
Kami berusaha keras untuk memastikan bahwa setelah memesan taksi kepada pengguna, mobil yang bersih dan dapat diservis dari merek, warna dan nomor yang ditampilkan dalam aplikasi akan datang kepada pengguna. Dan untuk ini kami menggunakan kendali mutu jarak jauh (DCC).
Hari ini saya akan memberi tahu pembaca Habr tentang cara menggunakan pembelajaran mesin untuk mengurangi biaya kontrol kualitas dalam layanan yang berkembang pesat dengan ratusan ribu mesin dan tidak menempatkan mesin pada jalur yang tidak mematuhi aturan layanan.
Bagaimana DCC diatur sebelum pembelajaran mesin
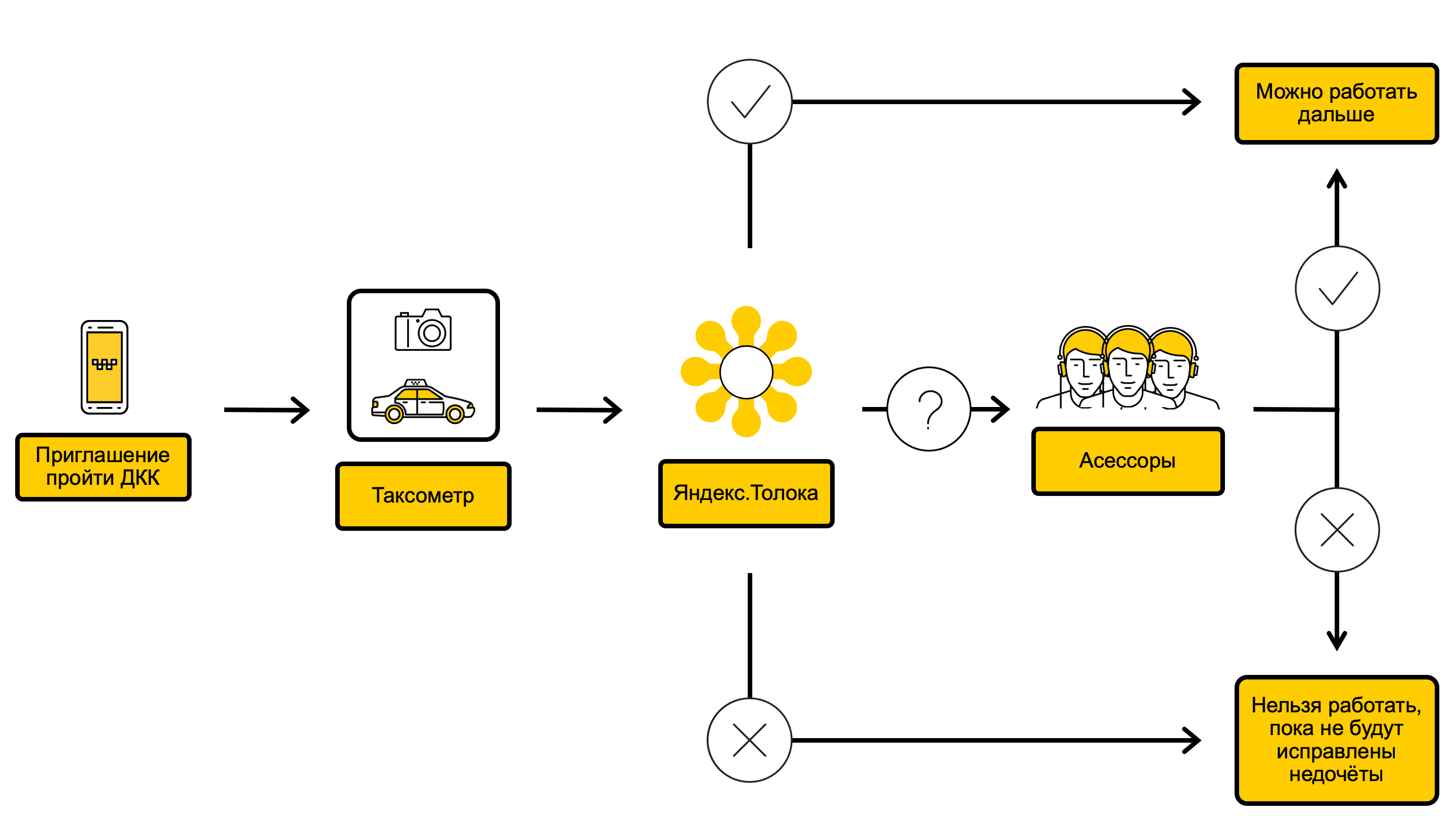
Diagram proses DCC
Dalam proses DCC, kami memeriksa foto-foto mobil dan membuat keputusan apakah mungkin untuk memenuhi pesanan pada mobil seperti itu atau, misalnya, harus dicuci sebelumnya. Semuanya dimulai dengan fakta bahwa melalui aplikasi pengemudi Taximeter kita memanggil driver pada DCC. Ini biasanya terjadi setiap 10 hari sekali, tetapi kadang-kadang lebih jarang atau lebih sering - tergantung pada seberapa sukses pengemudi melewati pemeriksaan sebelumnya. Segera setelah panggilan ke DCC, pengemudi menerima pesan yang mengundang mereka untuk menjalani kontrol foto. Segera setelah pengemudi menerima undangan, dalam aplikasi yang sama, ia memotret bagian luar dan interior mobil dari sudut yang berbeda dan mengirimkan foto ke Yandex.Taxi. Pengemudi dapat menerima pesanan saat DCC aktif.

Layar mulai DCC dalam aplikasi Taximeter

Layar untuk memotret mobil di aplikasi Taximeter
Foto-foto yang dihasilkan jatuh ke Yandex.Toloka - layanan di mana, menggunakan crowdsourcing, Anda dapat dengan cepat melakukan tugas volume yang sederhana, tetapi besar. Tentang cara kerjanya dan mengapa Yandex.Tolok diperlukan, kami menulis di blog kami .
Di Yandex.Tolok, dalam satu pemeriksaan, setidaknya tiga pemain menjawab pertanyaan tentang kondisi mobil, dan jika pemain setuju berdasarkan jawaban mereka, keputusan dibuat apakah pengemudi dapat menerima pesanan. Cek di Yandex.Tolok memiliki dua hasil:
- Jika semuanya baik-baik saja secara visual dengan mobil, pengemudi terus menerima pesanan.
- Jika mobil kotor, rusak, atau warnanya, warnanya atau jumlahnya tidak cocok dengan yang ditunjukkan pada kartu pengemudi, Yandex.Taxi membatasi kemampuan pengemudi untuk menerima pesanan untuk sementara waktu.
Jika para pemain tidak mencapai konsensus, foto-foto tersebut dikirim ke karyawan Yandex.Taxi - penilai yang memeriksa mobil secara lebih menyeluruh dan kemudian membuat keputusan akhir. Penilai menjalani program pelatihan khusus dan memiliki lebih banyak pengalaman.

Begitu melihat pelaksana DCC Yandex.Tolki
Tantangan
Dengan pertumbuhan Yandex.Taxi, jumlah inspeksi DCC juga meningkat, yang berarti bahwa biaya untuk tolkers dan penilai bertambah. Selain itu, kecepatan memeriksa mobil menurun. Saat DCC sedang berlangsung, Anda dapat mengizinkan pengemudi menerima pesanan, atau tidak. Kedua opsi memiliki kelemahan: dalam kasus pertama, pengemudi yang tidak bertanggung jawab akan memiliki waktu untuk menerima beberapa pesanan pada mobil yang tidak memenuhi standar, pada yang kedua - semua pengemudi yang dipanggil untuk kontrol foto tidak akan dapat bekerja sampai pemeriksaan selesai. Karena itu, penting untuk memeriksa mobil dengan cepat sehingga pengguna dan pengemudi tidak mengalami ketidaknyamanan.
Melihat bagaimana grafik biaya dan waktu pemindaian rata-rata tumbuh, kami menyadari bahwa kami ingin mengurangi biaya Toloka, membongkar penilai, dan mengurangi waktu pemindaian rata-rata, dengan kata lain, untuk mengotomatisasi sebagian dari pemeriksaan. Secara alami, kami tidak ingin mengorbankan kualitas layanan dan kehilangan lebih banyak mobil yang tidak memenuhi standar kualitas untuk saluran, dan juga tidak ingin membatasi penerimaan pesanan oleh pengemudi bonafid. Kami perlu mengotomatisasi DCC dan pada saat yang sama tidak meningkatkan pangsa kesalahan dalam keseluruhan aliran pemeriksaan.
Bagaimana kami menerapkan pembelajaran mesin di DCC
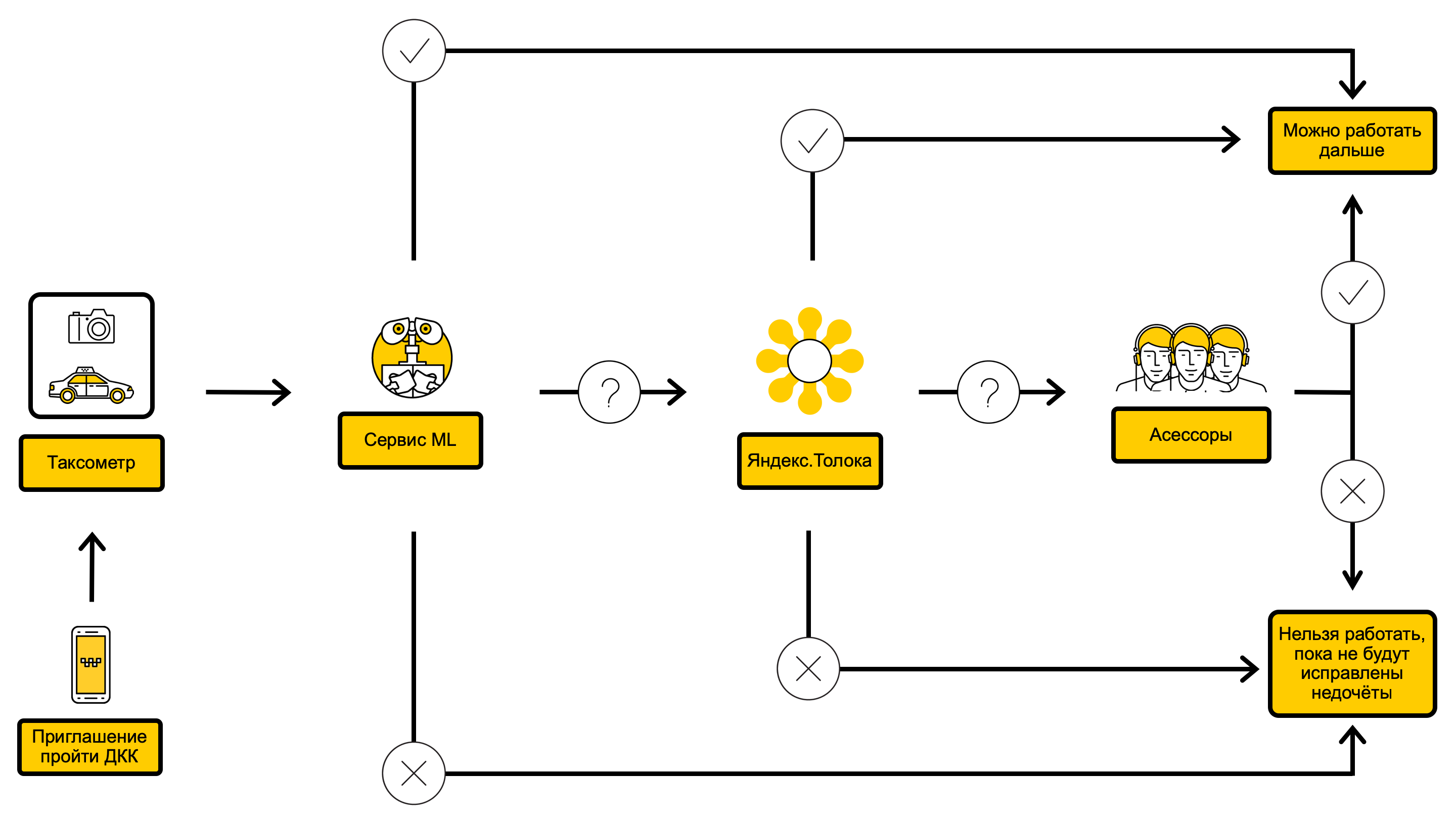
Diagram proses DCC dengan ML di dalamnya
Untuk memulainya, kami memutuskan pada pernyataan masalah: untuk mengotomatiskan sebanyak mungkin pemeriksaan, sambil tidak meningkatkan tingkat kesalahan dalam aliran keseluruhan.
Mari kita cari tahu kesalahan apa yang ada dalam tugas kita. Mereka datang dalam dua bentuk: false positive dan false negative . Dalam terminologi kami, negatif adalah hasil dari pemeriksaan yang dengannya pengemudi dapat terus bekerja, dan positif adalah hasil yang mensyaratkan batas waktu pada penerimaan pesanan. Kemudian false negative adalah kasus di mana kami dipaksa untuk mengizinkan pengemudi dengan mobil yang buruk untuk menerima pesanan, dan false positive - sebaliknya, ketika kami tidak mengizinkan pengemudi untuk bekerja dengan mobil yang baik-baik saja. Ternyata False Negative Rate (FNR) adalah pangsa pengemudi dengan mobil "buruk" yang diizinkan untuk menerima pesanan, dan False Positive Rate (FPR) adalah persentase pengemudi yang tidak diizinkan untuk bekerja sama, walaupun mereka baik-baik saja dengan mobil. Jadi, dari pengenalan pembelajaran mesin ke dalam sistem, kami menginginkan yang berikut: mengotomatiskan sebanyak mungkin pemeriksaan, tanpa meningkatkan FPR dan FNR dibandingkan dengan sistem tanpa pembelajaran mesin.
Selanjutnya, perlu untuk memahami metrik apa yang harus dipandu ketika memilih model dan ambang batas untuk membuat keputusan berdasarkan prediksi mereka. Jelas dari kondisi masalah bahwa kami tertarik pada tiga jumlah:
- Bagian dari utas yang model mesin pembelajaran dapat secara otomatis menjawab.
- Sistem FNR.
- Sistem FPR.
Kami memaksimalkan nilai pertama sambil mengamati pembatasan pada yang kedua dan ketiga.
Ini dapat menimbulkan pertanyaan: mengapa tidak memaksimalkan penghematan uang atau meminimalkan waktu pemindaian rata-rata secara langsung, dan tidak melalui pembagian cek otomatis? Mengoptimalkan uang adalah ide yang sangat menarik, tetapi biasanya sulit untuk diterapkan. Dalam kasus kami, tabungan terdiri dari dua faktor: yang pertama adalah tabungan dari setiap cek otomatis, karena setiap cek di penilai atau di Yandex.Tolok membutuhkan uang; yang kedua - menghemat dari mengurangi jumlah kesalahan, karena setiap kesalahan biaya uang Yandex.Taxi. Menghitung secara obyektif berapa banyak kesalahan yang harus kita bayar adalah tugas yang sangat sulit, oleh karena itu kita dibatasi untuk menghitung tabungan hanya dengan faktor pertama. Nilai ini meningkat secara monoton dalam proporsi pemeriksaan otomatis, sehingga fraksi ini dapat dimaksimalkan alih-alih menabung. Alasan yang sama berlaku untuk waktu DCC rata-rata, tetapi juga menurun secara monoton sesuai dengan bagian pemeriksaan otomatis.
Pemilihan model
Kita dapat mengatakan bahwa pemeriksaan DCC dikurangi menjadi pilihan pilihan jawaban untuk sejumlah pertanyaan tentang keadaan mobil dari foto-fotonya, dan ini terdengar seperti tugas klasifikasi gambar. Tugas-tugas seperti itu diselesaikan oleh visi komputer, dan di zaman kita - alat khusus, jaringan saraf convolutional. Kami memutuskan untuk menggunakannya untuk otomasi DCC.
Solusi pertama atau pendekatan "sekaligus"
Sekarang kita telah memahami apa yang harus dioptimalkan dan mengapa, sekarang saatnya untuk mengumpulkan data dan melatih model-model tersebut. Mudah untuk mengumpulkan data, karena semua cek DCC dicatat dan disimpan dalam bentuk yang mudah. Dalam versi pertama solusi, foto-foto eksterior dan interior mobil dari empat sudut, merek, model dan warna mobil, serta hasil 10 inspeksi DCC sebelumnya, digunakan sebagai tanda. Sebagai variabel target, kami mengambil jawaban untuk semua pertanyaan verifikasi, misalnya: "Apakah mobilnya rusak?" atau "Apakah warna mobil cocok dengan yang ada di kartu pengemudi?" Variabel target utama adalah jawaban untuk pertanyaan utama: "Apakah perlu membatasi kemampuan pengemudi untuk menerima pesanan?" Kami mengajarkan satu model besar, sangat mirip dengan VGG dengan perhatian SENet, untuk menjawab semua pertanyaan pada saat yang sama dan sebagai hasilnya kami mengalami beberapa masalah.

Pendekatan All-in-One
Masalah pendekatan "sekaligus":
- Kami tidak dapat menjawab pertanyaan tentang korespondensi nomor mobil di foto yang ditunjukkan dalam kartu pengemudi. Sebuah jaringan besar untuk mengklasifikasikan gambar tidak dapat mengatasi tugas ini, untuk ini kita memerlukan model Optical Character Recognition (OCR) khusus, yang diasah untuk mengenali plat nomor.
- Variabel target tidak lengkap dan berisik. Menemukan cacat serius dalam penampilan mobil, yang cukup untuk membuat keputusan, penilai sering lupa menjawab pertanyaan lain. Jadi, jika mobil di foto itu kotor dan rusak, maka dengan probabilitas tinggi kami hanya mengamati satu dari tanda: "mobil kotor" atau "mobil dengan kerusakan", sedangkan kedua model diperlukan untuk model kami.
- Tidak ada interpretabilitas dari solusi model. Model dapat menjawab pertanyaan verifikasi utama dengan akurasi lebih tinggi daripada acak, tetapi jawaban ini berkorelasi lemah dengan jawaban untuk pertanyaan lain. Dengan kata lain, jika jawabannya adalah: "Perlu membatasi kemampuan untuk menerima pesanan," kami hampir tidak pernah melihat alasan untuk keputusan seperti itu dalam sisa jawaban model. Secara umum, keakuratan jawaban untuk semua pertanyaan, kecuali yang utama, mendekati acak. Kami tidak dapat menjelaskan kepada pengemudi apa yang sebenarnya perlu diperbaiki untuk menerima pesanan lagi, yang berarti bahwa kami tidak dapat membatasi kemampuan pengemudi untuk menerima pesanan.
- Jumlah kesalahan negatif palsu dalam jawaban atas pertanyaan: "Apakah perlu membatasi kemampuan pengemudi untuk menerima pesanan?" - terlalu besar untuk mulai secara otomatis menyetujui cek. Kami tidak dapat memberikan FNR yang sama seperti pada sistem yang berjalan tanpa pembelajaran mesin, dan ini adalah salah satu persyaratan dalam tugas kami.
Bersama-sama, keempat alasan ini tidak memungkinkan kami untuk menerapkan solusi pertama, tetapi kami tidak putus asa dan menemukan solusi kedua.
Solusi kedua, atau pendekatan "semua kecuali secara bertahap"
Kami memutuskan untuk fokus memeriksa bagian luar mobil, karena mereka membentuk sekitar 70% dari total aliran. Selain itu, kami memutuskan untuk membagi tugas umum menjadi sub-tugas dan belajar bagaimana menjawab semua pertanyaan DCC secara terpisah.

Dekati “segalanya, tetapi secara bertahap”
Sekali waktu, layanan kami sudah terlibat dalam otomatisasi DCC dan berhasil memperkenalkan model yang memungkinkan Anda untuk memfilter foto yang gelap dan tidak relevan. Kami terus menggunakan model ini lebih lanjut untuk menjawab pertanyaan: "Apakah ada foto mobil yang sebenarnya berikut ini: depan, sisi kiri, sisi kanan, belakang?".
Pekerjaan kami pada solusi kedua dimulai dengan fakta bahwa kami menggunakan Yandex. Cari model layanan visi komputer (dari orang-orang yang membuat DeepHD ) untuk mengenali plat nomor pada mobil. Jadi kami dapat menjawab pertanyaan: "Apakah nomor dan kode wilayah mobil sepenuhnya sesuai dengan yang ditunjukkan dalam kartu pengemudi?" Jika kita membicarakan hal ini lebih terinci, kami membandingkan hasil pengakuan dengan angka yang tertera pada kartu pengemudi dan, tergantung pada jarak Levenshtein di antara mereka, kami memilih salah satu dari opsi jawaban: "angka cocok", "angka tidak cocok" atau "pertanyaan tidak dapat dijawab dengan tepat".
Selanjutnya, kami melatih pengklasifikasi mobil untuk mengenali merek dan model, serta warna. Dari saat ini kita dapat menjawab pertanyaan: "Apakah warna, model, dan warna mobil yang tertera pada kartu pengemudi?"
Sebagai kesimpulan, kami melatih pengklasifikasi untuk menemukan mobil yang rusak dan kotor, ini memungkinkan kami untuk menutup pertanyaan: "Apakah ada kerusakan atau cacat pada bodi mobil?" dan "Seberapa kotor badan mobil itu?"
Pendekatan "semua tapi secara bertahap" memungkinkan kami untuk memecahkan masalah memeriksa nomor plat mobil. Kami juga dapat menyingkirkan ketidaklengkapan dan keributan dari variabel target, karena sekarang kami memiliki pilihan di mana objek kelas negatif sepenuhnya berhasil diperiksa, dan objek kelas positif memeriksa di mana penilai atau ketiga Yandex.Tolki pelaksana Polandia menemukan kesalahan tertentu, misalnya, kerusakan pada kasus tersebut . Setelah menyelesaikan dua masalah pertama, model kami menjadi dapat ditafsirkan, dan kami dapat menjelaskan kepada pengemudi alasan pembatasan tersebut, sehingga dengan tes berikutnya ia akan memperbaiki kekurangannya. Kualitas keseluruhan jawaban atas pertanyaan juga telah tumbuh secara signifikan, dan FPR dan FNR untuk beberapa kombinasi ambang batas kepercayaan model telah jatuh ke tingkat Yandex.Tolki, yang memungkinkan model untuk diperkenalkan ke dalam produksi.
Implementasi dalam produksi
Kami punya pilihan: untuk meluncurkan proses reguler yang akan menerapkan model pada cek yang terakumulasi dalam antrian, atau untuk membuat layanan terpisah di mana Anda dapat pergi melalui API dan menerima respons model secara real time. Karena penting bagi kita untuk cepat menemukan mobil "buruk", kami memilih opsi kedua. Segera setelah bagian utama dari layanan ini ditulis dan ia dapat mendukung fungsionalitas yang diperlukan, kami mulai menambahkan model ke dalamnya.
Untuk sepenuhnya menyetujui cek, Anda harus dapat menjawab semua pertanyaan dari instruksi, tetapi untuk membatasi akses pengemudi yang tidak bermoral ke layanan, dalam beberapa kasus cukup untuk dapat menjawab setidaknya satu pertanyaan. Oleh karena itu, kami memutuskan untuk tidak menunggu sampai semua model siap, tetapi menambahkannya saat tersedia. Pipa umum menambahkan model tampak seperti ini:
- Kumpulkan sampel.
- Latih modelnya.
- Ukur kualitas dan pilih ambang offline.
- Tambahkan model ke layanan di latar belakang dan ukur kualitas online.
- Masukkan model dalam produksi dan mulailah mengambil keputusan berdasarkan prediksi.
Pendekatan ini memungkinkan kami tidak hanya untuk secara instan menemukan semakin banyak mobil "buruk" ketika model baru diperkenalkan, tetapi juga untuk mengukur kualitas online tanpa biaya waktu tambahan saat model bekerja di latar belakang.
Pada akhirnya, saatnya tiba ketika kami menambahkan ke layanan dan menguji model terbaru. Sekarang kita bisa menjawab semua pertanyaan inspeksi, yang berarti mereka akan secara otomatis disetujui. Karena ada lebih banyak mobil "bagus" di Yandex.Taxi daripada yang "buruk", persetujuan inspeksi otomatis telah menghasilkan peningkatan tajam pada metrik utama kami - bagian dari arus inspeksi otomatis. Kami hanya bisa memilih ambang batas yang tepat yang akan memaksimalkan pangsa pemeriksaan otomatis, sambil mempertahankan FPR dan FNR keseluruhan dari keseluruhan sistem pada tingkat yang sama. Untuk memilih ambang, kami menggunakan sampel yang ditandai secara independen oleh pelaksana Yandex.Tolki, penilai, dan karyawan Yandex.Taxi yang melatih penilai untuk memeriksa mobil. Kami menggunakan markupnya sebagai nilai sebenarnya dari variabel target.
Hasil
Segera setelah kami memasukkan model dalam produksi, penting untuk mengukur kualitas keputusan online yang dibuat berdasarkan jawaban mereka. Dan inilah angka-angka yang kami lihat:
- 30% dari pemeriksaan eksterior kendaraan sekarang menerima respons otomatis.
- FNR tetap pada level yang sama, sementara FPR turun, dan kami mulai jarang membatasi akses ke layanan untuk mereka yang tidak pantas mendapatkannya.
- Beban pada penilai menurun sebesar 14%, dan mereka dapat mencurahkan lebih banyak waktu untuk tes kompleks yang tidak dapat dilakukan oleh layanan pembelajaran mesin.
- Waktu deteksi untuk mobil dengan cacat serius selama inspeksi berkurang dari beberapa jam menjadi beberapa detik.
Dengan demikian, pengenalan pembelajaran mesin tidak hanya membantu menghemat uang, tetapi juga membuat layanan lebih aman dan nyaman bagi pengguna. Namun, ini masih jauh dari akhir cerita. Tim kami yang berkembang pesat akan terus bekerja secara aktif untuk mengotomatiskan lebih banyak cek dan membuat Yandex.Taxi semakin nyaman, nyaman dan aman.
Moral sejarah
Saat bekerja pada otomatisasi DCC di Yandex.Taxi, kami menghadapi banyak masalah, menemukan beberapa solusi yang berhasil dan membuat enam kesimpulan penting:
- Tidak selalu mungkin untuk menyelesaikan masalah secara langsung (bahkan jika Anda memiliki pembelajaran mendalam).
- Model ini sebagus data yang dilatihnya (terdengar klise, tetapi memang demikian).
- Dalam memecahkan masalah apa pun, penting untuk membangun kebutuhan nyata bisnis, dan bukan meminimalkan cross-entropy.
- Dalam memecahkan beberapa masalah, orang masih penting, meskipun pengenalan pembelajaran mesin (halo, Yandex.Toloka!).
- Keputusan berdasarkan prediksi model pembelajaran mesin mungkin tidak dibuat dalam semua kasus, tetapi hanya pada bagian di mana model sangat percaya diri dalam jawaban mereka. Dalam kasus lain, mungkin layak membuat keputusan dengan cara lama - dengan bantuan orang.
- Selain pilihan arsitektur dan pelatihan model, ada banyak lagi tahapan proyek yang dapat sangat mempengaruhi seberapa baik masalah bisnis diselesaikan. Tahapan-tahapan ini adalah: pengumpulan data, pemilihan metrik kualitas, opsi implementasi model, logika pengambilan keputusan produk berdasarkan prediksi model, dan banyak lagi.
Lebih dari menarik tentang teknologi Taksi
Harga dinamis, atau Bagaimana Yandex.Taxi memprediksi permintaan tinggi .
Bagaimana Yandex.Taxi memprediksi waktu pengiriman mobil menggunakan pembelajaran mesin .