Kami di OpenAI menemukan bahwa skala kebisingan gradien, metode statistik sederhana, memprediksi paralelisasi pembelajaran jaringan netral di berbagai tugas. Karena gradien biasanya menjadi ribut untuk tugas-tugas yang lebih kompleks, peningkatan ukuran paket yang tersedia untuk pemrosesan simultan akan terbukti berguna di masa depan, dan akan menghilangkan salah satu keterbatasan potensial sistem AI. Dalam kasus umum, hasil ini menunjukkan bahwa pelatihan jaringan saraf tidak boleh dianggap sebagai seni yang misterius, dan bahwa itu dapat diberikan akurasi dan sistematis.
Selama beberapa tahun terakhir, para peneliti AI telah semakin berhasil dalam mempercepat pembelajaran jaringan saraf dengan memparalelkan data, memecah paket data yang besar ke dalam banyak komputer. Para peneliti telah berhasil menggunakan puluhan ribu unit untuk
klasifikasi gambar dan
pemodelan bahasa , dan bahkan untuk jutaan
agen pembelajaran yang memperkuat Dota 2. Paket besar tersebut dapat meningkatkan jumlah daya komputasi yang secara efektif terlibat dalam pengajaran satu model, dan merupakan satu kekuatan yang mendorong
pertumbuhan dalam pelatihan AI. Namun, dengan paket data yang terlalu besar, ada penurunan cepat dalam pengembalian algoritmik, dan tidak jelas mengapa pembatasan ini ternyata lebih besar untuk beberapa tugas dan lebih kecil untuk yang lain.
 Penskalaan kebisingan gradien, rerata di atas pendekatan pelatihan, menyumbang sebagian besar (r 2 = 80%) dari variasi ukuran paket data penting untuk berbagai masalah, berbeda dengan enam urutan besarnya. Ukuran paket diukur dalam jumlah gambar, token (untuk model bahasa) atau pengamatan (untuk game).
Penskalaan kebisingan gradien, rerata di atas pendekatan pelatihan, menyumbang sebagian besar (r 2 = 80%) dari variasi ukuran paket data penting untuk berbagai masalah, berbeda dengan enam urutan besarnya. Ukuran paket diukur dalam jumlah gambar, token (untuk model bahasa) atau pengamatan (untuk game).Kami menemukan bahwa dengan mengukur skala kebisingan gradien, statistik sederhana yang secara numerik menentukan rasio signal-to-noise dalam gradien jaringan, kami dapat memperkirakan ukuran paket maksimum. Heuristically, skala kebisingan mengukur variasi data dari sudut pandang model (pada tahap pelatihan tertentu). Ketika skala kebisingan kecil, pembelajaran paralel pada sejumlah besar data dengan cepat menjadi berlebihan, dan ketika itu besar, kita bisa belajar banyak pada kumpulan data besar.
Statistik jenis ini banyak digunakan untuk
menentukan ukuran sampel , dan
disarankan untuk digunakan dalam pembelajaran yang mendalam , tetapi tidak secara sistematis digunakan untuk pelatihan jaringan saraf modern. Kami telah mengkonfirmasi prediksi ini untuk berbagai tugas pembelajaran mesin yang digambarkan dalam grafik di atas, termasuk pengenalan pola, pemodelan bahasa, game Atari dan Dota. Secara khusus, kami melatih jaringan saraf yang dirancang untuk menyelesaikan masing-masing masalah pada paket data dari berbagai ukuran (secara terpisah menyesuaikan kecepatan belajar untuk masing-masing), dan membandingkan percepatan pembelajaran dengan yang diprediksi oleh skala kebisingan. Karena paket data berukuran besar sering memerlukan penyesuaian yang cermat dan mahal atau jadwal khusus kecepatan pelatihan agar pelatihan menjadi efektif, mengetahui batas atas di muka, Anda bisa mendapatkan keuntungan yang signifikan saat melatih model baru.
Kami merasa berguna untuk memvisualisasikan hasil percobaan ini sebagai kompromi antara waktu pelatihan aktual dan jumlah total perhitungan yang diperlukan untuk pelatihan (sebanding dengan biaya dalam uang). Pada paket data yang sangat kecil, menggandakan ukuran paket memungkinkan pelatihan dilakukan dua kali lebih cepat tanpa menggunakan daya komputasi tambahan (kami menjalankan dua kali masing-masing utas yang bekerja dua kali lebih cepat). Pada maket data yang sangat besar, paralelisasi tidak mempercepat pembelajaran. Kurva di tikungan tengah, dan skala kebisingan gradien memprediksi di mana tepatnya tikungan terjadi.
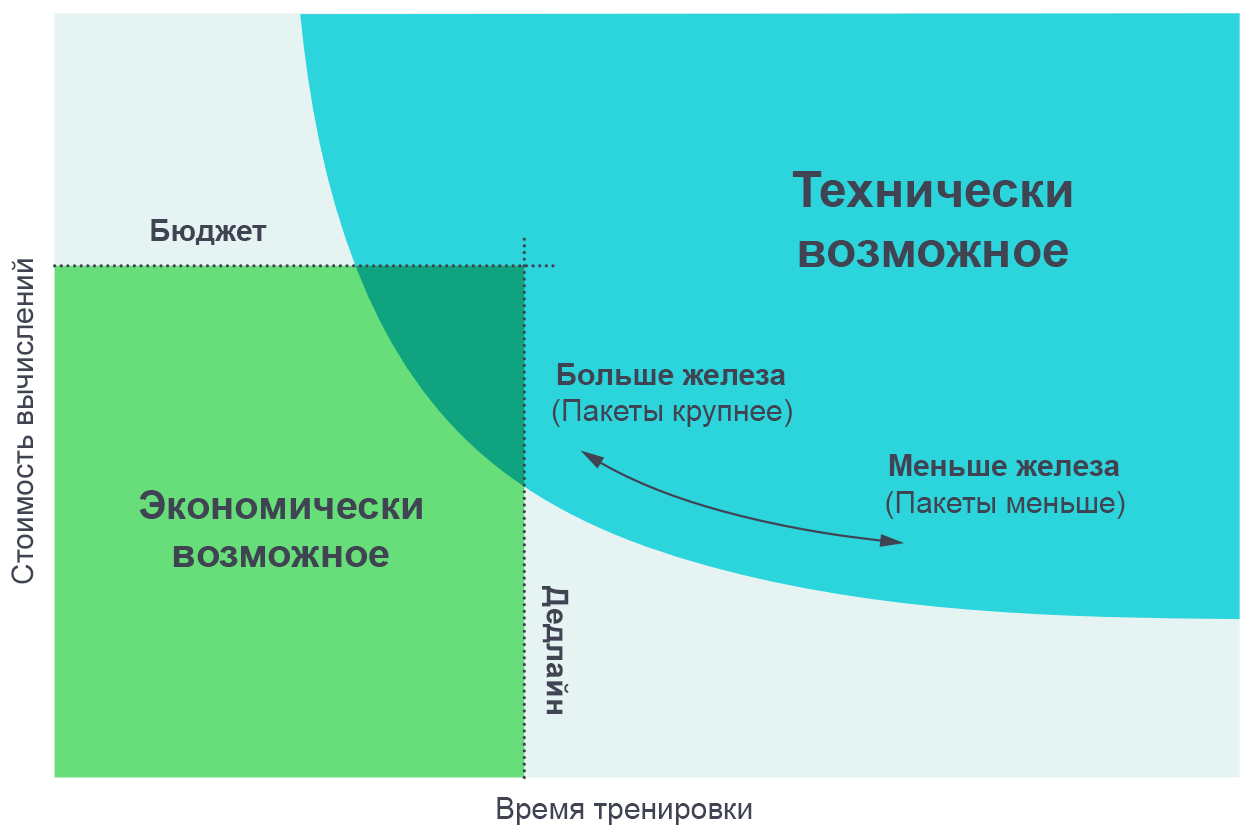 Meningkatkan jumlah proses paralel memungkinkan Anda untuk melatih model yang lebih kompleks dalam waktu yang wajar. Diagram perbatasan Pareto adalah cara yang paling intuitif untuk memvisualisasikan perbandingan algoritma dan skala.
Meningkatkan jumlah proses paralel memungkinkan Anda untuk melatih model yang lebih kompleks dalam waktu yang wajar. Diagram perbatasan Pareto adalah cara yang paling intuitif untuk memvisualisasikan perbandingan algoritma dan skala.Kami memperoleh kurva ini dengan menetapkan tujuan untuk tugas tersebut (misalnya, 1000 poin dalam permainan Atari Beam Rider), dan mengamati berapa lama waktu yang dibutuhkan untuk melatih jaringan saraf untuk mencapai tujuan ini pada ukuran paket yang berbeda. Hasilnya cukup akurat bertepatan dengan prediksi model kami, dengan mempertimbangkan berbagai nilai tujuan yang kami tetapkan.
[
Halaman dengan artikel asli menyajikan grafik interaktif kompromi antara pengalaman dan waktu pelatihan yang diperlukan untuk mencapai tujuan yang diberikan ]
Pola skala kebisingan gradien
Kami menemukan beberapa pola dalam skala gradien kebisingan, atas dasar yang kita dapat membuat asumsi tentang masa depan pelatihan AI.
Pertama, dalam percobaan kami dalam proses pembelajaran, skala kebisingan biasanya meningkat dengan urutan besarnya atau lebih. Rupanya, ini berarti bahwa jaringan mempelajari fitur-fitur yang lebih “jelas” dari masalah di awal pelatihan, dan kemudian mempelajari perincian yang lebih kecil. Misalnya, dalam tugas mengklasifikasikan gambar, jaringan saraf pertama dapat belajar mengidentifikasi fitur skala kecil, seperti tepi atau tekstur yang ditunjukkan pada sebagian besar gambar, dan hanya kemudian membandingkan hal-hal kecil ini bersama-sama, menciptakan konsep yang lebih umum, seperti kucing atau anjing. Untuk mendapatkan gambaran tentang seluruh ragam wajah dan tekstur, jaringan saraf perlu melihat sejumlah kecil gambar, sehingga skala noise lebih kecil; segera setelah jaringan tahu lebih banyak tentang objek yang lebih besar, itu akan dapat memproses lebih banyak gambar pada saat yang sama tanpa mempertimbangkan data duplikat.
Kami melihat beberapa
indikasi awal bahwa efek yang sama juga bekerja pada model lain yang berurusan dengan set data yang sama - untuk model yang lebih kuat, skala kebisingan gradien lebih tinggi, tetapi hanya karena mereka memiliki lebih sedikit kerugian. Oleh karena itu, ada beberapa bukti bahwa meningkatkan skala kebisingan selama pelatihan bukan hanya artefak konvergensi, tetapi karena peningkatan dalam model. Jika demikian, maka kita dapat berharap bahwa di masa depan, model yang ditingkatkan akan memiliki skala kebisingan yang besar dan akan lebih cocok untuk paralelisasi.
Kedua, tugas-tugas yang secara objektif lebih kompleks lebih baik menerima paralelisasi. Dalam konteks mengajar dengan seorang guru, kemajuan nyata terlihat dalam transisi dari MNIST ke SVHN dan ImageNet. Dalam konteks pelatihan penguatan, kemajuan yang jelas terlihat dalam transisi dari Atari Pong ke
Dota 1v1 dan
Dota 5v5 , dan ukuran paket data yang optimal bervariasi 10.000 kali. Oleh karena itu, saat AI mengatasi tugas yang semakin kompleks, diharapkan model akan mengatasi set data yang semakin besar.
Konsekuensinya
Tingkat paralelisasi data secara serius mempengaruhi kecepatan pengembangan kemampuan AI. Mempercepat pembelajaran memungkinkan untuk membuat model yang lebih mampu dan mempercepat penelitian, memungkinkan Anda untuk mempersingkat waktu setiap iterasi.
Dalam studi sebelumnya, "
AI dan perhitungan, " kami melihat bahwa perhitungan untuk melatih model terbesar berlipat ganda setiap 3,5 bulan, dan mencatat bahwa tren ini didasarkan pada kombinasi ekonomi (keinginan untuk menghabiskan uang untuk perhitungan) dan kemampuan algoritmik untuk memaralelkan pembelajaran . Faktor terakhir (paralelisasi algoritmik) lebih sulit diprediksi, dan keterbatasannya belum sepenuhnya dipelajari, tetapi hasil kami saat ini merupakan langkah maju dalam sistematisasi dan ekspresi numeriknya. Secara khusus, kami memiliki bukti bahwa tugas yang lebih kompleks, atau model yang lebih kuat yang ditujukan untuk tugas yang diketahui, akan memungkinkan pekerjaan yang lebih paralel dengan data. Ini akan menjadi faktor kunci yang mendukung pertumbuhan eksponensial komputasi terkait pembelajaran. Dan kami bahkan tidak mempertimbangkan
perkembangan terbaru dalam bidang model paralel, yang dapat memungkinkan kami untuk lebih meningkatkan paralelisasi dengan menambahkannya ke pemrosesan data paralel yang ada.
Pertumbuhan yang berkelanjutan dari bidang pelatihan komputasi dan basis algoritmanya yang dapat diprediksi berbicara tentang kemungkinan peningkatan eksplosif kemampuan AI dalam beberapa tahun mendatang, dan menekankan perlunya
studi awal
tentang penggunaan yang aman dan
bertanggung jawab dari sistem tersebut. Kesulitan utama dalam membuat kebijakan AI adalah memutuskan bagaimana langkah-langkah tersebut dapat digunakan untuk memprediksi karakteristik sistem AI di masa depan, dan menggunakan pengetahuan ini untuk membuat aturan yang memungkinkan masyarakat untuk memaksimalkan sifat-sifatnya yang bermanfaat dan meminimalkan kerusakan teknologi ini.
OpenAI berencana untuk melakukan analisis ketat untuk memprediksi masa depan AI, dan secara proaktif mengatasi tantangan yang diangkat oleh analisis ini.