Kami terus bereksperimen dengan format mitaps. Baru-baru ini, di ring tinju, kami
bertabrakan dengan bus data terpusat dan Service Mesh. Kali ini kami memutuskan untuk mencoba sesuatu yang lebih damai - StandUp, yaitu mikrofon terbuka. Topik dipilih dalam database memori.

Dalam kasus apa saya harus beralih ke memori? Bagaimana dan mengapa skala? Dan apa yang layak diperhatikan? Jawabannya ada dalam pidato pembicara, yang akan kita bahas dalam posting ini.
Tapi pertama-tama, bayangkan pembicara:
- Andrey Trushkin, Kepala Pusat Inovasi dan Teknologi Canggih Promsvyazbank
- Vladislav Shpileva, pengembang Tarantool
- Artyom Shitov, Arsitek Solusi GridGain
Beralih ke dalam memori
Tren saat ini di pasar keuangan memberlakukan persyaratan yang jauh lebih ketat pada waktu respons dan pengoperasian otomatisasi proses secara umum. Selain itu, hampir semua lembaga keuangan terbesar saat ini berupaya membangun ekosistem mereka sendiri.
Dalam hal ini, kami melihat sendiri dua aplikasi utama dari solusi dalam memori. Yang pertama adalah caching data integrasi. Menurut skenario klasik, di perusahaan besar ada beberapa sistem otomatis yang menyediakan data atas permintaan pengguna. Atau sistem eksternal - tetapi dalam hal ini, pemrakarsa dalam kebanyakan kasus adalah pengguna. Secara tradisional, sistem ini menyimpan data terstruktur dengan cara tertentu dalam database, mengaksesnya sesuai permintaan.
Saat ini, sistem seperti itu tidak lagi memenuhi persyaratan dalam hal beban. Di sini kita tidak boleh melupakan panggilan jarak jauh dari sistem ini oleh sistem konsumen. Ini menyiratkan perlunya merevisi pendekatan untuk penyimpanan dan penyajian data - untuk pengguna, sistem otomatis atau layanan individu. Output logis - penyimpanan data yang relevan yang digunakan oleh layanan di level lapisan dalam memori; ada banyak kasus sukses serupa di pasar.
Ini adalah kasus pertama. Yang kedua efektif, dari sudut pandang teknis, manajemen proses bisnis. Sistem BPM tradisional mengotomatiskan pelaksanaan operasi tertentu sesuai dengan algoritma yang telah ditentukan. Dan dalam banyak kasus muncul pertanyaan: mengapa sistem ini tidak cukup efisien dan cukup cepat?
Biasanya, sistem tersebut menulis setiap langkah (atau serangkaian langkah kecil, yang dirancang sebagai transaksi bisnis) ke basis data. Jadi mereka terikat dengan waktu respons dan interaksi dengan sistem ini. Sekarang jumlah instance proses bisnis yang berjalan secara bersamaan dalam waktu nyata adalah pesanan yang besarnya lebih dari 10 tahun yang lalu. Jadi sistem manajemen proses bisnis modern harus memiliki kinerja yang jauh lebih tinggi dan memastikan pelaksanaan aplikasi yang terdesentralisasi. Terlebih lagi, saat ini semua perusahaan bergerak menuju pembentukan lingkungan layanan-mikro yang besar. Tantangannya adalah bahwa berbagai proses proses bisnis dapat berbagi dan menggunakan data operasional secara efisien. Dalam kerangka orkestrasi, masuk akal untuk menyimpannya dalam solusi dalam memori.
Masalah rekonsiliasi
Misalkan kita memiliki sejumlah besar node dan layanan, bahwa sejumlah proses bisnis dilakukan, tindakan yang diimplementasikan dalam bentuk layanan-mikro. Untuk meningkatkan kinerja, masing-masing mulai menulis statusnya ke instance memori lokal. Kami mendapat banyak contoh lokal. Bagaimana memastikan relevansi dan konsistensi untuk semua?
Kami menggunakan zonasi di area memori. Misalnya, tergantung pada domain bisnis. Ketika kami memotong domain bisnis, kami menentukan bahwa beberapa layanan microser / proses bisnis hanya bekerja dalam kerangka zona yang bertanggung jawab untuk domain yang sesuai. Dengan cara ini kita dapat mempercepat pembaruan cache dan seluruh solusi dalam memori.
Pada saat yang sama, cache yang bertanggung jawab atas domain beroperasi dalam mode replikasi penuh - jumlah node yang terbatas karena distribusi antar domain memastikan kecepatan dan kebenaran solusi dalam mode ini. Zonasi dan fragmentasi maksimum membantu menyelesaikan masalah sinkronisasi, operasi klaster, dll. pada sejumlah besar node.
Secara alami sering muncul pertanyaan tentang keandalan solusi dalam memori. Ya, tidak semuanya bisa diletakkan di sana. Untuk memastikan keandalan, kami selalu memiliki basis data di sebelah dalam memori. Misalnya, untuk masalah-masalah penting dengan pelaporan yang perlu disatukan, yang mungkin sulit pada sejumlah besar node. Jadi apa visi kami hari ini:
sinergi dari dua pendekatan .
Perlu juga dicatat bahwa kedua pendekatan ini juga tidak sepenuhnya benar hanya untuk kontras. Dan pada saat yang sama, fokuslah pada mereka. Produsen dan kontributor sistem virtualisasi kemas yang canggih, seperti Kubernetes, sudah memberi kami opsi untuk penyimpanan jangka panjang yang andal. Kasus-kasus industri yang baik untuk menerapkan solusi telah muncul, di mana penyimpanan dilakukan dalam format virtual.
Salah satu surat kabar AS terbesar memberikan kesempatan bagi para pembacanya untuk menerima masalah apa pun secara online yang telah diterbitkan sejak awal penerbitan surat kabar ini pada abad ke-19. Kita bisa membayangkan tingkat bebannya. Penyimpanan diimplementasikan oleh mereka melalui platform Apache Kafka, yang digunakan untuk Kubernetes. Berikut adalah opsi lain untuk menyimpan informasi dan menyediakan akses ke sana di bawah beban besar ke sejumlah besar pelanggan. Saat merancang solusi baru, opsi ini juga patut diperhatikan.
Penskalaan basis data dalam memori dengan Tarantool
Misalkan kita memiliki server. Ini menerima permintaan, menyimpan data. Tiba-tiba ada lebih banyak permintaan dan data, server berhenti mengatasi beban. Anda dapat mengunggah lebih banyak perangkat keras ke server dan itu akan menerima lebih banyak permintaan. Tapi ini jalan buntu karena tiga alasan sekaligus: biaya tinggi, kemampuan teknis terbatas dan masalah dengan toleransi kesalahan. Sebaliknya, ada penskalaan horizontal: “teman” datang ke server untuk membantunya menyelesaikan tugas. Dua jenis penskalaan horizontal adalah replikasi dan sharding.
Replikasi adalah ketika ada banyak server, mereka semua menyimpan data yang sama dan permintaan klien tersebar di semua server ini. Beginilah cara menghitung, bukan data, skala. Ini berfungsi ketika data ditempatkan pada satu node, tetapi ada begitu banyak permintaan klien yang satu server tidak bisa mengatasinya. Toleransi kesalahan juga sangat ditingkatkan di sini.
Sharding digunakan untuk mengukur data: banyak server dibuat, dan mereka menyimpan data yang berbeda. Jadi Anda menskalakan perhitungan dan data. Tetapi toleransi kesalahan dalam hal ini rendah. Jika satu server gagal, bagian dari data akan hilang.
Ada pendekatan ketiga - untuk menggabungkan mereka. Kami membagi cluster menjadi subclusters, menyebutnya set replika. Masing-masing menyimpan data yang sama, dan data tidak bersinggungan di antara set replika. Hasilnya adalah penskalaan data, dan komputasi, dan toleransi kesalahan.
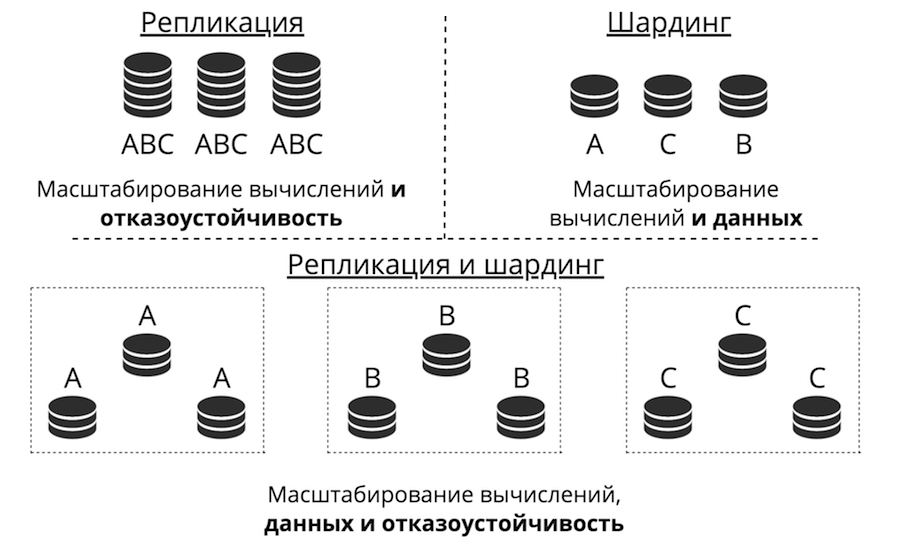
Replikasi
Replikasi dapat terdiri dari dua jenis: asinkron dan sinkron. Asynchronous adalah ketika permintaan klien tidak menunggu sampai data tersebar di seluruh replika: menulis ke satu replika sudah cukup. Segera setelah data sampai ke disk, ke log, transaksi berhasil dan suatu hari nanti di latar belakang data ini direplikasi. Sinkron - saat transaksi dibagi menjadi 2 fase: siapkan dan komit. Komit tidak akan mengembalikan kesuksesan sampai data direplikasi ke kuorum replika.
Replikasi asinkron jelas lebih cepat karena tidak ada yang bersandar pada jaringan. Data akan dikirim ke jaringan di latar belakang, dan transaksi itu sendiri, sebagaimana dicatat dalam log, telah selesai. Tetapi ada masalah: replika dapat tertinggal satu sama lain, tidak sinkron.
Replikasi sinkron lebih dapat diandalkan, tetapi jauh lebih lambat dan lebih sulit untuk diterapkan. Ada protokol yang rumit. Di Tarantool, Anda dapat memilih salah satu dari jenis replikasi ini, tergantung pada tugasnya.

Keterlambatan replika memunculkan tidak hanya desinkronisasi, tetapi juga pada masalah ketidaktahuan master: ia tidak tahu bagaimana meneruskan perubahannya ke replika. Perubahan biasanya diberikan secara bertahap - mereka diterapkan, dan dalam bentuk yang sama mereka terbang ke replika. Tapi apa yang harus dilakukan dengan mereka jika replika itu tidak tersedia? Misalnya, semuanya dapat dikonfigurasi di Tarantool, dan wizard menjadi sangat fleksibel.
Tantangan lain: bagaimana membuat topologi menjadi kompleks? Mail.ru, misalnya, memiliki topologi dengan ratusan Tarantool. Ini memiliki kernel tarantool di mana replika tarantula untuk cadangan terikat dalam lingkaran. Di Tarantool, Anda dapat membuat topologi yang sepenuhnya sewenang-wenang, replikasi dengan ini hidup dengan sempurna.
Sharding
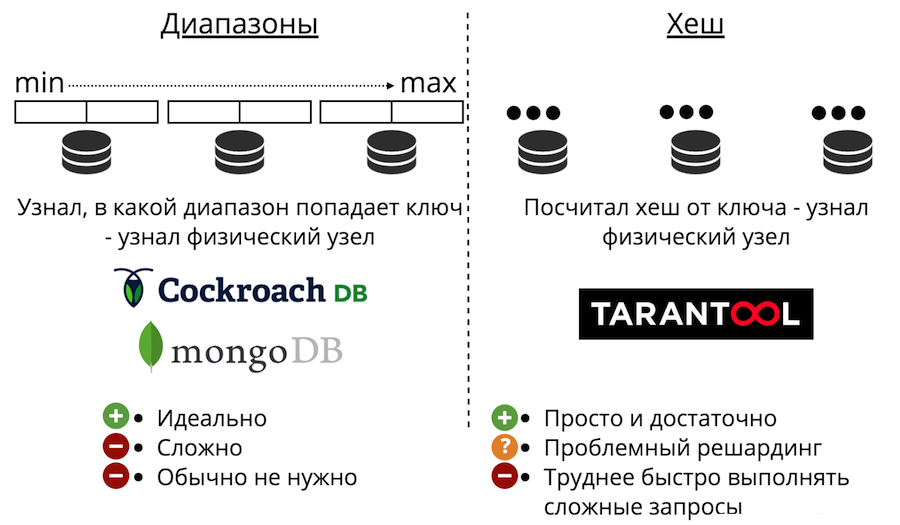
Sekarang mari kita beralih ke penskalaan data: sharding. Itu bisa dari dua jenis: rentang dan hash. Range sharding adalah ketika semua data diurutkan dengan beberapa kunci sharding, dan urutan besar ini dibagi menjadi rentang sehingga setiap rentang memiliki jumlah data yang kira-kira sama. Dan setiap rentang sepenuhnya disimpan pada satu simpul fisik. Tapi biasanya pecahan seperti itu tidak diperlukan. Apalagi itu selalu sangat rumit.
Ada juga sharding dengan hash. Itu hanya disajikan di Tarantool. Jauh lebih mudah untuk diterapkan, digunakan, dan hampir selalu cocok daripada rentang sharding. Ia bekerja seperti ini: kami mempertimbangkan fungsi hash dari catatan dan mengembalikan jumlah simpul fisik yang akan disimpan. Ada masalah: pertama, sulit untuk dengan cepat menyelesaikan permintaan yang kompleks.
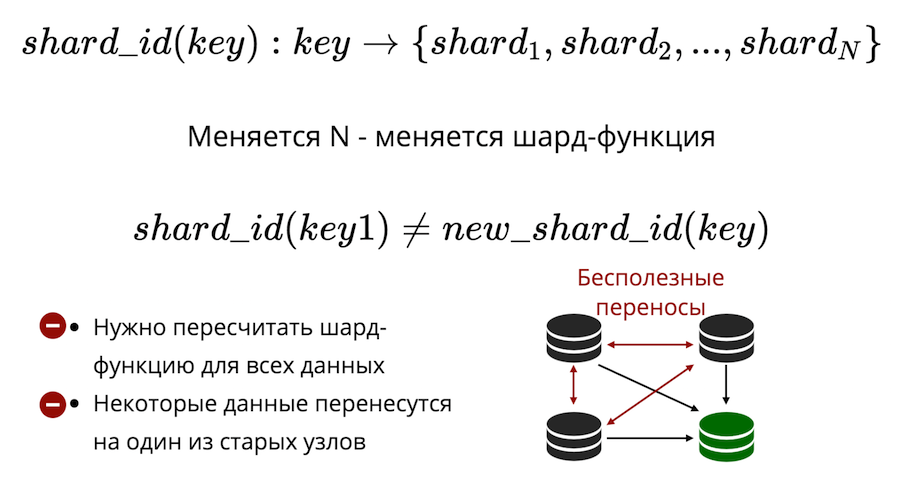
Kedua, ada masalah pengerjaan ulang. Ada beberapa jenis fungsi beling yang mengembalikan jumlah beling fisik di mana kunci harus disimpan. Dan ketika jumlah node berubah, fungsi shard juga berubah. Ini berarti bahwa untuk semua data yang ada di cluster, itu harus dihitung ulang dan diverifikasi lagi. Selain itu, dalam sharding klasik, beberapa data tidak akan ditransfer ke node baru, tetapi hanya terseret di antara node yang lama. Transfer tidak berguna tidak dapat dikurangi menjadi nol dalam sharding klasik.
Tarantool menggunakan virtual sharding: data didistribusikan bukan pada node fisik, tetapi pada yang virtual. Ember virtual dalam kluster virtual. Dan kisah virtual dituangkan pada yang fisik. Dan sudah ada dijamin bahwa setiap lantai virtual terletak sepenuhnya pada satu lantai fisik.
Bagaimana cara mengatasi masalah resolding? Faktanya adalah bahwa jumlah ember sudah diperbaiki dan secara serius melebihi jumlah node fisik. Jadi, tidak peduli seberapa besar Anda skala fisik cluster Anda, ember akan selalu cukup untuk menyimpan data dan mendistribusikannya secara merata. Dan karena fakta bahwa fungsi beling tidak berubah, Anda tidak perlu menghitung ulang ketika komposisi gugus berubah.
Hasilnya, kami mendapatkan
tiga jenis sharding: rentang, hash, dan ember virtual . Dalam hal rentang dan ember, ada masalah pencarian fisik.
Bagaimana cara mengatasinya? Cara pertama: hanya melarang pengerjaan ulang. Kemudian untuk pengulangan, Anda harus membuat cluster baru dan mentransfer semuanya di sana. Cara kedua: selalu pergi ke semua node. Tapi ini tidak masuk akal, karena Anda perlu skala, dan perhitungannya tidak skala seperti itu. Opsi ketiga: modul proxy, yang berfungsi sebagai semacam router untuk bucket. Anda memulainya, mengirim permintaan di sana, menunjukkan nomor ember, dan itu akan mengirim permintaan Anda sebagai proxy ke simpul fisik yang diinginkan.
Memori Lanjut dengan Contoh Platform GridGain
Bisnis ini memiliki persyaratan basis data tambahan. Dia ingin semua ini toleran terhadap kesalahan dan bencana. Dia ingin ketersediaan tinggi: agar tidak ada yang hilang, sehingga Anda dapat pulih dengan cepat. Juga dibutuhkan skalabilitas yang mudah dan murah, dukungan yang tidak rumit, kepercayaan pada platform dan mekanisme akses yang efisien.
Semua ide ini bukanlah hal baru. Banyak dari hal-hal ini, sampai taraf tertentu, diimplementasikan dalam DBMS klasik, khususnya replikasi antar pusat data.
In-Memory bukan lagi sebuah teknologi startup, itu adalah produk matang yang digunakan oleh perusahaan terbesar di dunia (Barclays, Citi Group, Microsoft, dll.). Diasumsikan bahwa semua persyaratan ini dipenuhi.
Jadi jika bencana tiba-tiba terjadi, harus ada kesempatan untuk pulih dari cadangan. Dan jika kita berbicara tentang organisasi keuangan, penting agar cadangan ini konsisten, dan bukan hanya salinan dari semua drive. Sehingga tidak ada situasi di mana pada beberapa bagian node data dipulihkan pada waktu X, dan pada bagian lain pada waktu Y. Sangat penting untuk memiliki Point-in-time Recovery, sehingga bahkan dalam situasi korupsi data atau kecelakaan yang sangat parah, meminimalkan jumlah kerugian.
Penting untuk bisa mendorong data ke disk. Sehingga cluster tidak jatuh di bawah kelebihan dan terus bekerja lebih lambat. Dan untuk cepat naik dari disk, dan kemudian sudah memompa data ke dalam memori.
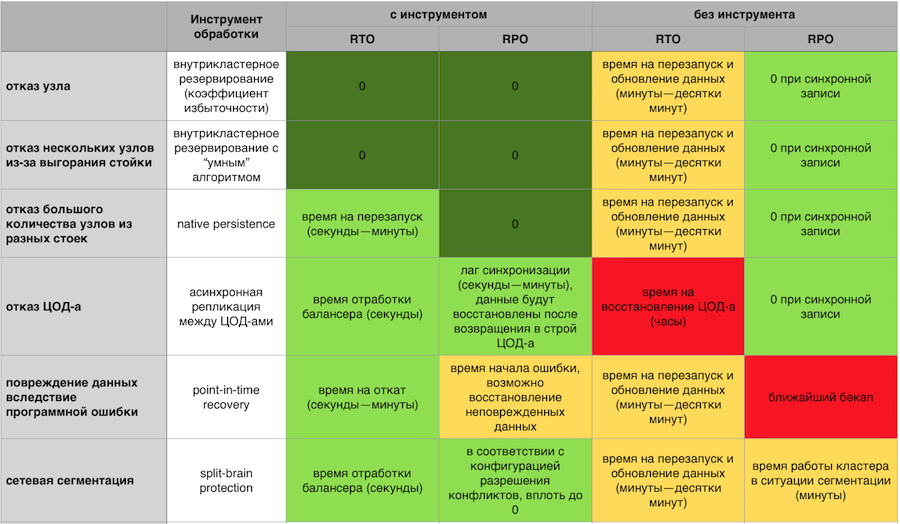 In-Memory response terhadap crash dengan dan tanpa komponen toleransi kesalahan GridGain
In-Memory response terhadap crash dengan dan tanpa komponen toleransi kesalahan GridGainCluster failover harus skala dengan mudah secara horizontal dan vertikal. Saya tidak merasa ingin membayar untuk server saya dan menonton bagaimana setengah dari sumber daya idle. Saya tidak ingin keluar dari ratusan proses yang perlu dikelola. Saya menginginkan sistem sederhana dari sudut pandang dukungan, dengan input-output node yang mudah dari cluster dan sistem pemantauan yang matang dan matang.
Pertimbangkan MongoDB dalam perspektif ini. Setiap orang yang telah bekerja dengan MongoDB menyadari sejumlah besar proses. Jika kita memiliki MongoDB yang diarsir dari 5 pecahan, maka setiap pecahan akan memiliki satu set replika dari tiga proses (dengan rasio redundansi 3). Dan ini hanya 15 proses pada data itu sendiri. Penyimpanan konfigurasi cluster adalah proses plus 3 lainnya, secara total mendapat 18, dan ini tidak termasuk router. Jika Anda ingin 20 pecahan, selamat datang dari 63+ (misalnya, 8, total 71) proses lainnya.
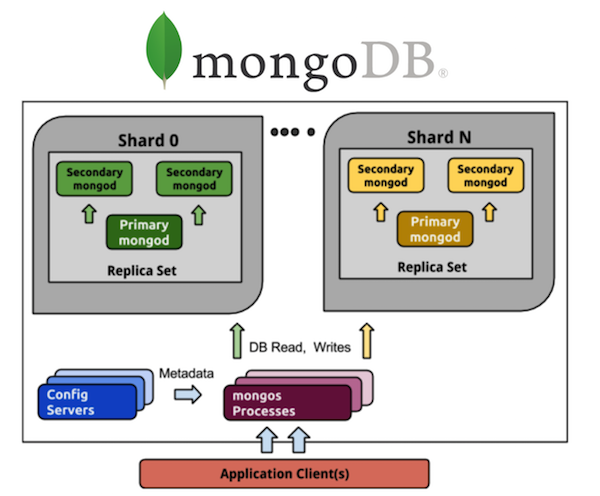
Bandingkan dengan Cassandra. Kami mengambil semua 5 pecahan yang sama - ini adalah 5 proses dan 5 node dengan rasio redundansi yang sama yaitu 3, yang jauh lebih sederhana dalam hal kontrol. Saya ingin 20 pecahan - ini adalah 20 proses. Saya bisa skala cluster saya ke sejumlah node, belum tentu kelipatan 3 (atau nilai lain dari koefisien redundansi). Jauh lebih mudah dan lebih murah untuk diimplementasikan dan dipelihara daripada set replika.

Selain itu, Anda perlu mempercayai sistem, untuk memahami apa yang orang-orang berdiri di belakang setiap produk individu. Idealnya, lisensi harus open source atau open core. Sehingga dalam kasus kematian vendor, sesuatu bisa dilakukan. Baik juga jika kode sumber dikelola oleh komunitas independen - kita semua ingat bagaimana MongoDB dan Redis mengubah lisensi atas permintaan perusahaan manajemen. Bagaimana Aerospike memperkenalkan pembatasan pada edisi komunitas "open source" pada awal tahun.
Butuh akses efektif ke data. Hampir semua memiliki bahasa permintaan terstruktur dalam satu bentuk atau lainnya. Paling sering mereka menggunakan SQL, perlu bahwa adaptasi dengan bahasa ini semudah mungkin. Ini akan membantu eksekusi permintaan terdistribusi, ketika Anda tidak perlu mengirim permintaan secara terpisah ke setiap node, tetapi Anda dapat berkomunikasi dengan cluster seperti dengan "jendela tunggal". Tanpa berpikir dari sudut pandang API, ini adalah sekumpulan node (ingat betapa sulitnya bekerja dengan Memcache pada volume besar bahkan pada tingkat put / get yang paling sederhana, tanpa potensi query SQL yang kompleks), mendistribusikan jaminan DDL dan ACID.
Dan akhirnya, dukungan. Jika sesuatu tiba-tiba tidak berfungsi, maka perusahaan kehilangan uang. Untuk beberapa bidang ini tidak kritis, tetapi seringkali penting bahwa seseorang memikul tanggung jawab untuk produk dan pekerjaannya. Bahwa dimungkinkan kapan saja untuk mengajukan klaim, dan itu cepat diselesaikan.
Dengan posting ini kami menyelesaikan tahun Promsvyazbank di Habré. Kami mengumpulkan harapan Tahun Baru bagi penduduk Khabrovsk dalam sebuah video pendek: