Selamat malam
Dari kursus kami
"Pengembang C ++" kami menawarkan kepada Anda sebuah studi kecil dan menarik tentang algoritma paralel.
Ayo pergi.
Dengan munculnya algoritma paralel di C ++ 17, Anda dapat dengan mudah memperbarui kode "komputasi" dan mendapatkan manfaat dari eksekusi paralel. Pada artikel ini, saya ingin mempertimbangkan algoritma STL, yang secara alami mengungkapkan ide komputasi independen. Bisakah kita mengharapkan akselerasi 10x dengan prosesor 10-inti? Atau mungkin lebih? Atau kurang? Mari kita bicarakan.
Pengantar Algoritma Paralel
C ++ 17 menawarkan pengaturan kebijakan eksekusi untuk sebagian besar algoritma:
- sequenced_policy - jenis kebijakan eksekusi, digunakan sebagai tipe unik untuk menghilangkan kelebihan algoritma paralel dan persyaratan bahwa paralelisasi eksekusi algoritma paralel tidak mungkin: objek global terkait adalah
std::execution::seq ; - parallel_policy - jenis kebijakan eksekusi yang digunakan sebagai tipe unik untuk menghilangkan kelebihan algoritma paralel dan menunjukkan bahwa paralelisasi eksekusi algoritma paralel dimungkinkan: objek global yang sesuai adalah
std::execution::par ; - parallel_un berikutnyaenced_policy - jenis kebijakan eksekusi yang digunakan sebagai tipe unik untuk menghilangkan kelebihan algoritma paralel dan untuk mengindikasikan bahwa paralelisasi dan vektorisasi eksekusi algoritma paralel dimungkinkan: objek global yang sesuai adalah
std::execution::par_unseq ;
Secara singkat:
- gunakan
std::execution::seq untuk eksekusi berurutan dari algoritma; - gunakan
std::execution::par untuk mengeksekusi algoritma secara paralel (biasanya menggunakan beberapa implementasi Thread Pool (thread pool)); - gunakan
std::execution::par_unseq untuk eksekusi paralel dari algoritma dengan kemampuan untuk menggunakan perintah vektor (misalnya, SSE, AVX).
Sebagai contoh cepat, panggil
std::sort paralel:
std::sort(std::execution::par, myVec.begin(), myVec.end());
Perhatikan betapa mudahnya menambahkan parameter eksekusi paralel ke algoritme! Tetapi apakah peningkatan kinerja yang signifikan akan tercapai? Apakah ini akan meningkatkan kecepatan? Atau adakah perlambatan?
std::transform paralel std::transformPada artikel ini, saya ingin memperhatikan algoritma
std::transform , yang berpotensi menjadi dasar untuk metode paralel lainnya (bersama dengan
std::transform_reduce ,
for_each ,
scan ,
sort ...).
Kode pengujian kami akan dibuat sesuai dengan templat berikut:
std::transform(execution_policy,
Misalkan fungsi
ElementOperation tidak memiliki metode sinkronisasi, dalam hal ini kode memiliki potensi eksekusi paralel atau bahkan vektorisasi. Setiap perhitungan elemen independen, urutannya tidak penting, sehingga implementasi dapat menghasilkan beberapa utas (mungkin dalam kumpulan utas) untuk pemrosesan elemen independen.
Saya ingin bereksperimen dengan hal-hal berikut:
- ukuran bidang vektor besar atau kecil;
- konversi sederhana yang menghabiskan sebagian besar waktu mengakses memori;
- lebih banyak operasi aritmatika (ALU);
- ALU dalam skenario yang lebih realistis.
Seperti yang Anda lihat, saya ingin tidak hanya menguji jumlah elemen yang "baik" untuk menggunakan algoritma paralel, tetapi juga operasi ALU yang menggunakan prosesor.
Algoritma lain, seperti pengurutan, akumulasi (dalam bentuk std :: mengurangi) juga menawarkan eksekusi paralel, tetapi juga membutuhkan lebih banyak pekerjaan untuk menghitung hasilnya. Karena itu, kami akan mempertimbangkan mereka sebagai kandidat untuk artikel lain.
Catatan Benchmark
Untuk pengujian saya, saya menggunakan Visual Studio 2017, 15,8 - karena ini adalah satu-satunya implementasi dalam implementasi kompiler populer / STL saat ini (November, 2018) (GCC di jalan!). Selain itu, saya hanya fokus pada
execution::par , karena
execution::par_unseq tidak tersedia di MSVC (kerjanya mirip dengan
execution::par ).
Ada dua komputer:
- i7 8700 - PC, Windows 10, i7 8700 - 3,2 GHz, 6 core / 12 utas (Hyperthreading);
- i7 4720 - Laptop, Windows 10, i7 4720, 2.6 GHz, 4 core / 8 utas (Hyperthreading).
Kode dikompilasi dalam x64, Rilis lebih lanjut, auto-vektorisasi diaktifkan secara default, saya juga menyertakan serangkaian perintah yang diperluas (SSE2) dan OpenMP (2.0).
Kode ini ada di github saya:
github / fenbf / ParSTLTests / TransformTests / TransformTests.cppUntuk OpenMP (2.0), saya menggunakan paralelisme hanya untuk loop:
#pragma omp parallel for for (int i = 0; ...)
Saya menjalankan kode 5 kali dan melihat hasil minimum.
Peringatan : Hasil hanya mencerminkan pengamatan kasar, periksa sistem / konfigurasi Anda sebelum digunakan dalam produksi. Persyaratan dan lingkungan Anda mungkin berbeda dari saya.Anda dapat membaca lebih lanjut tentang implementasi MSVC di
pos ini . Dan
inilah laporan terbaru Bill O'Neill dengan CppCon 2018 (Bill menerapkan Parallel STL di MSVC).
Baiklah, mari kita mulai dengan contoh-contoh sederhana!
Konversi sederhanaPertimbangkan kasus ketika Anda menerapkan operasi yang sangat sederhana ke vektor input. Ini bisa berupa penyalinan atau penggandaan elemen.
Sebagai contoh:
std::transform(std::execution::par, vec.begin(), vec.end(), out.begin(), [](double v) { return v * 2.0; } );
Komputer saya memiliki 6 atau 4 core ... dapatkah saya mengharapkan eksekusi berurutan lebih cepat 4,6x? Inilah hasil saya (waktu dalam milidetik):
| Operasi | Ukuran vektor | i7 4720 (4 core) | i7 8700 (6 core) |
|---|
| eksekusi :: seq | 10rb | 0,002763 | 0,001924 |
| eksekusi :: par | 10rb | 0,009869 | 0,008983 |
| paralel openmp untuk | 10rb | 0,003158 | 0,002246 |
| eksekusi :: seq | 100rb | 0,051318 | 0,028872 |
| eksekusi :: par | 100rb | 0,043028 | 0,025664 |
| paralel openmp untuk | 100rb | 0,022501 | 0,009624 |
| eksekusi :: seq | 1000rb | 1.69508 | 0,52419 |
| eksekusi :: par | 1000rb | 1.65561 | 0,359619 |
| paralel openmp untuk | 1000rb | 1.50678 | 0,344863 |
Pada mesin yang lebih cepat, kita dapat melihat bahwa dibutuhkan sekitar 1 juta elemen untuk melihat peningkatan kinerja. Di sisi lain, di laptop saya semua implementasi paralel lebih lambat.
Dengan demikian, sulit untuk melihat peningkatan kinerja yang signifikan menggunakan transformasi tersebut, bahkan dengan peningkatan jumlah elemen.
Kenapa begitu?
Karena operasinya elementer, inti prosesor dapat memanggilnya hampir secara instan, hanya menggunakan beberapa siklus. Namun, core prosesor menghabiskan lebih banyak waktu menunggu memori utama. Jadi, dalam hal ini, sebagian besar mereka akan menunggu, bukan membuat perhitungan.
Membaca dan menulis variabel dalam memori membutuhkan sekitar 2-3 siklus jika di-cache, dan beberapa ratus siklus jika tidak di-cache.https://www.agner.org/optimize/optimizing_cpp.pdfSecara kasar Anda dapat mencatat bahwa jika algoritme Anda bergantung pada memori, maka Anda seharusnya tidak mengharapkan peningkatan kinerja dengan komputasi paralel.
Lebih banyak perhitunganKarena bandwidth memori sangat penting dan dapat memengaruhi kecepatan hal-hal ... mari kita tingkatkan jumlah komputasi yang memengaruhi setiap elemen.
Idenya adalah bahwa lebih baik menggunakan siklus prosesor daripada membuang-buang waktu menunggu memori.
Untuk mulai dengan, saya menggunakan fungsi trigonometri, misalnya,
sqrt(sin*cos) (ini adalah perhitungan bersyarat dalam bentuk yang tidak optimal, hanya untuk menempati prosesor).
Kami menggunakan
sqrt ,
sin dan
cos , yang dapat mengambil ~ 20 per
sqrt dan ~ 100 per fungsi trigonometri. Jumlah perhitungan ini dapat mencakup penundaan akses memori.
Untuk informasi lebih lanjut tentang keterlambatan tim, lihat
Panduan Perf sangat baik
oleh Agner Fogh .
Berikut ini adalah kode benchmark:
std::transform(std::execution::par, vec.begin(), vec.end(), out.begin(), [](double v) { return std::sqrt(std::sin(v)*std::cos(v)); } );
Dan sekarang apa? Bisakah kita mengandalkan peningkatan kinerja dari upaya sebelumnya?
Berikut ini beberapa hasil (waktu dalam milidetik):
| Operasi | Ukuran vektor | i7 4720 (4 core) | i7 8700 (6 core) |
|---|
| eksekusi :: seq | 10rb | 0,105005 | 0,070577 |
| eksekusi :: par | 10rb | 0,055661 | 0,03176 |
| paralel openmp untuk | 10rb | 0,096321 | 0,024702 |
| eksekusi :: seq | 100rb | 1.08755 | 0,707048 |
| eksekusi :: par | 100rb | 0,259354 | 0,17195 |
| paralel openmp untuk | 100rb | 0,898465 | 0,189915 |
| eksekusi :: seq | 1000rb | 10.5159 | 7.16254 |
| eksekusi :: par | 1000rb | 2.44472 | 1.10099 |
| paralel openmp untuk | 1000rb | 4.78681 | 1.89017 |
Akhirnya, kami melihat angka yang bagus :)
Untuk 1000 elemen (tidak ditampilkan di sini), waktu perhitungan paralel dan berurutan serupa, oleh karena itu untuk lebih dari 1000 elemen kita melihat peningkatan dalam versi paralel.
Untuk 100 ribu elemen, hasil pada komputer yang lebih cepat hampir 9 kali lebih baik daripada versi serial (sama untuk versi OpenMP).
Dalam versi terbesar sejuta elemen, hasilnya 5 atau 8 kali lebih cepat.
Untuk perhitungan seperti itu, saya mencapai akselerasi "linear", tergantung pada jumlah core prosesor. Yang diharapkan.
Fresnel dan vektor tiga dimensiPada bagian di atas, saya menggunakan perhitungan "diciptakan", tetapi bagaimana dengan kode asli?
Mari kita pecahkan persamaan Fresnel yang menggambarkan pantulan dan kelengkungan cahaya dari permukaan yang halus dan rata. Ini adalah metode populer untuk menghasilkan pencahayaan realistis dalam game 3D.
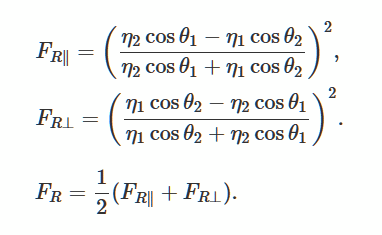
 Foto dari Wikimedia
Foto dari WikimediaSebagai contoh yang baik, saya menemukan
deskripsi dan implementasi ini .
Tentang menggunakan perpustakaan GLMAlih-alih membuat implementasi saya sendiri, saya menggunakan
perpustakaan glm . Saya sering menggunakannya di proyek OpenGl saya.
Perpustakaan mudah diakses melalui
Conan Package Manager , jadi saya akan menggunakannya juga.
Tautan ke paket.
File Conan:
[requires] glm/0.9.9.1@g-truc/stable [generators] visual_studio
dan baris perintah untuk menginstal perpustakaan (ini menghasilkan file alat peraga yang dapat saya gunakan dalam proyek Visual Studio):
conan install . -s build_type=Release -if build_release_x64 -s arch=x86_64
Pustaka terdiri dari tajuk, jadi Anda bisa mengunduhnya secara manual jika mau.
Kode aktual dan tolok ukurSaya mengadaptasi kode untuk
glm dari
scratchapixel.com :
Kode menggunakan beberapa instruksi matematis, produk skalar, perkalian, pembagian, sehingga prosesor memiliki sesuatu untuk dilakukan. Alih-alih vektor ganda, kami menggunakan vektor 4 elemen untuk meningkatkan jumlah memori yang digunakan.
Benchmark:
std::transform(std::execution::par, vec.begin(), vec.end(), vecNormals.begin(),
Dan inilah hasilnya (waktu dalam milidetik):
| Operasi | Ukuran vektor | i7 4720 (4 core) | i7 8700 (6 core) |
|---|
| eksekusi :: seq | 1rb | 0,032764 | 0,016361 |
| eksekusi :: par | 1rb | 0,031186 | 0,028551 |
| paralel openmp untuk | 1rb | 0,005526 | 0,007699 |
| eksekusi :: seq | 10rb | 0,246722 | 0,169383 |
| eksekusi :: par | 10rb | 0,090794 | 0,067048 |
| paralel openmp untuk | 10rb | 0,049739 | 0,029835 |
| eksekusi :: seq | 100rb | 2.49722 | 1.69768 |
| eksekusi :: par | 100rb | 0,530157 | 0,283268 |
| paralel openmp untuk | 100rb | 0,495024 | 0,291609 |
| eksekusi :: seq | 1000rb | 25/08/28 | 16.9457 |
| eksekusi :: par | 1000rb | 5.15235 | 2.33768 |
| paralel openmp untuk | 1000rb | 5.11801 | 2.95908 |
Dengan komputasi "nyata", kami melihat bahwa algoritma paralel memberikan kinerja yang baik. Untuk operasi seperti itu pada dua mesin Windows saya, saya mencapai akselerasi dengan ketergantungan hampir linier pada jumlah core.
Untuk semua tes, saya juga menunjukkan hasil dari OpenMP dan dua implementasi: MSVC dan OpenMP bekerja dengan cara yang sama.
KesimpulanPada artikel ini, saya melihat tiga kasus menggunakan komputasi paralel dan algoritma paralel. Mengganti algoritma standar dengan std :: eksekusi :: versi par mungkin tampak sangat menggoda, tetapi ini tidak selalu layak dilakukan! Setiap operasi yang Anda gunakan di dalam algoritma dapat bekerja secara berbeda dan lebih tergantung pada prosesor atau memori. Karena itu, pertimbangkan setiap perubahan secara terpisah.
Hal yang perlu diingat:
- eksekusi paralel, biasanya, melakukan lebih dari sekuensial, karena perpustakaan harus mempersiapkan eksekusi paralel;
- tidak hanya jumlah elemen yang penting, tetapi juga jumlah instruksi yang digunakan prosesor;
- lebih baik mengambil tugas yang independen satu sama lain dan sumber daya bersama lainnya;
- algoritma paralel menawarkan cara mudah untuk membagi pekerjaan menjadi utas yang terpisah;
- jika operasi Anda bergantung pada memori, Anda seharusnya tidak mengharapkan peningkatan kinerja, dan dalam beberapa kasus, algoritme mungkin lebih lambat;
- untuk mendapatkan peningkatan kinerja yang layak, selalu mengukur timing dari setiap masalah, dalam beberapa kasus hasilnya mungkin sangat berbeda.
Terima kasih khusus kepada JFT untuk membantu artikel ini!
Perhatikan juga sumber saya yang lain tentang algoritma paralel:
Lihatlah artikel lain yang terkait dengan Algoritma Paralel:
Cara Meningkatkan Kinerja dengan Intel Parallel STL dan C ++ 17 Algoritma ParalelAKHIR
Kami menunggu komentar dan pertanyaan yang dapat Anda tinggalkan di sini atau di
guru kami di
pintu terbuka .