 Dari seorang penerjemah:
Dari seorang penerjemah: hari ini kami
menerbitkan untuk Anda sebuah artikel gabungan oleh tiga pengembang, Akaash Chikarmane, Erte Bablu dan Nikhil Gaur, yang menjelaskan metode untuk memprediksi peringkat aplikasi di Google Play Store.
Pada artikel ini, kami akan menunjukkan bagaimana kami memproses informasi yang kami gunakan untuk memprediksi peringkat. Kami juga akan menjelaskan mengapa kami menggunakan ini atau itu dari mereka. Kami akan berbicara tentang transformasi paket data yang kami kerjakan dan tentang apa yang dapat dicapai dengan menggunakan visualisasi.
Skillbox merekomendasikan: Kursus praktis dua tahun "Saya seorang Pengembang Web PRO . "
Kami mengingatkan Anda: untuk semua pembaca "Habr" - diskon 10.000 rubel saat mendaftar untuk kursus Skillbox apa pun menggunakan kode promosi "Habr".
Mengapa kami memutuskan untuk melakukannya
Aplikasi seluler telah lama menjadi bagian integral dari kehidupan, semakin banyak pengembang yang terlibat dalam kreasi mereka sendiri. Selain itu, banyak yang secara langsung bergantung pada pendapatan yang dibawa aplikasi. Karena itu, meramalkan kesuksesan sangat penting bagi mereka.
Tujuan kami adalah untuk menentukan peringkat keseluruhan aplikasi, untuk melakukan ini secara komprehensif, karena terlalu banyak orang menilai program, hanya mengandalkan jumlah "bintang" yang ditetapkan oleh pengguna. Aplikasi dengan 4-5 poin lebih kredibel.
Persiapan
Sebagian besar proyek ini bekerja dengan data, termasuk preprocessing. Karena semua informasi diambil dari Google Play Store, array yang dihasilkan mengandung banyak kesalahan. Kami menggunakan beberapa model regresi, termasuk Gradient-Boosting Regressor dari paket XGBoost, Linear Regression, dan RidgeRegression.
Pengumpulan dan analisis data
Dataset yang kami kerjakan dapat
ditemukan di sini . Ini terdiri dari dua bagian. Yang pertama adalah informasi yang objektif, seperti ukuran aplikasi, jumlah instalasi, kategori, jumlah ulasan, jenis aplikasi, genre, tanggal pembaruan terakhir, dll., Dan subyektif, yaitu ulasan pengguna.
Ulasan sendiri menjadi sasaran analisis. Setelah membandingkan hasilnya, kami memutuskan apakah akan memasukkan data survei dalam model akhir atau tidak.
Kami membentuk data objektif yang ditetapkan oleh 12 fungsi dan satu variabel target (peringkat). Paket termasuk 10,8 ribu unit informasi. Sedangkan untuk tinjauan pengguna, kami memilih 100 fungsi yang paling relevan dan digunakan untuk 64,3 ribu elemen. Semua data dikumpulkan langsung dari Google Play Store, terakhir kali diperbarui tiga bulan lalu.
Pra-pemrosesan data
Set informasi awal terlihat seperti ini:
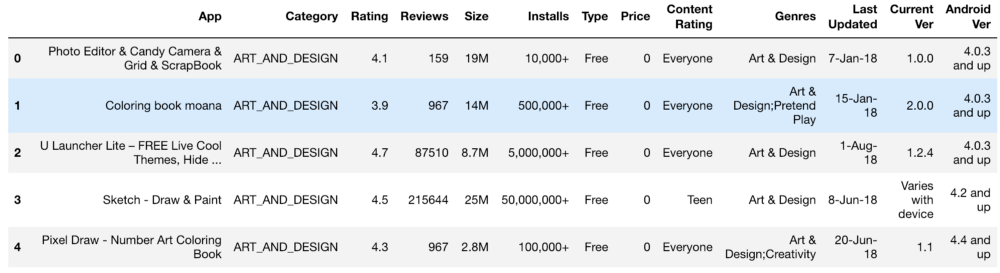
Pengaturan, peringkat, biaya, dan ukuran - kami memproses semua ini sedemikian rupa untuk mendapatkan angka yang dapat dimengerti oleh mesin. Saat memproses berbagai fungsi, muncul masalah, seperti kebutuhan untuk menghapus "+". Dalam biaya kami menghapus $. Volume aplikasi ternyata menjadi yang paling bermasalah dalam hal pemrosesan, karena baik KB maupun MB, jadi perlu dilakukan beberapa pekerjaan untuk mengurangi semuanya menjadi satu format. Data primer ditunjukkan di bawah ini dan mereka juga setelah diproses.
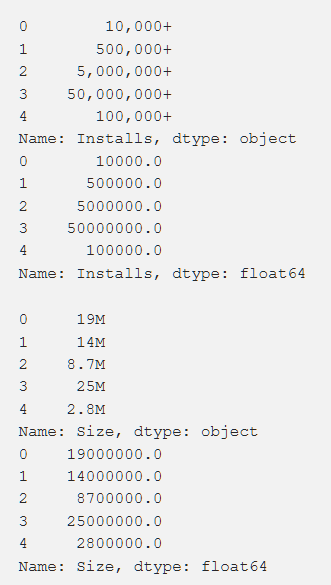
Selain itu, kami mengubah beberapa data, menjadikannya lebih relevan dengan pekerjaan kami. Misalnya, informasi tentang pembaruan aplikasi terbaru tidak terlalu berguna. Agar lebih bermakna, kami mengonversinya menjadi informasi tentang waktu yang berlalu sejak pembaruan terakhir. Kode untuk tugas ini ditunjukkan di bawah ini.
from datetime import datetime from dateutil.relativedelta import relativedelta n = 3
Itu juga perlu untuk membawa ke variabel standar tunggal dengan beberapa nilai yang berbeda (misalnya, "Genre"). Cara ini dilakukan ditunjukkan di bawah ini.
from copy import deepcopy from sklearn.preprocessing import LabelEncoder def one_hot_encode_by_label(df, labels): df_new = deepcopy(df) for label in labels: dummies = df_new[label].str.get_dummies(sep = ";") df_new = df_new.drop(labels = label, axis = 1) df_new = df_new.join(dummies) return df_new def label_encode_by_label(df, labels): df_new = deepcopy(df) le = LabelEncoder() for label in labels: print(label + " is label encoded") le.fit(df_new[label]) dummies = le.transform(df_new[label]) df_new.drop(label, axis = 1) df_new[label] = pd.Series(dummies) return df_new
Untuk menormalkan data, kami mencoba konversi log1p. Sebelum dia:
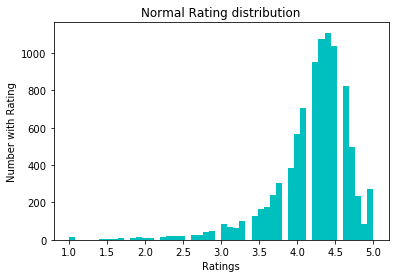
Setelah:
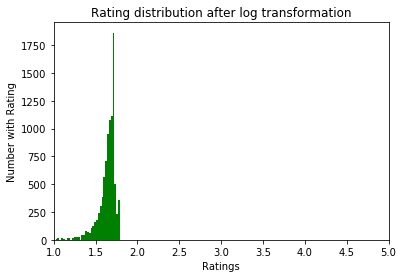
Eksplorasi data
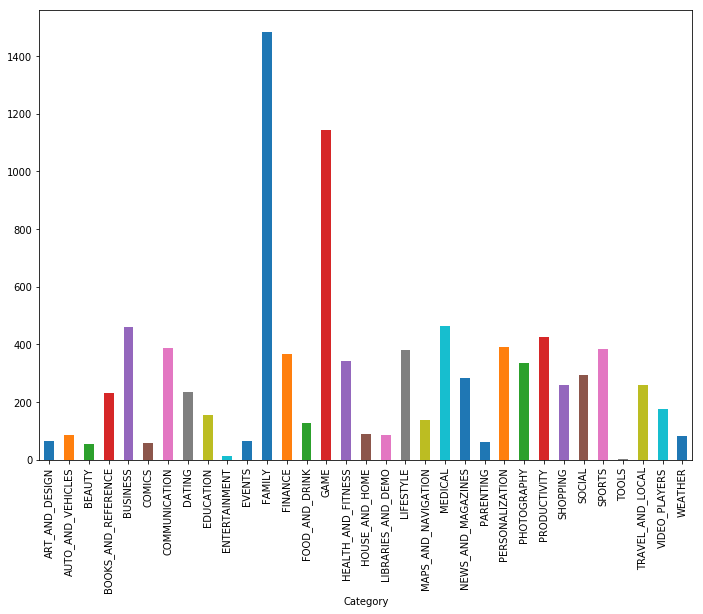
Seperti yang Anda lihat, permainan dan aplikasi untuk keluarga adalah dua kategori paling populer. Sebagian besar aplikasi juga berada dalam kategori "Untuk semua umur".
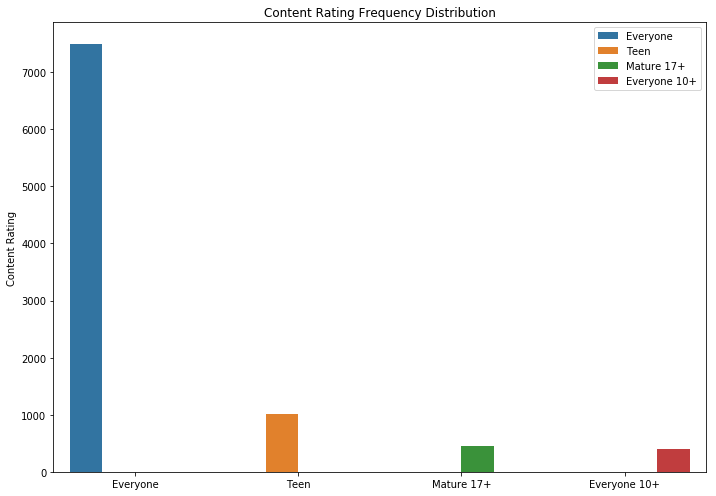

Adalah logis bahwa aplikasi dengan peringkat maksimum memiliki lebih banyak ulasan daripada yang berperingkat rendah. Beberapa dari mereka memiliki lebih banyak ulasan daripada yang lainnya. Mungkin alasannya adalah pesan pop-up, panggilan untuk menilai atau teknik serupa lainnya.

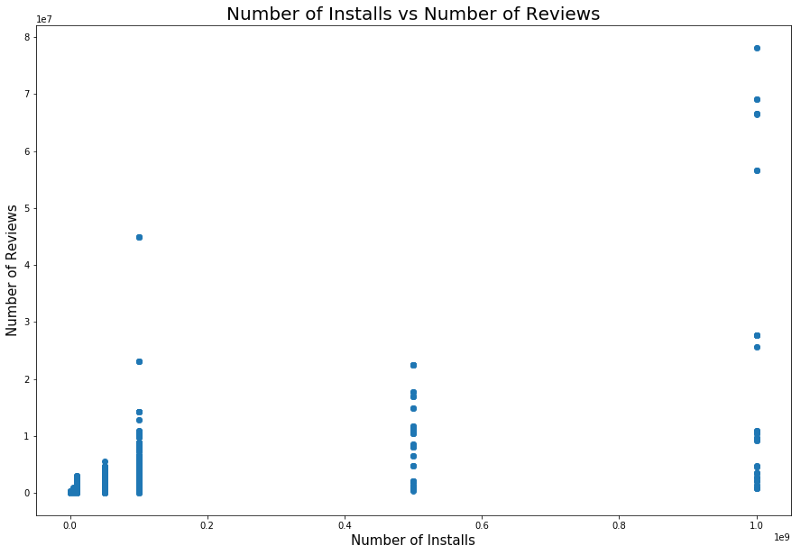
Ada juga hubungan antara jumlah instalasi dan jumlah ulasan. Korelasi ditunjukkan pada tangkapan layar di bawah ini.
Analisis terperinci dari ketergantungan ini dapat memberikan pemahaman tentang mengapa kategori aplikasi populer memiliki lebih banyak instalasi dan lebih banyak ulasan.
Model dan Hasil
Kami menggunakan pemisahan tes untuk memecah data menjadi set tes dan pelatihan. Validasi silang dengan GridSearchCV digunakan untuk meningkatkan hasil pelatihan model untuk menemukan alpha terbaik dengan Lasso, Regresi Ridge dan XGBRegressor dari paket XGBoost. Model yang terakhir ini umumnya sangat efektif, tetapi jika menggunakannya, kita harus berhati-hati dalam menyesuaikan hasilnya - ini adalah salah satu bahaya yang menunggu peneliti. Nilai rms awal tanpa ada pengolahan khusus objek (hanya coding dan pembersihan) adalah sekitar 0,228.
Setelah konversi peringkat, kesalahan standar turun menjadi 0,219, yang merupakan sedikit peningkatan, tetapi kami menyadari bahwa kami melakukan semuanya dengan benar.
Kami menggunakan regresi linier setelah mengevaluasi hubungan antara ulasan, sikap, dan peringkat. Secara khusus, kami menganalisis informasi statistik dari variabel-variabel ini, termasuk r-squared dan p, membuat keputusan tentang regresi linier sebagai hasilnya. Model regresi linier pertama yang digunakan menunjukkan korelasi antara pengaturan dan peringkat 0,2233, model regresi linier Ulasan dan Penilaian kami memberi kami MSE 0,2107, dan model regresi linier gabungan, Ulasan, Pengaturan, dan Peringkat ", Memberi kami MSE 0,214.
Selain itu, kami menggunakan model KNeighborsRegressor. Hasil penggunaannya ditunjukkan di bawah ini.

Kesimpulan
Setelah data primer dari Google Play Store dikonversi menjadi format yang dapat digunakan, kami merencanakan dan mengambil fungsi untuk memahami korelasi antara nilai-nilai individual. Kemudian hasil ini digunakan untuk membangun model yang optimal.
Awalnya, kami percaya bahwa tidak akan terlalu sulit untuk menemukannya, sehingga kami dapat membangun model yang akurat. Tetapi tugas itu lebih sulit dari yang kami harapkan.
Selain apa yang telah dilakukan, Anda juga dapat:
- buat model terpisah untuk setiap genre;
- Buat fitur baru dari versi OS Android, seperti yang kami lakukan sebelumnya dengan tanggal;
- untuk mempelajari algoritme lebih dalam - kami memiliki cukup banyak poin data kategorikal dan numerik;
- parsing dan hapus data secara independen dari Google App Store.
Semua hasil
tersedia di sini .
Skillbox merekomendasikan: