Ketika mengembangkan suatu produk, mereka jarang memperhatikan kinerjanya dengan intensitas tinggi permintaan yang masuk. Sedikit atau tidak melakukan ini sama sekali - tidak ada cukup waktu, spesialis, atau mereka membenarkan diri mereka dengan ungkapan khas: "Semuanya bekerja dengan cepat pada kita di prod, jadi mengapa memeriksa sesuatu yang lain?" Dalam kasus seperti itu, mungkin akan tiba saatnya ketika produksi yang berfungsi baik tiba-tiba jatuh karena arus pengunjung yang melonjak, misalnya, di bawah Habraeffect. Maka menjadi jelas bahwa melakukan penelitian tentang produktivitas sangat diperlukan.
Tugas ini membingungkan banyak orang karena ada kebutuhan, tetapi tidak ada pemahaman yang jelas tentang apa dan bagaimana mengukur dan bagaimana menafsirkan hasilnya, kadang-kadang tidak ada persyaratan non-fungsional yang terbentuk. Berikutnya, saya akan berbicara tentang di mana harus memulai jika Anda memutuskan untuk pergi rute ini, dan menjelaskan metrik apa yang penting dalam penelitian kinerja dan bagaimana menggunakannya.
Sedikit teori
Bayangkan kita memiliki aplikasi bola dalam ruang hampa - ia menerima permintaan dan memberikan jawaban kepada mereka. Untuk kesederhanaan, itu bisa berupa layanan microser dengan satu metode yang tidak pergi ke mana pun dan tidak bergantung pada komponen atau aplikasi lain. Dalam hal ini, kami tidak terlalu tertarik dengan apa yang tertulis, bagaimana kerjanya dan dalam lingkungan apa diluncurkan.
Apa yang ingin kita ketahui tentang kinerja secara umum? Mungkin baik untuk mengetahui aliran maksimum permintaan masuk di mana layanan stabil, kinerjanya dengan aliran ini dan waktu yang diperlukan untuk menyelesaikan satu permintaan. Sangat bagus jika Anda dapat menentukan alasan yang membatasi pertumbuhan produktivitas lebih lanjut.
Jelas, Anda perlu mengukur waktu respons terhadap permintaan, masing-masing, dengan aliran permintaan atau intensitas yang masuk, kami akan berarti jumlah permintaan per unit waktu, biasanya per detik, dan kinerja - jumlah respons terhadap unit waktu yang sama. Waktu respons dapat tersebar dalam rentang yang luas, jadi bagi pemula, masuk akal untuk menyajikannya sebagai rata-rata per detik.
Selain itu, masalah dapat muncul di berbagai tingkatan: dimulai dengan fakta bahwa layanan menjawab dengan kesalahan (dan itu baik jika itu lima ratus, dan bukan "200 OK {" status ":" error "}", dan diakhiri dengan fakta bahwa layanan berhenti merespons sama sekali atau jawaban mulai hilang di tingkat jaringan. Permintaan yang gagal harus dapat ditangkap, dan mudah untuk menyajikannya sebagai persentase dari total. Grafik kinerja, waktu respons, dan tingkat kesalahan versus intensitas adalah seperti ini:
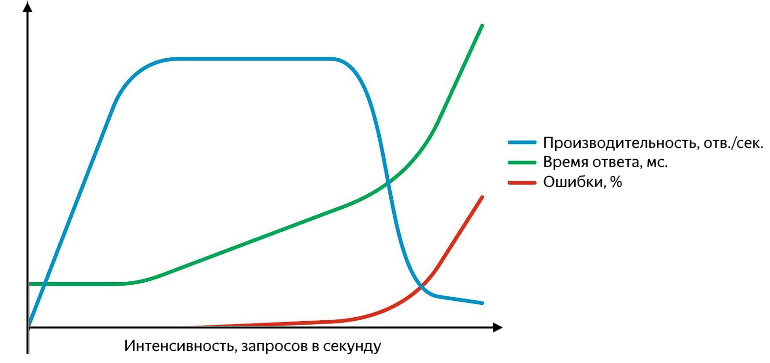
Dengan meningkatnya intensitas permintaan, waktu respons dan peningkatan tingkat kesalahan
Sementara produktivitas tumbuh secara linear dengan intensitas, layanan baik-baik saja. Berhasil memproses seluruh aliran permintaan masuk, waktu respons tidak berubah, tidak ada kesalahan. Terus meningkatkan intensitas, kami memperoleh perlambatan dalam pertumbuhan produktivitas sampai saat kejenuhan, di mana produktivitas mencapai maksimum dan waktu respons mulai tumbuh. Peningkatan intensitas berikutnya akan menyebabkan kebingungan - peningkatan waktu respons yang signifikan dan penurunan produktivitas, pertumbuhan kesalahan yang aktif akan dimulai. Pada tahap pertumbuhan dan saturasi, ada dua poin penting - kinerja normal dan maksimum.
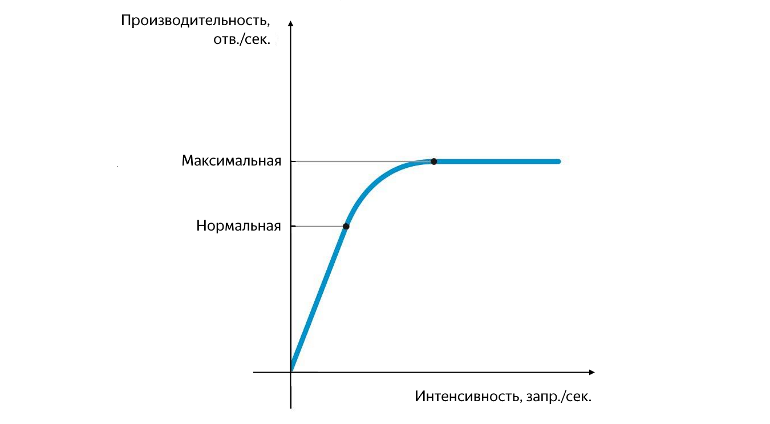
Posisi kinerja normal dan maksimum
Produktivitas normal dicapai pada saat ketika tingkat pertumbuhannya mulai menurun, dan maksimum - pada saat ketika tingkat pertumbuhannya menjadi nol. Memisahkan kinerja antara normal dan maksimum sangat penting. Pada intensitas yang sesuai dengan kinerja normal, aplikasi harus bekerja secara stabil, dan nilai kinerja normal mencirikan ambang setelah kemacetan layanan mulai muncul, yang berdampak negatif pada operasinya. Ketika kinerja maksimum tercapai, hambatan mulai sepenuhnya membatasi pertumbuhan lebih lanjut, layanan tidak stabil, dan, sebagai aturan, pada saat ini latar belakang kesalahan yang kecil namun stabil mulai muncul.
Masalahnya dapat disebabkan oleh berbagai alasan - antrian diblokir, tidak ada cukup utas, kumpulan telah habis, CPU atau RAM telah sepenuhnya digunakan, kecepatan baca / tulis yang tidak memadai dari disk, dan sejenisnya. Penting untuk dipahami bahwa mengoreksi satu hambatan akan mengakibatkan kinerja menjadi terbatas oleh yang berikutnya dan seterusnya. Tidak mungkin untuk benar-benar menghilangkan hambatan, itu hanya bisa dipindahkan.
Eksperimennya
Pertama-tama, perlu untuk menentukan besarnya intensitas di mana layanan mencapai kinerja normal dan maksimum, dan waktu respons rata-rata yang sesuai. Untuk melakukan ini, dalam percobaan, cukup meningkatkan aliran permintaan yang masuk. Lebih sulit untuk menentukan nilai intensitas maksimum dan waktu percobaan.
Anda dapat mulai dari apa yang tertulis dalam persyaratan non-fungsional (jika ada), dari beban pengguna maksimum dari penjualan, atau cukup mengambil nilai dari langit-langit. Jika intensitas aliran yang masuk tidak cukup, layanan tidak akan punya waktu untuk mencapai saturasi dan perlu mengulangi percobaan. Jika intensitasnya terlalu tinggi, layanan akan sangat cepat mencapai saturasi, dan kemudian debugging. Dalam kasus seperti itu, mudah untuk melakukan pemantauan sehingga dengan peningkatan jumlah kesalahan yang signifikan, Anda tidak boleh membuang waktu dengan sia-sia dan menghentikan percobaan.
Dalam percobaan kami, kami secara bertahap meningkatkan intensitas dari 0 hingga 1000 permintaan per detik selama 10 menit. Ini cukup untuk layanan untuk mencapai saturasi, dan kemudian, jika perlu, kami menyesuaikan waktu dan intensitas dalam percobaan berikutnya untuk mendapatkan hasil yang lebih akurat. Pada grafik di atas, semuanya mulus dan indah, tetapi di dunia nyata bisa sulit pada pandangan pertama untuk menentukan nilai kinerja normal.
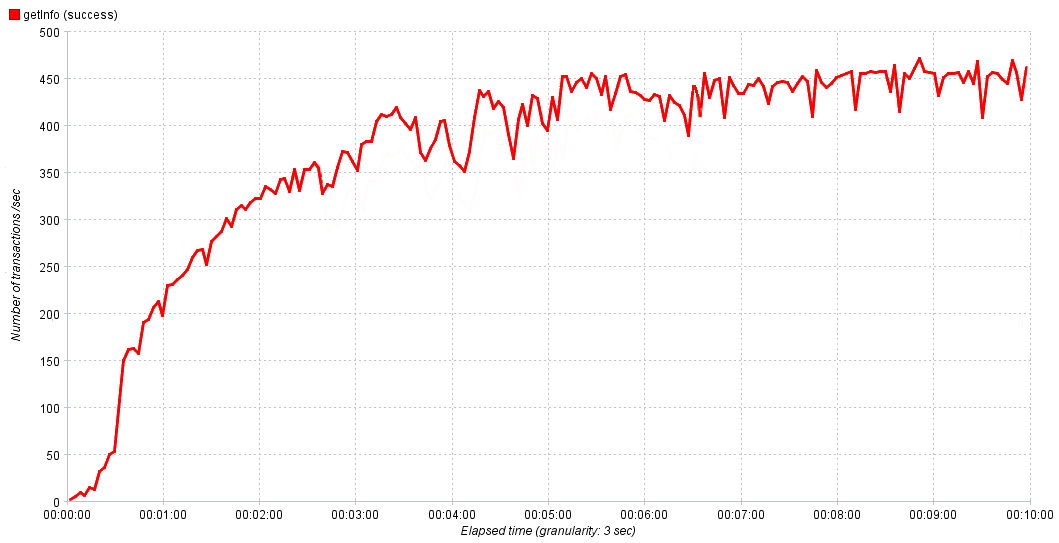
Ketergantungan nyata dari kinerja layanan tepat waktu
Dalam hal ini, kami mengambil 80-90% dari maksimum untuk kinerja normal. Jika kita mengamati pertumbuhan aktif kesalahan setelah mencapai saturasi, masuk akal untuk menyelidikinya, karena itu adalah hasil dari kemacetan, mempelajarinya akan membantu melokalkannya dan meneruskannya untuk koreksi.
Jadi, hasil pertama didapat. Sekarang kita tahu kinerja aplikasi normal dan maksimum, serta waktu respons yang sesuai dengannya. Hanya itu semua Tentu tidak! Dengan kinerja normal, layanan harus bekerja secara stabil, yang berarti Anda perlu memeriksa operasinya di bawah beban normal untuk sementara waktu. Yang mana Anda dapat kembali melihat persyaratan non-fungsional, bertanya pada analis, atau memantau durasi periode aktivitas maksimum pada prod. Dalam percobaan kami, kami meningkatkan beban dari 0 ke normal secara normal dan bertahan selama 10-15 menit. Ini cukup jika beban pengguna maksimum secara signifikan kurang dari normal, tetapi jika sebanding, waktu percobaan harus ditingkatkan.
Untuk dengan cepat mengevaluasi hasil percobaan, mudah untuk mengumpulkan data yang diperoleh dalam bentuk metrik berikut:
- waktu respon rata-rata
- median
- 90% persentil
- % kesalahan
- kinerja.
Apa waktu respons rata-rata dapat dipahami, tetapi rata-rata adalah ukuran yang memadai hanya dalam kasus distribusi normal sampel, karena terlalu sensitif terhadap "pencilan" - nilai terlalu besar atau terlalu kecil yang sangat bergeser dari tren umum. Median adalah bagian tengah dari seluruh sampel waktu respons, setengah dari nilai kurang dari itu, sisanya lebih besar. Mengapa itu dibutuhkan?
Pertama, berdasarkan definisinya, ia kurang sensitif terhadap pencilan, yaitu metrik yang lebih memadai, dan kedua, dengan membandingkannya dengan rata-rata, orang dapat dengan cepat menilai karakteristik distribusi respons. Dalam situasi yang ideal, keduanya sama - distribusi waktu respons adalah normal, dan layanannya baik-baik saja!
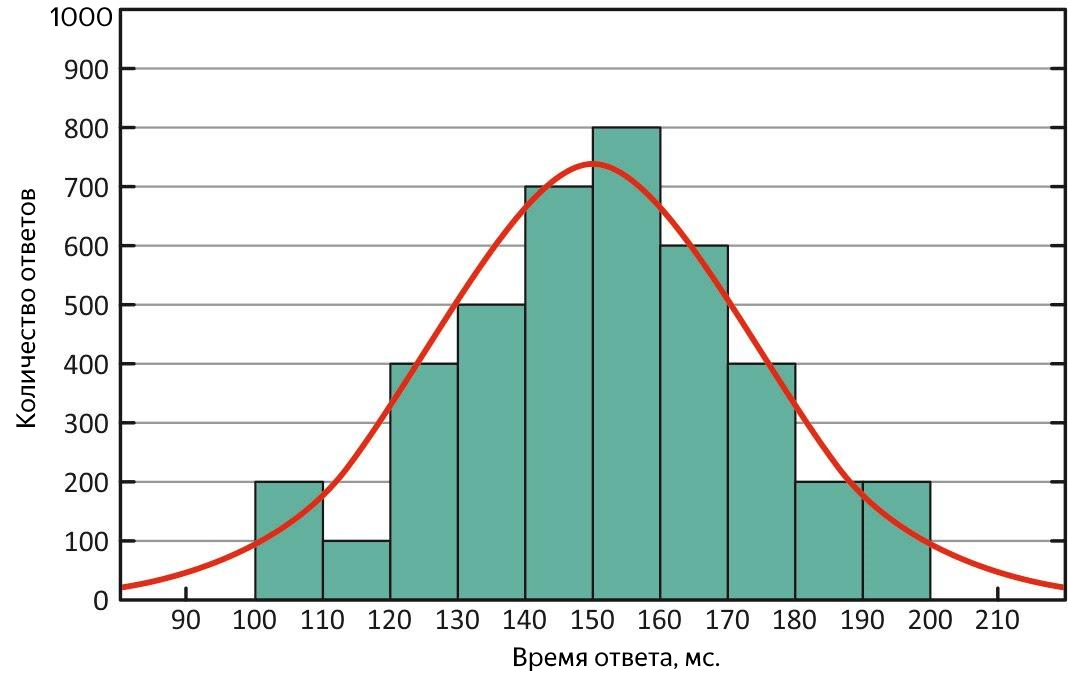
Distribusi waktu respons yang normal. Dengan distribusi ini, mean dan median setara
Jika rata-rata sangat berbeda dari median, maka distribusinya miring, dan "pencilan" dapat hadir selama percobaan. Jika rata-rata lebih besar - ada periode ketika layanan merespons sangat lambat, dengan kata lain, itu melambat.
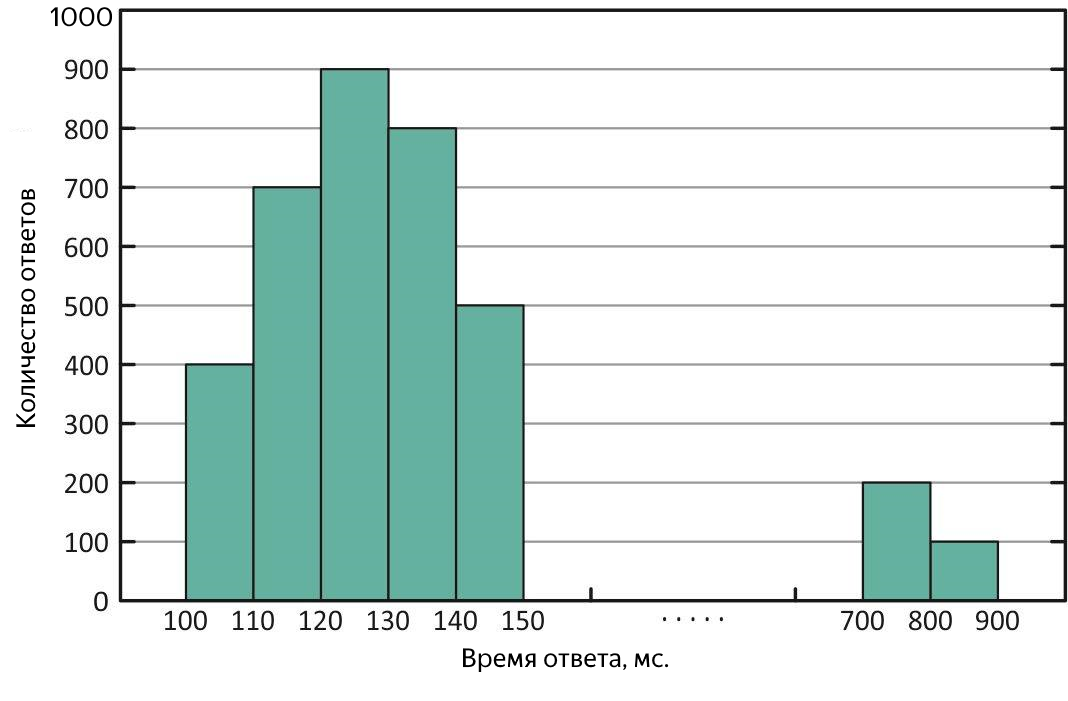
Distribusi waktu respons dengan "outliers" dari jawaban yang panjang. Dengan distribusi ini, rata-rata lebih besar dari median.
Kasus-kasus seperti itu membutuhkan analisis tambahan. Untuk memperkirakan skala "emisi," kuantil atau persentil datang untuk menyelamatkan.
Kuantil, dalam konteks sampel yang diperoleh, adalah nilai waktu respons, yang cocok untuk semua bagian permintaan. Jika Anda menggunakan% kueri, maka ini adalah persentil (omong-omong, median adalah persentil 50%). Lebih mudah menggunakan persentil 90% untuk memperkirakan emisi. Misalnya, sebagai hasil percobaan, median 100 ms diperoleh, dan rata-rata - 250 ms, melebihi median 2,5 kali! Jelas, ini tidak sepenuhnya baik, kami melihat pada 90% kuantil, dan ada 1000 ms - sebanyak 10% dari semua permintaan yang berhasil diselesaikan selama lebih dari satu detik, berantakan, Anda perlu mengetahuinya. Untuk mencari kueri panjang, Anda dapat menggigit file dengan hasil percobaan atau langsung di log layanan, tetapi lebih baik untuk menyajikan waktu respons rata-rata dalam bentuk grafik versus waktu, itu akan segera menunjukkan waktu dan sifat dari "outlier" yang tersedia.
Ringkasan
Jadi, Anda berhasil melakukan eksperimen dan mendapatkan hasilnya. Baik atau buruk, itu tergantung pada persyaratan untuk layanan, tetapi bukan angka yang diperoleh lebih penting, tetapi mengapa angka-angka ini, dan memahami apa pertumbuhan selanjutnya dibatasi oleh. Jika Anda berhasil menemukan hambatan - sangat bagus, jika tidak, maka cepat atau lambat kebutuhan akan produktivitas dapat meningkat, dan Anda masih harus mencarinya, jadi terkadang lebih mudah untuk mencegah situasi.
Dalam catatan ini, saya memberikan pendekatan dasar untuk meneliti kinerja dengan menjawab pertanyaan yang saya miliki di awal. Jangan takut untuk meneliti kinerja, itu perlu!
PS
Kunjungi ruang obrolan telegram kami yang nyaman di mana Anda dapat mengajukan pertanyaan, membantu dengan saran dan hanya berbicara tentang riset kinerja.