
Anda dapat menemukan sejumlah besar berbagai artikel di jaringan tentang metode untuk menggunakan algoritma statistik matematika, tentang jaringan saraf, dan tentang manfaat pembelajaran mesin secara umum. Area-area ini berkontribusi pada peningkatan yang signifikan dalam kehidupan manusia dan masa depan robot yang lebih cerah. Misalnya, generasi baru tanaman yang mampu bekerja secara penuh atau sebagian tanpa campur tangan manusia atau mesin autopilot.
Pengembang menggabungkan kombinasi pendekatan ini dan metode pembelajaran mesin dalam arah yang berbeda. Daerah-daerah ini kemudian menerima nama, asli dan tidak terlalu, misalnya: IOT (Internet Of Things), WOT (Web Of Things), Industri 4.0 (Industri 4.0), Kecerdasan Buatan (AI) dan lainnya. Konsep-konsep ini disatukan oleh fakta bahwa deskripsi mereka adalah tingkat atas, yaitu, tidak ada alat dan teknologi khusus yang dipertimbangkan, mereka juga tidak siap untuk mengimplementasikan sistem, dan tujuan utamanya adalah untuk memvisualisasikan hasil yang diinginkan. Tetapi teknologi sudah ada, meskipun seringkali tidak memiliki platform tunggal.
Solusi ini disediakan oleh kedua vendor perangkat lunak besar: SAS, SAP, Oracle, IBM, serta startup kecil yang membuat persaingan kuat untuk pemain besar, serta solusi open source - solusi open source. Semua keragaman ini sangat menyulitkan pelaksanaan tugas yang cepat dan efektif, karena membutuhkan integrasi yang melelahkan dari berbagai sistem di antara mereka sendiri, upaya besar pengembang untuk membuat model pembelajaran mesin yang baik dan implementasi masa depan dari solusi ini dengan cara yang produktif. Tetapi pada saat yang sama, kriteria utama untuk keberhasilan setiap proyek inovasi yang mengubah pendekatan perusahaan untuk melakukan bisnis seringkali memerlukan bukti cepat keberhasilan dan solvabilitas, jika tidak, tidak ada yang berani untuk meluncurkannya. Dan ini tidak mungkin tanpa menggunakan platform tunggal yang akan memungkinkan Anda untuk dengan cepat menyelesaikan seluruh siklus persiapan (pencarian, pengumpulan, pembersihan, konsolidasi) data dan mendapatkan hasil akhir dalam bentuk analitik berkualitas tinggi (termasuk menggunakan algoritma pembelajaran mesin), dan, sebagai hasilnya, untung untuk perusahaan.
Tentang SAS
Banyak yang mungkin setuju bahwa SAS memiliki posisi tinggi di pasar untuk solusi analitik lanjutan. Ulasan solusi SAS mungkin berbeda, tetapi tidak ada yang acuh tak acuh, yang dikonfirmasi oleh kehadiran sejumlah besar pelanggan di Rusia dan di dunia. Sebagian besar berkat algoritma dan model siap pakai yang dapat dengan mudah dan cepat diimplementasikan di perusahaan dan dengan cepat mendapatkan hasilnya. Banyak yang telah ditulis tentang ini di artikel pertama di blog SAS - Anda dapat membacanya di sini . Artikel ini menjelaskan latar belakang kesuksesan SAS dan sejarahnya. Tetapi komunitas TI dan bisnis berkembang pesat dan menjadi lebih banyak alat yang dibutuhkan, sehingga SAS telah merilis platform analitik baru, SAS Viya. Platform ini mencakup semua yang terbaik yang telah dibuat oleh SAS sejak awal hingga saat ini, untuk menentukan tren terkini di kelas solusi untuk analitik lanjutan. Kembali ke nama dan definisi yang indah, SAS Viya menyediakan platform terpadu untuk arah seperti ilmu data swalayan menggunakan kemampuan dalam memori, yang dikembangkan menggunakan pendekatan komputasi terdistribusi (cloud) dan arsitektur layanan mikro. Jadi, artikel ini membuka serangkaian artikel tentang platform SAS Viya, untuk memilah apa itu Viya, apa yang bisa dan bagaimana menggunakannya.
Sulit memilih
Kami telah menemukan bahwa sekarang di pasar ada sejumlah besar produk dari vendor terkenal dan pemain yang lebih kecil, serta open source, yang memungkinkan Anda untuk menyelesaikan berbagai masalah analitis di semua bidang bisnis. Kriteria apa, kecuali untuk harga, yang harus diperhitungkan ketika memutuskan pilihan platform tertentu?

Untuk mulai dengan, sekarang pengguna bisnis menjadi lebih dan lebih terlibat dalam siklus analitik penuh dan membutuhkan kemandirian yang lebih besar dari TI. Kriteria yang dimengerti oleh para pengguna ini menjadi yang terdepan - kemudahan penggunaan (antarmuka tunggal), minimalisasi pembelajaran sistem baru (lebih sedikit kode, lebih banyak grafis), kinerja (dalam hal analitik - ini adalah kemampuan untuk dengan cepat mendapatkan hasil pada set data besar), ketersediaan algoritma dan model yang sudah jadi untuk bekerja. Waktu untuk layar hitam hampir habis, jendela terminal, meskipun dalam bentuk yang berbeda, masih tersedia dan memungkinkan Anda untuk menulis dan men-debug kode saat bepergian, tetapi sebagian besar fungsi sudah dapat diimplementasikan sebagai blok dalam antarmuka grafis, yang membuka pintu bagi setiap pengguna level untuk bekerja dengan analitik tingkat lanjut (meskipun masih diinginkan untuk mengetahui matematika).
Tren kedua yang mau tak mau menaklukkan pasar adalah teknologi cloud. Dari sudut pandang perusahaan, ini adalah kemungkinan pengelolaan sumber daya yang tersedia yang fleksibel untuk proyek apa pun. Ada banyak penelitian tentang waktu ketika teknologi cloud telah sepenuhnya menggantikan solusi klasik. Tetapi di sini penting untuk memahami bahwa komputasi awan bukan hanya perangkat keras yang hidup di suatu tempat yang jauh di pusat data eksternal, tetapi juga pendekatan yang sangat fleksibel dalam menyediakan semua jenis layanan dalam bentuk layanan yang dapat diperoleh dengan cepat dan tanpa perlu membangun atau membangun kembali infrastruktur TI yang kompleks.
Tren lain adalah penggunaan teknologi Big Data. Dan penggunaan seluruh ekosistem Hadoop secara keseluruhan dengan bahasa dan teknologinya sendiri, serta sistem open source lain yang tersedia yang menyediakan antarmuka untuk bekerja dengan data, seperti R, Python dan lainnya. Tidak ada gunanya bersaing di bidang ini, tetapi masuk akal untuk memiliki teknologi untuk diintegrasikan dengan ekosistem ini. Atau tidak hanya mengintegrasikan, tetapi menggunakan kemampuan ekosistem ini seperti halnya dengan SAS Hadoop Embedded Process atau menggunakan Kafka untuk membangun Ketersediaan Tinggi untuk sistem ESP (SAS Event Stream Processing). Dan kadang-kadang bahkan meningkatkan dan mempercepat, seperti kemampuan untuk menjalankan kode R pada mesin CAS di SAS Viya.
Platform universal
Permintaan menciptakan pasokan dan SAS Viya tidak terkecuali aturan. Jika kita merujuk pada definisi resmi SAS Viya, yang diberikan oleh Jim Goodnight (sangat berkurang, tetapi maknanya tetap dipertahankan) selama pengumuman pada 2016 di forum SAS global, maka SAS Viya adalah: “Sistem cloud yang menggunakan pendekatan komputasi terdistribusi ... dan memberikan platform analitik terpadu
Nah, jika Anda menyatakan secara singkat ide dan tujuan platform SAS Viya, maka ini adalah platform universal untuk semua jenis analisis di semua tahap proyek, mulai dari persiapan data hingga penggunaan algoritme pembelajaran mesin yang kompleks. Ada 4 blok tugas:
1. Persiapan data
2. Visualisasi dan penelitian data
3. Analisis prediktif
4. Analisis lanjutan dalam bentuk algoritma pembelajaran mesin
Informasi untuk Pembaca
Karena agak sulit untuk mengatakan semuanya dalam kerangka satu artikel tanpa mengurangi nuansa penting, langkah-langkah ini akan dipertimbangkan dalam artikel berikut dengan contoh. Pada artikel ini, kami akan mempertimbangkan topik penting dari mesin SAS Viya, yang menyediakan kerja cepat alat analitik. Artikel tentang antarmuka modern dan indah adalah yang berikutnya.
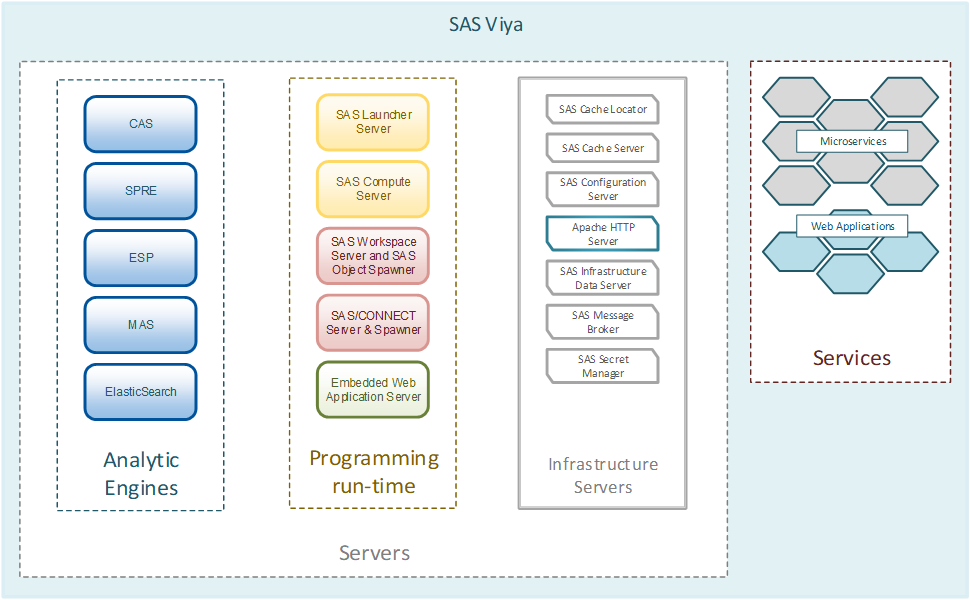
Dasar dari platform SAS Viya
SAS Viya memiliki beberapa fitur utama untuk memulai. Mereka yang telah bekerja dengan solusi SAS tahu bahwa SAS didasarkan pada bahasa analitik SAS Base khusus, yang melakukan tugas analitis pada mesinnya. Ini dapat digunakan dalam konfigurasi Grid pada cluster atau pada satu mesin komputasi yang kuat. Di sinilah letak perbedaan utama antara SAS Viya dan solusi analitik SAS 9. SAS Viya didasarkan pada mesin pemrosesan data
CAS (Cloud Analytics Service) yang unik dan baru. Dua fitur utama: yang pertama adalah teknologi dalam memori yang melakukan semua operasi dengan data dalam RAM, dan yang kedua adalah pendekatan komputasi terdistribusi. CAS dapat berjalan pada satu host, tetapi dioptimalkan untuk bekerja pada sekelompok mesin - pengontrol dan server pemrosesan data, yang memungkinkan Anda untuk menyimpan dan memproses data pada node yang berbeda dari cluster untuk memparalelkan beban (pendekatan konseptual sangat dekat dengan konsep sistem Hadoop). Jika kita menunjukkan arsitektur CAS dalam diagram, kita mendapatkan gambar berikut untuk instalasi MPP atau SMP:

Mengapa cloud?
SAS, ketika mengembangkan platform Viya, dan CAS pada khususnya, mengambil keuntungan dari konsep komputasi awan. Mereka dapat dibagi menjadi 4 kelompok:
1. Aksesibilitas melalui sejumlah besar API klien yang berbeda. Bagi SAS, ini adalah langkah maju yang besar. Tidak ada batasan lagi untuk hanya menggunakan bahasa SAS Base untuk analitik. Anda dapat menggunakan Python (misalnya, dari Notebook Jupiter), R, Lua, dll., Yang akan dieksekusi di CAS pada platform SAS Viya.
2. Elastisitas. Anda dapat dengan mudah skala sistem dengan menghubungkan / memutuskan node cluster CAS. Aplikasi dapat diakses melalui web dan diatur sebagai layanan microser. Mereka independen satu sama lain dalam hal pemasangan, pemutakhiran dan operasi.
3. Ketersediaan tinggi. CAS menggunakan sistem mirroring data antara node cluster. Satu set data disimpan pada beberapa node, yang mengurangi risiko kehilangan data. Pergantian jika terjadi kegagalan salah satu node terjadi secara otomatis sambil mempertahankan status tugas, yang seringkali penting untuk perhitungan analitik yang berat.
4. Peningkatan keamanan. Karena cloud dapat diperoleh dari penyedia publik, implementasinya harus memenuhi persyaratan yang lebih ketat untuk keandalan saluran transmisi data.
Anda dapat menggunakan platform Viya di mana saja - di cloud, pada mesin khusus di pusat data Anda sendiri, di sekelompok mesin apa pun. Toleransi kesalahan dari solusi disediakan secara otomatis.
Bagaimana cara kerja CAS?
Saya akan menganalisis operasi CAS menggunakan contoh instalasi MPP. SMP menyederhanakan, tetapi mempertahankan prinsip-prinsip CAS. Dalam kehidupan nyata, SMP dapat digunakan sebagai uji lingkungan lokal untuk menguji model dengan transfer pengembangan selanjutnya ke platform MPP untuk kinerja yang lebih baik.
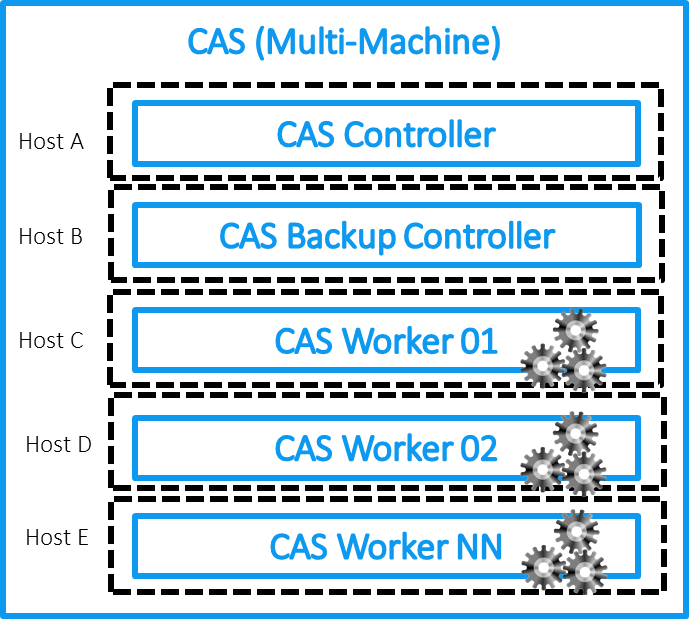
Mari kita lihat lagi arsitektur CAS tingkat atas di SAS Viya:
Jika kita berbicara tentang CAS, maka itu terdiri dari sebuah pengontrol, dengan cara lain, sebuah master node (plus dimungkinkan untuk mengalokasikan node lain untuk node pengontrol cadangan) dan work node. Master node menyimpan meta-informasi tentang data yang terletak di node cluster dan bertanggung jawab untuk mendistribusikan permintaan ke node ini (Pekerja CAS) yang memproses dan menyimpan data. Secara terpisah, server dialokasikan di mana ada layanan analitis dan modul tambahan yang diperlukan agar platform dapat berfungsi. Mungkin juga ada beberapa tergantung pada tugas. Misalnya, Anda dapat menggunakan server untuk SPRE (SAS Programming Runtime Environment), yang memungkinkan Anda untuk menjalankan tugas SAS 9 klasik pada platform Viya menggunakan CAS dan SPRE, pada mesin terpisah dalam kerangka instalasi Viya.
Ada konfigurasi menarik yang memperluas kemungkinan menggunakan CAS pada platform Viya, dan membenarkan huruf pertama namanya Cloud:
Multitenancy menyediakan kemampuan untuk berbagi sumber daya dan data antar departemen. Pada saat yang sama, "penyewa" diberi antarmuka tunggal untuk mengakses platform dan pemisahan logis dari berbagai fungsi platform Viya disediakan. Ada banyak pilihan. Mungkin masalah ini akan dipertimbangkan dalam artikel terpisah.
Bagaimana dengan keandalan RAM dan cara memuat data ke CAS?
Karena kita berbicara tentang analitik, dan terutama tentang solusi canggih untuk analitik lanjutan, jelas bahwa kita berbicara tentang sejumlah besar data. Dan bagian penting dari proses ini adalah pemuatan data yang cepat ke dalam RAM untuk operasi bersamanya dan memastikan ketersediaan data yang tinggi.
Setiap sistem dalam memori untuk keandalan memerlukan pencadangan data yang ada dalam RAM. RAM tidak tahu bagaimana mempertahankan keadaan ketika daya dimatikan, ditambah semua data mungkin tidak cocok di bidang RAM, dan mekanisme diperlukan untuk dengan cepat memuat ulang data dalam RAM. Karenanya, untuk tabel yang dimuat ke CAS untuk analitik, salinan dibuat di area memori hanya baca dari format SASHDAT khusus. Untuk memastikan ketersediaan tinggi, file-file ini dicerminkan pada beberapa node di cluster. Parameter ini dapat dikonfigurasi. Idenya adalah bahwa jika sebuah simpul hilang, data akan secara otomatis dimuat ke dalam RAM pada simpul tetangga dari salinan file SASHDAT. Area penyimpanan untuk salinan ini dalam struktur CAS disebut CAS_DISK_CACHE .
CAS_DISK_CACHE adalah bagian penting dari CAS, yang diperlukan tidak hanya untuk memastikan toleransi kesalahan, tetapi juga untuk mengoptimalkan penggunaan memori. Diagram di bawah ini menunjukkan berbagai cara menyimpan SASHDAT dan prinsip memuat data ke dalam RAM. Misalnya, dataset A diperoleh dari database Oracle dan disimpan pada simpul CAS yang sama dalam RAM dan pada disk. Plus, dataset A ini diduplikasi pada node lain hanya ke hard drive. Ada banyak opsi (beberapa di antaranya tidak memerlukan cadangan tambahan - ini akan dibahas di bawah), tetapi gagasan utamanya adalah selalu memiliki salinan untuk dengan cepat mengembalikan data yang sebelumnya diunduh ke RAM. Omong-omong, dalam hal mengatur dua parameter: MAXTABLEMEM = 0 dan COPIES = 0 pada tingkat sesi, data hanya akan hidup dalam RAM.
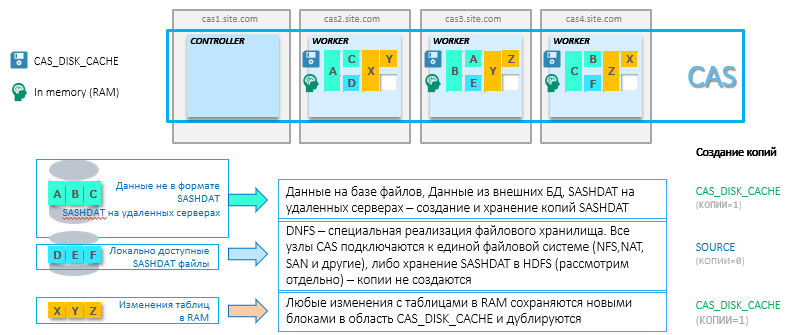
Saya juga ingin mempertimbangkan konfigurasi CAS yang menarik dengan Hadoop. Untuk menggunakan konfigurasi CAS ini dengan sistem Hadoop, Anda harus menginstal SAS Plugins untuk Hadoop. Gagasan utama dari pendekatan ini adalah bahwa node dari cluster Hadoop juga menjadi node CAS yang berfungsi. Data ditarik ke dalam RAM langsung dari file dalam HDFS tanpa beban jaringan. Ini adalah opsi terbaik dalam hal kinerja. Anda dapat menggunakan Hadoop baik hanya untuk menyimpan file SASHDAT (HDFS pada cluster akan memainkan peran CAS_DISK_CACHE - reservasi di tingkat HDFS), atau bersama-sama dengan data lain. Alokasi sumber daya pada cluster Hadoop dilakukan melalui YARN. Skema untuk menginstal CAS pada cluster Hadoop:
Memuat
Pemuatan data sederhana. Kami dapat menentukan berbagai sumber untuk input ke CAS. Mereka dapat dimuat baik dalam aliran tunggal atau paralel. Karena basis data relasional lebih sering digunakan sebagai sumber, kami akan mempertimbangkan topik memuat data ke CAS dari RDBMS. Untuk mengoptimalkan pemuatan data ke dalam cluster CAS, diinginkan untuk menginstal perangkat lunak klien dari database sumber pada setiap node dari cluster. Dalam hal ini, setiap node CAS cluster akan menerima bagian data secara paralel. Saat memasang klien hanya pada pengontrol, semua data akan dikirim melalui pengontrol CAS.
Misalnya, ketika mengatur parameter numreadnodes = 3, tabel akan secara otomatis dibagi menjadi 3 potongan data untuk memuat ke node CAS yang berbeda - dalam hal ini, distribusi data akan didasarkan pada pengelompokan berdasarkan kolom angka pertama menggunakan operasi mod 3.
Jika Hadoop atau Teradata digunakan sebagai sumber, maka menggunakan Proses Tertanam untuk Hadoop atau Teradata, pemuatan akan dilakukan langsung dari setiap node dari cluster Hadoop atau Teradata. Perhatikan bahwa dalam kasus instalasi terpisah dari cluster Hadoop (CAS tidak diinstal pada node Hadoop), area CAS_DISK_CACHE akan dibuat pada cluster CAS.
Bagaimana cara memulai dengan CAS?
Istilah penting dalam pekerjaan CAS adalah perpustakaan dan sesi. Saat Anda mulai bekerja dengan CAS, hal pertama yang dibuat adalah sesi. Ini dapat didefinisikan secara manual saat bekerja melalui SAS Studio, atau secara otomatis dibuat melalui antarmuka grafis yang tersedia di SAS Viya ketika terhubung ke CAS. Di dalam sesi, semua data dan transformasi yang didefinisikan di perpustakaan baru dibuat secara default dengan cakupan lokal. Data (didefinisikan dalam caslib) dan hasil langkah-langkah dari sesi lokal hanya terlihat di sesi ini. Jika kita perlu membuat hasilnya tersedia untuk umum, kita dapat mendefinisikan kembali caslib dengan parameter global dan operator promosinya, dan data akan tersedia dari sesi lain. Perpustakaan yang sudah ditentukan dengan parameter global akan tersedia dari sesi apa pun. Ini dilakukan untuk berbagi sumber daya secara optimal dan mengelola hak akses data. Setelah terputus dari sesi lokal, semua data sementara dihapus jika caslib belum didefinisikan ulang secara global. Kami dapat mengonfigurasi parameter TIMEOUT untuk menghapus data saat memutuskan sambungan dari sesi, untuk menghindari kemungkinan kerugian selama kegagalan jaringan jangka pendek atau untuk kembali ke sesi ini untuk analisis lebih lanjut (misalnya, Anda dapat mengatur parameter TIMEOUT ke 3600 detik, yang akan memberi kita 60 menit waktu untuk kembali ke sesi). Selain itu, data dapat disimpan pada setiap langkah konversi ke format SASHDAT khusus atau ke basis data yang dapat diakses, yang koneksinya dikonfigurasi oleh operator SAVE sederhana.
Pustaka caslibs menjelaskan kumpulan data yang akan tersedia di CAS. Saat membuat caslib, tipe koneksi dan parameter koneksi ditunjukkan. Dalam definisi caslib, kami segera menunjuk ke sumber data dan area target di dalam memori. Juga di tingkat caslib, lebih mudah untuk mengatur hak akses untuk grup pengguna ke data yang dijelaskan dalam caslib. Ini dilakukan dalam antarmuka grafis.
Contoh deskripsi caslib untuk berbagai jenis sumber:
caslib caspth path="/data/cust/" type=path; caspth – , path - caslib pgdvd datasource=( srctype="postgres", username="casdm", password="xxxxxx", server="sasdb.race.sas.com", database="dvdrental", schema="public", numreadnodes=3) ; caslib hivelib desc="HIVE Caslib" datasource=(SRCTYPE="HIVE",SERVER="gatekrbhdp01.gatehadoop.com", HADOOPCONFIGDIR="/opt/sas/hadoop/client_conf/", HADOOPJARPATH="/opt/sas/hadoop/client_jar/", schema="default",dfDebug=sqlinfo) GLOBAL ;
Setelah menentukan caslib, kami dapat memuat data ke dalam RAM untuk diproses lebih lanjut. Contoh memuat data caslib hivelib:
proc casutil; load casdata="stocks" casout="stocks" outcaslib="hivelib" incaslib="hivelib" PROMOTE ; quit; /* casdata – ( hive), casout – CAS, outcaslib – caslib, , incaslib – caslib, .*/ /* in/out caslib , */
Dalam setiap sesi, permintaan dieksekusi secara berurutan. Ini penting ketika menulis kode secara manual, tetapi ketika menggunakan antarmuka grafis yang tersedia di Viya, Anda tidak dapat memikirkannya. Aplikasi klien GUI sendiri membuat sesi terpisah untuk menyelesaikan langkah secara paralel.
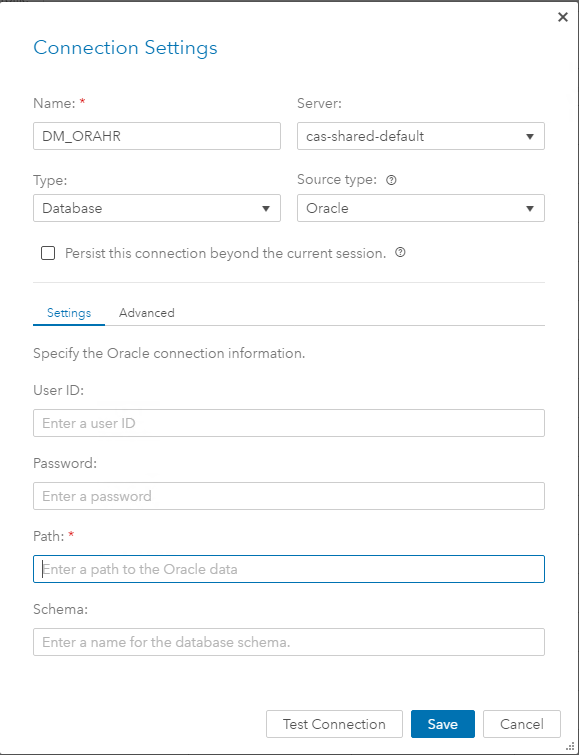
Antarmuka sepenuhnya grafis dan pendekatan untuk bekerja melalui mereka kami akan mempertimbangkan dalam artikel berikut. Di sini saya akan menambahkan tangkapan layar dari langkah-langkah untuk membuat DM_ORAHR caslib dan memuat data ke dalam RAM melalui GUI:
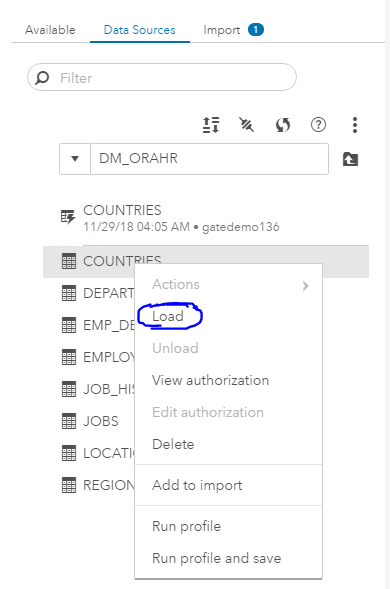
Ini baru permulaan.
Pada bagian ini saya mengakhiri bagian tentang CAS dan kembali ke platform Viya. Karena Viya diciptakan untuk pengguna bisnis, dalam proses kerja, tidak perlu untuk memahami secara mendalam spesifikasi CAS. Ada antarmuka grafis yang nyaman untuk semua operasi, dan CAS akan menyediakan kerja cepat semua langkah analitis karena dalam memori dan komputasi terdistribusi.
Sekarang Anda dapat beralih ke antarmuka pengguna yang tersedia di Viya. Saat ini ada banyak dari mereka, dan jumlah produk terus meningkat. Pada awal artikel, mereka dialokasikan ke dalam 4 kelompok, yang diperlukan untuk siklus analitik lengkap. Kembali ke gagasan utama, Viya adalah platform tunggal untuk penambangan data dan analitik lanjutan. Dan pekerjaan dimulai dengan persiapan dan pencarian data ini. Dan di bagian selanjutnya dari seri artikel tentang Viya, saya akan berbicara tentang alat persiapan data yang tersedia untuk analis.
Alih-alih kesimpulan, nama Viya berasal dari kata Via (dari bahasa Inggris "melalui" atau "melalui"). Ide utama dari nama ini adalah transisi sederhana dari solusi SAS 9 klasik ke platform baru yang dibuat untuk membawa analitik ke tingkat yang baru.