Hai teman-teman!

Dalam publikasi terakhir tahun yang akan datang, kami ingin menyebutkan Reinforcement Learning - sebuah topik yang sudah kami terjemahkan dalam
buku .
Menilai sendiri: ada artikel dasar dengan Medium, yang menguraikan konteks masalah, menggambarkan algoritma paling sederhana dengan implementasi di Python. Artikel ini memiliki beberapa gif. Dan motivasi, penghargaan dan memilih strategi yang tepat di jalan menuju kesuksesan adalah hal-hal yang akan sangat berguna bagi kita masing-masing di tahun mendatang.
Selamat membaca!
Pembelajaran yang diperkuat adalah suatu bentuk pembelajaran mesin di mana agen belajar untuk bertindak di lingkungan, melakukan tindakan dan dengan demikian mengembangkan intuisi, setelah itu ia mengamati hasil dari tindakannya. Pada artikel ini saya akan memberitahu Anda bagaimana memahami dan merumuskan masalah belajar dengan penguatan, dan kemudian menyelesaikannya dengan Python.
Baru-baru ini, kita menjadi terbiasa dengan kenyataan bahwa komputer bermain game melawan manusia - baik sebagai bot dalam game multi-pemain, atau sebagai saingan dalam game satu-satu: katakanlah, di Dota2, PUB-G, Mario. Perusahaan riset
Deepmind membuat
keributan tentang berita itu ketika program AlphaGo 2016 mereka mengalahkan juara Korea Selatan pada 2016. Jika Anda seorang gamer yang rajin, Anda bisa mendengar tentang lima pertandingan Dota 2 OpenAI Five, di mana mobil-mobil bertarung melawan orang-orang dan mengalahkan para pemain terbaik di Dota2 dalam beberapa pertandingan. (Jika Anda tertarik pada perinciannya, algoritme dianalisis secara terperinci di
sini dan diperiksa bagaimana mesin dimainkan).

Versi terbaru dari OpenAI Five
mengambil Roshan .
Jadi, mari kita mulai dengan pertanyaan sentral. Mengapa kita perlu pelatihan yang diperkuat? Apakah hanya digunakan dalam permainan, atau apakah itu berlaku dalam skenario realistis untuk menyelesaikan masalah yang diterapkan? Jika ini adalah pelatihan penguatan bacaan pertama Anda, Anda tidak bisa membayangkan jawaban untuk pertanyaan-pertanyaan ini. Memang, pembelajaran yang diperkuat adalah salah satu teknologi yang paling banyak digunakan dan berkembang pesat di bidang kecerdasan buatan.
Berikut adalah sejumlah bidang studi di mana sistem pembelajaran penguatan sangat dibutuhkan:
- Kendaraan tak berawak
- Industri game
- Robotika
- Sistem Rekomendasi
- Periklanan dan Pemasaran
Gambaran umum dan latar belakang pembelajaran penguatanJadi, bagaimana fenomena pembelajaran dengan penguatan terbentuk ketika kita memiliki begitu banyak mesin dan metode pembelajaran mendalam yang kita miliki? "Dia ditemukan oleh Rich Sutton dan Andrew Barto, supervisor penelitian Rich, yang membantunya mempersiapkan PhD." Paradigma pertama terbentuk pada 1980-an dan kemudian kuno. Selanjutnya, Rich percaya bahwa dia memiliki masa depan yang hebat, dan dia akhirnya akan menerima pengakuan.
Pembelajaran yang diperkuat mendukung otomasi di lingkungan di mana ia digunakan. Baik mesin dan pembelajaran mendalam beroperasi dalam cara yang kira-kira sama - mereka diatur secara strategis berbeda, tetapi kedua paradigma mendukung otomatisasi. Jadi, mengapa pelatihan penguatan muncul?
Ini sangat mengingatkan pada proses pembelajaran alami di mana proses / model bertindak dan menerima umpan balik tentang bagaimana dia berhasil mengatasi tugas: baik dan tidak.
Mesin dan pembelajaran mendalam juga merupakan opsi pelatihan, namun, mereka lebih disesuaikan untuk mengidentifikasi pola dalam data yang tersedia. Di sisi lain, dalam pembelajaran penguatan, pengalaman tersebut diperoleh melalui coba-coba; sistem secara bertahap menemukan opsi yang tepat atau global optimal. Keuntungan tambahan yang serius dari pembelajaran yang diperkuat adalah bahwa dalam hal ini, tidak perlu menyediakan satu set data pelatihan yang luas, seperti halnya mengajar dengan seorang guru. Beberapa fragmen kecil sudah cukup.
Konsep pembelajaran penguatanBayangkan mengajarkan kucing Anda trik baru; tetapi, sayangnya, kucing tidak mengerti bahasa manusia, jadi Anda tidak dapat mengambil dan memberi tahu mereka apa yang akan Anda mainkan dengan mereka. Karena itu, Anda akan bertindak berbeda: meniru situasi, dan kucing akan berusaha merespons dengan satu atau lain cara dalam merespons. Jika kucing bereaksi seperti yang Anda inginkan, maka Anda menuangkan susu ke dalamnya. Apakah Anda mengerti apa yang akan terjadi selanjutnya? Sekali lagi, dalam situasi yang sama, kucing akan melakukan tindakan yang diinginkan lagi, dan dengan antusiasme yang lebih besar, berharap bahwa ia akan diberi makan lebih baik lagi. Ini adalah bagaimana pembelajaran terjadi pada contoh positif; tetapi, jika Anda mencoba untuk "mendidik" kucing dengan insentif negatif, misalnya, perhatikan dengan seksama dan mengerutkan kening, ia biasanya tidak belajar dalam situasi seperti itu.
Pembelajaran yang diperkuat bekerja dengan cara yang sama. Kami memberi tahu mesin tersebut beberapa input dan tindakan, dan kemudian memberi hadiah kepada mesin tergantung pada hasilnya. Tujuan utama kami adalah memaksimalkan imbalan. Sekarang mari kita lihat bagaimana merumuskan kembali masalah di atas dalam hal pembelajaran penguatan.
- Kucing bertindak sebagai "agen" yang terpapar pada "lingkungan".
- Lingkungan adalah rumah atau area bermain, tergantung pada apa yang Anda ajarkan pada kucing.
- Situasi yang timbul dari pelatihan disebut "keadaan". Dalam kasus kucing, contoh kondisi adalah ketika kucing "berlari" atau "merangkak di bawah tempat tidur."
- Agen bereaksi dengan melakukan tindakan dan berpindah dari satu "keadaan" ke yang lain.
- Setelah keadaan berubah, agen menerima "hadiah" atau "denda" tergantung pada tindakan yang telah diambil.
- "Strategi" adalah metodologi untuk memilih tindakan untuk mendapatkan hasil terbaik.
Sekarang kita telah mengetahui apa itu pembelajaran penguatan, mari kita bicara secara rinci tentang asal-usul dan evolusi pembelajaran penguatan dan pembelajaran penguatan yang mendalam, bahas bagaimana paradigma ini memungkinkan kita untuk memecahkan masalah yang tidak mungkin untuk dipelajari dengan atau tanpa guru, dan perhatikan juga hal-hal berikut fakta yang aneh: saat ini, mesin pencari Google dioptimalkan menggunakan algoritma pembelajaran penguatan.
Memahami terminologi penguatan pembelajaranAgen dan Lingkungan memainkan peran kunci dalam algoritma pembelajaran penguatan. Lingkungan adalah dunia di mana Agen harus bertahan hidup. Selain itu, Agen menerima sinyal penguatan dari Lingkungan (hadiah): ini adalah angka yang menggambarkan seberapa baik atau buruk kondisi dunia saat ini dapat dipertimbangkan. Tujuan Agen adalah untuk memaksimalkan total hadiah, yang disebut "keuntungan". Sebelum menulis algoritma pembelajaran penguatan pertama kami, Anda perlu memahami terminologi berikut.

- Negara : Negara bagian adalah uraian lengkap tentang dunia di mana tidak ada satu bagian pun dari informasi yang mencirikan dunia ini yang hilang. Itu bisa berupa posisi, tetap atau dinamis. Sebagai aturan, negara-negara tersebut ditulis dalam bentuk array, matriks atau tensor orde tinggi.
- Tindakan : Tindakan biasanya tergantung pada kondisi lingkungan, dan di lingkungan yang berbeda agen akan mengambil tindakan yang berbeda. Banyak tindakan agen yang valid dicatat dalam ruang yang disebut "ruang tindakan". Biasanya, jumlah tindakan di ruang terbatas.
- Lingkungan : Ini adalah tempat di mana agen itu ada dan dengan mana ia berinteraksi. Berbagai jenis penghargaan, strategi, dll. Digunakan untuk lingkungan yang berbeda.
- Hadiah dan kemenangan : Anda harus terus-menerus memonitor fungsi hadiah R saat berlatih dengan bala bantuan. Sangat penting ketika mengatur algoritma, mengoptimalkannya, dan juga ketika Anda berhenti belajar. Itu tergantung pada keadaan dunia saat ini, tindakan yang baru saja diambil dan keadaan dunia berikutnya.
- Strategi : strategi adalah aturan yang menurutnya agen memilih tindakan selanjutnya. Himpunan strategi juga disebut sebagai "otak" agen.
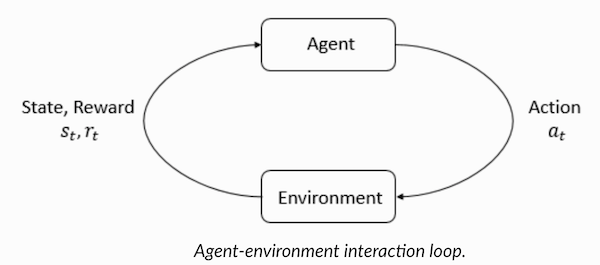
Sekarang kita telah terbiasa dengan terminologi pembelajaran penguatan, mari kita selesaikan masalah menggunakan algoritma yang sesuai. Sebelum ini, Anda perlu memahami bagaimana merumuskan masalah seperti itu, dan ketika memecahkan masalah ini, bergantung pada terminologi pelatihan dengan penguatan.
Solusi taksiJadi, kami beralih ke pemecahan masalah dengan menggunakan algoritma penguatan.
Misalkan kita memiliki zona pelatihan untuk taksi tak berawak, yang kita latih untuk mengantarkan penumpang ke tempat parkir di empat titik berbeda (
R,G,Y,B ). Sebelum itu, Anda perlu memahami dan mengatur lingkungan tempat kami memulai pemrograman dengan Python. Jika Anda baru mulai mempelajari Python, saya merekomendasikan
artikel ini untuk Anda .
Lingkungan untuk memecahkan masalah taksi dapat dikonfigurasi menggunakan OpenAI's
Gym - ini adalah salah satu perpustakaan paling populer untuk memecahkan masalah dengan pelatihan penguatan. Nah, sebelum menggunakan gym, Anda harus menginstalnya di komputer Anda, dan manajer paket Python bernama pip nyaman untuk ini. Berikut ini adalah perintah instalasi.
pip install gymSelanjutnya, mari kita lihat bagaimana lingkungan kita akan ditampilkan. Semua model dan antarmuka untuk tugas ini sudah dikonfigurasi di gym dan diberi nama di bawah
Taxi-V2 . Cuplikan kode di bawah ini digunakan untuk menampilkan lingkungan ini.
“Kami memiliki 4 lokasi (ditunjukkan dengan berbagai huruf); tugas kami adalah untuk mengambil penumpang di satu titik dan mengantarnya di tempat lain. Kami mendapatkan +20 poin untuk pendaratan penumpang yang sukses dan kehilangan 1 poin untuk setiap langkah yang dihabiskan untuk itu. Ada juga penalti 10 poin untuk setiap penumpang yang tidak diinginkan dan turun dari penumpang. ” (Sumber:
gym.openai.com/envs/Taxi-v2 )
Ini adalah output yang akan kita lihat di konsol kita:

Taksi V2 ENV
Hebat,
env adalah jantung dari OpenAi Gym, ini adalah antarmuka lingkungan terpadu. Berikut ini adalah metode env yang kami anggap berguna:
env.reset : mengatur ulang lingkungan dan mengembalikan keadaan awal acak.
env.step(action) :
env.step(action) pengembangan lingkungan satu langkah dalam waktu.
env.step(action) : mengembalikan variabel berikut
observation : Pengamatan lingkungan.reward : reward apakah tindakan Anda bermanfaat.done : Menunjukkan apakah kami berhasil mengambil dan menurunkan penumpang dengan benar, juga disebut sebagai "satu episode."info : Informasi tambahan seperti kinerja dan latensi yang diperlukan untuk tujuan debugging.env.render : Menampilkan satu bingkai lingkungan (berguna untuk rendering)
Jadi, setelah memeriksa lingkungannya, mari kita coba untuk lebih memahami masalahnya. Taksi adalah satu-satunya mobil di tempat parkir ini. Parkir dapat dibagi menjadi kotak
5x5 , di mana kami mendapatkan 25 kemungkinan lokasi taksi. 25 nilai ini adalah salah satu elemen ruang negara kita. Harap dicatat: saat ini, taksi kami terletak di titik dengan koordinat (3, 1).
Ada 4 titik di lingkungan di mana penumpang diizinkan naik: ini adalah:
R, G, Y, B atau
[(0,0), (0,4), (4,0), (4,3)] dalam koordinat ( horizontal; vertikal), jika mungkin untuk menafsirkan lingkungan di atas dalam koordinat Cartesius. Jika Anda juga memperhitungkan satu lagi (1) keadaan penumpang: di dalam taksi, Anda dapat mengambil semua kombinasi lokasi penumpang dan tujuan mereka untuk menghitung jumlah negara bagian di lingkungan kami untuk pelatihan taksi: kami memiliki empat (4) tujuan dan lima (4+) 1) lokasi penumpang.
Jadi, di lingkungan kita untuk taksi, ada 5 × 5 × 5 × 4 = 500 negara. Seorang agen menangani salah satu dari 500 syarat dan mengambil tindakan. Dalam kasus kami, opsinya adalah sebagai berikut: bergerak ke satu arah atau yang lain, atau keputusan untuk mengambil / menurunkan penumpang. Dengan kata lain, kami memiliki enam kemungkinan tindakan yang kami miliki:
pickup, drop, utara, timur, selatan, barat (Empat nilai terakhir adalah arah di mana taksi dapat bergerak.)
Ini adalah
action space : set dari semua tindakan yang agen kami dapat ambil dalam keadaan tertentu.
Seperti yang jelas dari ilustrasi di atas, taksi tidak dapat melakukan tindakan tertentu dalam beberapa situasi (gangguan dinding). Dalam kode yang menggambarkan lingkungan, kita cukup memberikan penalti -1 untuk setiap pukulan di dinding, dan taksi bertabrakan dengan dinding. Dengan demikian, denda tersebut akan menumpuk, sehingga taksi akan berusaha untuk tidak menabrak dinding.
Tabel hadiah: Saat membuat lingkungan taksi, tabel hadiah utama yang disebut P juga dapat dibuat. Anda dapat menganggapnya sebagai matriks, di mana jumlah negara sesuai dengan jumlah baris dan jumlah tindakan dengan jumlah kolom. Artinya, kita berbicara tentang matriks
states × actions .
Karena benar-benar semua kondisi dicatat dalam matriks ini, Anda dapat melihat nilai hadiah default yang ditetapkan untuk keadaan yang telah kami pilih untuk menggambarkan:
>>> import gym >>> env = gym.make("Taxi-v2").env >>> env.P[328] {0: [(1.0, 433, -1, False)], 1: [(1.0, 233, -1, False)], 2: [(1.0, 353, -1, False)], 3: [(1.0, 333, -1, False)], 4: [(1.0, 333, -10, False)], 5: [(1.0, 333, -10, False)] }
Struktur kamus ini adalah sebagai berikut:
{action: [(probability, nextstate, reward, done)]} .
- Nilai 0–5 sesuai dengan tindakan (selatan, utara, timur, barat, pickup, dropoff) yang dapat dilakukan taksi dalam keadaan saat ini seperti yang ditunjukkan dalam ilustrasi.
- selesai memungkinkan Anda untuk menilai ketika kami berhasil menurunkan penumpang pada titik yang diinginkan.
Untuk mengatasi masalah ini tanpa pelatihan penguatan, Anda dapat mengatur status target, memilih ruang, dan kemudian, jika Anda dapat mencapai status target untuk sejumlah iterasi, asumsikan bahwa momen ini sesuai dengan hadiah maksimum. Di negara-negara lain, nilai hadiah dapat mendekati maksimum jika program bertindak dengan benar (mendekati tujuan) atau mengakumulasi denda jika itu membuat kesalahan. Selain itu, nilai denda bisa mencapai tidak lebih rendah dari -10.
Mari kita menulis kode untuk menyelesaikan masalah ini tanpa pelatihan penguatan.
Karena kami memiliki tabel-P dengan nilai hadiah default untuk setiap negara bagian, kami dapat mencoba mengatur navigasi taksi kami hanya berdasarkan tabel ini.
Kami membuat lingkaran tanpa akhir, menggulir hingga penumpang mencapai tujuan (satu episode), atau, dengan kata lain, hingga tingkat hadiah mencapai 20. Metode
env.action_space.sample() secara otomatis memilih tindakan acak dari serangkaian semua tindakan yang tersedia . Pertimbangkan apa yang terjadi:
import gym from time import sleep
Kesimpulan:
kredit: OpenAI
Masalahnya dipecahkan, tetapi tidak dioptimalkan, atau algoritma ini tidak akan berfungsi dalam semua kasus. Kami membutuhkan agen interaksi yang sesuai sehingga jumlah iterasi yang dihabiskan oleh mesin / algoritma untuk menyelesaikan masalah tetap minimal. Di sini algoritma Q-learning akan membantu kita, implementasi yang akan kita bahas di bagian selanjutnya.
Memperkenalkan Q-LearningDi bawah ini adalah yang paling populer dan salah satu algoritma pembelajaran penguatan paling sederhana. Lingkungan menghargai agen untuk pelatihan bertahap dan untuk fakta bahwa dalam keadaan tertentu ia mengambil langkah paling optimal. Dalam implementasi yang dibahas di atas, kami memiliki tabel hadiah “P”, yang akan dipelajari oleh agen kami. Berdasarkan tabel hadiah, ia memilih tindakan berikutnya tergantung pada seberapa bermanfaatnya, dan kemudian memperbarui nilai lain, yang disebut nilai-Q. Akibatnya, sebuah tabel baru dibuat, disebut Q-table, ditampilkan pada kombinasi (Status, Action). Jika nilai-Q lebih baik, maka kami mendapatkan hadiah yang lebih optimal.
Misalnya, jika taksi dalam keadaan di mana penumpang berada pada titik yang sama dengan taksi, sangat mungkin bahwa nilai Q untuk tindakan "penjemputan" lebih tinggi daripada tindakan lain, misalnya, "mengantar penumpang" atau "pergi ke utara" ".
Nilai-Q diinisialisasi dengan nilai acak, dan ketika agen berinteraksi dengan lingkungan dan menerima berbagai penghargaan dengan melakukan tindakan tertentu, nilai-Q diperbarui sesuai dengan persamaan berikut:

Ini menimbulkan pertanyaan: bagaimana menginisialisasi nilai-Q dan bagaimana menghitungnya. Saat tindakan dilakukan, nilai-Q dieksekusi dalam persamaan ini.
Di sini, Alpha dan Gamma adalah parameter dari algoritma Q-learning. Alpha adalah langkah belajar, dan gamma adalah faktor diskon. Kedua nilai dapat berkisar dari 0 hingga 1 dan terkadang sama dengan satu. Gamma dapat sama dengan nol, tetapi alpha tidak bisa, karena nilai kerugian selama pembaruan harus dikompensasi (tingkat pembelajaran positif). Nilai alfa di sini sama dengan ketika mengajar dengan seorang guru. Gamma menentukan seberapa penting kita ingin memberikan hadiah yang menanti kita di masa depan.
Algoritma ini dirangkum di bawah ini:
- Langkah 1: inisialisasi tabel-Q, mengisinya dengan nol, dan untuk nilai-Q kita tetapkan konstanta acak.
- Langkah 2: Sekarang biarkan agen merespons lingkungan dan mencoba tindakan yang berbeda. Untuk setiap perubahan status, kami memilih salah satu dari semua tindakan yang dimungkinkan dalam kondisi ini (S).
- Langkah 3: Pergi ke status berikutnya (S ') berdasarkan hasil dari tindakan sebelumnya (a).
- Langkah 4: Untuk semua tindakan yang mungkin dari status (S '), pilih satu dengan nilai Q tertinggi.
- Langkah 5: Perbarui nilai-nilai Q-tabel sesuai dengan persamaan di atas.
- Langkah 6: Ubah status berikutnya menjadi yang sekarang.
- Langkah 7: Jika negara target tercapai, kami menyelesaikan proses, dan kemudian ulangi.
Q-learning dengan Python import gym import numpy as np import random from IPython.display import clear_output
Hebat, sekarang semua nilai Anda akan disimpan dalam variabel
q_table .
Jadi, model Anda dilatih dalam kondisi lingkungan, dan sekarang tahu cara memilih penumpang dengan lebih akurat. Dan Anda berkenalan dengan fenomena pembelajaran penguatan, dan Anda dapat memprogram algoritma untuk memecahkan masalah baru.
Teknik pembelajaran penguatan lainnya:
- Markov proses pengambilan keputusan (MDP) dan persamaan Bellman
- Pemrograman Dinamis: RL Berbasis Model, Iterasi Strategi, dan Iterasi Nilai
- Pelatihan-Q yang mendalam
- Metode penurunan strategi gradien
- Sarsa
Kode untuk latihan ini terletak di:
vihar / python-reinforcement-learning