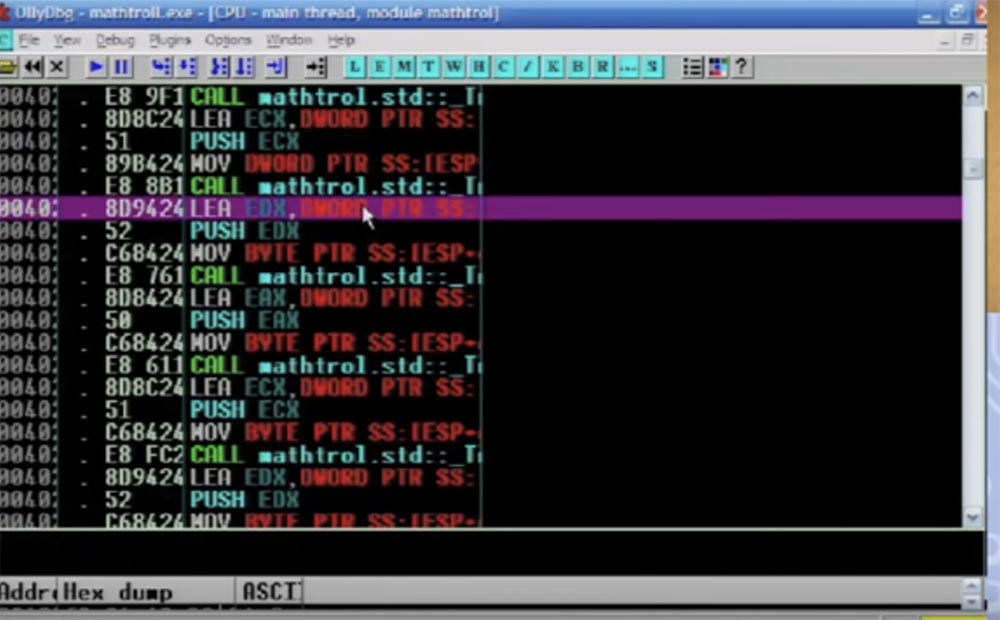
Di sini fungsi aktif CALL EAX disorot, maka instruksi lompatan yang akan diterapkan berikut, Anda melihat banyak hal yang berbeda di buffer, dan semua ini dilakukan dengan masing-masing instruksi.
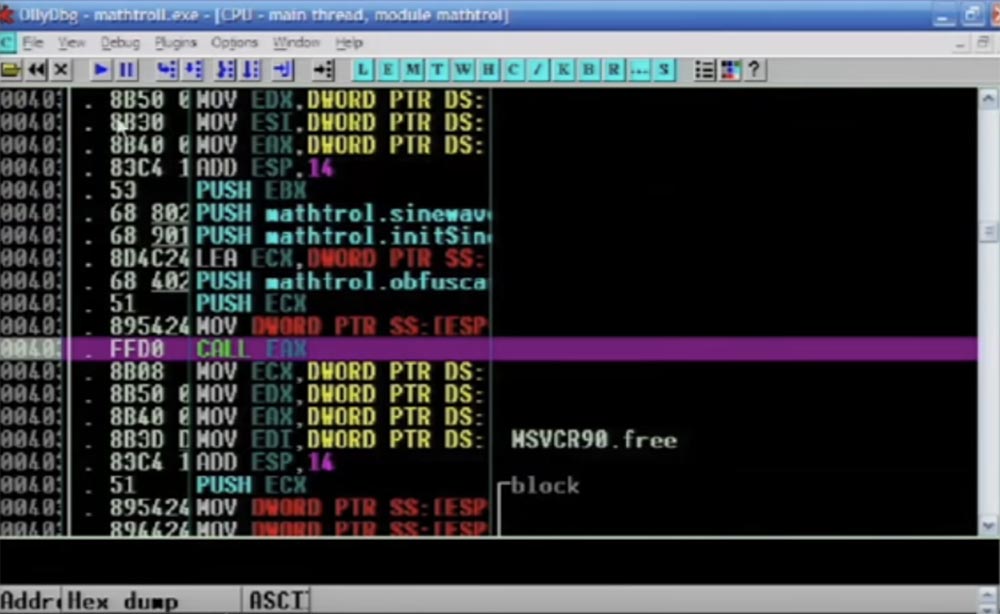

Sekarang saya memundurkan program sampai akhir, dan Anda akan melihat hasilnya. Jadi, kodenya masih tampak hebat, banyak instruksi JMP dikompilasi di sini, terlihat membingungkan, dan sebenarnya itu membingungkan.
Slide berikutnya menunjukkan representasi grafis seperti apa tumpukan itu.

Setiap kali ini terjadi, saya menghasilkan rumus gelombang sinus acak yang bentuknya sewenang-wenang, Anda lihat di sini banyak bentuk yang berbeda, dan itu keren. Saya pikir kode dimulai di suatu tempat di kiri atas, tetapi saya tidak ingat persis. Jadi dia memutar semua, Anda tidak hanya bisa membuat sinusoid, tetapi juga memutar spiral.
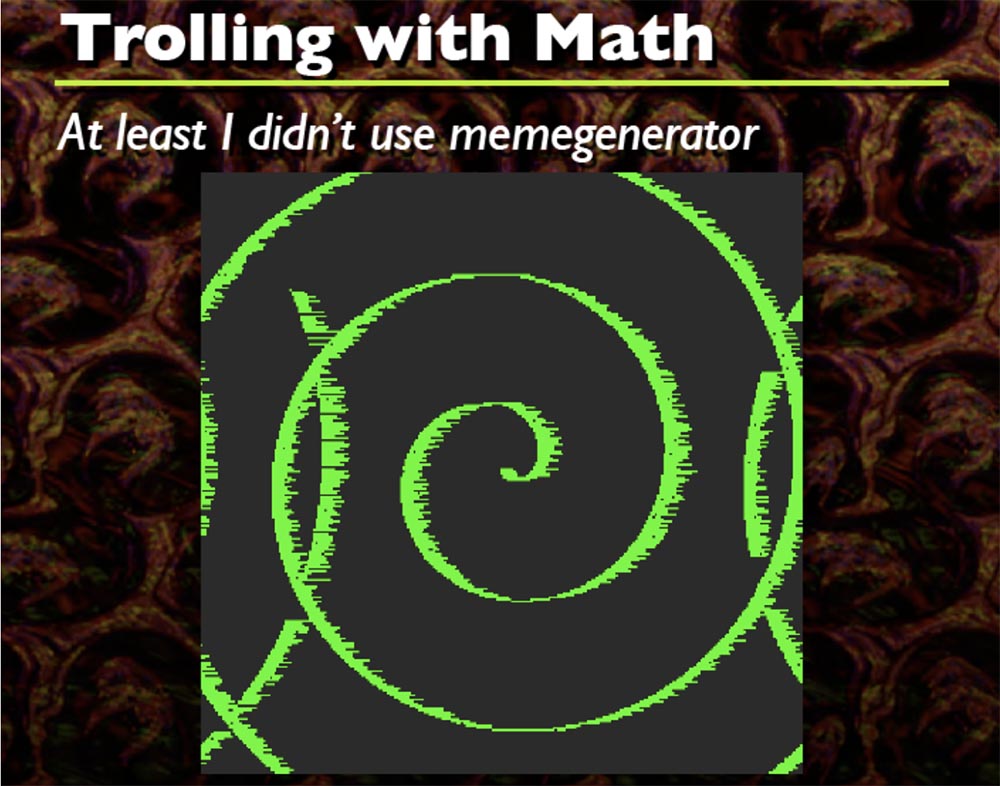
Hanya dua rumus yang berfungsi di sini, yang saya sertakan dalam kode sumber. Berdasarkan ini, Anda dapat melakukan banyak hal kreatif seperti yang Anda inginkan, pada dasarnya itu hanya DIFF dari buffer awal ke buffer akhir.
Masalahnya adalah bahwa contoh kode ini menggunakan lompatan tanpa syarat, yang sebenarnya buruk, karena kode harus persis sama seperti sebelumnya, yaitu, lompatan tanpa syarat hanya mengikuti satu arah. Oleh karena itu, Anda harus pergi dari titik masuk ke ujung dengan cara yang sama, singkirkan instruksi lompatan dan selesai - Anda mendapatkan kode Anda! Apa yang harus dilakukan Hal ini diperlukan untuk mengubah lompatan tanpa syarat menjadi yang bersyarat. Lompatan bersyarat dibuat dalam dua arah, itu jauh lebih baik, kita dapat mengatakan bahwa itu adalah 50% lebih baik.
Di sini kita memiliki dilema yang menarik: jika kita membutuhkan lompatan bersyarat, maka kita masih perlu menggunakan lompatan tanpa syarat ... apa-apaan ini? Jadi apa yang kita lakukan? Predikat buram akan menyelamatkan kita! Bagi mereka yang tidak tahu, predikat buram pada dasarnya adalah pernyataan Boolean yang selalu dieksekusi untuk versi tertentu terlepas dari apa pun.
Jadi, mari kita lihat perluasan ruang nol yang saya sebutkan sebelumnya. Jika Anda memiliki serangkaian instruksi dan mereka memiliki lompatan tanpa syarat, transisi di antara setiap instruksi, maka serangkaian instruksi perakitan yang tidak secara langsung mempengaruhi instruksi yang kita butuhkan dapat mendahului atau mengikuti satu instruksi.
Misalnya, jika Anda menulis instruksi yang sangat spesifik yang tidak mengubah perakitan utama dari apa yang Anda coba bingungkan, yaitu, Anda mencoba untuk tidak terlibat dengan register selama Anda mempertahankan status setiap instruksi perakitan. Dan ini bahkan lebih menakjubkan.
Anda dapat mempertimbangkan setiap instruksi rakitan, yang dapat membingungkan, seperti pembukaan, data rakitan, dan catatan tambahan. Pembukaannya adalah yang mendahului instruksi perakitan, dan nota tambahannya adalah yang mengikutinya. Pembukaan biasanya digunakan atau dapat digunakan untuk dua hal:
- koreksi konsekuensi dari predikat buram dari pembukaan sebelumnya;
- fragmen kode anti-debugging.
Tetapi pembukaan pada dasarnya terbatas karena Anda tidak dapat melakukan terlalu banyak.
Postscript adalah hal yang lebih lucu. Dapat digunakan untuk:
- Predikat yang tidak jelas dan rumit melompat ke bagian kode berikut;
- anti-debugging dan kebingungan pelaksanaan kode secara keseluruhan;
- enkripsi dan dekripsi berbagai fragmen kode dalam program itu sendiri.
Saat ini saya sedang bekerja pada kemungkinan mengenkripsi dan mendekripsi setiap instruksi individu sehingga ketika setiap instruksi dieksekusi, ia mendekripsi bagian berikutnya, bagian berikutnya, berikutnya, dan seterusnya. Slide berikut menunjukkan contohnya.

Baris pembuka dan panggilan debugger disorot dalam warna hijau. Semua yang dilakukan oleh panggilan ini adalah untuk memeriksa apakah kami memiliki debugger, setelah itu kami pergi ke bagian kode yang sewenang-wenang.
Di bawah ini kami memiliki predikat buram yang sangat sederhana. Jika Anda mempertahankan nilai Eax dalam postscript ke instruksi atas, maka ikuti operator XOR, sehingga JZ Anda berpikir: "OK, saya jelas bisa ke kiri atau kanan, saya pikir saya lebih baik ke kanan, karena ada 0". Kemudian POP EAX dijalankan, EAX Anda kembali, setelah itu instruksi selanjutnya diproses, dan seterusnya.
Ini, jelas, menciptakan masalah yang jauh lebih besar daripada strategi dasar kami, seperti efek residual dan kerumitan menghasilkan set instruksi yang berbeda. Oleh karena itu, akan sangat sulit untuk menentukan bagaimana suatu instruksi mempengaruhi instruksi yang lain. Anda dapat melempar sandal kepada saya, karena saya belum menyelesaikan program luar biasa ini, tetapi Anda dapat mengikuti kemajuan pengembangan di blog saya.

Saya perhatikan bahwa rumus kami f (x) tidak harus dihitung secara iteratif, misalnya f (1), f (2), ... f (n). Tidak ada yang mencegah mereka untuk dihitung secara acak. Jika Anda pintar, Anda dapat menentukan berapa banyak instruksi yang Anda butuhkan, dan kemudian menetapkan, misalnya, f (27), f (54), f (9), dan ini akan menjadi tempat di mana instruksi Anda ditempatkan secara acak. Ketika Anda melakukan ini, tergantung pada bagaimana Anda menulis kode Anda, Anda dapat menghentikannya terlebih dahulu, dan kode tersebut masih akan mengikat instruksi Anda secara acak.
Jika kode Anda dihasilkan berdasarkan rumus yang dapat diprediksi, maka mengikuti bahwa titik masuk juga dapat diprediksi, sehingga Anda dapat naik satu tingkat lebih banyak sebelum Anda selesai menerima kode dan secara signifikan membingungkan titik masuk ke tingkat tertentu. Misalnya, ambil 300 instruksi perakitan yang berasal dari satu titik masuk.
Sekarang mari kita bicara tentang kekurangannya.

Metode ini membutuhkan kompilasi kode yang cermat, terutama menggunakan GCC atau, Tuhan melarang, menggunakan C ++. C ++ sebenarnya adalah bahasa yang cukup keren karena beberapa alasan, tetapi Anda tahu bahwa semua penyedot mengisap. Jadi hal utama dalam hal ini adalah kompilasi buatan tangan yang kompeten, karena jika upaya Anda untuk membingungkan majelis Anda sendiri akan menyebabkan persetujuan geng yang menemukan worm Conficker, maka Anda mengacau.
Anda akan membutuhkan banyak memori. Ingat gambar dengan gelombang sinus. Merah adalah kodenya, dan biru adalah memori yang diperlukan agar bisa berfungsi, dan itu harus cukup untuk semuanya berfungsi sebagaimana mestinya.
Anda mungkin akan berurusan dengan dataset raksasa setelah Anda menyelesaikan kode. Dan itu akan meningkat secara signifikan jika Anda ingin membingungkan lebih dari satu fungsi.
Pointer fungsi berperilaku tak terduga - kadang dengan benar, kadang tidak. Itu tergantung pada apa yang Anda lakukan, dan pasti akan ada masalah karena Anda tidak dapat memprediksi di mana dan kapan fungsi pointer menyala di perakitan Anda.
Semakin rumit Anda menghasilkan kebingungan dan memanipulasi perakitan dalam pembukaan dan catatan tambahan, semakin sulit untuk memperbaiki dan men-debug. Jadi, menulis kode seperti itu adalah menyeimbangkan antara "oke, saya akan dengan hati-hati memasukkan satu atau dua JMP di sini" dan "bagaimana saya bisa menyelesaikannya dalam waktu singkat"? Jadi Anda hanya perlu memasukkan instruksi dan kemudian mencari tahu selama beberapa bulan apa yang telah Anda lakukan.
Saya harap Anda belajar sesuatu yang bermanfaat hari ini. Menurut pendapat saya, saya benar-benar mabuk dan karena itu saya tidak benar-benar mengerti apa yang terjadi sekarang. Slide berikutnya menunjukkan kontak Twitter saya, blog dan situs web saya, jadi kunjungi saya atau tulis.

Itu saja, terima kasih sudah datang!
Terima kasih telah tinggal bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikannya kepada teman-teman Anda,
diskon 30% untuk pengguna Habr pada analog unik dari server entry-level yang kami temukan untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps dari $ 20 atau bagaimana membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps hingga Januari secara gratis ketika membayar untuk jangka waktu enam bulan, Anda dapat memesan di
sini .
Dell R730xd 2 kali lebih murah? Hanya kami yang memiliki
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV dari $ 249 di Belanda dan Amerika Serikat! Baca tentang
Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?