Pada awal Desember, Montreal menjadi tuan rumah konferensi
Sistem Pemrosesan Informasi Saraf tahunan ke-32 tentang pembelajaran mesin. Menurut tabel peringkat tidak resmi, konferensi ini adalah acara top-1 format ini di dunia. Semua tiket konferensi tahun ini terjual habis dalam catatan 13 menit. Kami memiliki tim besar ilmuwan data MTS, tetapi hanya satu dari mereka - Marina Yaroslavtseva (
magoli ) - cukup beruntung untuk sampai ke Montreal. Bersama Danila
Savenkov (
danila_savenkov ), yang dibiarkan tanpa visa dan mengikuti konferensi dari Moskow, kita akan berbicara tentang karya-karya yang menurut kami paling menarik bagi kami. Sampel ini sangat subyektif, tetapi mudah-mudahan ini akan menarik minat Anda.
 Jaringan saraf berulang relasionalAbstrakKode
Jaringan saraf berulang relasionalAbstrakKodeKetika bekerja dengan urutan, seringkali sangat penting bagaimana elemen-elemen dari urutan tersebut saling berhubungan satu sama lain. Arsitektur standar jaringan perulangan (GRU, LSTM) hampir tidak dapat memodelkan hubungan antara dua elemen yang cukup jauh satu sama lain. Hingga taraf tertentu, perhatian membantu mengatasi hal ini (
https://youtu.be/SysgYptB198 ,
https://youtu.be/quoGRI-1l0A ), tetapi tetap saja ini tidak sepenuhnya benar. Perhatian memungkinkan Anda untuk menentukan bobot kondisi tersembunyi dari masing-masing langkah urutan akan memengaruhi kondisi tersembunyi terakhir dan, karenanya, prediksi. Kami tertarik pada hubungan unsur-unsur urutan.
Tahun lalu, sekali lagi di NIPS, google menyarankan untuk mengabaikan pengulangan sama sekali dan menggunakan
perhatian pribadi . Pendekatannya terbukti sangat baik, meskipun terutama pada tugas seq2seq (artikel ini memberikan hasil terjemahan mesin).
Artikel tahun ini menggunakan ide perhatian diri sebagai bagian dari LSTM. Tidak banyak perubahan:
- Kami mengubah vektor keadaan sel ke matriks "memori" M. Sampai batas tertentu, matriks memori adalah banyak vektor keadaan sel (banyak sel memori). Mendapatkan elemen baru dari urutan, kami menentukan berapa banyak elemen ini harus memperbarui setiap sel memori.
- Untuk setiap elemen dari urutan, kami akan memperbarui matriks ini menggunakan perhatian produk multi-head dot (MHDPA, Anda dapat membaca tentang metode ini dalam artikel yang disebutkan dari google). Hasil MHPDA untuk elemen saat ini dari urutan dan matriks M dijalankan melalui mesh yang terhubung penuh, sigmoid dan kemudian matriks M diperbarui dengan cara yang sama seperti keadaan sel dalam LSTM
Dikatakan bahwa itu adalah karena MHDPA bahwa grid dapat mempertimbangkan interkoneksi elemen urutan bahkan ketika mereka dihapus dari satu sama lain.
Sebagai masalah mainan, model diminta dalam urutan vektor untuk menemukan vektor N berdasarkan jarak dari Mth dalam hal jarak Euclidean. Misalnya, ada urutan 10 vektor dan kami meminta Anda untuk menemukan yang berada di tempat ketiga di dekat yang kelima. Jelas bahwa untuk menjawab pertanyaan model ini, perlu untuk mengevaluasi jarak dari semua vektor ke yang kelima dan mengurutkannya. Di sini, model yang diusulkan oleh penulis dengan percaya diri mengalahkan LSTM dan
DNC . Selain itu, penulis membandingkan model mereka dengan arsitektur lain pada Learning to Execute (kami mendapatkan beberapa baris kode untuk dimasukkan, memberikan hasilnya), Mini-Pacman, Pemodelan Bahasa dan di mana-mana melaporkan hasil terbaik.
Imputasi Seri Waktu Multivariat dengan Jaringan Adversarial GeneratifAbstrakKode (meskipun mereka tidak menautkan artikel ini di sini)
Dalam rangkaian waktu multidimensi, sebagai suatu peraturan, ada sejumlah besar kelalaian, yang mencegah penggunaan metode statistik lanjutan. Solusi standar - mengisi dengan mean / nol, menghapus kasus yang tidak lengkap, mengembalikan data berdasarkan ekspansi matriks dalam situasi ini, seringkali tidak berfungsi, karena mereka tidak dapat mereproduksi ketergantungan waktu dan distribusi kompleks deret waktu multidimensi.
Kemampuan jaringan permusuhan generatif (GAN) untuk meniru setiap distribusi data, khususnya, dalam tugas-tugas "menggambar" wajah dan menghasilkan kalimat, sudah dikenal luas. Tetapi, sebagai suatu peraturan, model-model tersebut membutuhkan pelatihan awal pada dataset lengkap tanpa kesenjangan, atau tidak memperhitungkan sifat konsisten dari data.
Penulis mengusulkan untuk melengkapi GAN dengan elemen baru - Gaten Recurrent Unit for Imputation (GRUI). Perbedaan utama dari GRU biasanya adalah bahwa GRUI dapat belajar dari data pada interval panjang yang berbeda antara pengamatan dan menyesuaikan efek pengamatan tergantung pada jarak waktu dari titik saat ini. Parameter atenuasi khusus β dihitung, nilainya bervariasi dari 0 hingga 1 dan semakin kecil, semakin besar jeda waktu antara pengamatan saat ini dan yang sebelumnya tidak kosong.


Baik diskriminator dan generator GAN terdiri dari lapisan GRUI dan lapisan yang terhubung penuh. Seperti biasa dalam GAN, generator belajar mensimulasikan data sumber (dalam hal ini, cukup mengisi celah di baris), dan diskriminator belajar untuk membedakan baris yang diisi dengan generator dari yang asli.
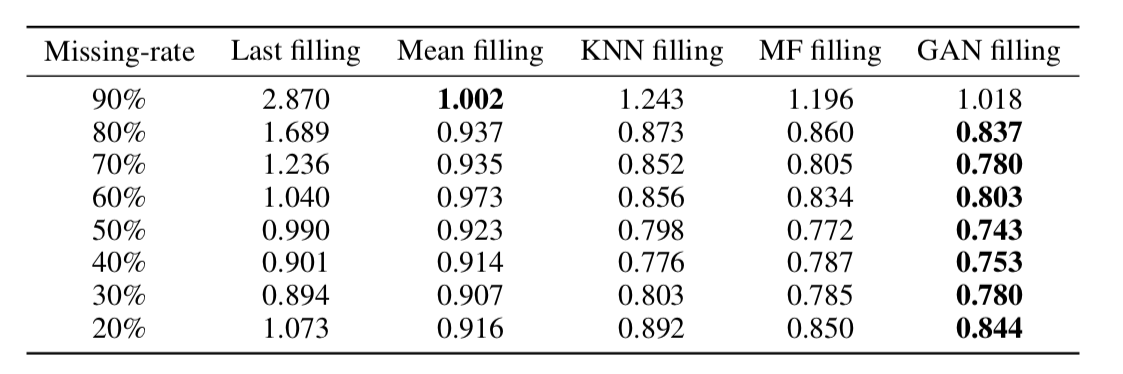
Ternyata, pendekatan ini sangat memadai mengembalikan data bahkan dalam rangkaian waktu dengan bagian yang sangat besar dari kelalaian (dalam tabel di bawah ini - pemulihan data UMK dalam dataset KDD tergantung pada persentase kelalaian dan metode pemulihan. Dalam kebanyakan kasus, metode berbasis GAN memberikan akurasi terbesar pemulihan).
 Tentang Dimensi Kata-Kata yang DigunakanAbstrakKode
Tentang Dimensi Kata-Kata yang DigunakanAbstrakKodePenyematan kata / representasi vektor kata adalah pendekatan yang banyak digunakan untuk berbagai aplikasi NLP: dari sistem rekomendasi hingga analisis pewarnaan emosional teks dan terjemahan mesin.
Selain itu, pertanyaan tentang bagaimana mengatur secara optimal hiperparameter yang penting seperti dimensi vektor tetap terbuka. Dalam praktiknya, paling sering dipilih oleh pencarian lengkap empiris atau ditetapkan secara default, misalnya, pada level 300. Pada saat yang sama, dimensi yang terlalu kecil tidak memungkinkan untuk mencerminkan semua hubungan yang signifikan antara kata-kata, dan terlalu besar dapat menyebabkan pelatihan ulang.
Para penulis penelitian mengusulkan solusi mereka untuk masalah ini dengan meminimalkan parameter kehilangan PIP, ukuran baru dari perbedaan antara dua opsi penyematan.
Perhitungan didasarkan pada matriks-PIP yang berisi produk skalar dari semua pasangan representasi vektor kata dalam corpus. Kehilangan PIP dihitung sebagai norma Frobenius antara matriks PIP dari dua embedding: dilatih pada data (dilatih menyematkan E_hat) dan ideal, dilatih pada data bising (oracle embedding E).
Tampaknya sederhana: Anda harus memilih dimensi yang meminimalkan kehilangan PIP, satu-satunya momen yang tidak bisa dipahami adalah di mana mendapatkan penanaman oracle. Pada 2015-2017, sejumlah karya diterbitkan di mana ditunjukkan bahwa berbagai metode untuk membangun embeddings (word2vec, GloVe, LSA) secara implisit memfaktisasi (menurunkan dimensi) matriks sinyal dari kasing. Dalam kasus word2vec (skip-gram), matriks sinyal adalah
PMI , dalam kasus GloVe itu adalah matriks penghitungan log. Diusulkan untuk mengambil kamus yang ukurannya tidak terlalu besar, membangun matriks sinyal dan menggunakan SVD untuk mendapatkan oracle embedding. Dengan demikian, dimensi embedded oracle sama dengan peringkat matriks sinyal (dalam praktiknya, untuk kamus 10k kata, dimensi akan menjadi urutan 2k). Namun, matriks sinyal empiris kami selalu berisik dan kami harus menggunakan skema rumit untuk mendapatkan oracle embedding dan memperkirakan kehilangan PIP dengan matriks berisik.
Para penulis berpendapat bahwa untuk memilih dimensi penyematan optimal, cukup menggunakan kamus 10k kata, yang tidak terlalu banyak dan memungkinkan Anda untuk menjalankan prosedur ini dalam jumlah waktu yang wajar.
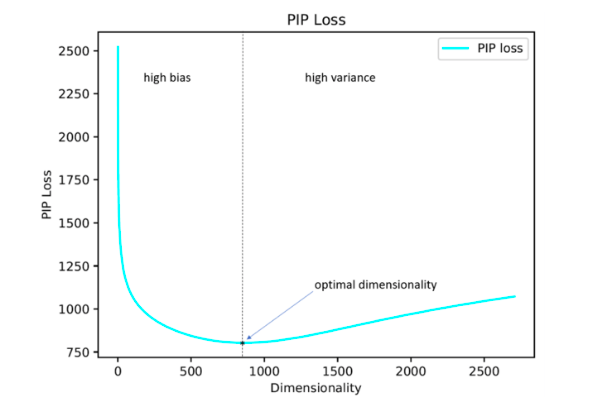
Ternyata, dimensi penyematan dihitung dengan cara ini dalam banyak kasus dengan kesalahan hingga 5% bertepatan dengan dimensi optimal yang ditentukan berdasarkan perkiraan ahli. Ternyata (diharapkan) bahwa Word2Vec dan GloVe praktis tidak berlatih ulang (kehilangan PIP tidak turun pada dimensi yang sangat besar), tetapi LSA dilatih ulang dengan cukup kuat.
Menggunakan kode yang diposting di github oleh penulis, orang dapat mencari dimensi optimal dari Word2Vec (skip-gram), GloVe, LSA.
FRAGE: Representasi Frekuensi-AgnostikAbstrakKodePara penulis berbicara tentang bagaimana embeddings bekerja secara berbeda untuk kata-kata langka dan populer. Maksud saya bukan berarti menghentikan kata-kata (kami tidak menganggapnya sama sekali), tetapi kata-kata informatif yang tidak terlalu jarang.
Pengamatan adalah sebagai berikut:
Jika kita berbicara tentang kata-kata populer, maka kedekatannya dengan ukuran kosinus mencerminkan dengan sangat baik
- afinitas semantik mereka. Untuk kata-kata langka, ini tidak begitu (apa yang diharapkan), dan (apa yang kurang diharapkan) teratas-n dari kata kosinus terdekat dengan kata langka juga jarang dan pada saat yang sama tidak berhubungan secara semantik. Artinya, kata-kata yang jarang dan sering di ruang pernikahan hidup di tempat yang berbeda (di kerucut yang berbeda, jika kita berbicara tentang kosinus)
- Selama pelatihan, vektor kata populer diperbarui lebih sering dan rata-rata dua kali lipat dari inisialisasi daripada vektor untuk kata-kata langka. Ini mengarah pada fakta bahwa penyisipan kata-kata langka rata-rata lebih dekat ke asal. Sejujurnya, saya selalu percaya bahwa, sebaliknya, kata-kata langka embeddings rata-rata lebih lama dan saya tidak tahu bagaimana berhubungan dengan pernyataan penulis =)
Apa pun hubungan antara norma L2 dari embeddings, pemisahan kata-kata populer dan langka bukanlah fenomena yang sangat baik. Kami ingin embeddings untuk mencerminkan semantik kata, bukan frekuensinya.
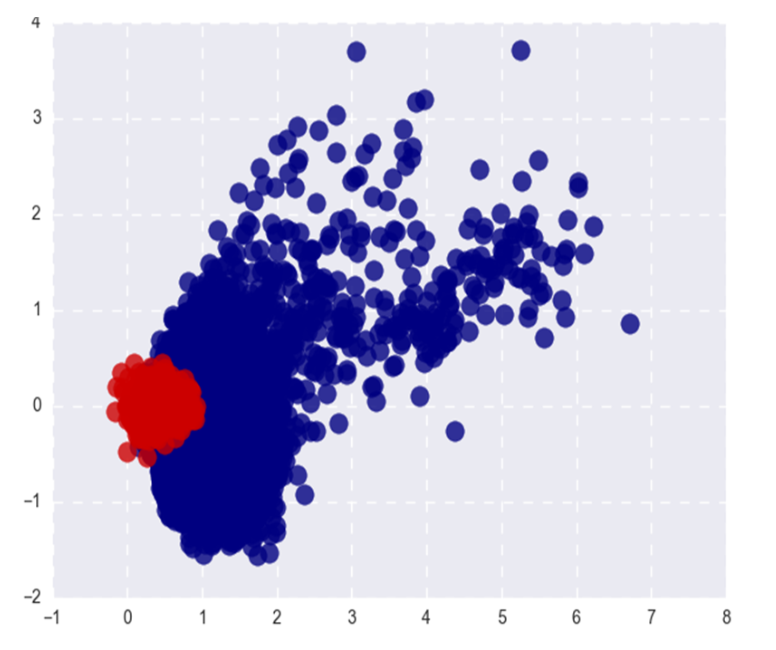
Gambar menunjukkan Word2Vec kata populer (merah) dan langka (biru) setelah SVD. Populer di sini mengacu pada 20% kata teratas dalam frekuensi.
Jika masalahnya hanya pada norma L2 embeddings, kita bisa menormalkannya dan hidup bahagia, tetapi, seperti yang saya katakan di paragraf pertama, kata-kata langka juga dipisahkan dari yang populer dengan kedekatan cosinus (dalam koordinat polar).
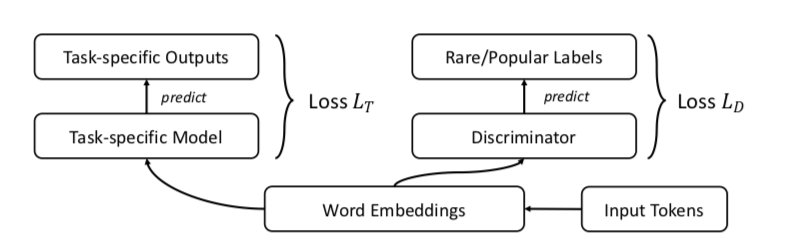
Penulis menyarankan, tentu saja, GAN. Mari kita lakukan hal yang sama seperti sebelumnya, tetapi tambahkan pembeda yang akan mencoba untuk membedakan antara kata-kata populer dan langka (sekali lagi, kami menganggap top-n% dari kata dalam frekuensi menjadi populer).
Itu terlihat seperti ini:
Para penulis menguji pendekatan pada tugas kesamaan kata, terjemahan mesin, klasifikasi teks dan pemodelan bahasa dan di mana-mana mereka melakukan lebih baik daripada garis dasar. Dalam kesamaan kata, dinyatakan bahwa kualitas tumbuh terutama terlihat pada kata-kata langka.
Salah satu contoh: kewarganegaraan. Masalah lewati-gram: kebahagiaan, Pakistan, pemberhentian, penguatan. Masalah FRAGE: populasi, städtischen, martabat, bürger. Kata-kata warga dan warga di FRAGE berada di tempat ke-79 dan ke-7, masing-masing (berdekatan dengan kewarganegaraan), dalam lompatan gram mereka tidak berada di atas 10.000.
Untuk beberapa alasan, penulis memposting kode hanya untuk terjemahan mesin dan pemodelan bahasa, kesamaan kata dan tugas klasifikasi teks dalam repositori, sayangnya, tidak terwakili.
Penyelarasan Lintas-Modal Tanpa Spasi untuk Ruang Bicara dan TeksAbstrakKode: tidak ada kode, tapi saya mau
Studi terbaru menunjukkan bahwa dua ruang vektor dilatih menggunakan algoritma embedding (misalnya, word2vec) pada badan teks dalam dua bahasa yang berbeda dapat dicocokkan satu sama lain tanpa markup dan pencocokan konten antara kedua bangunan. Secara khusus, pendekatan ini digunakan untuk terjemahan mesin di Facebook. Salah satu sifat kunci dari ruang embedding digunakan: di dalamnya, kata-kata yang mirip harus dekat secara geometris, dan yang berbeda, sebaliknya, harus jauh dari satu sama lain. Diasumsikan bahwa, secara umum, struktur ruang vektor dilestarikan terlepas dari bahasa tempat korpus digunakan untuk mengajar.
Para penulis artikel melangkah lebih jauh dan menerapkan pendekatan yang serupa dengan bidang pengenalan dan terjemahan ucapan otomatis. Diusulkan untuk melatih ruang vektor secara terpisah untuk corpus teks dalam bahasa yang diinginkan (misalnya, Wikipedia), secara terpisah untuk corpus pidato yang direkam (dalam format audio), mungkin dalam bahasa lain, sebelumnya dipecah menjadi kata-kata, dan kemudian membandingkan dua ruang ini dengan cara yang sama seperti dengan dua kasus teks.
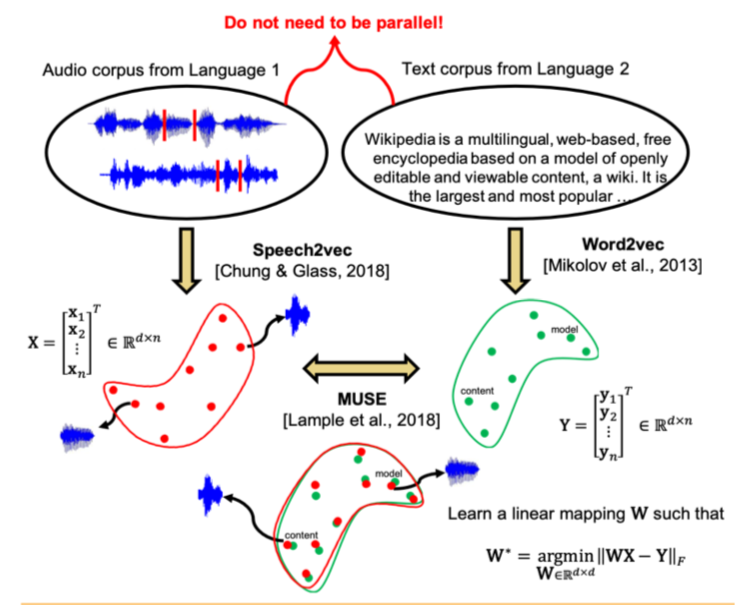
Untuk corpus teks, word2vec digunakan, dan untuk pidato, pendekatan yang serupa, yang disebut oleh Speech2vec, didasarkan pada LSTM dan metodologi yang digunakan untuk word2vec (CBOW / skip-gram), sehingga diasumsikan bahwa ia menggabungkan kata-kata secara tepat dengan karakteristik kontekstual dan semantik, dan tidak terdengar.
Setelah kedua ruang vektor dilatih dan ada dua set embeddings - S (pada tubuh ucapan), yang terdiri dari n embeds dimensi d1 dan T (pada badan teks), yang terdiri dari m embeds dimensi d2, Anda perlu membandingkannya. Idealnya, kami memiliki kamus yang menentukan vektor dari S yang sesuai dengan vektor dari T. Lalu dua matriks dibentuk untuk perbandingan: k embedding dipilih dari S, yang membentuk matriks X ukuran d1 xk; dari T, k embeddings yang sesuai (menurut kamus) yang sebelumnya dipilih dari S juga dipilih, dan matriks Y ukuran d2 xk diperoleh. Selanjutnya, Anda perlu menemukan pemetaan linear W sedemikian rupa sehingga:
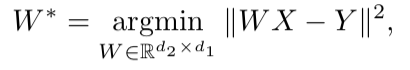
Tetapi karena artikel tersebut mempertimbangkan pendekatan tanpa pengawasan, awalnya tidak ada kamus, oleh karena itu, prosedur untuk membuat kamus sintetis, yang terdiri dari dua bagian, diusulkan. Pertama, kami mendapatkan perkiraan pertama W menggunakan pelatihan domain-adversarial (model kompetitif seperti GAN, tetapi bukannya generator - pemetaan linear W, yang dengannya kami mencoba membuat S dan T tidak dapat dibedakan satu sama lain, dan diskriminator mencoba menentukan asal sebenarnya dari penanaman). Kemudian, berdasarkan kata-kata yang embeddingsnya menunjukkan kecocokan terbaik satu sama lain dan paling sering ditemukan di kedua bangunan, kamus dibentuk. Setelah itu, penyempurnaan W sesuai dengan rumus di atas terjadi.
Pendekatan ini memberikan hasil yang sebanding dengan belajar pada data berlabel, yang dapat sangat berguna dalam tugas mengenali dan menerjemahkan pidato dari bahasa langka yang terlalu sedikit kasus teks ucapan paralel, atau tidak ada.
Deteksi Anomali Jauh Menggunakan Transformasi GeometrisAbstrakKodePendekatan yang agak tidak biasa dalam deteksi anomali, yang, menurut penulis, sangat mengalahkan pendekatan lain.
Idenya adalah ini: mari kita datang dengan K transformasi geometris yang berbeda (kombinasi dari pergeseran, 90 derajat rotasi dan refleksi) dan menerapkannya pada setiap gambar dari dataset asli. Gambar yang diperoleh sebagai hasil dari transformasi ke-i sekarang akan menjadi milik kelas i, yaitu, akan ada total kelas K, masing-masing akan diwakili oleh jumlah gambar yang semula dalam dataset. Sekarang kita akan mengajarkan klasifikasi multikelas pada markup tersebut (penulis memilih resnet lebar).
Sekarang kita bisa mendapatkan vektor K y (Ti (x)) dimensi K untuk gambar baru, di mana Ti adalah transformasi ke-i, x adalah gambar, y adalah output model. Definisi dasar "normalitas" adalah sebagai berikut:
Di sini, untuk gambar x, kami menambahkan probabilitas prediksi kelas yang benar untuk semua transformasi. Semakin besar “normalitas”, semakin besar kemungkinan gambar diambil dari distribusi yang sama dengan sampel pelatihan. Para penulis mengklaim bahwa ini sudah bekerja sangat keren, tetapi bagaimanapun menawarkan cara yang lebih kompleks yang bekerja bahkan sedikit lebih baik. Kami akan menganggap bahwa vektor y (Ti (x)) untuk setiap transformasi Ti adalah
Dirichlet yang terdistribusi dan kami akan mengambil kemungkinan logaritma sebagai ukuran "normalitas" gambar. Parameter distribusi Dirichlet diestimasi pada satu set pelatihan.
Penulis melaporkan peningkatan kinerja luar biasa dibandingkan dengan pendekatan lain.
Kerangka Kerja Terpadu Sederhana untuk Mendeteksi Sampel yang Tidak Terdistribusi dan Serangan MusuhAbstrakKodeIdentifikasi dalam sampel untuk penerapan model kasus berbeda secara signifikan dari distribusi sampel pelatihan adalah salah satu persyaratan utama untuk mendapatkan hasil klasifikasi yang dapat diandalkan. Pada saat yang sama, jaringan saraf dikenal untuk fitur mereka dengan tingkat kepercayaan yang tinggi (dan salah) untuk mengklasifikasikan objek yang tidak ditemukan dalam pelatihan, atau sengaja rusak (contoh permusuhan).
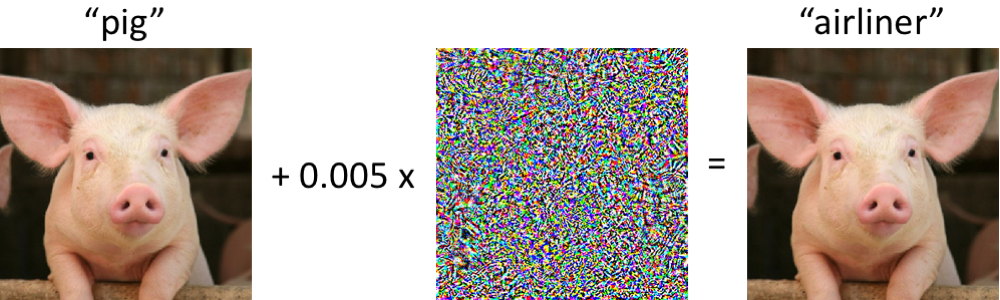
Penulis artikel ini menawarkan metode baru untuk mengidentifikasi kasus-kasus tersebut dan "buruk" lainnya. Pendekatan diimplementasikan sebagai berikut: pertama, jaringan saraf dengan output softmax biasa dilatih, kemudian output dari lapisan kedua dari belakang diambil, dan classifier generatif dilatih di atasnya. Biarkan ada x - yang diumpankan ke input model untuk objek klasifikasi tertentu, y - label kelas yang sesuai, lalu anggaplah bahwa kita memiliki classifier softmax pra-terlatih dari formulir:
Dimana wc dan bc adalah bobot dan konstanta dari lapisan softmax untuk kelas c, dan f (.) Adalah output dari DNN kedelai kedua dari belakang.
Lebih lanjut, tanpa perubahan apa pun pada pengklasifikasi pra-terlatih, transisi dibuat ke pengklasifikasi generatif, yaitu, analisis diskriminan. Diasumsikan bahwa fitur yang diambil dari lapisan kedua dari classifier softmax memiliki distribusi normal multidimensi, masing-masing komponen yang sesuai dengan satu kelas. Kemudian distribusi kondisional dapat ditentukan melalui vektor cara distribusi multidimensi dan matriks kovariannya:
Untuk mengevaluasi parameter dari classifier generatif, rata-rata empiris dihitung untuk setiap kelas, serta kovarians untuk kasus dari sampel pelatihan {(x1, y1), ..., (xN, yN)}:
di mana N adalah jumlah kasus dari kelas yang sesuai dalam set pelatihan. Kemudian, ukuran reliabilitas dihitung pada sampel uji - jarak Mahalanobis antara test case dan distribusi kelas normal terdekat dengan case ini.
Ternyata, metrik seperti itu bekerja jauh lebih andal pada objek atipikal atau rusak, tanpa memberikan perkiraan tinggi, seperti lapisan softmax. Dalam sebagian besar perbandingan pada data yang berbeda, metode yang diusulkan menunjukkan hasil yang melampaui keadaan terkini dalam menemukan kedua kasus yang tidak ada dalam pelatihan, dan sengaja dimanjakan.
Selanjutnya, penulis mempertimbangkan aplikasi lain yang menarik dari metodologi mereka: gunakan classifier generatif untuk menyoroti kelas-kelas baru yang tidak dalam pelatihan tentang tes, dan kemudian memperbarui parameter dari classifier itu sendiri sehingga dapat menentukan kelas baru ini di masa depan.
Contoh Adversarial yang Menipu Visi Komputer dan Manusia Berbatas WaktuAbstrak:
https://arxiv.org/abs/1802.08195adversarial examples . , . adversarial example . , , , , , , , adversarial attacks.

adversarial examples. adversarial examples , ( , ).
, adversarial example, . , , 63 . accuracy 10% , adversarial. , adversarial , . , perturbation perturbation , accuracy .
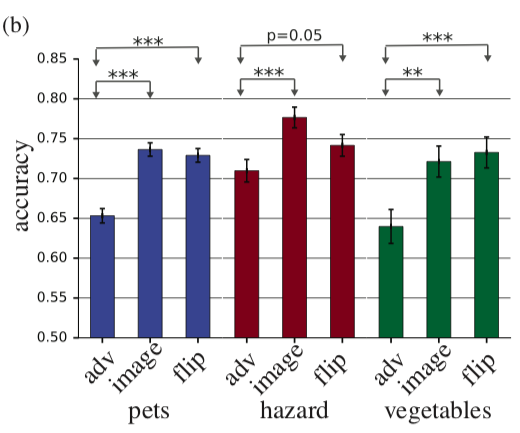
adv — adversarial example, image — , flip — + adversarial perturbation, .
Sanity Checks for Saliency MapsAbstract— . deep learning, saliency maps. Saliency maps . saliency map, , “”.

: “ saliency maps?” , :
- Saliency map
- Saliency map ,
, : cascading randomization ( , , saliency map) independent randomization ( ). : , saliency maps.
saliency map , , saliency maps. : “To our surprise, some widely deployed saliency methods are independent of both the data the model was trained on, and the model parameters”, — . , , saliency maps, , cascading randomization:
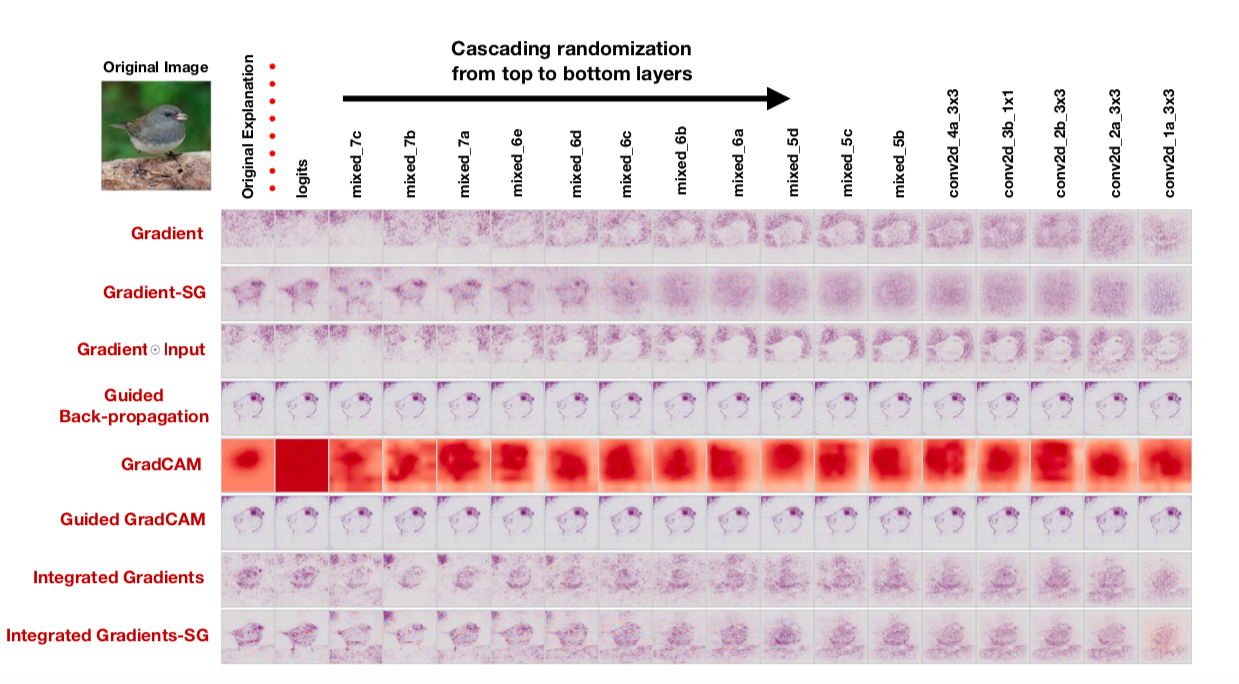
, . , saliency maps .
, — saliency maps , , confirmation bias. , .
An intriguing failing of convolutional neural networks and the CoordConv solutionAbstract:
https://arxiv.org/abs/1807.03247: , 10 .
Uber. , , , . , :
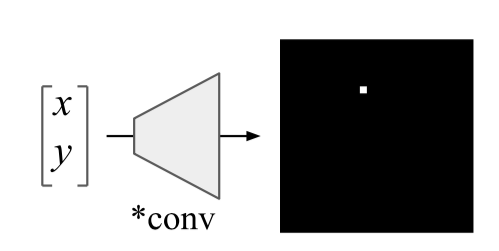
: ( CoodrConv ) i j, :
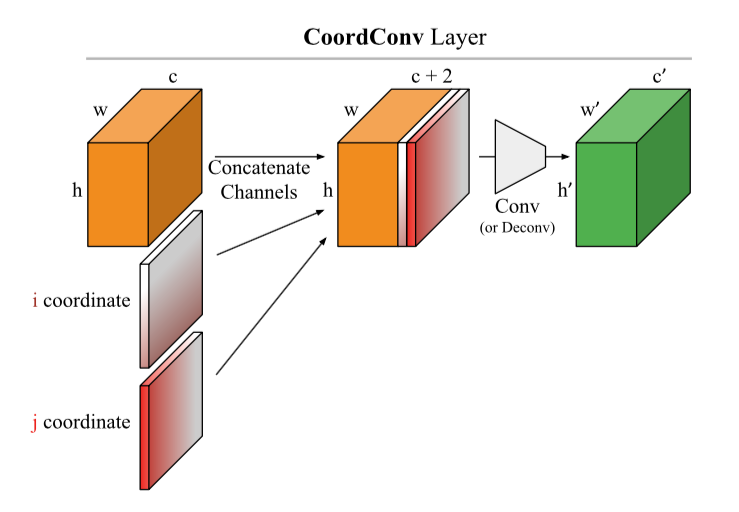
, :
- ImageNet'. , , , ,
- CoordConv object detection. MNIST, Faster R-CNN, IoU 21%
- CoordConv GAN .
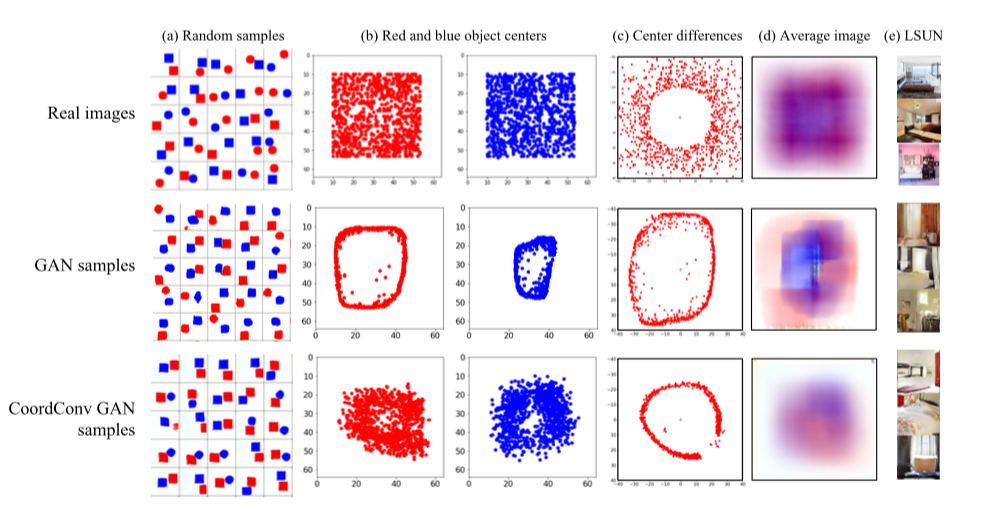
GAN' : LSUN. , — c. , GAN' , , . CoordConv , . LSUN d , , CoordConv GAN,
- 4. CoordConv A2C ( ) .
, , . CoordConv
U-net :
https://arxiv.org/abs/1812.01429, https://www.kaggle.com/c/tgs-salt-identification-challenge/discussion/69274 ,
https://github.com/mjDelta/Kaggle-RSNA-Pneumonia-Detection-Challenge .
.
Regularizing by the Variance of the Activations' Sample-VariancesAbstractbatch normalization. - . : S1 S2 :
di mana σ2 adalah varians sampel dalam S1 dan S2, masing-masing, β adalah koefisien positif terlatih. Penulis menyebut hal ini variance constancy loss (VCL) dan menambahkannya ke total loss.
Pada bagian tentang percobaan, penulis mengeluh tentang bagaimana hasil artikel orang lain tidak direproduksi dan berkomitmen untuk mengeluarkan kode yang dapat direproduksi (ditata). Pertama, mereka bereksperimen dengan mesh 11-layer kecil pada dataset gambar kecil (CIFAR-10 dan CIFAR-100). Kami mendapatkan bahwa VCL terbukti, jika Anda menggunakan Leaky ReLU atau ELU sebagai aktivasi, tetapi normalisasi bets berfungsi lebih baik dengan ReLU. Kemudian mereka menambah jumlah layer sebanyak 2 kali dan beralih ke Tiny Imagenet - versi sederhana dari Imagenet dengan 200 kelas dan resolusi 64x64. Dalam validasi, VCL mengungguli normalisasi batch pada grid dengan ELU, serta ResNet-110 dan DenseNet-40, tetapi mengungguli Wide-ResNet-32. Suatu hal yang menarik adalah bahwa hasil terbaik diperoleh ketika himpunan bagian S1 dan S2 terdiri dari dua sampel.
Selain itu, penulis menguji VCL dalam jaringan umpan-maju dan VCL menang lebih sering daripada jaringan dengan normalisasi batch atau tanpa regularisasi.
DropMax: Adaptive Variational SoftmaxAbstrakKodeDiusulkan dalam masalah klasifikasi multi-kelas pada setiap iterasi dari gradient descent untuk setiap sampel untuk secara acak menjatuhkan sejumlah kelas yang salah. Selain itu, probabilitas dengan mana kita menjatuhkan satu atau kelas lain untuk satu atau objek lain juga sedang dilatih. Akibatnya, ternyata jaringan "berkonsentrasi" pada membedakan antara kelas yang paling sulit untuk dipisahkan.
Eksperimen pada subset MNIST, CIFAR, dan Imagenet menunjukkan bahwa DropMax berkinerja lebih baik daripada SoftMax standar dan beberapa modifikasinya.
Model Intelektual Yang Akurat dengan Interaksi Berpasangan(Teman Jangan Biarkan Teman Menyebarkan Model Kotak Hitam: Pentingnya Kecerdasan dalam Pembelajaran Mesin)
Abstrak:
http://www.cs.cornell.edu/~yinlou/papers/lou-kdd13.pdfKode: tidak ada di sana. Saya sangat tertarik dengan bagaimana penulis mengarsipkan nama yang sedikit imperatif dengan kurangnya kode. Akademisi, pak =)
Anda dapat melihat paket ini, misalnya:
https://github.com/dswah/pyGAM . Interaksi fitur ditambahkan ke dalamnya belum lama ini (yang sebenarnya membedakan GAM dari GA2M).
Artikel ini disajikan dalam rangka lokakarya "Interpretabilitas dan Keteguhan dalam Audio, Pidato, dan Bahasa", meskipun dikhususkan untuk interpretabilitas model secara umum, dan bukan untuk bidang analisis suara dan ucapan. Mungkin, semua orang dihadapkan pada batas tertentu dengan dilema memilih antara interpretabilitas model dan akurasinya. Jika kita menggunakan regresi linear biasa, maka kita dapat memahami dengan koefisien bagaimana masing-masing variabel independen mempengaruhi dependen. Jika kita menggunakan model kotak hitam, misalnya, peningkatan gradien tanpa batasan pada kompleksitas atau jaringan saraf yang dalam, model yang disetel dengan benar pada data yang sesuai akan sangat akurat, tetapi melacak dan menjelaskan semua pola yang ditemukan model dalam data akan bermasalah. Dengan demikian, akan sulit untuk menjelaskan model kepada pelanggan dan melacak apakah dia telah mempelajari sesuatu yang tidak kita sukai. Tabel di bawah ini memberikan perkiraan interpretabilitas relatif dan akurasi berbagai jenis model.

Contoh situasi di mana interpretabilitas model yang buruk dikaitkan dengan risiko besar: pada salah satu set data medis, masalah memprediksi probabilitas pasien meninggal akibat pneumonia telah terpecahkan. Pola menarik berikut ditemukan dalam data: jika seseorang memiliki asma bronkial, maka kemungkinan kematian akibat pneumonia lebih rendah daripada pada orang tanpa penyakit ini. Ketika para peneliti beralih ke dokter praktek, ternyata pola seperti itu benar-benar ada, karena orang dengan asma dalam kasus pneumonia menerima bantuan yang paling cepat dan obat-obatan yang kuat. Jika kami melatih xgboost pada dataset ini, kemungkinan besar ia akan menangkap pola ini, dan model kami akan mengklasifikasikan pasien dengan asma sebagai kelompok berisiko rendah dan, karenanya, akan merekomendasikan prioritas yang lebih rendah dan intensitas pengobatan untuk mereka.
Para penulis artikel menawarkan alternatif yang dapat ditafsirkan dan akurat pada saat yang sama - ini adalah GA2M, subspesies dari model aditif umum.
GAM klasik dapat dianggap sebagai generalisasi lebih lanjut dari GLM: suatu model adalah penjumlahan, setiap istilah yang mencerminkan pengaruh hanya satu variabel independen pada dependen, tetapi pengaruhnya dinyatakan bukan oleh satu koefisien bobot, seperti dalam GLM, tetapi oleh fungsi nonparametrik yang halus (sebagai aturan, ditentukan dengan sendirinya fungsi - splines atau pohon dengan kedalaman kecil, termasuk "tunggul"). Karena fitur ini, GAM dapat memodelkan hubungan yang lebih kompleks daripada model linier sederhana. Di sisi lain, dependensi yang dipelajari (fungsi) dapat divisualisasikan dan ditafsirkan.
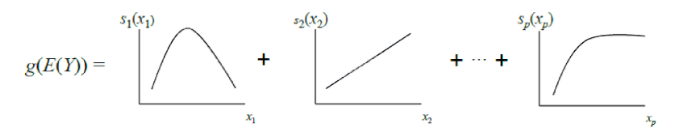
Namun, GAM standar masih sering tidak mencapai keakuratan algoritma kotak hitam. Untuk memperbaikinya, penulis artikel menawarkan kompromi - untuk menambah persamaan model, selain fungsi satu variabel, sejumlah kecil fungsi dua variabel - pasangan yang dipilih dengan cermat yang interaksinya signifikan untuk memprediksi variabel dependen. Dengan demikian, GA2M diperoleh.
Pertama, GAM standar dibangun (tanpa memperhitungkan interaksi variabel), dan kemudian pasangan variabel ditambahkan langkah demi langkah (GAM yang tersisa digunakan sebagai variabel target). Untuk kasus ketika ada banyak variabel dan memperbarui model setelah setiap langkah sulit secara komputasi, algoritma peringkat FAST diusulkan, dengan mana Anda dapat memilih sebelumnya pasangan yang berpotensi berguna dan menghindari penghitungan lengkap.
Pendekatan ini memungkinkan kami untuk mencapai kualitas yang dekat dengan model kompleksitas yang tidak terbatas. Tabel menunjukkan tingkat kesalahan model aditif umum dibandingkan dengan hutan acak untuk menyelesaikan masalah klasifikasi pada dataset yang berbeda, dan dalam kebanyakan kasus kualitas prediksi untuk GA2M dengan FAST dan untuk hutan acak tidak berbeda secara signifikan.
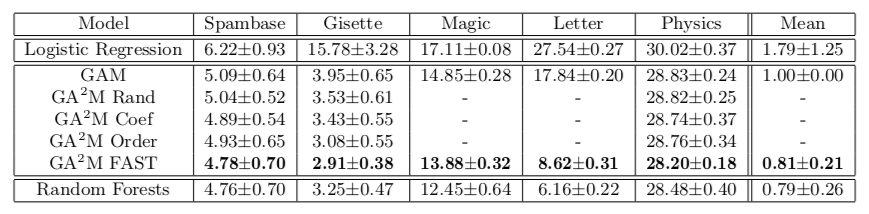
Saya ingin menarik perhatian pada fitur-fitur karya akademisi yang menawarkan untuk mengirimkan dorongan dan pemahaman mendalam ini ke tungku. Harap dicatat bahwa dataset yang hasilnya disajikan tidak lebih dari 20 ribu objek (semua dataset dari repositori UCI). Sebuah pertanyaan alami muncul: apakah benar-benar tidak ada dataset terbuka dengan ukuran normal untuk eksperimen seperti itu pada 2018? Anda bisa melangkah lebih jauh dan membandingkan pada dataset 50 objek - ada kemungkinan bahwa model konstan tidak akan berbeda secara signifikan dari hutan acak.
Poin selanjutnya adalah regularisasi. Pada sejumlah besar tanda, sangat mudah untuk melatih ulang bahkan tanpa interaksi. Para penulis mungkin percaya bahwa masalah ini tidak ada, dan satu-satunya masalah adalah model kotak hitam. Setidaknya dalam artikel itu, regularisasi tidak dibicarakan di mana pun, meskipun itu jelas diperlukan.
Dan yang terakhir, tentang interpretabilitas. Bahkan model linier tidak dapat diartikan jika kita memiliki banyak fitur. Ketika Anda memiliki 10 ribu bobot yang terdistribusi secara normal (dalam hal menggunakan regularisasi L2 akan menjadi seperti ini), tidak mungkin untuk mengatakan dengan tepat tanda mana yang bertanggung jawab atas fakta bahwa predict_proba memberikan 0,86. Untuk interpretabilitas, kami ingin tidak hanya model linier, tetapi model linier dengan bobot jarang. Tampaknya ini dapat dicapai dengan regularisasi L1, tetapi di sini juga tidak begitu sederhana. Dari serangkaian fitur yang sangat berkorelasi, regularisasi L1 akan memilih satu hampir secara tidak sengaja. Sisanya akan mendapatkan bobot 0, meskipun jika salah satu dari fitur ini memiliki kemampuan prediksi, yang lain jelas bukan hanya noise. Dalam hal interpretasi model, ini mungkin OK, dalam hal memahami hubungan fitur dan variabel target, ini sangat buruk. Artinya, bahkan dengan model linier, tidak semuanya begitu sederhana, rincian lebih lanjut tentang model yang dapat ditafsirkan dan kredibel dapat ditemukan di
sini .
Visualisasi untuk Pembelajaran Mesin: UMAPLenyapKodePada hari tutorial, salah satu yang pertama dilakukan adalah "Visualisasi untuk Pembelajaran Mesin" oleh Google Brain. Sebagai bagian dari tutorial, kami diberitahu tentang sejarah visualisasi, mulai dari pencipta grafik pertama, serta tentang berbagai fitur otak manusia dan persepsi serta teknik yang dapat digunakan untuk menarik perhatian pada hal terpenting dalam gambar, bahkan berisi banyak detail kecil - misalnya, menyoroti bentuk, warna, bingkai, dll., seperti pada gambar di bawah ini. Saya akan melewati bagian ini, tetapi ada
ulasan yang bagus .

Secara pribadi, saya paling tertarik dengan topik visualisasi set data multidimensi, khususnya pendekatan Uniform Manifold Approximation and Projection (UMAP) - sebuah metode baru non-linear untuk mengurangi dimensi. Itu diusulkan pada bulan Februari tahun ini, sehingga masih sedikit orang yang menggunakannya, tetapi terlihat menjanjikan baik dalam hal waktu kerja dan dalam hal kualitas pemisahan kelas dalam visualisasi dua dimensi. Jadi, pada kumpulan data yang berbeda, UMAP 2-10 kali lebih cepat dari t-SNE dan metode lain dalam hal kecepatan, dan semakin besar dimensi data, semakin besar kesenjangan dalam kinerja:
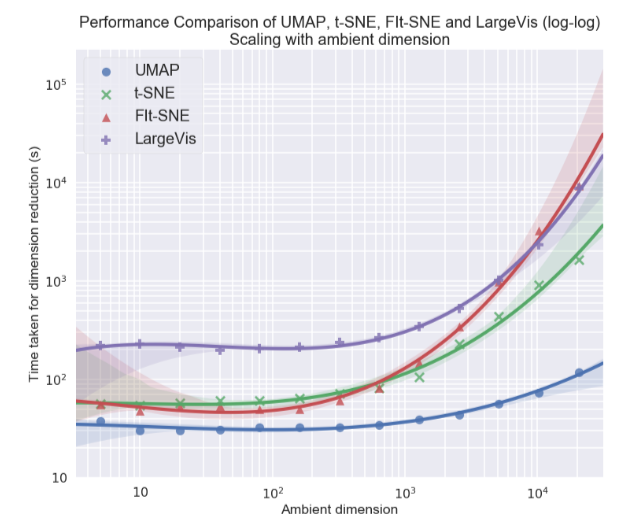
Selain itu, tidak seperti t-SNE, waktu operasi UMAP hampir tidak tergantung pada dimensi ruang baru tempat kami akan menanamkan dataset kami (lihat gambar di bawah), yang menjadikannya alat yang cocok untuk tugas-tugas lain (selain visualisasi) - khususnya, untuk mengurangi dimensi sebelum melatih model.
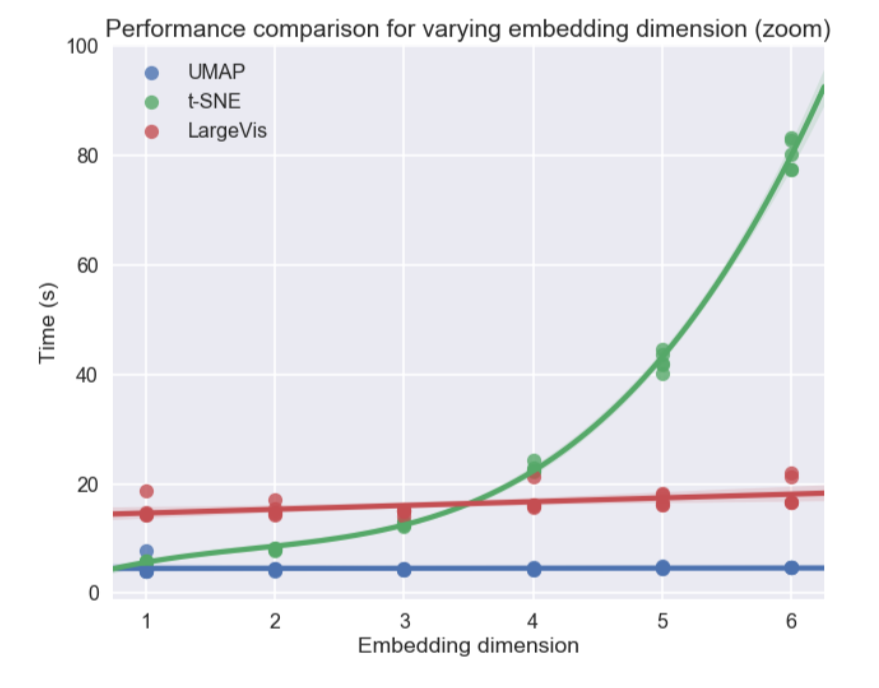
Pada saat yang sama, pengujian pada set data yang berbeda menunjukkan bahwa UMAP bekerja tidak lebih buruk untuk visualisasi, dan t-SNE lebih baik di beberapa tempat: misalnya, pada set data MNIST dan Mode MNIST, kelas lebih baik dipisahkan dalam versi dengan UMAP:
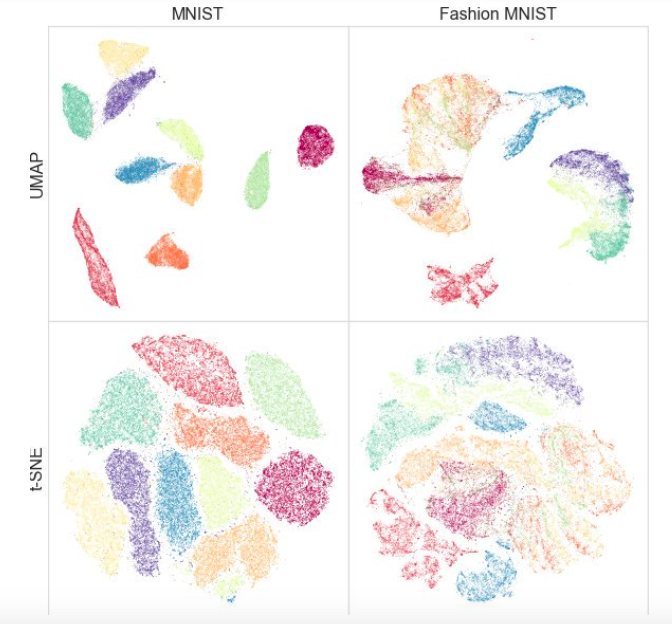
Nilai tambah tambahan adalah implementasi yang mudah: kelas UMAP mewarisi dari kelas sklearn, sehingga Anda dapat menggunakannya sebagai transformator reguler di pipa sklearn. Selain itu, dikatakan bahwa UMAP lebih dapat ditafsirkan daripada t-SNE, seperti lebih baik mempertahankan struktur data global.
Di masa depan, penulis berencana untuk menambahkan dukungan untuk pelatihan semi-diawasi - yaitu, jika kita memiliki tag untuk setidaknya beberapa objek, kita dapat membangun UMAP berdasarkan informasi ini.
Artikel apa yang kamu suka? Tulis komentar, ajukan pertanyaan, kami akan menjawabnya.