Baru-baru ini, pengembangan web telah dibagi. Sekarang kita tidak semua pemrogram stack penuh - kita adalah front-end dan back-end. Dan hal yang paling sulit tentang ini, seperti halnya di tempat lain, adalah masalah interaksi dan integrasi.
Frontend dengan backend berinteraksi melalui API. Dan seluruh hasil pengembangan tergantung pada apa API itu, seberapa baik atau buruk backend dan frontend telah sepakat di antara mereka sendiri. Jika kita semua mulai berdiskusi bersama bagaimana melakukan upgrade, dan menghabiskan sepanjang hari untuk mengerjakannya, kita mungkin tidak mendapatkan tugas bisnis.
Agar tidak tergelincir dan berkembang biak tentang nama-nama variabel, Anda memerlukan spesifikasi yang baik. Mari kita bicara tentang bagaimana rasanya membuat hidup lebih mudah bagi semua orang. Pada saat yang sama, kami akan menjadi ahli dalam gudang sepeda.

Mari kita mulai dari jauh - dengan masalah yang sedang kita pecahkan.
Dahulu kala, pada tahun 1959,
Cyril Parkinson (jangan bingung dengan penyakitnya, dia adalah seorang penulis dan tokoh ekonomi) muncul dengan beberapa undang-undang yang menarik. Misalnya, bahwa pengeluaran tumbuh dengan pendapatan, dll. Salah satunya disebut Hukum Triviality:
Waktu yang dihabiskan untuk mendiskusikan item berbanding terbalik dengan jumlah yang dipertimbangkan.
Parkinson adalah seorang ekonom, jadi dia menjelaskan hukumnya dalam istilah ekonomi, kira-kira seperti ini. Jika Anda datang ke dewan direksi dan mengatakan bahwa Anda membutuhkan $ 10 juta untuk membangun pembangkit listrik tenaga nuklir, kemungkinan besar masalah ini akan dibahas jauh lebih sedikit daripada alokasi 100 pound untuk gudang sepeda untuk karyawan. Karena semua orang tahu cara membangun gudang sepeda, setiap orang memiliki pendapatnya sendiri, semua orang merasa penting dan ingin berpartisipasi, dan pembangkit listrik tenaga nuklir adalah sesuatu yang abstrak dan jauh, 10 juta juga belum pernah terlihat - ada sedikit pertanyaan.
Pada tahun 1999, hukum sepele Parkinson muncul dalam pemrograman, yang kemudian dikembangkan secara aktif. Dalam pemrograman, hukum ini ditemukan terutama dalam literatur berbahasa Inggris dan terdengar seperti metafora. Itu disebut
efek Bikeshed (efek dari gudang sepeda), tetapi esensinya sama - kami siap untuk gudang sepeda dan ingin membahas lebih lama daripada pembangunan pembangkit listrik.
Istilah ini diciptakan oleh pengembang Denmark Poul-Henning Kamp, yang terlibat dalam pembuatan FreeBSD. Selama proses desain, tim menghabiskan waktu yang sangat lama untuk mendiskusikan bagaimana fungsi tidur seharusnya bekerja. Ini adalah kutipan dari
surat dari Poul-Henning Kamp (pengembangan kemudian dilakukan dalam korespondensi email):
Itu adalah proposal untuk membuat tidur (1) DTRT Jika diberi argumen non-integer yang membuat ini mematikan rumput saya tidak akan mengatakan lebih banyak tentang itu, karena itu adalah barang yang jauh lebih kecil daripada yang akan harapkan dari panjang utasnya, dan sudah mendapat perhatian lebih dari beberapa * masalah * yang kita miliki di sini.
Dalam surat ini, dia mengatakan bahwa ada banyak masalah yang jauh lebih penting yang belum terselesaikan: "Jangan berurusan dengan gudang sepeda, kita akan melakukan sesuatu dengan ini dan melanjutkan!"
Jadi Poul-Henning Kamp pada tahun 1999 memperkenalkan istilah efek bikeshed ke dalam literatur berbahasa Inggris, yang dapat diulangi menjadi:
Jumlah noise yang diciptakan oleh perubahan kode berbanding terbalik dengan kompleksitas perubahan.
Semakin sederhana penambahan atau perubahan yang kita buat, semakin banyak pendapat yang perlu kita dengar tentang hal itu. Saya pikir banyak yang bertemu ini. Jika kita memecahkan pertanyaan sederhana, misalnya, bagaimana memberi nama variabel, itu tidak masalah untuk mesin - pertanyaan ini akan menyebabkan sejumlah besar holivar. Tetapi serius, sangat penting untuk masalah bisnis yang tidak dibahas dan pergi di latar belakang.
Menurut Anda apa yang lebih penting: bagaimana kita berkomunikasi antara backend dan frontend, atau tugas bisnis yang kita lakukan? Semua orang berpikir berbeda, tetapi pelanggan mana pun, orang yang mengharapkan Anda membawakannya uang, akan mengatakan: "Kerjakan tugas bisnis kami kepada saya!" Dia benar-benar tidak peduli bagaimana Anda mentransfer data antara backend dan frontend. Mungkin dia bahkan tidak tahu apa itu backend dan frontend.
Untuk meringkas pendahuluan, saya ingin mengatakan:
API adalah gudang sepeda.Tautan presentasiTentang pembicara: Alexey Avdeev (
Avdeev ) bekerja untuk perusahaan Neuron.Digital, yang menangani neuron dan membuat tampilan keren untuk mereka. Alex juga memperhatikan OpenSource, dan menyarankan semua orang. Dia telah terlibat dalam pengembangan untuk waktu yang lama - sejak 2002, dia menemukan Internet kuno, ketika komputer besar, internet kecil, dan kurangnya JS tidak mengganggu siapa pun dan semua orang membuat situs di atas meja.
Bagaimana cara menangani gudang sepeda?
Setelah Cyril Parkinson yang terhormat menyimpulkan hukum kesederhanaan, ia banyak dibahas. Ternyata efek dari gudang sepeda di sini dapat dengan mudah dihindari:
- Jangan dengarkan saran. Saya pikir idenya begitu - jika Anda tidak mendengarkan kiatnya, Anda dapat melakukan hal seperti itu, terutama dalam pemrograman, dan terutama jika Anda adalah pengembang pemula.
- Lakukan seperti yang kamu inginkan. "Aku seorang seniman, begitu!" - tidak ada efek bikeshed, semua yang Anda butuhkan sudah selesai, tetapi hal-hal yang sangat aneh muncul pada output. Ini sering ditemukan dalam freelance. Tentunya Anda menemukan tugas yang harus Anda selesaikan untuk pengembang lain dan implementasi yang menyebabkan Anda kebingungan.
- Apakah penting untuk bertanya pada diri sendiri? Jika tidak, Anda bisa saja tidak membahasnya, tetapi itu adalah masalah kesadaran pribadi.
- Gunakan kriteria objektif. Saya akan berbicara tentang hal ini dalam laporan ini. Untuk menghindari efek dari gudang sepeda, Anda dapat menggunakan kriteria yang secara objektif mengatakan mana yang lebih baik. Mereka ada.
- Jangan bicara tentang apa yang tidak ingin Anda dengarkan. Di perusahaan kami, pengembang backend awal adalah introvert, sehingga mereka melakukan sesuatu yang tidak mereka katakan kepada orang lain. Akibatnya, kami menemukan kejutan. Metode ini berfungsi, tetapi dalam pemrograman itu bukan pilihan terbaik.
- Jika Anda tidak peduli dengan masalah tersebut, Anda bisa membiarkannya pergi atau memilih salah satu opsi yang diusulkan yang muncul dalam proses holivarov.
Alat anti-bikeshedding
Saya ingin berbicara tentang
alat obyektif untuk menyelesaikan masalah gudang sepeda. Untuk mendemonstrasikan apa alat anti-bikeshedding, saya akan menceritakan sedikit kisah.
Bayangkan kita memiliki pengembang backend pemula. Dia baru-baru ini datang ke perusahaan, dan dia diperintahkan untuk merancang layanan kecil, misalnya, sebuah blog, di mana Anda perlu menulis protokol REST.
 Roy Fielding, penulis REST
Roy Fielding, penulis RESTDalam foto tersebut, Roy Fielding, yang pada tahun 2000 membela tesisnya "Gaya arsitektur dan desain arsitektur perangkat lunak jaringan" dan dengan demikian memperkenalkan istilah REST. Selain itu, ia menemukan HTTP dan, pada kenyataannya, adalah salah satu pendiri Internet.
REST adalah seperangkat prinsip arsitektur yang mengatakan bagaimana merancang protokol REST, API REST, layanan RESTful. Ini adalah prinsip arsitektur yang cukup abstrak dan kompleks. Saya yakin tidak ada di antara Anda yang pernah melihat API yang dibuat sepenuhnya sesuai dengan semua prinsip RESTful.
Persyaratan Arsitektur REST
Saya akan memberikan beberapa persyaratan untuk protokol
REST , yang kemudian akan saya rujuk dan andalkan. Ada cukup banyak dari mereka, Anda dapat membacanya lebih lanjut di Wikipedia.
1.
Model client-server.Prinsip REST yang paling penting, yaitu interaksi kita dengan backend. Menurut REST, backend adalah server, front-end adalah klien, dan kami berkomunikasi dalam format client-server. Perangkat seluler juga merupakan klien. Pengembang untuk jam tangan, untuk lemari es, layanan lain - juga mengembangkan bagian klien. API RESTful adalah server yang diakses klien.
2.
Kurangnya kondisi.Tidak boleh ada keadaan di server, yaitu, semua yang diperlukan untuk jawaban datang dalam permintaan. Ketika sebuah sesi disimpan di server, dan tergantung pada sesi ini jawaban yang berbeda datang, ini merupakan pelanggaran prinsip REST.
3.
Keseragaman antarmuka.Ini adalah salah satu prinsip dasar yang mendasari di mana REST API harus dibangun. Ini termasuk yang berikut:
- Identifikasi sumber daya adalah bagaimana kita harus membangun URL. Pada REST, kami beralih ke server untuk beberapa jenis sumber daya.
- Manipulasi sumber daya melalui presentasi. Server mengembalikan kita pandangan yang berbeda dari apa yang ada di database. Tidak masalah jika Anda menyimpan informasi dalam MySQL atau PostgreSQL - kami memiliki pandangan.
- Pesan yang menggambarkan diri sendiri - yaitu, pesan berisi id, tautan tempat Anda bisa mendapatkan pesan ini lagi - semua yang diperlukan untuk bekerja dengan sumber daya ini lagi.
- Hypermedia adalah tautan ke tindakan berikut dengan sumber daya. Menurut saya tidak ada REST API yang melakukannya, tetapi dijelaskan oleh Roy Fielding.
Ada 3 prinsip lagi yang tidak saya kutip karena tidak penting untuk cerita saya.
Blog yang tenang
Kembali ke pengembang backend awal, yang diminta untuk membuat layanan untuk blog di RESTful. Di bawah ini adalah contoh prototipe.
Ini adalah situs di mana ada artikel, Anda dapat mengomentarinya, artikel dan komentar memiliki penulis - cerita standar. Pengembang backend pemula kami akan melakukan RESTful API untuk blog ini.
Kami bekerja dengan semua data blog berdasarkan
CRUD .
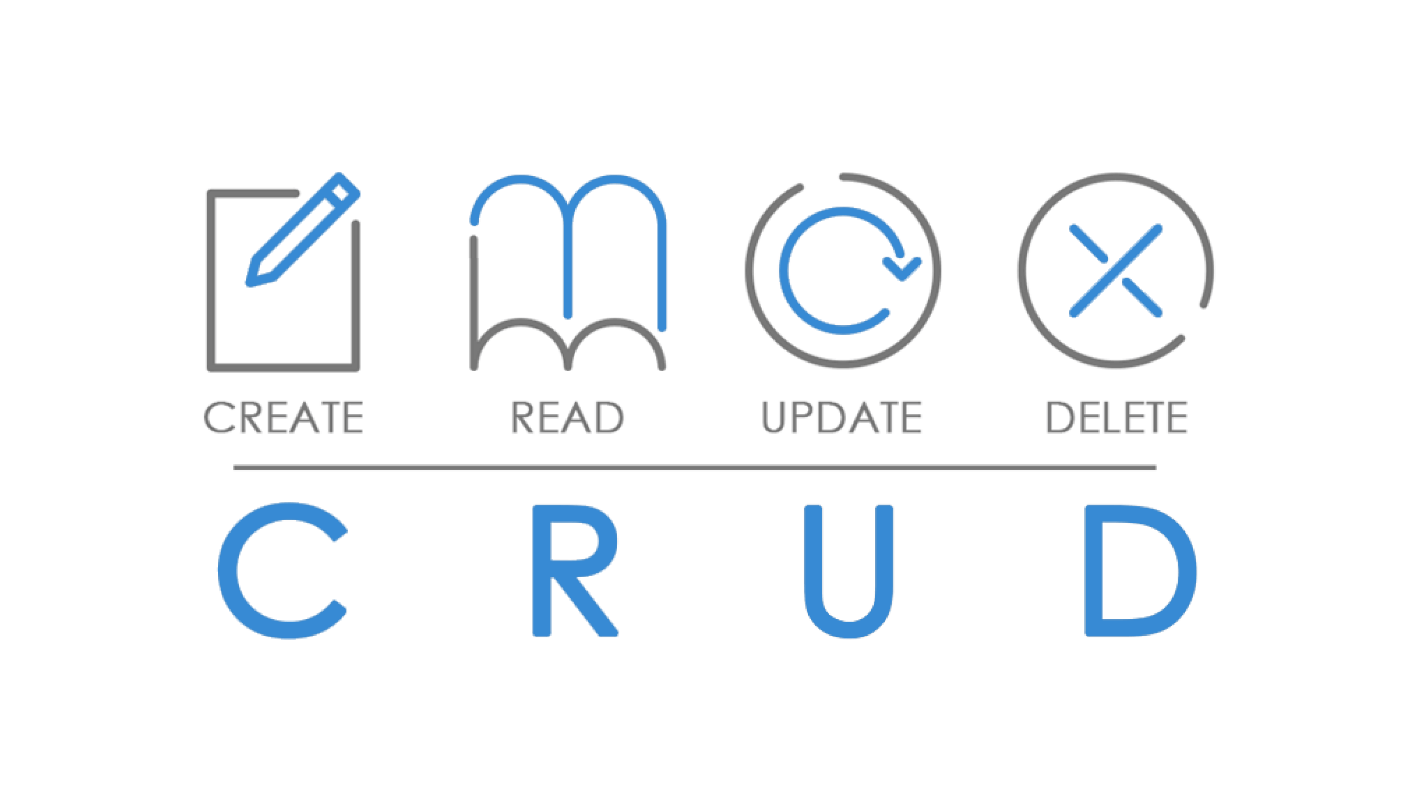
Seharusnya dimungkinkan untuk membuat, membaca, memperbarui, dan menghapus sumber daya apa pun. Mari kita coba meminta pengembang backend kami untuk membangun AP yang tenang berdasarkan prinsip CRUD. Artinya, tulis metode untuk membuat artikel, dapatkan daftar artikel atau satu artikel, perbarui dan hapus.
Mari kita lihat bagaimana dia bisa melakukannya.
 Semuanya salah dengan semua prinsip REST
Semuanya salah dengan semua prinsip REST . Hal yang paling menarik adalah ia bekerja. Saya benar-benar mendapatkan API yang terlihat seperti ini. Bagi pelanggan, ini adalah gudang sepeda, bagi pengembang itu adalah kesempatan untuk bersantai dan berdebat, dan bagi pengembang pemula, ini hanyalah dunia baru yang besar dan berani tempat ia tersandung setiap kali, jatuh, menghancurkan kepalanya. Dia harus mengulanginya lagi dan lagi.

Ini adalah opsi REST. Berdasarkan prinsip-prinsip mengidentifikasi sumber daya, kami bekerja dengan sumber daya - dengan artikel dan menggunakan metode HTTP yang diusulkan oleh Roy Fielding. Dia tidak bisa tidak menggunakan pekerjaan sebelumnya dalam pekerjaan berikutnya.
Untuk memperbarui artikel, banyak yang menggunakan metode PUT, yang memiliki semantik yang sedikit berbeda. Metode PATCH memperbarui bidang yang disahkan, dan PUT hanya mengganti satu artikel dengan yang lain. Secara semantik, PATCH digabung, dan PUT diganti.
Pengembang backend pemula kami jatuh, mereka mengambilnya dan berkata: "Semuanya beres, lakukan seperti itu," dan dia dengan jujur mengubahnya. Tapi kemudian dia akan menemukan jalan panjang yang sangat jauh melalui duri.
Kenapa begitu benar?- karena Roy Fielding berkata demikian;
- karena itu ISTIRAHAT;
- karena ini adalah prinsip arsitektur yang menjadi dasar profesi kita sekarang.
Namun, ini adalah "gudang sepeda", dan metode sebelumnya akan berhasil. Komputer dikomunikasikan sebelum REST, dan semuanya berfungsi. Tapi sekarang standar telah muncul di industri.
Hapus artikel
Pertimbangkan contoh menghapus artikel. Misalkan ada normal, metode sumber daya HAPUS / artikel, yang menghapus artikel dengan id. HTTP berisi tajuk. Header Terima menerima jenis data yang ingin diterima klien sebagai respons. Junior kami menulis sebuah server yang mengembalikan 200 OK, Content-Type: application / json, dan mengirimkan tubuh kosong:
01. DELETE /articles/ 1 /1.1
02. Accept: application/json01. HTTP/1.1 200 OK
02. Content-Type: application/json
03. null
Kesalahan yang sangat
umum telah dibuat di sini - tubuh kosong . Semuanya tampaknya logis - artikel telah dihapus, 200 OK, header aplikasi / json hadir, tetapi kemungkinan besar klien akan jatuh. Ini akan melempar kesalahan karena benda kosong tidak valid. Jika Anda pernah mencoba untuk mengurai string kosong, maka Anda dihadapkan dengan fakta bahwa setiap parser json tersandung dan jatuh pada ini.
Bagaimana cara memperbaiki situasi ini? Mungkin pilihan terbaik adalah lulus json. Jika kami menyatakan: "Terima, beri kami json", server mengatakan: "Jenis-Konten, saya beri Anda json", beri json. Objek kosong, array kosong - letakkan sesuatu di sana - ini akan menjadi solusi, dan itu akan berhasil.
Masih ada solusinya. Selain 200 OK, ada kode respons 204 - tidak ada konten. Dengannya, Anda tidak bisa mentransmisikan tubuh. Tidak semua orang tahu tentang ini.
Jadi saya mengarahkan ke jenis media.
Jenis pantomim
Jenis media seperti ekstensi file, hanya di web. Ketika kami mengirimkan data, kami harus menginformasikan atau meminta jenis apa yang ingin kami terima sebagai tanggapan.
- Secara default, ini teks / polos - hanya teks.
- Jika tidak ada yang ditentukan, maka browser kemungkinan besar akan berarti aplikasi / octet-stream - hanya sedikit aliran.
Anda dapat menentukan jenis tertentu saja:
- aplikasi / pdf;
- gambar / png;
- aplikasi / json;
- aplikasi / xml;
- application / vnd.ms-excel.
Header-Jenis Konten dan Terima adalah dan penting.
API dan klien harus lulus header Tipe-Konten dan Terima.
Jika API Anda dibangun di JSON, selalu sampaikan Accept: application / json dan Content-Type application / json.
Jenis file contoh.

Jenis media mirip dengan jenis file ini, hanya di Internet.
Kode Jawaban
Contoh berikutnya dari petualangan pengembang junior kami adalah kode respons.

Tingkat respons terlucu adalah 200 OK. Semua orang mencintainya - itu berarti semuanya berjalan dengan baik. Saya bahkan punya kasing - Saya menerima
kesalahan 200 OK . Sesuatu benar-benar jatuh pada server, sebagai respons terhadap respons, muncul halaman HTML di mana kesalahan HTML telah dikompilasi. Saya meminta aplikasi json dengan kode 200 OK, dan berpikir bagaimana cara mengatasinya? Anda pergi dengan tanggapan, mencari kata "kesalahan", Anda berpikir bahwa ini adalah kesalahan.
Ini berfungsi, bagaimanapun, dalam HTTP ada banyak kode lain yang dapat Anda gunakan, dan REST merekomendasikan agar Anda menggunakannya pada REST. Misalnya, pembuatan entitas (artikel) dapat dijawab:
- 201 Created adalah kode yang berhasil. Artikel ini dibuat, sebagai tanggapan Anda perlu mengembalikan artikel yang dibuat.
- 202 Diterima artinya permintaan telah diterima, tetapi hasilnya nanti. Ini adalah operasi jangka panjang. Pada Diterima, tidak ada badan yang dapat dikembalikan. Artinya, jika Anda tidak memberikan Tipe-Konten dalam respons, maka tubuh mungkin juga tidak. Atau Teks / Pesawat Jenis Konten - itu saja, tidak ada pertanyaan. String kosong adalah teks / bidang yang valid.
- 204 Tidak Ada Konten - tubuh mungkin sama sekali tidak ada.
- 403 Forbidden - Anda tidak diizinkan membuat artikel ini.
- 404 Tidak Ditemukan - Anda naik di tempat yang salah, tidak ada cara seperti itu, misalnya.
- 409 Konflik adalah kasus ekstrem yang digunakan beberapa orang. Terkadang diperlukan jika Anda membuat id pada klien, dan bukan pada backend, dan pada saat itu seseorang sudah berhasil membuat artikel ini. Konflik adalah jawaban yang tepat dalam kasus ini.
Penciptaan Entitas
Contoh berikut: kita membuat entitas, misalnya Content-Type: application / json, dan meneruskan aplikasi ini / json. Ini membuat klien - frontend kami. Mari kita buat artikel ini:
01. POST /articles /1.1
02. Content-Type: application/json
03. { "id": 1, "title": " JSON API"}Kode mungkin datang sebagai respons:
- 422 Entitas yang tidak dapat diproses - Entitas yang tidak diproses. Semuanya tampak hebat - semantik, ada kode;
- 403 Dilarang
- 500 Galat Server Internal.
Tetapi benar-benar tidak dapat dipahami apa yang sebenarnya terjadi: entitas apa yang tidak diproses, mengapa saya tidak pergi ke sana, dan apa yang akhirnya terjadi pada server?
Kembalikan kesalahan
Pastikan (dan junior tidak tahu tentang ini) sebagai respons, kembalikan kesalahan. Ini semantik dan benar. Ngomong-ngomong, Fielding tidak menulis tentang ini, yaitu, ia diciptakan kemudian dan dibangun di atas REST.
Backend dapat mengembalikan array dengan kesalahan sebagai respons, mungkin ada beberapa.
01. HTTP/1.1 422 Unprocessable Entity
02. Content-Type: application/json
03.
04. { "errors": [{
05. "status": "422",
06. "title": "Title already exist",
07. }]}Setiap kesalahan dapat memiliki status dan judulnya sendiri. Ini hebat, tetapi sudah berjalan di tingkat konvensi di atas REST. Ini bisa menjadi alat anti-bikeshedding kami untuk segera berhenti berdebat dan membuat API yang bagus dan langsung.
Tambahkan Pagination
Contoh berikut: desainer datang ke pengembang backend awal kami dan berkata: “Kami memiliki banyak artikel, kami membutuhkan pagination. Kami menggambar yang ini. "

Mari kita pertimbangkan lebih terinci. Pertama-tama, 336 halaman sangat mencolok. Ketika saya melihat ini, saya berpikir tentang cara mendapatkan angka ini. Di mana mendapatkan 336, karena ketika saya meminta daftar artikel saya mendapatkan daftar artikel. Misalnya, ada 10 ribu di antaranya, yaitu, saya harus mengunduh semua artikel, membaginya dengan jumlah halaman dan mencari tahu nomor ini. Untuk waktu yang sangat lama saya akan memuat artikel ini, saya perlu cara untuk mendapatkan jumlah entri dengan cepat. Tetapi jika API kami mengembalikan daftar, lalu ke mana harus menempatkan jumlah catatan ini secara umum, karena serangkaian artikel datang sebagai tanggapan. Ternyata karena jumlah catatan tidak diletakkan di mana pun, maka harus ditambahkan ke setiap artikel sehingga setiap artikel mengatakan: "Dan ada begitu banyak dari kita semua!"
Namun, ada konvensi di atas API REST yang menyelesaikan masalah ini.
Daftar permintaan
Untuk membuat API dapat diperpanjang, Anda dapat segera menggunakan parameter GET untuk pagination: ukuran halaman saat ini dan nomornya, sehingga potongan halaman yang kami minta dikembalikan kepada kami. Ini nyaman. Sebagai tanggapan, Anda tidak bisa langsung memberikan array, tetapi menambahkan nesting tambahan. Misalnya, kunci data akan berisi larik, data yang kami minta, dan kunci meta, yang sebelumnya tidak ada, akan berisi total.
01. GET /articles? page[size]=30&page[number]=2
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
Dengan cara ini, API dapat mengembalikan informasi tambahan. Selain menghitung, mungkin ada beberapa informasi lain - itu dapat diperluas. Sekarang, jika junior tidak segera melakukannya, dan hanya setelah dia diminta melakukan piyamaisasi, maka dia
membuat perubahan mundur yang tidak kompatibel , memecahkan API, dan semua klien harus mengulangnya - biasanya sangat menyakitkan.
Piyamaisasi berbeda. Saya menawarkan beberapa peretas yang dapat Anda gunakan.
[offset] ... [batas]
01. GET /articles? page[offset]=30&page[limit]=30
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
Mereka yang bekerja dengan database mungkin sudah memiliki subkorteks [offset] ... [limit]. Menggunakannya alih-alih halaman [ukuran] ... halaman [angka] akan lebih mudah. Ini adalah pendekatan yang sedikit berbeda.
Penempatan kursor
01. GET /articles? page[published_at]=1538332156
02. Content-Type: application/json01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }Lokasi kursor menggunakan pointer ke entitas yang akan mulai memuat catatan. Misalnya, sangat nyaman ketika Anda menggunakan pagination atau memuat daftar yang sering berubah. Katakanlah artikel baru terus ditulis di blog kami. Halaman ketiga sekarang bukan halaman ketiga yang sama dalam satu menit, tetapi jika kita pergi ke halaman keempat, kita akan mendapatkan beberapa catatan dari halaman ketiga di atasnya, karena seluruh daftar akan bergerak.
Masalah ini diselesaikan dengan pagination kursor. Kami mengatakan: "Muat artikel yang datang setelah artikel yang diterbitkan pada waktu itu" - tidak ada lagi pergeseran teknologi, dan ini keren.
Masalah N +1
Masalah berikutnya yang pasti akan dihadapi oleh pengembang junior kami adalah masalah N +1 (pendukung akan mengerti). Misalkan Anda ingin daftar 10 artikel. Kami mengunggah daftar artikel, setiap artikel memiliki penulis, dan untuk setiap Anda perlu mengunduh penulis. Kami mengirim:
- 1 permintaan untuk daftar artikel;
- 10 permintaan untuk penulis setiap artikel.
Total: 11 pertanyaan untuk menampilkan daftar kecil.
Tambahkan tautan
Di backend, masalah ini diselesaikan di semua ORM - Anda hanya perlu ingat untuk menambahkan koneksi ini. Koneksi ini juga dapat digunakan di ujung depan. Ini dilakukan sebagai berikut:
01. GET /articles? include =author
02. Content-Type: application/json
Anda dapat menggunakan parameter GET khusus, sebut itu termasuk (seperti pada backend), mengatakan tautan apa yang perlu kita muat bersama dengan artikel. Misalkan kita mengunggah artikel, dan kami ingin segera mendapatkan penulis bersama dengan artikel. Jawabannya terlihat seperti ini:
01. /1.1 200
02. { "data": [{
03. { attributes: { "id": 1, "title": "JSON API" },
04. { relationships: {
05. "author": { "id": 1, "name": "Avdeev" } }
06. }, ...
07. }]}Atribut artikel sendiri ditransfer ke data dan hubungan kunci ditambahkan. Kami menempatkan semua koneksi dalam kunci ini. Dengan demikian, dengan satu permintaan, kami menerima semua data yang sebelumnya menerima 11 permintaan. Ini adalah hack kehidupan keren yang memecahkan masalah dengan N +1 di front end dengan baik.
Masalah duplikasi data
Misalkan Anda ingin menampilkan 10 artikel yang menunjukkan penulis, semua artikel memiliki satu penulis, tetapi objek dengan penulisnya sangat besar (misalnya, nama belakang yang sangat panjang, yang membutuhkan satu megabyte). Satu penulis dimasukkan dalam jawaban 10 kali, dan 10 inklusi dari penulis yang sama dalam jawaban akan memakan waktu 10 MB.
Karena semua objek adalah sama, masalah yang satu penulis dimasukkan 10 kali (10 MB) diselesaikan dengan bantuan normalisasi, yang digunakan dalam database. Di ujung depan, Anda juga dapat menggunakan normalisasi dalam bekerja dengan API - ini sangat keren.
01. /1.1 200
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": "JSON API" },
05. "relationships": { ... }
06. "author": { "id": 1, "type": "people" } }
07. }, ... ]
08. }Kami menandai semua entitas dengan beberapa tipe (ini adalah tipe representasi, tipe sumber daya). Roy Fielding memperkenalkan konsep sumber daya, yaitu, mereka meminta artikel - menerima “artikel”. Dalam hubungan, kami menempatkan tautan ke tipe orang, yaitu, kami masih memiliki sumber daya orang di tempat lain. Dan sumber daya itu sendiri kami ambil dalam kunci yang terpisah, yang terletak pada tingkat yang sama dengan data.
01. /1.1 200
02. {
03. "data": [ ... ],
04. "included": [{
05. "id": 1, "type": "people",
06. "attributes": { "name": "Avdeev" }
07. }]
08. }Dengan demikian, semua entitas terkait dalam satu kejadian termasuk dalam kunci khusus yang disertakan. Kami hanya menyimpan tautan, dan entitas itu sendiri disertakan.
Ukuran permintaan berkurang. Ini adalah hack kehidupan yang tidak diketahui oleh back-end awal. Dia akan mencari tahu nanti ketika dia perlu memecahkan API.
Tidak semua bidang sumber daya diperlukan
Peretasan kehidupan berikut dapat diterapkan ketika tidak semua bidang sumber daya diperlukan. Ini dilakukan dengan menggunakan parameter GET khusus, yang mencantumkan atribut yang akan dikembalikan, dipisahkan oleh koma. Misalnya, artikelnya besar, dan mungkin ada megabita di bidang konten, dan kami hanya perlu menampilkan daftar tajuk - kami tidak memerlukan konten dalam respons.
GET /articles ?fields[article]=title /1.101. /1.1 200 OK
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": " JSON API" },
05. }, ... ]
06. }Jika Anda perlu, misalnya, juga tanggal publikasi, Anda dapat menulis “tanggal publikasi” yang dipisahkan koma. Sebagai tanggapan, dua bidang akan datang dalam atribut. Ini adalah konvensi yang dapat digunakan sebagai alat anti-bikeshedding.
Cari berdasarkan artikel
Seringkali kita membutuhkan pencarian dan filter. Ada konvensi untuk ini - filter khusus GET parameter:
●
GET /articles ?filters[search]=api HTTP/1.1 - pencarian;
●
GET /articles ?fiIters[from_date]=1538332156 HTTP/1.1 - unduh artikel dari tanggal tertentu;
●
GET /articles ?filters[is_published]=true HTTP/1.1 - unduh artikel yang baru saja diterbitkan;
●
GET /articles ?fiIters[author]=1 HTTP/1.1 - unduh artikel dengan penulis pertama.
Menyortir Artikel
●
GET /articles ?sort=title /1.1 - menurut judul;
●
GET /articles ?sort=published_at HTTP/1.1 - berdasarkan tanggal publikasi;
●
GET /articles ?sort=-published_at HTTP/1.1 - menurut tanggal publikasi di arah yang berlawanan;
●
GET /articles ?sort=author,-publisbed_at HTTP/1.1 - pertama oleh penulis, kemudian menurut tanggal publikasi dalam arah yang berlawanan, jika artikel berasal dari penulis yang sama.
Perlu mengubah URL
Solusi: hypermedia, yang sudah saya sebutkan, bisa dilakukan sebagai berikut. Jika kita ingin objek (sumber daya) mendeskripsikan diri, klien dapat memahami melalui hypermedia apa yang dapat dilakukan dengannya, dan server dapat berkembang secara independen dari klien, maka kita dapat menambahkan tautan ke daftar artikel, ke artikel itu sendiri menggunakan kunci tautan khusus :
01. GET /articles /1.1
02. {
03. "data": [{
04. ...
05. "links": { "self": "http://localhost/articles/1" },
06. "relationships": { ... }
07. }],
08. "links": { "self": " http://localhost/articles " }
09. }
Atau yang terkait, jika kami ingin memberi tahu klien cara mengunggah komentar pada artikel ini:
01. ...
02. "relationships": {
03. "comments": {
04. "links": {
05. "self": "http://localhost/articles/l/relationships/comments ",
06. "related": " http://localhost/articles/l/comments "
07. }
08. }
09. }Klien melihat ada tautan, mengikutinya, memuat komentar. Jika tidak ada tautan, maka tidak ada komentar. Ini nyaman, tetapi sangat sedikit yang melakukannya. Fielding datang dengan prinsip-prinsip REST, tetapi tidak semuanya memasuki industri kami. Kami terutama menggunakan dua atau tiga.
Pada 2013, semua peretasan yang saya ceritakan, Steve Klabnik digabungkan ke dalam spesifikasi API JSON dan terdaftar sebagai
jenis media baru di atas JSON . Jadi pengembang backend junior kami, secara bertahap berkembang, datang ke API JSON.
API JSON
Semuanya dijelaskan secara rinci di
http://jsonapi.org/implementations/ : bahkan ada daftar 170 implementasi spesifikasi yang berbeda untuk 32 bahasa pemrograman - dan ini hanya ditambahkan ke katalog. Perpustakaan, parser, serializers, dll. Sudah ditulis.
Karena spesifikasi ini adalah open source, semua orang berinvestasi di dalamnya. Saya, antara lain, menulis sesuatu sendiri. Saya yakin ada banyak orang seperti itu. Anda dapat bergabung dengan proyek ini sendiri.
API JSON Pro
Spesifikasi JSON API memecahkan sejumlah masalah -
kesepakatan bersama untuk semua orang . Karena ada kesepakatan umum, kami
tidak berdebat di dalam tim - gudang sepeda didokumentasikan. Kami memiliki kesepakatan tentang bahan apa yang membuat gudang sepeda dan cara melukisnya.
Sekarang, ketika pengembang melakukan sesuatu yang salah dan saya melihatnya, saya tidak memulai diskusi, tetapi saya mengatakan: "Tidak oleh JSON API!" dan tunjukkan di tempat dalam spesifikasi. Mereka membenci saya di perusahaan, tetapi lambat laun menjadi terbiasa, dan semua orang mulai menyukai API JSON. Kami membuat layanan standar baru sesuai dengan spesifikasi ini. Kami memiliki kunci tanggal, kami siap untuk menambahkan meta, termasuk kunci. Ada filter parameter GET dicadangkan untuk filter. Kami tidak memperdebatkan apa yang disebut filter - kami menggunakan spesifikasi ini. Ini menjelaskan cara membuat URL.
Karena kami tidak berdebat, tetapi melakukan tugas bisnis,
pengembangan produktivitas lebih tinggi . Kami memiliki spesifikasi yang dijelaskan, pengembang membaca backend, membuat API, kami mengacaukannya - pelanggan senang.
Masalah populer telah diselesaikan , misalnya, dengan pagination. Ada banyak petunjuk dalam spec.
Karena ini JSON (terima kasih kepada Douglas Crockford untuk format ini), ini lebih ringkas daripada XML, sangat
mudah dibaca dan dimengerti .
Fakta bahwa ini adalah
Open Source dapat menjadi plus dan minus, tapi saya suka Open Source.
Kontra JSON API
Objek telah berkembang (tanggal, atribut, termasuk, dll.) -
frontend perlu mengurai jawaban: dapat beralih ke array, berjalan di sekitar objek dan tahu bagaimana mengurangi bekerja. Tidak semua pengembang pemula mengetahui hal-hal rumit ini. Ada perpustakaan serializers / deserializers, Anda dapat menggunakannya. Secara umum, ini hanya bekerja dengan data, tetapi objeknya besar.
Dan
backend memiliki rasa sakit:
- Kontrol sarang - termasuk dapat dinaiki sangat jauh;
- Kompleksitas permintaan basis data - mereka terkadang dibangun secara otomatis, dan ternyata sangat sulit;
- Keamanan - Anda dapat naik ke hutan, terutama jika Anda menghubungkan semacam perpustakaan;
- Spesifikasi sulit dibaca. Dia berbahasa Inggris, dan itu membuat takut beberapa orang, tetapi lambat laun semua orang terbiasa dengan itu;
- Tidak semua perpustakaan mengimplementasikan spesifikasi dengan baik - ini adalah masalah Open Source.
Jebakan API JSON
Sedikit hardcore.
Jumlah hubungan dalam masalah ini tidak terbatas. Jika kami menyertakan, meminta artikel, menambahkan komentar, maka sebagai tanggapan kami akan menerima semua komentar dari artikel ini. Ada 10.000 komentar - dapatkan 10.000 komentar:
GET /articles/1?include=comments /1.101. ...
02. "relationships": {
03. "comments": {
04. "data": [0 ... ∞]
05. }
06. }Dengan demikian, sebenarnya 5 MB datang ke permintaan kami sebagai tanggapan: “Ada tertulis dalam spesifikasi - perlu memformulasikan ulang permintaan dengan benar:
GET /comments? filters[article]=1& page[size]=30 HTTP/1.101. {
02. "data": [0 ... 29]
03. }Kami meminta komentar dengan filter berdasarkan artikel, katakan: "30 buah, tolong" dan dapatkan 30 komentar. Ini adalah ambiguitas.
Hal-hal yang sama dapat dirumuskan secara ambigu :
●
GET /articles/1 ?include=comments HTTP/1.1 - minta artikel dengan komentar;
●
GET /articles/1/comments HTTP/1.1 - minta komentar pada artikel;
●
GET /comments ?filters[article]=1 HTTP/1.1 - minta komentar dengan filter berdasarkan artikel.
Ini adalah satu dan sama - data yang sama, yang diperoleh dengan cara yang berbeda, ada beberapa ambiguitas. Perangkap ini tidak segera terlihat.
Hubungan polimorfik satu-ke-banyak masuk ke REST dengan sangat cepat.
01. GET /comments?include=commentable /1.1
02.
03. ...
04. "relationships": {
05. "commentable" : {
06. "data": { "type": "article", "id": "1″ }
07. }
08. }Ada koneksi polimorfik yang dapat dikomentari di backend - itu merangkak keluar ke REST. Jadi itu harus terjadi, tetapi bisa disamarkan. Anda tidak dapat menyamarkannya di API JSON - itu akan keluar.
Hubungan banyak-ke-banyak yang kompleks dengan opsi tingkat lanjut . Juga, semua tabel penghubung keluar:
01. GET /users?include =users_comments /1.1
02.
03. ...
04. "relationships": {
05. "users_comments": {
06. "data": [{ "type": "users_comments", "id": "1″ }, ...]
07. },
08. }Kesombongan
Swagger adalah alat penulisan dokumentasi online.
Katakanlah pengembang backend kami diminta untuk menulis dokumentasi untuk API-nya, dan ia menulisnya. Ini mudah jika APInya sederhana. Jika ini adalah JSON API, Swagger tidak dapat ditulis dengan mudah.
Contoh: Toko hewan peliharaan kesombongan. Setiap metode dapat dibuka, lihat respons dan contoh.
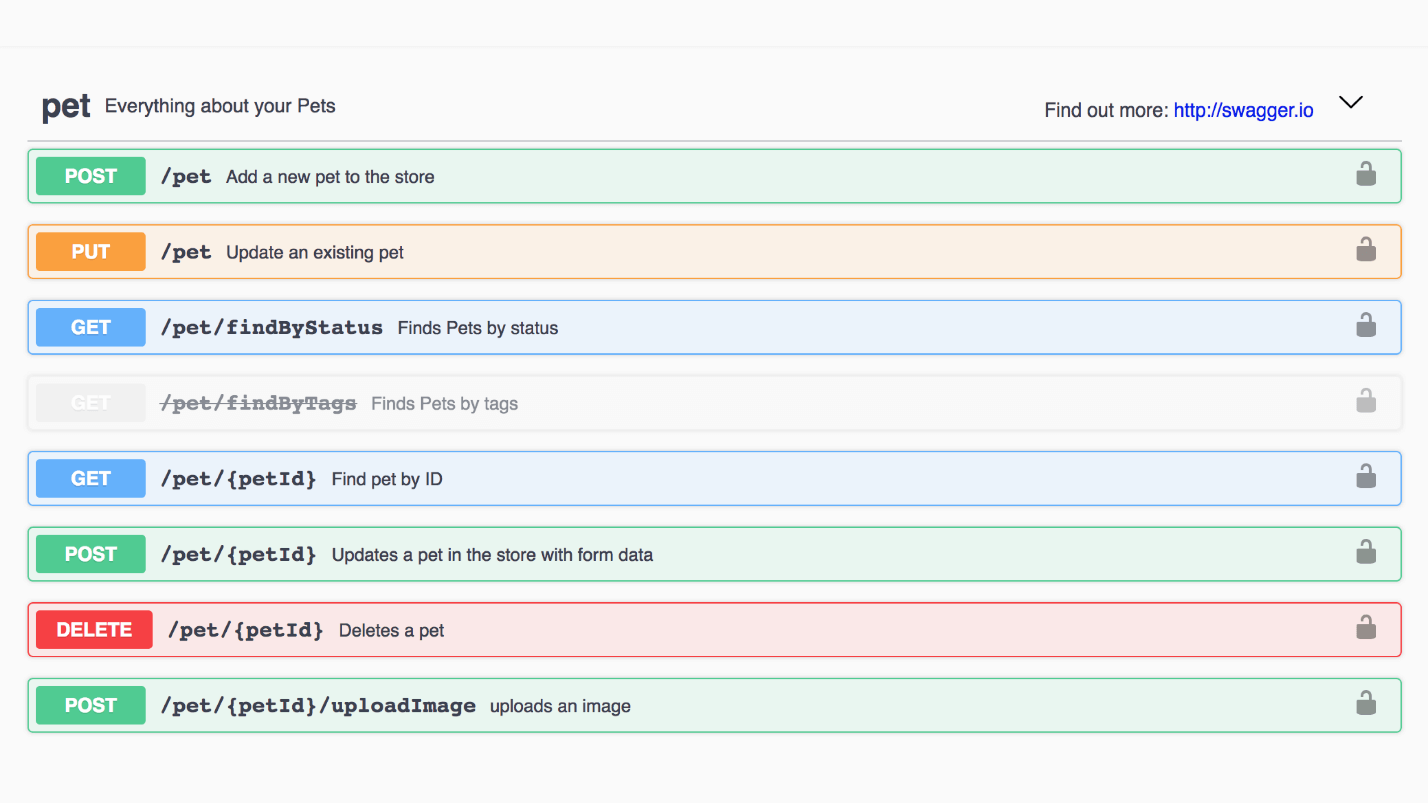
Ini adalah contoh dari model Pet. Ini adalah antarmuka yang keren, semuanya mudah dibaca.
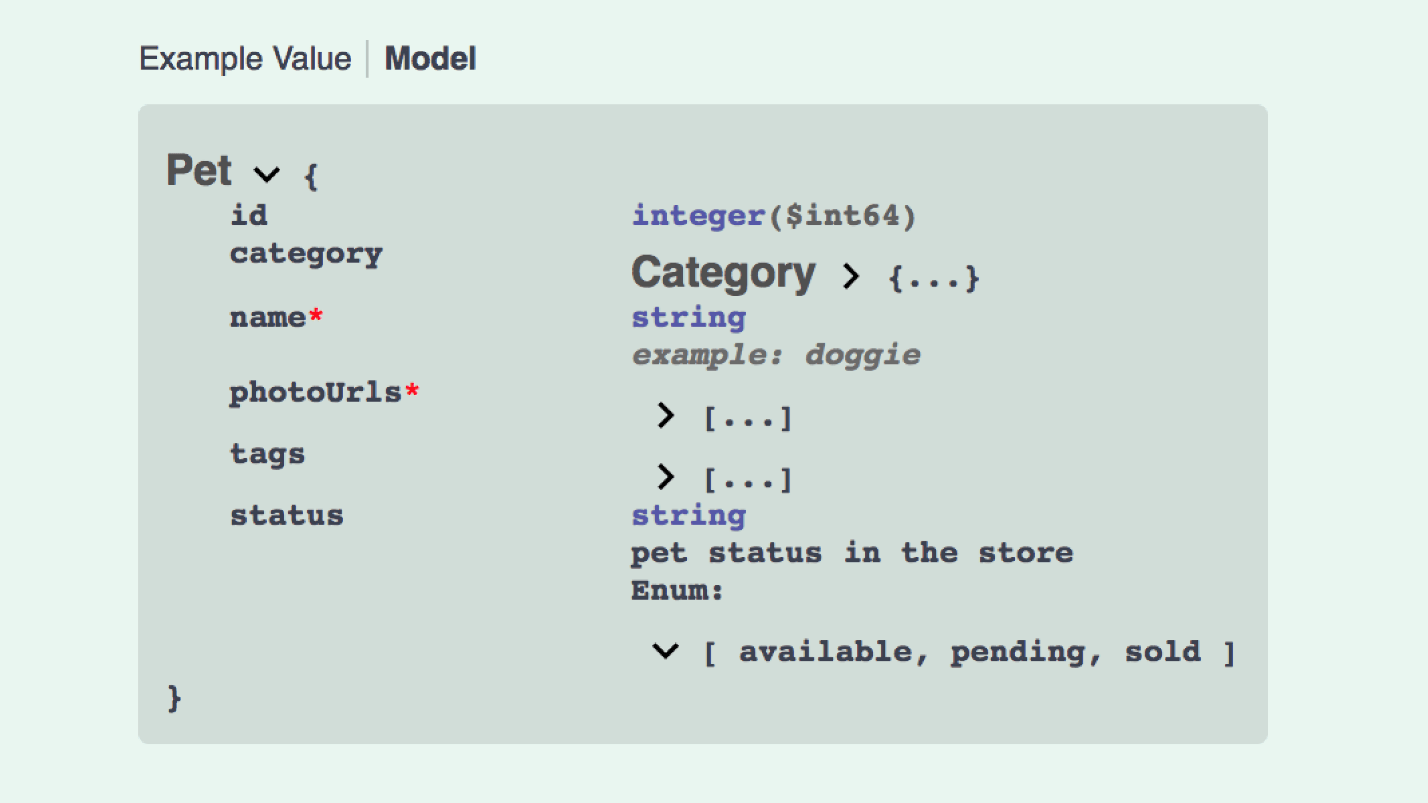
Dan ini adalah bagaimana penciptaan model API JSON terlihat seperti:

Ini tidak terlalu bagus. Kami membutuhkan data, dalam data sesuatu dengan hubungan, termasuk berisi 5 jenis model, dll. Anda dapat menulis Swagger, Open API adalah hal yang kuat, tetapi rumit.
Alternatif
Ada spesifikasi OData, yang muncul sedikit lebih lambat - pada tahun 2015. Ini adalah "Cara terbaik untuk REST", seperti yang dijamin situs web resmi. Ini terlihat seperti ini:
01. GET http://services.odata.org/v4/TripRW/People HTTP/1.1 - DAPATKAN permintaan;
02. OData-Version: 4.0 - header khusus dengan versi;
03. OData-MaxVersion: 4.0 - Header Versi Khusus Kedua
Jawabannya terlihat seperti ini:
01. HTTP/1.1 200 OK
02. Content-Type: application/json; odata.metadata=minimal
03. OData-Version: 4.0
04. {
05. '@odata.context': 'http://services.odata.org/V4/
06. '@odata.nextLink' : 'http://services.odata.org/V4/
07. 'value': [{
08. '@odata.etag': 1W/108D1D5BD423E51581′,
09. 'UserName': 'russellwhyte',
10. ...
Berikut ini adalah aplikasi / json dan objek yang diperluas.
Kami tidak menggunakan OData, pertama, karena sama dengan API JSON, tetapi tidak ringkas. Ada benda besar dan menurut saya semuanya jauh lebih buruk dibaca. OData juga keluar di Open Source, tetapi lebih rumit.
Bagaimana dengan GraphQL?
Tentu saja, ketika kami mencari format API baru, kami mengalami hype ini.
●
Ambang entri tinggi.Dari sudut pandang frontend, semuanya terlihat keren, tetapi Anda tidak bisa membuat pengembang baru menulis GraphQL, karena Anda harus mempelajarinya terlebih dahulu. Ini seperti SQL - Anda tidak dapat langsung menulis SQL, setidaknya Anda harus membaca apa itu, melalui tutorial, yaitu, ambang entri meningkat.
●
Efek dari big bang.Jika tidak ada API dalam proyek ini, dan kami mulai menggunakan GraphQL, setelah sebulan kami menyadari bahwa itu tidak cocok untuk kami, itu akan terlambat. Harus menulis kruk. Anda dapat berevolusi dengan API JSON atau OData - RESTful paling sederhana, semakin meningkat, berubah menjadi API JSON.
●
Neraka di backend.GraphQL memanggil neraka di backend - satu lawan satu, sama seperti API JSON yang diimplementasikan sepenuhnya, karena GraphQL mendapatkan kendali penuh atas kueri, dan ini adalah perpustakaan, dan Anda perlu menyelesaikan banyak pertanyaan:
- kontrol bersarang;
- rekursi
- pembatasan frekuensi;
- kontrol akses.
Alih-alih kesimpulan
Saya sarankan berhenti berdebat tentang gudang sepeda, dan gunakan alat anti-bikeshedding sebagai spesifikasi dan buat API dengan spesifikasi yang bagus.
Untuk menemukan standar Anda dalam memecahkan masalah gudang sepeda, Anda dapat melihat tautan ini:
●
http://jsonapi.org●
http://www.odata.org●
https://graphgl.org●
http://xmlrpc.scripting.com●
https://www.jsonrpc.org: alexey-avdeev.com github .
, Frontend Conf , 27 28 ++ . , .
? ? ? , ? !
, , , , .