Halo, Habr! Nama saya Pavel Lipsky. Saya seorang insinyur, saya bekerja untuk Sberbank-Technology. Spesialisasi saya adalah menguji toleransi kesalahan dan kinerja backend sistem terdistribusi besar. Sederhananya, saya merusak program orang lain. Dalam posting ini saya akan berbicara tentang injeksi kesalahan - metode pengujian yang memungkinkan Anda menemukan masalah dalam sistem dengan membuat kegagalan buatan. Saya akan mulai dengan bagaimana saya sampai pada metode ini, maka kita akan berbicara tentang metode itu sendiri dan bagaimana kita menggunakannya.
Artikel ini akan memiliki contoh Java. Jika Anda tidak pemrograman di Jawa - tidak apa-apa, cukup pahami pendekatan itu sendiri dan prinsip-prinsip dasar. Apache Ignite digunakan sebagai basis data, tetapi pendekatan yang sama berlaku untuk DBMS lainnya. Semua contoh dapat diunduh dari
GitHub saya.
Mengapa kita membutuhkan semua ini?
Saya akan mulai dengan ceritanya. Pada 2005, saya bekerja untuk Rambler. Pada saat itu, jumlah pengguna Rambler berkembang pesat, dan arsitektur dua-tier kami "server - database - server - application" berhenti mengatasi. Kami memikirkan cara mengatasi masalah kinerja, dan menarik perhatian pada teknologi memcached.
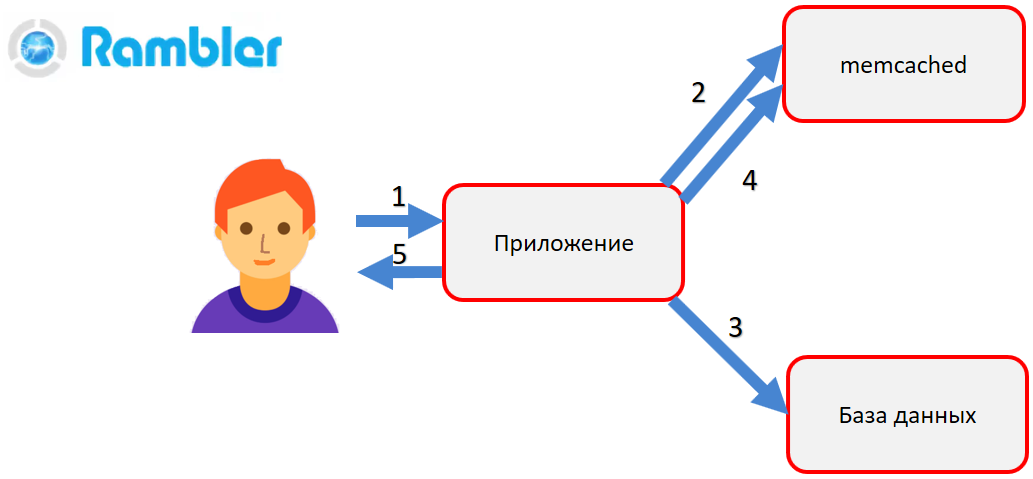
Apa itu memcached? Memcached - tabel hash dalam memori akses acak dengan akses ke objek yang disimpan dengan kunci. Misalnya, Anda perlu mendapatkan profil pengguna. Aplikasi mengakses memcached (2). Jika ada objek di dalamnya, maka itu segera dikembalikan ke pengguna. Jika tidak ada objek, maka banding dibuat ke database (3), objek dibentuk dan dimasukkan ke dalam memcached (4). Kemudian, pada panggilan berikutnya, kita tidak perlu lagi membuat panggilan sumber daya mahal ke database - kita akan mendapatkan objek siap pakai dari RAM - memcached.
Karena memcached, kami secara nyata menurunkan database, dan aplikasi kami mulai bekerja lebih cepat. Tetapi, ternyata, terlalu dini untuk bersukacita. Seiring dengan peningkatan produktivitas, kami mendapat tantangan baru.
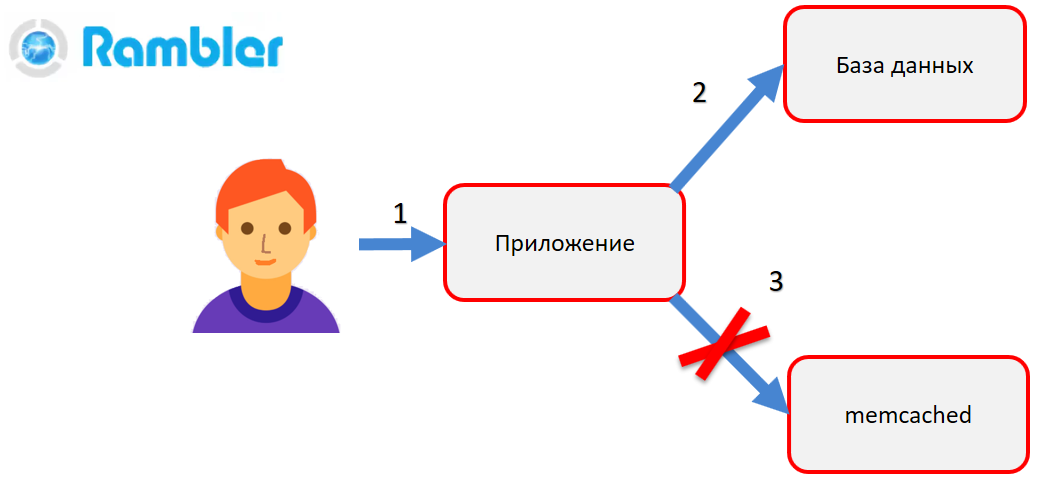
Ketika Anda perlu mengubah data, aplikasi pertama-tama membuat koreksi ke database (2), membuat objek baru dan kemudian mencoba memasukkannya ke dalam memcached (3). Artinya, objek lama harus diganti dengan yang baru. Bayangkan bahwa pada saat ini terjadi hal yang mengerikan - koneksi antara aplikasi dan memcached terputus, server memcached atau bahkan aplikasi itu sendiri crash. Jadi, aplikasi tidak dapat memperbarui data dalam memcached. Akibatnya, pengguna akan pergi ke halaman situs (misalnya, profilnya), melihat data lama dan tidak mengerti mengapa ini terjadi.
Bisakah bug ini terdeteksi selama pengujian fungsional atau pengujian kinerja? Saya pikir, kemungkinan besar, kita tidak akan menemukannya. Untuk mencari bug semacam itu ada jenis pengujian khusus - injeksi kesalahan.
Biasanya selama pengujian injeksi kesalahan ada bug yang populer disebut
mengambang . Mereka muncul di bawah beban, ketika lebih dari satu pengguna bekerja dalam sistem, ketika situasi abnormal terjadi - kerusakan peralatan, listrik terputus, kerusakan jaringan, dll.
Sistem TI Sberbank Baru
Beberapa tahun yang lalu, Sberbank mulai membangun sistem TI baru. Mengapa Berikut adalah statistik dari situs web Bank Sentral:
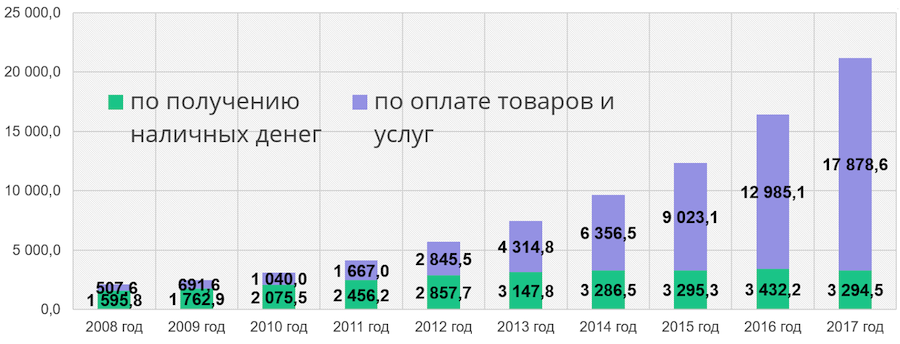
Bagian hijau dari kolom adalah jumlah penarikan tunai di ATM, bagian biru adalah jumlah operasi untuk membayar barang dan jasa. Kami melihat bahwa jumlah transaksi tanpa uang tunai meningkat dari tahun ke tahun. Dalam beberapa tahun, kita harus mampu menangani meningkatnya beban kerja dan terus menawarkan layanan baru kepada pelanggan kami. Ini adalah salah satu alasan untuk menciptakan sistem IT Sberbank baru. Selain itu, kami ingin mengurangi ketergantungan kami pada teknologi Barat dan mainframe yang mahal, yang harganya jutaan dolar, dan beralih ke teknologi open source dan server kelas bawah.
Awalnya, kami meletakkan dasar teknologi Apache Ignite di jantung arsitektur Sberbank baru. Lebih tepatnya, kami menggunakan plugin Gridgain berbayar. Teknologi ini memiliki fungsionalitas yang cukup kaya: menggabungkan sifat-sifat database relasional (ada dukungan untuk pertanyaan SQL), NoSQL, pemrosesan terdistribusi dan penyimpanan data dalam RAM. Apalagi saat Anda reboot, data yang ada di RAM tidak akan hilang di mana pun. Dimulai dengan versi 2.1, Apache Ignite telah mendistribusikan Apache Ignite Persistent Data Store dengan dukungan SQL.
Saya akan mencantumkan beberapa fitur dari teknologi ini:
- Penyimpanan dan pemrosesan data dalam RAM
- Penyimpanan disk
- Dukungan SQL
- Eksekusi tugas terdistribusi
- Penskalaan horisontal
Teknologi ini relatif baru, sehingga membutuhkan perhatian khusus.
Sistem TI baru Sberbank secara fisik terdiri dari banyak server yang relatif kecil yang dirakit dalam satu cloud cluster. Semua node identik dalam struktur, peer to peer, melakukan fungsi menyimpan dan memproses data.
Di dalam cluster dibagi menjadi sel-sel yang disebut. Satu sel adalah 8 node. Setiap pusat data memiliki 4 node.
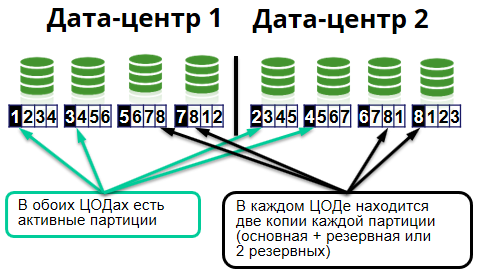
Karena kami menggunakan Apache Ignite, kotak data dalam memori, maka, karenanya, semua ini disimpan dalam cache yang didistribusikan server. Selain itu, cache, pada gilirannya, dibagi menjadi potongan - potongan yang identik. Di server, mereka direpresentasikan sebagai file. Partisi dari cache yang sama dapat disimpan di server yang berbeda. Untuk setiap partisi di cluster, ada node primer dan cadangan.
Node utama menyimpan partisi utama dan memproses permintaan mereka, mereplikasi data ke node cadangan (backup node), di mana partisi cadangan disimpan.
Ketika merancang arsitektur baru Sberbank, kami sampai pada kesimpulan bahwa komponen sistem dapat dan akan gagal. Katakanlah, jika Anda memiliki sekelompok 1000 server low-end besi, maka dari waktu ke waktu Anda akan mengalami kegagalan perangkat keras. Potongan RAM, kartu jaringan dan hard drive, dll. Akan gagal. Kami akan menganggap perilaku ini sebagai perilaku sistem yang sepenuhnya normal. Situasi seperti itu harus ditangani dengan benar dan pelanggan kita seharusnya tidak melihatnya.
Tapi itu tidak cukup untuk merancang ketahanan sistem terhadap kegagalan, penting untuk menguji sistem selama kegagalan ini. Seperti Caitie McCaffrey dari Microsoft Research, seorang peneliti sistem terdistribusi yang terkenal, mengatakan: "Anda tidak akan pernah tahu bagaimana sistem berperilaku selama kegagalan darurat sampai Anda mereproduksi kegagalan."
Pembaruan yang Hilang
Mari kita ambil contoh sederhana, aplikasi perbankan yang mensimulasikan transfer uang. Aplikasi akan terdiri dari dua bagian: Server Apache Ignite dan klien Apache Ignite. Sisi server adalah gudang data.
Aplikasi klien terhubung ke server Apache Ignite. Membuat cache di mana kuncinya adalah ID akun dan nilainya adalah objek akun. Secara total, sepuluh objek tersebut akan disimpan dalam cache. Dalam hal ini, awalnya kami akan memberikan $ 100 pada setiap akun (sehingga ada sesuatu untuk ditransfer). Dengan demikian, total saldo pada semua akun akan sama dengan $ 1.000.
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.ATOMIC); try (IgniteCache<Integer, Account> cache = ignite.getOrCreateCache(cfg)) { for (int i = 1; i <= ENTRIES_COUNT; i++) cache.put(i, new Account(i, 100)); System.out.println("Accounts before transfers"); printAccounts(cache); printTotalBalance(cache); for (int i = 1; i <= 100; i++) { int pairOfAccounts[] = getPairOfRandomAccounts(); transferMoney(cache, pairOfAccounts[0], pairOfAccounts[1]); } } ... private static void transferMoney(IgniteCache<Integer, Account> cache, int fromAccountId, int toAccountId) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); int amount = getRandomAmount(fromAccount.balance); if (amount < 1) { return; } fromAccount.withdraw(amount); toAccount.deposit(amount); cache.put(fromAccountId, fromAccount); cache.put(toAccountId, toAccount); }
Lalu kami melakukan 100 transfer uang acak antara 10 akun ini. Misalnya, $ 50 ditransfer dari akun A ke akun B. lainnya Secara skematis, proses ini dapat direpresentasikan sebagai berikut:

Sistem ditutup, transfer hanya dilakukan secara internal, mis. total saldo harus tetap sama dengan $ 1000.
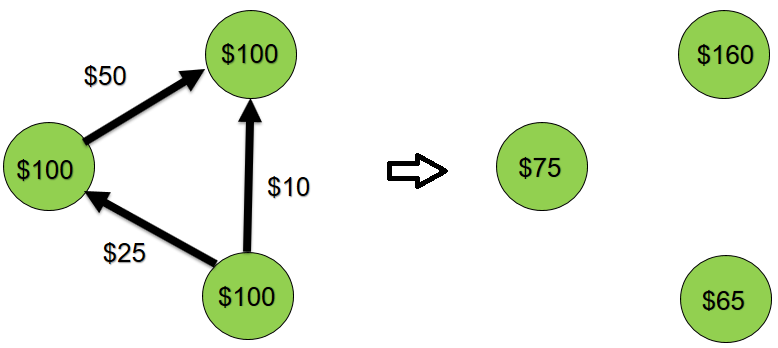
Luncurkan aplikasi.
Kami mendapat nilai yang diharapkan dari total saldo - $ 1000. Sekarang mari kita sedikit mempersulit aplikasi kita - mari kita buat multitask. Pada kenyataannya, beberapa aplikasi klien dapat bekerja secara bersamaan dengan akun yang sama. Jalankan dua tugas yang secara bersamaan akan melakukan transfer uang antara sepuluh akun.
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.ATOMIC); cfg.setCacheMode(CacheMode.PARTITIONED); cfg.setIndexedTypes(Integer.class, Account.class); try (IgniteCache<Integer, Account> cache = ignite.getOrCreateCache(cfg)) {
Total saldo adalah $ 1.296. Pelanggan bersukacita, bank menderita kerugian. Mengapa ini terjadi?

Di sini kita melihat bagaimana dua tugas secara bersamaan mengubah keadaan akun A. Namun tugas kedua berhasil mencatat perubahannya lebih awal daripada yang pertama. Kemudian tugas pertama mencatat perubahannya, dan semua perubahan yang dilakukan oleh tugas kedua segera menghilang. Anomali ini disebut masalah pembaruan yang hilang.
Agar aplikasi berfungsi sebagaimana mestinya, basis data kami harus mendukung transaksi ACID dan kode kami harus mempertimbangkan ini.
Mari kita lihat properti ACID untuk aplikasi kita untuk memahami mengapa ini sangat penting.

- A - Atomicity, atomicity. Entah semua perubahan yang diajukan akan dilakukan ke database, atau tidak ada yang dibuat. Artinya, jika kami mengalami kegagalan antara langkah 3 dan 6, perubahan tidak boleh ada di database
- C - Konsistensi, Integritas. Setelah transaksi selesai, basis data harus tetap dalam kondisi yang konsisten. Dalam contoh kami, ini berarti bahwa jumlah A dan B harus selalu sama, total saldo adalah $ 1000.
- I - Isolasi, isolasi. Transaksi tidak boleh saling mempengaruhi. Jika satu transaksi melakukan transfer, dan yang lainnya menerima nilai akun A dan B setelah langkah 3 dan hingga langkah 6, ia berpikir bahwa sistem memiliki lebih sedikit uang daripada yang diperlukan. Ada nuansa di sini yang akan saya fokuskan nanti.
- D - Daya Tahan Setelah transaksi melakukan perubahan pada basis data, perubahan ini tidak boleh hilang sebagai akibat dari kegagalan.
Jadi, dalam metode transferMoney, kami akan melakukan transfer uang dalam transaksi.
private void transferMoney(int fromAccountId, int toAccountId) { try (Transaction tx = ignite.transactions().txStart()) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); int amount = getRandomAmount(fromAccount.balance); if (amount < 1) { return; } int fromAccountBalanceBeforeTransfer = fromAccount.balance; int toAccountBalanceBeforeTransfer = toAccount.balance; fromAccount.withdraw(amount); toAccount.deposit(amount); cache.put(fromAccountId, fromAccount); cache.put(toAccountId, toAccount); tx.commit(); } catch (Exception e){ e.printStackTrace(); } }
Luncurkan aplikasi.
Hm Transaksi tidak membantu. Total saldo adalah $ 6951! Apa masalah dengan perilaku aplikasi ini?
Pertama, mereka memilih jenis cache ATOMIC, mis. tanpa dukungan transaksi ACID:
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.TOMIC);
Kedua, metode txStart memiliki dua parameter penting dari tipe enum yang akan lebih baik untuk ditentukan: metode kunci (mode concurrency di Apache Ignite) dan tingkat isolasi. Bergantung pada nilai parameter ini, transaksi dapat membaca dan menulis data dengan berbagai cara. Di Apache Ignite, parameter ini ditetapkan sebagai berikut:
try (Transaction tx = ignite.transactions().txStart( , )) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); ... tx.commit(); }
Anda dapat menggunakan PESSIMISTIC (kunci pesimis) atau OPTIMISTIK (kunci optimis) sebagai nilai parameter METODE LOCK. Mereka berbeda dalam instan pemblokiran. Saat menggunakan PESSIMISTIC, kunci dikenai pada baca / tulis pertama dan ditahan hingga transaksi dilakukan. Misalnya, ketika transaksi dengan kunci pesimistis melakukan transfer dari akun A ke akun B, transaksi lain tidak akan dapat membaca atau menulis nilai-nilai akun ini hingga transaksi yang membuat transfer dilakukan. Jelas bahwa jika transaksi lain ingin mengakses akun A dan B, mereka dipaksa untuk menunggu transaksi selesai, yang memiliki dampak negatif pada keseluruhan kinerja aplikasi. Penguncian optimis tidak membatasi akses ke data untuk transaksi lain, namun, selama fase persiapan transaksi untuk komit (tahap persiapan, Apache Ignite menggunakan protokol 2PC), akan dilakukan pemeriksaan - apakah data berubah dengan transaksi lain? Dan jika terjadi perubahan, maka transaksi akan dibatalkan. Dalam hal kinerja, OPTIMISTIK akan berjalan lebih cepat, tetapi lebih cocok untuk aplikasi di mana tidak ada persaingan dengan data.
Parameter INSULATION LEVEL menentukan tingkat isolasi transaksi dari satu sama lain. Standar SQL ANSI / ISO mendefinisikan 4 jenis isolasi, dan untuk setiap tingkat isolasi, skenario transaksi yang sama dapat menghasilkan hasil yang berbeda.
- READ_UNCOMMITED adalah tingkat isolasi terendah. Transaksi dapat melihat data yang "tidak dikomit" kotor.
- READ_COMMITTED - ketika transaksi melihat di dalam dirinya sendiri hanya data sensitif
- REPEATABLE_READ - artinya jika pembacaan dilakukan di dalam transaksi, maka pembacaan ini harus diulang.
- SERIALIZABLE - level ini mengasumsikan tingkat isolasi transaksi maksimum - seolah-olah tidak ada pengguna lain dalam sistem. Hasil transaksi paralel akan seolah-olah dieksekusi secara berurutan. Tetapi bersama dengan tingkat isolasi yang tinggi, kami mendapatkan pengurangan kinerja. Karena itu, Anda harus hati-hati mendekati pilihan tingkat isolasi ini.
Untuk banyak DBMS modern (Microsoft SQL Server, PostgreSQL dan Oracle), level isolasi default adalah READ_COMMITTED. Misalnya, ini akan berakibat fatal, karena tidak akan melindungi kami dari pembaruan yang hilang. Hasilnya akan sama seperti jika kita belum pernah menggunakan transaksi sama sekali.

Dari
dokumentasi transaksi Apache Ignite , cocok bagi kami untuk menggunakan kombinasi metode kunci dan tingkat isolasi:
- PESSIMISTIC REPEATABLE_READ - kunci dikenakan pada pembacaan pertama atau penulisan data dan ditahan sampai selesai.
- PESSIMISTIC SERIALIZABLE - berfungsi serupa dengan PESSIMISTIC REPEATABLE_READ
- SERIALISASI YANG OPTIMIS - versi data yang diperoleh setelah pembacaan pertama diingat, dan jika versi ini berbeda selama tahap persiapan untuk komit (data diubah oleh transaksi lain), transaksi akan dibatalkan. Mari kita coba opsi ini.
private void transferMoney(int fromAccountId, int toAccountId) { try (Transaction tx = ignite.transactions().txStart(OPTIMISTIC, SERIALIZABLE)) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); int amount = getRandomAmount(fromAccount.balance); if (amount < 1) { return; } int fromAccountBalanceBeforeTransfer = fromAccount.balance; int toAccountBalanceBeforeTransfer = toAccount.balance; fromAccount.withdraw(amount); toAccount.deposit(amount); cache.put(fromAccountId, fromAccount); cache.put(toAccountId, toAccount); tx.commit(); } catch (Exception e){ e.printStackTrace(); } }
Hore, dapatkan $ 1.000, seperti yang diharapkan. Pada upaya ketiga.
Menguji di bawah beban
Sekarang kami akan membuat pengujian kami lebih realistis - kami akan menguji di bawah beban. Dan tambahkan node server tambahan. Ada banyak alat untuk melakukan stress testing, di Sberbank kami menggunakan HP Performance Center. Ini adalah alat yang cukup kuat, mendukung lebih dari 50 protokol, dirancang untuk tim besar dan menghabiskan banyak uang. Saya menulis contoh saya di JMeter - ini gratis dan menyelesaikan masalah kami 100%. Saya tidak ingin menulis ulang kode di Jawa, jadi saya akan menggunakan sampler JSR223.
Kami akan membuat arsip JAR dari kelas aplikasi kami dan memuatnya ke dalam rencana pengujian. Untuk membuat dan mengisi cache, jalankan kelas CreateCache. Setelah menginisialisasi cache, Anda dapat menjalankan skrip JMeter.
Semuanya keren, dapatkan $ 1.000.
Shutdown darurat cluster cluster
Sekarang kita akan lebih destruktif: selama operasi cluster, kita akan crash salah satu dari dua node server. Melalui utilitas Visor, yang termasuk dalam paket Gridgain, kita dapat memonitor cluster Apache Ignite dan membuat sampel data yang berbeda. Di tab Penampil SQL, jalankan kueri SQL untuk mendapatkan saldo keseluruhan untuk semua akun.
Apa itu 553 dolar. Pelanggan takut, bank menderita kerugian reputasi. Apa yang kita lakukan salah kali ini?
Ternyata ada jenis cache di Apache Ignite:
- dipartisi - satu atau beberapa salinan cadangan disimpan di dalam cluster
- cache yang direplikasi - semua partisi (semua bagian dari cache) disimpan dalam satu server. Tembolok seperti itu cocok terutama untuk buku referensi - sesuatu yang jarang berubah dan sering dibaca.
- lokal - semua dalam satu simpul

Kami akan sering mengubah data kami, jadi kami akan memilih cache yang dipartisi dan menambahkan cadangan tambahan untuk itu. Artinya, kita akan memiliki dua salinan data - primer dan cadangan.
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.TRANSACTIONAL); cfg.setCacheMode(CacheMode.PARTITIONED); cfg.setBackups(1);
Kami meluncurkan aplikasi. Saya mengingatkan Anda bahwa sebelum transfer kami memiliki $ 1000. Kami memulai dan selama operasi kami "memadamkan" salah satu node
Dalam utilitas Visor, kami membuat kueri SQL untuk mendapatkan saldo total $ 1000. Semuanya berjalan dengan baik!
Kasus keandalan
Dua tahun lalu, kami baru mulai menguji sistem TI Sberbank yang baru. Entah bagaimana, kami pergi ke insinyur pengawal kami dan bertanya: apa yang bisa menghancurkan sama sekali? Mereka menjawab kami: semuanya bisa pecah, uji semuanya! Tentu saja, jawaban ini tidak cocok untuk kita. Kami duduk bersama, menganalisis statistik kegagalan dan menyadari bahwa kasus yang paling mungkin kami temui adalah kegagalan simpul.
Selain itu, ini dapat terjadi karena alasan yang sangat berbeda. Misalnya, aplikasi mungkin macet, crash JVM, crash OS, atau kegagalan perangkat keras.
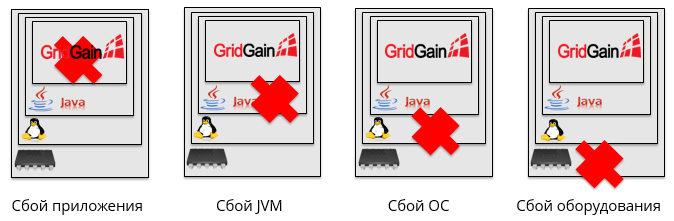
Kami membagi semua kemungkinan kegagalan menjadi 4 kelompok:
- Peralatan
- Jaringan
- Perangkat lunak
- Lainnya
Mereka datang dengan tes untuk mereka dan menyebut mereka kasus keandalan. Kasus keandalan tipikal terdiri dari deskripsi kondisi sistem sebelum pengujian, langkah-langkah untuk mereproduksi kegagalan, dan deskripsi perilaku yang diharapkan selama kegagalan.
Kasus keandalan: peralatan
Grup ini mencakup beberapa kasus seperti:
- Kegagalan daya
- Kehilangan akses total ke hard drive
- Kegagalan satu jalur akses hard drive
- CPU, RAM, disk, beban jaringan
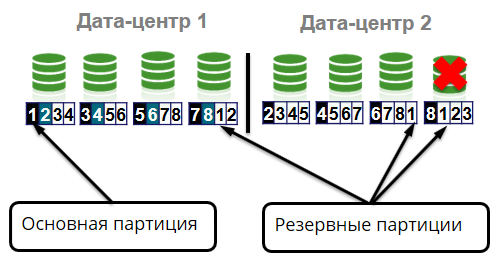
Cluster menyimpan 4 salinan identik dari setiap partisi: satu partisi primer dan tiga partisi cadangan. Misalkan sebuah simpul meninggalkan sebuah cluster karena kegagalan peralatan. Dalam hal ini, partisi utama harus pindah ke node yang masih hidup lainnya.
Apa lagi yang bisa terjadi? Hilangnya rak di dalam sel.
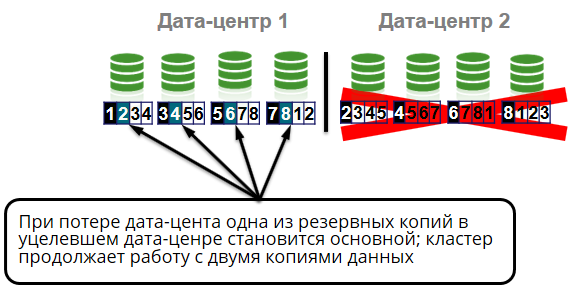
Semua node sel berada di rak yang berbeda. Yaitu output rak tidak akan menyebabkan kegagalan cluster atau kehilangan data. Kami akan memiliki tiga salinan empat. Tetapi bahkan jika kita kehilangan seluruh pusat data, itu juga tidak akan menjadi masalah besar bagi kita, karena kami masih memiliki dua salinan data lagi dari empat.
Beberapa kasus dilakukan langsung di pusat data dengan bantuan insinyur pendukung. Misalnya, mematikan hard drive, mematikan daya ke server atau rak.
Kasus keandalan: jaringan
Untuk menguji kasus yang terkait dengan fragmentasi jaringan, kami menggunakan iptables. Dan menggunakan utilitas NetEm kami meniru:
- keterlambatan jaringan dengan fungsi distribusi yang berbeda
- paket hilang
- coba lagi paket
- paket pemesanan ulang
- distorsi paket
Kasus jaringan lain yang menarik yang kami uji adalah split-brain. Ini adalah ketika semua node cluster hidup, tetapi karena segmentasi jaringan mereka tidak dapat berkomunikasi satu sama lain. Istilah ini berasal dari kedokteran dan berarti bahwa otak dibagi menjadi dua belahan, yang masing-masing menganggap dirinya unik. Hal yang sama dapat terjadi pada sebuah cluster.
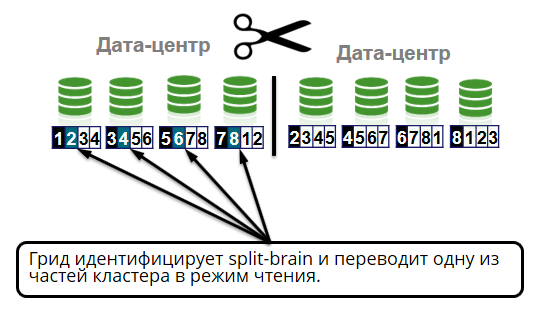
Terjadi bahwa antara pusat data koneksi hilang. Misalnya, tahun lalu, karena kerusakan pada kabel serat optik oleh excavator, klien bank Tochka, Otkrytie, dan bank Rocketbank tidak melakukan transaksi melalui Internet selama beberapa jam, terminal tidak menerima kartu dan ATM tidak berfungsi. Banyak yang telah ditulis tentang kecelakaan ini di Twitter.
Dalam kasus kami, situasi otak terpecah harus ditangani dengan benar. Sebuah grid mengidentifikasi otak-terpisah - membagi sebuah cluster menjadi dua bagian. Setengah masuk ke mode baca. Ini adalah setengah di mana ada lebih banyak node yang hidup atau koordinator berada (node tertua di cluster).
Kasus keandalan: perangkat lunak
Ini adalah kasus yang berkaitan dengan kegagalan berbagai subsistem:
- DPL ORM - modul akses data, seperti Hibernate ORM
- Transportasi antar moda - pengiriman pesan antar modul (layanan microser)
- Sistem pembalakan
- Sistem akses
- Apache Ignite Cluster
- ...
Karena sebagian besar perangkat lunak ditulis dalam Java, kami rentan terhadap semua masalah yang melekat pada aplikasi Java. Menguji berbagai pengaturan pengumpul sampah. Menjalankan tes dengan crash mesin virtual java.
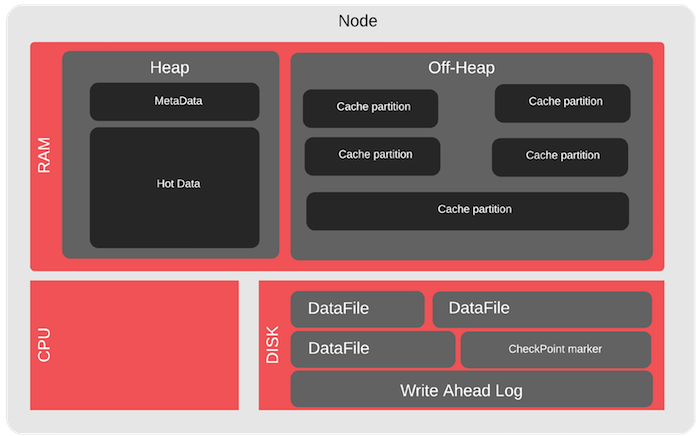
Untuk kluster Apache Ignite, ada case khusus untuk off-heap - ini adalah area memori yang dikendalikan oleh Apache Ignite. Ini jauh lebih besar dari heap java dan dirancang untuk menyimpan data dan indeks. Di sini Anda dapat, misalnya, menguji overflow. Kami meluap-luap dan melihat bagaimana cluster bekerja ketika beberapa data tidak masuk ke dalam RAM, mis. baca dari disk.
Kasus lainnya
Ini adalah kasus-kasus yang tidak termasuk dalam tiga kelompok pertama. Ini termasuk utilitas yang memungkinkan pemulihan data jika terjadi kecelakaan besar atau ketika data dimigrasikan ke cluster lain.
- Utilitas untuk membuat snapshot (cadangan) data - pengujian snapshot penuh dan tambahan.
- Pemulihan ke titik waktu tertentu - Mekanisme PITR (Pemulihan dalam waktu).
Utilitas untuk injeksi kesalahan
Saya ingat
tautan ke contoh dari laporan saya. Anda dapat mengunduh distribusi Apache Ignite dari situs resmi -
Unduh Apache Ignite . Dan sekarang saya akan membagikan utilitas yang kami gunakan di Sberbank, jika Anda tiba-tiba tertarik pada topik tersebut.
Kerangka kerja
Manajemen Konfigurasi:
Utilitas Linux:
Alat Uji Beban:
Baik di dunia modern maupun di Sberbank, semua perubahan bersifat dinamis dan sulit untuk memprediksi teknologi mana yang akan digunakan dalam beberapa tahun mendatang. Tapi saya tahu pasti bahwa kita akan menggunakan metode Fault Injection. Metode ini bersifat universal - sangat cocok untuk menguji teknologi apa pun, benar-benar berfungsi, membantu menangkap banyak bug dan membuat produk yang kami kembangkan menjadi lebih baik.