Baru-baru ini, kami
berbicara tentang cara mendapatkan magang di Google. Selain Google, siswa kami mencoba tangan mereka di JetBrains, Yandex, Acronis, dan perusahaan lain.
Pada artikel ini saya akan berbagi pengalaman magang di
JetBrains Research , berbicara tentang tugas yang mereka selesaikan di sana, dan membahas bagaimana pembelajaran mesin dapat menemukan bug dalam kode program.

Tentang diri saya
Nama saya Egor Bogomolov, saya seorang mahasiswa tahun ke-4 dari gelar sarjana HSE St. Petersburg dalam Matematika Terapan dan Ilmu Komputer. Selama 3 tahun pertama, saya, seperti teman-teman sekelas saya, belajar di Universitas Akademik, dan sejak September kami telah pindah ke Sekolah Tinggi Ekonomi bersama seluruh departemen.
Setelah tahun ke-2 saya melanjutkan magang musim panas di Google Zurich. Di sana saya menghabiskan tiga bulan bekerja di tim Kalender Android, sebagian besar waktu melakukan frontend'om dan sedikit riset UX. Bagian paling menarik dari pekerjaan saya adalah penelitian tentang bagaimana antarmuka kalender akan terlihat di masa depan. Ternyata menyenangkan bahwa hampir semua pekerjaan yang saya lakukan pada akhir magang berakhir di versi utama aplikasi. Tetapi topik magang di Google sangat baik dibahas dalam posting sebelumnya, jadi saya akan berbicara tentang apa yang saya lakukan musim panas ini.
Apa itu JB Research?
JetBrains Research adalah sekumpulan laboratorium yang bekerja di berbagai bidang: bahasa pemrograman, matematika terapan, pembelajaran mesin, robot, dan lainnya. Di setiap daerah ada beberapa kelompok ilmiah. Berdasarkan arahan saya, saya paling mengenal kegiatan kelompok di bidang pembelajaran mesin. Masing-masing dari mereka menyelenggarakan seminar mingguan di mana anggota kelompok atau tamu undangan berbicara tentang pekerjaan mereka atau artikel menarik di bidang mereka. Banyak siswa dari HSE datang ke seminar ini, karena mereka pergi ke seberang jalan dari gedung utama Kampus HSE di St. Petersburg.
Di program sarjana kami, kami wajib terlibat dalam pekerjaan penelitian (R&D) dan mempresentasikan hasil penelitian dua kali setahun. Seringkali pekerjaan ini secara bertahap berkembang menjadi magang musim panas. Ini juga terjadi dengan pekerjaan penelitian saya: musim panas ini saya magang di laboratorium "Metode Pembelajaran Mesin dalam Rekayasa Perangkat Lunak" dengan penyelia riset saya Timofey Bryksin. Tugas yang sedang dikerjakan di laboratorium ini meliputi saran refactoring otomatis, analisis gaya kode untuk programmer, penyelesaian kode, dan mencari kesalahan dalam kode program.
Magang saya berlangsung dua bulan (Juli dan Agustus), dan pada musim gugur saya terus terlibat dalam tugas-tugas yang ditugaskan dalam kerangka penelitian. Saya bekerja di beberapa area, yang paling menarik dari mereka, menurut saya, adalah pencarian bug secara otomatis dalam kode, dan saya ingin membicarakannya. Titik awalnya adalah
artikel oleh Michael Pradel .
Pencarian bug otomatis
Bagaimana bug dicari sekarang?
Mengapa mencari bug lebih atau kurang jelas. Mari kita lihat bagaimana keadaan mereka sekarang. Detektor bug modern sebagian besar didasarkan pada analisis kode statis. Untuk setiap jenis kesalahan, cari pola yang sebelumnya diperhatikan yang dapat ditentukan. Kemudian, untuk mengurangi jumlah positif palsu, heuristik ditemukan, diciptakan untuk setiap kasus individu. Pola dapat dicari baik dalam pohon sintaksis abstrak (AST) yang dibangun oleh kode dan dalam grafik dari aliran kontrol atau data.
int foo() { if ((x < 0) || x > MAX) { return -1; } int ret = bar(x); if (ret != 0) { return -1; } else { return 1; } }
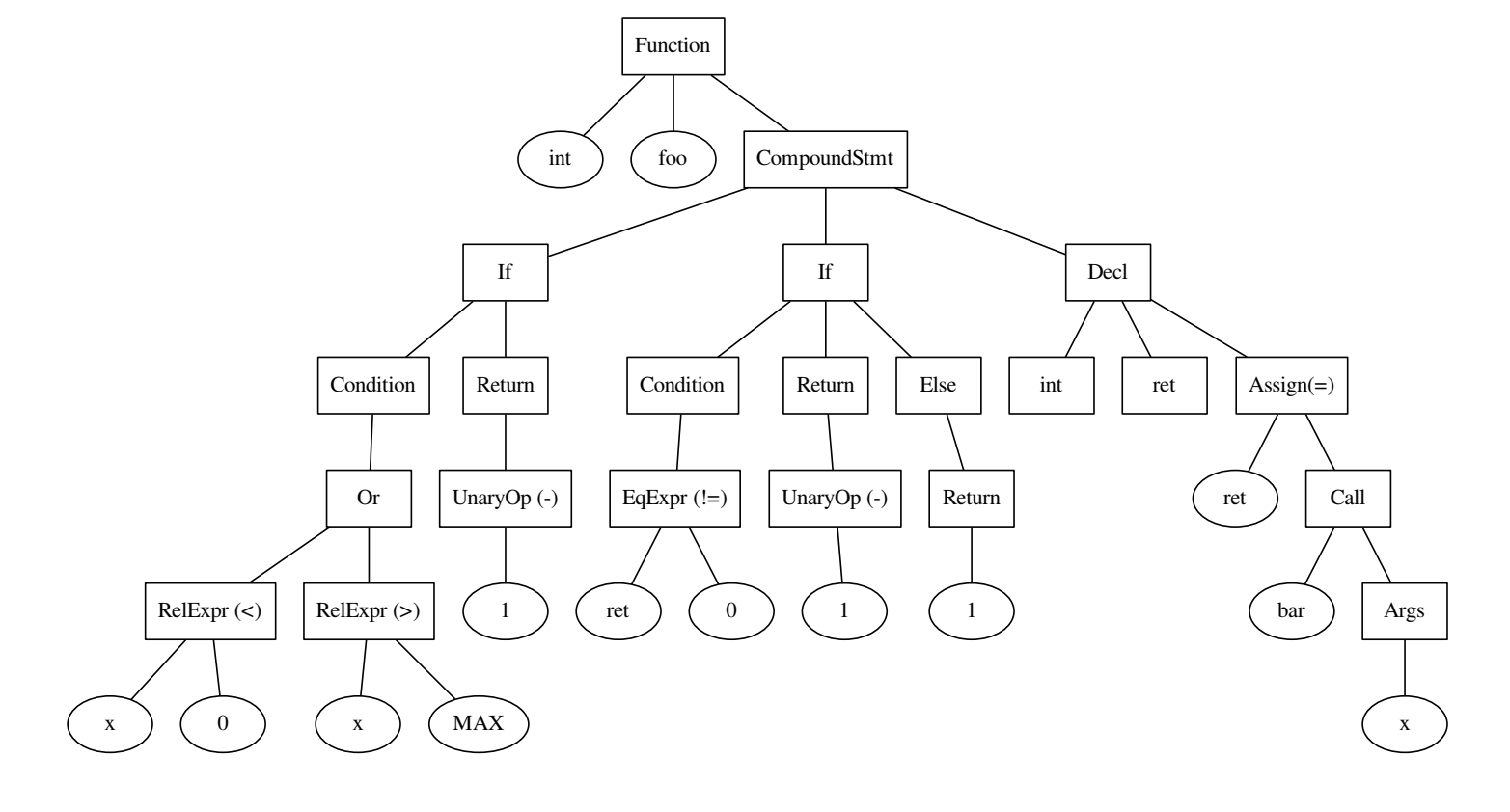
Kode dan pohon yang dibangun di atasnya.
Untuk memahami cara kerjanya, pertimbangkan sebuah contoh. Jenis bug dapat berupa penggunaan = bukannya == di C ++. Mari kita lihat bagian kode berikut:
int value = 0; … if (value = 1) { ... } else { … }
Ada kesalahan dalam ekspresi kondisional, sedangkan yang pertama = dalam penugasan nilai ke variabel sudah benar. Pola berasal dari sini: jika tugas digunakan di dalam kondisi in, ini adalah bug potensial. Mencari pola seperti itu di AST, kita dapat mendeteksi kesalahan dan memperbaikinya.
int value = 0; … if (value == 1) { ... } else { … }
Dalam kasus yang lebih umum, kita tidak akan dapat dengan mudah menemukan cara untuk menggambarkan kesalahan. Misalkan kita ingin menentukan urutan operan yang benar. Sekali lagi, lihat fragmen kode:
for (int i = 2; i < n; i++) { a[i] = a[1 - i] + a[i - 2]; }
int bitReverse(int i) { return 1 - i; }
Dalam kasus pertama, penggunaan 1-i salah, dan yang kedua sepenuhnya benar, yang jelas dari konteksnya. Tetapi bagaimana menggambarkannya dalam bentuk pola? Dengan komplikasi jenis kesalahan, kita harus mempertimbangkan bagian kode yang lebih besar dan menganalisis lebih banyak kasus individual.
Contoh motivasi terakhir: informasi berguna juga terkandung dalam nama metode dan variabel. Bahkan lebih sulit untuk diungkapkan oleh beberapa kondisi yang ditentukan secara manual.
int getSquare(int xDim, int yDim) { … } int x = 3, y = 4; int s = getSquare(y, x);
Seseorang memahami bahwa, kemungkinan besar, argumen dalam pemanggilan fungsi dicampuradukkan, karena kita memiliki pemahaman bahwa x lebih mirip xDim daripada yDim. Tetapi bagaimana cara melaporkan ini ke detektor? Anda dapat menambahkan beberapa jenis heuristik dari bentuk "nama variabel adalah awalan dari nama argumen", tetapi anggaplah x lebih sering lebar daripada tinggi, jadi tidak lagi dinyatakan.
Total: masalah dari pendekatan modern untuk menemukan kesalahan adalah bahwa banyak pekerjaan harus dilakukan dengan tangan Anda: untuk menentukan pola, menambahkan heuristik, karena ini, menambahkan dukungan untuk jenis kesalahan baru di detektor menjadi memakan waktu. Selain itu, sulit untuk menggunakan bagian penting dari informasi yang ditinggalkan oleh pengembang dalam kode: nama-nama variabel dan metode.
Bagaimana pembelajaran mesin dapat membantu?
Seperti yang mungkin Anda perhatikan, dalam banyak contoh kesalahan dapat dilihat oleh manusia, tetapi sulit untuk dijelaskan secara formal. Dalam situasi seperti itu, metode pembelajaran mesin sering dapat membantu. Mari kita memikirkan pencarian untuk menyusun ulang argumen dalam panggilan fungsi dan memahami apa yang kita butuhkan untuk mencari mereka menggunakan pembelajaran mesin:
- Sejumlah besar kode sampel tanpa bug
- Sejumlah besar kode dengan kesalahan jenis tertentu
- Metode untuk memvariasikan potongan kode
- Model yang akan kami ajarkan untuk membedakan antara kode dengan dan tanpa kesalahan
Kita bisa berharap bahwa dalam sebagian besar kode yang diletakkan di domain publik, argumen dalam panggilan fungsi berada dalam urutan yang benar. Oleh karena itu, untuk kode sampel tanpa bug, Anda dapat mengambil beberapa dataset besar. Dalam kasus penulis artikel asli, itu adalah JS 150K (150 ribu file dalam Javascript), dalam kasus kami, dataset serupa untuk Python.
Menemukan kode dengan bug jauh lebih sulit. Tapi kita tidak bisa mencari kesalahan orang lain, tetapi lakukan sendiri! Untuk jenis kesalahan, Anda perlu menentukan fungsi yang, menurut bagian kode yang benar, akan membuatnya rusak. Dalam kasus kami, atur ulang argumen dalam panggilan fungsi.
Bagaimana cara membuat vektor kode?
Berbekal banyak kode baik dan buruk, kami hampir siap untuk mengajarkan sesuatu. Sebelum itu, kita masih perlu menjawab pertanyaan: bagaimana menyajikan fragmen kode?
Panggilan fungsi dapat direpresentasikan sebagai tupel nama metode, nama metodenya, nama dan tipe argumen yang diteruskan ke variabel. Jika kita belajar bagaimana membuat vektor token individu (nama variabel dan metode, semua "kata" yang ditemukan dalam kode), maka kita dapat mengambil gabungan vektor-vektor token yang menarik bagi kita dan mendapatkan vektor yang diinginkan untuk fragmen.
Untuk membuat vektor token, mari kita lihat bagaimana kata-kata dalam teks biasa membuat vektor. Salah satu cara paling sukses dan populer adalah word2vec yang diusulkan pada 2013.
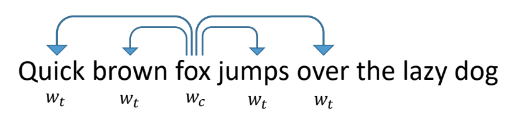
Ini berfungsi sebagai berikut: kami mengajarkan jaringan untuk memprediksi dengan kata kata lain yang muncul di sebelahnya dalam teks. Dalam hal ini, jaringan terlihat seperti lapisan input ukuran kamus, lapisan tersembunyi ukuran vektorisasi yang ingin kita terima, dan lapisan output, juga ukuran kamus. Selama pelatihan, jaringan diberi makan dengan vektor unit input dengan satu unit di tempat kata yang dipertanyakan (rubah), dan pada output kami ingin mendapatkan kata-kata yang terjadi di dalam jendela di sekitar kata ini (cepat, coklat, melompat, lebih). Dalam hal ini, jaringan pertama-tama menerjemahkan semua kata menjadi vektor pada lapisan tersembunyi, dan kemudian membuat prediksi.
Vektor yang dihasilkan untuk setiap kata memiliki sifat yang baik. Sebagai contoh, vektor kata dengan makna yang mirip dekat satu sama lain, dan jumlah dan perbedaan vektor adalah penambahan dan perbedaan dari "makna" kata-kata.
Untuk membuat vektorisasi token yang serupa dalam kode, Anda perlu mengatur lingkungan yang akan diprediksi. Mereka mungkin informasi dari AST: jenis simpul di sekitar, token yang ditemukan, posisi di pohon.
Setelah menerima vektorisasi, Anda dapat melihat token mana yang mirip satu sama lain. Untuk melakukan ini, hitung jarak cosinus di antara mereka. Akibatnya, vektor tetangga berikut diperoleh untuk Javascript (angka adalah jarak kosinus):
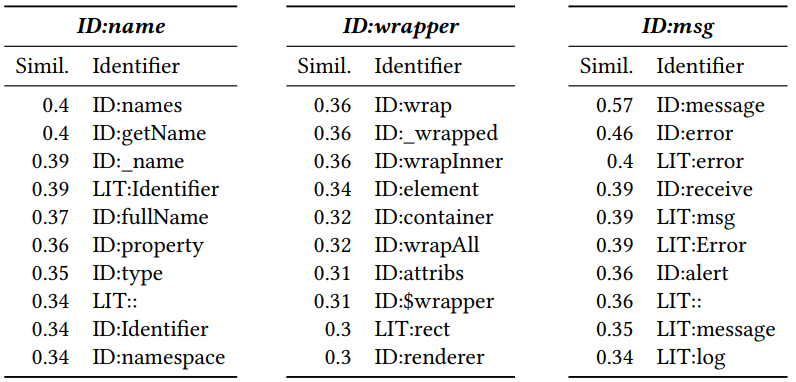
ID dan LIT yang ditambahkan di awal menunjukkan apakah token adalah pengidentifikasi (nama variabel, metode) atau literal (konstan). Dapat dilihat bahwa kedekatan itu bermakna.
Pelatihan Klasifikasi
Setelah menerima vektorisasi untuk token individu, mendapatkan tampilan untuk sepotong kode dengan potensi kesalahan cukup sederhana: ini adalah gabungan dari vektor-vektor yang penting untuk klasifikasi token. Perceptron dua lapis dilatih dalam potongan kode dengan ReLU sebagai fungsi aktivasi dan putus untuk mengurangi overfitting. Belajar konvergen dengan cepat, model yang dihasilkan kecil dan dapat membuat prediksi untuk ratusan contoh per detik. Ini memungkinkan Anda untuk menggunakannya secara waktu nyata, yang akan dibahas nanti.
Hasil
Penilaian kualitas dari classifier yang dihasilkan dibagi menjadi dua bagian: evaluasi pada sejumlah besar contoh yang dibuat secara artifisial dan verifikasi manual pada sejumlah kecil (50 untuk setiap detektor) dari contoh dengan probabilitas prediksi tertinggi. Hasil untuk tiga detektor (argumen disusun ulang, kebenaran dari operator biner dan operan biner) adalah sebagai berikut:
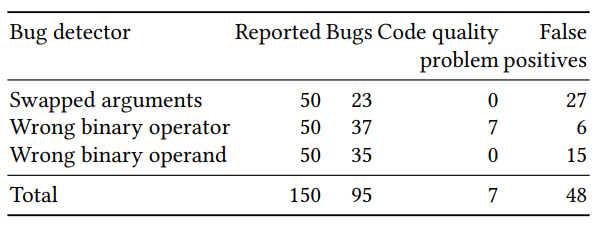
Beberapa kesalahan yang diprediksi akan sulit ditemukan dengan metode pencarian klasik. Contoh dengan pengaturan ulang dan kesalahan dalam panggilan ke p.done:
var p = new Promise (); if ( promises === null || promises . length === 0) { p. done (error , result ) } else { promises [0](error, result).then( function(res, err) { p.done(res, err); }); }
Ada juga contoh di mana tidak ada kesalahan, tetapi variabel harus dinamai ulang agar tidak menyesatkan orang yang mencoba mencari tahu kode. Misalnya, menambahkan lebar dan masing-masing tampaknya bukan ide yang baik, meskipun ternyata tidak menjadi bug:
var cw = cs[i].width + each;
Porting Python
Saya terlibat dalam porting karya Michael Pradel dari js ke python, dan kemudian membuat plug-in untuk PyCharm yang mengimplementasikan inspeksi berdasarkan metode yang dijelaskan di atas. Kami menggunakan dataset
Python 150K (150 ribu file Python tersedia di GitHub).
Pertama, ternyata di Python ada lebih banyak token yang berbeda daripada di javascript. Untuk js, 10.000 token paling populer menyumbang lebih dari 90% dari semua yang ditemui, sementara untuk Python perlu menggunakan sekitar 40.000.Ini menyebabkan peningkatan ukuran token dalam vektor, yang membuat porting ke plugin sulit.
Kedua, setelah menerapkan untuk Python mencari argumen yang salah dalam panggilan fungsi dan melihat hasil secara manual, saya mendapat tingkat kesalahan lebih dari 90%, yang berbeda dengan hasil untuk js. Setelah mengerti alasannya, ternyata dalam javascript lebih banyak fungsi dideklarasikan dalam file yang sama dengan panggilan mereka. Saya, mengikuti contoh penulis artikel, pada awalnya tidak mengizinkan deklarasi fungsi dari file lain, yang menyebabkan hasil yang buruk.
Menjelang akhir Agustus, saya menyelesaikan implementasi untuk Python dan menulis dasar untuk plugin tersebut. Plugin ini terus dikembangkan, sekarang siswa Anastasia Tuchina dari laboratorium kami terlibat dalam ini.
Anda dapat menemukan langkah-langkah untuk mencoba cara kerja plugin di wiki repositori.
Tautan di github:
Repositori dengan implementasi pythonRepositori dengan plugin