"
Perusahaan " - operator telekomunikasi PJSC "Megafon"
"
Noda " adalah server RabbitMQ.
"
Cluster " adalah kombinasi, dalam kasus kami tiga, node RabbitMQ bekerja secara keseluruhan.
"
Contour " - satu set cluster RabbitMQ, aturan untuk bekerja dengan yang ditentukan pada penyeimbang di depan mereka.
"
Balancer ", "
hap " - Haproxy - balancer yang melakukan fungsi pengalihan beban pada kluster dalam loop. Sepasang server Haproxy yang berjalan secara paralel digunakan untuk setiap loop.
"
Subsistem " - penerbit dan / atau konsumen pesan yang dikirim melalui kelinci
"
SYSTEM " - satu set Subsystems, yang merupakan solusi perangkat lunak dan perangkat keras tunggal yang digunakan oleh Perusahaan, dicirikan oleh distribusinya di seluruh Rusia, tetapi dengan beberapa pusat di mana semua informasi mengalir dan tempat kalkulasi dan perhitungan utama berlangsung.
SISTEM - sistem yang didistribusikan secara geografis - dari Khabarovsk dan Vladivostok ke St. Petersburg dan Krasnodar. Secara arsitektur, ini adalah beberapa Kontur pusat, dibagi oleh fitur-fitur subsistem yang terhubung dengannya.
Apa tugas transportasi dalam realitas telekomunikasi?
Singkatnya: respons Subsistem terhadap tindakan setiap pelanggan mengikuti, yang pada gilirannya menginformasikan Subsistem lainnya tentang peristiwa dan perubahan selanjutnya. Pesan dihasilkan oleh tindakan apa pun dengan SISTEM, tidak hanya dari pelanggan, tetapi juga dari sisi karyawan Perusahaan, dan dari Subsistem (sejumlah besar tugas dilakukan secara otomatis).
Fitur-fitur transportasi dalam telekomunikasi: aliran besar, beragam data yang besar ditransmisikan melalui transportasi asinkron.
Beberapa Subsistem hidup di Cluster terpisah karena beratnya aliran pesan - tidak ada sumber daya yang tersisa di cluster, misalnya, dengan aliran pesan 5-6 ribu pesan / detik, jumlah data yang ditransfer dapat mencapai 170-190 Megabita / detik. Dengan profil beban seperti itu, upaya untuk mendaratkan orang lain di kluster ini akan menimbulkan konsekuensi yang menyedihkan: karena tidak ada sumber daya yang cukup untuk memproses semua data pada saat yang sama, kelinci akan mulai mendorong koneksi masuk ke
aliran - proses penerbitan sederhana akan dimulai, dengan semua konsekuensi untuk semua Subsistem dan SISTEM di utuh
Persyaratan dasar untuk transportasi:
- Aksesibilitas kendaraan harus 99,99%. Dalam praktiknya, ini diterjemahkan ke dalam persyaratan operasional 24/7 dan kemampuan untuk secara otomatis menanggapi setiap situasi darurat.
- Keamanan data:% dari pesan yang hilang pada transportasi harus cenderung ke 0.
Misalnya, setelah melakukan panggilan, beberapa pesan berbeda terbang melalui transportasi asinkron. beberapa pesan ditujukan untuk subsistem yang hidup di sirkuit yang sama, dan beberapa pesan ditujukan untuk transmisi ke simpul pusat. Pesan yang sama dapat diklaim oleh beberapa subsistem, oleh karena itu, pada tahap publikasi pesan pada kelinci, itu disalin dan dikirim ke konsumen yang berbeda. Dan dalam beberapa kasus, menyalin pesan secara wajib diimplementasikan pada sirkuit perantara - ketika informasi perlu dikirim dari sirkuit di Khabarovsk ke sirkuit di Krasnodar. Transmisi dilakukan melalui salah satu Kontur pusat, tempat salinan pesan dibuat, untuk penerima pusat.
Selain peristiwa yang disebabkan oleh tindakan pelanggan, pesan layanan yang menukar Subsistem melalui transportasi. Dengan demikian, beberapa ribu rute perpesanan yang berbeda diperoleh, sebagian berpotongan, beberapa ada dalam isolasi. Cukup untuk menyebutkan jumlah antrian yang terlibat dalam rute pada Kontur yang berbeda untuk memahami skala perkiraan peta pengangkutan: Di sirkuit pusat 600, 200, 260, 15 ... dan di Sirkuit jauh 80-100 ...
Dengan keterlibatan transportasi seperti itu, persyaratan untuk aksesibilitas 100% dari semua simpul transportasi tidak lagi tampak berlebihan. Kami beralih ke penerapan persyaratan ini.
Bagaimana kita menyelesaikan tugas
Selain
RabbitMQ itu sendiri ,
Haproxy digunakan untuk menyeimbangkan beban dan memberikan respons otomatis terhadap keadaan darurat.
Beberapa kata tentang lingkungan perangkat keras dan lunak tempat kelinci kita ada:
- Semua server kelinci adalah virtual, dengan parameter 8-12 CPU, 16 Gb Mem, 200 Gb HDD. Seperti yang ditunjukkan oleh pengalaman, bahkan penggunaan server non-virtual menyeramkan dengan 90 core dan banyak RAM memberikan peningkatan kinerja kecil dengan biaya yang jauh lebih tinggi. Versi yang digunakan: 3.6.6 (dalam praktiknya - paling stabil dari 3.6) dengan erlang 18.3, 3.7.6 dengan erlang 20.1.
- Untuk Haproxy, persyaratannya jauh lebih rendah: 2 CPU, 4 Gb Mem, versi haproxy stabil 1,8. Beban sumber daya di semua server haproxy tidak melebihi 15% CPU / Mem.
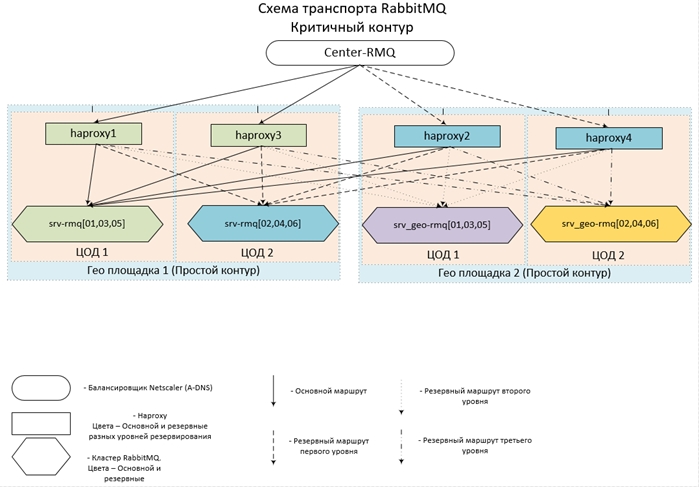
- Seluruh kebun binatang terletak di 14 pusat data di 7 situs di seluruh negeri, disatukan dalam satu jaringan. Di setiap pusat data ada sekelompok tiga node dan satu hub.
- Untuk sirkuit jarak jauh, 2 pusat data digunakan, untuk masing-masing sirkuit pusat - 4.
- Sirkuit Pusat berinteraksi satu sama lain serta dengan Sirkuit jarak jauh, pada gilirannya, Sirkuit jarak jauh hanya bekerja dengan Sirkuit pusat, mereka tidak memiliki komunikasi langsung satu sama lain.
- Konfigurasi Haps dan Cluster dalam Sirkuit yang sama benar-benar identik. Titik masuk untuk setiap sirkuit adalah alias untuk beberapa catatan A-DNS. Dengan demikian, untuk mencegah hal ini terjadi, setidaknya satu hap dan setidaknya satu dari Cluster (setidaknya satu node dalam Cluster) di setiap Sirkuit akan tersedia. Karena kasus kegagalan bahkan 6 server di dua pusat data pada saat yang sama sangat tidak mungkin, penerimaan dianggap mendekati 100%.
Ini terlihat dikandung (dan diimplementasikan) semua ini seperti ini:

Sekarang beberapa konfigurasi.
Konfigurasi haproxy| frontend center-rmq_5672 | |
| mengikat | *: 5672 |
| mode | tcp |
| maxconn | 10.000 |
| klien timeout | 3j |
| opsi | tcpka |
| opsi | tcplog |
| default_backend | center-rmq_5672 |
| frontend center-rmq_5672_lvl_1 | |
| mengikat | localhost: 56721 |
| mode | tcp |
| maxconn | 10.000 |
| klien timeout | 3j |
| opsi | tcpka |
| opsi | tcplog |
| default_backend | center-rmq_5672_lvl_1 |
| backend center-rmq_5672 |
| keseimbangan | lessconn |
| mode | tcp |
| fullconn | 10.000 |
| batas waktu | server 3j |
| server | srv-rmq01 10/10/10/10/106767 periksa kenaikan antar 5 naik 2 jatuh 3 pada sesi shutdown-backup-sesi yang ditandai |
| server | srv-rmq03 10/10/10/2011 11672 periksa kenaikan antar 5 naik 2 jatuh 3 pada sesi shutdown-backup-sesi yang ditandai |
| server | srv-rmq05 10/10/10/126767 periksa kenaikan antar 5 naik 2 jatuh 3 pada sesi shutdown-backup-sesi yang ditandai |
| server | localhost 127.0.0.1 ∗ 6721 periksa antar 5 naik 2 jatuh 3 cadangan on-ditandai-down shutdown-sesi |
| backend center-rmq_5672_lvl_1 |
| keseimbangan | lessconn |
| mode | tcp |
| fullconn | 10.000 |
| batas waktu | server 3j |
| server | srv-rmq02 10/10/10/136767 periksa kenaikan antar 5 naik 2 jatuh 3 pada sesi shutdown-backup-sesi yang ditandai |
| server | srv-rmq04 10/10/10/14/1067 periksa kenaikan antar 5 naik 2 jatuh 3 pada sesi shutdown-backup-sesi yang ditandai |
| server | srv-rmq06 10.10.10.5:0767 periksa kenaikan antar 5 naik 2 jatuh 3 sesi shutdown-backup-cadangan |
Bagian pertama dari bagian depan menjelaskan titik masuk - mengarah ke kelompok utama, bagian kedua dirancang untuk menyeimbangkan tingkat cadangan. Jika Anda cukup menggambarkan semua server kelinci cadangan di bagian backend (instruksi cadangan), itu akan bekerja dengan cara yang sama - jika cluster utama benar-benar tidak dapat diakses, koneksi akan pergi ke yang cadangan, namun, semua koneksi akan pergi ke server cadangan PERTAMA dalam daftar. Untuk memastikan load balancing pada semua node cadangan, kami hanya memperkenalkan satu front lagi, yang kami sediakan hanya dengan localhost, dan kami menetapkannya sebagai server cadangan.
Contoh di atas menjelaskan penyeimbangan Loop jarak jauh - yang beroperasi dalam dua pusat data: server srv-rmq {01,03,05} - hidup di pusat data No. 1, srv-rmq {02,04,06} - di pusat data No. 2. Jadi, untuk mengimplementasikan solusi empat-coda, kita hanya perlu menambahkan dua front lokal dan dua bagian backend dari server kelinci yang sesuai.
Perilaku penyeimbang dengan konfigurasi ini adalah sebagai berikut: Sementara setidaknya satu server utama masih hidup, kami menggunakannya. Jika server utama tidak tersedia, kami bekerja dengan cadangan. Jika setidaknya satu server utama tersedia, semua koneksi ke server cadangan terputus dan, ketika koneksi dipulihkan, mereka sudah jatuh pada Cluster utama.
Pengalaman operasi konfigurasi seperti itu menunjukkan ketersediaan hampir 100% dari masing-masing sirkuit. Solusi ini mengharuskan Subsistem sepenuhnya legal dan sederhana: untuk dapat terhubung kembali dengan kelinci setelah memutuskan hubungan.
Jadi, kami telah menyediakan penyeimbangan muatan ke sejumlah Cluster yang sewenang-wenang dan secara otomatis beralih di antara mereka, sekarang saatnya untuk pergi langsung ke kelinci.
Setiap Cluster dibuat dari tiga node, seperti yang ditunjukkan oleh praktik - jumlah node paling optimal, yang memastikan keseimbangan ketersediaan / toleransi kesalahan / kecepatan yang optimal. Karena kelinci tidak menskala secara horizontal (kinerja cluster sama dengan kinerja server paling lambat), kami membuat semua node dengan parameter optimal yang sama untuk CPU / Mem / Hdd. Kami memposisikan server sedekat mungkin satu sama lain - dalam kasus kami, kami mengajukan mesin virtual di dalam lahan yang sama.
Adapun prasyarat, berikut yang pada bagian Subsistem akan memastikan operasi yang paling stabil dan pemenuhan persyaratan untuk menyimpan pesan yang diterima:
- Bekerja dengan kelinci hanya melalui protokol amqp / amqps - melalui penyeimbangan. Otorisasi di bawah akun lokal - dalam setiap cluster (well, dan seluruh sirkuit)
- Subsistem terhubung ke kelinci dalam mode pasif: Tidak ada manipulasi dengan entitas kelinci (pembuatan antrian / eschendzhey / bind) diizinkan dan dibatasi pada tingkat hak akun - kami hanya tidak memberikan hak untuk mengonfigurasi.
- Semua entitas yang diperlukan dibuat secara terpusat, bukan melalui Subsistem, dan pada semua Cluster Cluster dilakukan dengan cara yang sama - untuk memastikan peralihan otomatis ke Cluster cadangan dan sebaliknya. Kalau tidak, kita bisa mendapatkan gambar: kita beralih ke cadangan, tetapi antrian atau ikatan tidak ada, dan kita bisa mendapatkan pilihan kesalahan koneksi atau kehilangan pesan.
Sekarang pengaturan langsung pada kelinci:
- Host lokal tidak memiliki akses ke antarmuka web
- Akses ke Web diatur melalui LDAP - kami mengintegrasikan dengan AD dan mendapatkan pencatatan siapa dan ke mana saja pada webcam. Pada tingkat konfigurasi, kami membatasi hak akun AD, kami tidak hanya mengharuskan berada dalam grup tertentu, tetapi kami hanya memberikan hak untuk "melihat". Kelompok pemantau lebih dari cukup. Dan kami menggantungkan hak administrator pada grup lain dalam AD, sehingga lingkaran pengaruh pada transportasi sangat terbatas.
- Untuk memudahkan administrasi dan pelacakan:
Pada semua VHOST, kami segera menutup kebijakan level 0 dengan aplikasi ke semua antrian (pola :. *):
- ha-mode: all - menyimpan semua data pada semua node cluster, kecepatan pemrosesan pesan menurun, tetapi keamanan dan ketersediaannya dipastikan.
- ha-sync-mode: otomatis - menginstruksikan crawler untuk secara otomatis menyinkronkan data pada semua node cluster: keamanan dan ketersediaan data juga meningkat.
- queue-mode: lazy - mungkin salah satu opsi paling berguna yang telah muncul pada kelinci sejak versi 3.6 - rekaman langsung pesan pada HDD. Opsi ini secara dramatis mengurangi konsumsi RAM dan meningkatkan keamanan data selama berhenti / jatuh node atau cluster secara keseluruhan.
- Pengaturan dalam file konfigurasi ( rabbitmq-main / conf / rabbitmq.config ):
- Bagian kelinci : {vm_memory_high_watermark_paging_ratio, 0,5} - ambang untuk mengunduh pesan ke disk 50%. Dengan malas diaktifkan, itu berfungsi lebih sebagai asuransi ketika kita membuat kebijakan, misalnya, level 1, di mana kita lupa memasukkan malas .
- {vm_memory_high_watermark, 0.95} - kami membatasi kelinci hingga 95% dari total RAM, karena hanya kelinci yang hidup di server, tidak masuk akal untuk menerapkan pembatasan yang lebih ketat. 5% "isyarat luas" jadi - tinggalkan OS, pemantauan dan hal-hal kecil lainnya yang bermanfaat. Karena nilai ini adalah batas atas, ada cukup untuk semua orang.
- {cluster_partition_handling, pause_minority} - mendeskripsikan perilaku cluster ketika Partisi Jaringan terjadi, untuk tiga atau lebih cluster node flag ini disarankan - ini memungkinkan cluster untuk memulihkan dirinya sendiri.
- {disk_free_limit, "500MB"} - semuanya sederhana, ketika ada ruang kosong 500 MB - penerbitan pesan akan dihentikan, hanya pengurangan yang akan tersedia.
- {auth_backends, [rabbit_auth_backend_internal, rabbit_auth_backend_ldap]} - pesanan otorisasi untuk kelinci: Pertama, keberadaan USG dalam database lokal diperiksa, dan jika tidak, buka server LDAP.
- Bagian rabbitmq_auth_backend_ldap - konfigurasi interaksi dengan AD: {server, ["srv_dc1", "srv_dc2"]} - daftar pengontrol domain tempat otentikasi akan dilakukan.
- Parameter yang secara langsung menggambarkan pengguna dalam AD, port LDAP dan sebagainya adalah murni individu dan dijelaskan secara rinci dalam dokumentasi.
- Yang paling penting bagi kami adalah deskripsi tentang hak dan pembatasan administrasi dan akses ke antarmuka Web kelinci: tag_queries:
[{administrator, {in_group, "cn = rabbitmq-admin, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = ru"}},
{pemantauan,
{in_group, "cn = rabbitmq-web, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = ru"}
}] - desain ini memberikan hak administratif untuk semua pengguna grup rabbitmq-admin dan hak pemantauan (minimal memadai untuk melihat akses) untuk grup rabbitmq-web.
- resource_access_query :
{untuk,
[{izin, konfigurasikan, {in_group, "cn = rabbitmq-admin, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = ru"}},
{izin, tulis, {in_group, "cn = rabbitmq-admin, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = ru"}},
{izin, baca, {konstan, true}}
]
} - kami memberikan hak untuk mengonfigurasi dan menulis hanya ke grup administrator, kepada semua orang yang berhasil masuk, hak tersebut hanya untuk dibaca - dapat membaca pesan melalui antarmuka Web.
Kami mendapatkan kluster yang dikonfigurasi (pada tingkat file konfigurasi dan pengaturan di kelinci itu sendiri) yang memaksimalkan ketersediaan dan keamanan data. Dengan ini kami menerapkan persyaratan - memastikan ketersediaan dan keamanan data ... dalam banyak kasus.
Ada beberapa poin yang harus dipertimbangkan ketika mengoperasikan sistem yang sarat muatan:
- Lebih baik mengatur semua properti tambahan antrian (TTL, expire, max-length, dll) oleh politisi, daripada menggantung parameter saat membuat antrian. Ternyata struktur dapat disesuaikan secara fleksibel yang dapat disesuaikan dengan cepat untuk mengubah realitas.
- Menggunakan TTL. Semakin lama antrian, semakin tinggi beban pada CPU. Untuk mencegah "menerobos langit-langit" lebih baik untuk membatasi panjang antrian melalui max-length juga.
- Selain kelinci itu sendiri, sejumlah aplikasi utilitas berputar di server, yang, anehnya, juga membutuhkan sumber daya CPU. Kelinci rakus, secara default, mengambil semua kernel yang tersedia ... Situasi yang tidak menyenangkan mungkin berubah: perjuangan untuk sumber daya, yang dapat dengan mudah menyebabkan rem pada kelinci. Untuk menghindari terjadinya situasi seperti itu, misalnya, sebagai berikut: Ubah parameter peluncuran erlang - perkenalkan batas wajib pada jumlah core yang digunakan. Kami melakukan ini sebagai berikut: cari file rabbitmq-env , cari parameter SERVER_ERL_ARGS = dan tambahkan + sct L0-Xc0-X + SY: Y ke dalamnya. Di mana X adalah jumlah core-1 (penghitungan dimulai dari 0), Y - Jumlah core -1 (dihitung dari 1). + sct L0-Xc0-X - mengubah pengikatan ke kernel, + SY: Y - mengubah jumlah sheduler yang diluncurkan oleh erlang. Jadi untuk sistem 8 core, parameter yang ditambahkan akan berbentuk: + sct L0-6c0-6 + S 7: 7. Dengan cara ini, kami memberi kelinci hanya 7 core dan berharap bahwa OS, dengan meluncurkan proses lain, akan bertindak secara optimal dan menggantungnya pada kernel yang tidak dimuat.
Nuansa operasi kebun binatang yang dihasilkan
Apa pengaturan tidak dapat melindungi dari adalah mnesia runtuh basis - sayangnya, itu terjadi dengan probabilitas tidak nol. Hasil bencana seperti itu tidak disebabkan oleh kegagalan global (misalnya, kegagalan total seluruh pusat data - beban hanya akan beralih ke cluster lain), tetapi lebih banyak kegagalan lokal - dalam segmen jaringan yang sama.
Selain itu, kegagalan jaringan lokal yang menakutkan, karena shutdown darurat satu atau dua node tidak akan mengakibatkan konsekuensi fatal - hanya semua permintaan akan pergi ke satu node, dan seperti yang kita ingat, kinerja tergantung pada kinerja hanya node itu sendiri. Kegagalan jaringan (kami tidak memperhitungkan gangguan kecil dalam komunikasi - mereka mengalami tanpa rasa sakit) mengarah pada situasi di mana node memulai proses sinkronisasi satu sama lain dan kemudian koneksi terputus-putus selama beberapa detik.
Misalnya, beberapa berkedip jaringan, dan dengan frekuensi lebih dari 5 detik (batas waktu seperti itu diatur dalam pengaturan Hapov, Anda tentu dapat memainkannya, tetapi untuk memeriksa efektivitasnya, Anda perlu mengulangi kegagalan, yang tidak diinginkan).
Cluster masih bisa menahan satu atau dua iterasi seperti itu, tetapi lebih - kemungkinannya sudah minimal. Dalam situasi seperti itu, penghentian simpul yang jatuh dapat menyelamatkan, tetapi hampir mustahil untuk melakukannya secara manual. Lebih sering, hasilnya bukan hanya hilangnya node dari cluster dengan pesan
"Network Partition" , tetapi juga gambar ketika data pada bagian antrian tinggal hanya node ini dan tidak punya waktu untuk melakukan sinkronisasi dengan yang tersisa. Secara visual - dalam data antrian adalah
NaN .
Dan sekarang ini adalah sinyal yang tidak ambigu - beralih ke Cluster cadangan. Pergantian akan memberikan suatu hal, Anda hanya perlu menghentikan kelinci pada kluster utama - hitungan beberapa menit. Sebagai hasilnya, kami memperoleh pemulihan kapasitas kerja transportasi dan kami dapat melanjutkan dengan aman ke analisis kecelakaan dan eliminasi.
Untuk menghilangkan gugus yang rusak dari bawah beban, untuk mencegah degradasi lebih lanjut, hal yang paling sederhana adalah membuat kelinci bekerja di pelabuhan selain 5672. Karena kita memantau kelinci melalui pelabuhan biasa, perpindahannya, misalnya, oleh 5673 dalam pengaturan kelinci, itu akan memungkinkan Anda untuk sepenuhnya meluncurkan cluster tanpa rasa sakit dan mencoba untuk mengembalikan operabilitasnya dan pesan yang tersisa di dalamnya.
Kami melakukannya dalam beberapa langkah:
- Hentikan semua node cluster yang gagal - hap akan mengalihkan beban ke cluster cadangan
- RABBITMQ_NODE_PORT=5673 rabbitmq-env – , Web - 15672.
- .
Saat startup, indeks akan dibangun kembali, dan dalam sebagian besar kasus, semua data akan dipulihkan secara penuh. Sayangnya, crash terjadi karena Anda harus secara fisik menghapus semua pesan dari disk, hanya menyisakan konfigurasi - direktori msg_store_persistent , msg_store_transient , antrian (untuk versi 3.6) atau msg_stores (untuk versi 3.7) dihapus dalam folder dengan database .Setelah terapi radikal seperti itu, klaster diluncurkan dengan pelestarian struktur internal, tetapi tanpa pesan.Dan opsi yang paling tidak menyenangkan (hanya diamati sekali): Kerusakan pada pangkalan sedemikian rupa sehingga perlu untuk menghapus seluruh pangkalan dan membangun kembali cluster dari awal.Untuk kenyamanan mengelola dan memperbarui kelinci, tidak digunakan perakitan yang siap pakai dalam rpm, tetapi kelinci yang dibongkar dengan cpio dan dikonfigurasi ulang (mengubah jalur dalam skrip). Perbedaan utama: itu tidak memerlukan hak akses root untuk menginstal / mengkonfigurasi, tidak diinstal pada sistem (kelinci yang dibangun kembali dikemas dengan sempurna dalam tgz) dan dijalankan dari pengguna mana pun. Pendekatan ini memungkinkan Anda untuk meningkatkan versi secara fleksibel (jika tidak memerlukan penghentian penuh dari kluster - dalam hal ini, cukup beralih ke kluster cadangan dan perbarui, jangan lupa untuk menentukan port bergeser untuk operasi). Bahkan dimungkinkan untuk menjalankan beberapa instance RabbitMQ pada mesin yang sama - opsi ini sangat nyaman untuk pengujian - Anda dapat menggunakan salinan arsitektur yang berkurang dari kebun binatang pertempuran.Sebagai hasil dari perdukunan dengan cpio dan path dalam skrip, kami mendapatkan opsi build: dua folder rabbitmq-base (di majelis asli - folder mnesia) dan rabbimq-main - di sini saya meletakkan semua skrip yang diperlukan dari kelinci dan erlang itu sendiri.Di rabbimq-main / bin - symlink ke skrip kelinci dan erlang dan skrip pelacakan kelinci (deskripsi di bawah).Dalam rabbimq-main / init.d - skrip rabbitmq-server yang melaluinya log mulai / berhenti / berputar; di lib, kelinci itu sendiri; di lib64 - erlang (menggunakan stripped-down, hanya untuk kelinci, versi erlang).Sangat mudah untuk memperbarui perakitan yang dihasilkan ketika versi baru dirilis - tambahkan konten rabbimq-main / lib dan rabbimq-main / lib64 dari versi baru dan ganti symlink di bin. Jika pembaruan juga memengaruhi skrip kontrol - cukup ubah jalur ke skrip kami di dalamnya.Keuntungan signifikan dari pendekatan ini adalah kesinambungan versi yang lengkap - semua jalur, skrip, perintah kontrol tetap tidak berubah, yang memungkinkan Anda untuk menggunakan skrip utilitas yang ditulis sendiri tanpa doping untuk setiap versi.Sejak jatuhnya kelinci, meskipun jarang, tetapi terjadi, perlu untuk menerapkan mekanisme untuk memantau peningkatan kesehatan mereka dalam hal jatuh (sambil mempertahankan log alasan kejatuhan). Kegagalan node dalam 99% kasus disertai dengan entri log, bahkan membunuh jejak daun, ini memungkinkan untuk menerapkan pemantauan keadaan kelinci menggunakan skrip sederhana.Untuk versi 3.6 dan 3.7, skrip sedikit berbeda karena perbedaan dalam entri log.Untuk 3.7, hanya dua baris yang diubah if (os.path.isfile('/data/logs/rabbitmq/startup_log')) and (os.path.isfile('/data/logs/rabbitmq/startup_err')): if ((b' OK ' in LastRow('/data/logs/rabbitmq/startup_log')) or (b'FAILED' in LastRow('/data/logs/rabbitmq/startup_log'))) and not (b'Gracefully halting Erlang VM' in LastRow('/data/logs/rabbitmq/startup_err')):
Kami membuat akun crontab tempat kelinci akan bekerja (secara default rabbitmq) menjalankan skrip ini (nama skrip: check_and_run) setiap menit (pertama, kami meminta admin untuk memberikan akun hak untuk menggunakan crontab, tetapi jika kami memiliki hak root, kami melakukannya sendiri):
* / 1 * * * * ~ / rabbitmq-main / bin / check_and_runPoin kedua menggunakan kelinci yang dirakit ulang adalah rotasi log.
Karena kami tidak terikat dengan sistem logrotate, kami menggunakan fungsionalitas yang disediakan oleh pengembang: script
rabbitmq-server dari init.d (untuk versi 3.6)
Dengan membuat perubahan kecil ke
rotate_logs_rabbitmq ()Tambahkan:
find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.log.*.back -maxdepth 0 -type f | xargs -i gzip {} find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete
Hasil menjalankan skrip rabbitmq-server dengan kunci rotate-log: log dikompresi oleh gzip, dan disimpan hanya selama 30 hari terakhir.
http_api - path tempat kelinci meletakkan log http - dikonfigurasi dalam file konfigurasi:
{rabbitmq_management, [{rates_mode, detail}, {http_log_dir, path_to_logs / http_api "}]}Pada saat yang sama, saya memperhatikan
{rates_mode, detail } - opsi sedikit meningkatkan beban, tetapi memungkinkan Anda untuk melihat informasi tentang pengguna yang memposting pesan dalam EXCHENGE pada antarmuka WEB (dan karenanya melalui API). Informasi sangat diperlukan, karena semua koneksi melalui balancer - kita hanya akan melihat IP balancers itu sendiri. Dan jika Anda membuat teka-teki semua Subsistem yang berfungsi dengan kelinci sehingga mereka mengisi parameter properti Klien di properti koneksi mereka ke kelinci, maka akan mungkin untuk mendapatkan informasi terperinci pada tingkat koneksi siapa tepatnya, di mana dan dengan intensitas apa mempublikasikan pesan.
Dengan rilis versi baru 3.7, ada penolakan lengkap dari
skrip rabbimq-server di init.d. Untuk memfasilitasi operasi (keseragaman perintah kontrol terlepas dari versi kelinci) dan transisi yang lebih lancar antar versi, pada kelinci yang dirakit ulang kami terus menggunakan skrip ini. Yang benar adalah lagi: kami
akan sedikit mengubah
rotate_logs_rabbitmq () , karena mekanisme penamaan log setelah rotasi telah berubah di 3.7:
mv ${RABBITMQ_LOG_BASE}/$NODENAME.log.0 ${RABBITMQ_LOG_BASE}/$NODENAME.log.$(date +%Y%m%d-%H%M%S).back mv ${RABBITMQ_LOG_BASE}/$(echo $NODENAME)_upgrade.log.0 ${RABBITMQ_LOG_BASE}/$(echo $NODENAME)_upgrade.log.$(date +%Y%m%d-%H%M%S).back find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete
Sekarang tinggal menambahkan tugas untuk rotasi log ke crontab - misalnya, setiap hari di 23-00:
00 23 * * * ~ / rabbitmq-main / init.d / rabbitmq-server rotate-logMari kita beralih ke tugas-tugas yang perlu diselesaikan dalam rangka pengoperasian "peternakan kelinci":
- Manipulasi dengan entitas kelinci - pembuatan / penghapusan entitas kelinci: ekschendzhey, antrian, ikatan, sekop, pengguna, kebijakan. Dan untuk melakukan ini benar-benar identik pada semua Cluster Cluster.
- Setelah beralih ke / dari Cluster cadangan, diperlukan untuk mentransfer pesan yang tetap di sana ke Cluster saat ini.
- Membuat salinan cadangan dari konfigurasi semua Cluster semua Sirkuit
- Sinkronisasi penuh konfigurasi Cluster dalam Contour
- Hentikan / mulai kelinci
- Untuk menganalisis aliran data saat ini: lakukan semua pesan pergi dan jika mereka pergi, lalu ke mana mereka pergi atau ...
- Temukan dan tangkap pesan yang lewat dengan kriteria apa pun
Pengoperasian kebun binatang kami dan solusi dari tugas-tugas yang terdengar dengan menggunakan plug-in
manajemen rabbitmq_man reguler yang disediakan adalah mungkin, tetapi sangat merepotkan, itulah sebabnya sebuah shell dikembangkan dan diimplementasikan untuk
mengendalikan seluruh variasi kelinci .