
Suatu ketika, ketika langit biru, rumput lebih hijau dan dinosaurus menjelajahi bumi ... Tidak, lupakan dinosaurus. Secara umum, suatu ketika muncul ide untuk mengalihkan perhatian dari pemrograman web standar dan melakukan sesuatu yang lebih gila. Tentu saja bisa menjadi apa saja, tetapi pilihan ada pada menulis juru bahasa Anda sendiri. Apa yang bisa saya katakan ...
Jangan pernah menulis bahasa pemrograman Anda sendiri . Tetapi saya mengambil beberapa pengalaman dari semua ini, jadi saya memutuskan untuk membagikannya. Mari kita mulai dengan fondasi - lexer.
Kata Pengantar
Sebelum Anda mulai memahami apa jenis "lexer" binatang itu, ada baiknya mencari tahu apa yang terbuat dari YaPs.
Di dunia modern, setiap kompiler / interpreter / transpiler / sesuatu-yang-ada-seperti (mari, saya sebut saja lebih lanjut "kompiler", tanpa perbedaan antar jenis) dibagi menjadi dua bagian. Dalam terminologi paman yang pandai, bidak seperti itu disebut "frontend" dan "backend". Tidak, ini sama sekali tidak apa, ketika bekerja dengan web, apa yang biasa kita panggil dan bagian depan tidak ditulis dalam JS dengan HTML. Meskipun ... Oke.
Tugas frontend pertama adalah untuk mengambil
teks dan mengubahnya menjadi
AST (pohon sintaksis abstrak), memeriksa sintaks (dan kadang-kadang semantik) di jalan. Tugas backend kedua adalah membuat semuanya berfungsi. Jika kode tersebut dirakit di dalam interpreter, maka AST membuat satu set instruksi untuk prosesor virtual (mesin virtual), jika kompiler, maka set instruksi untuk prosesor nyata. Dalam kehidupan, semuanya cukup rumit dan mungkin tidak dapat diimplementasikan dengan cukup seperti itu. Sebagai contoh, dalam kasus kompiler GCC, semuanya dicampuradukkan, tetapi Dentang sudah lebih kanonik, LLVM adalah perwakilan khas dari "backend" untuk kompiler.
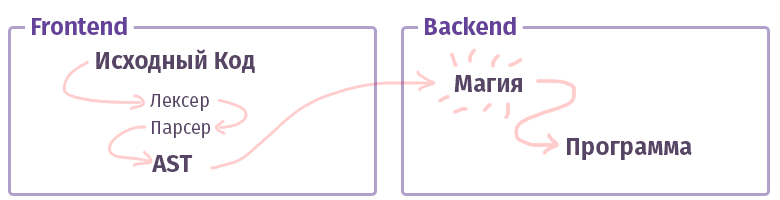
Sekarang mari kita mengenal bagian yang disebut frontend.
Analisis leksikal
Tugas lexer dan tahap analisis leksikal adalah untuk mendapatkan banyak, banyak surat di pintu masuk dan mengelompokkannya ke dalam beberapa kategori - "token". Oleh karena itu, analisis leksikal juga disebut "tokenization". Ini adalah tahap pertama dari pemrosesan teks yang dihasilkan oleh setiap kompiler yang ada.
Sesuatu seperti ini:
$tokens = ['class', '\w+', '}', '{']; var_dump(lex('class Example {}', $tokens));
Ngomong-ngomong, di sini kita telah menulis banyak alat untuk membuat hidup lebih mudah. Fungsi
preg yang sama yang kami gunakan untuk menguraikan teks cukup
mampu untuk tugas ini. Namun, ada alat yang lebih nyaman untuk masalah ini:
- Phlexy , ditulis oleh Nikita Popov.
- Hoa adalah toolkit yang terdiri dari Lexer + Parser + Grammar.
- Port Yacc , ditulis oleh Anthony Ferrara, yang juga merupakan toolkit komprehensif, dan di mana parser PHP Popov yang terkenal ditulis, dapat diterapkan dalam alat yang menggunakan analisis kode.
- Railt Lexer implementasi saya untuk PHP 7.1+
- Parle adalah ekstensi untuk PHP yang memungkinkan serangkaian ekspresi PCRE terbatas (tanpa lookahead dan beberapa konstruksi sintaks lainnya).
- Dan akhirnya, fungsi standar token_get_all php, yang dimaksudkan langsung untuk analisis leksikal PHP.
Ya, jelas bahwa ada banyak alat bantu yang dapat membagi teks dengan token, mungkin saya bahkan lupa sesuatu, seperti lexer
Doctrine . Tapi selanjutnya apa?
Jenis-Jenis Lexers
Dan seperti biasa, semuanya tidak sesederhana kelihatannya. Setidaknya ada dua kategori berbeda dari lexers. Ada opsi yang biasa, cukup sepele, di mana Anda menyelinap aturan, dan sudah membagi semuanya menjadi token. Konfigurasi daripadanya tidak jauh berbeda dari contoh yang ditunjukkan oleh saya di atas. Namun, ada opsi lain yang disebut
multistate . Lexer seperti itu sedikit lebih sulit untuk dipahami, oleh karena itu, saya ingin berbicara lebih banyak tentang mereka.
Tugas multistate lexer adalah menampilkan berbagai token tergantung pada kondisi sebelumnya. Sebagai contoh, dalam PHP, keadaan "transisi" tersebut dibentuk menggunakan tag <? Php +?>, Di dalam baris, komentar, dan konstruksi
HEREDOC /
NOWDOC .
Ingat contoh sebelumnya dengan 4 token di atas? Mari kita sedikit memodifikasinya untuk memahami status ini:
class Example {
Dalam hal ini, jika kita memiliki lexer yang paling sederhana tanpa kapabilitas PCRE yang luas, maka kita mendapatkan set token berikut:
var_dump(lex(...));
Seperti yang dapat Anda lihat, kami mendapatkan kusen dangkal yang sepenuhnya pada elemen 3-5: Komentar diambil secara tak terduga dan dibagi menjadi token, meskipun seharusnya dianggap sebagai keseluruhan.
Tentu saja, dengan fungsional PCRE, token semacam itu dapat dihancurkan dengan bantuan keteraturan sederhana "
// [^ \ n] * \ n ", tetapi jika tidak? Atau apakah kita ingin menghancurkannya dengan tangan kita? Singkatnya, dalam kasus multistate lexer - kita dapat mengatakan bahwa semua token harus berada di grup
No1 , segera setelah token "
// " ditemukan, maka transisi ke grup
No2 akan terjadi. Dan di dalam grup kedua, transisi balik, jika token "
\ n " ditemukan - transisi kembali ke grup pertama.
Sesuatu seperti ini:
$tokens = [ 'group-1' => [ 'class', '\w+', '{', '}', '//' => 'group-2'
Saya pikir sekarang menjadi lebih jelas bagaimana beberapa HEREDOC diurai, karena bahkan dengan semua kekuatan PCRE, menulis reguler untuk kasus ini sangat bermasalah, mengingat bahwa sintaks HEREDOC ini mendukung interpolasi variabel. Coba parsing sesuatu seperti ini dengan fungsi
token_get_all bawaan (note> 12 token):
<?php $example = 42; $a = <<<EOL Your answer is $example !!! EOL; var_dump(token_get_all(file_get_contents(__FILE__)));
Yah, sepertinya kita siap untuk mulai berlatih.
Berlatih
Mari kita ingat apa yang kita miliki di PHP untuk hal-hal seperti itu? Yah, tentu saja, preg_match! Oke, turunlah. Algoritma berbasis preg_match diimplementasikan di
Hoa dan
dalam implementasi Phelxy ini . Tugasnya cukup sederhana:
- Kami memiliki di tangan teks sumber dan berbagai pelanggan tetap.
- Kami cocok sampai sesuatu yang cocok ditemukan.
- Segera setelah Anda menemukan bagian, potong dari teks dan cocokkan lebih lanjut.
Dalam bentuk kode, akan terlihat seperti ini:
Lembar kode <?php class SimpleLexer { private $tokens = []; public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[$name] = \sprintf('/\G%s/isSum', $definition); } } public function lex(string $sources): iterable { [$offset, $length] = [0, \strlen($sources)]; while ($offset < $length) { [$name, $token] = $this->next($sources, $offset); yield $name => $token; $offset += \strlen($token); } } private function next(string $sources, int $offset): array { foreach ($this->tokens as $name => $pcre) { \preg_match($pcre, $sources, $matches, 0, $offset); $token = \reset($matches); if (\count($matches) && \strpos($sources, $token, $offset) === $offset) { return [$name, $token]; } } throw new \RuntimeException('Unrecognized token at offset ' . $offset); } }
Menggunakan lembar kode $lexer = new SimpleLexer([ 'T_CLASS' => 'class', 'T_CONST' => '\w+', 'T_BRACE_OPEN' => '{', 'T_BRACE_CLOSE' => '}', 'T_WHITESPACE' => '\s+', ]); echo \sprintf('| %-10s | %-20s |', 'VALUE', 'NAME') . "\n"; foreach ($lexer->lex('class Example {}') as $name => $token) { echo \sprintf('| %-10s | %-20s |', '"' . \trim($token, "\n") . '"', $name) . "\n"; }
Pendekatan ini cukup sepele dan memungkinkan beberapa dorongan keyboard untuk memodifikasi lexer di wilayah metode berikutnya (), menambahkan transisi antara negara dan mengubah pembagian masturbasi ini menjadi lexer multistate primitif. Di area
$ this-> token, tambahkan saja sesuatu seperti
$ this-> token [$ this-> state] .
Namun, di samping primitivisme itu sendiri, ada kelemahan lain, tidak fatal seperti yang mungkin terjadi, tetapi masih ... Implementasi seperti itu sangat lambat. Pada i7 7600k, pemilik yang kebetulan saya kebetulan - sebuah algoritma yang sama memproses sekitar 400 token per detik, dan dengan peningkatan variasi mereka (yaitu, definisi yang kami sampaikan ke konstruktor) - dapat memperlambat kecepatan perubahan presiden di Rusia ... ahem maaf Saya ingin mengatakan, tentu saja, bahwa itu akan bekerja
sangat lambat .
Oke, apa yang bisa kita lakukan? Sebagai permulaan, Anda dapat memahami apa yang salah. Faktanya adalah bahwa setiap kali kita memanggil
preg_match di dalam belantara bahasa, kompiler dengan JIT yang disebut PCRE naik (Dan dengan PHP 7.3, PCRE2 sudah). Setiap kali dia mem-parsing pelanggan tetap dan mengumpulkan parser untuk mereka, yang dengannya kita mem-parsing teks untuk membuat token. Kedengarannya agak aneh dan tautologis. Namun singkatnya, setiap token memerlukan kompilasi dari 1 ke N tetap, di mana N adalah jumlah definisi token ini. Pada saat yang sama, perlu dicatat bahwa bahkan bendera "
S " yang diterapkan dan pengoptimalan menggunakan "
\ G " di konstruktor, di mana ekspresi reguler untuk token dihasilkan, tidak membantu.
Hanya ada satu jalan keluar dari situasi ini - Anda harus menguraikan semua teks ini dalam satu pass, yaitu dengan menjalankan hanya satu fungsi
preg_match . Tetap menyelesaikan dua masalah:
- Bagaimana cara menunjukkan bahwa hasil dari ekspresi reguler N1 sesuai dengan token N2? Yaitu cara menunjukkan bahwa " \ w + ", misalnya, adalah T_CONST .
- Bagaimana menentukan urutan token sebagai hasilnya. Seperti yang Anda ketahui, hasil preg_match atau preg_match_all akan berisi semua yang tercampur aduk. Dan bahkan dengan bantuan bendera yang dilewati sebagai argumen keempat, situasinya tidak akan berubah.
Di sini Anda dapat berhenti sejenak dan berpikir sedikit. Baik atau tidak.
Solusi untuk masalah pertama
bernama kelompok PCRE , yang juga disebut "submasks." Dengan menggunakan aturan: "
(? <T_WHITESPACE> \ s + | <T_WORD> \ w + | ...) " Anda bisa mendapatkan semua token dalam satu pass dengan membandingkannya dengan namanya. Sebagai hasil dari pertandingan, array asosiatif akan dibentuk, terdiri dari pasangan "
[TOKEN_NAME => TOKEN_VALUE] ".
Yang kedua sedikit lebih rumit. Tetapi di sini Anda dapat menerapkan trik taktis dan menggunakan fungsi
preg_replace_callback . Keunikannya adalah bahwa anonim yang dilewatkan sebagai argumen kedua akan dipanggil secara ketat secara berurutan untuk setiap token, dari yang pertama hingga yang terakhir.
Agar tidak merana - implementasinya adalah sebagai berikut:
Tutup kode lain class PregReplaceLexer { private $tokens = []; public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[] = \sprintf('(?<%s>%s)', $name, $definition); } } public function lex(string $sources): iterable { $result = []; \preg_replace_callback($this->compilePcre(), function (array $matches) use (&$result) { foreach (\array_reverse($matches) as $name => $value) { if (\is_string($name) && $value !== '') { $result[] = [$name, $value]; break; } } }, $sources); foreach ($result as [$name, $value]) { yield $name => $value; } } private function compilePcre(): string { return \sprintf('/\G(?:%s)/isSum', \implode('|', $this->tokens)); } }
Dan penggunaannya tidak berbeda dengan versi sebelumnya. Pada saat yang sama, kecepatan kerja meningkat dari
400 menjadi
57.000 token per detik. Algoritme inilah yang saya terapkan
dalam implementasi saya , mengambil penulisan ulang kode sumber Hoa. Omong-omong, jika Anda menggunakan Parle, Anda dapat memeras hingga
600.000 token per detik. Dan gambaran keseluruhan terlihat seperti ini (dengan XDebug dihidupkan di PHP 7.1, sehingga angkanya lebih rendah, tetapi rasionya dapat direpresentasikan secara kasar).
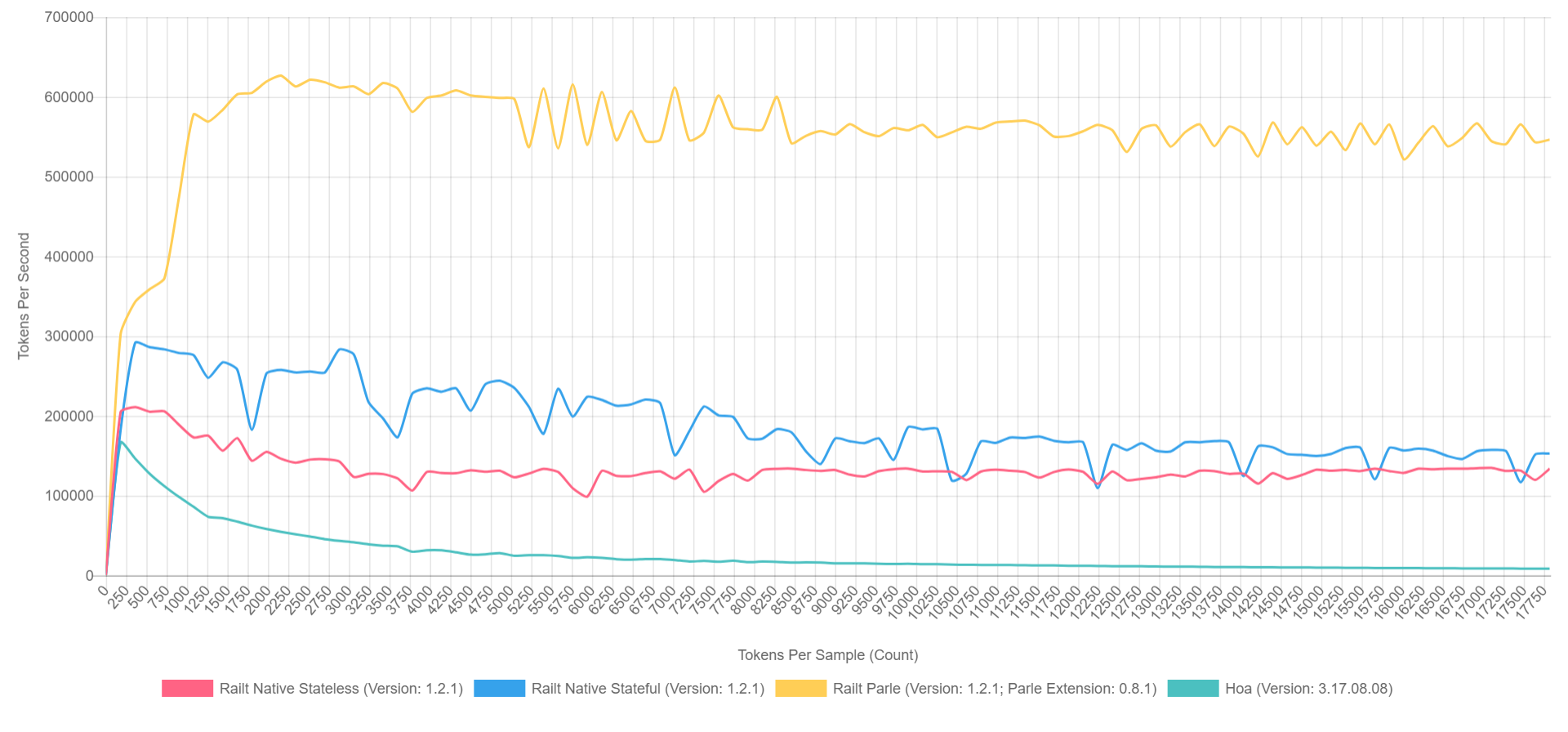
- Kuning adalah ekstensi asli Parle.
- Biru - implementasi melalui preg_replace_callback dengan pre-assembled regular.
- Merah - semuanya sama, tetapi dengan keteraturan yang dihasilkan selama panggilan ke preg_replace_callback .
- Hijau - implementasi melalui preg_match .
Mengapa
Ya, semua ini, tentu saja, luar biasa, tetapi yang tidak sabar ingin sekali mengajukan pertanyaan: "Siapa yang butuh ini?" Dalam dunia abstrak PHP, di mana prinsip "fig-fig-dan-site-ready" mendominasi - perpustakaan seperti itu tidak diperlukan, kita akan jujur. Tetapi jika kita berbicara tentang ekosistem secara keseluruhan, maka kita dapat mengingat perpustakaan terkenal seperti
symfony / yaml atau
Doctrine . Anotasi dalam Symfony adalah sub-bahasa yang sama di dalam PHP, membutuhkan penguraian leksikal dan sintaksis yang terpisah. Selain itu, ada transponder CoffeeScript, Less, dan Scss / Sass yang sedikit kurang terkenal yang ditulis dalam PHP. Nah, atau
Yay dan
preproses berdasarkan itu. Saya bahkan tidak akan menyebutkan alat analisis kode seperti phpmd atau phpcs. Dan generator dokumentasi seperti phpDocumentnor atau Sami cukup sepele. Masing-masing proyek ini sampai tingkat tertentu menggunakan analisis leksikal pada tahap pertama penguraian teks / kode.
Ini bukan daftar proyek yang lengkap dan mungkin saya harap cerita saya akan membantu Anda menemukan sesuatu yang baru dan mengisinya kembali.
Kata penutup
Ke depan, jika ada orang yang tertarik dengan topik parser dan kompiler, maka ada beberapa laporan menarik tentang topik ini, khususnya dari orang-orang dari JetBrains:
Namun, tentu saja, sebagian besar pertunjukan Andrei Breslav (
abreslav ), yang dapat ditemukan di YouTube yang luas - saya sarankan Anda untuk menonton.
Bagi penggemar fiksi
ada sumber daya yang secara pribadi sangat berguna bagi saya.
Posting tulisan skripum. Jika Anda berada di suatu tempat yang tersegel dalam luasnya epik ini, maka Anda dapat dengan aman memberi tahu penulis dalam bentuk apa pun yang nyaman bagi Anda.
Sebagai bonus, saya ingin memberikan
contoh lexer PHP sederhana , sepertinya tidak begitu menakutkan sekarang, dan sekarang bahkan jelas apa fungsinya, kan? Meskipun aku menipu, mata berdarah dari pelanggan tetap. =)
Terima kasih