
Kaggle adalah platform yang terkenal untuk kompetisi pembelajaran mesin hosting di mana jumlah pengguna terdaftar telah melebihi 2,5 juta. Ribuan ilmuwan data dari berbagai negara berpartisipasi dalam kompetisi, dan Kaggle menjadi tertarik dengan apa yang dimaksud dengan penonton. Pada Oktober 2018, survei kedua diselenggarakan dan 23.859 orang dari 147 negara menjawabnya.
Survei ini memiliki beberapa lusinan pertanyaan tentang berbagai topik: jenis kelamin dan usia, pendidikan dan bidang pekerjaan, pengalaman dan keterampilan, bahasa pemrograman dan perangkat lunak yang digunakan, dan banyak lagi.
Tapi Kaggle bukan hanya tempat untuk kompetisi, juga memungkinkan untuk mempublikasikan penelitian data atau solusi kompetisi (mereka disebut kernel dan mirip dengan Jupyter Notebook), sehingga dataset dengan hasil survei diterbitkan dalam domain publik, dan kompetisi diselenggarakan untuk penelitian terbaik dari data ini. Saya juga ambil bagian dan tidak menerima hadiah uang tunai, tetapi kernel saya mengambil tempat keenam dalam jumlah suara. Saya ingin membagikan hasil analisis saya.
Ada banyak data dan mereka dapat dilihat dari berbagai sudut. Saya tertarik pada perbedaan antara orang-orang dari berbagai negara, sehingga sebagian besar penelitian akan membandingkan orang-orang dari Rusia (karena kami tinggal di sini), Amerika (sebagai negara paling maju dalam hal DS), India (sebagai negara miskin dengan banyak DS) dan negara-negara lain.
Sebagian besar grafik dan analisis diambil dari kernel saya (mereka yang ingin dapat melihat kode Python di sana), tetapi ada juga ide-ide baru.
Ulasan umum
Saya langsung mencatat bahwa mereka yang menjawab pertanyaan-pertanyaan tersebut tidak cukup mewakili sampel ilmuwan data. Tidak semua orang tertarik menghabiskan waktu di kompetisi, seseorang hanya tidak mendengar tentang platform ini, akhirnya, ~ 24 ribu responden - hanya sebagian kecil dari semua peserta Kaggle. Namun demikian, kami hanya memiliki data ini, jadi di masa depan saya akan mempertimbangkan bahwa informasi yang tersedia cukup untuk menarik kesimpulan tentang negara dan secara umum.
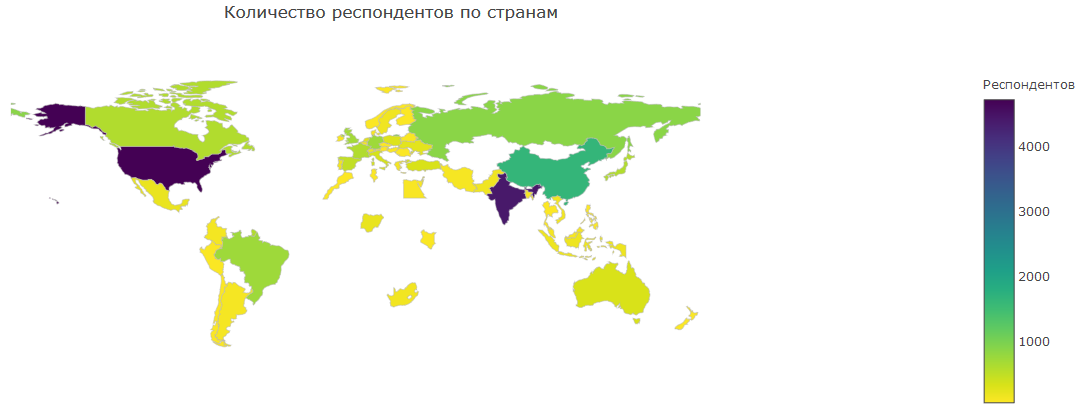
Di peta ini Anda dapat melihat jumlah orang yang disurvei di berbagai negara. Sebagian besar adalah Amerika dan India. Saat ini, Amerika, mungkin, bisa disebut sebagai pemimpin di DS, ditambah area ini telah menjadi populer di sana sebelumnya, yang menjelaskan banyak orang. India adalah negara dengan populasi besar yang telah lama memperhatikan IT. Berkat kursus dari Siraj Raval DS mendapatkan popularitas dan menarik sejumlah besar orang India. Cina tertinggal jauh di belakang, tapi saya kira ini karena kedekatan Internet mereka.
Di Rusia, Kanada, Brasil dan Eropa, ada juga cukup banyak DS, tetapi di negara-negara ini populasinya jauh lebih kecil, oleh karena itu, mereka belum bisa bersaing dalam hal jumlah peserta Kaggle.
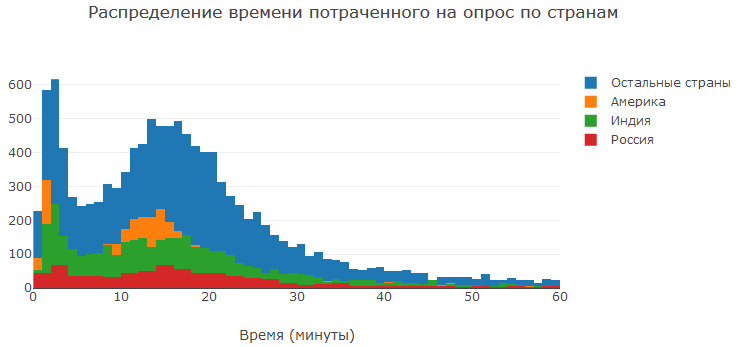
Mari kita lihat berapa banyak waktu yang dihabiskan orang dalam survei. Seperti yang Anda lihat, banyak orang menghabiskan 10-20 menit untuk survei, yang cukup untuk menjawab pertanyaan. Responden yang menjawab pertanyaan dalam waktu kurang dari beberapa menit, tampaknya, segera atau hampir segera menutup survei. Seseorang mungkin tidak menyukai survei, seseorang mungkin terlalu malas untuk menjawab, seseorang tidak ingin menjawab pertanyaan tentang jenis kelamin mereka (lebih lanjut tentang itu di bawah). Secara umum, masih ada orang yang menghabiskan puluhan jam untuk survei. Mereka mungkin hanya lupa tentang tab yang terbuka :)
Struktur usia dan jenis kelamin
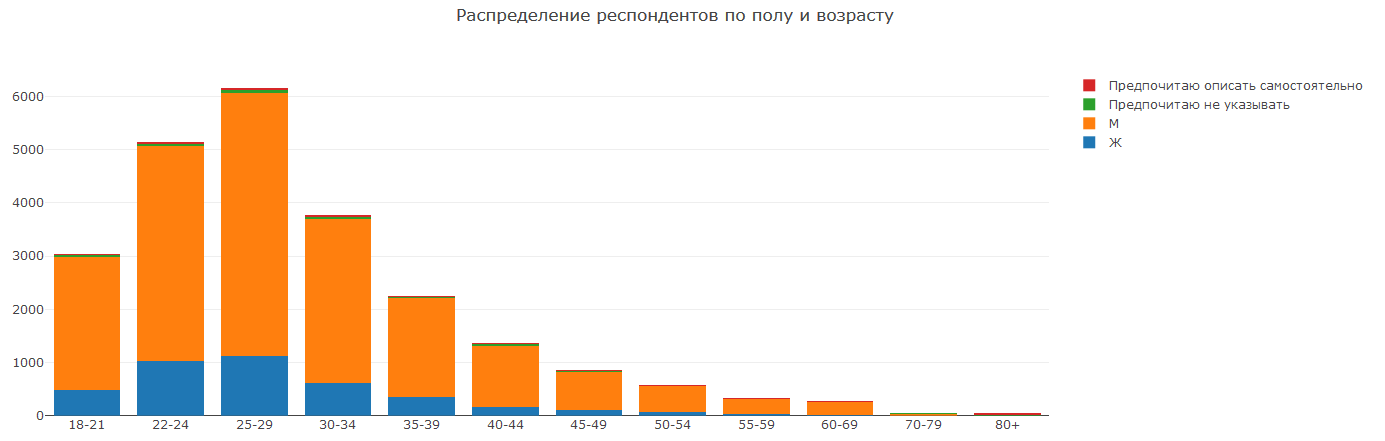
Secara umum, gambarnya tidak mengejutkan. Yang terpenting, anak muda berusia 22-29, atau bahkan 18-34 tahun, berpartisipasi dalam Kaggle. Ini adalah anak sekolah, siswa dan lulusan baru. Kemungkinan besar, mereka semua mencari untuk memperoleh pengetahuan atau mencapai hasil yang mengesankan untuk mendapatkan keuntungan saat mencari pekerjaan. Ada jauh lebih banyak pria daripada wanita. Secara umum, ini tidak mengherankan, mengingat bahwa bidang kami menggabungkan TI, matematika, dan bidang-bidang lain di mana telah lama terjadi ketidakseimbangan gender. Apakah sesuatu perlu dilakukan secara aktif untuk memperbaiki ketidakseimbangan ini? Saya lebih suka tidak membahas artikel ini.
Perlu dicatat bahwa dimungkinkan juga untuk tidak menentukan jenis kelamin atau menentukannya sendiri. Mari kita lihat opsi yang paling populer:
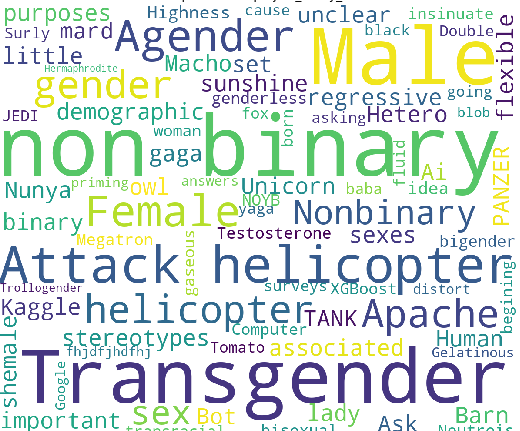
Di antara jawaban dalam bentuk bebas:
- non-biner (memadai)
- Helikopter serang (keren! Saya benar-benar ingin melihat orang tua saya)
- Pria (mengapa tidak memilih opsi ini saja?)
- Siapa kamu untuk menyindir saya memiliki jenis kelamin? (yah, karena kamu manusia?)
- Kaggle (yah, setidaknya tidak kaggloseksual)
- Yang Mulia (Anda jelas tidak mengacaukan pertanyaan ini dengan orang lain?)
- Sinar matahari kecil. :) (ini sangat imut!)
- Laki-laki ganda (lurus macho!)
- Pria dan wanita adalah jenis kelamin bukan jenis kelamin. Gender adalah set stereotip regresif yang terkait dengan seks kita. Tanyakan apa jenis kelamin kita untuk tujuan demografis, jika itu yang penting. (SWJ terdeteksi!)
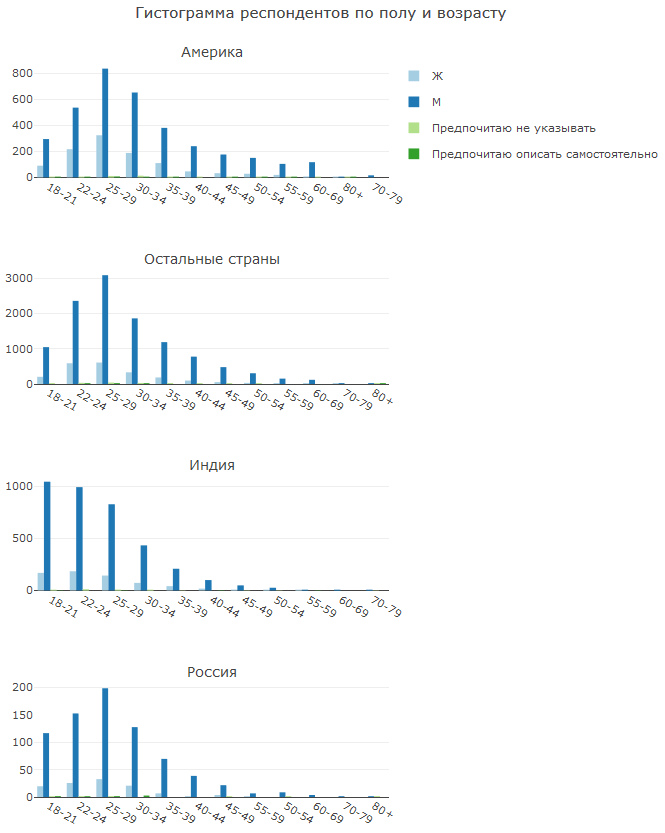
Sangat menarik untuk melihat perbedaan usia dan struktur seks di berbagai negara.
Di Amerika, proporsi wanita lebih tinggi daripada di negara lain. Ini karena dalam beberapa tahun terakhir, ada perjuangan aktif melawan "ketidaksetaraan gender." Apakah dia membutuhkannya atau tidak adalah pertanyaan, tetapi hasilnya terlihat.
India menonjol dengan sejumlah besar DS muda. Sepertinya para lelaki berpikir lebih dulu tentang masa depan dan memompa keterampilan sejak kecil. Nanti kita akan melihat bahwa sistem pendidikan di India meninggalkan banyak hal yang diinginkan.
Rusia secara keseluruhan mirip dengan negara lain.
Pendidikan

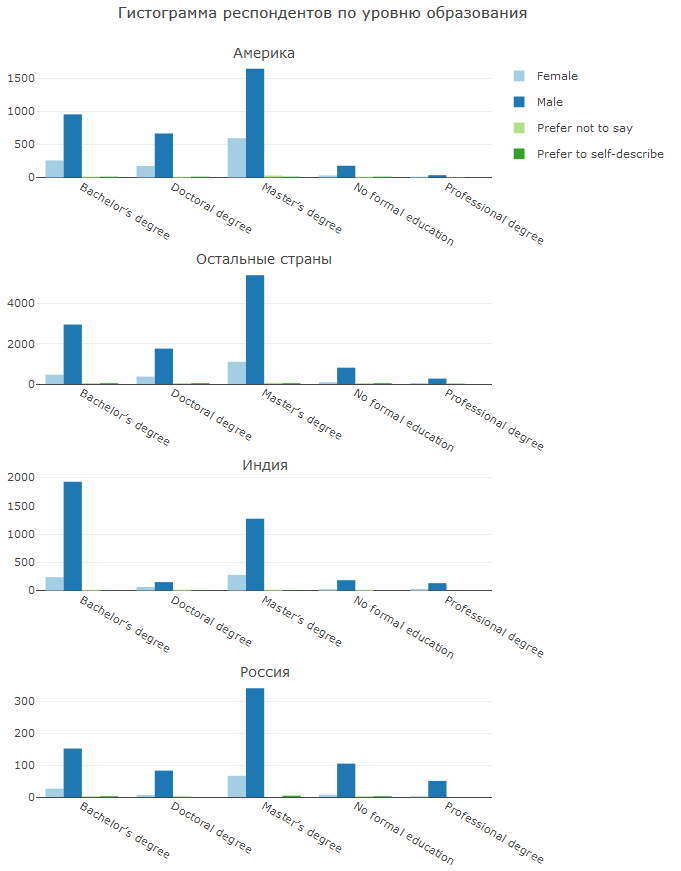

Seperti yang disebutkan sebelumnya, di India terdapat proporsi mahasiswa atau sarjana yang tinggi, tetapi praktis tidak ada pemegang gelar doktor. Rusia menonjol karena banyak DS tidak memiliki pendidikan formal (atau mereka tidak mau menjawab). Secara umum, ini mengesankan - tampaknya mereka bisa memasuki bidang DS dengan pekerjaan dan ketekunan mereka.
Sangat menarik untuk melihat bagaimana di berbagai negara DS muncul dari berbagai arah. CS, IT dan matematika / statistik berlaku di semua negara, tetapi di India bias dalam arah teknis terlihat, di Amerika disiplin bisnis (termasuk ekonomi) lebih penting, dan di Rusia fisika juga lebih penting.
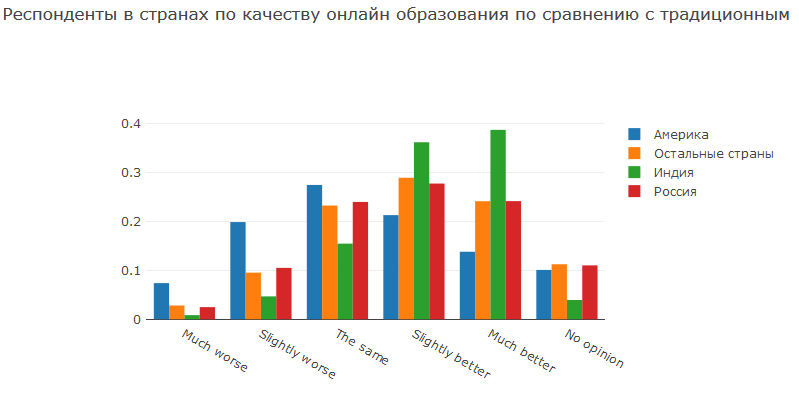
Dalam pertanyaan ini, orang-orang ditanyai pendapat mereka tentang apakah kualitas kursus pada platform online lebih baik atau lebih buruk daripada pendidikan tradisional. Dan di sini Anda dapat melihat perbedaan antar negara. Pendidikan di India buruk. Mungkin tidak ada cukup guru, mungkin kualitas pendidikan agak rendah, dalam hal apa pun, kebanyakan orang India lebih suka kursus online. Amerika memiliki sistem pendidikan yang dikembangkan, sebagai akibatnya, hampir sepertiga orang percaya bahwa pendidikan universitas berkualitas lebih tinggi. Di Rusia dan seluruh dunia, kualitas pendidikan tradisional tidak buruk dan hampir kalah dengan para pesaing.
Judul pekerjaan
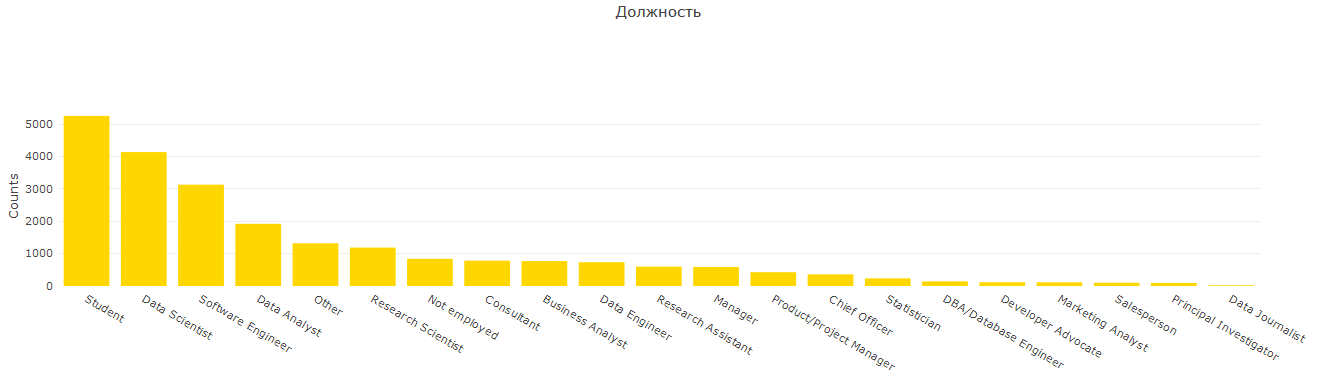
Sebagai bagian dari salah satu pertanyaan yang mereka tanyakan untuk menunjukkan posisi, menurut saya untuk tugas-tugas laporan ini begitu banyak pilihan tidak diperlukan. Setelah beberapa pemikiran, saya membentuk 7 kelompok dan mendapatkan gambar berikut:
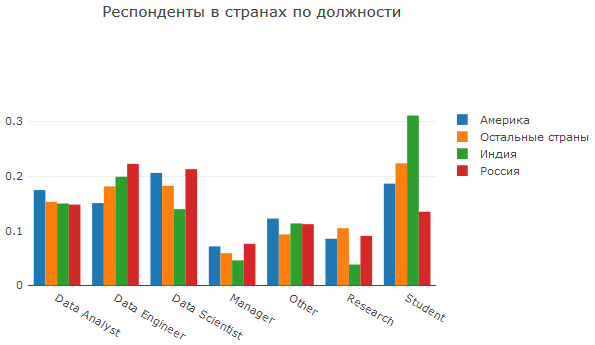
Di sini kita melihat konfirmasi lain bahwa banyak orang Indian Huggle adalah pelajar dan / atau perwakilan dari bidang yang lebih teknis. Amerika menonjol karena penekanannya pada analitik, dan Rusia menonjol di bidang terapan.
Tapi mari kita lihat gambar yang lebih detail:
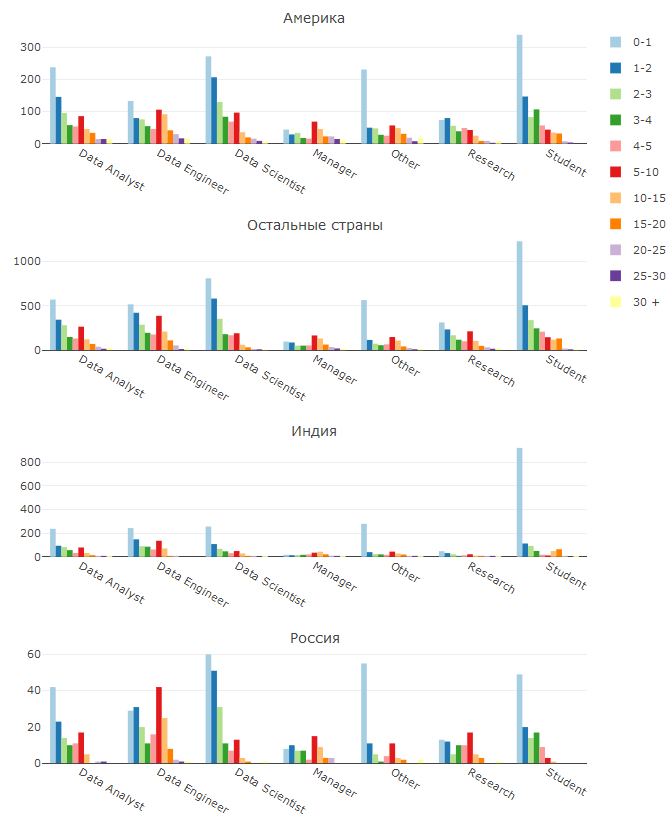
Di sini kita melihat berapa lama seseorang telah bekerja di posisinya saat ini.
Hal pertama yang menarik perhatian Anda - sebagian besar orang di semua posisi adalah pendatang baru. Saya melihat 2 penjelasan untuk fakta ini: apakah lulusan universitas atau telah mengubah ruang lingkup pekerjaan. Hipertensi pada DS / ML mulai baru-baru ini dan, menurut saya, semakin kuat, sebagai akibatnya semakin banyak orang ingin bergabung dengan arah baru dan menciptakan Kecerdasan Buatan mereka sendiri (karena orang-orang di luar DS jarang menyadari bahwa tidak akan ada AI dan tidak akan ada di masa mendatang tahun).
Fenomena menarik lainnya adalah sebagian besar insinyur data yang berpengalaman. Saya berasumsi bahwa banyak programmer berpengalaman memutuskan untuk berguling ke DS, tetapi DE lebih dekat dengan mereka - sebagian besar keterampilan yang tersedia cocok untuk menghasilkan solusi ML dalam produksi. Sangat menarik bahwa di Rusia pangsa DE dari 5-10 dan 10-15 tahun pengalaman cukup tinggi, tampaknya ini adalah pengembangan senior di Jawa dan bahasa lain, yang sangat diminati untuk sistem beban tinggi. Secara pribadi, saya secara terpisah terkejut oleh tingginya proporsi peneliti berpengalaman di Rusia, sampai saya mengerti alasannya.
Amerika menonjol di antara negara-negara lain dengan proporsi analis yang tinggi. Ada banyak alasan untuk ini: fakta bahwa di Amerika DS sering diambil untuk posisi analitis, dan fakta bahwa di sejumlah perusahaan besar analis data benar-benar melakukan pekerjaan DS, dan bahwa itu dapat dilatih kembali statistik.
Karena kita berbicara tentang pekerjaan, kita tidak bisa tidak menyentuh masalah gaji.
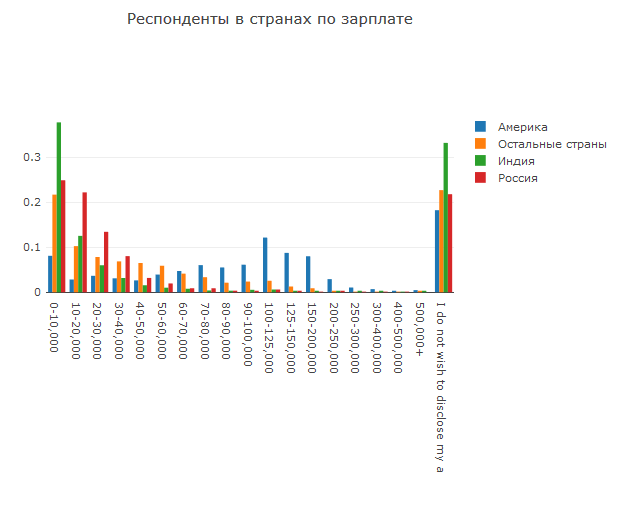
Semuanya sangat diharapkan di sini: gaji di India adalah yang terendah, di Rusia sedikit lebih tinggi, dan gaji Amerika adalah yang tertinggi.
Kepercayaan diri

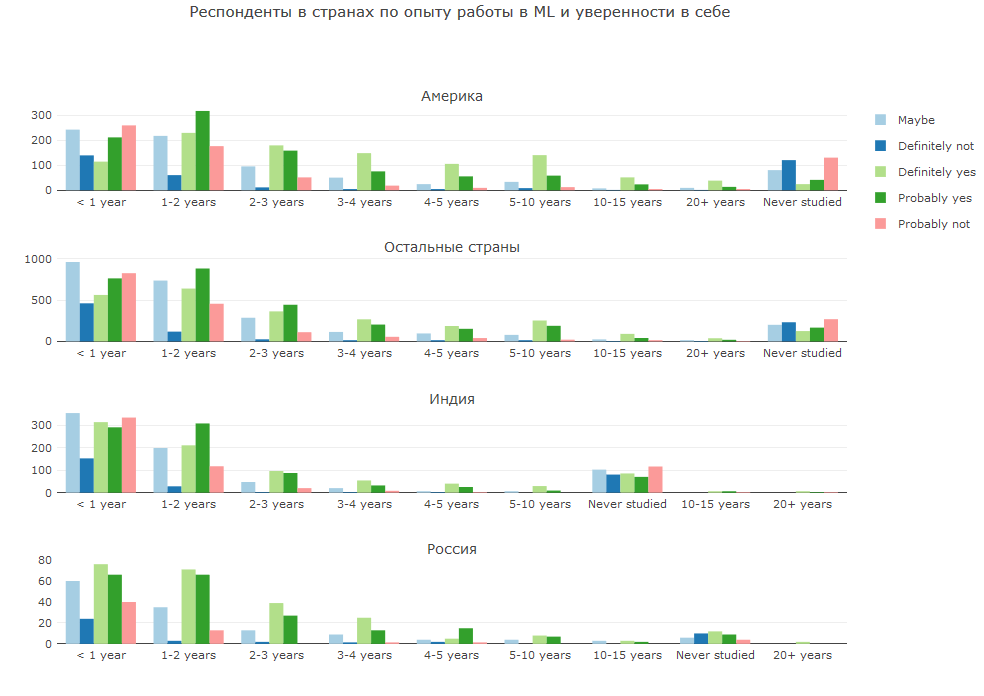
Kombinasi jawaban untuk 2 pertanyaan itu tampak sangat menarik bagi saya. Pertanyaan pertama adalah pengalaman dalam ML, yang kedua adalah apakah Anda menganggap diri Anda seorang DS. Di sini Anda dapat mengamati perbedaan pandangan dunia dan persepsi diri, atau perbedaan pemahaman tentang berbagai masalah.
Di sebagian besar negara, pendatang baru dengan pengalaman kurang dari dua tahun memiliki pendapat yang beragam - seseorang sudah percaya diri, seseorang sangat ragu. Saat pengalaman tumbuh, kepercayaan diri tumbuh. Di Rusia, sebagian besar pemula menganggap diri mereka DS, tetapi dengan pengalaman yang diperoleh, kepercayaan diri akan berkurang.
Pertanyaan lebih lanjut akan diajukan di mana beberapa jawaban dapat diindikasikan, sehingga penjumlahan dari saham mungkin memberikan lebih dari 100%
Sumber daya yang dikunjungi
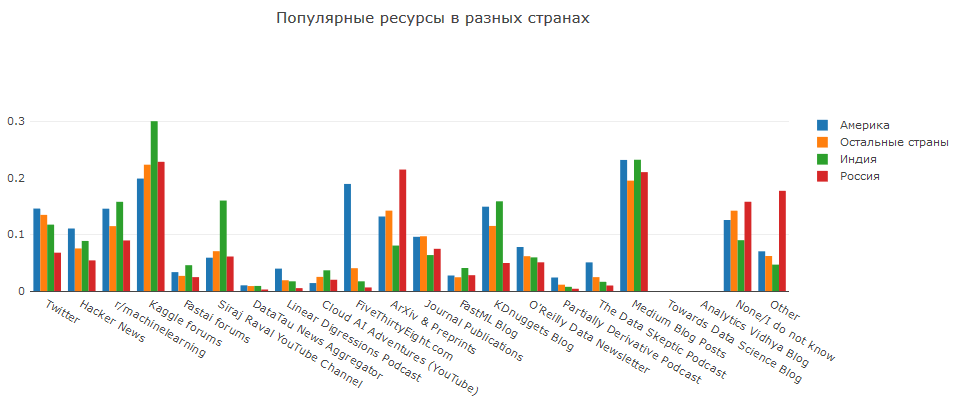
Kaggle dan Medium menghargai segalanya. Di Rusia, mereka suka membaca artikel tentang ArXiV, di Amerika mereka lebih suka https://fivethirtyeight.com (dan mereka hampir tidak pernah mengunjunginya di negara lain), dan di India mereka menyukai Siraj.
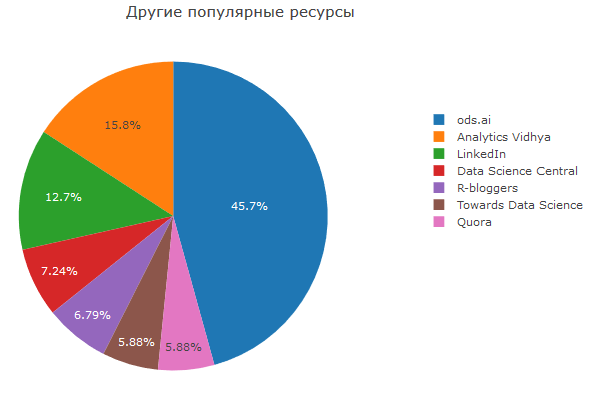
Saya juga ingin menyebutkan ods.ai, yang ternyata menjadi sumber daya paling populer, di antara yang ditentukan orang secara manual. Siapa lagi yang tidak ada di komunitas kami, gabung :)
IDE dan bahasa pemrograman


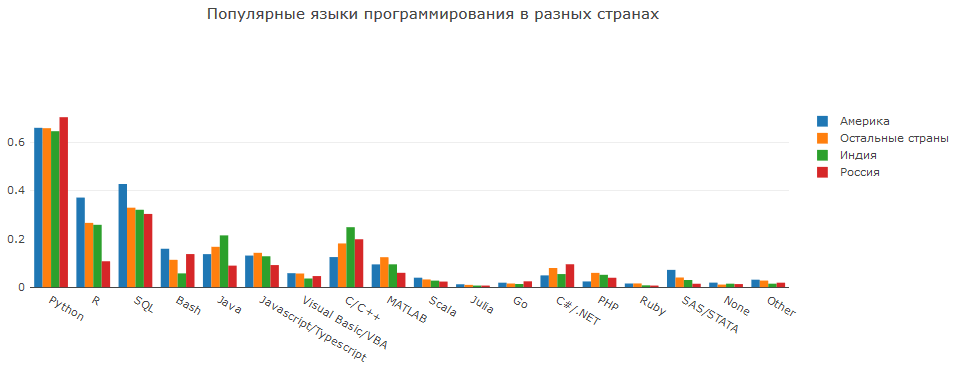
Dalam hal menggunakan IDE, orang dapat dibagi menjadi 2 kelompok utama: menggunakan IDE dengan visualisasi terintegrasi (Notebook Jupyter, RStudio, Spyder) dan menggunakan IDE klasik (VS Code, Vim).
Amerika menonjol dengan sebagian besar analis menggunakan R dan, sebagai hasilnya, RStudio. Namun, ide seperti Vim atau Atom juga dikenal. Pycharm populer di Rusia tidak hanya di kalangan DS, tetapi juga di kalangan programmer pada umumnya, sehingga jumlah orang yang menggunakannya tidak mengejutkan.
SQl, Java, Bash, C / C ++ juga bahasa yang penting untuk DS.
Kerangka kerja
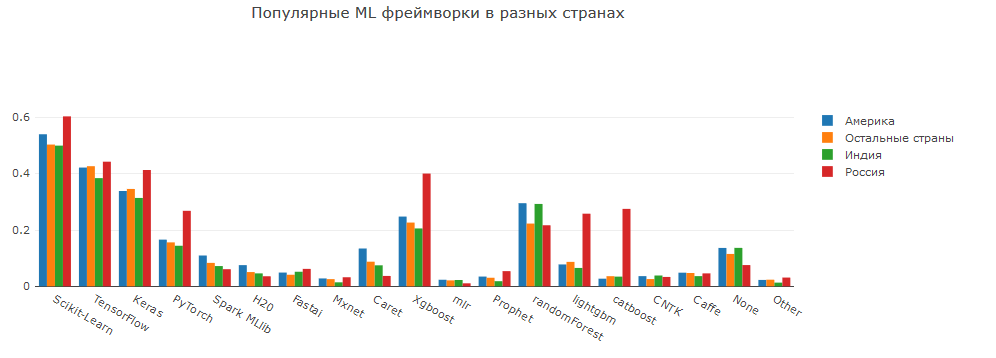
Agak mengherankan bagi saya bahwa pembagian penggunaan kerangka kerja DL tidak jauh lebih rendah dibandingkan dengan penggunaan sklearn. Mungkin banyak yang tertarik pada jaringan saraf, dan mereka ingin mempelajarinya sejak awal; mungkin sebuah bisnis mulai menggunakan neuron dalam tugasnya; dan mungkin hanya banyak peserta Kaggle yang tertarik untuk mencoba kompetisi dalam gambar dan teks.
Secara terpisah, saya ingin mencatat tingginya proporsi orang yang menggunakan perpustakaan Pytorch dan gradient meningkatkan di Rusia. LGB / XGB / catboost adalah implementasi peningkatan gradien yang paling terkenal, dan mereka menunjukkan kualitas tinggi pada data tabel. Pytorch muncul sejak lama, tetapi mulai mendapatkan popularitas tinggi dalam 1-2 tahun terakhir.
Visualisasi
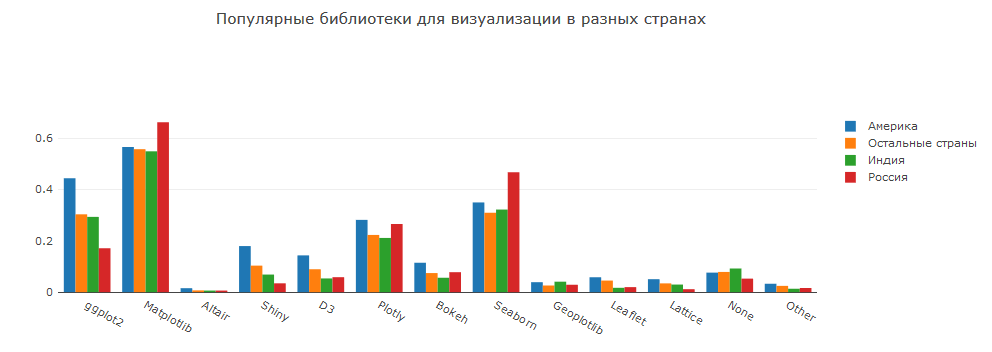
Analisis data apa tanpa visualisasi! Secara umum, gambarnya tidak mengejutkan. R adalah ggplot2 dan mengkilap. Python adalah matplotlib + seaborn, plotly / bokeh.
D3 memungkinkan Anda membuat visualisasi yang keren, tetapi cukup sulit untuk dikerjakan.
Altair adalah perpustakaan di Vega-Lite, saya berharap bahwa di masa depan itu akan mendapatkan popularitas berkat visualisasi interaktif menarik yang tersedia di dalamnya.
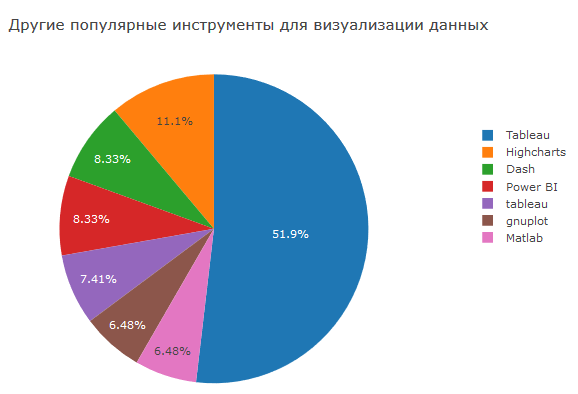
Tableau dan perangkat lunak BI lainnya terus tetap populer, yang tidak mengejutkan - ini adalah solusi berkualitas tinggi yang didukung dan dapat mengintegrasikan banyak hal dengan apa pun.
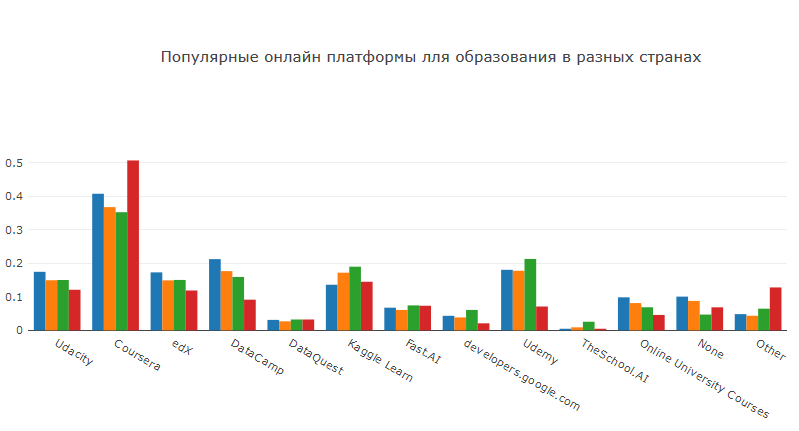
Coursera adalah pemimpin pasar dalam kursus pendidikan online. Di sana Anda dapat menemukan kursus di hampir semua topik dan level. Faktor penting adalah Anda dapat mengajukan permohonan bantuan keuangan dan mengambil kursus secara gratis. Udacity, Udemy dan edX tidak begitu populer, tetapi Anda juga dapat menemukan banyak kursus menarik di sana. Kaggle meluncurkan inisiatif pendidikannya sendiri beberapa waktu lalu. Yang menyenangkan adalah bahwa kursus dibuat dalam bentuk kernel, yang memberikan latihan dalam menggunakan kemampuan Kaggle. Kursus-kursus dari DataCamp memiliki format unik yang memungkinkan Anda memberikan latihan poin pada topik-topik tertentu, tetapi platform ini tidak mungkin memberikan pengetahuan mendalam.
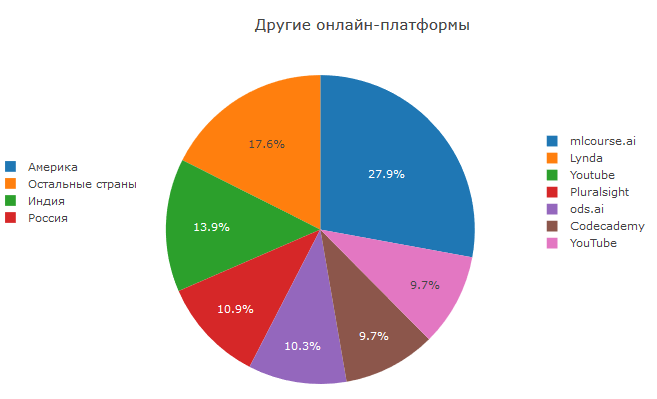
Secara terpisah, perlu dicatat bahwa mls.course.ai dari ods.ai adalah yang paling populer dari opsi yang ditentukan oleh pengguna. Baru-baru ini, sesi keempat kursus berakhir di mana lebih dari 7,5 ribu orang terdaftar. Karena kenyataan bahwa komunikasi utama terjadi di slack, kursus berakhir dengan proporsi orang yang mengesankan - secara signifikan lebih tinggi daripada kursus ML gratis lainnya. Kursus ini tidak hanya memberikan pengetahuan teoretis dan pekerjaan rumah yang kompleks, tetapi juga praktik berpartisipasi dalam kompetisi di Kaggle.
Alat Interpretasi
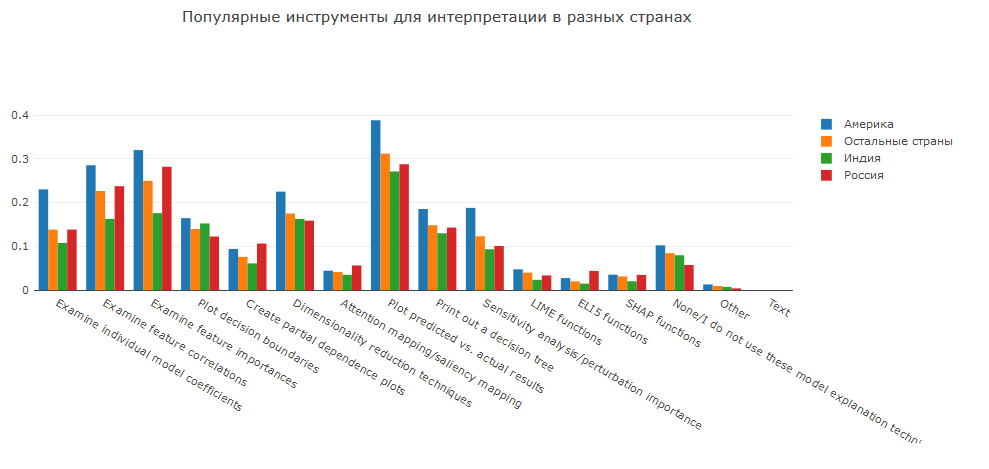
Akhirnya, mari kita lihat bagaimana orang yang berbeda menganalisis hasil model.
Analisis prediksi itu sendiri dan perbandingan distribusinya dengan distribusi variabel target adalah cara analisis dasar tetapi kualitatif. Mempelajari koefisien model linear atau pentingnya fitur dalam model kayu memungkinkan Anda menemukan fitur yang paling memengaruhi prediksi.
Selain itu, kerangka kerja khusus untuk analisis model baru-baru ini menjadi populer: SHAP, LIME, dan ELI5. Mereka memungkinkan kita untuk menjelaskan tidak hanya model sederhana, tetapi bahkan beberapa dari mereka yang dianggap kotak hitam.
Ringkasan
Kami melihat bagaimana DS berbeda satu sama lain di berbagai negara di dunia, dan juga menemukan apa yang menyatukan mereka. Analisis ini tidak mencakup semua data yang tersedia, tetapi menunjukkan yang menurut saya paling menarik. Mereka yang ingin dapat melakukan penelitian tentang data ini :)
Terima kasih atas perhatian anda!