
Dalam artikel sebelumnya, saya mencoba berbicara tentang dasar-dasar penetapan harga dan membangun pohon keputusan pelanggan untuk ritel klasik. Dalam artikel ini saya akan memberi tahu Anda tentang kasus yang sangat tidak standar dan mencoba meyakinkan Anda bahwa menggunakan pembelajaran mesin tidak sesulit kelihatannya. Artikel ini kurang teknis dan lebih cenderung menunjukkan bahwa Anda dapat memulai dari yang kecil dan ini sudah akan membawa manfaat nyata bagi bisnis.
Masalah awal
Ada rantai toko di benua kami yang mengubah bermacam-macamnya seminggu sekali, misalnya, pertama-tama menjual overlock dan kemudian pakaian olahraga pria. Semua barang yang tidak terjual dikirim ke gudang dan enam bulan kemudian dikembalikan ke toko lagi. Pada saat yang sama, toko memiliki sekitar 6 kategori barang yang berbeda. Yaitu Bermacam-macam toko untuk setiap minggu adalah sebagai berikut:
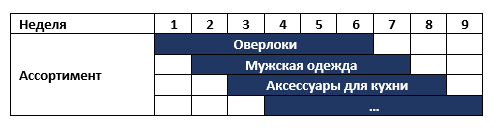
Jaringan meminta sistem perencanaan rentang dengan prasyarat untuk dukungan keputusan analitis untuk manajer kategori. Setelah berbicara dengan bisnis, kami mengusulkan dua solusi potensial yang sangat cepat yang dapat memberikan hasil ketika sistem perencanaan sedang digunakan:
- penjualan barang yang tidak dijual selama penjualan utama
- meningkatkan akurasi permintaan perkiraan di toko
Poin pertama pelanggan tidak puas - perusahaan bangga karena tidak mengatur penjualan dan mempertahankan tingkat margin yang konstan. Pada saat yang sama, sejumlah besar uang dihabiskan untuk logistik dan penyimpanan barang. Akibatnya, diputuskan untuk meningkatkan akurasi perkiraan permintaan untuk distribusi yang lebih akurat dari toko dan gudang.
Proses saat ini
Karena sifat bisnis, setiap produk individu tidak dijual untuk waktu yang lama dan bermasalah untuk mendapatkan cukup sejarah untuk analisis klasik. Proses peramalan saat ini sangat sederhana dan disusun sebagai berikut - beberapa minggu sebelum dimulainya penjualan utama di sebagian kecil dari tes penjualan toko dimulai. Berdasarkan hasil penjualan tes, keputusan dibuat untuk memperkenalkan barang ke seluruh jaringan dan diasumsikan bahwa setiap toko akan menjual rata-rata sebanyak itu dijual di toko tes.
Mendarat ke pelanggan, kami menganalisis data saat ini, menyadari apa yang terjadi, dan mengusulkan solusi yang sangat sederhana untuk meningkatkan akurasi perkiraan.
Menganalisis data
Dari data kami diberikan:
- Riwayat transaksi selama 1 tahun dan 2 bulan
- Hirarki produk untuk perencanaan. Sayangnya, itu hampir sepenuhnya tidak memiliki atribut barang, tetapi lebih pada itu nanti
- Informasi tentang kisaran dan harga untuk minggu-minggu tertentu
- Informasi tentang kota-kota di mana toko-toko berada
Kami tidak dapat membongkar informasi tentang saldo dalam waktu singkat, yang sangat penting dalam analisis semacam ini (jika Anda tidak menyimpan informasi ini, mulailah), oleh karena itu, di masa depan kami menggunakan asumsi bahwa barang ada di rak dan tidak ada kekurangan barang.
Kami segera memisahkan 2 bulan menjadi sampel uji untuk menunjukkan hasilnya. Lalu kami menggabungkan semua data yang tersedia menjadi satu showcase besar, membersihkannya dari pengembalian dan penjualan aneh (misalnya, jumlah dalam cek adalah 0,51 per potong barang). Butuh beberapa hari. Setelah menyiapkan etalase, kami melihat penjualan barang [unit] di tingkat tertinggi dan melihat gambar berikut:
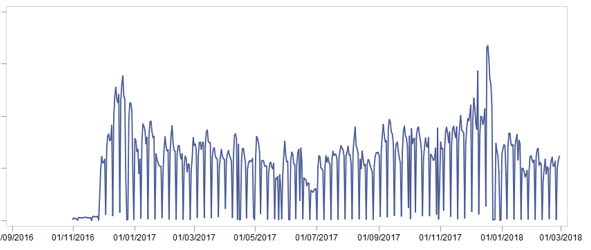
Bagaimana gambar ini dapat membantu kita? .. Tetapi dengan apa:
- Jelas, ada musim - penjualan di akhir tahun lebih tinggi daripada di tengah
- Ada musim dalam satu bulan - di tengah bulan, penjualan lebih tinggi daripada di awal dan di akhir
- Ada musim dalam seminggu - itu tidak begitu menarik, karena sebagai hasilnya, ramalan itu dibuat beberapa minggu
Item yang dijelaskan mengkonfirmasi bisnis. Tapi ini juga fitur hebat untuk meningkatkan ramalan! Sebelum menambahkannya ke model peramalan, mari kita pikirkan fitur penjualan apa lagi yang harus diperhitungkan ... Gagasan "jelas" muncul di benak saya:
- Penjualan bervariasi rata-rata di antara berbagai kelompok produk
- Penjualan bervariasi di antara berbagai toko
- (Mirip dengan paragraf sebelumnya) Penjualan bervariasi di antara berbagai kota
- (Gagasan yang kurang jelas) karena kekhasan bisnisnya, hubungan berikut ini terlihat: jika bermacam-macam masa depan dan sebelumnya serupa, maka penjualan bermacam-macam yang baru akan lebih rendah.
Kami memutuskan untuk berhenti dan membangun model.
Sebagai bagian dari konstruksi model, semua fitur yang ditemukan diterjemahkan ke dalam "fitur" model. Berikut adalah daftar fitur yang digunakan sebagai hasilnya:
- perkiraan saat ini yaitu rata-rata penjualan toko tes di [unit] didistribusikan ke semua toko
- nomor bulan dan jumlah minggu di bulan
- semua variabel kategori (kota, toko, kategori produk) dikodekan menggunakan kemungkinan dihaluskan (teknik berguna - siapa pun yang belum menggunakannya, gunakan itu)
- dihitung lag 4 rata-rata penjualan kategori produk. Yaitu jika perusahaan berencana untuk menjual T-shirt biru, maka lag penjualan rata-rata dari kategori T-shirt dihitung
ABT ternyata sederhana, setiap parameter dapat dipahami oleh bisnis dan tidak menyebabkan kesalahpahaman atau penolakan. Maka perlu dipahami bagaimana kita akan membandingkan kualitas perkiraan.
Pemilihan Metrik
Pelanggan mengukur akurasi perkiraan saat ini menggunakan metrik MAPE . Metrik ini populer dan sederhana, tetapi memiliki kelemahan tertentu dalam hal perkiraan permintaan. Faktanya adalah bahwa ketika menggunakan MAPE, kesalahan jenis perkiraan memiliki dampak terbesar pada indikator akhir:

Kesalahan perkiraan relatif 900% - sepertinya besar, tapi mari kita lihat penjualan produk lain:

Kesalahan perkiraan relatif adalah 33%, yang jauh lebih kecil dari 900%, tetapi penyimpangan absolut dari penyimpangan 100 [unit] jauh lebih penting bagi bisnis daripada penyimpangan 18 [unit]. Untuk mempertimbangkan fitur-fitur ini, Anda dapat membuat langkah-langkah menarik Anda sendiri, atau Anda dapat menggunakan ukuran populer lainnya dalam memperkirakan permintaan - WAPE . Ukuran ini memberi bobot lebih pada barang dengan penjualan lebih tinggi, yang bagus untuk tugas itu.
Kami memberi tahu perusahaan tentang berbagai pendekatan untuk mengukur kesalahan perkiraan, dan pelanggan dengan senang hati setuju bahwa menggunakan WAPE dalam tugas ini lebih masuk akal. Setelah itu, kami meluncurkan Random Forest hampir tanpa menyetel parameter hiper dan mendapatkan hasil berikut.
Hasil
Setelah memperkirakan periode pengujian, kami membandingkan nilai yang diprediksi dengan yang sebenarnya, serta dengan perkiraan perusahaan. Akibatnya, MAPE menurun lebih dari 15%, WAPE lebih dari 10% . Setelah menghitung dampak perkiraan yang membaik pada indikator bisnis, diperoleh pengurangan biaya dengan jumlah jutaan dolar yang agak besar.
1 minggu dihabiskan untuk semua pekerjaan!
Langkah selanjutnya
Sebagai bonus untuk pelanggan, kami melakukan percobaan DQ kecil. Untuk satu grup produk, dari nama produk, kami menguraikan karakteristik (warna, jenis produk, komposisi, dll.) Dan menambahkannya ke perkiraan. Hasilnya menginspirasi - dalam kategori ini, kedua ukuran kesalahan meningkatkan tambahan lebih dari 8%.
Akibatnya, pelanggan diberi deskripsi masing-masing fitur, parameter model, parameter perakitan ABT-showcase dan menjelaskan langkah-langkah lebih lanjut untuk meningkatkan perkiraan (menggunakan data historis selama lebih dari satu tahun; gunakan saldo; gunakan karakteristik barang, dll.).
Kesimpulan
Selama satu minggu kolaborasi dengan pelanggan, dimungkinkan untuk meningkatkan akurasi perkiraan secara signifikan, sementara secara praktis tidak mengubah proses bisnis.
Tentunya banyak orang sekarang berpikir bahwa kasus ini sangat sederhana dan mereka tidak bisa lepas dengan pendekatan ini di perusahaan. Pengalaman menunjukkan bahwa hampir selalu ada tempat di mana hanya asumsi dasar dan pendapat ahli yang digunakan. Dari tempat-tempat ini Anda dapat mulai menggunakan pembelajaran mesin. Untuk melakukan ini, Anda perlu mempersiapkan dan mempelajari data dengan cermat, berbicara dengan bisnis dan mencoba menerapkan model-model populer yang tidak memerlukan penyetelan panjang. Dan fitur susun, penyematan, model kompleks - itu saja untuk nanti. Saya harap saya meyakinkan Anda bahwa itu tidak sesulit kelihatannya, Anda hanya perlu berpikir sedikit dan tidak takut untuk memulai.
Jangan takut dengan pembelajaran mesin, cari tempat-tempat yang dapat digunakan dalam proses, jangan takut untuk meneliti data Anda dan biarkan konsultan datang kepada mereka dan mendapatkan hasil yang keren.
PS Kami sedang merekrut siswa pelajar Padawan muda untuk magang ritel di bawah bimbingan Jedi yang berpengalaman. Untuk memulai, akal sehat dan pengetahuan SQL sudah cukup, kami akan mengajarkan sisanya. Anda dapat berkembang menjadi pakar bisnis atau konsultan teknis, mana yang lebih menarik. Jika ada minat atau rekomendasi - tulis secara pribadi