Kompilator AOT yang mengoptimalkan biasanya disusun seperti ini:
- frontend mengubah kode sumber ke representasi perantara
- pipeline machine-independent optimization (IR): urutan lintasan yang menulis ulang IR untuk menghilangkan bagian dan struktur yang tidak efisien yang tidak dapat langsung dikonversi ke kode mesin. Terkadang bagian ini disebut ujung-tengah.
- Backend yang bergantung pada mesin untuk menghasilkan kode perakitan atau kode mesin.

Dalam beberapa kompiler, format IR tetap tidak berubah selama proses pengoptimalan, pada yang lain format atau semantiknya berubah. Dalam LLVM, format dan semantiknya diperbaiki, dan oleh karena itu dimungkinkan untuk menjalankan lintasan dengan urutan apa pun tanpa risiko kompilasi yang salah atau crash kompilator.
Urutan melewati optimisasi dikembangkan oleh pengembang kompiler, tujuannya adalah untuk menyelesaikan pekerjaan dalam waktu yang dapat diterima. Ini berubah dari waktu ke waktu, dan, tentu saja, ada serangkaian operan yang berbeda untuk dijalankan pada level optimisasi yang berbeda. Salah satu topik jangka panjang dalam penelitian komputer adalah penggunaan pembelajaran mesin atau metode lain untuk menemukan jalur optimalisasi pipa terbaik untuk penggunaan umum dan untuk aplikasi spesifik yang jalur pipa standarnya tidak terlalu cocok.
Prinsip-prinsip mendesain bagian-bagiannya adalah minimalisme dan ortogonalitas: setiap pass harus melakukan satu hal dengan baik, dan fungsinya tidak boleh tumpang tindih. Dalam praktiknya, kompromi terkadang dimungkinkan. Dalam praktiknya, ketika dua lintasan menghasilkan pekerjaan untuk satu sama lain, mereka dapat digabungkan menjadi satu lintasan yang lebih besar. Juga, beberapa fungsionalitas tingkat IR, seperti melipat operator konstan, sangat berguna sehingga tidak masuk akal untuk meletakkannya dalam lintasan terpisah, LLVM secara default meminimalkan operasi konstan ketika instruksi dibuat.
Dalam posting ini kita akan melihat bagaimana beberapa optimasi LLVM melewati bekerja. Maksud saya, Anda membaca
bagian ini tentang bagaimana Clang mengkompilasi fungsi atau bahwa Anda kurang lebih memahami cara kerja LLVM IR. Memahami formulir SSA (static single assignment) sangat membantu:
Wikipedia akan memberi Anda pengantar, dan
buku ini akan memberi Anda lebih banyak informasi daripada yang ingin Anda ketahui. Baca juga
Referensi Bahasa LLVM dan
daftar lintasan optimisasi .
Mari kita lihat bagaimana Dentang / LLVM 6.0.1 mengoptimalkan kode C ++ ini:
bool is_sorted(int *a, int n) { for (int i = 0; i < n - 1; i++) if (a[i] > a[i + 1]) return false; return true; }
Pada saat yang sama, kami ingat bahwa jalur optimasi adalah tempat yang sangat sibuk, dan kami akan kehilangan banyak momen menyenangkan, seperti:
Inlining adalah pengoptimalan sederhana namun sangat penting yang tidak terjadi dalam contoh ini, karena kami menganggap hanya satu fungsi. Hampir semua optimasi khusus untuk C ++, tetapi tidak untuk C. Auto-vektorisasi, yang mencegah keluar awal dari loop
Dalam teks di bawah ini, saya akan melewati semua lintasan yang tidak membuat perubahan pada kode. Juga, kita tidak akan melihat ke dalam backend, yang juga melakukan banyak pekerjaan. Tetapi bahkan bagian yang tersisa pun banyak! (Maaf untuk gambarnya, tetapi ini tampaknya menjadi cara terbaik untuk menghindari kesulitan pemformatan).
Berikut adalah file IR yang dibuat oleh Dentang (saya secara manual menghapus atribut "optnone" yang dimasukkan Dentang) dan baris perintah yang digunakan untuk melihat efek dari setiap pass optimasi:
opt -O2 -print-before-all -print-after-all is_sorted2.ll
Lulus pertama adalah
penyederhanaan CFG (grafik aliran kendali). Karena Dentang tidak melakukan pengoptimalan, IR yang dihasilkannya berisi opsi pengoptimalan sederhana:

Di sini, unit dasar 26 hanya bergerak ke blok 27. Blok tersebut dapat dihapus dengan mengarahkan referensi ke mereka oleh blok tujuan. LLVM akan secara otomatis memberi nomor baru pada blok. Daftar lengkap konversi yang dihasilkan oleh SimplifyCFG terdaftar di bagian atas lorong.
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
Sebagian besar peluang untuk pengoptimalan CFG muncul sebagai hasil dari pekerjaan pass LLVM lainnya. Misalnya, menghapus kode mati eliminasi dan memindahkan invarian lingkaran dapat dengan mudah menyebabkan blok dasar kosong.
Bagian selanjutnya,
SROA (penggantian skalar agregat), adalah salah satu yang paling banyak digunakan. Namanya menyebabkan beberapa kebingungan karena SROA hanya salah satu fungsinya. Pass memeriksa setiap pengalokasian instruksi (alokasi memori pada tumpukan fungsi), dan mencoba mengubahnya menjadi register SSA. Satu instruksi pengalokasian (
yaitu, pada kenyataannya, sebuah variabel pada tumpukan kira
- kira Terjemahan.) Berubah menjadi banyak register jika ia ditugaskan secara statis beberapa kali, dan jika pengalokasian adalah kelas atau struktur, ia dibagi menjadi komponen (ini disebut "skalar" pengganti ”sebagaimana disebutkan dalam nama bagian ini). Versi sederhana SROA akan menyerah untuk menumpuk variabel yang digunakan untuk operasi pengambilan alamat, tetapi versi LLVM berinteraksi dengan algoritma analisis alias dan bertindak dengan cara yang cerdas (meskipun ini tidak diperlukan dalam contoh berikut).

Setelah SROA, petunjuk pengalokasian (dan petunjuk pemuatan dan penyimpanan yang sesuai) menghilang, dan kode menjadi lebih bersih dan lebih cocok untuk pengoptimalan berikutnya (tentu saja, SROA tidak dapat menghapus semua pengalokasian dalam kasus umum, ini hanya terjadi jika analisis penunjuk dapat benar-benar menyingkirkan alias). Dalam prosesnya, SROA memasukkan instruksi phi ke dalam kode. Instruksi phi membentuk inti dari representasi SSA, dan kurangnya phi dalam kode yang dihasilkan oleh Clang memberitahu kita bahwa Clang menghasilkan versi sepele dari SSA, di mana blok-blok dasar dihubungkan melalui memori dan bukan melalui register SSA.
Berikut ini adalah "
eliminasi subekspresi umum awal ", CSE (penghapusan dini subekspresi umum). CSE mencoba menghilangkan kasus subekspresi berlebihan yang dapat terjadi baik dalam kode yang ditulis manusia maupun dalam kode yang dioptimalkan sebagian. "CSE Awal" adalah versi CSE cepat dan mudah yang mengidentifikasi kalkulasi redundan sepele.

Di sini,% 10 dan% 17 melakukan hal yang sama, yaitu, kode dapat ditulis ulang sehingga satu nilai digunakan, dan yang kedua dihapus. Ini memberikan beberapa wawasan tentang manfaat SSA: ketika setiap register ditugaskan hanya satu kali, tidak ada yang namanya beberapa versi dari satu register. Dengan demikian, perhitungan yang berlebihan dapat dideteksi menggunakan kesetaraan sintaksis, tanpa menggunakan analisis mendalam dari program (ini bukan kasus untuk lokasi memori yang ada di luar dunia SSA).
Berikutnya, beberapa lintasan diluncurkan yang tidak berpengaruh dalam kasus kami, dan kemudian "
pengoptimal variabel global " diluncurkan, yang digambarkan sebagai berikut:
, . , , , , ..Bagian ini membuat perubahan berikut:
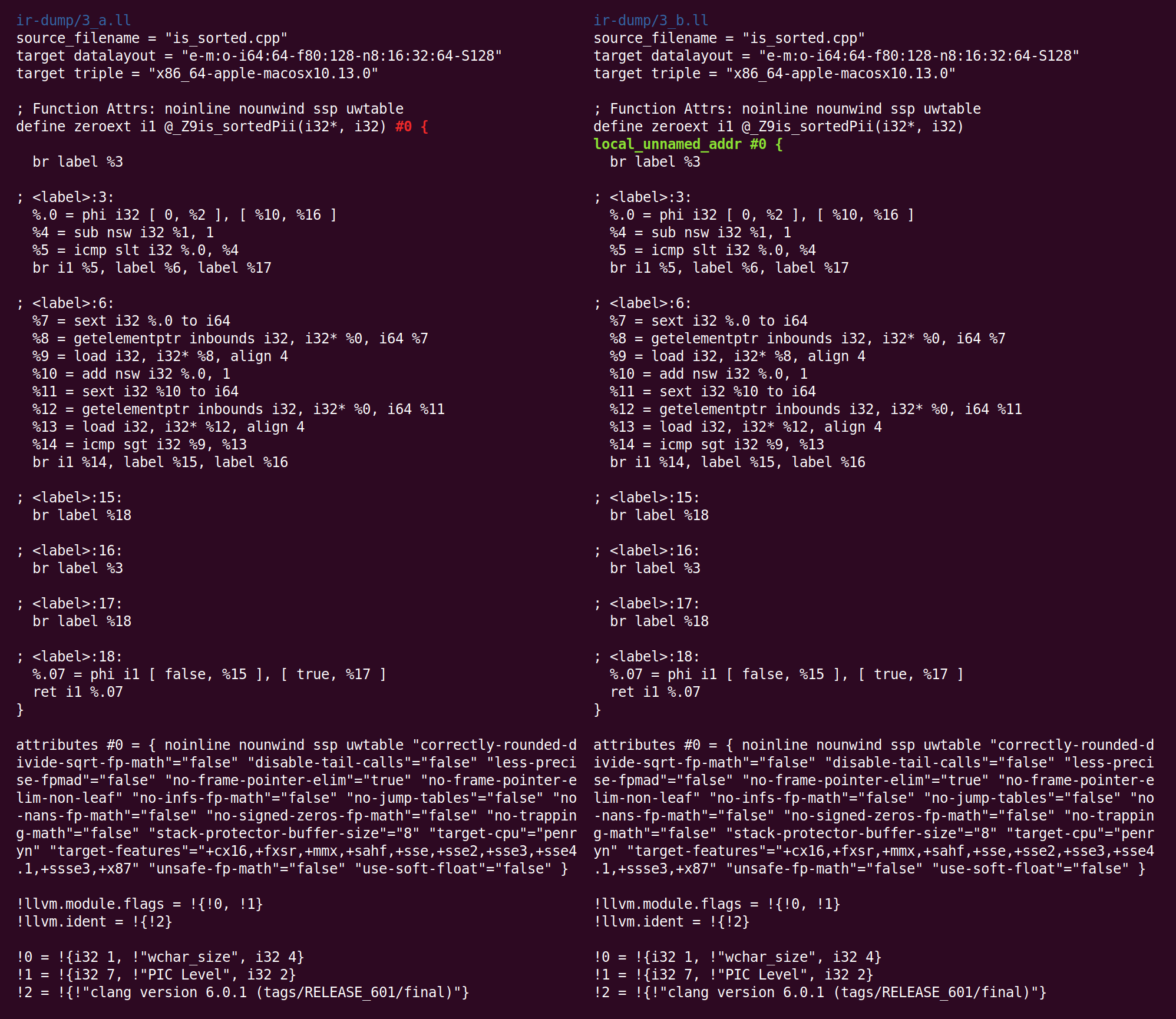
Dia menambahkan atribut fungsi: metadata yang digunakan oleh satu bagian dari kompiler untuk menyimpan informasi tentang apa yang mungkin berguna untuk bagian lain dari kompiler. Anda dapat membaca tentang tujuan dari atribut ini di
sini .
Tidak seperti optimasi lain yang kami pertimbangkan, optimizer variabel global adalah antar-prosedur, itu terlihat sepenuhnya pada modul LLVM. Modul (kurang lebih) setara dengan unit kompilasi dalam C dan C ++. Berbeda dengan optimasi antar-prosedur, intraprocedural hanya melihat satu fungsi pada satu waktu.
Bagian selanjutnya menggabungkan instruksi dan disebut "
instruksi combiner ", InstCombine. Ini adalah kumpulan besar dan beragam
optimisasi lubang intip , yang (biasanya) menulis ulang beberapa instruksi, dikombinasikan dengan data umum, dalam bentuk yang lebih efisien. InstCombine tidak mengubah aliran kontrol suatu fungsi. Dalam contoh di atas, dia tidak banyak berubah:
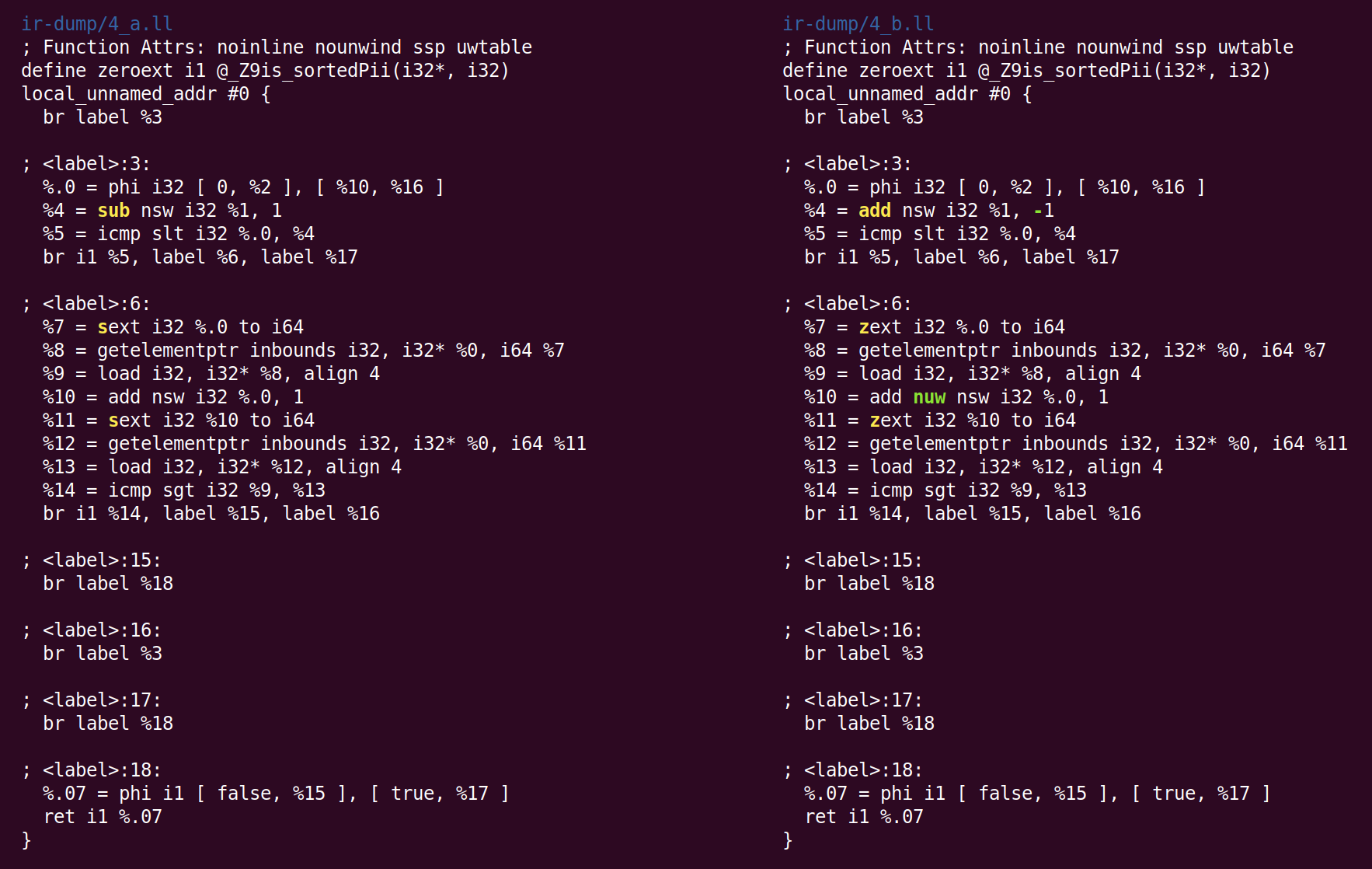
Di sini, alih-alih mengurangi 1 dari% 1, untuk menghitung% 4, kami menambahkan -1. Ini bukan optimasi, tetapi kanonikisasi. Ketika ada banyak cara untuk melakukan perhitungan, LLVM mencoba untuk membawanya ke bentuk kanonik (sering dipilih secara acak) yang akan dilewati oleh pass dan backend berikutnya. Perubahan kedua yang dibuat InstCombine adalah bentuk kanonik dari dua operasi ekspansi yang ditandatangani (instruksi sext), yang menghitung% 7 dan% 11 dikonversi menjadi nol ekspansi (zext). Konversi ini aman ketika kompiler dapat membuktikan bahwa operan sext adalah non-negatif. Dalam hal ini, ini karena variabel loop berubah dari 0 ke n (jika n negatif, loop tidak dieksekusi sama sekali). Perubahan terakhir adalah penambahan bendera “nuw” (tanpa bungkus yang tidak ditandatangani) pada instruksi yang menghitung% 10. Kita dapat melihat bahwa ini aman, dari kenyataan bahwa (1) variabel loop selalu meningkat dan (2) jika variabel dimulai dari nol dan meningkat, itu akan menjadi tidak terdefinisi ketika tanda berubah di persimpangan INT_MAX sebelum mencapai luapan yang tidak ditandai, mengikuti UINT_MAX. Bendera ini dapat digunakan untuk pengoptimalan berikutnya.
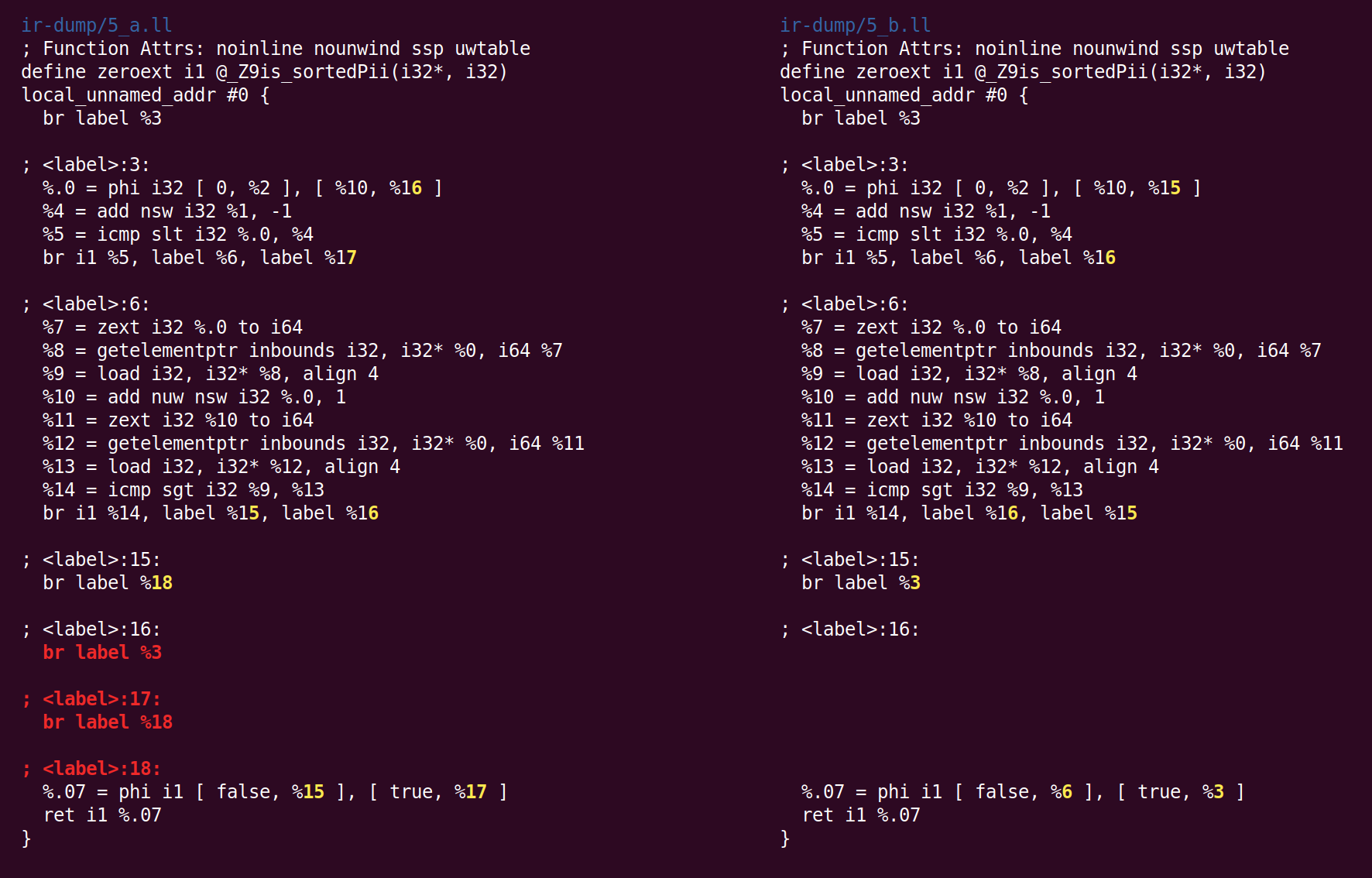
Selanjutnya, SimplifyCFG memulai yang kedua kalinya, dan menghapus dua blok dasar kosong:
Kemudian, “Deduce function attributes” meneruskan anotasi fungsi:

"Norecurse" berarti bahwa fungsi tidak termasuk dalam panggilan rekursif, "readonly" berarti bahwa fungsi tersebut tidak mengubah keadaan global. Atribut parameter "nocapture" berarti bahwa parameter tidak disimpan di mana pun setelah keluar dari fungsi, dan "readonly" berarti bahwa memori tidak dimodifikasi oleh fungsi. Anda dapat melihat
daftar atribut fungsi dan
atribut parameter .
Kemudian pass "
rotate loops " memindahkan kode dalam upaya untuk meningkatkan kondisi untuk optimasi berikutnya:

Meskipun perbedaannya terlihat menakutkan, perubahannya sebenarnya kecil. Kita dapat melihat apa yang terjadi, dengan cara yang lebih mudah dibaca, jika kita meminta LLVM untuk menggambar grafik transfer kendali sebelum dan sesudah melalui siklus rotasi. Inilah pandangan mereka sebelum (kiri) dan sesudah (kanan):
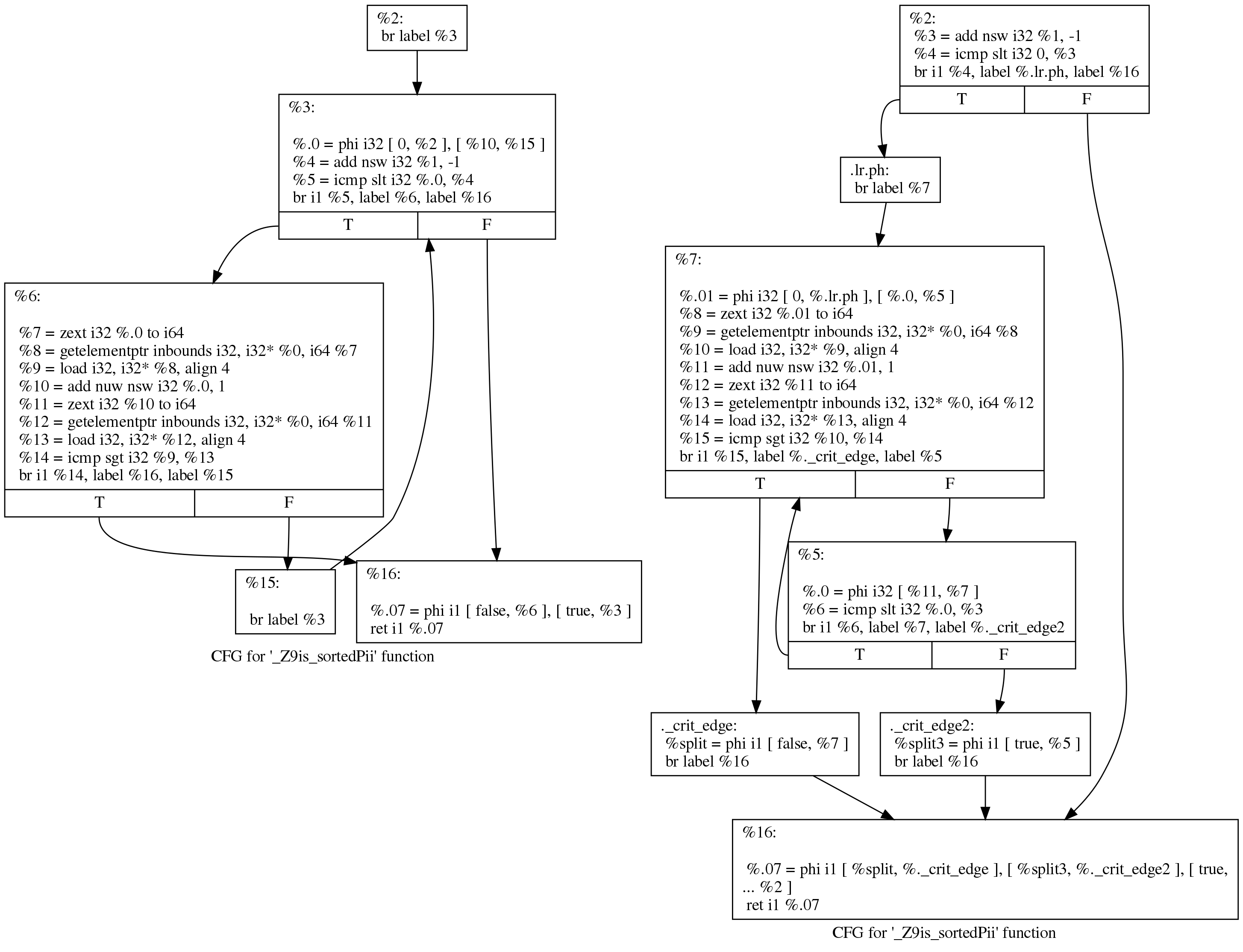
Kode asli masih mengikuti struktur loop yang dihasilkan Dentang:
initializer goto COND COND: if (condition) goto BODY else goto EXIT BODY: body modifier goto COND EXIT:
Setelah dijalankan, loop terlihat seperti ini:
initializer if (condition) goto BODY else goto EXIT BODY: body modifier if (condition) goto BODY else goto EXIT EXIT:
(Koreksi yang diajukan oleh Johannes Durfert tercantum di bawah ini - terima kasih!)
Tujuan dari putaran putaran pass adalah untuk menghapus satu cabang, yang memungkinkan untuk optimasi lebih lanjut. Saya tidak menemukan deskripsi yang lebih baik tentang konversi ini di Internet.
Pass penyederhanaan CFG meminimalkan dua blok dasar yang hanya berisi instruksi phi degenerasi (input tunggal):

Pass combiner instruksi mengubah “% 4 = 0 s <(% 1 - 1)” menjadi “% 4 =% 1 s> 1 ″ (di mana s <dan s> adalah operasi untuk membandingkan operan yang ditandatangani), ini transformasi yang bermanfaat, mengurangi panjang rantai ketergantungan dan juga dapat membuat instruksi "mati" (tidak dapat dicapai) (lihat
tambalan yang melakukan ini). Pass ini juga menghapus instruksi phi sepele yang ditambahkan oleh pass rotasi putaran.

Berikut ini adalah perikop “
canonicalize natural loops ”, yang dijelaskan dalam kode sumbernya sendiri sebagai berikut:
, .
(Loop pre-header) , , . ,, LICM.
, , ( ) ( ). , , "store-sinking", LICM.
, (backedge).
Indirectbr . , . , , .
, simplifycfg , , , .
, , CFG, .
Di sini kita melihat bahwa blok keluaran dimasukkan:
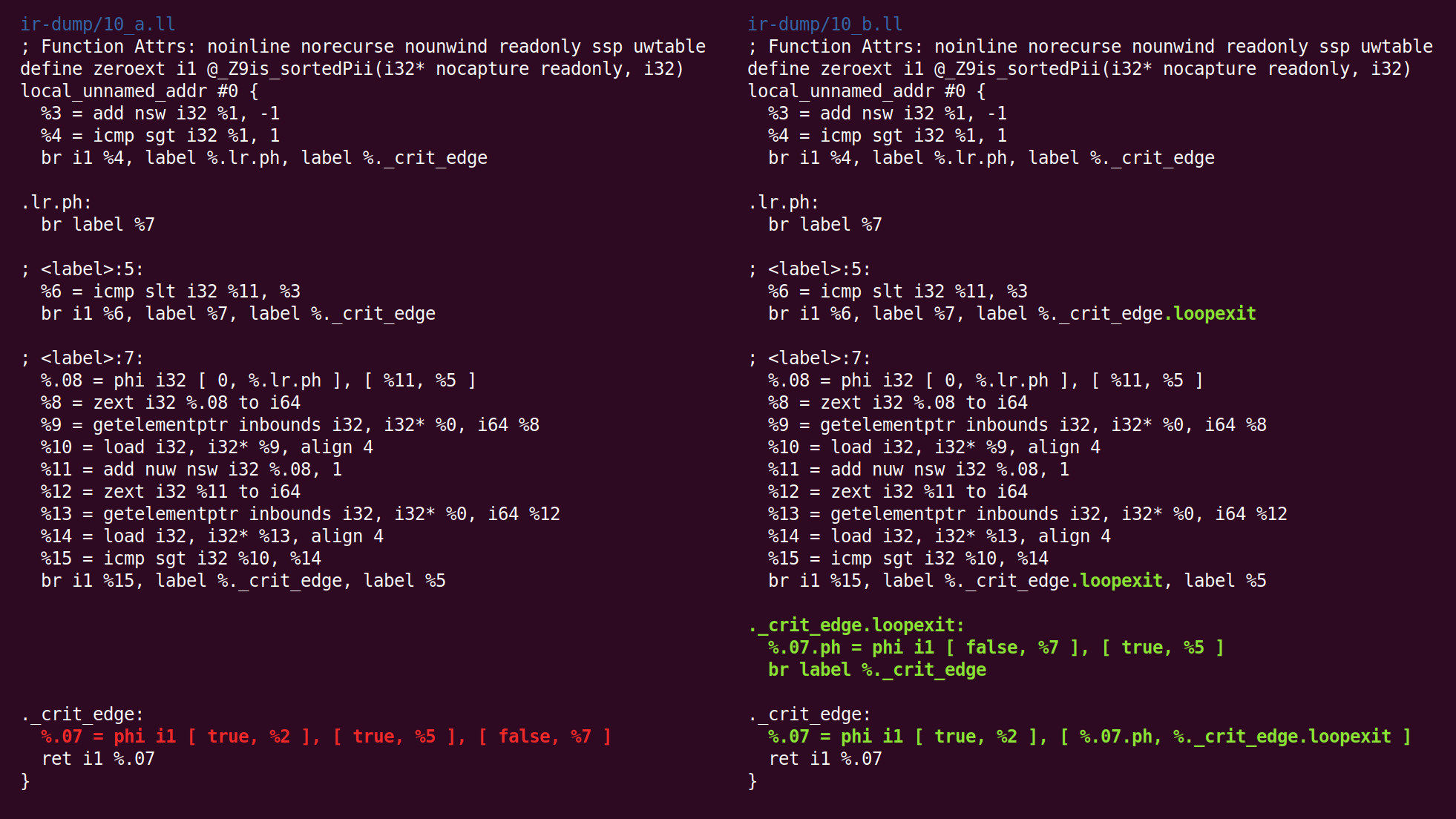
Kemudian ikuti "
penyederhanaan variabel loop ":
( , ), , .
, :
, . , 'for (i = 7; i*i < 1000; ++i)' 'for (i = 0; i != 25; ++i)'.
indvar , . , "".
Efek dari pass ini adalah mengubah variabel loop 32-bit menjadi 64-bit:
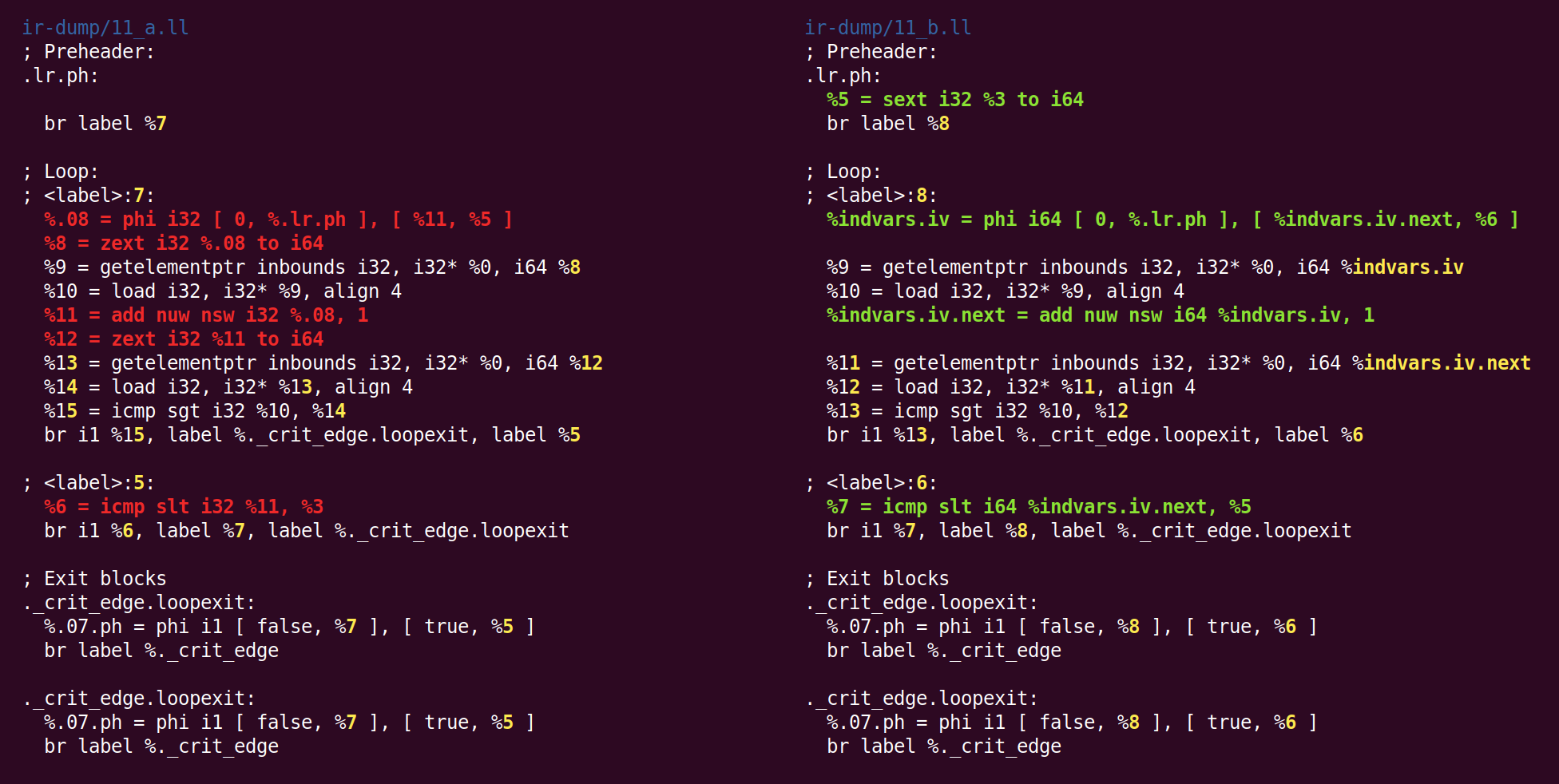
Saya tidak tahu mengapa zext - sebelumnya dilemparkan ke bentuk kanonik dari sext, kembali lagi ke sext.
Sekarang pass “
penomoran nilai global ” sedang melakukan optimasi yang sangat cerdas. Salah satu alasan untuk menulis posting ini adalah keinginan untuk menunjukkannya. Bisakah kamu melihatnya di sini?

Apakah kamu melihat? Ya, dua instruksi muat di loop di sebelah kiri, sesuai dengan [i] dan [i + 1]. Di sini, GVN menemukan bahwa memuat [i] tidak perlu, karena [i +1] dari satu iterasi dari loop dapat ditransfer ke yang berikutnya, seperti [i]. Trik sederhana ini mengurangi jumlah memori yang dibaca oleh fungsi menjadi setengahnya. Baik LLVM dan
GCC telah belajar untuk melakukan transformasi ini baru-baru ini.
Anda mungkin bertanya pada diri sendiri apakah trik ini akan berhasil jika kita membandingkan [i] dengan [i + 2]. Ternyata tidak, tetapi GCC dapat mengalokasikan
hingga empat register untuk kasus-kasus seperti itu.
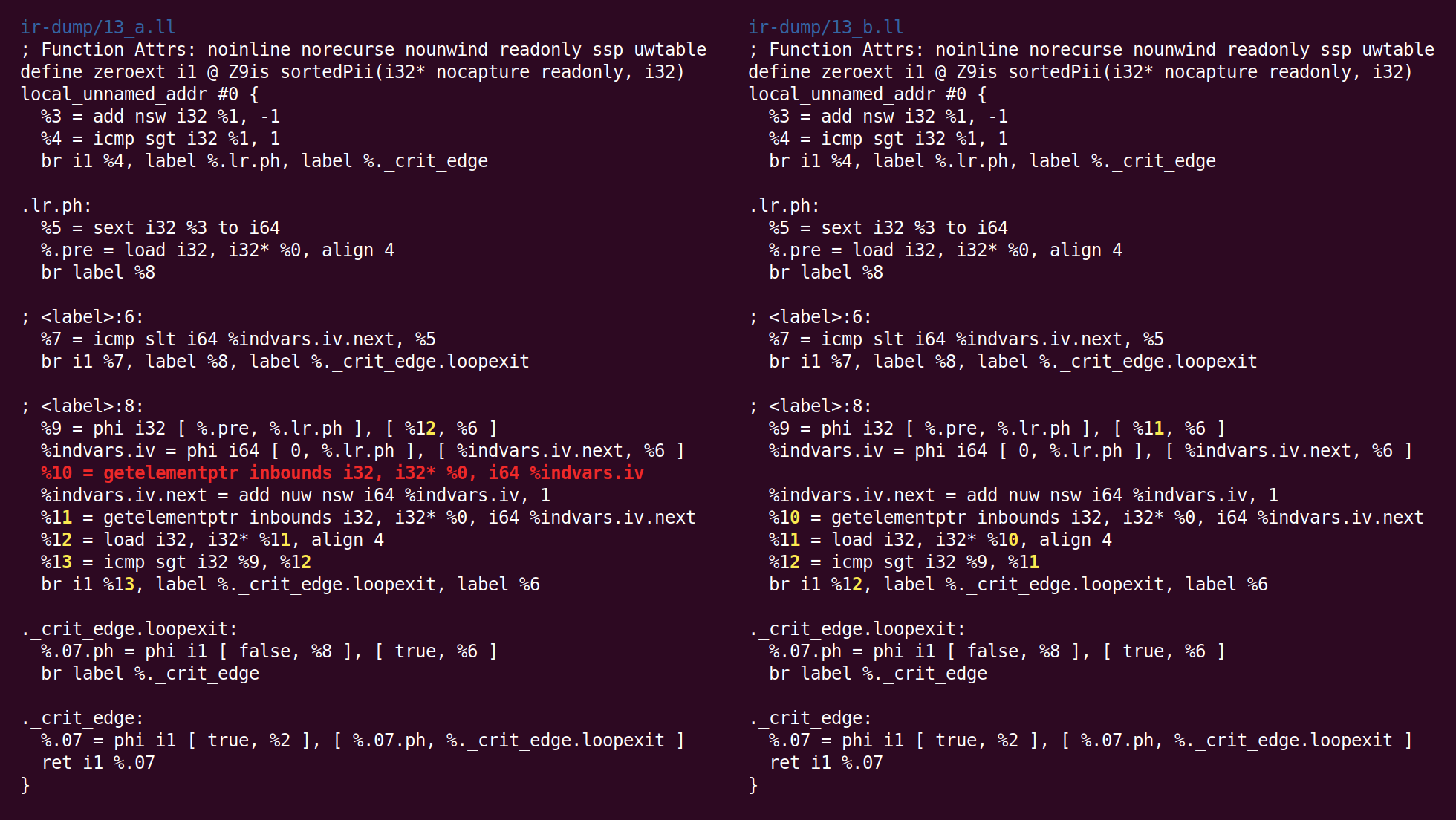
Kemudian pass “
penghapusan kode mati bit-tracking ” dimulai:
"Bit-Tracking Dead Code Elimination". (, "" "" ..) "" . , "" .Tapi di sini ternyata trik seperti itu tidak diperlukan, karena satu-satunya kode mati adalah instruksi GEP (get element pointer), dan itu sepele mati (pass GVN menghapus instruksi muatan yang menggunakan alamat yang dihitung oleh instruksi ini):
Sekarang algoritma untuk menggabungkan instruksi telah menempatkan add di unit dasar lain. Logika di mana transformasi ini ditempatkan di InstCombine tidak jelas bagi saya, mungkin tidak ada tempat yang jelas di mana ia dapat ditempatkan:

Sesuatu yang lebih aneh sedang terjadi sekarang: pass “
jump threading ” telah menghapus apa yang telah dilakukan pass “canonicalize natural loops” sebelumnya:

Kemudian kita kembali melemparkan ke bentuk kanonik:
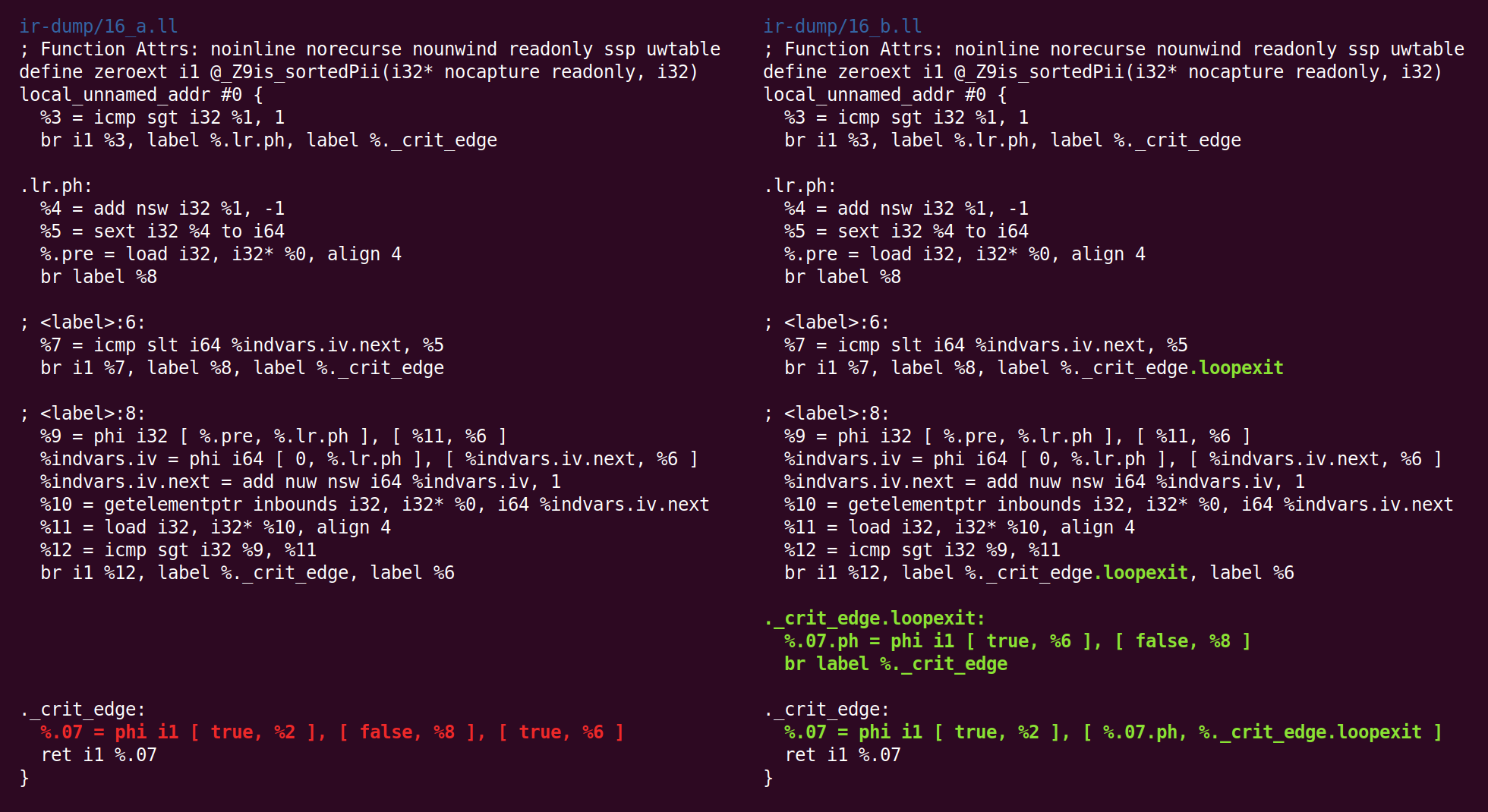
Dan penyederhanaan CFG mengubahnya secara berbeda:
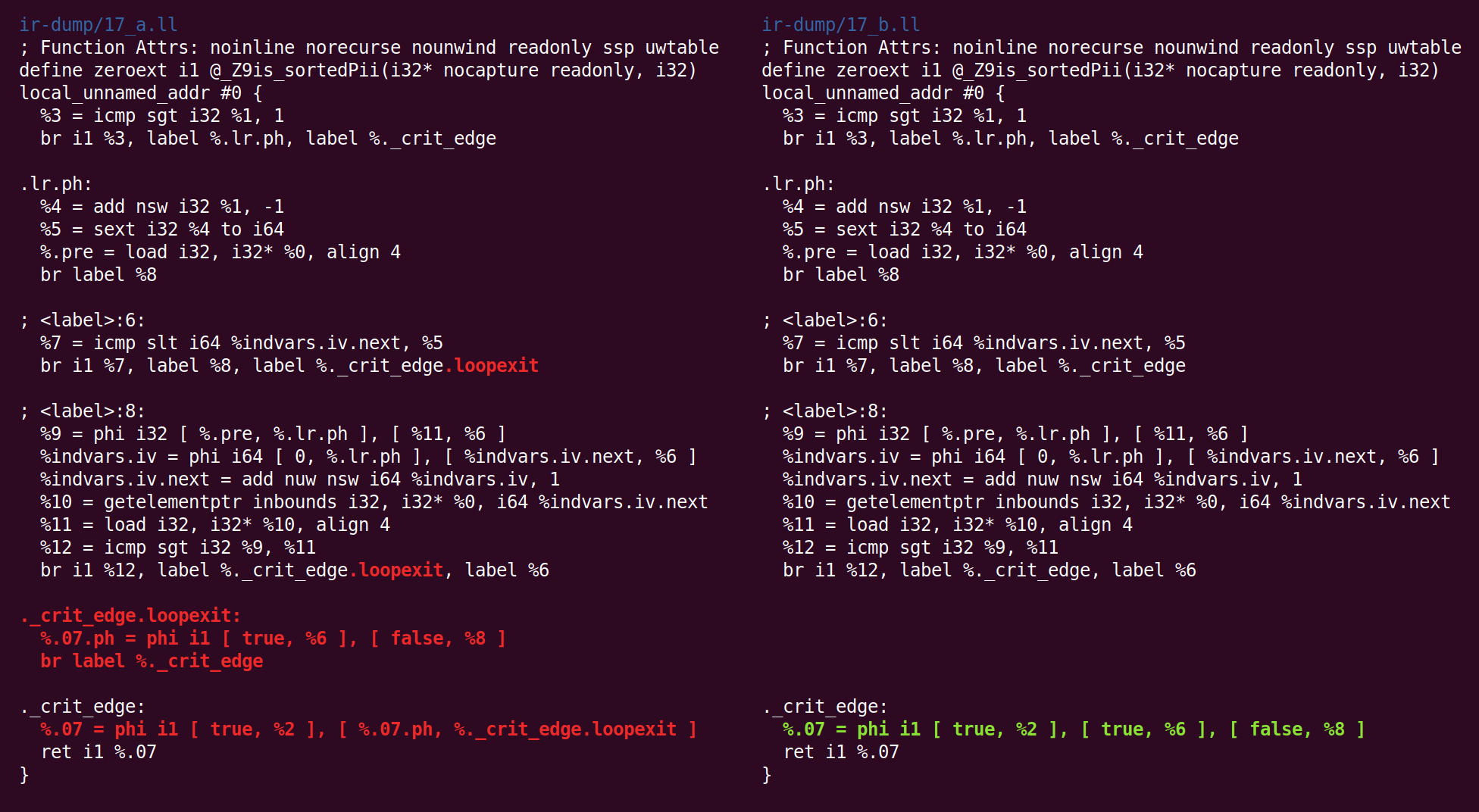
Dan kembali:
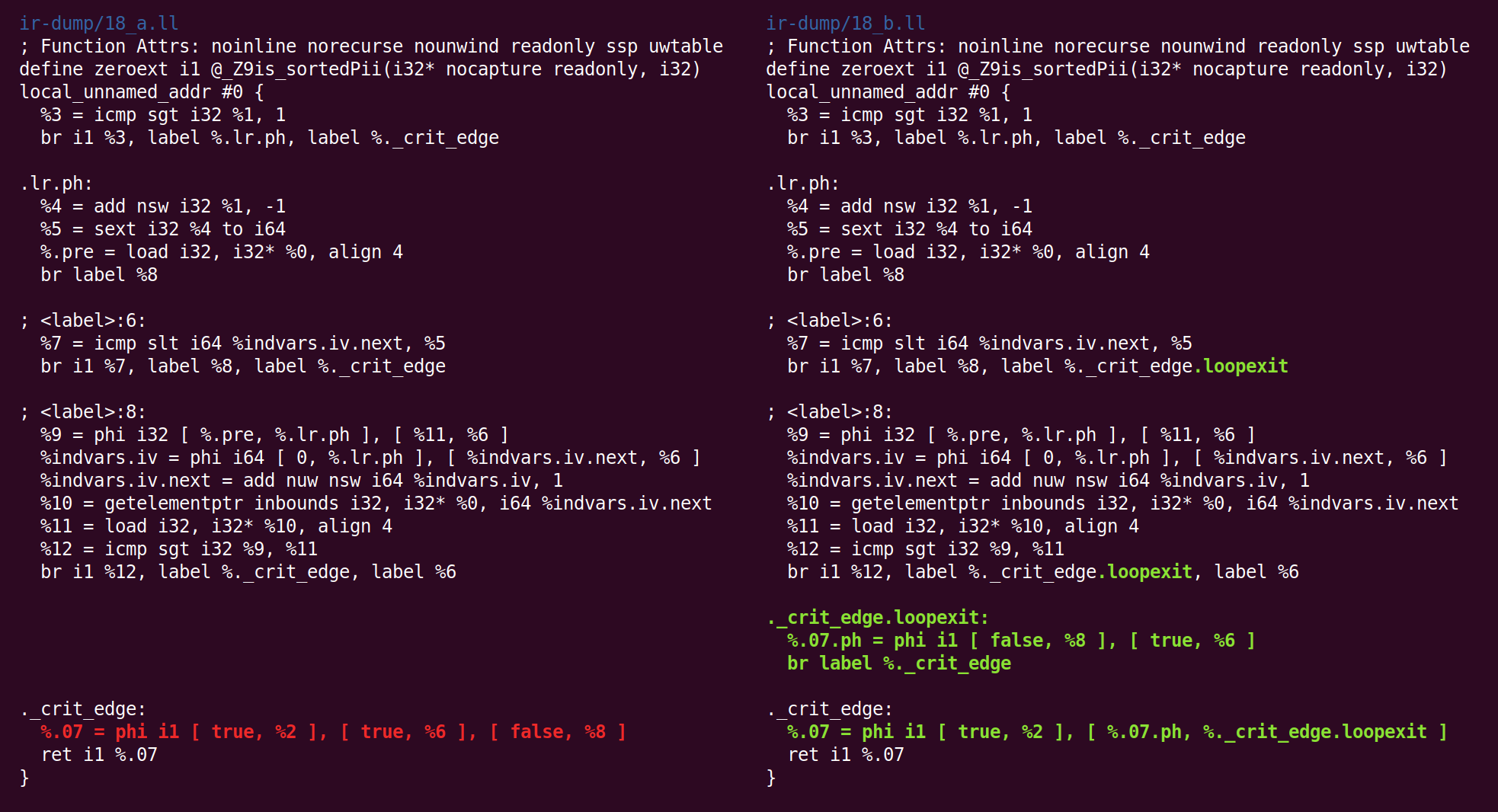
Dan di sana lagi:

Dan kembali:
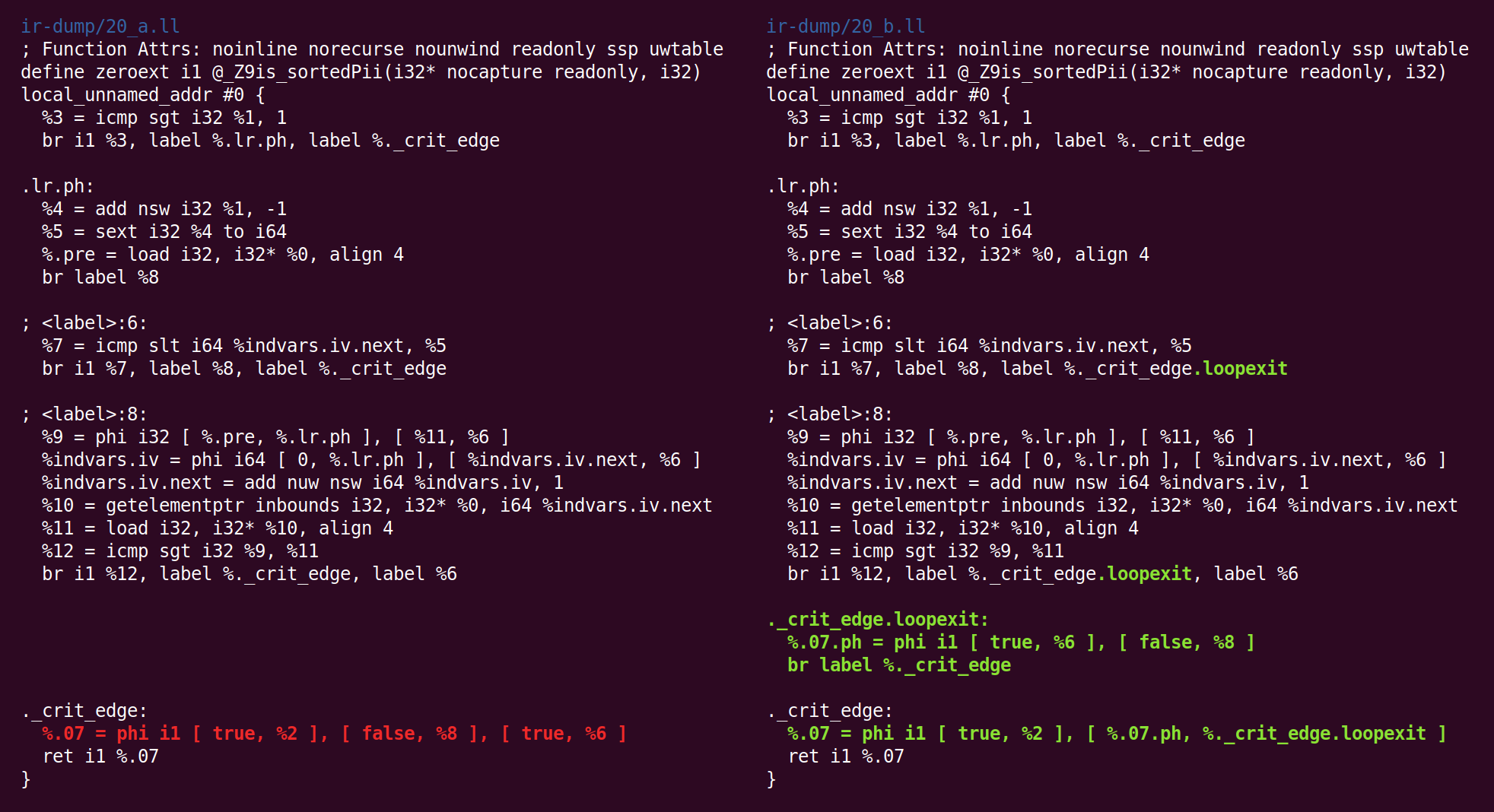
Dan disana:

Dan akhirnya, kita selesai dengan midland! Kode di sebelah kanan adalah kode yang akan kami sampaikan (dalam kasus kami) ke backend x86-64.
Anda mungkin ingin tahu apakah fluktuasi perilaku pada akhir pipa adalah hasil dari bug penyusun, tetapi mari kita perhatikan bahwa fungsi ini sangat, sangat sederhana dan ada banyak lintasan yang terlibat dalam pemrosesan, tetapi saya bahkan tidak menyebutkannya karena mereka tidak melakukan perubahan apa pun pada kode. Sepanjang paruh kedua dari pipa optimasi, kami terutama mengamati kasus-kasus degenerasi untuk fungsi ini.
Ucapan Terima Kasih: beberapa siswa dalam kursus kompiler mendalam saya musim gugur ini meninggalkan umpan balik pada draft posting ini (dan saya juga menggunakan bahan ini untuk pekerjaan rumah). Saya membahas fungsi-fungsi yang dibahas di sini dalam serangkaian kuliah yang bagus tentang optimasi loop.