Kantor Nizhny Novgorod dari Intel, antara lain, sedang mengembangkan algoritma visi komputer berdasarkan jaringan saraf yang dalam. Banyak algoritme kami yang dipublikasikan di repositori
Open Model Zoo . Pelatihan model membutuhkan sejumlah besar data yang ditandai. Secara teoritis, ada banyak cara untuk mempersiapkan mereka, tetapi ketersediaan perangkat lunak khusus mempercepat proses ini berkali-kali. Jadi, untuk meningkatkan efisiensi dan kualitas markup, kami telah mengembangkan alat kami sendiri -
Computer Annotation Tool (CVAT) .
Tentu saja, di Internet Anda dapat menemukan banyak data beranotasi, tetapi ada beberapa masalah. Sebagai contoh, tugas-tugas baru terus muncul yang tidak ada data seperti itu. Masalah lain adalah bahwa tidak semua data cocok untuk digunakan dalam pengembangan produk komersial, karena perjanjian lisensi mereka. Jadi, selain pengembangan dan pelatihan algoritma, aktivitas kami juga mencakup markup data. Ini adalah proses yang agak panjang dan memakan waktu, yang tidak masuk akal untuk diletakkan di pundak pengembang. Misalnya, untuk melatih salah satu algoritme kami, sekitar 769.000 objek ditandai selama lebih dari 3.100 jam kerja.
Ada dua solusi untuk masalah ini:
- Yang pertama adalah mentransfer data markup ke perusahaan pihak ketiga, dengan spesialisasi yang sesuai. Kami memiliki pengalaman serupa. Perlu dicatat proses rumit dari validasi data dan partisi ulang, serta kehadiran birokrasi.
- Yang kedua, lebih nyaman bagi kami, adalah penciptaan dan dukungan dari tim penjelasan kami sendiri. Kenyamanan terletak pada kemampuan untuk dengan cepat mengatur tugas-tugas baru, mengelola kemajuan implementasi mereka dan keseimbangan yang difasilitasi antara harga dan kualitas. Selain itu, dimungkinkan untuk menerapkan algoritma otomatisasi khusus dan meningkatkan kualitas markup.
Awalnya, Alat Anotasi Visi Komputer dikembangkan khusus untuk tim anotasi kami.

Tentu saja, tujuan kami bukan untuk menciptakan "standar ke-15". Pada awalnya, kami menggunakan solusi siap pakai -
Vatic , tetapi dalam prosesnya, tim anotasi dan algoritmik menyajikan persyaratan baru untuk itu, implementasi yang akhirnya mengarah pada penulisan ulang lengkap kode program.
Lebih lanjut dalam artikel:
- Informasi umum (fungsionalitas, aplikasi, kelebihan dan kekurangan alat)
- Sejarah dan evolusi (sebuah cerita pendek tentang bagaimana CVAT hidup dan berkembang)
- Perangkat internal (deskripsi arsitektur tingkat tinggi)
- Arah pengembangan (sedikit tentang tujuan yang ingin saya capai, dan cara yang mungkin untuk mereka)
Informasi umum
Computer Vision Annotation Tool (CVAT) adalah alat sumber terbuka untuk menandai gambar dan video digital. Tugas utamanya adalah untuk menyediakan pengguna dengan cara yang nyaman dan efektif untuk menandai set data. Kami membuat CVAT sebagai layanan universal yang mendukung berbagai jenis dan format markup.
Untuk pengguna akhir, CVAT adalah aplikasi web berbasis browser. Ini mendukung berbagai skenario kerja dan dapat digunakan baik untuk pekerjaan pribadi maupun tim. Tugas utama pembelajaran mesin dengan seorang guru di bidang pemrosesan gambar dapat dibagi menjadi tiga kelompok:
- Deteksi Objek
- Klasifikasi gambar
- Segmentasi gambar
CVAT cocok untuk semua skenario ini.
Keuntungan:- Kurangnya instalasi oleh pengguna akhir. Untuk membuat tugas atau menandai data, cukup buka tautan tertentu di browser.
- Kemampuan untuk bekerja bersama. Ada peluang untuk membuat tugas tersedia bagi publik bagi pengguna dan untuk memaralelkan pekerjaan di atasnya.
- Mudah digunakan. Menginstal CVAT di jaringan lokal adalah beberapa perintah melalui penggunaan Docker .
- Otomatisasi proses markup. Interpolasi, misalnya, memungkinkan Anda mendapatkan markup pada banyak bingkai, dengan pekerjaan nyata hanya pada beberapa yang penting.
- Pengalaman para profesional. Alat ini dikembangkan dengan partisipasi anotasi dan beberapa tim algoritmik.
- Kemampuan untuk berintegrasi. CVAT cocok untuk diintegrasikan ke dalam platform yang lebih luas. Misalnya, Onepanel .
- Dukungan opsional untuk berbagai alat:
- Deep Learning Deployment Toolkit (komponen sebagai bagian dari OpenVINO)
- Tensorflow Object Detection API (TF OD API)
- Sistem analisis ELK (Elasticsearch + Logstash + Kibana)
- NVIDIA CUDA Toolkit
- Dukungan untuk berbagai skenario anotasi.
- Sumber terbuka di bawah lisensi MIT sederhana dan gratis.
Kekurangan:- Dukungan browser terbatas. Kinerja bagian klien dijamin hanya di browser Google Chrome. Kami tidak menguji CVAT di peramban lain, tetapi secara teoritis, alat ini dapat berfungsi di Opera, Peramban Yandex, dan lainnya dengan mesin Chromium.
- Sistem tes otomatis belum dikembangkan. Semua pemeriksaan kesehatan dilakukan secara manual, yang secara signifikan memperlambat perkembangan. Namun, kami sudah bekerja pada solusi untuk masalah ini dalam hubungannya dengan siswa UNN mereka. Lobachevsky sebagai bagian dari proyek Lab IT .
- Dokumentasi kode sumber tidak tersedia. Terlibat dalam pengembangan bisa sangat sulit.
- Keterbatasan kinerja. Dengan meningkatnya permintaan pada volume markup, kami menghadapi berbagai masalah, seperti keterbatasan Chrome Sandbox dalam penggunaan RAM.
Tentu saja, daftar ini tidak lengkap, tetapi mengandung ketentuan dasar.
Seperti yang disebutkan sebelumnya, CVAT mendukung sejumlah komponen tambahan. Diantaranya adalah:
Deep Learning Deployment Toolkit sebagai bagian dari
OpenVINO Toolkit - digunakan untuk mempercepat peluncuran model TF OD API tanpa adanya GPU. Kami sedang mengerjakan beberapa kegunaan lain yang bermanfaat untuk komponen ini.
Tensorflow Object Detection API - digunakan untuk menandai objek secara otomatis. Secara default, kami menggunakan model Faster RCNN Inception Resnet V2, dilatih tentang
COCO (80 kelas), tetapi seharusnya tidak ada kesulitan untuk menghubungkan model lain.
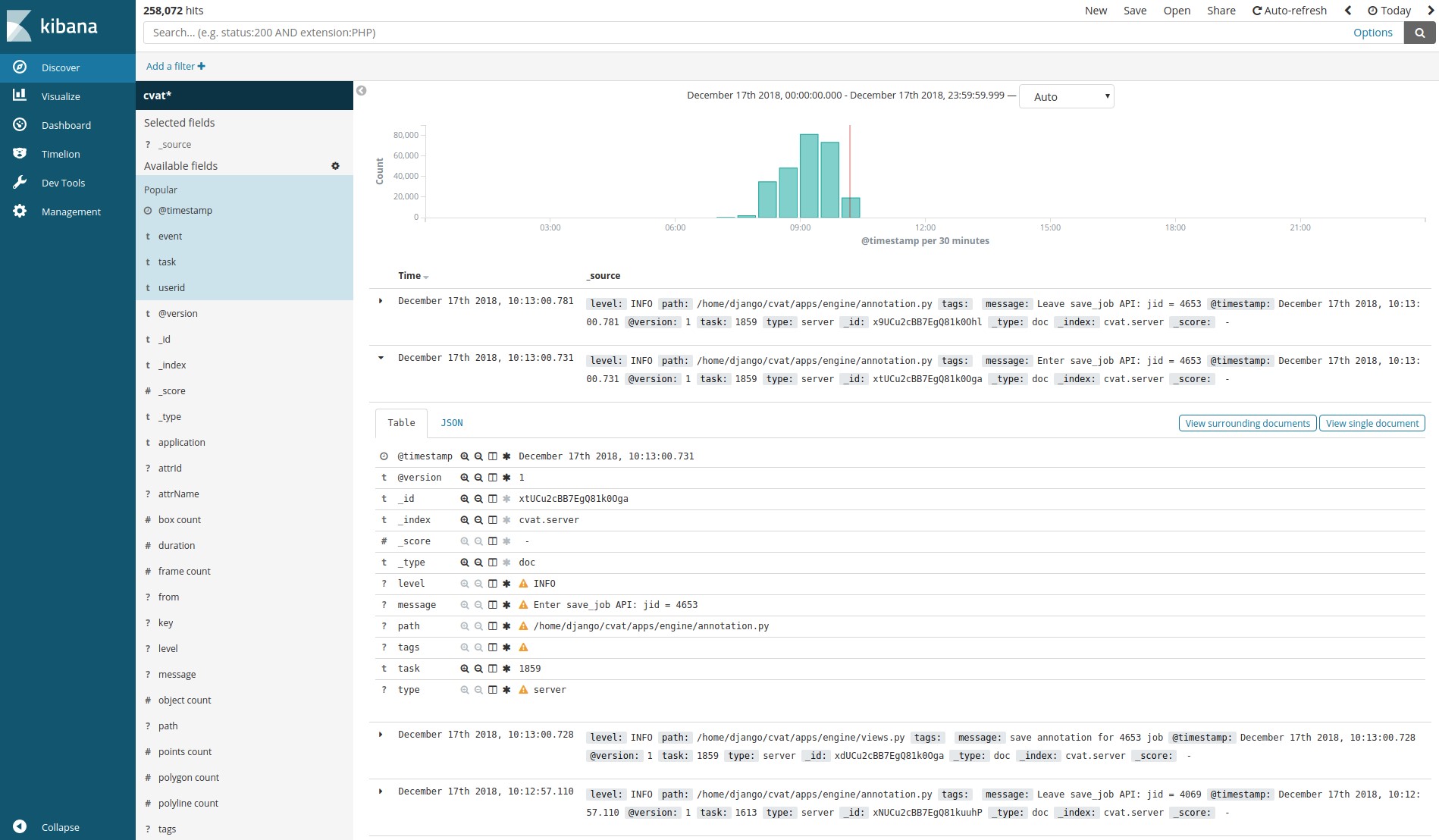
Logstash, Elasticsearch, Kibana - memungkinkan Anda untuk memvisualisasikan dan menganalisis log yang diakumulasikan oleh pelanggan. Ini dapat digunakan, misalnya, untuk memantau proses markup atau untuk mencari kesalahan dan penyebabnya.
 NVIDIA CUDA Toolkit
NVIDIA CUDA Toolkit - seperangkat alat untuk melakukan perhitungan pada prosesor grafis (GPU). Itu dapat digunakan untuk mempercepat tata letak otomatis dengan TF OD API atau di add-on kustom lainnya.
Markup data
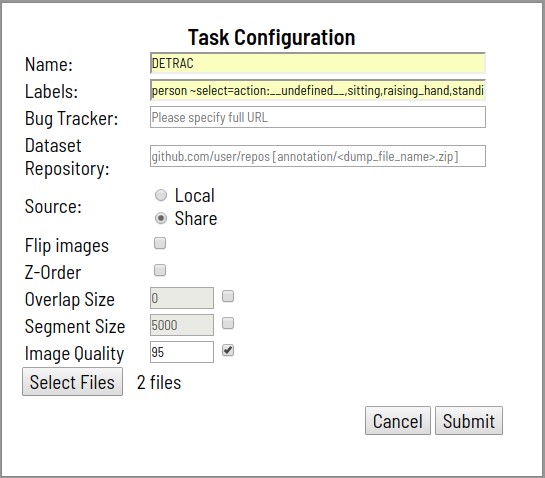
- Proses dimulai dengan pernyataan masalah untuk tata letak. Pementasan meliputi:
- Menentukan nama tugas
- Enumerasi kelas yang akan ditandai dan atributnya
- Menentukan File untuk Diunduh
- Data diunduh dari sistem file lokal, atau dari sistem file terdistribusi yang dipasang di sebuah wadah
- Tugas dapat berisi satu arsip dengan gambar, satu video, satu set gambar, dan bahkan struktur direktori dengan gambar saat mengunduh melalui penyimpanan terdistribusi
- Setel opsional:
- Tautan ke spesifikasi markup terperinci, serta informasi tambahan lainnya (Bug Tracker)
- Tautan ke repositori Git jarak jauh untuk menyimpan anotasi (Dataset Repository)
- Putar semua gambar 180 derajat (Membalikkan Gambar)
- Dukungan lapisan untuk tugas segmentasi (Z-Order)
- Ukuran Segmen Tugas yang dapat diunduh dapat dibagi menjadi beberapa subtugas untuk pekerjaan paralel
- Area Persimpangan Segmen (Tumpang tindih). Digunakan dalam video untuk menggabungkan anotasi di berbagai segmen
- Tingkat kualitas saat mengonversi gambar (Kualitas Gambar)
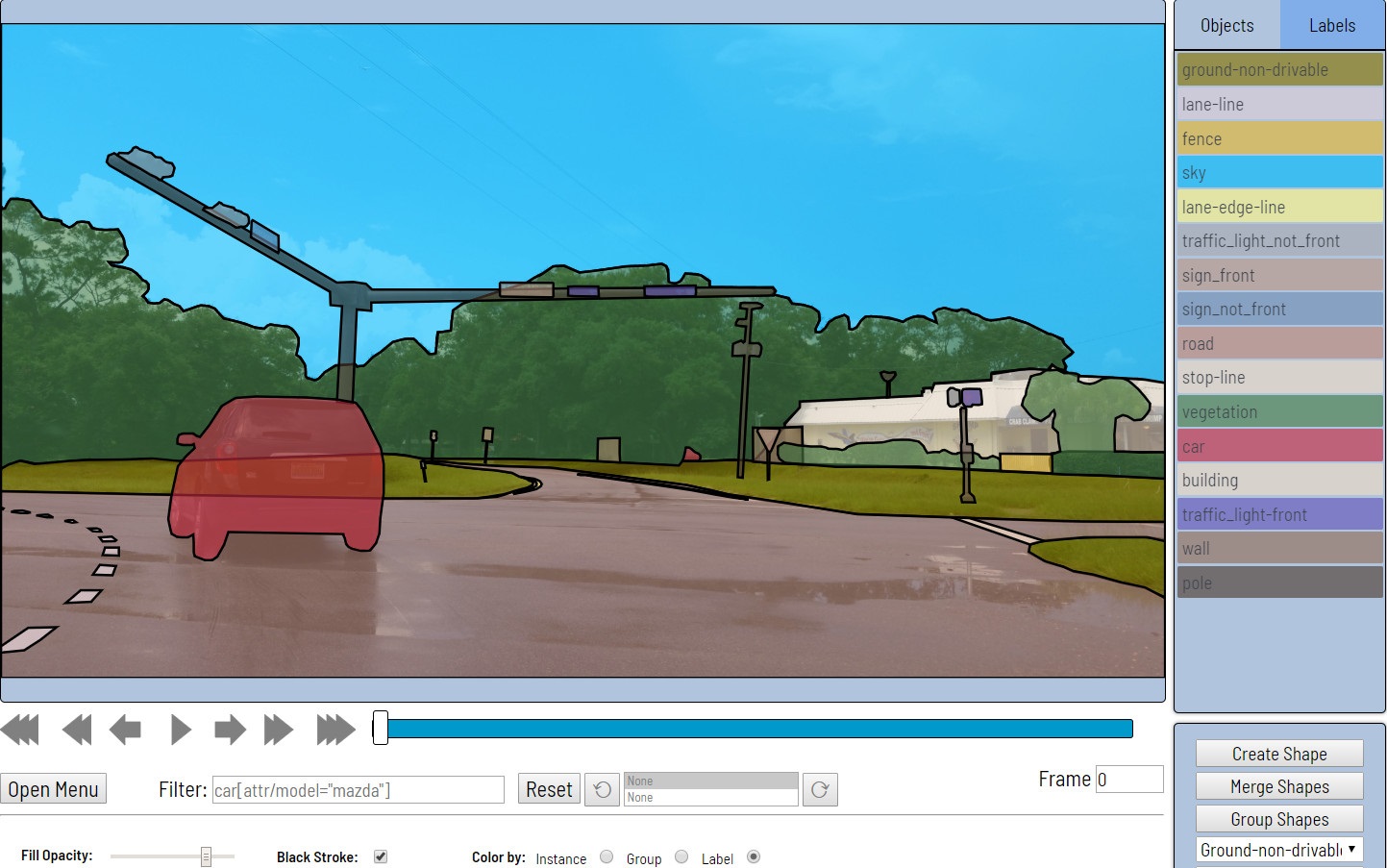
- Setelah memproses permintaan, tugas yang dibuat akan muncul di daftar tugas.

- Setiap tautan di bagian Pekerjaan sesuai dengan satu segmen. Dalam hal ini, tugas sebelumnya tidak tersegmentasi. Mengklik salah satu tautan membuka halaman markup.

- Selanjutnya, data langsung ditandai. Persegi panjang, poligon (terutama untuk tugas segmentasi), polyline (dapat berguna, misalnya, untuk marka jalan) dan banyak titik (misalnya, marka rambu wajah atau estimasi pose) disediakan sebagai primitif.
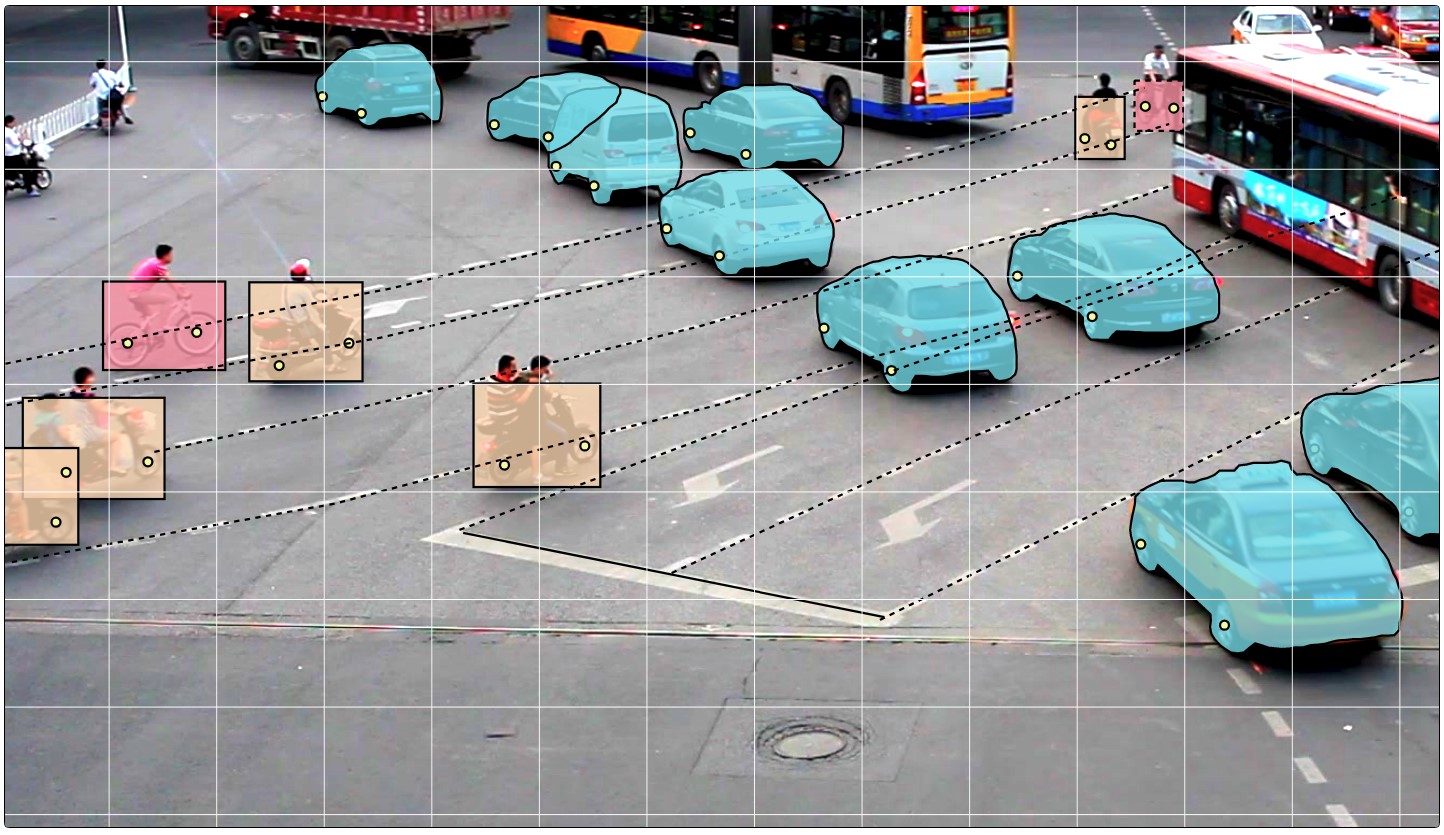
Berbagai alat otomatisasi juga tersedia (penyalinan, perkalian ke bingkai lain, interpolasi, penandaan awal dengan API TF OD), pengaturan visual, banyak hot key, pencarian, pemfilteran, dan fungsi berguna lainnya. Di jendela pengaturan, Anda dapat mengubah sejumlah parameter untuk pekerjaan yang lebih nyaman.
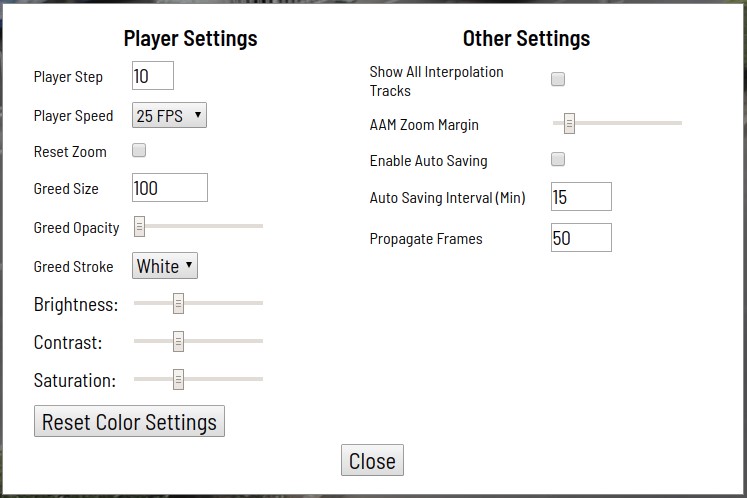
Kotak dialog bantuan berisi banyak pintasan keyboard yang didukung dan beberapa tips lainnya.

Proses markup dapat dilihat pada contoh di bawah ini.
CVAT secara linear dapat menginterpolasi persegi panjang dan atribut antara keyframe dalam video. Karena ini, anotasi pada set bingkai ditampilkan secara otomatis.
Mode Anotasi Atribut dikembangkan untuk skenario klasifikasi, yang memungkinkan Anda untuk mempercepat anotasi atribut dengan memfokuskan markup pada satu properti tertentu. Selain itu, markup di sini terjadi melalui penggunaan "hot keys".
Poligon mendukung segmentasi semantik dan skrip segmentasi instance. Pengaturan visual yang berbeda memfasilitasi proses validasi.
- Terima anotasi
Menekan tombol “Dump Annotation” memulai proses mempersiapkan dan memuat hasil markup sebagai satu file. File anotasi adalah file .xml yang ditentukan yang berisi beberapa metadata tugas dan seluruh anotasi. Markup dapat diunduh langsung ke repositori Git, jika yang terakhir terhubung pada tahap pembuatan tugas.
Sejarah dan evolusi
Pada awalnya, kami tidak memiliki penyatuan, dan setiap tugas markup dilakukan dengan alat sendiri, terutama ditulis dalam C ++ menggunakan
perpustakaan OpenCV . Alat-alat ini dipasang secara lokal pada mesin pengguna akhir, tidak ada mekanisme untuk berbagi data, saluran pipa umum untuk menetapkan dan menandai tugas, banyak hal harus dilakukan secara manual.
Titik awal sejarah CVAT dapat dianggap akhir tahun 2016, ketika
Vatic diperkenalkan sebagai alat tata letak, antarmuka yang disajikan di bawah ini. Vatic adalah open source dan memperkenalkan beberapa ide besar dan umum, seperti interpolasi markup antara keyframe dalam video atau arsitektur aplikasi client-server. Namun, secara umum, itu menyediakan fungsi markup yang agak sederhana, dan kami melakukan banyak pekerjaan sendiri.
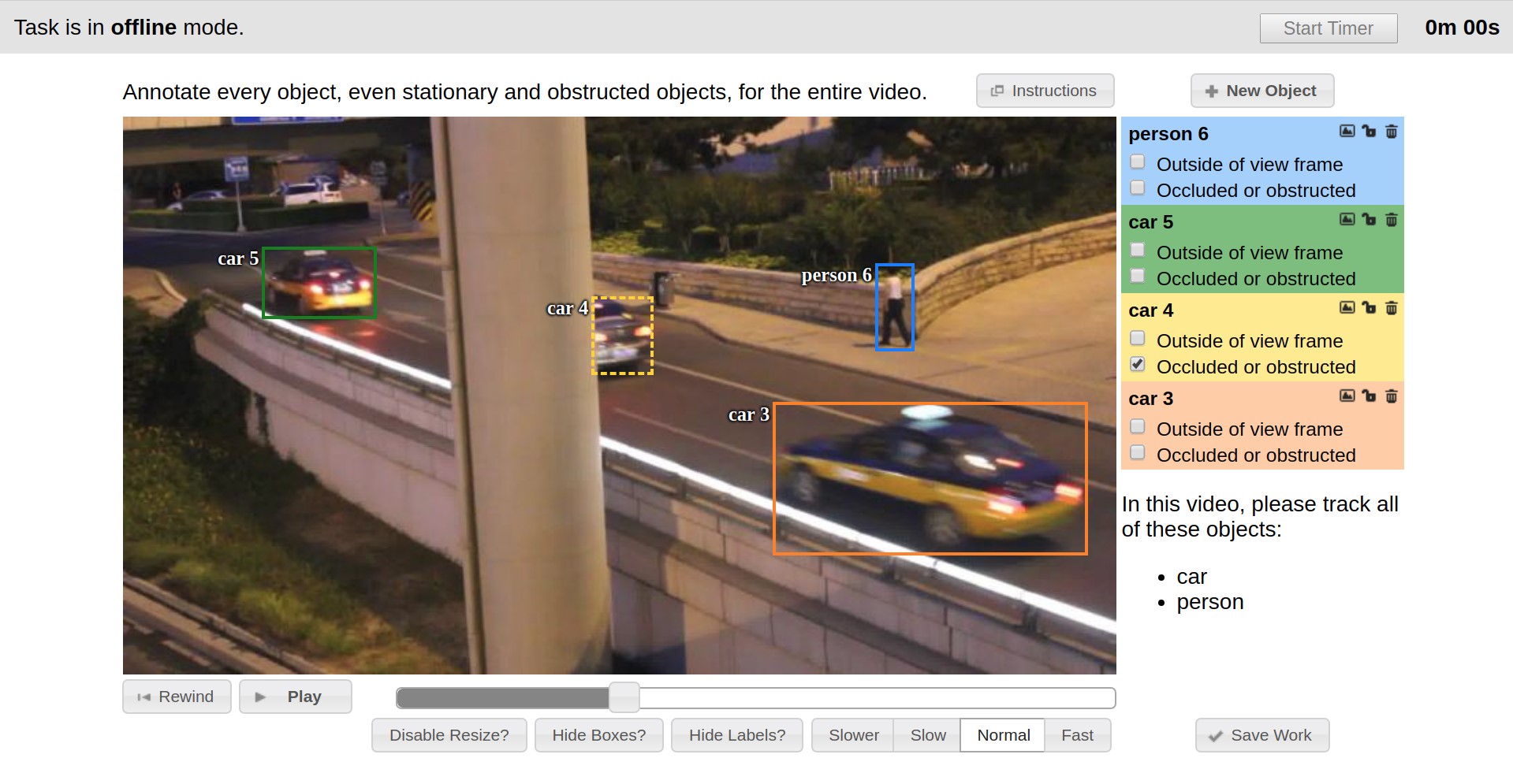
Jadi, misalnya, selama enam bulan pertama, kemampuan untuk membuat anotasi gambar diimplementasikan, atribut pengguna objek ditambahkan, halaman dikembangkan dengan daftar tugas yang ada dan kemampuan untuk menambahkan yang baru melalui antarmuka web.
Selama paruh kedua 2017, kami memperkenalkan Tensorflow Object Detection API sebagai metode untuk memperoleh markup awal. Ada banyak perbaikan kecil pada klien, tetapi pada akhirnya kami dihadapkan pada kenyataan bahwa bagian klien mulai bekerja sangat lambat. Faktanya adalah bahwa ukuran tugas meningkat, waktu pembukaannya meningkat secara proporsional dengan jumlah bingkai dan data yang ditandai, UI melambat karena presentasi yang tidak efisien dari objek yang ditandai, kemajuan sering hilang selama jam kerja. Produktivitas sebagian besar merosot pada tugas dengan gambar, karena fondasi arsitektur pada waktu itu pada awalnya dirancang untuk bekerja dengan video. Ada kebutuhan untuk perubahan lengkap dalam arsitektur klien, yang berhasil kami atasi. Sebagian besar masalah kinerja pada waktu itu hilang. Antarmuka web menjadi lebih cepat dan lebih stabil. Memberi tugas yang lebih besar menjadi mungkin. Pada periode yang sama, ada upaya untuk memperkenalkan pengujian unit untuk menyediakan, sampai batas tertentu, otomatisasi pemeriksaan selama perubahan. Tugas ini belum diselesaikan dengan sukses. Kami mengonfigurasi QUnit, Karma, Chrome Tanpa Kepala di wadah Docker, menulis beberapa tes, meluncurkan semua ini di CI. Namun, sebagian besar kode tetap, dan masih tetap, terungkap oleh tes. Inovasi lain adalah sistem tindakan pengguna logging dengan pencarian dan visualisasi selanjutnya berdasarkan ELK Stack. Ini memungkinkan Anda untuk memantau proses annotator dan mencari skenario tindakan yang mengarah pada pengecualian perangkat lunak.
Pada paruh pertama tahun 2018, kami memperluas fungsionalitas klien kami. Mode Anotasi Atribut ditambahkan, yang mengimplementasikan skrip yang efektif untuk menandai atribut, gagasan yang kami pinjam dari kolega dan digeneralisasi; Sekarang Anda dapat memfilter objek berdasarkan sejumlah tanda, menghubungkan penyimpanan umum untuk mengunduh data saat mengatur tugas dengan melihatnya melalui browser, dan banyak lainnya. Tugas menjadi lebih banyak dan masalah kinerja mulai muncul lagi, tetapi kali ini bagian server yang menjadi hambatan. Masalah dengan Vatic adalah bahwa ia berisi banyak kode yang ditulis sendiri untuk tugas-tugas yang dapat lebih mudah dan efisien diselesaikan menggunakan solusi yang sudah jadi. Jadi kami memutuskan untuk mengulangi sisi server. Kami memilih Django sebagai kerangka kerja server, sebagian besar karena popularitasnya dan ketersediaan banyak hal, seperti yang mereka katakan, di luar kotak. Setelah perubahan bagian server, ketika tidak ada yang tersisa dari Vatic, kami memutuskan bahwa kami telah melakukan banyak pekerjaan, yang dapat dibagikan dengan komunitas. Jadi diputuskan untuk pergi ke open source. Mendapatkan izin untuk ini di dalam perusahaan besar adalah proses yang agak sulit. Ada daftar besar persyaratan untuk ini. Termasuk, perlu untuk membuat nama. Kami membuat sketsa opsi dan melakukan serangkaian survei di antara rekan-rekan. Akibatnya, alat internal kami bernama CVAT, dan pada 29 Juni 2018, kode sumber diterbitkan di
GitHub di organisasi OpenCV di bawah lisensi MIT dan dengan versi awal 0.1.0. Pengembangan lebih lanjut terjadi di repositori publik.
Pada akhir September 2018, versi utama 0.2.0 dirilis. Ada banyak perubahan dan perbaikan kecil, tetapi fokus utamanya adalah mendukung jenis-jenis anotasi baru. Jadi, sejumlah alat untuk menandai dan memvalidasi segmentasi muncul, serta kemampuan untuk membuat anotasi dengan polyline atau titik.
Rilis berikutnya, seperti hadiah Natal, dijadwalkan untuk 31 Desember 2018. Poin yang paling signifikan di sini adalah integrasi opsional dari Deep Learning Deployment Toolkit sebagai bagian dari OpenVINO, yang digunakan untuk mempercepat peluncuran TF OD API tanpa adanya kartu grafis NVIDIA; sistem analisis log pengguna yang sebelumnya tidak tersedia dalam versi publik; banyak perbaikan di sisi klien.
Kami telah meringkas sejarah CVAT hingga saat ini (Desember 2018) dan meninjau peristiwa yang paling signifikan. Anda selalu dapat membaca lebih lanjut tentang riwayat perubahan di
changelog .
Perangkat internal
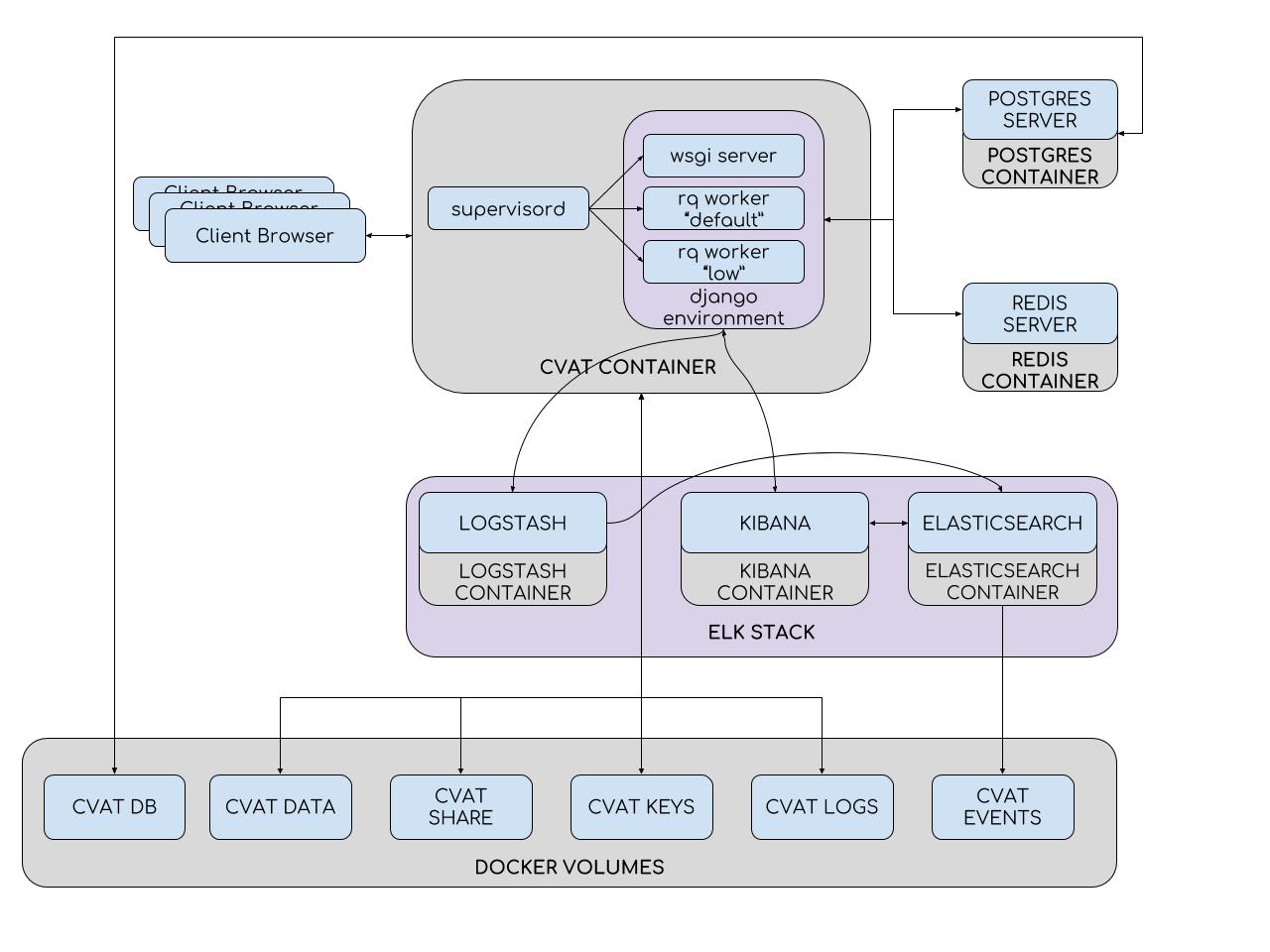
Untuk menyederhanakan instalasi dan penyebaran, CVAT menggunakan wadah Docker. Sistem ini terdiri dari beberapa wadah. Proses pengawas dijalankan dalam wadah CVAT, yang memunculkan beberapa proses Python di lingkungan Django. Salah satunya adalah server wsgi, yang menangani permintaan klien. Proses lain, pekerja rq, digunakan untuk memproses tugas "panjang" dari antrian Redis: default dan rendah. Tugas tersebut termasuk yang tidak dapat diproses dalam permintaan pengguna tunggal (mengatur tugas, menyiapkan file penjelasan, markup dengan TF OD API, dan lainnya). Jumlah pekerja dapat dikonfigurasi dalam file konfigurasi pengawas.
Lingkungan Django berinteraksi dengan dua server basis data. Server Redis menyimpan status antrian tugas, dan basis data CVAT berisi semua informasi tentang tugas, pengguna, anotasi, dll. PostgreSQL (dan SQLite 3 sedang dikembangkan) digunakan sebagai DBMS untuk CVAT. Semua data disimpan pada partisi pluggable (volume cvat db). Bagian digunakan jika perlu untuk menghindari kehilangan data saat memperbarui wadah. Dengan demikian, berikut ini dipasang di wadah CVAT:
- Bagian dengan video dan gambar (volume data cvat)
- Bagian dengan kunci (volume tombol cvat)
- Bagian dengan log (volume log cvat)
- Penyimpanan file bersama (cvat volume bersama)
Sistem analisis terdiri dari Elasticsearch, Logstash, dan Kibana yang dibungkus dalam wadah Docker. Saat menyimpan pekerjaan pada klien, semua data, termasuk log, ditransfer ke server. Server, pada gilirannya, mengirimkannya ke Logstash untuk disaring. Selain itu, ada kemampuan untuk mengirim notifikasi secara otomatis ke email ketika ada kesalahan. Selanjutnya, log masuk ke dalam Elasticsearch. Yang terakhir menyimpannya di partisi pluggable (volume acara cvat). Kemudian, pengguna dapat menggunakan antarmuka Kibana untuk melihat statistik dan log. Pada saat yang sama, Kibana akan secara aktif berinteraksi dengan Elasticsearch.
Pada level sumber, CVAT terdiri dari banyak aplikasi Django:
- otentikasi - otentikasi pengguna dalam sistem (dasar dan LDAP)
- engine - aplikasi utama (model basis data dasar; tugas bongkar dan muat; memuat dan menurunkan anotasi; antarmuka klien markup; antarmuka server untuk membuat, mengubah, dan menghapus tugas)
- dashboard - antarmuka klien untuk membuat, mengedit, mencari, dan menghapus tugas
- dokumentasi - tampilan dokumentasi pengguna di antarmuka klien
- tf_annotation - anotasi otomatis dengan Tensorflow Object Detection API
- log_viewer - mengirim log dari klien ke Logstash saat menyimpan tugas
- log_proxy - koneksi proxy CVAT → Kibana
- git - Integrasi repositori Git untuk menyimpan anotasi
Kami berusaha keras untuk membuat proyek dengan struktur yang fleksibel. Karena alasan ini, aplikasi opsional tidak memiliki penyisipan hardcode. Sayangnya, sementara kami tidak memiliki prototipe ideal dari sistem plug-in, tetapi secara bertahap, dengan pengembangan aplikasi baru, situasi di sini membaik.
Bagian klien diimplementasikan pada JavaScript dan template Django. JavaScript , , - ( ) model-view-controller. , (, , ) , . ( - UI), (, , : , , models, views controllers).
open source, . , . . , CVAT. , , . :
- CVAT , , , , . UI .
- . , .
- , . , .
- . deep learning , . , Deep Learning Deployment Toolkit OpenVINO - . , . , .
- demo- CVAT, , , . demo- Onepanel, CVAT .
- Amazon Mechanical Turk CVAT . SDK .
, . , , . open source . – , .
, PR . , ,
Gitter . , ! !
Referensi