
Jadi, inilah saatnya untuk berbicara tentang generasi prosesor multiselular berikutnya: MultiClet S1. Jika ini adalah pertama kalinya Anda mendengar tentang mereka, pastikan untuk memeriksa sejarah dan ideologi arsitektur dalam artikel ini:
Saat ini, prosesor baru sedang dalam pengembangan, tetapi hasil pertama telah muncul dan Anda dapat mengevaluasi kemampuannya.
Mari kita mulai dengan perubahan terbesar: fitur dasar.
Karakteristik
Direncanakan untuk mencapai indikator berikut:
- Jumlah sel: 64
- Proses teknis: 28 nm
- Frekuensi jam: 1,6 GHz
- Ukuran memori pada chip: 8 MB
- Area Kristal: 40mm 2
- Konsumsi Daya: 6 W
Bilangan real akan diumumkan berdasarkan hasil pengujian sampel yang diproduksi pada 2019. Selain karakteristik chip itu sendiri, prosesor akan mendukung hingga 16 GB DDR4 3200MHz RAM standar, PCI Express bus dan PLL.
Perlu dicatat bahwa proses pembuatan 28 nm adalah rentang rumah tangga terendah yang tidak memerlukan izin khusus untuk digunakan, jadi dialah yang terpilih. Dengan jumlah sel, opsi yang berbeda dipertimbangkan: 128 dan 256, tetapi dengan peningkatan luas kristal, persentase penolakan meningkat. Kami memilih 64 sel dan, dengan demikian, area yang relatif kecil, yang akan memberikan hasil yang lebih besar dari kristal yang cocok di piring. Pengembangan lebih lanjut dimungkinkan dalam kerangka
ICS (sistem dalam kasus ini) , di mana dimungkinkan untuk menggabungkan beberapa kristal 64-sel dalam satu kasus.
Harus dikatakan bahwa tujuan dan penggunaan prosesor berubah secara radikal. S1 tidak akan menjadi mikroprosesor yang dirancang untuk disematkan, seperti P1 dan R1, tetapi akselerator perhitungan. Sama seperti GPGPU, papan berbasis S1 dapat dimasukkan ke motherboard PCI Express dari PC biasa dan digunakan untuk pemrosesan data.
Arsitektur
Dalam S1, "multisel" sekarang menjadi unit komputasi minimal: satu set 4 sel yang menjalankan urutan perintah tertentu. Pada awalnya direncanakan untuk menggabungkan multisel menjadi kelompok yang disebut cluster untuk eksekusi perintah bersama: sebuah cluster harus berisi 4 multisel, secara total ada 4 cluster terpisah pada kristal. Namun, setiap sel memiliki koneksi lengkap dengan semua sel lain dalam cluster, dan dengan peningkatan dalam kelompok ikatan itu menjadi terlalu banyak, yang sangat menyulitkan desain topologi dari rangkaian mikro dan mengurangi karakteristiknya. Oleh karena itu, mereka memutuskan untuk meninggalkan divisi cluster, karena komplikasi tidak membenarkan hasil. Selain itu, untuk kinerja maksimum, yang paling bermanfaat adalah menjalankan kode secara paralel pada setiap multisel. Total, sekarang prosesor mengandung 16 multicell terpisah.
Multisel, walaupun terdiri dari 4 sel, berbeda dari 4 sel R1, di mana setiap sel memiliki ingatannya sendiri, blok perintah sampelnya sendiri, ALUnya sendiri. S1 diatur sedikit berbeda. ALU memiliki 2 bagian: blok aritmatika floating point dan blok aritmatika integer. Setiap sel memiliki blok integer yang terpisah, tetapi hanya ada dua blok dengan titik apung dalam multisel, dan oleh karena itu dua pasang sel membaginya di antara mereka sendiri. Hal ini dilakukan terutama untuk mengurangi luas kristal: aritmatika titik apung 64-bit, berbeda dengan aritmatika bilangan bulat, membutuhkan banyak ruang. Memiliki ALU seperti itu di setiap sel ternyata berlebihan: mengambil perintah tidak memberikan pemuatan ALU dan mereka menganggur. Sementara mengurangi jumlah blok ALU dan mempertahankan laju perintah sampel dan data, seperti yang telah ditunjukkan oleh praktik, total waktu untuk memecahkan masalah secara praktis tidak berubah atau sedikit berubah, dan blok ALU dimuat penuh. Selain itu, aritmatika floating-point tidak digunakan sesering dengan integer.
Pandangan skematis dari blok prosesor R1 dan S1 ditunjukkan pada diagram di bawah ini. Di sini:
- CU (Control Unit) - unit pengambilan instruksi
- ALU FX - unit aritmatika logika bilangan bulat aritmatika
- ALU FP - Unit logika aritmatika aritmatika floating point
- DMS (Data Memory Scheduler) - unit kontrol memori data
- DM - memori data
- PMS (Program Memory Scheduler) - unit kontrol memori program
- PM - memori program
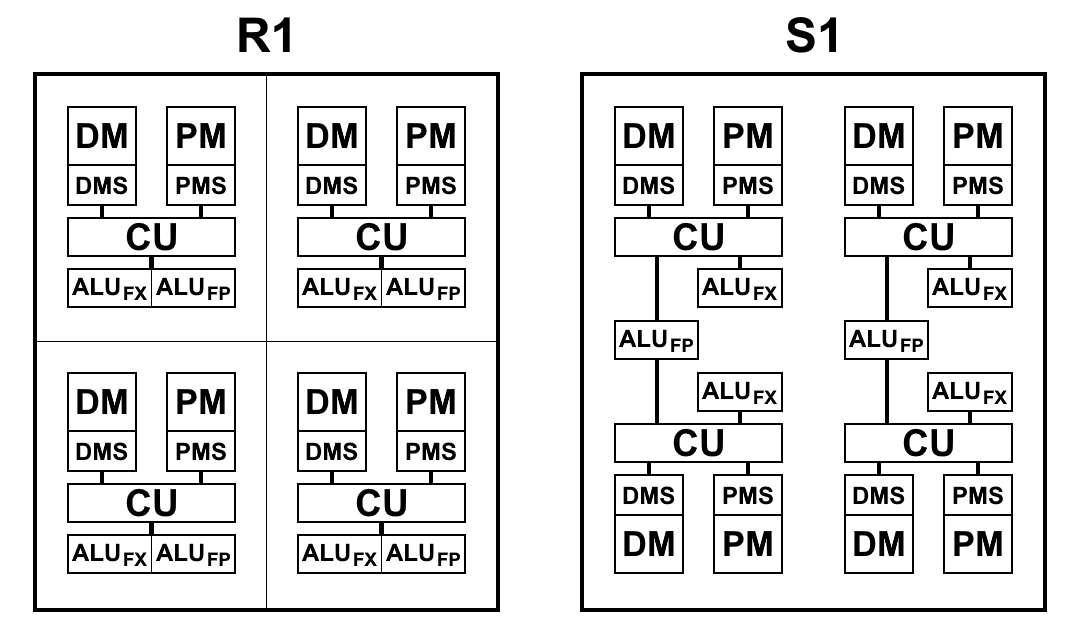
Perbedaan arsitektur S1:
- Tim sekarang dapat mengakses hasil tim dari paragraf sebelumnya. Ini adalah perubahan yang sangat penting yang memungkinkan Anda untuk mempercepat transisi saat membuat kode. Prosesor P1 dan R1 tidak punya pilihan selain menulis hasil yang diinginkan ke memori dan segera membacanya kembali dengan perintah pertama dalam paragraf baru. Bahkan ketika menggunakan memori pada sebuah chip, operasi menulis dan membaca mengambil masing-masing 2 hingga 5 siklus, yang dapat disimpan dengan hanya merujuk pada hasil perintah dari paragraf sebelumnya
- Menulis ke memori dan register sekarang terjadi segera, dan tidak di akhir paragraf, yang memungkinkan Anda untuk mulai menulis perintah sebelum akhir paragraf. Akibatnya, potensi waktu henti antar paragraf berkurang.
- Sistem perintah telah dioptimalkan, yaitu:
- Menambahkan aritmatika integer 64-bit: penjumlahan, pengurangan, perkalian angka 32-bit, yang mengembalikan hasil 64-bit.
- Metode membaca dari memori telah diubah: sekarang untuk perintah apa pun , Anda dapat dengan mudah menentukan alamat dari mana Anda ingin membaca data sebagai argumen, sementara urutan perintah membaca dan menulis dipertahankan.
Itu juga membuat memori yang terpisah membaca perintah usang. Sebagai gantinya, perintah nilai muat digunakan dalam sakelar muat (sebelumnya, dapatkan ), yang menetapkan alamat dalam memori sebagai argumen:
.data foo: .long 0x1234 .text habr: load_l foo ; foo load_l [foo] ; 0x1234 add_l [foo], 0xABCD ; ; complete
- Format perintah telah ditambahkan yang memungkinkan penggunaan 2 argumen konstan.
Sebelumnya, Anda bisa menetapkan konstanta hanya sebagai argumen kedua, argumen pertama harus selalu berupa tautan ke hasil di sakelar. Perubahan berlaku untuk semua tim dua argumen. Bidang konstan selalu 32 bit, jadi format ini memungkinkan, misalnya, untuk menghasilkan konstanta 64-bit dengan satu perintah.
Itu:
load_l 0x12345678 patch_q @1, 0xDEADBEEF
Itu menjadi:
patch_q 0x12345678, 0xDEADBEEF
- Tipe data vektor yang dimodifikasi dan ditambah.
Apa yang dulu disebut tipe data "dikemas" sekarang dapat dengan aman disebut vektorial. Dalam P1 dan R1, operasi pada bilangan yang dipaket hanya mengambil konstanta sebagai argumen kedua, mis., Misalnya, ketika menambahkan, setiap elemen vektor ditambahkan dengan angka yang sama, dan ini tidak dapat diterapkan secara cerdas. Sekarang, operasi serupa dapat diterapkan ke dua vektor penuh. Selain itu, cara ini bekerja dengan vektor sepenuhnya konsisten dengan mekanisme vektor di LLVM, yang sekarang memungkinkan kompiler untuk menghasilkan kode menggunakan tipe vektor.
patch_q 0x00010002, 0x00030004 patch_q 0x00020003, 0x00040005 mul_ps @1, @2 ; - 00020006000C0014
- Bendera prosesor dihapus.
Akibatnya, sekitar 40 tim hanya berdasarkan nilai-nilai bendera telah dihapus. Ini telah secara signifikan mengurangi jumlah tim dan, karenanya, area kristal. Dan semua informasi yang diperlukan sekarang disimpan langsung di sel switch.
- Saat membandingkan dengan nol, alih-alih bendera nol, sekarang hanya nilai di sakelar yang digunakan
- Alih-alih tanda bendera, sedikit sesuai dengan jenis perintah sekarang digunakan: 7 untuk byte, 15 untuk pendek, 31 untuk panjang, 63 untuk quad. Karena fakta bahwa karakternya berlipat hingga bit ke-63, apa pun jenisnya, Anda dapat membandingkan jumlah jenis yang berbeda:
.data long: .long -0x1000 byte: .byte -0x10 .text habr: a := load_b [byte] ; 0xFFFFFFFFFFFFFFF0, ; byte 7 63. b := loadu_b [byte] ; 0x00000000000000F0, ; .. loadu_b c := load_l [long] ; 0xFFFFFFFFFFFFF000. ge_l @a, @c ; " " 1: ; 31 , . lt_s @a, @b ; 1, .. b complete
- Bendera carry tidak lagi diperlukan, karena ada aritmatika 64-bit
- Waktu transisi dari paragraf ke paragraf dikurangi menjadi 1 ukuran (bukannya 2-3 dalam R1)
Kompiler berbasis LLVM
Kompiler bahasa C untuk S1 mirip dengan R1, dan karena arsitekturnya tidak berubah secara mendasar, masalah yang dijelaskan dalam artikel sebelumnya, sayangnya, belum hilang.
Namun, dalam proses penerapan sistem perintah baru, jumlah kode output menurun dengan sendirinya, hanya karena pembaruan sistem perintah. Selain itu, ada banyak lagi optimasi minor yang akan mengurangi jumlah instruksi dalam kode, beberapa di antaranya telah dilakukan (misalnya, menghasilkan konstanta 64-bit dengan satu instruksi). Tetapi ada optimasi yang lebih serius yang perlu dilakukan, dan mereka dapat dibangun dalam urutan efisiensi dan kompleksitas implementasi:
- Kemampuan untuk menghasilkan semua perintah dua argumen dengan dua konstanta.
Menghasilkan konstanta 64-bit melalui patch_q hanyalah kasus khusus, tetapi kita perlu yang umum. Faktanya, inti dari optimasi ini adalah untuk memungkinkan tim untuk menggantikan hanya argumen pertama sebagai konstanta, karena argumen kedua selalu bisa menjadi konstanta, dan ini telah lama diterapkan. Ini bukan kasus yang sangat sering, tetapi, misalnya, ketika Anda perlu memanggil suatu fungsi dan menulis alamat pengirim dari itu ke bagian atas tumpukan, Anda dapat
load_l func wr_l @1, #SP
mengoptimalkan ke
wr_l func, #SP
- Kemampuan untuk mengganti akses memori melalui argumen dalam perintah apa pun.
Misalnya, jika Anda perlu menambahkan dua angka dari memori, Anda bisa
load_l [foo] load_l [bar] add_l @1, @2
mengoptimalkan ke
add_l [foo], [bar]
Optimasi ini merupakan perpanjangan dari yang sebelumnya, namun, analisis sudah diperlukan di sini: penggantian seperti itu hanya dapat dilakukan jika nilai yang dimuat hanya digunakan sekali dalam perintah penambahan ini dan di tempat lain. Jika hasil pembacaan digunakan bahkan hanya dalam dua perintah, itu lebih menguntungkan untuk membaca dari memori sekali sebagai perintah terpisah, dan di dua lainnya untuk merujuknya melalui saklar.
- Optimalisasi transfer register virtual antara unit dasar.
Untuk R1, transfer semua register virtual dilakukan melalui memori, yang menimbulkan sejumlah besar membaca dan menulis ke memori, tetapi tidak ada cara lain untuk mentransfer data antar paragraf. S1 memungkinkan Anda untuk mengakses hasil dari perintah paragraf sebelumnya, oleh karena itu, secara teoritis, banyak operasi memori dapat dihapus, yang akan memberikan efek terbesar di antara semua optimasi. Namun, pendekatan ini masih dibatasi oleh peralihan: tidak lebih dari 63 hasil sebelumnya, sejauh ini dari setiap transfer virtual register dapat diimplementasikan seperti ini. Bagaimana melakukan ini bukanlah tugas sepele, dan analisis kemungkinan untuk menyelesaikannya belum dilakukan. Sumber kompiler dapat muncul di domain publik, jadi jika ada yang punya ide dan Anda ingin bergabung dengan pengembangan, maka Anda bisa melakukannya.
Tingkatan yang dicapai
Karena prosesor belum dirilis pada chip, sulit untuk menilai kinerjanya yang sebenarnya. Namun, kode kernel RTL sudah siap, yang berarti Anda dapat membuat penilaian menggunakan simulasi atau FPGA. Untuk menjalankan tolok ukur berikut, kami menggunakan simulasi menggunakan program ModelSim untuk menghitung waktu eksekusi yang tepat (dalam ukuran). Karena sulit untuk mensimulasikan seluruh kristal dan membutuhkan waktu yang sangat lama, oleh karena itu, satu multisel disimulasikan, dan hasilnya dikalikan 16 (jika tugas dirancang untuk multithreading), karena setiap multisel dapat bekerja sepenuhnya secara independen dari yang lain.
Pada saat yang sama, pemodelan multisel dilakukan pada Xilinx Virtex-6 untuk menguji kinerja kode prosesor pada perangkat keras nyata.
Coremark
CoreMark - seperangkat tes untuk penilaian komprehensif kinerja mikrokontroler dan prosesor sentral, serta kompiler C-nya. Seperti yang Anda lihat, prosesor S1 bukanlah yang satu atau yang lain. Namun, ini dimaksudkan untuk mengeksekusi kode arbitrase mutlak, yaitu siapa pun yang bisa berjalan di prosesor pusat. Jadi CoreMark cocok untuk mengevaluasi kinerja S1 tidak lebih buruk.
CoreMark berisi pekerjaan dengan daftar tertaut, matriks, mesin negara dan perhitungan jumlah
CRC . Secara umum, sebagian besar kode ternyata benar-benar berurutan (yang menguji
paralelisme perangkat keras multiseluler) dan dengan banyak cabang, itulah sebabnya kemampuan kompiler memainkan peran penting dalam kinerja akhir. Kode yang dikompilasi berisi beberapa paragraf pendek dan meskipun fakta bahwa kecepatan transisi di antara mereka telah meningkat, percabangan termasuk bekerja dengan memori, yang kami ingin hindari secara maksimal.
Kartu Skor CoreMark:
| Multiclet R1 (kompiler llvm) | Multiclet S1 (kompiler llvm) | Elbrus-4C (R500 / E) | Texas Inst. AM5728 ARM Cortex-A15 | Baikal-t1 | Intel Core i7 7700K |
|---|
| Tahun pembuatan | 2015 | 2019 | 2014 | 2018 | 2016 | 2017 |
| Frekuensi jam, MHz | 100 | 1600 | 700 | 1500 | 1200 | 4500 |
| Skor keseluruhan CoreMark | 59 | 18356 | 1214 | 15789 | 13142 | 182128 |
| Coremark / MHz | 0,59 | 11.47 | 5.0 | 10.53 | 10.95 | 40.47 |
Hasil satu multisel adalah 1147, atau 0,72 / MHz, yang lebih tinggi dari R1. Ini berbicara tentang keuntungan dari pengembangan arsitektur multisel pada prosesor baru.
Batu gandum
Whetstone - serangkaian tes untuk mengukur kinerja prosesor saat bekerja dengan angka floating point. Di sini situasinya jauh lebih baik: kode juga berurutan, tetapi tanpa banyak cabang dan dengan konkurensi internal yang baik.
Whetstone terdiri dari banyak modul, yang memungkinkan Anda untuk mengukur tidak hanya hasil keseluruhan, tetapi juga kinerja pada setiap modul tertentu:
- Elemen array
- Array sebagai parameter
- Melompat bersyarat
- Aritmatika integer
- Fungsi trigonometri (tan, sin, cos)
- Panggilan prosedur
- Array referensi
- Fungsi standar (sqrt, exp, log)
Mereka dibagi menjadi beberapa kategori: modul 1, 2, dan 6 mengukur kinerja operasi floating point (baris MFLOPS1-3); modul 5 dan 8 - fungsi matematika (COS MOPS, EXP MOPS); modul 4 dan 7 - bilangan bulat aritmatika (FIXPT MOPS, EQUAL MOPS); modul 3 - lompatan bersyarat (JIKA MOPS). Pada tabel di bawah ini, baris kedua MWIPS adalah indikator umum.
Tidak seperti CoreMark, Whetstone akan dibandingkan pada satu inti atau, seperti dalam kasus kami, pada satu multisel. Karena jumlah inti sangat berbeda dalam prosesor yang berbeda, maka, untuk kemurnian percobaan, kami mempertimbangkan indikator per megahertz.
Kartu Skor Whetstone:
| CPU | MultiClet R1 | MultiClet S1 | Core i7 4820K | ARM v8-A53 |
|---|
| Frekuensi, MHz | 100 | 1600 | 3900 | 1300 |
| MWIPS / MHz | 0,311 | 0,343 | 0,887 | 0,642 |
| MFLOPS1 / MHz | 0,157 | 0,156 | 0,341 | 0,268 |
| MFLOPS2 / MHz | 0,153 | 0,111 | 0,308 | 0,241 |
| MFLOPS3 / MHz | 0,029 | 0,124 | 0,167 | 0,239 |
| COS MOPS / MHz | 0,018 | 0,008 | 0,023 | 0,028 |
| EXP MOPS / MHz | 0,008 | 0,005 | 0,014 | 0,004 |
| FIXPT MOPS / MHz | 0,714 | 0,116 | 0,998 | 1.197 |
| JIKA MOPS / MHz | 0,081 | 0,196 | 1,504 | 1.436 |
| EQUAL MOPS / MHz | 0,143 | 0,149 | 0,251 | 0,439 |
Whetstone mengandung operasi komputasi yang jauh lebih langsung daripada CoreMark (yang sangat terlihat ketika melihat kode di bawah ini), jadi penting untuk diingat di sini: jumlah ALU titik-mengambang dikurangi setengahnya. Namun, kecepatan komputasi hampir tidak terpengaruh, dibandingkan dengan R1.
Beberapa modul sangat cocok pada arsitektur multiseluler. Sebagai contoh, modul 2 menghitung banyak nilai dalam satu siklus, dan berkat dukungan penuh angka floating-point presisi ganda oleh prosesor dan kompiler, setelah kompilasi kita mendapatkan paragraf besar dan indah yang benar-benar mengungkapkan kemampuan komputasi arsitektur multiseluler:
Paragraf besar dan indah untuk 120 tim pa: SR4 := loadu_q [#SP + 16] SR5 := loadu_q [#SP + 8] SR6 := loadu_l [#SP + 4] SR7 := loadu_l [#SP] setjf_l @0, @SR7 SR8 := add_l @SR6, 0x8 SR9 := add_l @SR6, 0x10 SR10 := add_l @SR6, 0x18 SR11 := loadu_q [@SR6] SR12 := loadu_q [@SR8] SR13 := loadu_q [@SR9] SR14 := loadu_q [@SR10] SR15 := add_d @SR11, @SR12 SR11 := add_d @SR15, @SR13 SR15 := sub_d @SR11, @SR14 SR11 := mul_d @SR15, @SR5 SR15 := add_d @SR12, @SR11 SR12 := sub_d @SR15, @SR13 SR15 := add_d @SR14, @SR12 SR12 := mul_d @SR15, @SR5 SR15 := sub_d @SR11, @SR12 SR16 := sub_d @SR12, @SR11 SR17 := add_d @SR11, @SR12 SR11 := add_d @SR13, @SR15 SR13 := add_d @SR14, @SR11 SR11 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR11 SR15 := add_d @SR17, @SR11 SR16 := add_d @SR14, @SR13 SR13 := div_d @SR16, @SR4 SR14 := sub_d @SR15, @SR13 SR15 := mul_d @SR14, @SR5 SR14 := add_d @SR12, @SR15 SR12 := sub_d @SR14, @SR11 SR14 := add_d @SR13, @SR12 SR12 := mul_d @SR14, @SR5 SR14 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR11, @SR14 SR11 := add_d @SR13, @SR15 SR14 := mul_d @SR11, @SR5 SR11 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR13, @SR11 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR4 := loadu_q @SR4 SR5 := loadu_q @SR5 SR6 := loadu_q @SR6 SR7 := loadu_q @SR7 SR15 := mul_d @SR13, @SR5 SR8 := loadu_q @SR8 SR9 := loadu_q @SR9 SR10 := loadu_q @SR10 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR17 SR14 := mul_d @SR13, @SR5 SR5 := add_d @SR16, @SR14 SR13 := add_d @SR11, @SR5 SR5 := div_d @SR13, @SR4 wr_q @SR15, @SR6 wr_q @SR12, @SR8 wr_q @SR14, @SR9 wr_q @SR5, @SR10 complete
popcnt
Untuk mencerminkan karakteristik arsitektur itu sendiri (terlepas dari kompilernya), kami akan mengukur sesuatu yang ditulis dalam assembler dengan mempertimbangkan semua fitur arsitektur. Misalnya, menghitung satuan bit dalam angka 512-bit (popcnt). Untuk kejelasan, kami akan mengambil hasil dari satu multisel, sehingga mereka dapat dibandingkan dengan R1.
Tabel perbandingan, jumlah siklus jam per siklus perhitungan 32-bit:
| Algoritma | Multiclet r1 | Multiclet S1 (satu multisel) |
|---|
| Bithacks | 5.0 | 2.625 |
Instruksi vektor baru yang diperbarui digunakan di sini, yang memungkinkan kami untuk mengurangi separuh jumlah instruksi dibandingkan dengan algoritma yang sama yang diterapkan pada assembler R1. Kecepatan kerja, masing-masing, meningkat hampir 2 kali lipat.
popcnt bithacks: b0 := patch_q 0x1, 0x1 v0 := loadu_q [v] v1 := loadu_q [v+8] v2 := loadu_q [v+16] v3 := loadu_q [v+24] v4 := loadu_q [v+32] v5 := loadu_q [v+40] v6 := loadu_q [v+48] v7 := loadu_q [v+56] b1 := patch_q 0x55555555, 0x55555555 i00 := slr_pl @v0, @b0 i01 := slr_pl @v1, @b0 i02 := slr_pl @v2, @b0 i03 := slr_pl @v3, @b0 i04 := slr_pl @v4, @b0 i05 := slr_pl @v5, @b0 i06 := slr_pl @v6, @b0 i07 := slr_pl @v7, @b0 b2 := patch_q 0x33333333, 0x33333333 i10 := and_q @i00, @b1 i11 := and_q @i01, @b1 i12 := and_q @i02, @b1 i13 := and_q @i03, @b1 i14 := and_q @i04, @b1 i15 := and_q @i05, @b1 i16 := and_q @i06, @b1 i17 := and_q @i07, @b1 b3 := patch_q 0x2, 0x2 i20 := sub_pl @v0, @i10 i21 := sub_pl @v1, @i11 i22 := sub_pl @v2, @i12 i23 := sub_pl @v3, @i13 i24 := sub_pl @v4, @i14 i25 := sub_pl @v5, @i15 i26 := sub_pl @v6, @i16 i27 := sub_pl @v7, @i17 i30 := and_q @i20, @b2 i31 := and_q @i21, @b2 i32 := and_q @i22, @b2 i33 := and_q @i23, @b2 i34 := and_q @i24, @b2 i35 := and_q @i25, @b2 i36 := and_q @i26, @b2 i37 := and_q @i27, @b2 i40 := slr_pl @i20, @b3 i41 := slr_pl @i21, @b3 i42 := slr_pl @i22, @b3 i43 := slr_pl @i23, @b3 i44 := slr_pl @i24, @b3 i45 := slr_pl @i25, @b3 i46 := slr_pl @i26, @b3 i47 := slr_pl @i27, @b3 b4 := patch_q 0x4, 0x4 i50 := and_q @i40, @b2 i51 := and_q @i41, @b2 i52 := and_q @i42, @b2 i53 := and_q @i43, @b2 i54 := and_q @i44, @b2 i55 := and_q @i45, @b2 i56 := and_q @i46, @b2 i57 := and_q @i47, @b2 i60 := add_pl @i50, @i30 i61 := add_pl @i51, @i31 i62 := add_pl @i52, @i32 i63 := add_pl @i53, @i33 i64 := add_pl @i54, @i34 i65 := add_pl @i55, @i35 i66 := add_pl @i56, @i36 i67 := add_pl @i57, @i37 b5 := patch_q 0xf0f0f0f, 0xf0f0f0f i70 := slr_pl @i60, @b4 i71 := slr_pl @i61, @b4 i72 := slr_pl @i62, @b4 i73 := slr_pl @i63, @b4 i74 := slr_pl @i64, @b4 i75 := slr_pl @i65, @b4 i76 := slr_pl @i66, @b4 i77 := slr_pl @i67, @b4 b6 := patch_q 0x1010101, 0x1010101 i80 := add_pl @i70, @i60 i81 := add_pl @i71, @i61 i82 := add_pl @i72, @i62 i83 := add_pl @i73, @i63 i84 := add_pl @i74, @i64 i85 := add_pl @i75, @i65 i86 := add_pl @i76, @i66 i87 := add_pl @i77, @i67 b7 := patch_q 0x18, 0x18 i90 := and_q @i80, @b5 i91 := and_q @i81, @b5 i92 := and_q @i82, @b5 i93 := and_q @i83, @b5 i94 := and_q @i84, @b5 i95 := and_q @i85, @b5 i96 := and_q @i86, @b5 i97 := and_q @i87, @b5 iA0 := mul_pl @i90, @b6 iA1 := mul_pl @i91, @b6 iA2 := mul_pl @i92, @b6 iA3 := mul_pl @i93, @b6 iA4 := mul_pl @i94, @b6 iA5 := mul_pl @i95, @b6 iA6 := mul_pl @i96, @b6 iA7 := mul_pl @i97, @b6 iB0 := slr_pl @iA0, @b7 iB1 := slr_pl @iA1, @b7 iB2 := slr_pl @iA2, @b7 iB3 := slr_pl @iA3, @b7 iB4 := slr_pl @iA4, @b7 iB5 := slr_pl @iA5, @b7 iB6 := slr_pl @iA6, @b7 iB7 := slr_pl @iA7, @b7 wr_q @iB0, c wr_q @iB1, c+8 wr_q @iB2, c+16 wr_q @iB3, c+24 wr_q @iB4, c+32 wr_q @iB5, c+40 wr_q @iB6, c+48 wr_q @iB7, c+56 complete
Ethereum
Tentu saja, tolok ukur itu baik, tetapi kami memiliki tugas khusus: membuat akselerator perhitungan, dan alangkah baiknya jika mengetahui cara mengatasi tugas nyata. Cryptocurrency modern adalah yang paling cocok untuk verifikasi seperti itu, karena algoritma penambangan berjalan pada banyak perangkat yang berbeda dan karenanya dapat berfungsi sebagai tolok ukur untuk perbandingan. Kami mulai dengan Ethereum dan algoritma Ethash, yang berjalan langsung di perangkat penambangan.
Pilihan Ethereum adalah karena pertimbangan berikut. Seperti yang Anda ketahui, algoritma seperti Bitcoin sangat efisien diimplementasikan oleh chip ASIC khusus, sehingga penggunaan prosesor atau kartu video untuk menambang Bitcoin dan klonnya menjadi tidak menguntungkan secara ekonomi karena kinerja rendah dan konsumsi daya tinggi. Komunitas penambang, dalam upaya untuk menjauh dari situasi ini, sedang mengembangkan cryptocurrency pada prinsip-prinsip algoritmik lainnya, dengan fokus pada pengembangan algoritma yang menggunakan prosesor tujuan umum atau kartu video untuk menambang. Tren ini kemungkinan akan berlanjut di masa depan. Ethereum adalah cryptocurrency paling terkenal berdasarkan pendekatan ini. Alat utama untuk menambang Ethereum adalah kartu video, yang dalam hal efisiensi (hashrate / TDP) secara signifikan (beberapa kali) di depan prosesor tujuan umum.
Ethash adalah algoritma yang disebut
memori terikat , mis. waktu kalkulasinya dibatasi terutama oleh kuantitas dan kecepatan memori, dan bukan oleh kecepatan kalkulasi itu sendiri. Sekarang untuk penambangan Ethereum, kartu video adalah yang paling cocok, tetapi kemampuan mereka untuk melakukan banyak operasi secara bersamaan tidak banyak membantu, dan mereka masih bersandar pada kecepatan RAM, yang jelas ditunjukkan dalam
artikel ini . Dari sana, Anda dapat mengambil gambar yang menggambarkan operasi algoritma untuk menjelaskan mengapa ini terjadi.
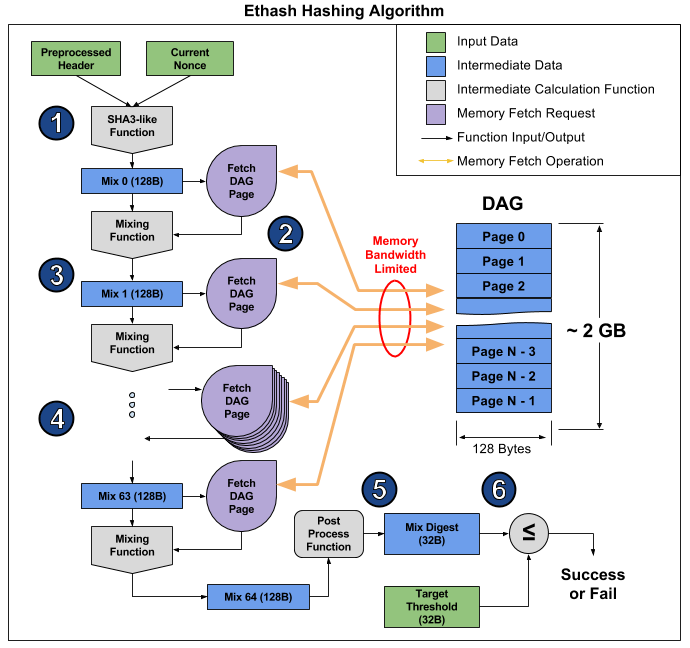
Artikel ini memecah algoritma menjadi 6 poin, tetapi 3 tahap dapat dibedakan untuk lebih jelasnya:
- Mulai: SHA-3 (512) untuk menghitung Mix 0 byte 128 asli (titik 1)
- Perhitungan ulang 64-kali lipat dari array Mix dengan membaca 128 byte berikutnya dan mencampurnya dengan yang sebelumnya melalui fungsi pencampuran, berjumlah 8 kilobyte (paragraf 2-4)
- Finalisasi dan verifikasi hasilnya
Membaca secara acak 128 byte dari RAM membutuhkan waktu lebih lama daripada yang terlihat. Jika Anda menggunakan kartu grafis MSI RX 470, yang memiliki 2048 perangkat komputasi dan bandwidth memori maksimum 211,2 GB / s, maka untuk melengkapi setiap perangkat Anda memerlukan 1 / (211.2 GB / (128 b * 2048)) = 1241 ns, atau sekitar 1496 siklus pada frekuensi tertentu. Mengingat ukuran fungsi pencampuran, kita dapat mengasumsikan bahwa dibutuhkan beberapa kali lebih lama untuk membaca memori dari kartu video daripada menghitung ulang informasi yang diterima. Akibatnya, tahap 2 dari algoritma membutuhkan banyak waktu, lebih lama daripada tahap 1 dan 3, yang pada akhirnya memiliki sedikit pengaruh pada kinerja, meskipun faktanya mengandung lebih banyak perhitungan (terutama dalam SHA-3). Anda bisa melihat hashrate dari kartu video ini: 26.375 megachash / s teoritis (hanya dibatasi oleh bandwidth memori) versus 24 megacheh / s aktual, yaitu, tahap 1 dan 3 hanya mengambil 10% dari waktu.
Pada S1, semua 16 multisel dapat bekerja secara paralel dan pada kode yang berbeda. Selain itu, RAM dual-channel akan diinstal, sepanjang satu saluran untuk 8 multicell. Pada tahap 2 dari algoritma Ethash, rencana kami adalah sebagai berikut: satu multisel membaca 128 byte dari memori dan mulai menghitung ulang, kemudian yang berikutnya membaca memori dan menghitung ulang, dan seterusnya hingga tanggal 8, mis. satu multisel, setelah membaca 128 byte memori, memiliki 7 * [waktu baca 128 byte] untuk menghitung ulang array. Diasumsikan bahwa pembacaan seperti itu akan memakan waktu 16 siklus, mis. 112 langkah diberikan untuk penghitungan ulang. Menghitung fungsi pencampuran membutuhkan siklus clock yang sama, sehingga S1 mendekati rasio bandwidth memory yang ideal dengan kinerja prosesor. Karena waktu tidak terbuang pada tahap kedua, bagian-bagian algoritma yang tersisa harus dioptimalkan sebanyak mungkin, karena dengan begitu mereka benar-benar memengaruhi kinerja.
Untuk mengevaluasi kecepatan komputasi SHA-3 (Keccak), sebuah program C dikembangkan dan diuji, berdasarkan versi optimalnya dalam assembler saat ini sedang dibuat. Pemrograman evaluasi menunjukkan bahwa satu multisel melakukan perhitungan SHA-3 (Keccak) dalam 1550 siklus clock. Oleh karena itu, total waktu untuk menghitung satu hash dengan satu multisel adalah 1550 + 64 * (16 + 112) = 9742 siklus. Dengan frekuensi 1,6 GHz dan 16 multicell paralel, kecepatan hash prosesor adalah 2,6 MHash / dtk.| Akselerator | MultiClet S1 | NVIDIA GeForce GTX 980 Ti | Radeon RX 470 | Radeon RX Vega 64 | NVIDIA GeForce GTX 1060 | NVIDIA GeForce GTX 1080 Ti |
|---|
| Harga | | $ 650 | $ 180 | $ 500 | $ 300 | $ 700 |
| Tingkat hasrat | 2,6 MHash / s | 21,6 MHash / s | 25,8 MHash / s | 43,5 MHash / s | 25 MHash / s | 55 MHash / s |
| TDP | 6 W | 250 W | 120 W | 295 W | 120 W | 250 W |
| Hashrate / TDP | 0,43 | 0,09 | 0,22 | 0,15 | 0,22 | 0,21 |
| Teknologi proses | 28 nm | 28 nm | 14 nm | 14 nm | 16 nm | 16 nm |
Saat menggunakan MultiClet S1 sebagai alat penambangan, 20 atau lebih prosesor sebenarnya dapat dipasang di papan. Dalam hal ini, hashrate dari papan tersebut akan sama dengan atau lebih tinggi dari hashrates dari kartu video yang ada, sementara konsumsi daya papan dengan S1 akan menjadi setengah lebih banyak, bahkan dibandingkan dengan kartu video dengan standar topografi 16 dan 14 nm.Sebagai kesimpulan, saya harus mengatakan bahwa tugas utama sekarang adalah membuat papan multiprosesor untuk penambang cryptocurrency multiseluler dan penambang superkomputer. Daya saing direncanakan akan tercapai karena konsumsi daya dan arsitektur yang kecil, yang sangat cocok untuk komputasi sewenang-wenang.Prosesor masih dalam pengembangan, tetapi Anda sudah dapat memulai pemrograman dalam assembler, serta mengevaluasi versi saat ini dari kompiler. Sudah ada SDK minimal yang berisi assembler, linker, compiler dan model fungsional, di mana Anda dapat memulai dan menguji program Anda.