Tampaknya kita begitu terbenam di dalam hutan pembangunan yang sangat tinggi sehingga kita tidak memikirkan masalah mendasarnya. Ambil, misalnya, sharding. Apa yang harus dipahami jika dimungkinkan untuk menulis pecahan bersyarat = n dalam pengaturan basis data dan semuanya akan dilakukan dengan sendirinya. Begitulah, tetapi jika, ketika terjadi kesalahan, sumber daya mulai benar-benar langka, saya ingin memahami apa alasannya dan bagaimana cara memperbaikinya.
Singkatnya, jika Anda berkontribusi implementasi hash alternatif Anda di Cassandra, maka hampir tidak ada wahyu untuk Anda. Tetapi jika beban pada layanan Anda sudah tiba, dan pengetahuan sistem tidak mengikutinya, maka Anda dipersilakan.
Andrei Aksyonov (
shodan ) yang hebat dan mengerikan dengan cara yang biasa akan mengatakan bahwa
sharding itu buruk, tidak sharding juga buruk , dan bagaimana hal itu diatur di dalam. Dan secara tidak sengaja, salah satu bagian dari cerita tentang sharding sebenarnya bukan tentang sharding, tetapi iblis tahu tentang apa - bagaimana memetakan objek ke pecahan.

Foto anjing laut (walaupun secara tidak sengaja ternyata adalah anak anjing) sepertinya sudah menjawab pertanyaan mengapa ini semua, tapi mari kita mulai secara berurutan.
Apa itu sharding?
Jika Anda terus-menerus google, ternyata ada batas yang agak kabur antara yang disebut partisi dan yang disebut sharding. Semua orang menyebut semua yang dia inginkan daripada yang dia inginkan. Beberapa orang membedakan antara partisi horizontal dan sharding. Yang lain mengatakan bahwa sharding adalah jenis partisi horizontal tertentu.
Saya tidak menemukan standar terminologis tunggal yang akan disetujui oleh para pendiri dan disertifikasi dalam ISO. Keyakinan batin pribadi adalah sesuatu seperti ini:
Partisi rata-rata adalah "memotong pangkalan menjadi berkeping-keping" dengan cara yang sewenang-wenang.
- Partisi vertikal Misalnya, ada meja raksasa dengan beberapa miliar entri dalam 60 kolom. Alih-alih memegang satu tabel raksasa seperti itu, kami menyimpan 60 tabel raksasa juga dengan masing-masing 2 miliar rekaman - dan ini bukan basis paruh waktu, tetapi partisi vertikal (sebagai contoh terminologi).
- Partisi horizontal - kami memotong baris demi baris, mungkin di dalam server.
Momen canggung di sini adalah perbedaan halus antara partisi horizontal dan sharding. Anda dapat memotong saya berkeping-keping, tetapi saya tidak akan memberi tahu Anda dengan pasti apa itu terdiri. Ada perasaan bahwa sharding dan partisi horizontal adalah tentang hal yang sama.
Sharding secara umum ketika sebuah tabel besar dalam hal basis data atau kumpulan dokumen, objek, jika Anda tidak memiliki database, tetapi toko dokumen, dipotong khusus untuk objek. Artinya, potongan dari 2 miliar objek dipilih, tidak peduli berapa ukurannya. Objek dengan sendirinya di dalam setiap objek tidak dipotong-potong, kita tidak membusuk menjadi kolom terpisah, yaitu, kita meletakkan bundel di tempat yang berbeda.
Tautkan ke presentasi untuk kelengkapan.Perbedaan terminologis yang halus telah berlangsung. Sebagai contoh, secara relatif, pengembang Postgres dapat mengatakan bahwa partisi horizontal adalah ketika semua tabel di mana tabel utama dibagi berada dalam skema yang sama, dan ketika pada mesin yang berbeda itu sharding.
Dalam arti umum, tanpa terikat dengan terminologi database tertentu dan sistem manajemen data tertentu, ada perasaan bahwa sharding hanya mengiris dokumen baris demi baris dan sebagainya - dan hanya itu:
Sharding (~ =, \ in ...) Horizontal Partitioning == adalah tipikal.
Saya menekankan, biasanya. Dalam arti bahwa kita melakukan semua ini bukan hanya untuk memotong 2 miliar dokumen menjadi 20 tabel, yang masing-masing akan lebih mudah dikelola, tetapi untuk mendistribusikannya ke banyak core, banyak disk atau banyak server fisik atau virtual yang berbeda .
Dipahami bahwa kita melakukan ini sehingga setiap beling - setiap data shatka - direplikasi berkali-kali. Tapi sebenarnya tidak.
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15
Faktanya, jika Anda membuat irisan data seperti itu, dan dari satu tabel SQL raksasa di MySQL, Anda akan menghasilkan 16 tabel kecil pada laptop Anda yang gagah berani, tanpa melampaui satu laptop, bukan skema tunggal, bukan database tunggal, dll. dll. - Segalanya, Anda sudah memiliki pecahan.
Mengingat ilustrasi dengan anak-anak anjing, ini mengarah pada yang berikut:
- Bandwidth meningkat.
- Latensi tidak berubah, yaitu masing-masing, sehingga dapat dikatakan, pekerja atau konsumen dalam hal ini, mendapatkan miliknya sendiri. Tidak diketahui apa yang didapat anak anjing dalam gambar, tetapi permintaan disajikan dalam waktu yang hampir bersamaan, seolah-olah anak anjing itu sendirian.
- Atau keduanya itu, dan yang lain, dan ketersediaan masih tinggi (replikasi).
Mengapa bandwidth? Kadang-kadang kita mungkin memiliki volume data yang tidak sesuai - tidak jelas di mana, tetapi tidak cocok - oleh 1 {core | drive | server | ...}. Hanya sumber daya tidak cukup dan hanya itu. Agar dapat bekerja dengan dataset besar ini, Anda perlu memotongnya.
Mengapa latensi? Pada satu inti, pemindaian tabel 2 miliar baris 20 kali lebih lambat dari pemindaian 20 tabel pada 20 kernel, melakukan hal ini secara paralel. Data sedang diproses terlalu lambat pada satu sumber daya.
Mengapa ketersediaan tinggi? Atau kami memotong data untuk melakukan satu dan yang lain pada saat yang sama, dan pada saat yang sama beberapa salinan dari setiap pecahan - replikasi menyediakan ketersediaan tinggi.
Contoh sederhana "bagaimana melakukannya dengan tangan Anda"
Sharding bersyarat dapat dipotong menggunakan tabel tes test.dokumen untuk 32 dokumen, dan dengan menghasilkan dari tabel ini 16 tabel uji untuk sekitar 2 dokumen test.docs00, 01, 02, ..., 15 masing-masing.
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15
Mengapa tentang? Karena apriori kita tidak tahu bagaimana id didistribusikan, jika dari 1 hingga 32 inklusif, maka masing-masing akan ada 2 dokumen, jika tidak.
Kami melakukan ini untuk apa. Setelah kita melakukan 16 tabel, kita dapat "menangkap" 16 dari apa yang kita butuhkan. Terlepas dari apa yang kita sandarkan, kita dapat memparalelkan sumber daya ini. Misalnya, jika tidak ada cukup ruang disk, masuk akal untuk menguraikan tabel ini menjadi disk terpisah.
Semua ini, sayangnya, tidak gratis. Saya menduga bahwa dalam kasus standar SQL kanonik (saya belum membaca ulang standar SQL untuk waktu yang lama, mungkin belum diperbarui untuk waktu yang lama), tidak ada sintaks standar resmi untuk mengatakan ke server SQL mana pun: “Server SQL yang terhormat, buatkan saya 32 pecahan dan menaruhnya di 4 disc. " Tetapi dalam implementasi individu, sering ada sintaks tertentu untuk melakukan hal yang sama secara prinsip. PostgreSQL memiliki mekanisme untuk mempartisi, MySQL MariaDB memilikinya, Oracle mungkin telah melakukan semua ini sejak lama.
Namun demikian, jika kita melakukan ini dengan tangan, tanpa dukungan basis data dan dalam kerangka kerja standar, maka kita
membayar secara kondisional kompleksitas akses ke data . Di mana ada SELECT * FROM dokumen WHERE sederhana id = 123, sekarang 16 x SELECT * FROM docsXX. Dan yah, jika kami mencoba untuk mendapatkan catatan dengan kunci. Secara signifikan lebih menarik jika kami mencoba untuk mendapatkan rentang catatan awal. Sekarang (jika, saya tekankan, seolah-olah bodoh, dan tetap dalam standar), hasil dari 16 SELECT * FROM ini harus digabungkan dalam aplikasi.
Perubahan kinerja apa yang diharapkan?- Linier yang intuitif.
- Secara teoritis - sublinear, karena hukum Amdahl .
- Dalam praktiknya - mungkin hampir linear, mungkin tidak.
Faktanya, jawaban yang benar tidak diketahui. Dengan aplikasi cerdas dari teknik sharding, Anda dapat mencapai kemunduran super-linier yang signifikan dalam pengoperasian aplikasi Anda, dan bahkan DBA akan berjalan dengan poker panas.
Mari kita lihat bagaimana ini bisa dicapai. Jelas bahwa hanya pengaturan pengaturan ke PostgreSQL beling = 16, dan kemudian lepas sendiri - ini tidak menarik. Mari kita pikirkan tentang bagaimana kita dapat mencapai hal itu sehingga
kita akan melambat menjadi 32 kali dari sharding , yang menarik dari sudut pandang bagaimana tidak melakukan ini.
Upaya kami untuk mempercepat atau memperlambat akan selalu bertumpu pada klasik - hukum Amdahl lama yang baik, yang mengatakan bahwa tidak ada paralelisasi sempurna dari permintaan apa pun, selalu ada beberapa bagian yang konsisten.
Hukum Amdahl
Selalu ada bagian serial.
Selalu ada bagian dari eksekusi permintaan yang paralel, dan selalu ada bagian yang tidak paralel. Bahkan jika menurut Anda itu adalah kueri paralel sempurna, setidaknya mengumpulkan deretan hasil yang akan Anda kirim ke klien, dari baris yang diterima dari setiap beling, selalu ada, dan selalu konsisten.
Selalu ada semacam bagian berurutan. Ini bisa sangat kecil, benar-benar tidak terlihat dengan latar belakang umum, itu bisa sangat besar dan, karenanya, sangat mempengaruhi paralelisasi, tetapi selalu ada.
Selain itu, pengaruhnya
berubah dan dapat tumbuh secara signifikan, misalnya, jika kita memotong tabel kita - mari kita tingkatkan - dari 64 catatan menjadi 16 tabel dari 4 catatan, bagian ini akan berubah. Tentu saja, dilihat dari jumlah data sebesar itu, kami bekerja pada ponsel dan prosesor 86 MHz, kami tidak memiliki cukup file yang dapat tetap dibuka pada saat bersamaan. Rupanya, dengan input seperti itu, kami membuka satu file sekaligus.
- Itu Total = Serial + Paralel . Di mana, misalnya, paralel adalah semua pekerjaan di dalam DB, dan serial mengirim hasilnya ke klien.
- Itu menjadi Total2 = Serial + Parallel / N + Xserial. Misalnya, ketika ORDER BY umum, Xserial> 0.
Dengan contoh sederhana ini, saya mencoba menunjukkan bahwa beberapa Xserial muncul. Selain fakta bahwa selalu ada bagian serial, dan fakta bahwa kami mencoba untuk bekerja dengan data secara paralel, bagian tambahan muncul untuk memastikan data ini diiris. Secara kasar, kita mungkin perlu:
- temukan 16 tabel ini di kamus basis data internal;
- buka file;
- mengalokasikan memori;
- pindah memori;
- noda hasil;
- sinkronisasi antara inti;
Efek tidak sinkron selalu muncul. Mereka mungkin tidak signifikan dan menempati sepersejuta dari total waktu, tetapi mereka selalu nol dan selalu ada. Dengan bantuan mereka, kita dapat secara dramatis kehilangan produktivitas setelah sharding.
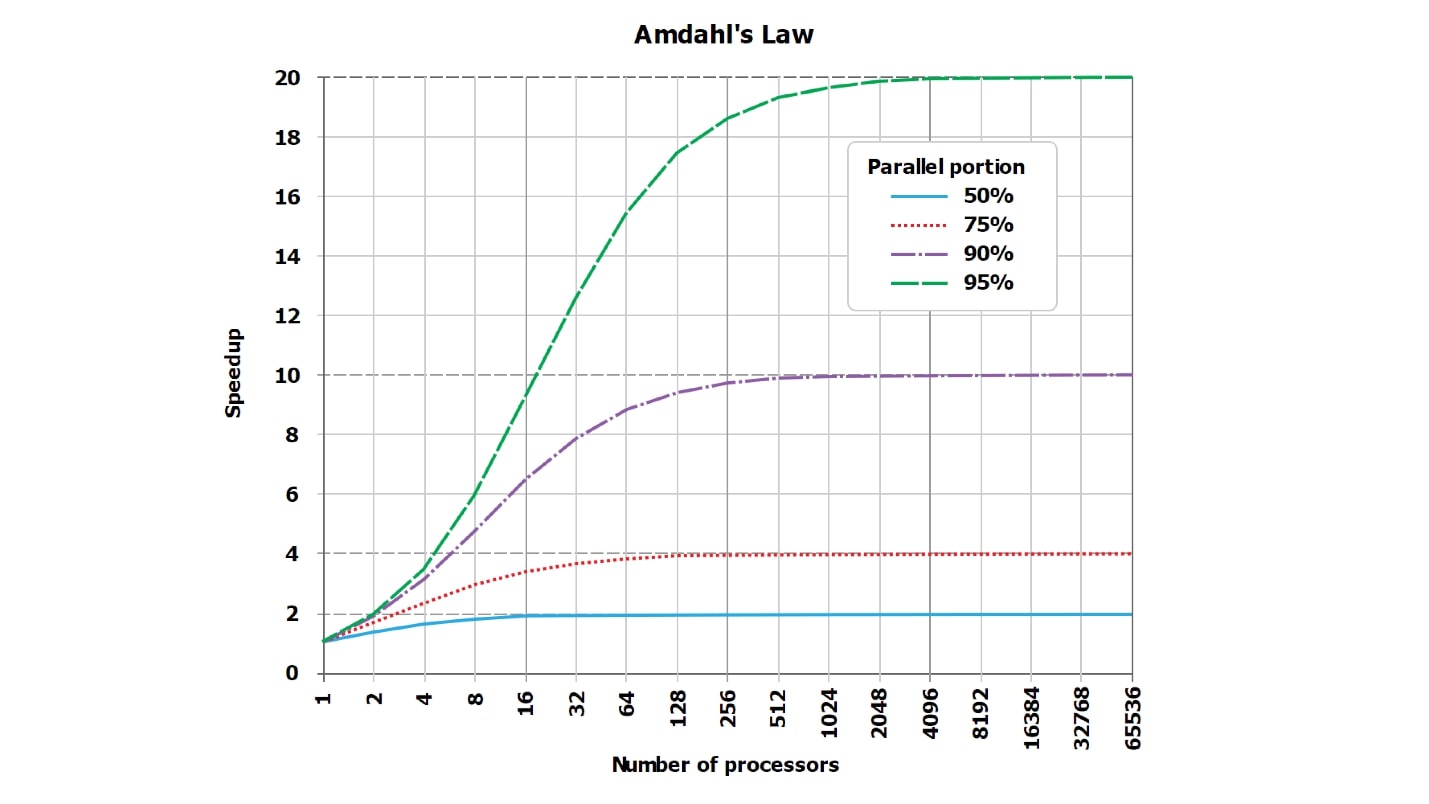
Ini adalah gambar standar tentang hukum Amdahl. Ini tidak mudah dibaca, tetapi penting bahwa garis-garis, yang idealnya harus lurus dan tumbuh secara linear, berbatasan dengan asimtot. Tetapi karena grafik dari Internet tidak dapat dibaca, saya membuat, menurut pendapat saya, lebih banyak tabel visual dengan angka.
Misalkan kita memiliki beberapa bagian serial dari pemrosesan permintaan, yang hanya membutuhkan 5%:
serial = 0,05 = 1/20.Secara intuitif, akan terlihat bahwa dengan bagian serial, yang hanya membutuhkan 1/20 dari pemrosesan permintaan, jika kita memparalelkan pemrosesan permintaan menjadi 20 core, maka akan menjadi sekitar 20, dalam kasus terburuk, 18 kali lebih cepat.
Sebenarnya,
matematika adalah hal yang tidak berperasaan :
wall = 0.05 + 0.95/num_cores, speedup = 1 / (0.05 + 0.95/num_cores)Ternyata jika Anda hati-hati menghitung, dengan bagian serial 5%, akselerasi akan 10 kali (10,3), dan ini adalah 51% dibandingkan dengan ideal teoretis.
| 8 core | = 5.9 | = 74% |
| 10 core | = 6.9 | = 69% |
| 20 core | = 10.3 | = 51% |
| 40 core | = 13.6 | = 34% |
| 128 core | = 17,4 | = 14% |
Menggunakan 20 core (20 disk, jika Anda suka) untuk tugas yang telah dikerjakan sebelumnya, kami secara teoritis tidak akan pernah mendapatkan akselerasi lebih dari 20 kali, tetapi secara praktis jauh lebih sedikit. Selain itu, dengan peningkatan jumlah paralel, inefisiensi tumbuh dengan cepat.
Ketika hanya 1% dari pekerjaan berseri yang tersisa, dan 99% diparalelkan, nilai akselerasi agak ditingkatkan:
| 8 core | = 7,5 | = 93% |
| 16 core | = 13.9 | = 87% |
| 32 core | = 24,4 | = 76% |
| 64 core | = 39,3 | = 61% |
Untuk permintaan yang sepenuhnya termonuklir, yang secara alami berjalan selama berjam-jam, dan pekerjaan persiapan dan merakit hasilnya membutuhkan waktu sangat sedikit (serial = 0,001), kita akan melihat efisiensi yang baik:
| 8 core | = 7.94 | = 99% |
| 16 core | = 15,76 | = 99% |
| 32 core | = 31,04 | = 97% |
| 64 core | = 60,20 | = 94% |
Harap dicatat bahwa
kami tidak akan pernah melihat 100% . Dalam kasus yang sangat baik, Anda dapat melihat, misalnya, 99,999%, tetapi tidak persis 100%.
Bagaimana cara mengocok dan memecahkan dalam N kali?
Anda dapat mengocok dan membobol tepat N kali:
- Kirim docs00 ... permintaan docs15 secara berurutan , tidak paralel.
- Dalam pertanyaan sederhana, jangan pilih dengan kunci , MANA sesuatu = 234.
Dalam hal ini, bagian berseri (serial) menempati tidak 1% dan bukan 5%, tetapi sekitar 20% dalam database modern. Anda bisa mendapatkan 50% dari bagian serial jika Anda mengakses database menggunakan protokol biner yang sangat efisien atau menautkannya sebagai pustaka dinamis ke skrip Python.
Sisa waktu pemrosesan untuk permintaan sederhana akan ditempati oleh operasi parsing permintaan yang tidak diparalelkan, persiapan rencana, dll. Artinya, melambat tidak membaca catatan.
Jika kita memecah data menjadi 16 tabel dan menjalankannya secara berurutan, seperti kebiasaan dalam bahasa pemrograman PHP, misalnya, (ia tidak tahu cara menjalankan proses asinkron dengan sangat baik), maka kami hanya mendapatkan penurunan 16 kali. Dan, mungkin, bahkan lebih, karena perjalanan pulang-pergi jaringan juga akan ditambahkan.
Tiba-tiba saat sharding, pilihan bahasa pemrograman menjadi penting.
Kami ingat tentang pilihan bahasa pemrograman, karena jika Anda mengirim permintaan ke database (atau server pencarian) secara berurutan, lalu dari mana akselerasi itu berasal? Melainkan, pelambatan akan muncul.
Sepeda dari kehidupan
Jika Anda memilih C ++,
tulis ke Thread POSIX , bukan Boost I / O. Saya melihat perpustakaan yang sangat baik dari pengembang berpengalaman dari Oracle dan MySQL sendiri, yang menulis komunikasi dengan server MySQL di Boost. Rupanya, mereka dipaksa untuk menulis dalam bahasa C murni di tempat kerja, tetapi kemudian mereka berhasil berbalik, mengambil Boost dengan I / O yang tidak sinkron, dll. Satu masalah - I / O asinkron ini, yang secara teoritis seharusnya mendorong 10 permintaan secara paralel, karena beberapa alasan memiliki titik sinkronisasi yang tidak terlihat di dalam. Ketika memulai 10 permintaan secara paralel, mereka dieksekusi tepat 20 kali lebih lambat dari satu, karena 10 kali untuk permintaan itu sendiri dan satu kali ke titik sinkronisasi.
Kesimpulan: tulis dalam bahasa yang mengimplementasikan running paralel dan menunggu permintaan berbeda dengan baik. Saya tidak tahu, jujur saja, apa sebenarnya yang disarankan selain Go. Bukan hanya karena saya benar-benar mencintai Go, tetapi karena saya tidak tahu apa pun yang lebih cocok.
Jangan menulis dalam bahasa yang tidak cocok di mana Anda tidak dapat menjalankan 20 pertanyaan paralel ke database. Atau di setiap kesempatan, jangan lakukan semuanya dengan tangan Anda - pahami cara kerjanya, tapi jangan lakukan secara manual.
Sepeda uji A / B
Kadang-kadang Anda dapat memperlambat karena Anda terbiasa dengan fakta bahwa semuanya bekerja, dan Anda tidak memperhatikan bahwa bagian bersambung, pertama, adalah yang besar.
- Segera ~ 60 pecahan indeks pencarian, kategori
- Ini adalah pecahan yang benar dan benar, di bawah area subjek.
- Ada hingga 1000 dokumen, dan ada 50.000 dokumen.
Ini adalah sepeda produksi, ketika permintaan pencarian sedikit berubah dan mereka mulai memilih lebih banyak dokumen dari 60 pecahan indeks pencarian. Semuanya bekerja dengan cepat dan berdasarkan prinsip: "Berhasil - jangan menyentuhnya", mereka semua lupa, yang sebenarnya ada di dalam 60 pecahan. Kami meningkatkan batas pengambilan sampel untuk setiap pecahan dari seribu hingga 50 ribu dokumen. Tiba-tiba, itu mulai melambat dan paralelisme berhenti. Permintaan sendiri, yang dieksekusi sesuai dengan pecahan, terbang cukup baik, dan panggung diperlambat, ketika 50 ribu dokumen dikumpulkan dari 60 pecahan. 3 juta dokumen akhir ini pada satu inti digabung bersama, disortir, bagian atas 3 juta dipilih dan diberikan kepada klien. Bagian serial yang sama melambat, hukum Amdal yang sama kejamnya bekerja.
Jadi mungkin Anda sebaiknya tidak melakukan sharding dengan tangan Anda, tetapi hanya secara manusiawi
beri tahu database: "Lakukan!"
Penafian: Saya tidak benar-benar tahu bagaimana melakukan sesuatu dengan benar. Saya seperti dari lantai yang salah !!!
Saya telah mempromosikan agama yang disebut "fundamentalisme algoritmik" di sepanjang kehidupan sadar saya. Ini dirumuskan secara singkat dengan sangat sederhana:
Anda tidak benar-benar ingin melakukan apa pun dengan tangan Anda, tetapi sangat berguna untuk mengetahui bagaimana itu diatur di dalam. Sehingga pada saat ketika terjadi kesalahan dalam database, Anda setidaknya mengerti apa yang salah di sana, bagaimana hal itu diatur di dalam dan kira-kira bagaimana hal itu dapat diperbaiki.
Mari kita lihat opsinya:
- "Tangan . " Sebelumnya, kami membagi data secara manual menjadi 16 tabel virtual, dan menulis ulang semua pertanyaan dengan tangan kami - ini sangat tidak nyaman. Jika ada kesempatan untuk tidak mengocok tangan - jangan mengocok tangan! Tetapi kadang-kadang ini tidak mungkin, misalnya, Anda memiliki MySQL 3.23, dan kemudian Anda harus melakukannya.
- "Otomatis". Kebetulan Anda dapat mengocok secara otomatis atau hampir secara otomatis, ketika database dapat mendistribusikan data itu sendiri, Anda hanya perlu menulis secara kasar di suatu tempat dengan pengaturan tertentu. Ada banyak pangkalan, dan mereka memiliki banyak pengaturan yang berbeda. Saya yakin bahwa di setiap basis data di mana dimungkinkan untuk menulis pecahan = 16 (apa pun sintaksisnya), banyak pengaturan lain terpaku pada case ini oleh mesin.
- "Semi-otomatis" - mode yang sepenuhnya kosmik, menurut saya, dan brutal. Artinya, basis itu sendiri tampaknya tidak mampu, tetapi ada tambalan tambahan eksternal.
Sulit untuk mengatakan sesuatu tentang mesin, kecuali mengirimnya ke dokumentasi pada database yang sesuai (MongoDB, Elastic, Cassandra, ... secara umum, yang disebut NoSQL). Jika Anda beruntung, maka Anda cukup menarik sakelar “make me 16 shards” dan semuanya akan berhasil. Pada saat itu, ketika itu tidak berhasil, sisa artikel mungkin diperlukan.
Tentang perangkat semi otomatis
Di beberapa tempat, teknologi informasi canggih menginspirasi horor chthonic. Sebagai contoh, MySQL out of the box tidak memiliki implementasi sharding ke versi tertentu untuk memastikan, namun, ukuran pangkalan yang dioperasikan dalam pertempuran tumbuh menjadi nilai tidak senonoh.
Menderita kemanusiaan di hadapan masing-masing DBA telah disiksa selama bertahun-tahun dan menulis beberapa solusi buruk yang dibuat tanpa alasan. Setelah itu, satu atau lebih solusi sharding yang layak disebut ProxySQL (MariaDB / Spider, PG / pg_shard / Citus, ...). Ini adalah contoh terkenal dari mantel yang sama ini.
ProxySQL secara keseluruhan, tentu saja, adalah solusi kelas enterprise lengkap untuk open source, untuk routing dan banyak lagi. Tetapi salah satu tugas yang harus dipecahkan adalah sharding untuk database, yang dengan sendirinya tidak tahu cara shard secara manusiawi. Anda lihat, tidak ada saklar "beling = 16", baik Anda harus menulis ulang setiap permintaan dalam aplikasi, dan ada banyak dari mereka, atau meletakkan lapisan menengah antara aplikasi dan database yang terlihat: "Hmm ... PILIH * DARI dokumen? Ya, itu harus dibagi menjadi 16 SELECT * FROM server1.document1 kecil, SELECT * FROM server2.document2 - ke server ini dengan nama pengguna / kata sandi, untuk ini dengan yang lain. Jika seseorang tidak menjawab, maka ... "dll.
Tepatnya ini bisa dilakukan dengan tambalan menengah. Mereka sedikit kurang dari untuk semua database. Untuk PostgreSQL, seperti yang saya pahami, pada saat yang sama ada beberapa solusi bawaan (PostgresForeign Data Wrappers, menurut pendapat saya, dibangun ke dalam PostgreSQL itu sendiri), ada tambalan eksternal.
Mengkonfigurasi setiap tambalan spesifik adalah topik raksasa terpisah yang tidak akan cocok dalam satu laporan, jadi kami hanya akan membahas konsep dasar.
Lebih baik kita bicara sedikit tentang teori buzz.
Otomatisasi sempurna mutlak?
Seluruh teori buzz dalam hal sharding dalam huruf F () ini, prinsip dasarnya
selalu sama mentah:
shard_id = F(object).Sharding umumnya tentang apa? Kami memiliki 2 miliar catatan (atau 64). Kami ingin membaginya menjadi beberapa bagian. Pertanyaan tak terduga muncul - bagaimana? Dengan prinsip apa saya harus menyebarkan 2 milyar catatan saya (atau 64) ke 16 server yang tersedia untuk saya?
Ahli matematika laten dalam diri kita harus menyarankan bahwa pada akhirnya selalu ada fungsi sihir tertentu yang, untuk setiap dokumen (objek, garis, dll.), Akan menentukan bagian mana yang akan diletakkan.
Jika kita masuk lebih dalam ke matematika, fungsi ini selalu tergantung tidak hanya pada objek itu sendiri (garis itu sendiri), tetapi juga pada pengaturan eksternal seperti jumlah total pecahan. Fungsi, yang untuk setiap objek harus mengatakan di mana harus meletakkannya, tidak dapat mengembalikan nilai lebih dari server di sistem. Dan fungsinya sedikit berbeda:
- shard_func = F1 (objek);
- shard_id = F2 (shard_func, ...);
- shard_id = F2 ( F1 (objek), current_num_shards, ...).
Tetapi lebih jauh lagi kita tidak akan menggali ke dalam hutan fungsi individu ini, kita hanya berbicara tentang apa fungsi sihir F ().
Apa itu F ()?
Mereka dapat menghasilkan banyak mekanisme implementasi yang berbeda dan banyak berbeda. Ringkasan sampel:
- F = rand ()% nums_shards
- F = somehash (object.id)% num_shards
- F = object.date% num_shards
- F = object.user_id% num_shards
- ...
- F = shard_table [somehash () | ... object.date | ...]
Fakta menarik - Anda dapat secara alami menyebarkan semua data secara acak - kami melemparkan catatan berikutnya pada server yang arbitrer, pada kernel yang arbitrer, dalam tabel arbitrer. Tidak akan ada banyak kebahagiaan dalam hal ini, tetapi itu akan berhasil.
Ada metode scamming yang sedikit lebih cerdas untuk fungsi hash yang dapat direproduksi atau bahkan konsisten, atau scamming untuk beberapa atribut. Mari kita pergi melalui setiap metode.
F = rand ()
Menyebarkan sekitar bukanlah metode yang sangat benar. Satu masalah: kami menyebarkan 2 miliar catatan kami per seribu server secara acak, dan kami tidak tahu di mana catatan itu berada. Kami perlu menarik pengguna_1, tetapi kami tidak tahu di mana itu. Kami pergi ke seribu server dan memilah-milah segalanya - entah bagaimana itu tidak efisien.
F = somehash ()
Mari menyebarkan pengguna dengan cara dewasa: membaca fungsi hash yang direproduksi dari user_id, ambil sisa divisi dengan jumlah server dan akses server yang diinginkan segera.
Kenapa kita melakukan ini? Lalu, kami memiliki beban tinggi dan kami tidak mendapatkan apa pun ke dalam satu server. Jika disela, hidup akan sangat sederhana.Nah, situasinya sudah membaik, untuk mendapatkan satu catatan, kami pergi ke satu server yang terkenal. Tetapi jika kita memiliki rentang kunci, maka dalam semua rentang ini kita perlu memilah-milah semua nilai kunci dan dalam batasnya pergi ke banyak pecahan karena kita memiliki kunci dalam jangkauan, atau untuk setiap server secara umum. Situasi, tentu saja, telah membaik, tetapi tidak untuk semua permintaan. Beberapa permintaan telah terpengaruh.
Sharding alami (F = object.date% num_shards)
Kadang-kadang, itu sering kali, 95% dari lalu lintas dan 95% dari beban adalah permintaan yang memiliki semacam sharding alami. , 95% - 1 , 3 , 7 , 5% . 95% , , , .
, , , - .
— , . , , , , . 5 % .
, :
- , 95% .
- 95% , , . , . , .
, — , - .
, , , , . « - ».
«». , .
1. :
, , .
, / , , , PM ( , PM ), . .
, . , , 100 . .
, , , , - .
2. «» : , join
, ?
- «» … WHERE randcol BETWEEN aaa AND bbb?
- «» … users_32shards JOIN posts_1024 shards?
: , !
, , , . . (, , document store ), , .
—
- . . , . , , , . - , , , , — .
, .
3. / :
: , .
, .
, , , . , , , 10 , - 30, 100 . . — , - — , - .
, : 16 -, 32. , 17, 23 — . , , - ?
: , , .
, «», « ».
#1.
- NewF(object), .
- NewF()=OldF() .
- .
- Aduh
, 2 , , . : 17 , 6 , 2 , 17 23 . 10 , , . .
#2.
— — 17 23, 16 32 ! , .
- NewF(object), .
- 2^N, 2^(N+1) .
- NewF()=OldF() 0,5.
- 50% .
- , .
, , . , , .
, . , 16 16, — .
, — .
#3. Consistent hashing
, consistent hashing
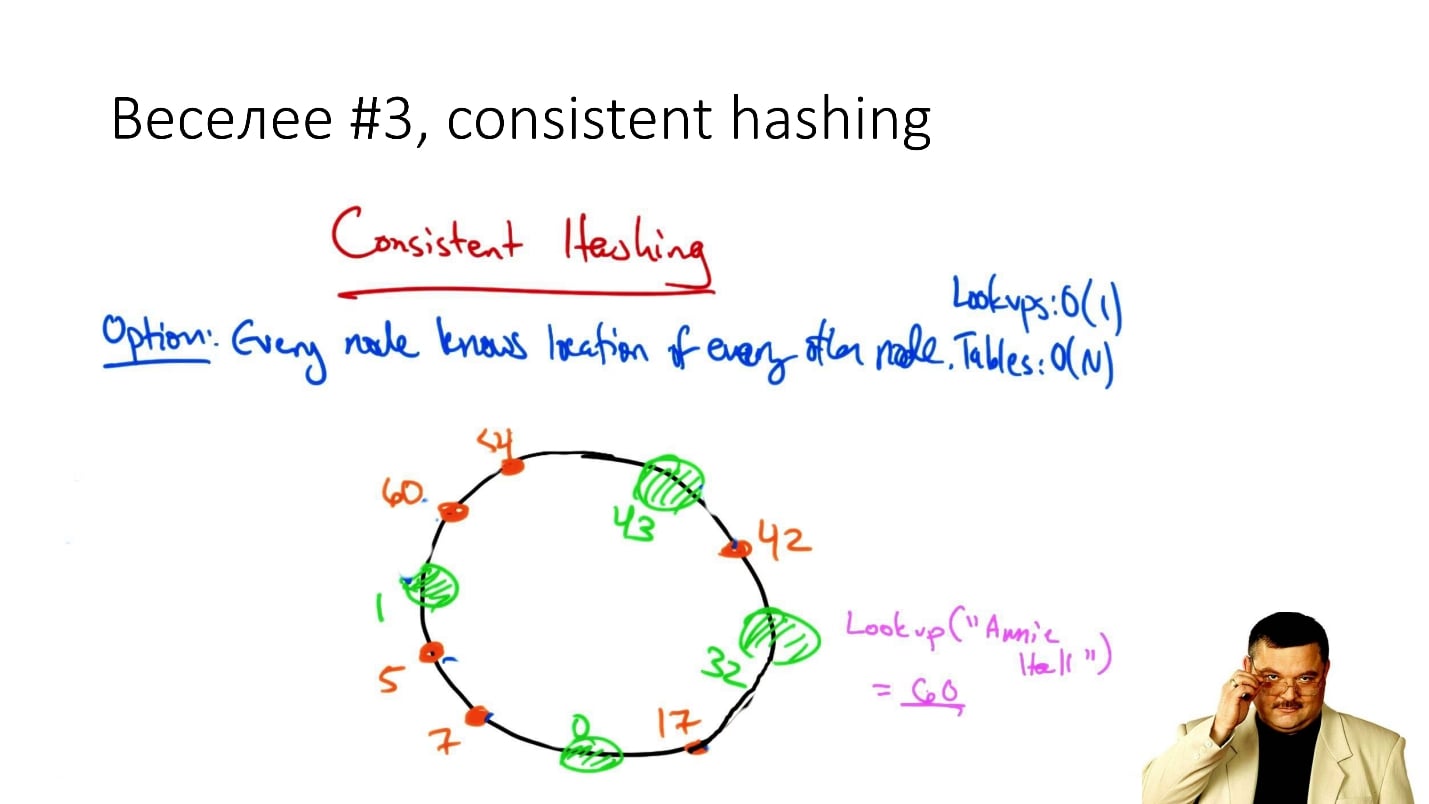
«consistent hashing», , .
: () , . , , , ( , ), .
, . , , , : , .
. , . , .., . , - , , .
, , , Cassandra . , , , , , .
, — / , , .
, : ? ? — , !
#4. Rendezvous/HRW
( , ):
shard_id = arg max hash(object_id, shard_id).Rendezvous hashing, , , Highest Random Weight. :
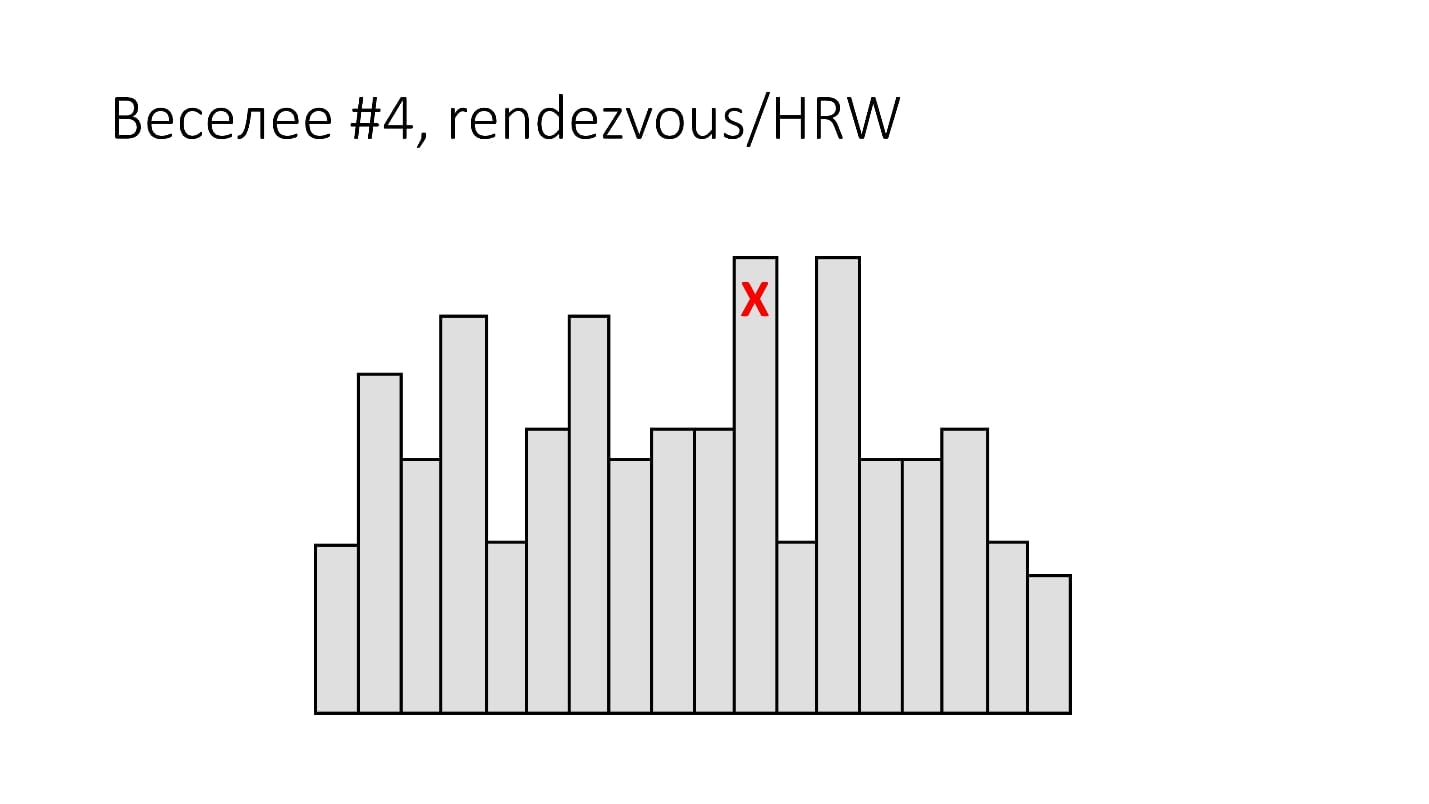
, , 16 . (), - , 16 , . -, .
HRW-hashing, Rendezvous hashing. , -, , .
, . , - - . .
, .
#5.
, Google - :
- Jump Hash — Google '2014.
- Multi Probe —Google '2015.
- Maglev — Google '2016.
, . , , , -, . .
#6.
— . ? , 2 , object_id 2 , .
, ? ?
. , - , , . , , , , .
:
- 1 .
- / / / : min/max_id => shard_id.
- 8 4 (4 !) — 20 .
- - , 20 — .
- 20 — .
2 - 16 — 100 - . : , , — 1 . , , .
, , , - , .
Kesimpulan
: « , !». , 20 .
, , . ,
— . 100$ , . -, . — .
, , «» (, DFS, ...) . , , highload - . , , - . —
, .
F() , , , .. , , 2
.
, , .
HighLoad++ , , —Sphinx—highload , .
Highload User Group. , .
, ,
HighLoad++ . , , . , , .
highload-, .
, , , . , , , .
24 - «», « ». , . ,
.
, , 8 9 - HighLoad++ early bird .