
Seperti biasa, terima kasih kepada Fred Hebert dan Sargun Dhillon untuk membaca draf artikel ini dan menawarkan beberapa saran yang sangat berharga.
Dalam pembicaraannya tentang kecepatan, Tamar Berkovichi of Box menekankan pentingnya pemeriksaan kinerja untuk kegagalan basis data otomatis. Secara khusus, ia mencatat bahwa pemantauan waktu eksekusi query end-to-end, sebagai metode untuk menentukan kesehatan database, lebih baik daripada ping sederhana (ping).
... mentransfer lalu lintas ke node lain (replika) untuk menghilangkan kelambanan, perlu untuk membangun perlindungan dari bouncing dan situasi perbatasan lainnya. Itu tidak sulit. Fokus dalam mengorganisasikan kerja yang efektif adalah untuk mengetahui kapan harus meletakkan basis data di posisi pertama, mis. Anda harus dapat mengevaluasi kesehatan database dengan benar. Sekarang, banyak parameter yang biasa kita perhatikan - misalnya, beban prosesor, latensi, tingkat kesalahan - adalah sinyal sekunder. Tak satu pun dari parameter ini yang benar-benar berbicara tentang kemampuan basis data untuk memproses lalu lintas klien. Karena itu, jika Anda menggunakannya untuk membuat keputusan tentang beralih, Anda bisa mendapatkan hasil positif palsu dan negatif palsu. Pemeriksa kesehatan kami benar-benar melakukan kueri sederhana pada node basis data dan menggunakan data pada kueri yang lengkap dan gagal untuk menilai kesehatan basis data secara lebih akurat.
Saya membahas hal ini dengan seorang teman, dan dia menyarankan agar pemeriksaan kesehatan harus sangat sederhana, dan bahwa lalu lintas nyata adalah kriteria terbaik untuk mengevaluasi kesehatan suatu proses.
Seringkali, diskusi yang terkait dengan pelaksanaan pemeriksaan kesehatan berputar di sekitar dua opsi yang berlawanan: komunikasi sederhana / tes sinyal atau tes ujung ke ujung yang kompleks. Dalam artikel ini saya ingin menekankan masalah yang terkait dengan penggunaan bentuk pemeriksaan kesehatan yang disebutkan di atas untuk beberapa jenis solusi penyeimbangan beban, serta perlunya pendekatan yang lebih rinci untuk menilai kesehatan suatu proses.
Dua jenis pemeriksaan kesehatan
Pemeriksaan kesehatan, bahkan dalam banyak sistem modern, pada umumnya, terbagi dalam dua kategori: pemeriksaan di tingkat simpul dan di tingkat layanan.
Misalnya, Kubernet mengimplementasikan validasi dengan menganalisis kesiapan dan kemampuan bertahan . Pemeriksaan ketersediaan digunakan untuk menentukan kemampuan perapian untuk melayani lalu lintas. Jika pemeriksaan kesiapan tidak dilakukan, itu dihapus dari titik akhir yang membentuk layanan , dan karena ini, di perapian, sampai pemeriksaan selesai, tidak ada lalu lintas yang diarahkan. Di sisi lain, pemeriksaan kemampuan bertahan digunakan untuk menentukan apakah suatu layanan merespons hang atau terkunci. Jika gagal, masing-masing wadah di kubelet dihidupkan ulang . Demikian pula, Konsul memungkinkan beberapa bentuk checks : berbasis script , checks berbasis HTTP diarahkan ke URL tertentu, pemeriksaan berbasis TTL, atau bahkan alias.
Metode yang paling umum untuk menerapkan pemeriksaan kesehatan di tingkat layanan adalah menentukan titik akhir pemeriksaan kesehatan. Misalnya, di gRPC, pemeriksaan kesehatan sendiri menjadi panggilan RPC. gRPC juga memungkinkan untuk pemeriksaan kesehatan tingkat layanan dan pemeriksaan kesehatan server gRPC umum.
Di masa lalu, pemeriksaan kesehatan tingkat inang digunakan sebagai sinyal untuk memicu peringatan. Misalnya, peringatan dengan beban prosesor rata-rata (saat ini dianggap sebagai pola anti-desain). Sekalipun pemeriksaan kesehatan tidak digunakan secara langsung untuk pemberitahuan, itu tetap berfungsi sebagai dasar untuk sejumlah keputusan infrastruktur otomatis lainnya, misalnya, mengenai keseimbangan beban dan (kadang-kadang) sirkuit terbuka. Dalam skema data kisi-kisi layanan seperti Utusan, data pemeriksaan kesehatan , ketika harus menentukan perutean lalu lintas ke suatu instance, terus berjalan sehubungan dengan data penemuan layanan.
Efisiensi adalah spektrum, bukan taksonomi biner
Permintaan gema, atau ping, hanya dapat menetapkan apakah layanan berfungsi , sedangkan tes ujung ke ujung adalah proxy untuk menetapkan apakah sistem mampu melakukan unit kerja tertentu , di mana unit kerja dapat berupa kueri basis data atau perhitungan tertentu . Terlepas dari bentuk pemeriksaan kesehatan, hasilnya dianggap sebagai biner murni: "lulus" atau "gagal".
Dalam opsi infrastruktur yang dinamis dan sering kali "secara otomatis diskalakan", satu proses yang hanya "bekerja" tidak masalah jika tidak dapat melakukan unit kerja tertentu. Ternyata pemeriksaan yang disederhanakan, seperti pengujian gema, hampir tidak berguna.
Sangat mudah untuk menentukan kapan suatu layanan benar-benar terputus , tetapi untuk menetapkan tingkat operabilitas dari layanan yang berjalan jauh lebih sulit. Sangat mungkin bahwa proses sedang berjalan (mis., Pemeriksaan kesehatan berlalu), dan lalu lintas dialihkan, tetapi untuk melakukan unit kerja tertentu, misalnya, selama periode keterlambatan layanan p99, ini tidak cukup.
Seringkali, pekerjaan tidak dapat diselesaikan karena prosesnya kelebihan beban. Dalam layanan yang sangat kompetitif, "kemacetan" berkorelasi rapi dengan jumlah permintaan bersamaan yang diproses hanya oleh satu proses dengan antrian berlebihan, yang dapat menyebabkan peningkatan penundaan untuk panggilan RPC (meskipun lebih sering, layanan tingkat bawah hanya menahan permintaan dan mencoba lagi pada batas waktu). Ini terutama benar jika titik akhir pemeriksaan kesehatan dikonfigurasi untuk secara otomatis kembali ke kode status HTTP 200, sedangkan operasi aktual yang dilakukan oleh layanan melibatkan I / O jaringan atau perhitungan.

Kinerja proses adalah sebuah spektrum. Pertama-tama, kami tertarik pada kualitas layanan , misalnya, waktu yang diperlukan untuk proses mengembalikan hasil unit kerja tertentu, dan keakuratan hasilnya.
Ada kemungkinan bahwa proses berfluktuasi antara berbagai tingkat kapasitas kerja selama masa kerjanya: dari kapasitas kerja penuh (misalnya, kemampuan untuk berfungsi pada tingkat paralelisme yang diharapkan) ke titik tidak dapat dioperasikannya (ketika antrian mulai terisi) dan titik di mana proses sepenuhnya masuk ke zona tidak beroperasi (dirasakan) mengurangi kualitas layanan). Hanya layanan yang paling sepele yang dapat dibangun dengan asumsi bahwa tidak ada tingkat kegagalan parsial dalam periode di mana kegagalan parsial menyiratkan bahwa beberapa fungsi berfungsi dan yang lainnya dimatikan, dan tidak hanya "beberapa permintaan dieksekusi, beberapa tidak dieksekusi". Jika arsitektur layanan tidak memungkinkan memperbaiki sebagian kegagalan dengan benar, maka klien secara otomatis memperbaiki tugas koreksi kesalahan.
Infrastruktur penyembuhan diri yang adaptif harus dibangun dengan pemahaman bahwa fluktuasi seperti itu sangat normal . Penting juga untuk diingat bahwa perbedaan ini hanya penting dalam kaitannya dengan penyeimbangan beban - untuk orkestra, misalnya, tidak masuk akal untuk memulai kembali proses hanya karena proses berada di ambang kelebihan beban.
Dengan kata lain, untuk tingkat orkestrasi, cukup masuk akal untuk mempertimbangkan operabilitas proses sebagai keadaan biner dan memulai kembali proses hanya setelah kegagalan atau pembekuan. Tetapi di lapisan penyeimbangan beban (apakah itu proxy eksternal, misalnya, Utusan, atau perpustakaan internal di sisi klien), sangat penting bahwa itu bertindak berdasarkan informasi yang lebih terperinci tentang pengoperasian proses - ketika membuat keputusan yang tepat tentang memutus rangkaian dan membuang muatan. Degradasi bertahap layanan tidak mungkin jika tidak mungkin untuk secara akurat menentukan tingkat kinerja layanan setiap saat.
Biarkan saya memberi tahu Anda dari pengalaman: konkurensi tak terbatas seringkali merupakan faktor utama yang menyebabkan penurunan layanan atau penurunan produktivitas secara permanen. Penyeimbangan beban (dan, sebagai akibatnya, penumpahan beban) sering bermuara pada pengelolaan konkurensi secara efisien dan menerapkan tekanan balik, mencegah sistem dari kelebihan muatan.
Kebutuhan akan umpan balik saat menerapkan tekanan balik
Matt Ranney menulis sebuah artikel fenomenal tentang konkurensi tak terbatas dan kebutuhan akan tekanan balik di Node.js. Seluruh artikel ini penasaran, tetapi kesimpulan utama (setidaknya bagi saya) adalah perlunya umpan balik antara proses dan unit outputnya (biasanya penyeimbang beban, tetapi terkadang layanan lain).
Kuncinya adalah ketika sumber daya habis, sesuatu harus diberikan di suatu tempat. Permintaan tumbuh, dan produktivitas tidak dapat secara ajaib meningkat. Untuk membatasi tugas yang masuk, hal pertama yang harus dilakukan adalah menetapkan batas kecepatan tertentu di tingkat situs, berdasarkan alamat IP, pengguna, sesi, atau, paling-paling, oleh beberapa elemen penting untuk aplikasi. Banyak penyeimbang beban dapat membatasi kecepatan dengan cara yang lebih rumit daripada membatasi server Node.js yang masuk, tetapi biasanya mereka tidak melihat masalah sampai prosesnya dalam situasi yang sulit.
Batas kecepatan dan sirkuit terbuka berdasarkan ambang dan batas statis bisa tidak dapat diandalkan dan tidak stabil dalam hal kebenaran dan skalabilitas. Beberapa load balancers (khususnya, HAProxy) menyediakan banyak statistik tentang panjang antrian internal untuk setiap server dan bagian server . Selain itu, HAProxy memungkinkan agent-check (pemeriksaan tambahan tidak tergantung pada pemeriksaan kesehatan normal), yang memungkinkan proses menyediakan server proxy dengan umpan balik kesehatan yang lebih akurat dan dinamis. Tautan ke dokumen :
Pemeriksaan kesehatan agen dilakukan oleh koneksi TCP ke port berdasarkan parameter agent-port ditentukan dan membaca string ASCII. Baris terdiri dari serangkaian kata yang dipisahkan oleh spasi, tab atau koma dalam urutan apa pun, secara opsional berakhiran /r dan / atau /n dan termasuk elemen-elemen berikut:
- Representasi nilai persentase integer positif ASCII, misalnya, 75% . Nilai-nilai dalam format ini menentukan bobot sebanding dengan yang awal
Nilai server tertimbang yang dikonfigurasi saat memulai HAProxy. Harap dicatat bahwa nilai nol bobot ditunjukkan pada halaman statistik sebagai DRAIN dari saat dampak yang serupa pada server (dihapus dari tambak LB).
- maxconn parameter string: diikuti oleh integer (tanpa spasi). Nilai dalam
Format ini menentukan maxconn server maxconn . Jumlah maksimum
koneksi yang dideklarasikan harus dikalikan dengan jumlah penyeimbang beban dan berbagai bagian server menggunakan pemeriksaan kesehatan ini untuk mendapatkan jumlah total koneksi yang dapat dibuat server. Sebagai contoh: maxconn:30
- Kata ready . Ini menerjemahkan keadaan administrasi server ke
Mode READY , membatalkan status DRAIN atau MAINT .
- Kata drain . Ini menerjemahkan keadaan administrasi server ke
Mode DRAIN ("tiriskan"), setelah itu server tidak akan menerima koneksi baru, dengan pengecualian koneksi yang diterima melalui database.
- Kata maint . Ini menerjemahkan keadaan administrasi server ke
Mode MAINT ("maintenance"), setelah itu server tidak akan menerima koneksi baru, dan pemeriksaan kesehatan berhenti.
- Kata-kata down , failed atau stopped , yang dapat diikuti oleh baris deskripsi setelah simbol tajam (#). Semuanya menunjukkan status operasional server DOWN ("mati"), tetapi karena kata itu sendiri ditampilkan di halaman statistik, perbedaannya memungkinkan administrator untuk menentukan apakah situasinya diharapkan: layanan mungkin sengaja dihentikan, beberapa tes konfirmasi mungkin muncul, tetapi gagal lulus, atau dianggap dinonaktifkan (tidak ada proses, tidak ada respons dari port).
- Kata di atas menunjukkan status operasional server UP ("on") jika pemeriksaan kesehatan juga mengkonfirmasi ketersediaan layanan.
Parameter yang tidak diklaim oleh agen tidak diubah. Misalnya, agen hanya dapat dirancang untuk memantau penggunaan prosesor dan hanya melaporkan nilai bobot relatif tanpa berinteraksi dengan kondisi pengoperasian. Demikian pula, program agen dapat dirancang sebagai antarmuka pengguna akhir dengan 3 sakelar yang memungkinkan administrator untuk hanya mengubah status administratif.
Namun, harus diingat bahwa hanya agen yang dapat membatalkan tindakannya sendiri, oleh karena itu, jika server diatur ke DRAIN atau DOWN menggunakan agen, agen harus melakukan tindakan lain yang setara untuk memulai kembali layanan.
Kegagalan untuk terhubung ke agen tidak dianggap sebagai kesalahan, karena kemampuan untuk terhubung diuji dengan secara teratur melakukan pemeriksaan kesehatan, yang mulai menggunakan parameter cek. Namun, jika pesan shutdown tiba, maka peringatan bukanlah ide yang baik untuk menghentikan agen, karena hanya agen yang melaporkan shutdown yang dapat mengaktifkan kembali server.
Skema komunikasi dinamis layanan ini dengan unit output sangat penting untuk menciptakan infrastruktur yang dapat beradaptasi sendiri. Contohnya adalah arsitektur tempat saya bekerja di pekerjaan sebelumnya.
Saya dulu bekerja di imgix , perusahaan startup pemrosesan gambar real-time. Menggunakan URL API sederhana, gambar diambil dan dikonversi secara waktu nyata dan kemudian digunakan di mana saja di dunia melalui CDN. Tumpukan kami cukup rumit ( seperti dijelaskan di atas ), tetapi singkatnya, infrastruktur kami mencakup tingkat penyeimbangan dan penyeimbangan muatan (bersama-sama dengan tingkat penerimaan data dari sumber), tingkat penyimpanan sumber, tingkat pemrosesan gambar dan tingkat pengiriman konten.

Level load balancing didasarkan pada layanan Spillway, yang bertindak sebagai proxy terbalik dan broker permintaan. Itu adalah layanan murni internal; di ambang, kami mulai nginx dan HAProxy dan Spillway, jadi itu tidak dirancang untuk menyelesaikan TLS atau melakukan fungsi lain dari set yang tak terhitung jumlahnya yang biasanya dalam kompetensi proxy perbatasan.
Spillway terdiri dari dua komponen: bagian klien (Spillway FE) dan broker. Meskipun pada awalnya kedua komponen berada dalam file biner yang sama, pada beberapa titik kami memutuskan untuk memisahkannya menjadi file biner terpisah yang digunakan secara bersamaan pada host yang sama. Terutama karena kedua komponen ini memiliki profil kinerja yang berbeda, dan bagian klien hampir sepenuhnya terhubung dengan prosesor. Tugas dari bagian klien adalah untuk melakukan pemrosesan awal dari setiap permintaan, termasuk verifikasi awal di tingkat caching sumber, untuk memastikan bahwa gambar di-cache di pusat data kami sebelum mengirim permintaan untuk konversi gambar ke pelaksana.
Pada waktu tertentu, kami memiliki kumpulan tetap (selusin atau lebih, jika ingatanku) dari seniman yang dapat dihubungkan ke broker Spillway yang sama. Artis bertanggung jawab atas konversi gambar yang sebenarnya (memotong, mengubah ukuran, pemrosesan PDF, rendering GIF, dll.). Mereka memproses semuanya mulai dari PDF ratusan halaman dan GIF dengan ratusan frame hingga file gambar sederhana. Fitur lain dari kontraktor adalah bahwa, meskipun semua jaringan sama sekali tidak sinkron, tidak ada konversi sebenarnya pada GPU itu sendiri. Karena kami bekerja secara real time, tidak mungkin untuk memprediksi seperti apa traffic kami pada titik waktu tertentu. Infrastruktur kami harus menyesuaikan diri dengan berbagai bentuk lalu lintas masuk - tanpa intervensi operator manual.
Mengingat pola lalu lintas yang berbeda dan heterogen yang sering kita temui, menjadi penting bagi para pelaku untuk menolak menerima permintaan yang masuk (bahkan ketika beroperasi penuh) jika menerima koneksi yang mengancam akan membebani pemain yang berlebih. Setiap permintaan untuk pemain berisi set metadata tertentu tentang sifat permintaan, yang memungkinkan pemain untuk menentukan apakah dia dapat melayani permintaan ini. Setiap pelaksana memiliki set data statistik sendiri tentang permintaan yang saat ini ia kerjakan. Karyawan menggunakan statistik ini bersama dengan metadata permintaan dan data heuristik lainnya, seperti data ukuran buffer socket, untuk menentukan apakah ia menerima permintaan yang masuk dengan benar. Jika karyawan tersebut memutuskan bahwa ia tidak dapat menerima permintaan tersebut, maka ia membuat respons yang tidak berbeda dari cek agen HAProxy yang memberitahukan Spillway tentang operabilitasnya.
Spillway memantau kinerja semua artis kolam renang. Pada awalnya saya mencoba mengirim permintaan tiga kali berturut-turut ke pelaksana yang berbeda (preferensi diberikan kepada mereka yang memiliki gambar asli di database lokal dan yang tidak kelebihan beban), dan jika ketiga pelaksana menolak untuk menerima permintaan, permintaan itu antri di broker di dalam memori. Pialang mendukung tiga bentuk antrian: antrian LIFO, antrian FIFO, dan antrian prioritas. Jika ketiga antrian dipenuhi, broker hanya menolak permintaan, memungkinkan klien (HAProxy) untuk mencoba lagi setelah periode penundaan. Ketika permintaan ditempatkan di salah satu dari tiga antrian, setiap pelaksana gratis dapat menghapusnya dari sana dan memprosesnya. Ada kesulitan tertentu yang terkait dengan menetapkan prioritas untuk permintaan dan memutuskan mana dari tiga antrian (LIFO, FIFO, antrian berdasarkan prioritas) yang harus ditempatkan, tetapi ini adalah topik untuk artikel terpisah.
Untuk pengoperasian layanan yang efektif, kami tidak perlu membahas bentuk umpan balik dinamis ini. Kami dengan hati-hati memantau ukuran antrian broker (ketiga antrian), dan Prometheus mengeluarkan salah satu peringatan utama ketika ukuran antrian melebihi batas tertentu (yang sangat jarang).
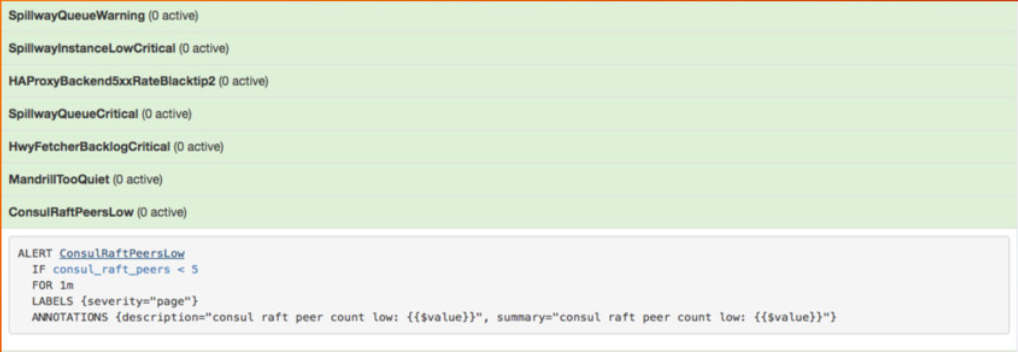
Gambar dari presentasi saya tentang sistem pemantauan Prometheus di Google NYC pada November 2016

Peringatan itu diambil dari presentasi saya tentang sistem pemantauan Prometheus di konferensi OSCON pada Mei 2017.
Pada awal tahun ini, Uber menerbitkan sebuah artikel yang menarik di mana ia menjelaskan pendekatannya dalam mengimplementasikan level pelepasan beban berdasarkan kualitas layanan.
Menganalisis kegagalan selama enam bulan terakhir, kami menemukan bahwa 28% dari mereka dapat dikurangi atau dicegah dengan degradasi yang lancar .
Tiga jenis kegagalan yang paling umum dikaitkan dengan faktor-faktor berikut:
- Perubahan skema permintaan masuk, termasuk kemacetan dan simpul operator yang buruk.
- Menipisnya sumber daya seperti prosesor, memori, sirkuit input / output atau sumber daya jaringan.
- Kegagalan ketergantungan, termasuk infrastruktur, gudang data, dan layanan hilir.
Kami menerapkan detektor kelebihan berdasarkan pada algoritma CoDel . Untuk setiap titik akhir yang diaktifkan, buffer permintaan yang ringan (diimplementasikan berdasarkan gourutin dan saluran ) ditambahkan untuk melacak penundaan antara saat menerima permintaan dari sumber panggilan dan dimulainya pemrosesan permintaan dalam handler. , , .
, , , - . 2013 Google «The Tail at Scale» , ( ), ( ) .
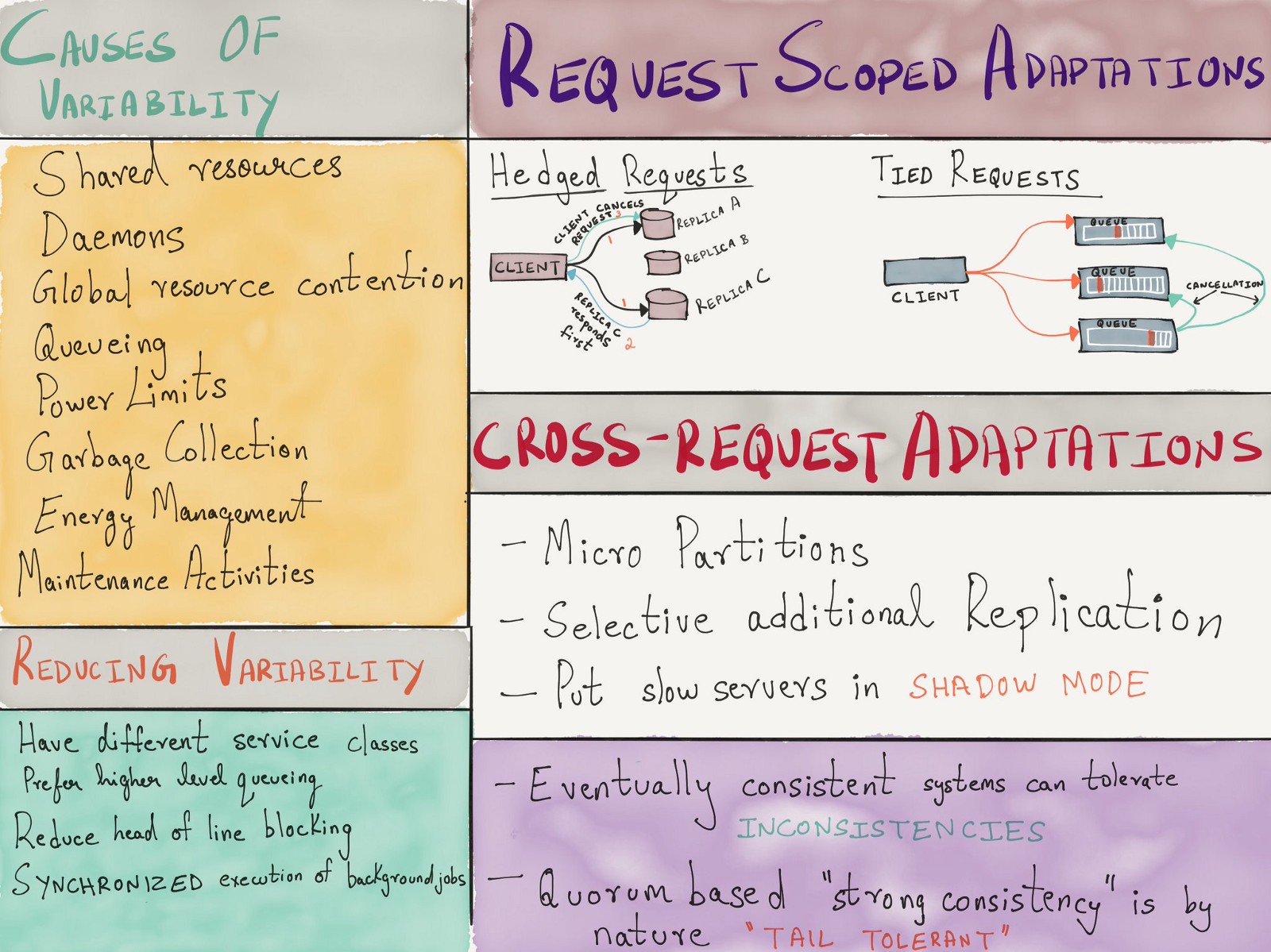
, . , .

( )
, , :
- , , QCon London 2018.
- : - , , LISA 2017.
- – , , Strangeloop 2017.
- : , , , Strangeloop 2017.
- « » .
Kesimpulan
, TCP/IP ( ), IP ECN ( IP ) Ethernet, , .
, . . , . .