Dalam kondisi beban tinggi, kompleksitas mengoptimalkan database relasional meningkat dengan urutan besarnya, karena membeli perangkat keras yang lebih kuat adalah mahal dan tidak ada cara untuk mematikan aplikasi pada malam hari untuk proses perubahan database yang lama dan migrasi data.
Kami baru-baru ini berbicara tentang bagaimana kami
mengoptimalkan kode PHP untuk aplikasi kami . Sekarang pergantian artikel telah terjadi tentang bagaimana kita benar-benar mengubah struktur internal dari database yang paling banyak dimuat dan penting di Badoo, tanpa kehilangan satu permintaan.
Sabar
Users DataBase, atau UDB, adalah layanan yang memulai hampir semua permintaan ke Badoo. Ini memecahkan beberapa masalah: pertama, itu adalah repositori pusat dari data pengguna utama yang otorisasi terjadi (misalnya, email, user_id atau facebook_id). Selain menyimpan data ini, layanan ini menyediakan kontrol keunikan (sehingga dua pengguna dengan email yang sama, facebook_id, dll. Tidak dapat mendaftar dalam sistem). Dan layanan yang sama memberikan informasi tentang yang mana dari ribuan pecahan yang berisi semua data pengguna lainnya.
Pada akhir 2018, UDB menyimpan data dari lebih dari 800 juta pengguna, yang menempati sekitar 1 TB ruang disk. Semua ini dilayani oleh pasangan server MySQL master-slave di masing-masing pusat data kami. Secara total, mereka memproses lebih dari 140.000 permintaan per detik.
Jatuhnya UDB berarti tidak dapat diaksesnya semua Badoo, karena kode tidak akan dapat menemukan beling tempat data pengguna berada. Oleh karena itu, permintaan besar ditempatkan untuk keandalan dan ketersediaan.
Karena kekhususan ini, sangat mahal untuk membuat perubahan dalam struktur penyimpanan, jadi kami menganggap desain UDB pada tahun 2013 dengan sangat serius. Namun, seiring waktu, persyaratan serta profil beban berubah. Dalam upaya untuk menyesuaikan sistem dengan persyaratan baru dan tingkat beban, banyak perubahan kecil dan sederhana telah dibuat, tetapi, sayangnya, perubahan seperti itu masih jauh dari yang paling efektif. Dan hari itu tiba ketika, alih-alih peretasan berikutnya atau pembelian perangkat keras yang mahal, lebih bijaksana untuk melakukan optimasi secara lebih global. Selanjutnya kita akan mempertimbangkan tahapan utama dari jalan ini.
Optimalisasi non-invasif
Setiap perubahan pada struktur database yang besar dan dimuat cukup mahal karena rumitnya proses migrasi data. Oleh karena itu, pertama-tama, Anda harus menghabiskan semua opsi optimasi yang tidak mempengaruhi struktur data, tetapi terbatas pada permintaan kode dan SQL. Mungkin ini akan cukup untuk menunda masalah beban kerja yang berlebihan selama beberapa tahun, yang akan memungkinkan Anda untuk melakukan sesuatu yang lebih penting bagi bisnis saat ini.
Semakin baik Anda memahami sistem Anda, semakin mudah bagi Anda untuk menemukan pendekatan untuk optimasi tersebut. Pastikan Anda mengumpulkan semua metrik yang dapat membantu Anda. Ini bukan hanya tentang metrik sistem seperti penggunaan CPU dan penggunaan RAM atau metrik dari basis data tertentu, tetapi juga tentang metrik tingkat aplikasi dari aplikasi yang terkait dengan basis data yang dioptimalkan. Berapa banyak permintaan per detik yang dimiliki berbagai jenis operasi? Apa waktu respon mereka? Berapa ukuran input dan output? Di metrik inilah Anda dapat menilai keberhasilan optimasi. Tidak mungkin Anda membutuhkan pengoptimalan yang akan sedikit mengurangi penggunaan CPU pada server database, tetapi pada saat yang sama meningkatkan waktu respons aplikasi Anda hingga sepuluh kali lipat.

Setelah mulai mengumpulkan metrik tingkat aplikasi tambahan untuk UDB, kami dapat lebih memahami operasi mana yang dilakukan yang menghasilkan 80% dari beban dan merupakan kandidat pertama untuk studi, dan yang digunakan sedikit atau tidak sama sekali.
Analisis terperinci dari operasi yang paling sering (mengambil pengguna yang memenuhi kriteria tertentu) menunjukkan bahwa, terlepas dari kenyataan bahwa semua data pengguna yang tersedia diminta dari database, pada kenyataannya aplikasi di 95% kasus hanya menggunakan user_id. Hanya dengan memisahkan kasus ini menjadi metode API terpisah yang mengekstraksi hanya satu kolom dari tabel, kami dapat mengambil manfaat dari penggunaan indeks penutup dan menghapus sekitar 5% dari beban CPU dari server database dengan ini.
Analisis operasi lain yang sering menunjukkan bahwa, meskipun faktanya dilakukan untuk setiap permintaan HTTP, pada kenyataannya, data yang diambilnya sangat jarang. Kami menerjemahkan permintaan ini ke model yang malas.
Tujuan utama metrik dalam hal proyek optimasi adalah untuk lebih memahami database Anda dan menemukan bagian yang paling gemuk. Tidak masuk akal untuk menghabiskan banyak waktu dan upaya mengoptimalkan kueri yang membentuk kurang dari 1% dari profil beban Anda. Jika Anda tidak memiliki metrik yang memungkinkan Anda memahami profil muatan Anda, kumpulkan. Dengan optimasi seperti itu di sisi kode, kami berhasil menghapus sekitar 15% penggunaan CPU dari 80% dari basis data yang dikonsumsi.
Menguji ide
Jika Anda akan mengoptimalkan basis data yang dimuat dengan mengubah strukturnya, Anda harus mulai dengan memeriksa ide-ide Anda di bangku tes, karena bahkan optimasi yang terlihat sangat menjanjikan secara teori mungkin tidak memiliki efek positif dalam praktik (dan kadang-kadang mereka bahkan memiliki efek negatif). Dan Anda tidak mungkin ingin tahu tentang hal ini hanya setelah lama migrasi data produksi.
Semakin dekat konfigurasi dudukan Anda dengan konfigurasi produksi, semakin dapat diandalkan Anda akan mendapatkan hasil. Poin penting adalah memastikan muatan dudukan yang benar. Menjalankan acak atau kueri yang sama dapat menyebabkan hasil yang salah. Pilihan terbaik adalah menggunakan permintaan nyata dari produksi. Untuk UDB, kami mencatat dari produksi setiap permintaan baca API kesepuluh (termasuk parameter) dalam bentuk hanya log JSON dalam file. Selama sehari, kami mengumpulkan log berukuran 65 GB dari 700 juta permintaan.
Kami tidak menguji catatan, dibandingkan dengan jumlah permintaan baca, sangat kecil dan tidak memengaruhi beban kami. Namun, ini mungkin bukan kasus Anda. Jika Anda ingin memuat bangku tes dengan permintaan menulis, Anda harus mengumpulkan setiap permintaan, karena melewatkan permintaan menulis dapat menyebabkan kesalahan konsistensi di bangku tes.
Langkah selanjutnya adalah kehilangan log pada dudukan dengan benar. Kami menggunakan 400 pekerja PHP, diluncurkan dari
skrip cloud kami , yang membaca log yang dikumpulkan dari antrian cepat dan menjalankan permintaan secara berurutan. Dalam hal ini, antrian diisi dengan skrip lain dengan kecepatan yang ditentukan secara ketat. Untuk menguji ide, kami menggunakan kecepatan x10, yang, dikalikan dengan fakta bahwa kami hanya mengumpulkan dari produksi setiap permintaan kesepuluh, memberikan jumlah RPS yang sama seperti dalam produksi.
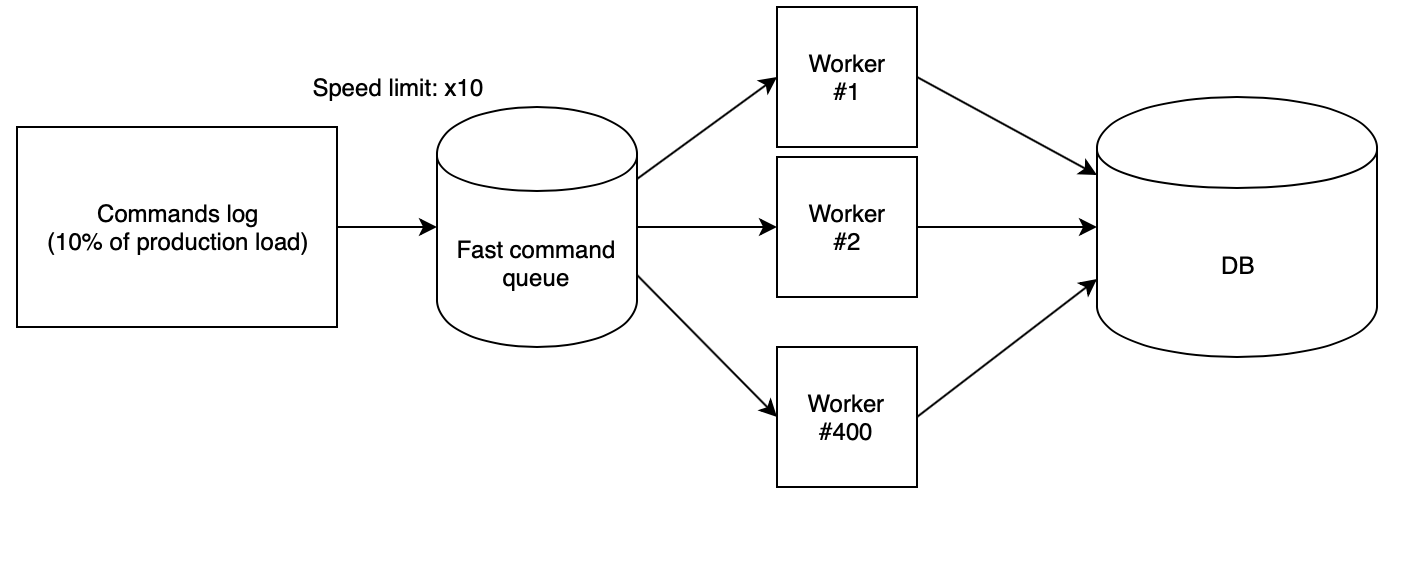
Dengan koefisien-koefisien ini, ternyata hari produksi dengan semua beban turun di bangku tes hanya dalam dua setengah jam.
Jadi, misalnya, tes pertama yang kami jalankan dengan kecepatan x5 (50% dari beban produksi) pada log kueri selama setengah hari terlihat seperti:
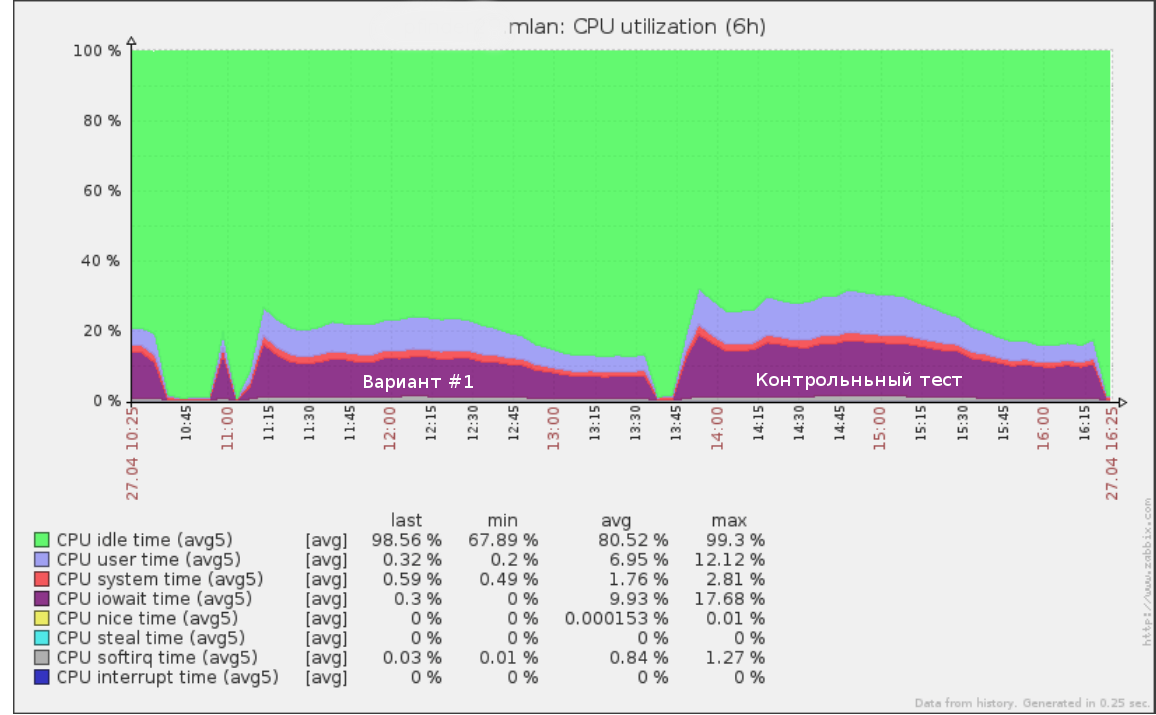
Alat yang sama dapat digunakan untuk melakukan uji kegagalan: meningkatkan kecepatan (dan karena itu RPS) hingga dudukan pada dudukan mulai menurun. Ini akan memberi Anda pemahaman yang jelas tentang seberapa banyak beban yang bisa ditahan oleh basis data Anda.
Setelah menguji skema data baru, penting juga untuk melakukan tes kontrol pada struktur database asli. Jika hasil dan kinerja saat ini pada produksi sangat berbeda, Anda harus terlebih dahulu memahami alasannya. Mungkin server pengujian tidak dikonfigurasi dengan benar dan Anda tidak dapat mempercayai data pengujian pemuatan.
Perlu juga memastikan bahwa kode baru berfungsi dengan benar. Tidak masuk akal untuk menguji kinerja kueri yang tidak melakukan pekerjaan. Anda akan dilayani dengan baik oleh tes integrasi yang memeriksa untuk melihat apakah API lama dan baru mengembalikan nilai yang sama pada panggilan API yang sama.
Setelah menerima hasil pada semua ide, hanya memilih opsi dengan keseimbangan terbaik antara harga dan kualitas dan memperkenalkan skema baru untuk produksi.
Perubahan skema
Pertama-tama, saya perhatikan bahwa mengubah skema data tanpa menghentikan pengoperasian layanan selalu sangat sulit, mahal dan berisiko. Karena itu, jika Anda memiliki kesempatan untuk menghentikan aplikasi sambil mengubah struktur - lakukan saja. Dalam kasus UDB, sayangnya, kami tidak mampu membelinya.
Faktor kedua yang mempengaruhi kompleksitas perubahan sirkuit adalah skala perubahan yang direncanakan. Jika semua perubahan yang diajukan pada tabel tidak hanya melampaui perubahan (misalnya, menambahkan sepasang indeks atau kolom baru), maka Anda dapat menghidupkannya dengan proses khas seperti
pt-online-skema-perubahan dan
gh-ost untuk MySQL atau budak alternatif diikuti dengan mengubah tempat mereka .
Dalam kasus kami, hasil yang sangat baik ditunjukkan dalam pengabaian vertikal satu tabel raksasa sekitar selusin lebih kecil dengan kolom dan indeks lainnya serta data dalam format yang berbeda. Konversi seperti itu dengan alat biasa tidak lagi mungkin. Jadi apa yang harus dilakukan?
Kami menerapkan algoritma berikut:
- Kami mencapai keadaan di mana skema lama dan baru dengan data saat ini ada secara bersamaan. Rekaman berjalan di kedua, dan pada saat yang sama ada jaminan konsistensi data di kedua versi. Kami akan mempertimbangkan item ini secara terperinci di bawah ini.
- Secara bertahap mengalihkan seluruh bacaan ke sirkuit baru, mengendalikan beban.
- Matikan rekaman dalam skema lama dan hapus.
Keuntungan utama dari pendekatan ini:
- keamanan: ada kemungkinan rollback instan hingga ke tahap terakhir (cukup alihkan pembacaan kembali ke skema lama, jika terjadi kesalahan);
- kontrol muatan penuh selama migrasi data;
- tidak perlu mengganti meja besar dari sirkuit lama
Namun, ada juga kelemahannya:
- kebutuhan untuk menjaga kedua versi skema pada disk selama proses migrasi (ini bisa menjadi masalah jika Anda memiliki sedikit ruang dan tabel yang dimigrasi sangat besar);
- banyak kode sementara untuk mendukung proses migrasi, yang akan terpotong setelah selesai;
- dimungkinkan untuk mencuci cache dengan membaca dari dua skema secara paralel; ada kekhawatiran bahwa versi lama dan baru akan bersaing untuk RAM, yang dapat menyebabkan degradasi layanan (pada kenyataannya, ini benar-benar menciptakan beban tambahan, namun, karena migrasi dilakukan di luar puncak, ini tidak menimbulkan masalah bagi kami).
Kesulitan utama dalam algoritma ini adalah poin pertama. Kami akan mempertimbangkannya secara rinci.
Ubah Sinkronisasi
Migrasi data statis tidak terlalu sulit. Namun, bagaimana jika Anda tidak bisa menghentikan seluruh rekaman saat database dimigrasi?
Ada beberapa opsi untuk mencapai sinkronisasi skema baru: migrasi dengan menggulung log dan rekaman idempoten migrasi.
Memigrasi snapshot data diikuti dengan memutar log perubahan berikut
Setiap transaksi pembaruan data dicatat dalam tabel khusus melalui pemicu di tingkat aplikasi, atau replikasi binlog digunakan sebagai log. Setelah Anda memiliki log seperti itu, Anda dapat membuka transaksi dan memigrasi snapshot data, mengingat posisi dalam log. Kemudian tetap mulai menerapkan log yang dikumpulkan pada skema baru. Demikian pula, misalnya,
alat pencadangan MySQL
Percona XtraBackup yang populer
berfungsi .
Setelah skema baru mengetahui log ke catatan saat ini, tahap yang paling penting dimulai: Anda masih perlu menjeda perekaman dalam skema lama untuk waktu yang singkat dan, memastikan bahwa seluruh log yang tersedia diterapkan ke skema baru, yang berarti bahwa data antara skema konsisten, Pada level aplikasi, aktifkan perekaman sekaligus di kedua sumber.
Kerugian utama dari pendekatan ini adalah bahwa Anda perlu menyimpan log operasi, yang dengan sendirinya dapat membuat beban dalam proses switching yang kompleks, serta dalam kemungkinan memecahkan rekor jika karena alasan tertentu sirkuit berubah menjadi tidak konsisten.
Catatan Idempoten
Gagasan utama dari pendekatan ini adalah untuk mulai menulis ke skema baru secara paralel dengan menulis ke yang lama sebelum perubahan sepenuhnya disinkronkan, dan kemudian menyelesaikan migrasi data yang tersisa. Demikian pula, biasanya kolom baru diisi dengan tabel besar.
Rekaman sinkron dapat diimplementasikan baik pada pemicu basis data dan dalam kode sumber. Saya menyarankan Anda untuk melakukan ini secara tepat dalam kode, karena dalam hal apa pun, Anda akhirnya harus menulis kode yang akan menulis data ke skema baru, dan implementasi migrasi di sisi kode akan memberi Anda lebih banyak kontrol.
Poin penting untuk dipertimbangkan adalah bahwa sampai migrasi selesai, skema baru akan berada dalam keadaan tidak konsisten. Karena itu, skenario dimungkinkan ketika memperbarui tabel baru mengarah pada pelanggaran konstanta basis data (kunci asing atau indeks unik), sementara dari sudut pandang skema saat ini, transaksi benar-benar benar dan harus dilakukan.
Situasi ini dapat menyebabkan kemunduran transaksi yang baik karena proses migrasi. Cara termudah untuk mengatasi masalah ini adalah menambahkan pengubah IGNORE ke semua permintaan untuk menulis data ke skema baru atau mencegat kemunduran transaksi tersebut dan menjalankan versi tanpa menulis ke skema baru.
Algoritma sinkronisasi melalui perekaman idempoten dalam kasus kami adalah sebagai berikut:
- Kami mengaktifkan perekaman dalam skema baru secara paralel dengan perekaman dalam skema lama dalam mode kompatibilitas (IGNORE).
- Kami menjalankan skrip yang secara bertahap melewati skema baru dan menangkap data yang tidak konsisten. Setelah itu, data di kedua tabel harus disinkronkan, tetapi ini tidak akurat karena kemungkinan konflik dalam ayat 1.
- Kami memulai pemeriksa konsistensi data - kami membuka transaksi dan secara berurutan membaca garis-garis dari skema baru dan lama yang membandingkan korespondensi mereka.
- Jika ada konflik, kami selesai dan kembali ke paragraf 3.
- Setelah pemeriksa menunjukkan bahwa data dalam kedua skema disinkronkan, maka seharusnya tidak ada perbedaan lebih lanjut antara skema, kecuali, tentu saja, kami melewatkan beberapa nuansa. Karenanya, kami menunggu beberapa saat (misalnya, seminggu) dan menjalankan pemeriksaan kontrol. Jika dia menunjukkan bahwa semuanya baik-baik saja, maka tugas selesai dengan sukses dan Anda dapat menerjemahkan bacaan.
Hasil
Sebagai hasil dari mengubah format data, kami dapat mengurangi ukuran tabel utama dari 544 GB menjadi 226 GB, dengan demikian mengurangi beban pada disk dan meningkatkan jumlah data berguna yang sesuai dengan RAM.
Secara total, dari awal proyek, menggunakan semua pendekatan yang dijelaskan, kami dapat mengurangi penggunaan CPU dari server database dari 80% menjadi 35% pada lalu lintas puncak. Hasil dari stress test berikutnya menunjukkan bahwa pada laju pertumbuhan beban saat ini, kita dapat tetap menggunakan perangkat keras yang ada selama setidaknya tiga tahun ke depan.
Membagi satu tabel besar menjadi beberapa menyederhanakan proses melakukan perubahan di masa depan dalam database, dan juga secara signifikan mempercepat beberapa skrip yang mengumpulkan data untuk BI.