Layanan pertama di Nomad I diluncurkan pada September 2016. Saat ini saya menggunakannya sebagai programmer dan dukungan sebagai administrator dari dua cluster Nomad - satu "rumah" untuk proyek pribadi saya (6 mesin mikro-virtual di Hetzner Cloud dan ArubaCloud di 5 pusat data berbeda di Eropa) dan yang kedua bekerja (sekitar 40 server virtual dan fisik pribadi di dua pusat data).
Selama masa lalu, cukup banyak pengalaman yang telah terakumulasi dengan lingkungan Nomad, dalam artikel saya akan menjelaskan masalah yang dihadapi oleh Nomad dan bagaimana cara mengatasinya.

Yamal nomad menjadikan instance Continous Delivery perangkat lunak Anda © National Geographic Russia
1. Jumlah node server per pusat data
Solusi: satu node server sudah cukup untuk satu pusat data.
Dokumentasi tidak secara eksplisit menunjukkan berapa banyak node server yang diperlukan dalam satu pusat data. Hanya diindikasikan bahwa 3-5 node diperlukan per wilayah, yang logis untuk konsensus protokol rakit.
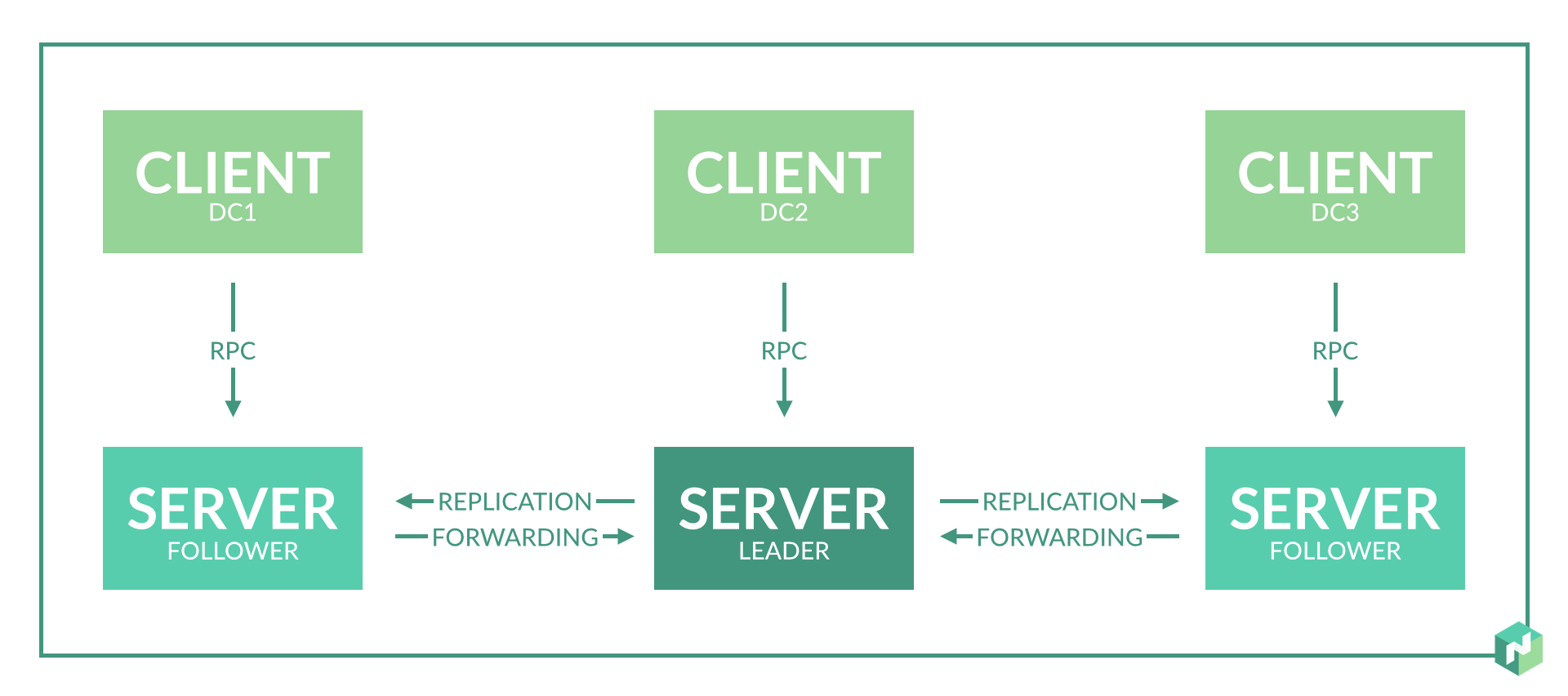
Pada awalnya, saya merencanakan 2-3 server node di setiap pusat data untuk menyediakan redundansi.
Setelah digunakan ternyata:
- Ini sama sekali tidak diperlukan, karena jika terjadi kegagalan simpul di pusat data, peran simpul server untuk agen di pusat data ini akan dimainkan oleh node server lain di wilayah tersebut.
- Ternyata lebih buruk lagi jika masalah 8 tidak diselesaikan. Ketika wizard terpilih kembali, ketidakkonsistenan dapat terjadi dan Nomad akan memulai kembali beberapa bagian dari layanan.
2. Sumber daya server untuk node server
Solusi: mesin virtual kecil sudah cukup untuk node server. Di server yang sama, diizinkan untuk menjalankan layanan non-sumber daya intensif lainnya.
Konsumsi memori daemon Nomad tergantung pada jumlah tugas yang berjalan. Konsumsi CPU - berdasarkan pada jumlah tugas dan jumlah server / agen di wilayah tersebut (tidak linier).
Dalam kasus kami: untuk 300 tugas yang berjalan, konsumsi memori adalah sekitar 500 MB untuk node master saat ini.
Dalam cluster yang berfungsi, mesin virtual untuk node server: 4 CPU, 6 GB RAM.
Diluncurkan tambahan: Konsul, Etcd, Vault.
3. Konsensus tentang kurangnya pusat data
Solusi: kami membuat tiga pusat data virtual dan tiga node server untuk dua pusat data fisik.
Pekerjaan Nomad di wilayah ini didasarkan pada protokol rakit. Untuk operasi yang benar, Anda memerlukan setidaknya 3 node server yang terletak di pusat data yang berbeda. Ini akan memungkinkan operasi yang benar dengan hilangnya konektivitas jaringan dengan salah satu pusat data.
Tetapi kami hanya memiliki dua pusat data. Kami membuat kompromi: kami memilih pusat data, yang lebih kami percayai, dan membuat simpul server tambahan di dalamnya. Kami melakukan ini dengan memperkenalkan pusat data virtual tambahan, yang secara fisik akan berlokasi di pusat data yang sama (lihat sub-paragraf 2 masalah 1).
Solusi alternatif: kami memecah pusat data menjadi wilayah yang terpisah.
Akibatnya, pusat data berfungsi secara independen dan konsensus hanya diperlukan dalam satu pusat data. Di dalam pusat data, dalam hal ini lebih baik untuk membuat 3 node server dengan menerapkan tiga pusat data virtual dalam satu fisik.
Opsi ini kurang nyaman untuk distribusi tugas, tetapi memberikan jaminan 100% atas independensi layanan jika terjadi masalah jaringan antara pusat data.
4. "Server" dan "agen" pada server yang sama
Solusi: valid jika Anda memiliki sejumlah server.
Dokumentasi pengembara mengatakan bahwa melakukan ini tidak diinginkan. Tetapi jika Anda tidak memiliki kesempatan untuk mengalokasikan mesin virtual terpisah untuk node server, Anda dapat menempatkan node server dan agen pada server yang sama.
Menjalankan secara bersamaan berarti memulai Nomad daemon dalam mode klien dan mode server.
Apa yang mengancam ini? Dengan beban yang besar pada CPU server ini, simpul server Nomad akan bekerja secara tidak stabil, mungkin ada kehilangan konsensus dan detak jantung, dan layanan yang dimuat ulang.
Untuk menghindari ini, kami meningkatkan batasan dari uraian masalah No. 8.
5. Implementasi ruang nama
Solusi: mungkin melalui organisasi pusat data virtual.
Terkadang Anda perlu menjalankan bagian dari layanan di server yang terpisah.
Solusinya adalah yang pertama, sederhana, tetapi lebih menuntut sumber daya. Kami membagi semua layanan ke dalam kelompok sesuai dengan tujuannya: frontend, backend, ... Tambahkan atribut meta ke server, meresepkan atribut untuk menjalankan semua layanan.
Solusi kedua sederhana. Kami menambahkan server baru, meresepkan atribut meta untuknya, meresepkan atribut peluncuran ini ke layanan yang diperlukan, semua layanan lain meresepkan larangan peluncuran di server dengan atribut ini.
Solusi ketiga rumit. Kami membuat pusat data virtual: luncurkan Konsul untuk pusat data baru, luncurkan simpul server Nomad untuk pusat data ini, jangan lupa jumlah node server untuk wilayah ini. Sekarang Anda dapat menjalankan layanan individual di pusat data virtual khusus ini.
6. Integrasi dengan Vault
Solusi: Hindari Nomad <-> Ketergantungan melingkar Vault.
Vault yang diluncurkan seharusnya tidak memiliki dependensi pada Nomad. Alamat Vault yang terdaftar di Nomad sebaiknya mengarah langsung ke Vault, tanpa lapisan penyeimbang (tetapi valid). Reservasi vault dalam hal ini dapat dilakukan melalui DNS - Konsul DNS atau eksternal.
Jika data Vault ditulis dalam file konfigurasi Nomad, maka Nomad mencoba mengakses Vault saat startup. Jika akses tidak berhasil, maka Nomad menolak untuk memulai.
Saya membuat kesalahan dengan ketergantungan siklik sejak lama, ini sempat hampir sepenuhnya menghancurkan cluster Nomad. Vault diluncurkan dengan benar, terlepas dari Nomad, tetapi Nomad melihat alamat Vault melalui penyeimbang yang berjalan di Nomad itu sendiri. Konfigurasi ulang dan me-reboot node server Nomad menyebabkan restart layanan penyeimbang, yang menyebabkan kegagalan untuk memulai node server sendiri.
7. Meluncurkan layanan statefull penting
Solusi: valid, tetapi saya tidak.
Apakah mungkin menjalankan PostgreSQL, ClickHouse, Redis Cluster, RabbitMQ, MongoDB via Nomad?
Bayangkan Anda memiliki serangkaian layanan penting, yang pekerjaannya terkait dengan sebagian besar layanan lainnya. Misalnya, database di PostgreSQL / ClickHouse. Atau penyimpanan jangka pendek umum di Redis Cluster / MongoDB. Atau bus data di Redis Cluster / RabbitMQ.
Semua layanan ini dalam beberapa bentuk mengimplementasikan skema toleransi kesalahan: Stolon / Patroni untuk PostgreSQL, implementasi rakitnya sendiri di Redis Cluster, implementasi clusternya sendiri di RabbitMQ, MongoDB, ClickHouse.
Ya, semua layanan ini dapat diluncurkan melalui Nomad dengan merujuk ke server tertentu, tetapi mengapa?
Plus - kemudahan peluncuran, format skrip tunggal, seperti layanan lainnya. Tidak perlu khawatir dengan skrip yang memungkinkan / apa pun.
Minus adalah titik kegagalan tambahan, yang tidak memberikan keuntungan apa pun. Secara pribadi, saya benar-benar menjatuhkan cluster Nomad dua kali karena berbagai alasan: sekali "rumah", sekali bekerja. Ini pada tahap awal memperkenalkan Nomad dan karena kecerobohan.
Juga, Nomad mulai berperilaku buruk dan memulai kembali layanan karena masalah nomor 8. Tetapi bahkan jika masalah itu diselesaikan, bahaya tetap ada.
8. Stabilisasi pekerjaan dan layanan restart dalam jaringan yang tidak stabil
Solusi: gunakan opsi penyetelan detak jantung.
Secara default, Nomad dikonfigurasi sehingga masalah jaringan jangka pendek atau beban CPU menyebabkan hilangnya konsensus dan pemilihan kembali wizard atau menandai simpul agen tidak dapat diakses. Dan ini mengarah pada reboot layanan secara spontan dan transfernya ke node lain.
Statistik cluster "rumah" sebelum memperbaiki masalah: masa hidup maksimum wadah sebelum memulai kembali adalah sekitar 10 hari. Di sini, masih dibebani dengan menjalankan agen dan server pada server yang sama dan menempatkannya di 5 pusat data yang berbeda di Eropa, yang menyiratkan beban besar pada CPU dan jaringan yang kurang stabil.
Statistik gugus kerja sebelum memperbaiki masalah: masa pakai kontainer maksimum sebelum memulai kembali adalah lebih dari 2 bulan. Semuanya relatif baik di sini karena server terpisah untuk node server Nomad dan jaringan yang sangat baik antara pusat data.
Nilai default
heartbeat_grace = "10s" min_heartbeat_ttl = "10s" max_heartbeats_per_second = 50.0
Dilihat oleh kode: dalam konfigurasi ini, detak jantung dilakukan setiap 10 detik. Dengan hilangnya dua detak jantung, pemilihan ulang master atau transfer layanan dari agen node dimulai. Pengaturan kontroversial, menurut saya. Kami mengeditnya tergantung pada aplikasi.
Jika Anda memiliki semua layanan yang berjalan dalam beberapa kasus dan didistribusikan oleh pusat data, maka kemungkinan besar, itu tidak masalah bagi Anda untuk menentukan periode tidak dapat diaksesnya server (sekitar 5 menit, dalam contoh di bawah) - kami membuat interval detak jantung lebih jarang dan periode yang lebih lama menentukan tidak dapat diaksesnya. Ini adalah contoh pengaturan cluster rumah saya:
heartbeat_grace = "300s" min_heartbeat_ttl = "30s" max_heartbeats_per_second = 10.0
Jika Anda memiliki konektivitas jaringan yang baik, memisahkan server untuk node server, dan periode menentukan tidak dapat diaksesnya server adalah penting (ada beberapa layanan yang berjalan dalam satu contoh dan penting untuk dengan cepat mentransfernya), kemudian tambahkan periode penentuan tidak dapat diaksesnya (heartbeat_grace). Secara opsional, Anda dapat melakukan lebih banyak detak jantung (dengan mengurangi min_heartbeat_ttl) - ini akan sedikit meningkatkan beban pada CPU. Contoh konfigurasi kluster kerja:
heartbeat_grace = "60s" min_heartbeat_ttl = "10s" max_heartbeats_per_second = 50.0
Pengaturan ini sepenuhnya memperbaiki masalah.
9. Memulai tugas berkala
Solusi: Layanan berkala Nomad dapat digunakan, tetapi cron lebih nyaman untuk dukungan.
Nomad memiliki kemampuan untuk meluncurkan layanan secara berkala.
Satu-satunya plus adalah kesederhanaan konfigurasi ini.
Kekurangan pertama adalah bahwa jika layanan mulai sering, itu akan mengotori daftar tugas. Misalnya, saat startup setiap 5 menit, 12 tugas tambahan akan ditambahkan ke daftar setiap jam, sampai Nomad GC terpicu, yang akan menghapus tugas-tugas lama.
Kekurangan kedua - tidak jelas cara mengkonfigurasi pemantauan layanan semacam itu dengan benar. Bagaimana memahami bahwa suatu layanan dimulai, memenuhi dan melakukan tugasnya sampai akhir?
Akibatnya, untuk diri saya sendiri, saya sampai pada implementasi tugas berkala "cron":
- Ini bisa menjadi cron reguler dalam wadah yang terus berjalan. Cron secara berkala menjalankan skrip tertentu. Pemeriksaan kesehatan skrip mudah ditambahkan ke wadah seperti itu, yang memeriksa setiap bendera yang membuat skrip yang sedang berjalan.
- Ini bisa menjadi wadah yang terus berjalan, dengan layanan yang terus berjalan. Peluncuran berkala telah diterapkan di dalam layanan. Baik skrip-pemeriksaan kesehatan atau http-pemeriksaan kesehatan dapat dengan mudah ditambahkan ke layanan seperti itu, yang segera memeriksa status dengan "bagian dalamnya".
Saat ini, saya menulis sebagian besar waktu di Go, masing-masing, saya lebih suka opsi kedua dengan http healthcheck - on Go dan peluncuran berkala, dan http healthcheck'i ditambahkan dengan beberapa baris kode.
10. Menyediakan layanan yang berlebihan
Solusi: Tidak ada solusi sederhana. Ada dua opsi yang lebih sulit.
Skema penyediaan yang disediakan oleh pengembang Nomad adalah untuk mendukung jumlah layanan yang berjalan. Anda mengatakan pengembara "meluncurkan saya 5 contoh layanan" dan dia mulai di suatu tempat di sana. Tidak ada kontrol atas distribusi. Mesin virtual dapat berjalan di server yang sama.
Jika server crash, instans ditransfer ke server lain. Ketika instance sedang ditransfer, layanan tidak berfungsi. Ini adalah opsi ketentuan cadangan yang buruk.
Kami melakukannya dengan benar:
- Kami mendistribusikan instance di server melalui differ_hosts .
- Kami mendistribusikan contoh di seluruh pusat data. Sayangnya, hanya dengan membuat salinan skrip dari formulir service1, service2 dengan konten yang sama, nama yang berbeda dan indikasi peluncuran di pusat data yang berbeda.
Dalam Nomad 0.9, sebuah fungsionalitas akan muncul yang akan memperbaiki masalah ini: akan mungkin untuk mendistribusikan layanan dalam rasio persentase antara server dan pusat data.
11. Web UI Nomad
Solusi: UI bawaan sangat buruk, hashi-ui indah.
Klien konsol melakukan sebagian besar fungsi yang diperlukan, tetapi kadang-kadang Anda ingin melihat grafik, tekan tombol ...
Nomad memiliki UI bawaan. Ini sangat tidak nyaman (bahkan lebih buruk daripada konsol).
Satu-satunya alternatif yang saya tahu adalah hashi-ui .
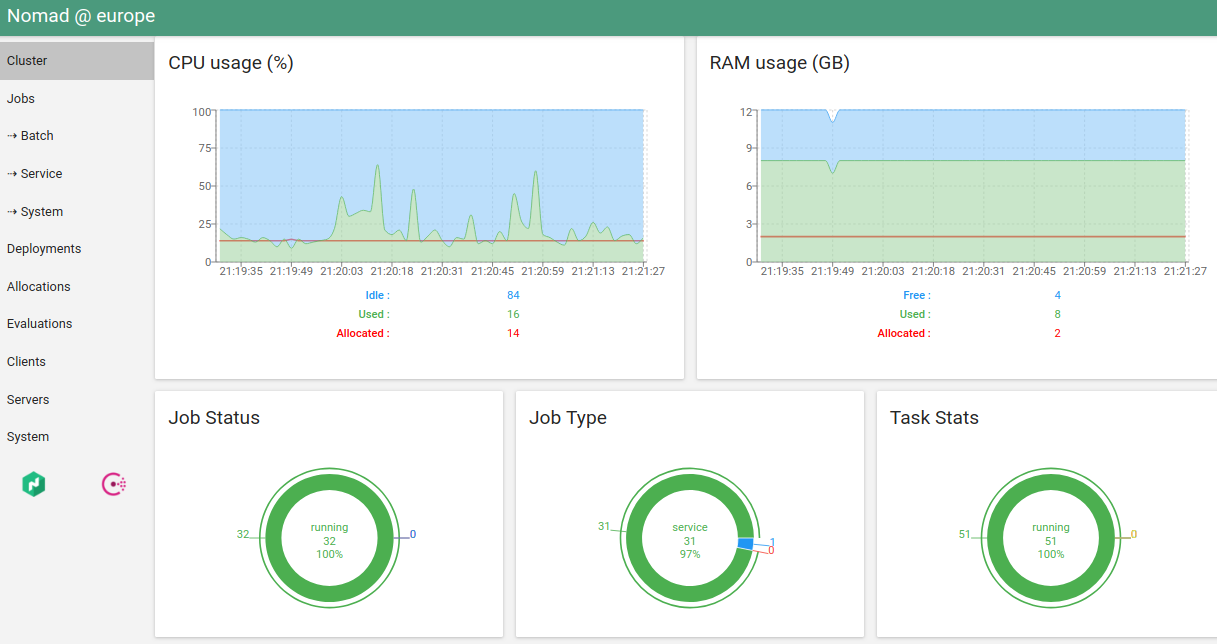
Bahkan, sekarang saya pribadi membutuhkan klien konsol hanya untuk "menjalankan nomad". Dan bahkan ini berencana untuk mentransfer ke CI.
12. Dukungan untuk kelebihan langganan dari memori
Solusi: no.
Dalam versi Nomad saat ini, Anda harus menentukan batas memori ketat untuk layanan ini. Jika batas terlampaui, layanan akan dibunuh oleh Pembunuh OOM.
Berlangganan berlebih adalah saat batas untuk layanan dapat ditentukan "dari dan ke." Beberapa layanan memerlukan lebih banyak memori saat startup daripada selama operasi normal. Beberapa layanan mungkin menggunakan lebih banyak memori daripada biasanya untuk waktu yang singkat.
Pilihan pembatasan ketat atau lunak adalah topik untuk diskusi, tetapi, misalnya, Kubernetes memungkinkan programmer untuk membuat pilihan. Sayangnya, dalam versi Nomad saat ini tidak ada kemungkinan seperti itu. Saya akui itu akan muncul di versi mendatang.
13. Membersihkan server dari layanan Nomad
Solusi:
sudo systemctl stop nomad mount | fgrep alloc | awk '{print $3}' | xargs -I QQ sudo umount QQ sudo rm -rf /var/lib/nomad sudo docker ps | grep -v '(-1|-2|...)' | fgrep -v IMAGE | awk '{print $1}' | xargs -I QQ sudo docker stop QQ sudo systemctl start nomad
Terkadang "ada yang tidak beres." Di server, ia membunuh node agen dan menolak untuk memulai. Atau simpul agen berhenti merespons. Atau simpul agen "kehilangan" layanan di server ini.
Ini kadang-kadang terjadi dengan versi Nomad yang lebih lama, sekarang ini tidak terjadi, atau sangat jarang.
Apa dalam hal ini yang paling mudah dilakukan, mengingat server drain tidak akan menghasilkan hasil yang diinginkan? Kami membersihkan server secara manual:
- Hentikan agen nomad.
- Buat umount pada mount yang dibuatnya.
- Hapus semua data agen.
- Kami menghapus semua wadah dengan memfilter wadah layanan (jika ada).
- Kami memulai agen.
14. Apa cara terbaik untuk menggunakan Nomad?
Solusi: tentu saja, melalui Konsul.
Konsul dalam hal ini sama sekali bukan lapisan tambahan, tetapi layanan yang secara organik cocok dengan infrastruktur, yang memberikan lebih banyak plus daripada minus: DNS, penyimpanan KV, mencari layanan, memantau ketersediaan layanan, kemampuan untuk bertukar informasi dengan aman.
Selain itu, itu terungkap semudah Nomad sendiri.
15. Mana yang lebih baik - Pengembara atau Kubernet?
Solusi: tergantung pada ...
Sebelumnya, kadang-kadang saya berpikir untuk memulai migrasi ke Kubernetes - saya sangat terganggu dengan reboot layanan berkala yang berkala (lihat masalah nomor 8). Tetapi setelah solusi lengkap untuk masalah ini, saya dapat mengatakan: Nomad cocok untuk saya saat ini.
Di sisi lain: Kubernetes juga memiliki layanan reload semi-spontan - ketika scheduler Kubernet mendistribusikan kembali instance tergantung pada beban. Ini tidak terlalu keren, tetapi ada kemungkinan besar dikonfigurasi.
Keuntungan Nomad: infrastrukturnya sangat mudah digunakan, skrip sederhana, dokumentasi yang baik, dukungan bawaan untuk Konsul / Vault, yang pada gilirannya memberikan: solusi sederhana untuk masalah penyimpanan kata sandi, DNS bawaan, helcheck yang mudah dikonfigurasikan.
Pro dari Kubernetes: Sekarang ini adalah "standar de facto." Dokumentasi yang baik, banyak solusi siap pakai, dengan deskripsi dan standarisasi peluncuran yang baik.
Sayangnya, saya tidak memiliki keahlian hebat yang sama di Kubernetes untuk dengan tegas menjawab pertanyaan - apa yang harus digunakan untuk cluster baru. Tergantung kebutuhan yang direncanakan.
Jika Anda memiliki banyak ruang nama yang direncanakan (masalah nomor 5) atau layanan spesifik Anda menggunakan banyak memori di awal, kemudian membebaskannya (masalah nomor 12) - pasti Kubernetes, karena dua masalah ini dalam Pengembara tidak sepenuhnya diselesaikan atau tidak nyaman.