Dalam artikel ini Anda akan mempelajari semua tentang perpustakaan Babel, dan yang paling penting - cara membuatnya kembali, dan memang perpustakaan mana pun.
Mari kita mulai dengan kutipan dari
Perpustakaan Babel oleh
Luis Borges .
Kutipan“Alam semesta - beberapa menyebutnya Perpustakaan - terdiri dari sejumlah besar galeri hexagonal yang tak terbatas, dengan ruang ventilasi luas yang dikelilingi oleh rel rendah. Dari setiap segi enam, dua lantai atas dan bawah terlihat, hingga tak terbatas. ”
“Perpustakaan adalah sebuah bola, pusat tepatnya di salah satu segi enam, dan permukaannya tidak dapat diakses. Di setiap dinding setiap segi enam ada lima rak, di setiap rak ada tiga puluh dua buku dengan format yang sama, setiap buku memiliki empat ratus sepuluh halaman, setiap halaman memiliki empat puluh baris, setiap baris berisi sekitar delapan puluh huruf hitam. Ada beberapa huruf di tulang belakang buku ini, tetapi mereka tidak menentukan atau memberi tahu apa yang akan dikatakan halaman-halaman itu. Ketidakcocokan ini, saya tahu, dulu tampak misterius. "
Jika Anda memasukkan segi enam acak, naik ke dinding mana pun, lihat rak apa saja dan ambil buku yang paling Anda sukai, maka kemungkinan besar Anda akan kesal. Bagaimanapun, Anda diharapkan untuk mencari tahu tentang arti kehidupan di sana, tetapi Anda melihat beberapa karakter yang aneh. Tapi jangan cepat kesal! Sebagian besar buku tidak ada artinya, karena mereka adalah pencarian kombinatorial dari semua varian yang mungkin dari dua puluh lima karakter (
ini adalah alfabet yang digunakan Borges di perpustakaannya, tetapi kemudian pembaca akan mengetahui bahwa ada sejumlah karakter di perpustakaan ). Hukum utama perpustakaan adalah bahwa tidak ada dua buku yang benar-benar identik di dalamnya, sehingga jumlahnya terbatas, dan perpustakaan juga suatu hari nanti akan berakhir. Borges percaya bahwa perpustakaan itu berkala:
Kutipan“Mungkin rasa takut dan usia tua menipu saya, tetapi saya berpikir bahwa umat manusia - satu-satunya - dekat dengan kepunahan, dan Perpustakaan akan bertahan: diterangi, tidak berpenghuni, tak ada habisnya, sama sekali tidak bergerak, diisi dengan volume yang berharga, tidak berguna, tidak rusak, misterius. Saya hanya menulis tanpa akhir. Saya tidak menetapkan kata ini karena cinta untuk retorika; Saya pikir logis untuk mengasumsikan bahwa dunia ini tidak ada habisnya. Mereka yang menganggapnya terbatas mengakui bahwa di suatu tempat di koridor jarak, dan tangga, dan segi enam dapat berakhir karena alasan yang tidak diketahui - asumsi seperti itu tidak masuk akal. Mereka yang membayangkannya tanpa batas lupa bahwa jumlah buku yang mungkin terbatas. Saya berani mengusulkan solusi untuk masalah kuno ini: Perpustakaan tidak terbatas dan berkala. Jika pengembara abadi memulai perjalanan ke segala arah, ia akan dapat memverifikasi setelah berabad-abad bahwa buku-buku yang sama diulang dalam kekacauan yang sama (yang, ketika diulang, menjadi urutan - Orde). Harapan anggun ini mencerahkan kesepian saya. "
Dibandingkan dengan omong kosong, ada sangat sedikit buku yang isinya setidaknya dapat dipahami oleh seseorang, tetapi ini tidak mengubah fakta bahwa perpustakaan memuat semua teks yang pernah dan akan ditemukan oleh seseorang. Dan selain itu, sejak kecil Anda terbiasa mempertimbangkan beberapa urutan simbol yang bermakna, sementara yang lain tidak. Bahkan, dalam konteks perpustakaan, tidak ada perbedaan di antara mereka. Tetapi apa yang masuk akal memiliki persentase yang jauh lebih rendah, dan kami menyebutnya bahasa. Ini adalah sarana komunikasi antar manusia. Bahasa apa pun hanya berisi beberapa puluh ribu kata, yang kita ketahui 70% dari kekuatannya, maka ternyata kita tidak bisa menafsirkan sebagian besar pencarian kombinatorial buku. Dan seseorang menderita
apophenia dan bahkan dalam rangkaian karakter acak melihat makna tersembunyi. Tapi ini ide yang bagus untuk
steganografi ! Baiklah, saya terus membahas topik ini di komentar.
Sebelum melanjutkan dengan implementasi perpustakaan ini, saya akan mengejutkan Anda dengan fakta yang menarik: jika Anda ingin membuat kembali perpustakaan Babel Louis Borges, Anda tidak akan berhasil, karena volumenya melebihi volume Alam Semesta yang kelihatan 10 ^ 611338 (!) Times. Dan tentang apa yang akan terjadi di perpustakaan yang lebih besar, saya bahkan takut untuk berpikir.
Implementasi perpustakaan
Deskripsi modul
Pengantar kecil kami sudah berakhir. Tetapi ini bukan tanpa makna: sekarang Anda mengerti seperti apa perpustakaan Babel, dan membaca hanya akan lebih menarik. Tapi saya akan menjauh dari ide asli, saya ingin membuat perpustakaan "universal", yang akan dibahas nanti. Saya akan menulis dalam JavaScript di bawah Node.js. Apa yang harus dapat dilakukan perpustakaan?
- Temukan teks yang diinginkan dengan cepat dan tampilkan lokasinya di perpustakaan
- Tentukan judul buku
- Temukan buku dengan judul yang tepat dengan cepat
Selain itu, itu harus bersifat universal, yaitu salah satu parameter pustaka dapat diubah jika saya mau. Baiklah, saya pikir saya pertama-tama akan menunjukkan seluruh kode modul, kita akan menganalisisnya secara terperinci, melihat cara kerjanya, dan saya akan mengatakan beberapa kata.
Repositori GithubFile utama adalah index.js, seluruh logika perpustakaan dijelaskan di sana, saya akan menjelaskan isi file ini.
let sha512 = require(`js-sha512`);
Kami menghubungkan modul yang mengimplementasikan
algoritma hasa sha512 . Ini mungkin tampak aneh bagi Anda, tetapi itu tetap berguna bagi kami.
Apa output dari modul kami? Ini mengembalikan fungsi, panggilan yang akan mengembalikan objek perpustakaan dengan semua metode yang diperlukan. Kami dapat mengembalikannya segera, tetapi mengelola pustaka tidak akan begitu nyaman ketika kami memberikan parameter ke fungsi dan mendapatkan pustaka "yang diperlukan". Ini akan memungkinkan kita untuk membuat perpustakaan "universal". Karena saya mencoba menulis dalam gaya ES6, fungsi panah saya menerima objek sebagai parameter, yang selanjutnya akan dihancurkan menjadi variabel yang diperlukan:
module.exports = ({ lengthOfPage = 4819, lengthOfTitle = 31, digs = '0123456789abcdefghijklmnopqrstuvwxyz', alphabet = ', .', wall = 5, shelf = 7, volume = 31, page = 421, } = {}) => {
Sekarang mari kita periksa parameternya. Sebagai parameter numerik standar, saya memutuskan untuk memilih bilangan prima, karena bagi saya tampaknya akan lebih menarik.
- lengthOfPage - jumlah, jumlah karakter pada satu halaman. Standarnya adalah 4819. Jika kita memfaktorkan angka ini, kita mendapatkan 61 dan 79. 61 baris dengan 79 karakter, atau sebaliknya, tetapi saya lebih suka opsi pertama.
- lengthOfTitle - jumlah, jumlah karakter dalam judul judul buku.
- digs - string, kemungkinan digit angka dengan basis sama dengan panjang string ini. Untuk apa angka ini? Ini akan berisi nomor (pengidentifikasi) dari segi enam yang ingin kita tuju. Secara default, ini adalah huruf latin kecil dan angka 0-9. Sebagian besar teks dikodekan di sini, sehingga akan menjadi sejumlah besar - beberapa ribu bit (tergantung pada jumlah karakter pada halaman), tetapi akan diproses karakter demi karakter.
- alfabet - string, karakter yang ingin kita lihat di perpustakaan. Itu akan diisi dengan mereka. Agar semuanya berfungsi dengan benar, jumlah karakter dalam alfabet harus sama dengan jumlah karakter dalam string dengan kemungkinan digit nomor yang mengidentifikasi segi enam.
- nomor dinding, nomor dinding maksimum, standar 5
- nomor rak , jumlah rak maksimum, standar 7
- volume - angka, nomor buku maksimum, secara default 31
- halaman - nomor, nomor halaman maksimum, standar 421
Seperti yang Anda lihat, ini sedikit seperti perpustakaan Babilonia Luis Borges yang asli. Tetapi saya telah mengatakan lebih dari sekali bahwa kita akan membuat perpustakaan "universal" yang dapat menjadi cara kita ingin melihatnya (oleh karena itu, nomor hex dapat diartikan dengan cara yang berbeda, misalnya, hanya pengidentifikasi dari beberapa tempat di mana yang diinginkan disimpan informasi). Perpustakaan Babilonia hanyalah salah satunya. Tetapi semuanya memiliki banyak kesamaan - satu algoritma bertanggung jawab atas kinerjanya, yang sekarang akan dibahas.
Algoritma pencarian halaman dan tampilan
Ketika kami pergi ke beberapa alamat, kami melihat isi halaman. Jika kita pergi ke alamat yang sama lagi, kontennya harus persis sama. Properti perpustakaan ini menyediakan algoritma untuk menghasilkan angka pseudorandom -
metode kongruen linier . Ketika kita perlu memilih karakter untuk menghasilkan alamat atau, sebaliknya, isi halaman, itu akan membantu kita, dan jumlah halaman, rak, dll akan digunakan sebagai biji-bijian. Konfigurasi PRNG saya: m = 2 ^ 32 (4294967296), a = 22695477, c = 1. Saya juga ingin menambahkan bahwa dalam implementasi kami hanya prinsip pembangkitan angka yang tersisa dari metode kongruen linier, sisanya diubah. Kami melanjutkan daftar program lebih lanjut:
Kode module.exports = ({ lengthOfPage = 4819, lengthOfTitle = 31, digs = '0123456789abcdefghijklmnopqrstuvwxyz', alphabet = ', .', wall = 5, shelf = 7, volume = 31, page = 421, } = {}) => { let seed = 13;
Seperti yang Anda lihat, butiran PRNG berubah setelah setiap penerimaan nomor, dan hasilnya langsung tergantung pada titik referensi yang disebut - butir, setelah angka akan menarik bagi kami. (kami menghasilkan alamat atau mendapatkan konten halaman)
Fungsi
getHash akan membantu kami menghasilkan titik referensi. Kami baru saja mendapatkan hash dari beberapa data, mengambil 7 karakter, menerjemahkan ke dalam sistem angka desimal dan Anda selesai!
Fungsi
mod berperilaku sama dengan operator%. Tetapi jika dividen adalah <0 (situasi seperti itu dimungkinkan), fungsi
mod akan mengembalikan angka positif karena struktur khusus, kita memerlukan ini untuk memilih karakter dari string
alfabet dengan benar ketika menerima konten halaman di alamat.
Dan potongan terakhir dari kode makanan penutup adalah objek perpustakaan yang dikembalikan:
Kode return { wall, shelf, volume, page, lengthOfPage, lengthOfTitle, search(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), page = pad(`${(Math.random()* this.page + 1 ^ 0)}`, 3), locHash = getHash(`${wall}${shelf}${volume}${page}`), hex = ``, depth = Math.random() * (this.lengthOfPage - searchStr.length) ^ 0; for (let i = 0; i < depth; i++){ searchStr = alphabet[Math.random() * alphabet.length ^ 0] + searchStr; } seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]] || -1, rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}-${+page}`; }, searchExactly(text) { const pos = Math.random() * (this.lengthOfPage - text.length) ^ 0; return this.search(`${` `.repeat(pos)}${text}${` `.repeat(this.lengthOfPage - (pos + text.length))}`); }, searchTitle(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), locHash = getHash(`${wall}${shelf}${volume}`), hex = ``; searchStr = searchStr.substr(0, this.lengthOfTitle); searchStr = searchStr.length == this.lengthOfTitle ? searchStr : `${searchStr}${` `.repeat(this.lengthOfTitle - searchStr.length)}`; seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]], rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}`; }, getPage(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}${pad(addressArray[4], 3)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfPage) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfPage); }, getTitle(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfTitle) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfTitle); } };
Pada awalnya, kami menulis properti perpustakaan yang saya jelaskan sebelumnya. Anda dapat mengubahnya bahkan setelah fungsi utama dipanggil (yang, pada prinsipnya, dapat disebut konstruktor, tetapi kode saya lemah mirip dengan implementasi kelas perpustakaan, jadi saya akan membatasi diri saya pada kata "main"). Mungkin perilaku ini tidak sepenuhnya memadai, tetapi fleksibel. Sekarang pergi ke setiap metode.
Metode pencarian
search(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random() * this.volume + 1 ^ 0)}`, 2), page = pad(`${(Math.random() * this.page + 1 ^ 0)}`, 3), locHash = getHash(`${wall}${shelf}${volume}${page}`), hex = ``, depth = Math.random() * (this.lengthOfPage - searchStr.length) ^ 0; for (let i = 0; i < depth; i++){ searchStr = alphabet[Math.random() * alphabet.length ^ 0] + searchStr; } seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]] || -1, rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}-${+page}`; }
Mengembalikan alamat string
searchStr di perpustakaan. Untuk melakukan ini, pilih
dinding, rak, volume, halaman secara acak.
volume dan
halaman juga diisi dengan nol dengan panjang yang diinginkan. Selanjutnya, gabungkan keduanya menjadi string untuk diteruskan ke fungsi
getHash .
LocHash yang dihasilkan adalah titik awal, mis. biji-bijian.
Untuk ketidakpastian yang lebih besar, kami menambah
kedalaman searchStr dengan karakter pseudorandom dari alfabet, mengatur seed
seed menjadi
locHash . Pada tahap ini, tidak masalah bagaimana kami melengkapi baris, sehingga Anda dapat menggunakan PRNG JavaScript bawaan, ini tidak penting. Anda dapat sepenuhnya mengabaikannya sehingga hasil yang menarik bagi kami selalu berada di bagian atas halaman.
Satu-satunya yang tersisa adalah menghasilkan pengidentifikasi segi enam. Untuk setiap karakter string
searchStr ,
kami mengeksekusi algoritma:
- Dapatkan nomor karakter indeks dalam alfabet dari objek alphabetIndexes . Jika tidak, kembali -1, tetapi jika ini terjadi, Anda pasti melakukan sesuatu yang salah.
- Hasilkan rand angka pseudo-acak menggunakan PRNG kami, dalam kisaran dari 0 hingga panjang alfabet.
- Hitung indeks baru, yang dihitung sebagai jumlah dari jumlah indeks simbol dan nomor acak semu, dibagi modulo panjang penggalian .
- Dengan demikian, kami mendapat digit pengidentifikasi segi enam - newChar (mengambilnya dari penggalian ).
- Tambahkan newChar ke hex identifier hex
Setelah menyelesaikan generasi
hex , kami mengembalikan alamat lengkap tempat di mana baris yang diinginkan terkandung. Komponen alamat dipisahkan oleh tanda hubung.
Metode Pencarian Tepat
searchExactly(text) { const pos = Math.random() * (this.lengthOfPage - text.length) ^ 0; return this.search(`${` `.repeat(pos)}${text}${` `.repeat(this.lengthOfPage - (pos + text.length))}`); }
Metode ini melakukan hal yang sama dengan metode
pencarian , tetapi mengisi semua ruang kosong (membuat
pencarian string
searchStr dengan panjang karakter
lengthOfPage ). Saat melihat halaman seperti itu, akan muncul bahwa tidak ada apa-apa di sana selain teks Anda.
Metode SearchTitle
searchTitle(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), locHash = getHash(`${wall}${shelf}${volume}`), hex = ``; searchStr = searchStr.substr(0, this.lengthOfTitle); searchStr = searchStr.length == this.lengthOfTitle ? searchStr : `${searchStr}${` `.repeat(this.lengthOfTitle - searchStr.length)}`; seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]], rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}`; }
Metode
searchTitle mengembalikan alamat buku yang disebut
searchStr . Di dalam, sangat mirip dengan
pencarian . Perbedaannya adalah ketika menghitung
locHash kita tidak menggunakan halaman untuk mengikat namanya ke buku. Seharusnya tidak tergantung pada halaman.
searchStr dipotong menjadi
lengthOfTitle dan diisi dengan spasi jika perlu. Demikian pula, pengidentifikasi segi enam dihasilkan dan alamat yang diterima dikembalikan. Harap perhatikan bahwa tidak ada halaman di dalamnya, seperti ketika mencari alamat teks arbitrer yang tepat. Jadi, jika Anda ingin mencari tahu apa yang ada di buku dengan nama yang Anda buat, tentukan halaman yang ingin Anda tuju.
Metode GetPage
getPage(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}${pad(addressArray[4], 3)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfPage) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfPage); }
Kebalikan dari metode
pencarian . Tugasnya adalah mengembalikan konten halaman ke alamat yang ditentukan. Untuk melakukan ini, kami mengonversi alamat ke array menggunakan pemisah "-". Sekarang kami memiliki berbagai komponen alamat: pengidentifikasi segi enam, dinding, rak, buku, halaman. Kami menghitung
locHash dengan cara yang sama seperti yang kami lakukan dalam metode
pencarian . Kami mendapatkan nomor yang sama ketika menghasilkan alamat. Ini berarti bahwa PRNG akan menghasilkan angka yang sama, perilaku inilah yang memastikan kebalikan dari transformasi kami terhadap teks sumber. Untuk menghitungnya, kami melakukan algoritme pada setiap karakter (de facto, ini adalah digit) dari pengidentifikasi segi enam:
- Kami menghitung indeks dalam penggalian string. Ambillah dari digsIndexes .
- Dengan menggunakan PRNG, kita menghasilkan rand angka pseudo-acak dalam kisaran 0 ke dasar sistem angka dalam jumlah besar, sama dengan panjang string yang berisi digit dari angka cantik ini. Semuanya jelas.
- Kami menghitung posisi simbol dari teks sumber newIndex sebagai perbedaan antara indeks dan rand , dibagi modulo panjang alfabet. Mungkin saja perbedaannya negatif, maka modulo divisi biasa akan memberikan indeks negatif, yang tidak sesuai dengan kami, jadi kami menggunakan versi modifikasi dari divisi modulo. (Anda dapat mencoba opsi mengambil nilai absolut dari rumus di atas, ini juga memecahkan masalah angka negatif, tetapi dalam praktiknya ini belum diuji)
- Karakter teks halaman adalah newChar , kami mendapatkan indeks dari alfabet.
- Tambahkan karakter teks ke hasilnya.
Hasil yang diperoleh pada tahap ini tidak akan selalu mengisi seluruh halaman, jadi kami akan menghitung butir baru dari hasil saat ini dan mengisi ruang kosong dengan karakter dari alfabet. PRNG membantu kami dalam memilih simbol.
Ini melengkapi perhitungan konten halaman, kami mengembalikannya, tidak lupa untuk memotong panjang maksimal. Mungkin pengidentifikasi segi enam itu besar di alamat input.
Metode GetTitle
getTitle(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfTitle) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfTitle); }
Nah, ceritanya sama. Bayangkan Anda membaca deskripsi metode sebelumnya, hanya ketika menghitung butir PRNG Anda tidak memperhitungkan nomor halaman, dan menambahkan dan memotong hasilnya ke panjang maksimum nama buku -
lengthOfTitle .
Menguji modul untuk membuat perpustakaan
Setelah kita memeriksa prinsip pengoperasian perpustakaan seperti Babilonia - inilah saatnya untuk mencoba semuanya dalam praktik. Saya akan menggunakan konfigurasi sedekat mungkin dengan yang dibuat oleh Louis Borges. Kami akan mencari frasa sederhana "habr.com":
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
Jalankan, hasilnya:

Saat ini, itu tidak memberi kita apa-apa. Tapi mari kita cari tahu apa yang tersembunyi di balik alamat ini! Kode akan seperti ini:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
Hasil:
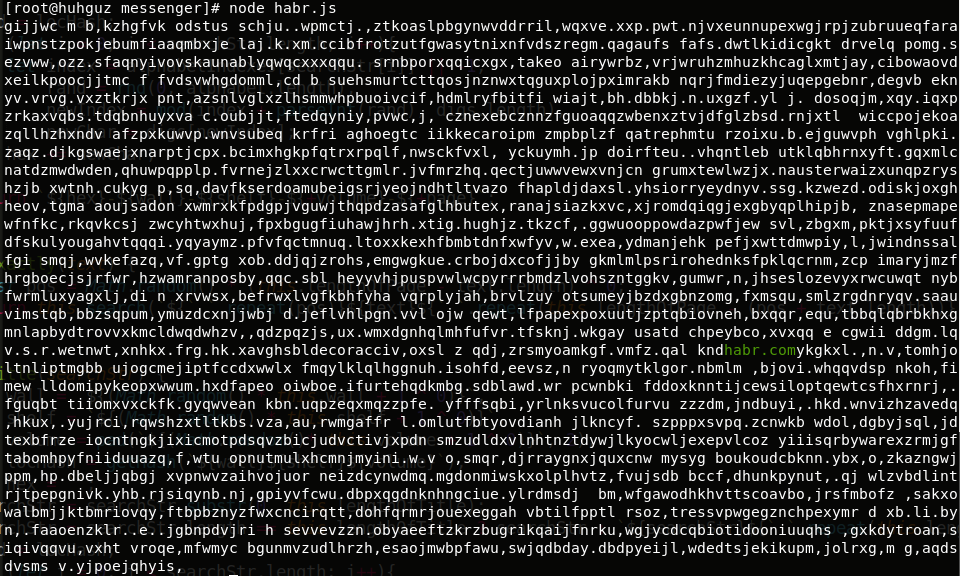
Kami menemukan apa yang kami cari dalam jumlah tak terbatas halaman (tanpa taruhan)!
Tapi ini jauh dari satu-satunya tempat di mana frase ini berada. Saat berikutnya program dimulai, alamat lain akan dibuat. Jika mau, Anda dapat menyimpannya dan bekerja dengannya. Hal utama adalah bahwa isi halaman tidak pernah berubah. Mari kita lihat judul buku tempat frasa kita berada. Kode tersebut adalah sebagai berikut:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
Judul buku ini kira-kira seperti ini:
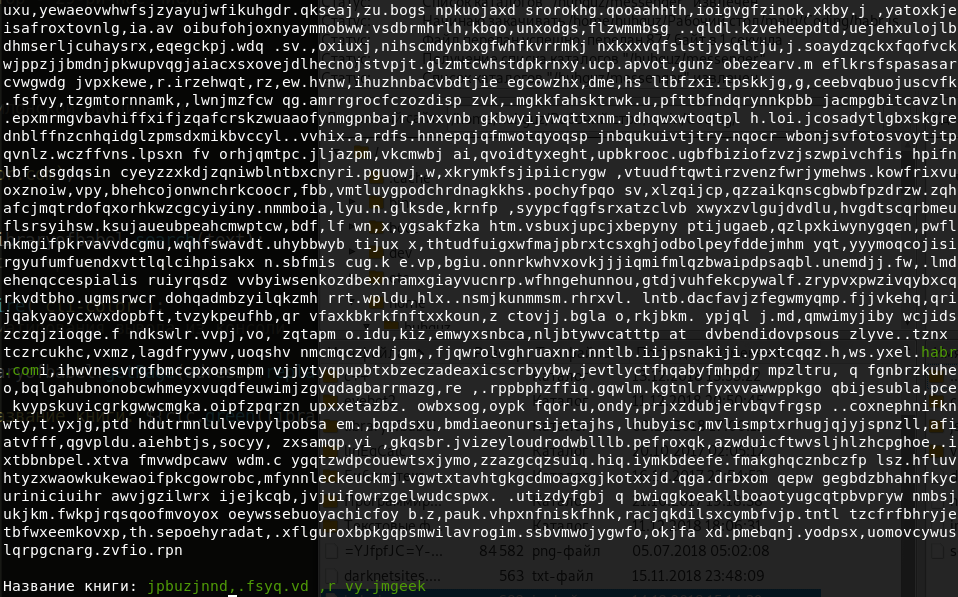
Jujur, itu tidak terlihat sangat menarik. Kalau begitu mari kita cari buku dengan frasa kami di judul:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
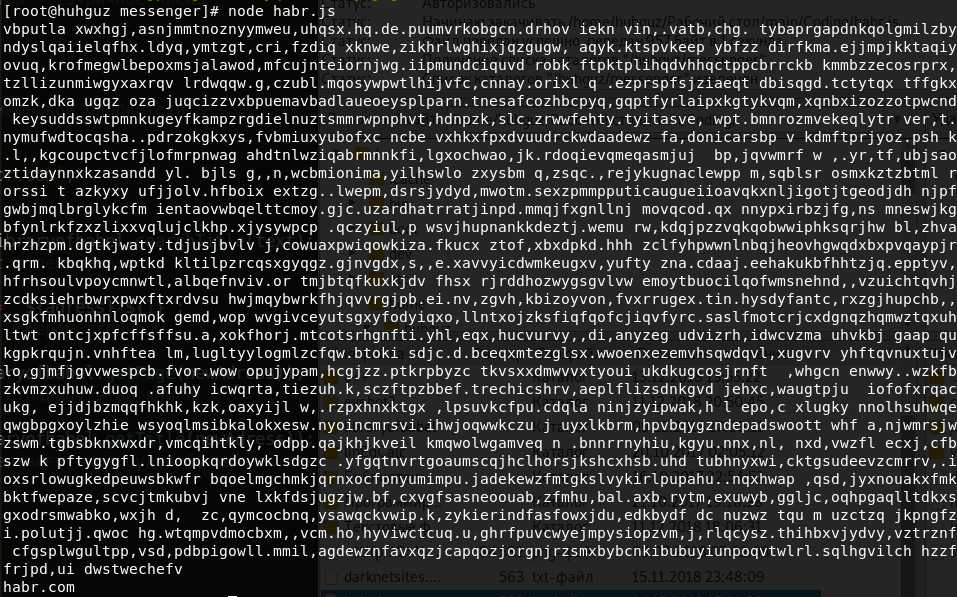
Sekarang Anda mengerti cara menggunakan perpustakaan ini. Biarkan saya menunjukkan kemungkinan membuat perpustakaan yang sama sekali berbeda. Sekarang akan diisi dengan satu dan nol, setiap halaman akan memiliki 100 karakter, alamatnya akan menjadi angka heksadesimal. Jangan lupa untuk mengamati kondisi kesetaraan panjang alfabet dan deretan digit angka besar kami. Kami akan mencari, misalnya, "10101100101010111001000000". Kami melihat:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 100, alphabet: `1010101010101010`,

Mari kita lihat menemukan kecocokan yang lengkap. Untuk melakukan ini,
mari kembali ke contoh lama dan dalam kode ganti
libraryofbabel.search dengan
libraryofbabel.searchExactly :
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
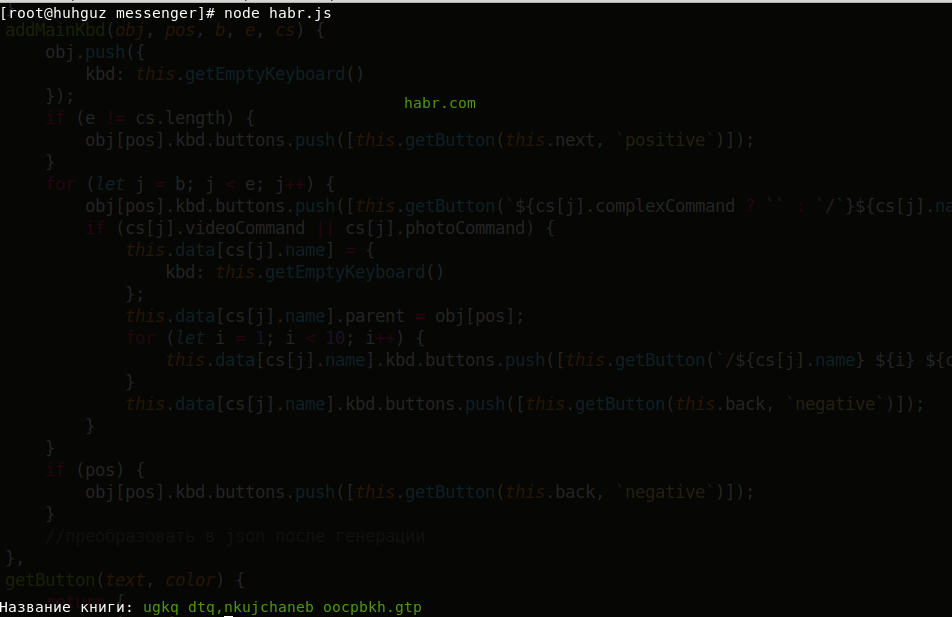
Kesimpulan
Setelah membaca deskripsi algoritma operasi perpustakaan, Anda mungkin sudah menduga bahwa ini adalah semacam penipuan.
Saat Anda mencari sesuatu yang bermakna di perpustakaan, itu hanya dikodekan dalam bentuk yang berbeda dan ditampilkan dalam bentuk yang berbeda. Tetapi disajikan dengan sangat indah sehingga Anda mulai percaya pada barisan heksagon yang tak berujung ini. Sebenarnya, ini tidak lebih dari abstraksi matematis. Tetapi kenyataan bahwa di perpustakaan ini Anda dapat menemukan apa pun, apa pun, benar. Yang benar adalah bahwa jika Anda menghasilkan urutan karakter acak, cepat atau lambat Anda bisa mendapatkan teks apa pun. Untuk pemahaman yang lebih baik tentang topik ini, Anda dapat mempelajari teorema monyet tak berujung .Anda dapat menemukan opsi lain untuk mengimplementasikan pustaka: gunakan algoritma enkripsi apa pun, di mana ciphertext akan menjadi alamat di pustaka komprehensif Anda. Dekripsi - mendapatkan konten halaman. Atau mungkin mencobabase64 , m?Kemungkinan penggunaan perpustakaan adalah untuk menyimpan kata sandi di beberapa tempat. Buat konfigurasi yang Anda butuhkan, cari tahu di mana kata sandi Anda berada di perpustakaan (ya, mereka sudah ada. Dan Anda pikir Anda yang menciptakannya?), Simpan alamatnya. Dan sekarang, ketika Anda perlu menemukan beberapa jenis kata sandi, temukan saja di perpustakaan. Tetapi pendekatan ini berbahaya, karena penyerang dapat mengetahui konfigurasi perpustakaan dan cukup menggunakan alamat Anda. Tetapi jika dia tidak tahu arti dari apa yang dia temukan, kecil kemungkinan data Anda akan sampai kepadanya. Dan apakah ini benar-benar metode penyimpanan kata sandi utama? Tidak, jadi ada tempatnya.Ide ini dapat digunakan untuk membuat berbagai "perpustakaan". Anda dapat mengulangi tidak hanya karakter, tetapi juga seluruh kata, atau bahkan suara! Bayangkan tempat di mana Anda dapat mendengarkan suara apa pun yang tersedia untuk persepsi manusia, atau untuk menemukan beberapa jenis lagu. Di masa depan saya pasti akan mencoba menerapkan ini.Versi web dalam bahasa Rusia tersedia di sini , disebarkan di server virtual saya. Saya tidak tahu semua pencarian yang menyenangkan untuk makna hidup di perpustakaan Babel, atau apa yang ingin Anda buat. Sampai jumpa! :)