
Saya bekerja di tim platform Odnoklassniki dan hari ini saya akan berbicara tentang arsitektur, desain, dan detail implementasi layanan distribusi musik.
Artikel ini adalah transkrip dari laporan di Joker 2018 .
Beberapa statistik
Pertama, beberapa kata tentang OK. Ini adalah layanan raksasa yang digunakan oleh lebih dari 70 juta pengguna. Mereka dilayani oleh 7 ribu mobil di 4 pusat data. Baru-baru ini, kami telah menembus tanda lalu lintas pada 2 Tb / s tanpa memperhitungkan banyak situs CDN. Kami memeras maksimal dari perangkat keras kami, layanan paling banyak melayani hingga 100.000 permintaan per detik dari simpul quad-core. Apalagi hampir semua layanan ditulis di Jawa.
Ada banyak bagian di OK, salah satu yang paling populer adalah "Musik". Di dalamnya, pengguna dapat mengunggah trek mereka, membeli dan mengunduh musik dengan kualitas yang berbeda. Bagian ini memiliki katalog yang luar biasa, sistem rekomendasi, radio dan banyak lagi. Tetapi tujuan utama dari layanan ini, tentu saja, adalah memainkan musik.
Distributor musik bertanggung jawab untuk mentransfer data ke pemutar pengguna dan aplikasi seluler. Anda dapat menangkapnya di inspektur web jika Anda melihat permintaan ke domain musicd.mycdn.me. API distributor sangat sederhana. Ini menanggapi
GET permintaan HTTP dan mengeluarkan rentang trek yang diminta.
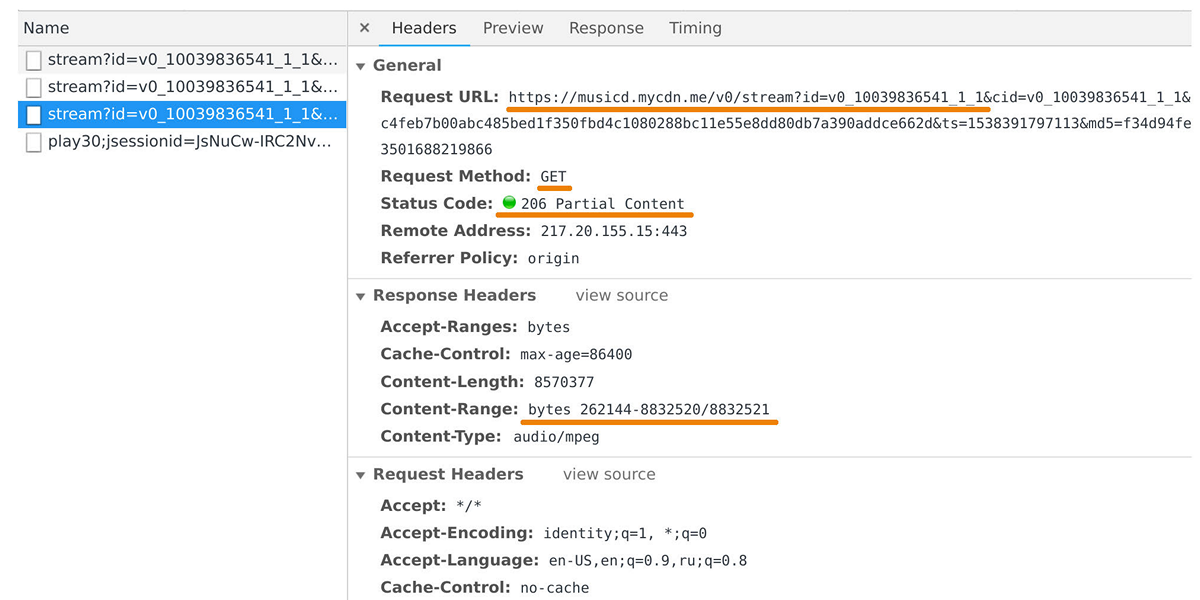
Pada puncaknya, beban mencapai 100 Gb / s hingga setengah juta koneksi. Faktanya, distributor musik adalah tampilan cache di depan repositori trek internal kami, yang didasarkan pada
One Blob Storage dan
One Cold Storage dan berisi petabytes data.
Karena saya sudah bicara tentang caching, mari kita lihat statistik pemutaran. Kami melihat TOP yang diucapkan.
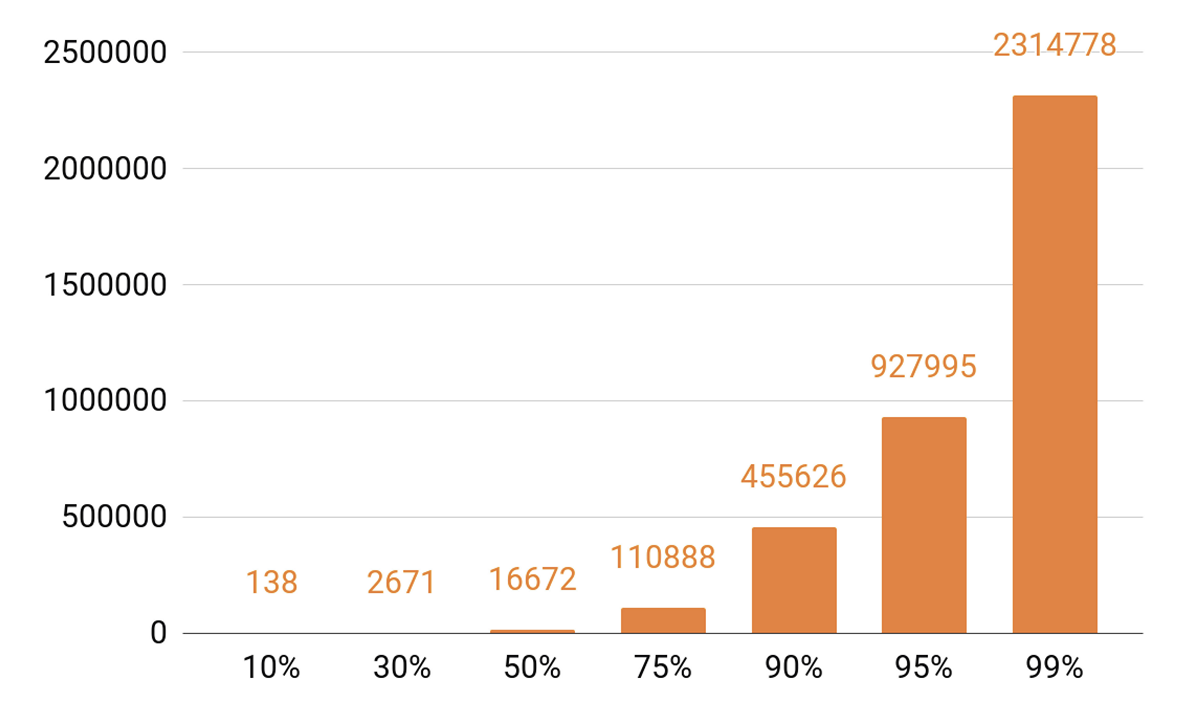
Sekitar 140 lagu mencakup 10% dari semua permainan per hari. Jika kita ingin server caching kita memiliki cache hit setidaknya 90%, maka kita perlu memasukkan setengah juta track. 95% - hampir satu juta lagu.
Persyaratan Distributor
Tujuan apa yang kami tetapkan saat mengembangkan versi distributor selanjutnya?
Kami ingin satu simpul untuk dapat menampung 100 ribu koneksi. Dan ini adalah koneksi klien yang lambat: sekelompok browser dan aplikasi seluler melalui jaringan dengan kecepatan yang bervariasi. Pada saat yang sama, layanan, seperti semua sistem kami, harus dapat diukur dan toleran terhadap kesalahan.
Pertama-tama, kita perlu skala bandwidth cluster untuk mengimbangi semakin populernya layanan dan dapat memberikan lebih banyak dan lebih banyak lalu lintas. Hal ini juga diperlukan untuk dapat mengukur kapasitas total cache cluster, karena cache hit dan persentase permintaan yang akan jatuh ke dalam penyimpanan trek secara langsung bergantung padanya.
Saat ini perlu untuk dapat skala sistem terdistribusi secara horizontal, yaitu, menambahkan mesin dan pusat data. Tetapi kami juga ingin menerapkan penskalaan vertikal. Server modern khas kami berisi 56 core, 0,5-1 TB RAM, antarmuka jaringan 10 atau 40 Gb dan selusin disk SSD.
Berbicara tentang skalabilitas horizontal, efek yang menarik muncul: ketika Anda memiliki ribuan server dan puluhan ribu disk, sesuatu yang terus-menerus rusak. Kegagalan disk adalah rutin, kami mengubahnya dengan 20-30 lembar per minggu. Dan kegagalan server tidak mengejutkan siapa pun; 2-3 mobil sehari diganti. Saya juga harus berurusan dengan kegagalan pusat data, misalnya, pada 2018 ada tiga kegagalan seperti itu, dan ini mungkin bukan yang terakhir.
Kenapa aku semua ini? Ketika kita merancang sistem apa pun, kita tahu bahwa mereka akan rusak cepat atau lambat. Oleh karena itu, kami selalu
mempelajari dengan cermat skenario kegagalan semua komponen sistem. Cara utama untuk mengatasi kegagalan adalah melalui replikasi data: beberapa salinan data disimpan pada node yang berbeda.
Kami juga memesan bandwidth jaringan. Ini penting karena jika komponen sistem gagal, itu tidak dapat diizinkan untuk memuat pada komponen yang tersisa untuk runtuh.
Menyeimbangkan
Pertama, Anda perlu mempelajari cara menyeimbangkan kueri pengguna antara pusat data, dan melakukannya secara otomatis. Ini kalau-kalau Anda perlu melakukan pekerjaan jaringan, atau jika pusat data telah gagal. Tetapi keseimbangan juga dibutuhkan di dalam pusat data. Dan kami ingin mendistribusikan permintaan antar node tidak secara acak, tetapi dengan bobot. Misalnya, ketika kami mengunggah versi baru dari suatu layanan dan ingin dengan lancar memasukkan simpul baru ke dalam rotasi. Bobot juga banyak membantu selama pengujian stres: kami menambah berat badan dan meletakkan beban yang jauh lebih berat pada simpul untuk memahami batas kemampuannya. Dan ketika sebuah simpul gagal di bawah beban, kami dengan cepat menurunkan berat dan menghapusnya dari rotasi menggunakan mekanisme penyeimbang.
Seperti apa tampilan jalur permintaan dari pengguna ke simpul, yang akan mengembalikan data dengan mempertimbangkan penyeimbangan akun?

Pengguna masuk melalui situs web atau aplikasi seluler dan menerima URL trek:
musicd.mycdn.me/v0/stream?id=...Untuk mendapatkan alamat IP dari nama host di URL, klien menghubungi DNS GSLB kami, yang mengetahui semua pusat data dan situs CDN kami. DNS GSLB memberikan klien alamat IP penyeimbang dari salah satu pusat data, dan klien membuat koneksi dengannya. Penyeimbang tahu tentang semua node di dalam pusat data dan beratnya. Itu, atas nama pengguna, membuat koneksi dengan salah satu node. Kami
menggunakan penyeimbang L4 berbasis N4Ware . Noda memberikan data pengguna secara langsung, melewati penyeimbang. Dalam layanan seperti distributor, lalu lintas keluar secara signifikan lebih tinggi dari yang masuk.
Jika pusat data macet, GSLB DNS mendeteksi ini dan dengan cepat menghapusnya dari rotasi: berhenti memberikan pengguna alamat IP penyeimbang pusat data ini. Jika sebuah simpul di pusat data gagal, maka bobotnya diatur ulang, dan penyeimbang di dalam pusat data berhenti mengirim permintaan ke sana.
Sekarang pertimbangkan untuk menyeimbangkan trek dengan node di dalam pusat data. Kami akan mempertimbangkan pusat data sebagai unit otonom independen, masing-masing akan hidup dan bekerja, bahkan jika semua yang lain mati. Track harus diseimbangkan di seluruh mesin secara merata sehingga tidak ada distorsi beban, dan mereplikasi mereka ke node yang berbeda. Jika satu simpul gagal, beban harus didistribusikan secara merata di antara yang tersisa.
Masalah ini dapat
diselesaikan dengan berbagai cara . Kami sepakat pada
hashing yang konsisten . Kami membungkus seluruh rentang hash pengidentifikasi trek yang mungkin dalam sebuah cincin, dan kemudian setiap trek ditampilkan pada suatu titik pada cincin ini. Kemudian kami kurang lebih mendistribusikan rentang cincin secara merata di antara node-node dalam cluster. Node yang akan menyimpan trek dipilih dengan hashing trek ke titik di atas ring dan bergerak searah jarum jam.
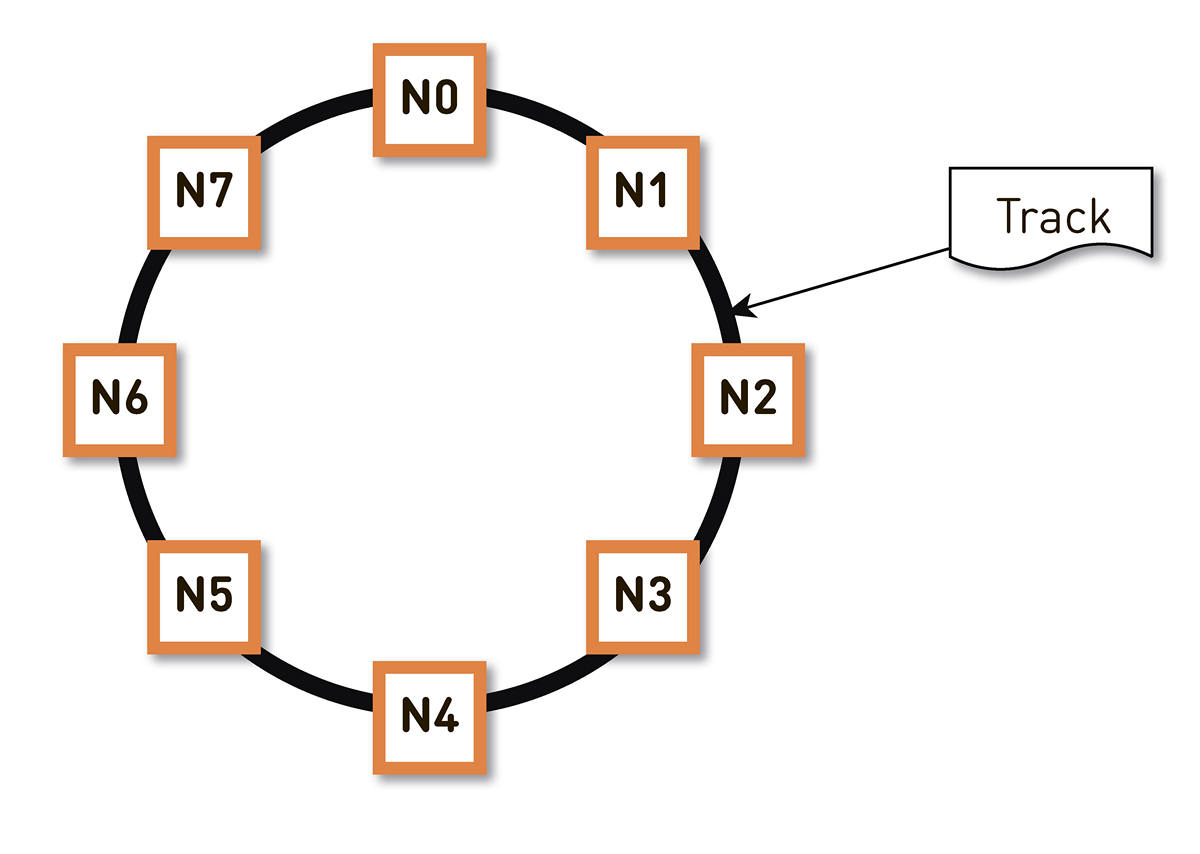
Tetapi skema semacam itu memiliki kelemahan: jika terjadi kegagalan simpul N2, misalnya, seluruh bebannya akan jatuh pada replika berikutnya di cincin - N3. Dan jika tidak memiliki margin ganda dalam kinerja - dan ini tidak dibenarkan secara ekonomi - maka, kemungkinan besar, simpul kedua juga akan memiliki waktu yang buruk. N3 dengan tingkat probabilitas tinggi akan berkembang, beban akan menuju N4, dan seterusnya - akan ada kegagalan kaskade di sepanjang keseluruhan cincin.
Masalah ini dapat diatasi dengan meningkatkan jumlah replika, tetapi kemudian total kapasitas yang berguna dari cluster di cincin berkurang. Karena itu, kami melakukan sebaliknya. Dengan jumlah node yang sama, cincin dibagi menjadi sejumlah besar rentang yang secara acak tersebar di sekitar cincin. Replika untuk trek dipilih sesuai dengan algoritma di atas.

Dalam contoh di atas, setiap node bertanggung jawab untuk dua rentang. Jika salah satu node gagal, seluruh bebannya tidak akan terletak pada node berikutnya di ring, tetapi akan didistribusikan di antara dua node lainnya dari cluster.
Cincin dihitung berdasarkan sekelompok kecil parameter secara algoritmik dan ditentukan pada setiap node. Artinya, kita tidak menyimpannya dalam semacam konfigurasi. Kami memiliki lebih dari seratus ribu rentang produksi ini, dan jika terjadi kegagalan pada salah satu simpul, beban didistribusikan secara merata antara semua simpul hidup lainnya.
Seperti apa jalur balik ke pengguna dalam sistem dengan hashing yang konsisten?
Pengguna melalui L4-balancer mendapatkan simpul acak. Pemilihan simpul adalah acak, karena penyeimbang tidak tahu apa-apa tentang topologi. Tapi kemudian setiap replika di cluster tahu tentang itu. Node yang menerima permintaan menentukan apakah itu merupakan replika dari trek yang diminta. Jika tidak, ia beralih ke mode proxy dengan salah satu replika, membuat koneksi dengannya, dan mencari data di penyimpanan lokalnya. Jika trek tidak ada, replika menariknya dari track store, menyimpannya ke toko lokal dan memberikan proxy, yang mengarahkan ulang data ke pengguna.
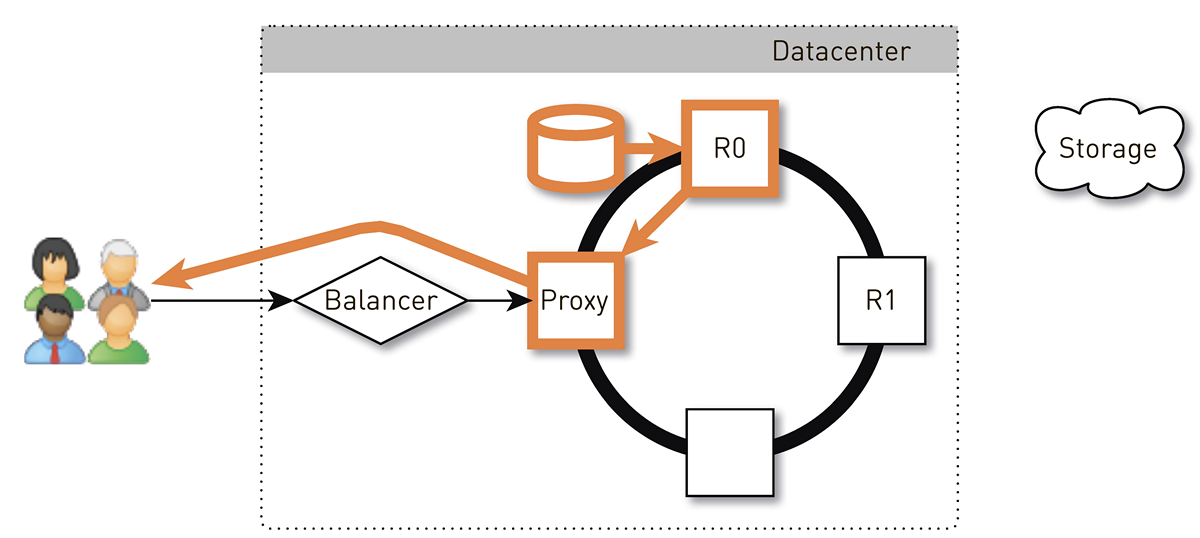
Jika drive dalam replika gagal, data dari penyimpanan akan ditransfer langsung ke pengguna. Dan jika replika gagal, maka proxy tahu tentang semua replika lain untuk trek ini, itu akan membuat koneksi dengan replika langsung lain dan menerima data dari itu. Jadi, kami menjamin bahwa jika pengguna meminta trek dan setidaknya satu replika masih hidup, ia akan menerima respons.
Bagaimana cara kerja simpul?
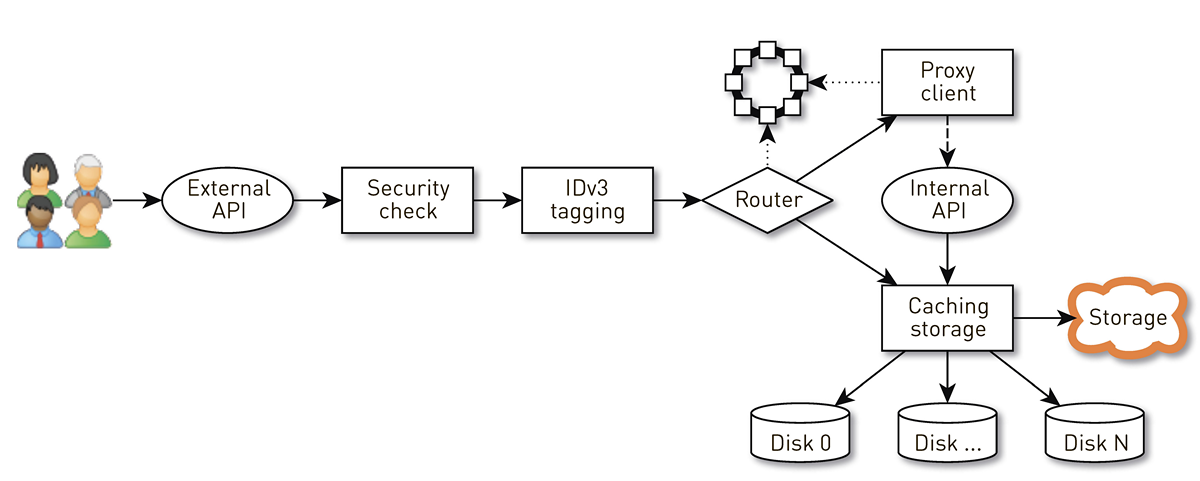
Node adalah pipa dari serangkaian tahapan yang dilewati permintaan pengguna. Pertama, permintaan masuk ke API eksternal (kami mengirim semuanya melalui HTTPS). Kemudian permintaan divalidasi - tanda tangan diverifikasi. Kemudian tag IDv3 dibangun jika perlu, misalnya, saat membeli trek. Permintaan menuju ke tahap routing, di mana berdasarkan topologi cluster ditentukan bagaimana data akan dikembalikan: apakah node saat ini adalah replika untuk lagu ini, atau kami akan proksi dari node lain. Dalam kasus kedua, simpul melalui klien proksi membuat koneksi ke replika melalui API HTTP internal tanpa verifikasi tanda tangan. Replika mencari data di penyimpanan lokal, jika menemukan trek, lalu memberikannya dari disknya; dan jika tidak, ia menarik trek dari penyimpanan, menyimpan dan memberi.
Beban simpul
Mari kita perkirakan beban yang harus dimiliki oleh satu simpul dalam konfigurasi ini. Mari kita memiliki tiga pusat data dengan masing-masing empat node.

Seluruh layanan harus melayani 120 Gbit / s, yaitu, 40 Gbit / s per pusat data. Misalkan networkers membuat manuver atau kecelakaan terjadi, dan ada dua pusat data DC1 dan DC3 yang tersisa. Sekarang masing-masing dari mereka harus memberikan 60 Gbit / s. Tapi di sini terserah kepada pengembang untuk meluncurkan beberapa pembaruan, di setiap pusat data ada 3 node yang tersisa dan masing-masing dari mereka harus memberikan 20 Gbit / s.
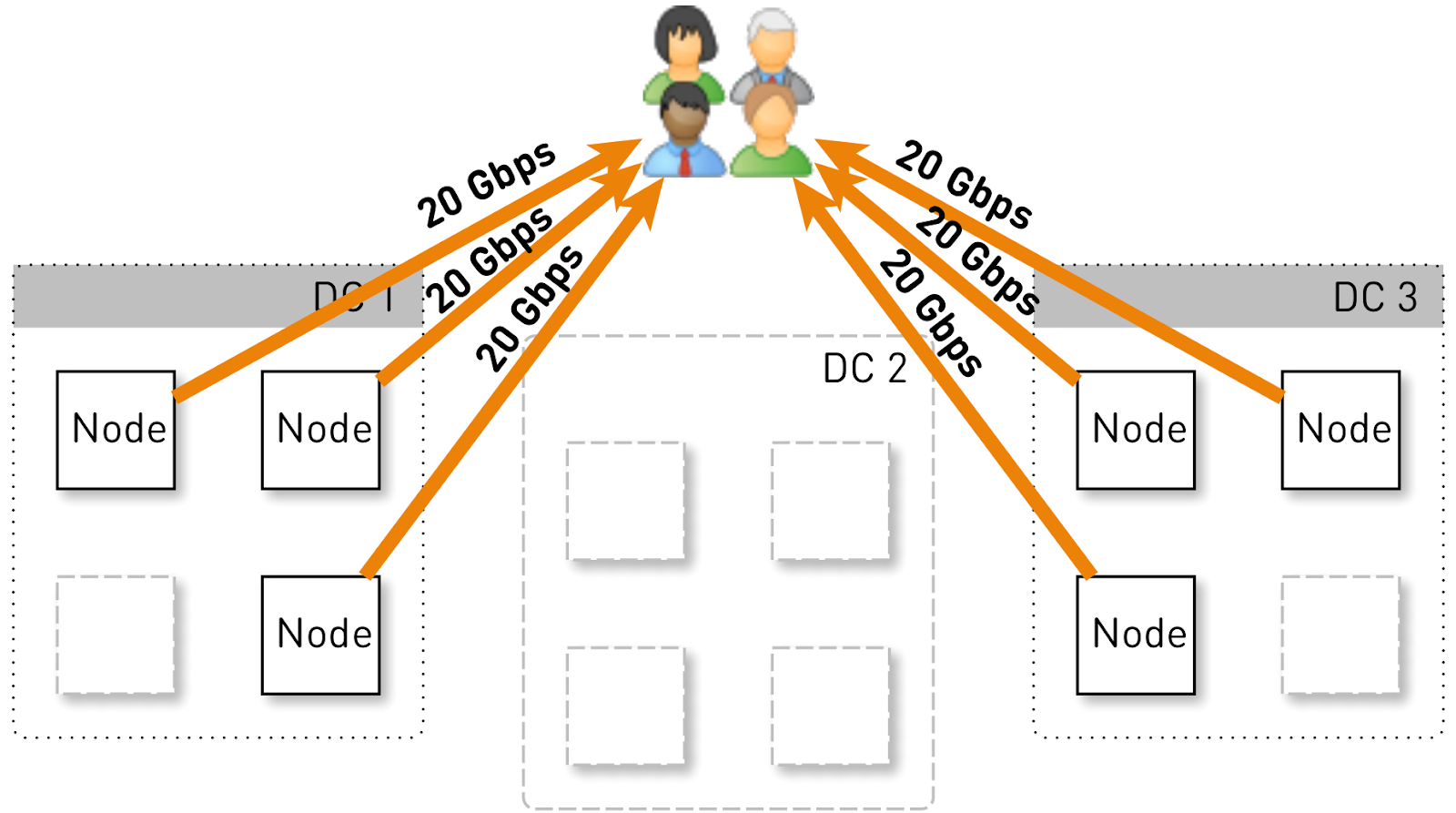
Namun pada awalnya di setiap pusat data ada 4 node. Dan jika kita menyimpan dua replika di pusat data, maka dengan probabilitas 50%, simpul yang menerima permintaan tidak akan menjadi replika trek yang diminta dan akan mem-proxy data. Yaitu, setengah dari lalu lintas di dalam pusat data diproksikan.
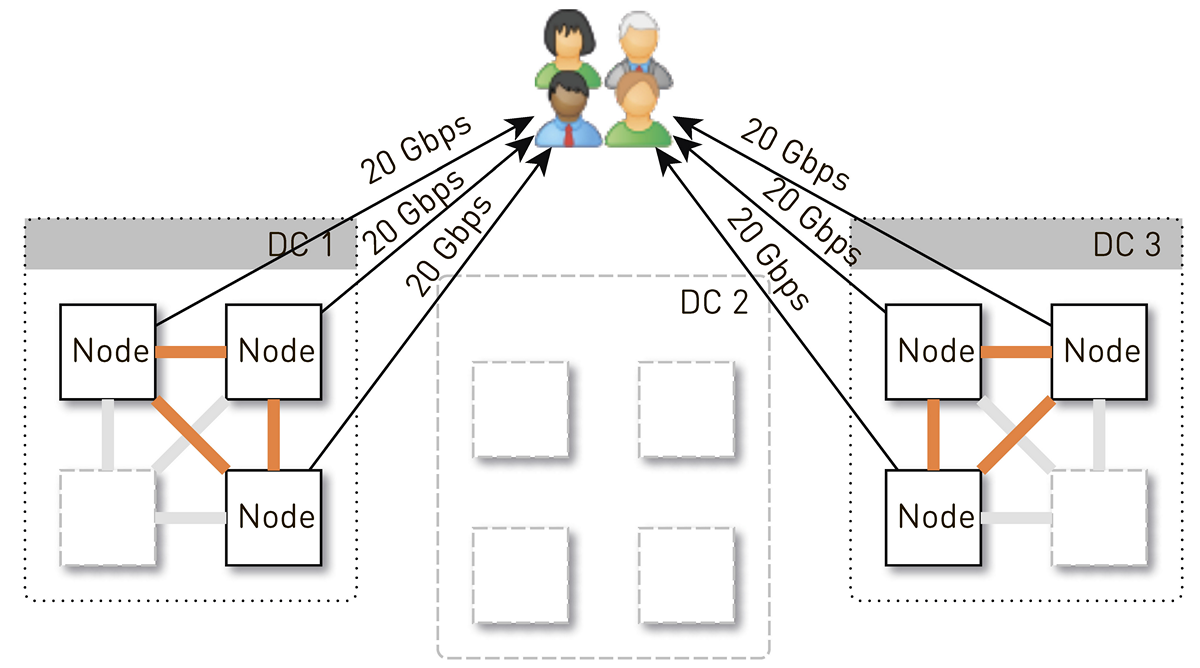
Jadi, satu node harus memberi pengguna 20 Gb / s. Dari jumlah tersebut, 10 Gb / s itu menarik dari tetangganya di pusat data. Tetapi skemanya simetris: node memberikan 10 Gb / s yang sama ke tetangga di pusat data. Ternyata 30 Gbit / s keluar dari node, yang 20 Gbit / s harus diservis dengan sendirinya, karena ini adalah replika dari data yang diminta. Selain itu, data akan berasal dari disk atau dari RAM, yang menampung sekitar 50 ribu trek "panas". Berdasarkan statistik pemutaran kami, ini memungkinkan Anda untuk menghapus 60-70% dari beban dari disk, dan akan tetap sekitar 8 Gb / s. Utas ini cukup mampu menghadirkan selusin SSD.
Penyimpanan data pada suatu node
Jika Anda menempatkan setiap lagu dalam file yang terpisah, maka biaya pengelolaan file-file ini akan sangat besar. Bahkan merestart node dan memindai data pada disk akan memakan waktu beberapa menit, jika tidak puluhan menit.
Ada batasan yang kurang jelas untuk skema ini. Misalnya, Anda dapat memuat trek hanya dari awal. Dan jika pengguna meminta pemutaran dari tengah dan cache tidak terjawab, maka kami tidak akan dapat mengirim satu byte sampai kami memuat data ke lokasi yang diinginkan dari repositori trek. Selain itu, kita dapat menyimpan trek hanya secara keseluruhan, bahkan jika itu adalah buku audio raksasa yang mereka berhenti mendengarkan pada menit ketiga. Ini akan terus membebani hard disk, membuang ruang yang mahal dan mengurangi hit cache dari node ini.
Oleh karena itu, kami melakukannya dengan cara yang sama sekali berbeda: kami membagi trek menjadi 256 KB blok, karena ini berkorelasi dengan ukuran blok di SSD, dan kami sudah beroperasi dengan blok-blok ini. Disk 1 TB berisi 4 juta blok. Setiap disk dalam sebuah node adalah penyimpanan independen, dan semua blok dari setiap track didistribusikan di semua disk.
Kami tidak segera sampai pada skema seperti itu, pada awalnya semua blok dari satu track terletak pada satu disk. Tapi ini menyebabkan distorsi yang kuat dari beban antara disk, karena jika lagu populer menabrak salah satu disk, semua permintaan untuk datanya akan pergi ke satu disk. Untuk mencegah hal ini, kami mendistribusikan blok setiap trek di semua disk, menyeimbangkan beban.
Selain itu, kami tidak lupa bahwa kami memiliki banyak RAM, tetapi kami memutuskan untuk tidak melakukan cache semantik, karena kami memiliki cache halaman yang luar biasa di Linux.
Bagaimana cara menyimpan blok pada disk?
Pertama kami memutuskan untuk mendapatkan satu file XFS raksasa seukuran disk dan meletakkan semua blok di dalamnya. Kemudian muncul ide untuk bekerja dengan perangkat blok secara langsung. Kami menerapkan kedua opsi, membandingkannya dan ternyata ketika bekerja secara langsung dengan perangkat blok, perekaman 1,5 kali lebih cepat, waktu respons 2-3 kali lebih rendah, total beban sistem 2 kali lebih rendah.
Indeks
Tetapi itu tidak cukup untuk dapat menyimpan blok, Anda perlu mempertahankan indeks dari blok trek musik ke blok pada disk.

Ternyata cukup kompak, satu entri indeks hanya membutuhkan 29 byte. Untuk penyimpanan 10 TB, indeksnya sedikit di atas 1 GB.
Ada satu hal yang menarik di sini. Dalam setiap catatan seperti itu, Anda harus menyimpan ukuran total seluruh trek. Ini adalah contoh klasik denasionalisasi. Alasannya adalah bahwa, sesuai dengan spesifikasi dalam respons rentang HTTP, kami harus mengembalikan ukuran total sumber daya, serta membentuk header Panjang Konten. Jika bukan ini, maka semuanya akan menjadi lebih kompak.
Kami merumuskan sejumlah persyaratan untuk indeks: untuk bekerja dengan cepat (lebih disukai, disimpan dalam RAM), agar ringkas dan tidak memakan ruang pada cache halaman. Indeks lain harus persisten. Jika kita kehilangan itu, kita akan kehilangan informasi tentang di mana pada disk lagu mana yang disimpan, dan ini sama saja dengan membersihkan disk. Dan secara umum, saya ingin blok-blok lama, yang sudah lama tidak diakses, untuk digantikan, membuat ruang untuk trek yang lebih populer. Kami telah memilih kebijakan
crowding-out LRU : blok-blok ramai keluar satu menit sekali, 1% blok tetap bebas. Tentu saja, struktur indeks harus aman dari thread, karena kami memiliki 100 ribu koneksi per node. Semua kondisi ini secara ideal dipenuhi oleh
SharedMemoryFixedMap dari pustaka sumber terbuka
satu-nio kami.
Kami menempatkan indeks pada
tmpfs , ia bekerja dengan cepat, tetapi ada nuansa. Ketika mesin restart, semua yang ada di
tmpfs , termasuk indeks, hilang. Selain itu, jika karena
sun.misc.Unsafe proses kami
sun.misc.Unsafe tidak jelas dalam keadaan apa indeks tetap. Karena itu, kami membuat kesan sekali dalam satu jam. Tetapi ini tidak cukup: karena kami menggunakan ekstrusi blok, kami harus mendukung
WAL , di mana kami menulis informasi tentang blok yang diekstrusi. Entri tentang blok dalam gips dan WAL perlu diurutkan entah bagaimana selama pemulihan. Untuk melakukan ini, kami menggunakan blok generasi. Ia memainkan peran sebagai penghitung transaksi global dan bertambah setiap kali indeks berubah. Mari kita lihat contoh cara kerjanya.
Ambil indeks dengan tiga entri: dua blok trek No. 1 dan satu blok trek No. 2.
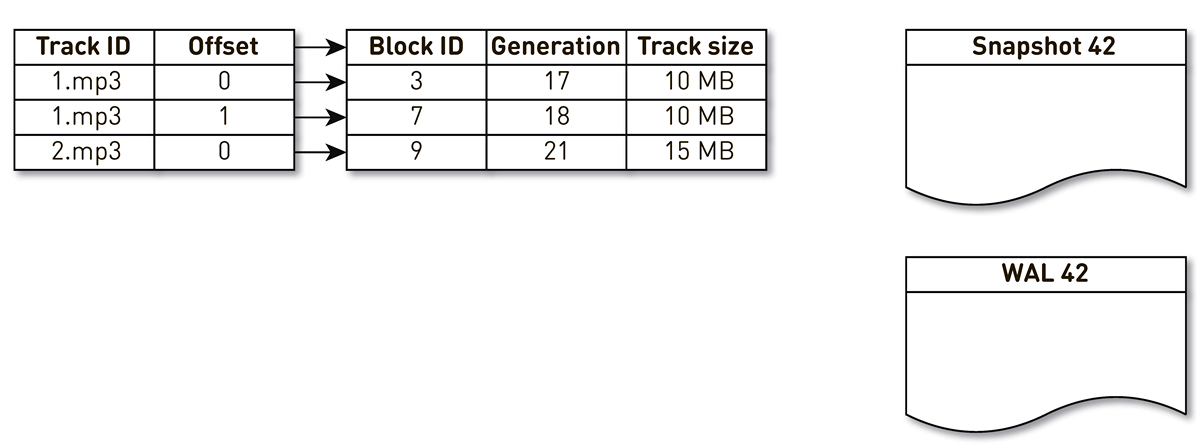
Aliran pembuatan gips terbangun dan diiterasi oleh indeks ini: tupel pertama dan kedua jatuh ke gips. Kemudian aliran crowding beralih ke indeks, menyadari bahwa blok ketujuh belum diakses untuk waktu yang lama, dan memutuskan untuk menggunakannya untuk hal lain. Proses memaksa blok keluar dan menulis catatan ke WAL. Dia dapat memblokir 9, melihat bahwa dia belum dihubungi untuk waktu yang lama, dan juga menandainya sebagai ramai keluar. Di sini pengguna mengakses sistem dan terjadi cache miss - trek diminta yang tidak kami miliki. Kami menyimpan blok lagu ini di repositori kami, menimpa blok 9. Dalam hal ini, generasi bertambah dan menjadi sama dengan 22. Selanjutnya, proses membuat cetakan diaktifkan, yang belum menyelesaikan pekerjaannya, mencapai catatan terakhir dan menulisnya ke cetakan. Akibatnya, kami memiliki dua rekaman langsung dalam indeks, pemeran dan WAL.
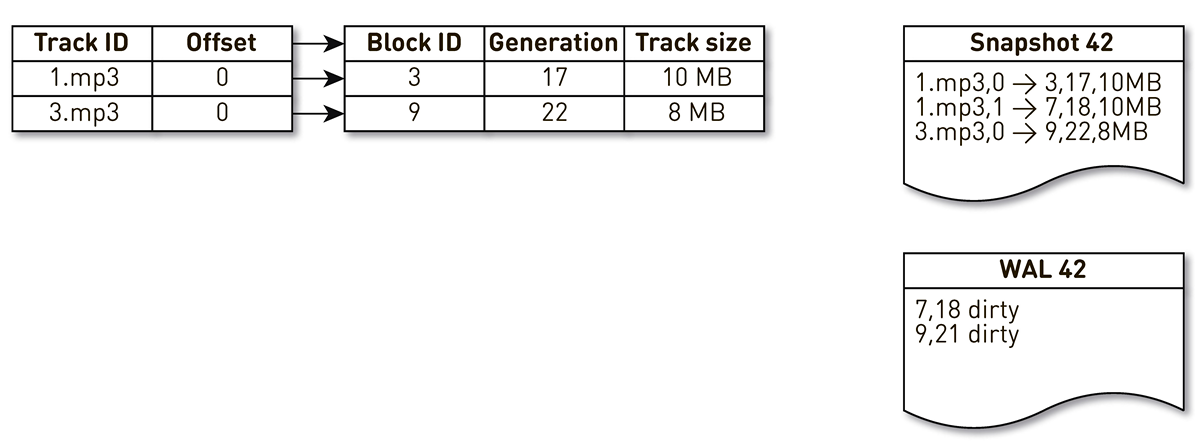
Ketika node saat ini jatuh, itu akan mengembalikan keadaan awal indeks sebagai berikut. Pertama, pindai WAL dan buat peta blok kotor. Kartu menyimpan pemetaan dari nomor blok ke generasi ketika blok ini digantikan.
Setelah itu, kita mulai beralih ke cetakan menggunakan peta sebagai filter. Kami melihat catatan pertama para pemeran, yang berkaitan dengan memblokir nomor 3. Dia tidak disebutkan di antara yang kotor, yang berarti dia masih hidup dan masuk ke dalam indeks. Kita dapat memblokir nomor 7 dengan generasi kedelapan belas, tetapi peta blok yang kotor memberi tahu kita bahwa hanya pada generasi ke-18 blok itu dihadang. Karena itu, tidak masuk dalam indeks. Kita sampai pada catatan terakhir, yang menggambarkan isi blok 9 dengan 22 generasi. Blok ini disebutkan dalam peta blok kotor, tetapi digantikan sebelumnya. Jadi, ini digunakan kembali untuk data baru dan masuk ke dalam indeks. Tujuan tercapai.
Optimalisasi
Tapi bukan itu saja, kita turun lebih dalam.
Mari kita mulai dengan cache halaman. Kami mengandalkannya pada awalnya, tetapi ketika kami mulai melakukan pengujian memuat versi pertama,
ternyata tingkat hit cache halaman tidak mencapai 20%. Mereka menyarankan bahwa masalahnya dibaca di depan: kami tidak menyimpan file, tetapi memblokir, sambil melayani banyak koneksi, dan dalam konfigurasi ini, bekerja dengan disk secara efisien efisien. Kami hampir tidak pernah membaca apa pun secara berurutan. Untungnya, di Linux ada panggilan
posix_fadvise yang memungkinkan Anda untuk memberi tahu kernel bagaimana kita akan bekerja dengan deskriptor file - khususnya, kita dapat mengatakan bahwa kita tidak perlu membaca ke depan dengan melewati flag
POSIX_FADV_RANDOM . Panggilan sistem ini tersedia melalui
one-nio . Dalam operasi, hit cache kami adalah 70-80%. Jumlah pembacaan fisik dari disk menurun lebih dari 2 kali, keterlambatan respons HTTP menurun 20%.
Mari kita melangkah lebih jauh. Layanan ini memiliki ukuran tumpukan yang agak besar. Untuk membuat hidup lebih mudah untuk cache TLB prosesor, kami memutuskan untuk memasukkan Huge Pages untuk proses Java kami. Akibatnya, kami mendapat keuntungan nyata untuk waktu pengumpulan sampah (Waktu GC / Total Waktu Safepoint adalah 20-30% lebih rendah), pemuatan kernel menjadi lebih seragam, tetapi tidak melihat adanya pengaruh pada grafik latensi HTTP.Insiden
Segera setelah layanan dimulai, satu-satunya (sejauh) insiden terjadi.Suatu malam setelah akhir hari kerja, keluhan tentang bermain musik dituangkan dalam dukungan. Pengguna menulis bahwa mereka memasukkan lagu favorit mereka, tetapi setiap beberapa detik mereka mendengar musik aneh dari waktu dan orang lain, dan pemain mengatakan kepada mereka bahwa itu memainkan lagu favorit mereka. Cukup cepat mempersempit lingkaran pencarian ke satu mobil, yang memberi sesuatu yang aneh. Kami menemukan dari log bahwa itu baru saja dimulai kembali. Untuk mempermudah, kami memiliki dua disk dan indeks yang menggambarkan isi blok. Satu indeks mengatakan bahwa blok keempat dari trek Daft Punk terletak di blok nomor 2 dari disk sdc, dan blok nol dari trek Stas Mikhailov terletak di blok nol dari disk sdd.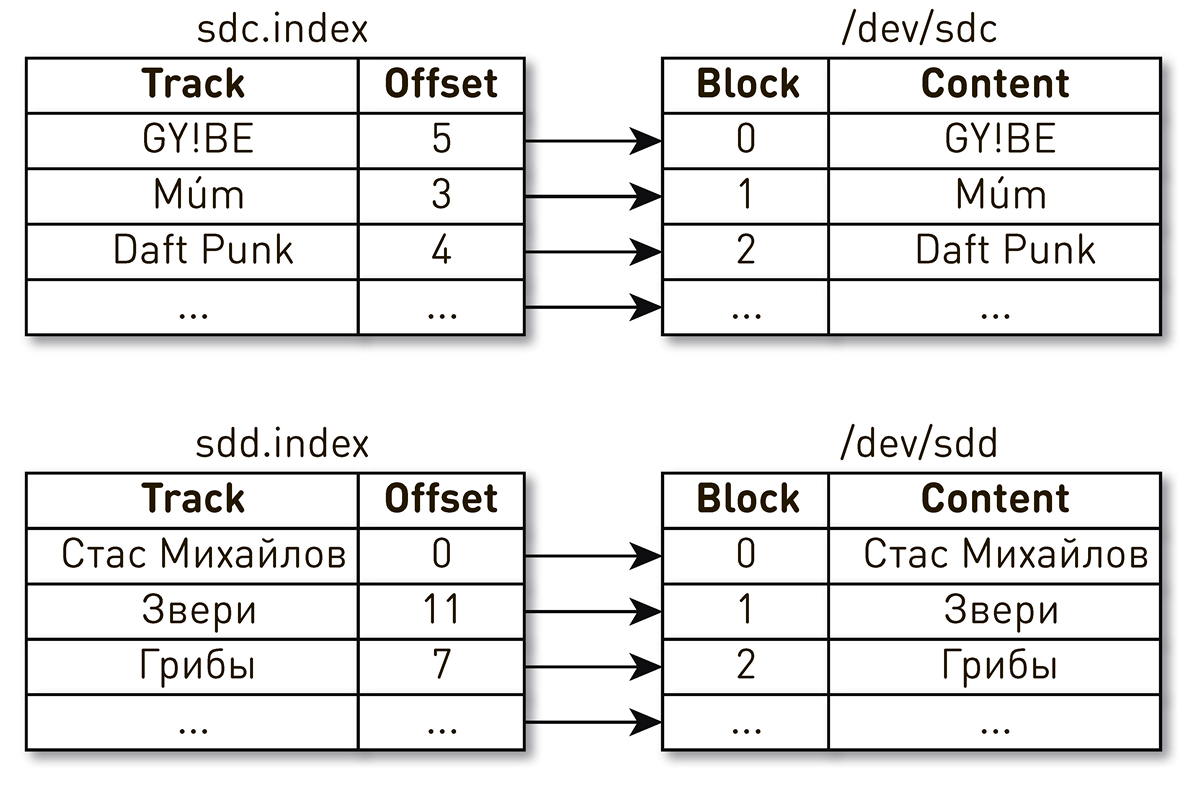 Ternyata setelah me-reboot mesin, nama drive berubah tempat dengan semua konsekuensi berikutnya. Masalah ini terkenal di Linux : jika ada beberapa pengontrol disk di server, maka urutan penamaan disk tidak dijamin.
Ternyata setelah me-reboot mesin, nama drive berubah tempat dengan semua konsekuensi berikutnya. Masalah ini terkenal di Linux : jika ada beberapa pengontrol disk di server, maka urutan penamaan disk tidak dijamin. Perbaiki ternyata sederhana. Ada beberapa jenis ID persisten untuk disk. Kami menggunakan WWN berdasarkan nomor seri disk dan menggunakannya untuk mengidentifikasi indeks, snapshot, dan WAL. Ini tidak mengecualikan pengocokan disk itu sendiri, tetapi tidak peduli bagaimana mereka mengocok, pemetaan indeks pada disk tidak akan dilanggar dan kami akan selalu memberikan data yang benar.
Perbaiki ternyata sederhana. Ada beberapa jenis ID persisten untuk disk. Kami menggunakan WWN berdasarkan nomor seri disk dan menggunakannya untuk mengidentifikasi indeks, snapshot, dan WAL. Ini tidak mengecualikan pengocokan disk itu sendiri, tetapi tidak peduli bagaimana mereka mengocok, pemetaan indeks pada disk tidak akan dilanggar dan kami akan selalu memberikan data yang benar.Analisis insiden
Analisis masalah dalam sistem terdistribusi seperti itu sulit karena permintaan pengguna melewati banyak tahap dan melintasi batas-batas node. Dalam hal CDN, semuanya menjadi lebih rumit, karena untuk CDN, hulu adalah pusat data rumah. Mungkin ada banyak harapan seperti itu. Selain itu, sistem melayani ratusan ribu koneksi pengguna. Cukup sulit untuk memahami pada tahap apa ada masalah dengan pemrosesan permintaan dari pengguna tertentu.Kami menyederhanakan hidup kami seperti ini. Saat masuk, kami menandai semua permintaan dengan tag yang mirip dengan Open Tracing dan Zipkin. Tag ini mencakup pengidentifikasi pengguna, permintaan, dan trek yang diminta. Tag ini di dalam pipeline ditransmisikan dengan semua data dan permintaan yang terkait dengan koneksi saat ini, dan antar node ditransmisikan sebagai header HTTP dan dipulihkan oleh sisi penerima. Saat kami perlu mengatasi masalah, kami mengaktifkan debugging, mencatat tag, menemukan semua catatan yang terkait dengan pengguna tertentu atau melacak, mengagregasi dan mencari tahu bagaimana permintaan diproses sepanjang jalan melalui cluster.Mengirim data
Pertimbangkan skema khas untuk mengirim data dari disk ke soket. Sepertinya tidak ada yang rumit: pilih buffer, baca dari disk ke buffer, kirim buffer ke soket. ByteBuffer buffer = ByteBuffer.allocate(size); int count = fileChannel.read(buffer, position); if (count <= 0) {
Salah satu masalah dengan pendekatan ini adalah bahwa dua salinan data tersembunyi disembunyikan di sini:FileChannel.read() kernel space user space;SocketChannel.write() , user space kernel space.
Untungnya, ada panggilan di Linux sendfile()yang memungkinkan Anda untuk meminta kernel untuk mengirim data dari file ke soket dari offset tertentu secara langsung, melewati penyalinan ke ruang pengguna. Dan tentu saja, panggilan ini tersedia melalui one-nio . Pada tes beban, kami memulai lalu lintas pengguna pada satu node dan memaksa proxy dari node tetangga, yang mengirim data hanya melalui sendfile()- beban prosesor pada 10 Gb / s sendfile()mendekati 0 saat digunakan ,tetapi dalam kasus soket SSL ruang-pengguna, kami tidak bisa manfaatkan sendfile()dan kami tidak punya pilihan selain mengirim data dari file melalui buffer. Dan di sini kita punya kejutan lain. Jika Anda mempelajari sumber SocketChanneldan FileChannel, atau menggunakan Async Profilerdan sistem poprofilirovat dalam proses data kembali dengan cara ini, cepat atau lambat Anda mendapatkan ke kelas sun.nio.ch.IOUtilyang mendidih turun semua panggilan read(), dan write()pada saluran ini. Kode semacam itu disembunyikan di sana. ByteBuffer bb = Util.getTemporaryDirectBuffer(dst.remaining()); try { int n = readIntoNativeBuffer(fd, bb, position, nd); bb.flip(); if (n > 0) dst.put(bb); return n; } finally { Util.offerFirstTemporaryDirectBuffer(bb); }
Ini adalah kumpulan buffer asli. Saat Anda membaca dari file di tumpukan ByteBuffer, pertama perpustakaan standar mengambil buffer dari kumpulan ini, membaca data ke dalamnya, lalu menyalinnya ke tumpukan Anda ByteBuffer, dan mengembalikan buffer asli kembali ke kumpulan. Saat menulis ke soket, hal yang sama terjadi.Skema kontroversial. Di sini one-nio datang untuk menyelamatkan lagi . Kami membuat pengalokasi MallocMT- sebenarnya, ini adalah kumpulan memori. Jika kami memiliki SSL dan kami terpaksa mengirim data melalui buffer, lalu pilih buffer di luar Java heap, bungkus ByteBuffer, baca tanpa menyalin tambahan dari FileChannelbuffer ini dan menulis ke soket. Dan kemudian kita mengembalikan buffer ke pengalokasi. final Allocator allocator = new MallocMT(size, concurrency); int write(Socket socket) { if (socket.getSslContext() != null) { long address = allocator.malloc(size); ByteBuffer buf = DirectMemory.wrap(address, size); int available = channel.read(buf, offset); socket.writeRaw(address, available, flags);
100.000 koneksi per node
Tetapi keberhasilan sistem tidak dijamin dengan implementasi yang masuk akal di tingkat bawah. Ada masalah lain di sini. Konveyor pada setiap node melayani hingga 100 ribu koneksi simultan. Bagaimana mengatur perhitungan dalam sistem seperti itu?Hal pertama yang terlintas dalam pikiran adalah untuk membuat utas eksekusi untuk setiap klien atau koneksi, dan di dalamnya kami melakukan tahapan pipa satu demi satu. Jika perlu, blokir, lalu pindah. Tetapi dengan skema seperti itu, biaya konteks beralih dan tumpukan arus akan berlebihan, karena kita berbicara tentang distributor dan ada banyak aliran. Karena itu, kami pergi ke arah lain.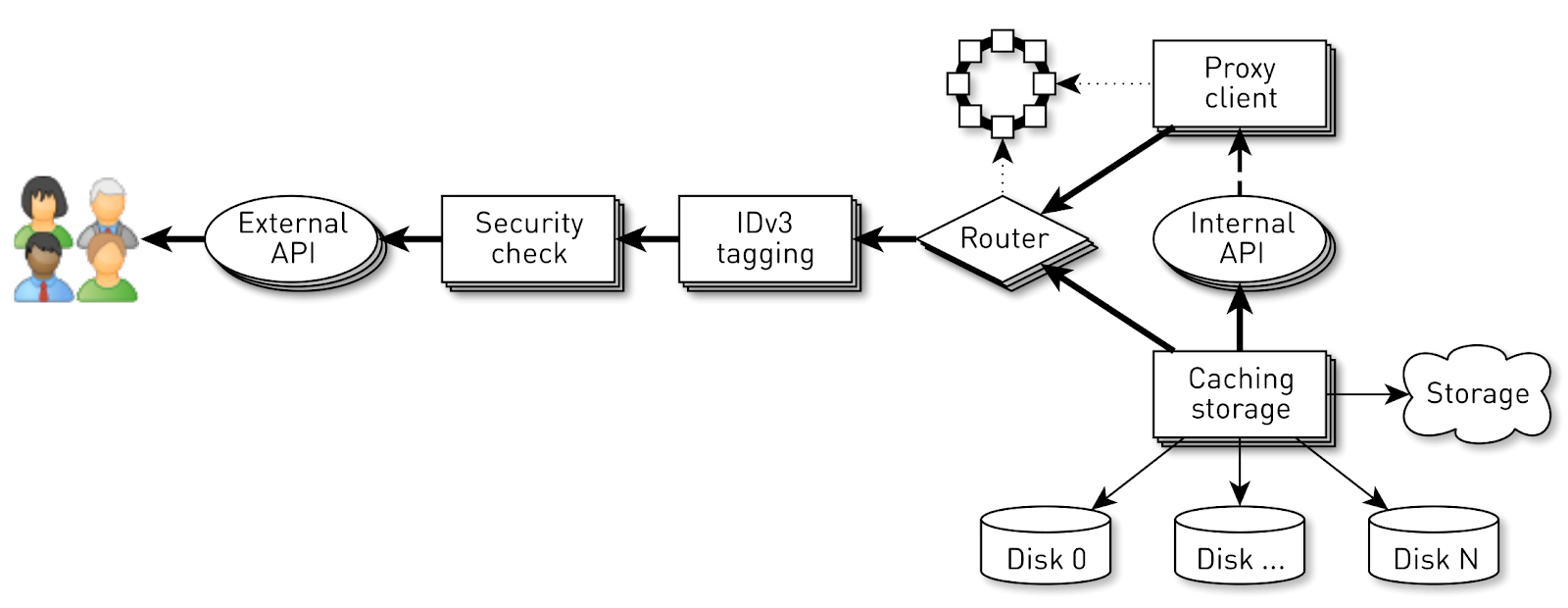 Pipa logis dibuat untuk setiap koneksi, yang terdiri dari tahapan-tahapan yang saling berinteraksi secara asinkron. Setiap tahap memiliki giliran yang menyimpan permintaan yang masuk. Untuk pelaksanaan tahapan, kolam thread umum kecil digunakan. Jika Anda perlu memproses pesan dari antrian permintaan, kami mengambil aliran dari kumpulan, memproses pesan dan mengembalikan aliran ke kumpulan. Dengan skema ini, data didorong dari penyimpanan ke klien.Tetapi skema semacam itu bukan tanpa cacat. Backends jauh lebih cepat daripada koneksi pengguna. Ketika data melewati pipa, itu terakumulasi dalam tahap paling lambat, yaitu pada tahap penulisan blok ke soket koneksi klien. Cepat atau lambat, ini akan menyebabkan runtuhnya sistem. Jika Anda mencoba membatasi antrian pada tahap-tahap ini, maka semuanya akan langsung terhenti, karena jaringan pipa dalam rantai ke soket pengguna akan diblokir. Dan karena mereka menggunakan kumpulan utas bersama, mereka akan memblokir semua utas di dalamnya. Perlu tekanan balik.Untuk melakukan ini, kami menggunakan aliran jet. Inti dari pendekatan ini adalah bahwa pelanggan mengontrol kecepatan data yang berasal dari penerbit menggunakan permintaan. Permintaan berarti berapa banyak lagi data yang siap diproses pelanggan bersama dengan permintaan sebelumnya yang telah diisyaratkannya. Penerbit memiliki hak untuk mengirim data, tetapi tidak melebihi total akumulasi permintaan saat ini, minus data yang sudah dikirim.Dengan demikian, sistem secara dinamis beralih antara mode push dan pull. Dalam mode push, pelanggan lebih cepat dari penerbit, artinya penerbit selalu memiliki permintaan yang tidak memuaskan dari pelanggan, tetapi tidak ada data. Segera setelah data muncul, ia segera mengirimkannya ke pelanggan. Mode tarikan terjadi ketika penerbit lebih cepat dari pelanggan. Artinya, penerbit akan senang mengirim data, hanya permintaan nol. Segera setelah pelanggan mengatakan siap memproses sedikit lagi, penerbit segera mengirimkannya sepotong data sebagai bagian dari permintaan.Konveyor kami berubah menjadi aliran jet. Setiap tahap berubah menjadi penerbit untuk tahap sebelumnya dan pelanggan untuk tahap berikutnya.Antarmuka stream jet terlihat sangat sederhana.
Pipa logis dibuat untuk setiap koneksi, yang terdiri dari tahapan-tahapan yang saling berinteraksi secara asinkron. Setiap tahap memiliki giliran yang menyimpan permintaan yang masuk. Untuk pelaksanaan tahapan, kolam thread umum kecil digunakan. Jika Anda perlu memproses pesan dari antrian permintaan, kami mengambil aliran dari kumpulan, memproses pesan dan mengembalikan aliran ke kumpulan. Dengan skema ini, data didorong dari penyimpanan ke klien.Tetapi skema semacam itu bukan tanpa cacat. Backends jauh lebih cepat daripada koneksi pengguna. Ketika data melewati pipa, itu terakumulasi dalam tahap paling lambat, yaitu pada tahap penulisan blok ke soket koneksi klien. Cepat atau lambat, ini akan menyebabkan runtuhnya sistem. Jika Anda mencoba membatasi antrian pada tahap-tahap ini, maka semuanya akan langsung terhenti, karena jaringan pipa dalam rantai ke soket pengguna akan diblokir. Dan karena mereka menggunakan kumpulan utas bersama, mereka akan memblokir semua utas di dalamnya. Perlu tekanan balik.Untuk melakukan ini, kami menggunakan aliran jet. Inti dari pendekatan ini adalah bahwa pelanggan mengontrol kecepatan data yang berasal dari penerbit menggunakan permintaan. Permintaan berarti berapa banyak lagi data yang siap diproses pelanggan bersama dengan permintaan sebelumnya yang telah diisyaratkannya. Penerbit memiliki hak untuk mengirim data, tetapi tidak melebihi total akumulasi permintaan saat ini, minus data yang sudah dikirim.Dengan demikian, sistem secara dinamis beralih antara mode push dan pull. Dalam mode push, pelanggan lebih cepat dari penerbit, artinya penerbit selalu memiliki permintaan yang tidak memuaskan dari pelanggan, tetapi tidak ada data. Segera setelah data muncul, ia segera mengirimkannya ke pelanggan. Mode tarikan terjadi ketika penerbit lebih cepat dari pelanggan. Artinya, penerbit akan senang mengirim data, hanya permintaan nol. Segera setelah pelanggan mengatakan siap memproses sedikit lagi, penerbit segera mengirimkannya sepotong data sebagai bagian dari permintaan.Konveyor kami berubah menjadi aliran jet. Setiap tahap berubah menjadi penerbit untuk tahap sebelumnya dan pelanggan untuk tahap berikutnya.Antarmuka stream jet terlihat sangat sederhana. Publishermari masukSubscriber , dan ia seharusnya hanya menerapkan empat penangan: interface Publisher<T> { void subscribe(Subscriber<? super T> s); } interface Subscriber<T> { void onSubscribe(Subscription s); void onNext(T t); void onError(Throwable t); void onComplete(); } interface Subscription { void request(long n); void cancel(); }
Subscription memungkinkan Anda memberi sinyal permintaan dan berhenti berlangganan. Tidak ada tempat yang lebih mudah.
Sebagai elemen data, kami tidak melewatkan array byte, tetapi abstraksi seperti chunk. Kami melakukan ini agar tidak menyeret keluar data di heap, jika memungkinkan. Chunk adalah tautan data dengan antarmuka yang sangat terbatas yang memungkinkan Anda hanya membaca data ByteBuffer, menulis ke soket, atau ke file. interface Chunk { int read(ByteBuffer dst); int write(Socket socket); void write(FileChannel channel, long offset); }
Ada banyak implementasi chunks:- Yang paling populer, yang digunakan dalam kasus cache hit dan ketika mengirim data dari disk, adalah implementasi di atas
RandomAccessFile. Potongan hanya berisi tautan ke file, offset dalam file ini dan ukuran data. Ia melewati seluruh pipa, mencapai soket koneksi pengguna, dan di sana berubah menjadi panggilan sendfile(). Artinya, memori tidak dikonsumsi sama sekali. - cache miss : . , — , , — .
- , - heap.
ByteBuffer .
Terlepas dari kesederhanaan API ini, harus aman menurut spesifikasi, dan sebagian besar metode harus non-pemblokiran. Kami memilih jalur dalam semangat Model Aktor yang Diketik, terinspirasi oleh contoh-contoh dari repositori aliran jet resmi . Untuk membuat pemanggilan metode non-pemblokiran, saat kita memanggil metode, kita mengambil semua parameter, membungkusnya dalam pesan, memasukkannya ke dalam antrian untuk dieksekusi, dan mengembalikan kontrol. Pesan dari antrian diproses secara ketat secara berurutan.Tanpa sinkronisasi, kodenya sederhana dan mudah.. publisher subscriber , , executor, .
AtomicBoolean happens before .
:
@Override void request(final long n) { enqueue(new Request(n)); } void enqueue(final M message) { mailbox.offer(message); tryScheduleToExecute(); }
tryScheduleToExecute() :
if (on.compareAndSet(false, true)) { try { executor.execute(this); } catch (Exception e) { ... } }
run() :
if (on.get()) try { dequeueAndProcess(); } finally { on.set(false); if (!messages.isEmpty()) { tryScheduleToExecute(); } } }
dequeueAndProcess() :
M message; while ((message = mailbox.poll()) != null) {
Kami mendapat implementasi yang sepenuhnya non-pemblokiran. Kode sederhana dan konsisten, tanpa volatile, Atomic*, pertengkaran, dan lain-lain. Di seluruh sistem kami, ada total 200 utas untuk melayani 100.000 koneksi.Pada akhirnya
Dalam produksi, kami memiliki 12 mesin, sementara ada lebih dari margin ganda dalam bandwidth. Setiap mesin dalam mode normal memberikan hingga 10 Gbit / s melalui ratusan ribu koneksi. Kami telah menyediakan skalabilitas dan ketahanan. Semuanya ditulis dalam Java dan one-nio .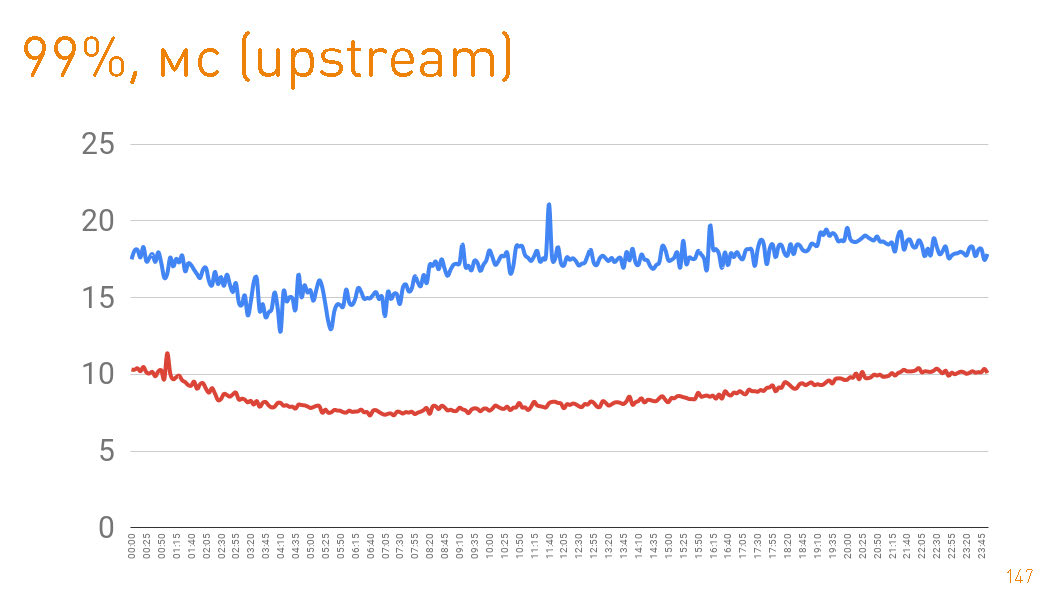 Ini adalah grafik hingga byte pertama yang diberikan kepada pengguna dari sisi server. 99 persentil kurang dari 20 ms. Grafik biru adalah kembalinya data HTTPS ke pengguna. Grafik merah adalah kembalinya data dari replika ke proxy melalui
Ini adalah grafik hingga byte pertama yang diberikan kepada pengguna dari sisi server. 99 persentil kurang dari 20 ms. Grafik biru adalah kembalinya data HTTPS ke pengguna. Grafik merah adalah kembalinya data dari replika ke proxy melalui sendfile()HTTP.Sebenarnya, cache hit dalam produksi adalah 97%, sehingga grafik menggambarkan latensi repositori trek kami, dari mana kami menarik data jika ada cache yang hilang, yang juga tidak buruk, mengingat petabyte data.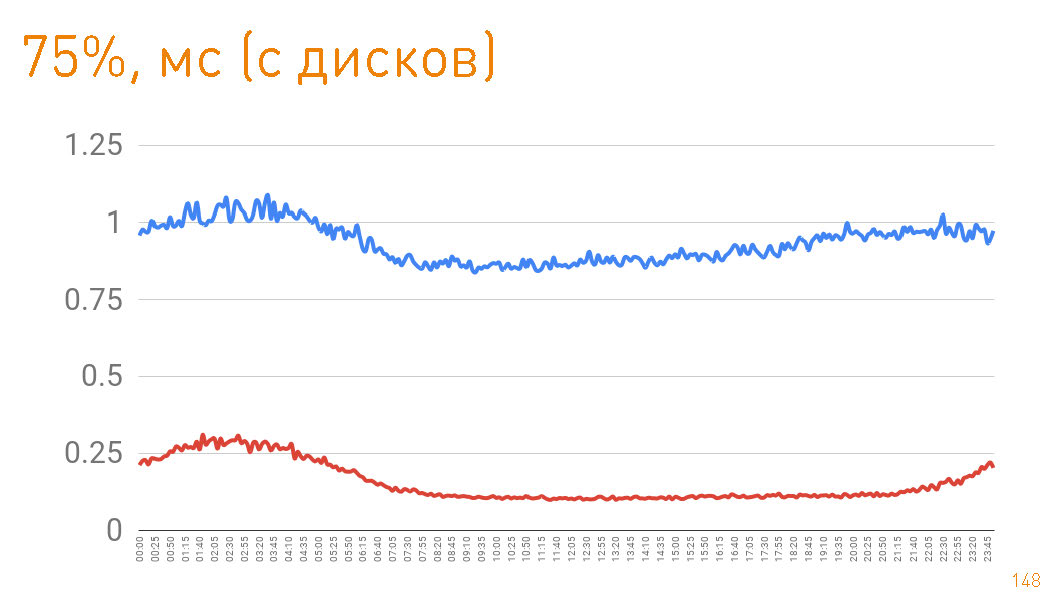 Jika Anda melihat persentil ke-75 ketika kembali dari disk, maka byte pertama terbang ke pengguna setelah 1 ms. Replika di dalam cluster berkomunikasi dengan kecepatan yang lebih besar - mereka bertanggung jawab atas 300 μs.
Jika Anda melihat persentil ke-75 ketika kembali dari disk, maka byte pertama terbang ke pengguna setelah 1 ms. Replika di dalam cluster berkomunikasi dengan kecepatan yang lebih besar - mereka bertanggung jawab atas 300 μs. Yaitu
0,7 ms adalah biaya proksi.Dalam artikel ini, kami ingin menunjukkan bagaimana kami membangun sistem yang terukur dan sarat muatan yang memiliki kecepatan tinggi dan toleransi kesalahan yang sangat baik. Kami berharap kami berhasil.