Hai Saya Dima, dan saya telah duduk di Python selama beberapa waktu sekarang. Hari ini saya ingin menunjukkan kepada Anda perbedaan antara dua kerangka kerja yang tidak sinkron - Tornado dan Aiohttp. Saya akan menceritakan kisah tentang pilihan antara kerangka kerja dalam proyek kami, bagaimana coroutine di Tornado dan AsyncIO berbeda, saya akan menunjukkan tolok ukur dan memberikan beberapa kiat bermanfaat tentang cara masuk ke belantara kerangka kerja dan berhasil keluar dari sana.

Seperti yang Anda ketahui, Avito adalah layanan iklan yang cukup besar. Kami memiliki banyak data dan memuat, 35 juta pengguna setiap bulan dan 45 juta iklan aktif setiap hari. Saya bekerja sebagai penasihat teknis kelompok pengembangan rekomendasi. Tim saya menulis layanan microser, sekarang kami memiliki sekitar dua puluh di antaranya. Beban menumpuk pada semua ini - seperti 5k RPS.
Memilih Kerangka Asinkron
Pertama, saya akan memberi tahu Anda bagaimana kami berada di tempat sekarang. Pada 2015, kami perlu memilih kerangka kerja yang tidak sinkron, karena kami tahu:
- Anda harus membuat banyak permintaan ke layanan microser lainnya: http, json, rpc;
- Anda perlu mengumpulkan data dari berbagai sumber sepanjang waktu: Redis, Postgres, MongoDB.
Dengan demikian, kami memiliki banyak tugas jaringan, dan aplikasi ini terutama diisi dengan input / output. Versi python saat itu adalah 3.4, async dan menunggu belum muncul. Aiohttp juga - dalam versi 0.x. Asynchronous Tornado Facebook muncul pada 2010. Banyak driver database ditulis untuknya yang kita butuhkan. Tornado menunjukkan hasil yang stabil pada tolok ukur. Lalu kami menghentikan pilihan kami pada kerangka ini.
Tiga tahun kemudian, kami sangat mengerti.
Pertama, Python 3.5 keluar dengan mekanik async / menunggu. Kami menemukan apa perbedaan antara hasil dan hasil dari dan bagaimana Tornado konsisten dengan menunggu (spoiler: tidak terlalu baik).
Kedua, kami mengalami masalah kinerja aneh dengan sejumlah besar coroutine di scheduler, bahkan ketika CPU tidak sepenuhnya terisi.
Ketiga, kami menemukan bahwa ketika melakukan sejumlah besar permintaan http ke layanan Tornado lainnya, Anda harus berteman terutama dengan resolver dns asinkron, tidak menghormati batas waktu untuk membuat koneksi dan mengirimkan permintaan yang kami tentukan. Dan secara umum, metode terbaik untuk membuat permintaan http di Tornado adalah curl, yang agak aneh dalam dirinya sendiri.
Dalam pidatonya
di PyCon Russia 2018, Andrei Svetlov mengatakan: “Jika Anda ingin menulis beberapa jenis aplikasi web yang tidak sinkron, harap hanya menulis async, tunggu. Event loop, mungkin, Anda tidak akan memerlukannya sama sekali segera. Jangan masuk ke belantara kerangka agar tidak bingung. Jangan gunakan primitif level rendah, dan semuanya akan baik-baik saja dengan Anda ... ". Sayangnya, selama tiga tahun terakhir, kami harus sering naik ke bagian dalam Tornado, belajar banyak hal menarik dari sana dan melihat traysback raksasa untuk 30-40 panggilan.
Hasil vs hasil dari
Salah satu masalah terbesar untuk dipahami dalam python asinkron adalah perbedaan antara hasil dan hasil.
Guido Van Rossum menulis lebih banyak tentang ini. Saya melampirkan terjemahan dengan sedikit singkatan.
Saya telah ditanya beberapa kali mengapa PEP 3156 bersikeras menggunakan hasil-dari bukan hasil, yang mengecualikan kemungkinan backporting di Python 3.2 atau bahkan 2.7.
(...)
kapan pun Anda menginginkan hasil di masa depan, Anda menggunakan hasil.
Ini diimplementasikan sebagai berikut. Fungsi yang berisi hasil adalah (jelas) generator, jadi harus ada semacam kode berulang. Sebut saja dia perencana. Bahkan, penjadwal tidak "beralih" dalam arti klasik (dengan for-loop); alih-alih, ini mendukung dua koleksi mendatang.
Saya akan menyebut koleksi pertama sebagai urutan "yang dapat dieksekusi". Ini adalah masa depan, yang hasilnya tersedia. Meskipun daftar ini tidak kosong, penjadwal memilih satu item dan mengambil satu langkah iterasi. Langkah ini memanggil metode generator .send () dengan hasil dari masa depan (yang mungkin merupakan data yang baru saja dibaca dari soket); di generator, hasil ini muncul sebagai nilai balik dari ekspresi hasil. Ketika kirim () mengembalikan hasil atau selesai, penjadwal mem-parsing hasil (yang mungkin StopIteration, pengecualian lain, atau semacam objek).
(Jika Anda bingung, Anda mungkin harus membaca tentang cara kerja generator, khususnya, metode .send (). Mungkin PEP 342 adalah titik awal yang baik).
(...)
koleksi masa depan kedua didukung oleh penjadwal terdiri dari masa depan, yang masih menunggu I / O. Entah bagaimana mereka diteruskan ke pilih / polling / shell dll yang memberikan panggilan balik ketika file deskriptor siap untuk I / O. Callback sebenarnya melakukan operasi I / O yang diminta oleh masa depan, menetapkan nilai masa depan yang dihasilkan ke hasil operasi I / O, dan memindahkan masa depan ke antrian eksekusi.
(...)
Sekarang kita telah mencapai yang paling menarik. Misalkan Anda sedang menulis protokol yang kompleks. Di dalam protokol Anda, Anda membaca byte dari soket menggunakan metode recv (). Bytes ini sampai ke buffer. Metode recv () dibungkus dengan shell async, yang menetapkan I / O dan mengembalikan masa depan, yang dieksekusi ketika I / O selesai, seperti yang saya jelaskan di atas. Sekarang anggaplah bahwa beberapa bagian lain dari kode Anda ingin membaca data dari buffer satu baris pada satu waktu. Misalkan Anda menggunakan metode readline (). Jika ukuran buffer lebih besar dari panjang garis rata-rata, metode readline () Anda bisa mendapatkan baris berikutnya dari buffer tanpa memblokir; tetapi kadang-kadang buffer tidak berisi seluruh baris, dan readline () pada gilirannya panggilan recv () pada soket.
Pertanyaan: haruskah readline () kembali lagi atau tidak? Itu tidak akan sangat baik jika dia kadang-kadang mengembalikan string byte, dan kadang-kadang di masa depan, memaksa penelepon untuk melakukan pengecekan tipe dan hasil bersyarat. Jadi jawabannya adalah readline () harus selalu mengembalikan masa depan. Ketika readline () dipanggil, ia memeriksa buffer, dan jika ia menemukan setidaknya seluruh baris di sana, itu menciptakan masa depan, menetapkan hasil masa depan dari sebuah baris yang diambil dari buffer, dan mengembalikan masa depan. Jika buffer tidak memiliki seluruh baris, ia memulai I / O dan mengharapkannya, dan ketika I / O selesai, ia mulai lagi.
(...)
Tetapi sekarang kami membuat banyak yang di masa depan yang tidak memerlukan pemblokiran I / O, tetapi masih memaksa panggilan ke penjadwal, karena readline () mengembalikan masa depan, hasil diperlukan dari pemanggil, dan itu berarti panggilan ke penjadwal.
Penjadwal dapat mentransfer kontrol langsung ke coroutine jika melihat bahwa masa depan, yang telah selesai, ditampilkan, atau dapat mengembalikan masa depan ke antrian eksekusi. Yang terakhir akan sangat memperlambat pekerjaan (asalkan ada lebih dari satu coroutine yang dapat dieksekusi), karena tidak hanya menunggu di akhir antrian diperlukan, tetapi lokalitas memori (jika ada sama sekali) mungkin juga hilang.
(...)
Efek bersih dari semua ini adalah bahwa penulis coroutine perlu mengetahui tentang yield di masa depan, dan oleh karena itu ada hambatan psikologis yang lebih besar untuk mengatur ulang kode kompleks menjadi coroutine yang lebih mudah dibaca - jauh lebih kuat daripada resistensi yang ada, karena pemanggilan fungsi dengan Python cukup lambat. Dan saya ingat dari percakapan dengan Glyph bahwa kecepatan itu penting dalam struktur I / O asinkron yang khas.
Sekarang mari kita bandingkan ini dengan hasil-dari.
(...)
Anda mungkin pernah mendengar bahwa "hasil dari S" kira-kira setara dengan "untuk i di S: hasil i". Dalam kasus yang paling sederhana, ini benar, tetapi ini tidak cukup untuk memahami coroutine. Pertimbangkan hal-hal berikut (jangan berpikir tentang I / O async):
def driver(g): print(next(g)) g.send(42) def gen1(): val = yield 'okay' print(val) driver(gen1())
Kode ini mencetak dua baris yang berisi "oke" dan "42" (dan kemudian menghasilkan StopIteration yang tidak tertangani, yang dapat Anda tekan dengan menambahkan hasil pada akhir gen1). Anda dapat melihat kode ini beraksi di pythontutor.com di tautan .
Sekarang pertimbangkan hal berikut:
def gen2(): yield from gen1() driver(gen2())
Cara kerjanya sama persis . Sekarang pikirkan. Bagaimana cara kerjanya? Ekstensi hasil-dari yang sederhana di for-loop tidak dapat digunakan di sini, karena dalam hal ini kode akan mengembalikan Tidak ada. (Cobalah) . Hasil-dari bertindak sebagai "saluran transparan" antara driver dan gen1. Yaitu, ketika gen1 memberikan nilai "oke", ia meninggalkan gen2, melalui hasil-dari, ke pengemudi, dan ketika pengemudi mengirimkan 42 kembali ke gen2, nilai ini dikembalikan kembali melalui hasil-dari ke gen1 lagi (di mana ia menjadi hasil dari hasil )
Hal yang sama akan terjadi jika pengemudi melemparkan kesalahan ke generator: kesalahan melewati hasil-dari ke generator internal yang memprosesnya. Sebagai contoh:
def throwing_driver(g): print(next(g)) g.throw(RuntimeError('booh')) def gen1(): try: val = yield 'okay' except RuntimeError as exc: print(exc) else: print(val) yield throwing_driver(gen1())
Kode akan memberikan "oke" dan "bah", serta kode berikut:
def gen2(): yield from gen1()
(Lihat di sini: goo.gl/8tnjk )
Sekarang saya ingin memperkenalkan grafis sederhana (ASCII) agar dapat berbicara tentang kode semacam ini. Saya menggunakan [f1 -> f2 -> ... -> fN) untuk mewakili tumpukan dengan f1 di bagian bawah (bingkai panggilan terlama) dan fN di bagian atas (bingkai panggilan terbaru), di mana setiap item dalam daftar adalah generator, dan -> menghasilkan-dari . Contoh pertama, driver (gen1 ()) tidak memiliki hasil-dari, tetapi memiliki generator gen1, sehingga terlihat seperti ini:
[ gen1 )
Pada contoh kedua, gen2 memanggil gen1 menggunakan yield-from, sehingga terlihat seperti ini:
[ gen2 -> gen1 )
Saya menggunakan notasi matematika untuk interval setengah-terbuka [...) untuk menunjukkan bahwa frame lain dapat ditambahkan ke kanan ketika generator paling kanan menggunakan yield-from untuk memanggil generator lain, sedangkan ujung kiri lebih atau kurang diperbaiki. Akhiran kiri adalah apa yang dilihat pengemudi (mis., Penjadwal).
Sekarang saya siap untuk kembali ke contoh readline (). Kita dapat menulis ulang readline () sebagai generator yang memanggil read (), generator lain menggunakan yield-from; yang terakhir, pada gilirannya, panggilan recv (), yang melakukan input / output aktual dari soket. Di sebelah kiri kami adalah aplikasi, yang kami juga anggap sebagai generator yang memanggil readline (), lagi-lagi menggunakan yield-from. Skemanya adalah sebagai berikut:
[ app -> readline -> read -> recv )
Sekarang generator recv () menyetel I / O, mengikatnya ke masa depan, dan meneruskannya ke scheduler menggunakan * yield * (bukan yield-from!). masa depan pergi ke kiri di sepanjang kedua hasil-dari panah di penjadwal (terletak di sebelah kiri "["). Perhatikan bahwa penjadwal tidak tahu bahwa itu berisi setumpuk generator; yang dia tahu adalah dia mengandung generator paling kiri dan dia baru saja mengeluarkan masa depan. Ketika I / O selesai, penjadwal mengatur hasil di masa depan dan mengirimkannya kembali ke generator; hasilnya bergerak ke kanan sepanjang kedua yiled-dari panah ke generator recv, yang menerima byte yang ingin dibaca dari soket sebagai hasil hasil.
Dengan kata lain, hasil-dari penjadwal kerangka menangani operasi I / O seperti penjadwal kerangka kerja berbasis hasil yang saya jelaskan sebelumnya. * Tetapi: * dia tidak perlu khawatir tentang optimasi ketika masa depan sudah dieksekusi, karena penjadwal tidak berpartisipasi dalam transfer kontrol antara readline () dan read () atau antara read () dan recv (), dan sebaliknya. Oleh karena itu, penjadwal tidak berpartisipasi sama sekali ketika app () memanggil readline (), dan readline () dapat memenuhi permintaan dari buffer (tanpa memanggil read ()) - interaksi antara app () dan readline () dalam kasus ini sepenuhnya diproses oleh penerjemah bytecode Python Penjadwal dapat lebih sederhana, dan jumlah masa depan dibuat dan dikelola oleh penjadwal kurang, karena tidak ada masa depan yang dibuat dan dihancurkan dengan setiap panggilan coroutine. Satu-satunya masa depan yang masih dibutuhkan adalah yang mewakili I / O aktual, misalnya, dibuat oleh recv ().
Jika Anda telah membaca sampai titik ini, Anda layak mendapat hadiah. Saya menghilangkan banyak detail implementasi, tetapi ilustrasi di atas pada dasarnya mencerminkan gambar dengan benar.
Hal lain yang ingin saya tunjukkan. * Anda dapat * membuat bagian dari kode menggunakan hasil-dari, dan bagian lain menggunakan hasil. Tetapi hasil mengharuskan setiap tautan dalam rantai memiliki masa depan, bukan hanya coroutine. Karena ada beberapa keuntungan menggunakan hasil-dari, saya ingin pengguna tidak harus ingat kapan harus menggunakan hasil, dan ketika hasil-dari, lebih mudah untuk selalu menggunakan hasil-dari. Sebuah solusi sederhana bahkan memungkinkan recv () menggunakan yield-from untuk melewati I / O masa depan ke penjadwal: metode __iter__ sebenarnya adalah generator yang dikeluarkan oleh masa depan.
(...)
Dan satu hal lagi. Nilai apa yang dihasilkan dari pengembalian? Ternyata ini adalah nilai pengembalian generator * eksternal *.
(...)
Jadi, meskipun panah mengikat frame kiri dan kanan ke target * menghasilkan *, mereka juga melewati nilai pengembalian yang biasa dengan cara biasa, satu frame stack pada suatu waktu. Pengecualian dipindahkan dengan cara yang sama; tentu saja, pada setiap level, coba / kecuali diperlukan untuk menangkap mereka.
Ternyata hasil dari hampir sama dengan menunggu.
hasil dari vs async
def coro () ^ y = hasil dari a | async def async_coro (): y = menunggu a |
| 0 load_global | 0 load_global |
| 2 get_yield_from_iter | 2 get_awaitable |
| 4 load_const | 4 load_const |
| 6 yield_from | 6 yield_from |
| 8 store_fast | 8 store_fast |
| 10 load_const | 10 load_const
|
| 12 return_value | 12 return_value |
Dua coroutine dari sekolah lama dan baru hanya memiliki satu perbedaan kecil - dapatkan hasil dari iter vs dapatkan ditunggu.
Kenapa ini semua? Tornado menggunakan hasil sederhana. Sebelum versi 5, ini menghubungkan seluruh rangkaian panggilan melalui hasil, yang tidak kompatibel dengan hasil keren baru dari / menunggu paradigma.
Benchmark asinkron paling sederhana
Sulit untuk menemukan kerangka kerja yang benar-benar baik, memilihnya hanya berdasarkan tes sintetik. Dalam kehidupan nyata, banyak hal bisa salah.
Saya mengambil Aiohttp versi 3.4.4, Tornado 5.1.1, uvloop 0.11, mengambil prosesor server Intel Xeon, CPU E5 v4, 3.6 GHz, dan dengan Python 3.6.5 saya mulai memeriksa daya saing server web.
Masalah umum yang kami pecahkan dengan bantuan layanan microser, dan yang berfungsi dalam mode asinkron, terlihat seperti ini. Kami akan menerima permintaan. Untuk masing-masing dari mereka, kami akan membuat satu permintaan ke beberapa layanan mikro, mendapatkan data dari sana, lalu pergi ke dua atau tiga layanan microser lain, juga secara tidak sinkron, kemudian menulis data di suatu tempat ke database dan mengembalikan hasilnya. Ternyata banyak poin dimana kita akan menunggu.
Kami melakukan operasi yang lebih sederhana. Kami menyalakan server, membuatnya tidur 50 ms. Buat coroutine dan lengkapi. Kami tidak akan memiliki RPS yang sangat besar (itu mungkin bukan urutan besarnya mirip dengan apa yang terlihat dalam tolok ukur sepenuhnya sintetis) dengan penundaan yang dapat diterima karena fakta bahwa banyak coroutine secara bersamaan akan berputar di server yang kompetitif.
@tornado.gen.coroutine def old_school_work(): yield tornado.gen.sleep(SLEEP_TIME) async def work(): await tornado.gen.sleep(SLEEP_TIME)
Load - DAPATKAN permintaan http. Durasi - 300an, 1an - pemanasan, 5 pengulangan beban.
 Hasil pada persentil waktu respons layanan.
Hasil pada persentil waktu respons layanan.Apa itu persentil?Anda memiliki sejumlah besar angka. Persentil ke-95 X berarti bahwa 95% dari nilai dalam sampel ini kurang dari X. Dengan probabilitas 5%, angka Anda akan lebih besar dari X.
Kita melihat bahwa Aiohttp melakukan pekerjaan yang baik pada 1000 RPS pada tes sederhana. Sejauh ini tanpa
uvloop .
Bandingkan Tornado dengan coroutine dari sekolah lama (hasil) dan baru (async). Penulis sangat menyarankan untuk menggunakan async. Kita dapat memastikan bahwa mereka benar-benar jauh lebih cepat.
Pada 1200 RPS, Tornado, bahkan dengan coroutine sekolah baru, sudah mulai menyerah, dan Tornado dengan coroutine sekolah lama benar-benar terpesona. Jika kita tidur selama 50 ms, dan microservice bertanggung jawab untuk 80 ms - ini tidak masuk ke gerbang sama sekali.
Sekolah baru Tornado di 1.500 RPS telah sepenuhnya menyerah, sementara Aiohttp masih jauh dari batas 3.000 RPS. Yang paling menarik belum datang.
Pyflame, membuat profil microservice yang berfungsi
Mari kita lihat apa yang terjadi saat ini dengan prosesor.

Ketika kami menemukan cara kerja layanan asinkron Python dalam produksi, kami mencoba memahami apa yang ditabraknya. Dalam kebanyakan kasus, masalahnya adalah dengan CPU atau deskriptor. Ada alat profil hebat yang dibuat di Uber, profiler
Pyflame , yang didasarkan pada panggilan sistem ptrace.
Kami memulai beberapa layanan dalam wadah dan mulai melemparkan beban tempur di atasnya. Seringkali ini bukan tugas yang sangat sepele - untuk membuat hanya beban yang ada dalam pertempuran, karena sering terjadi bahwa Anda menjalankan tes sintetis pada pengujian beban, Anda melihat, dan semuanya berfungsi dengan baik. Anda mendorong beban tempur padanya, dan di sini microservice mulai tumpul.
Selama operasi, profiler ini melakukan snapshot dari tumpukan panggilan untuk kami. Anda tidak dapat mengubah layanan sama sekali, cukup jalankan pyflame di dekat Anda. Ini akan mengumpulkan jejak tumpukan sekali dalam periode waktu tertentu, dan kemudian melakukan visualisasi yang keren. Profiler ini memberikan overhead yang sangat sedikit, terutama jika dibandingkan dengan cProfile. Pyflame juga mendukung program multithreaded. Kami meluncurkan hal ini langsung di prod, dan kinerjanya tidak banyak menurun.
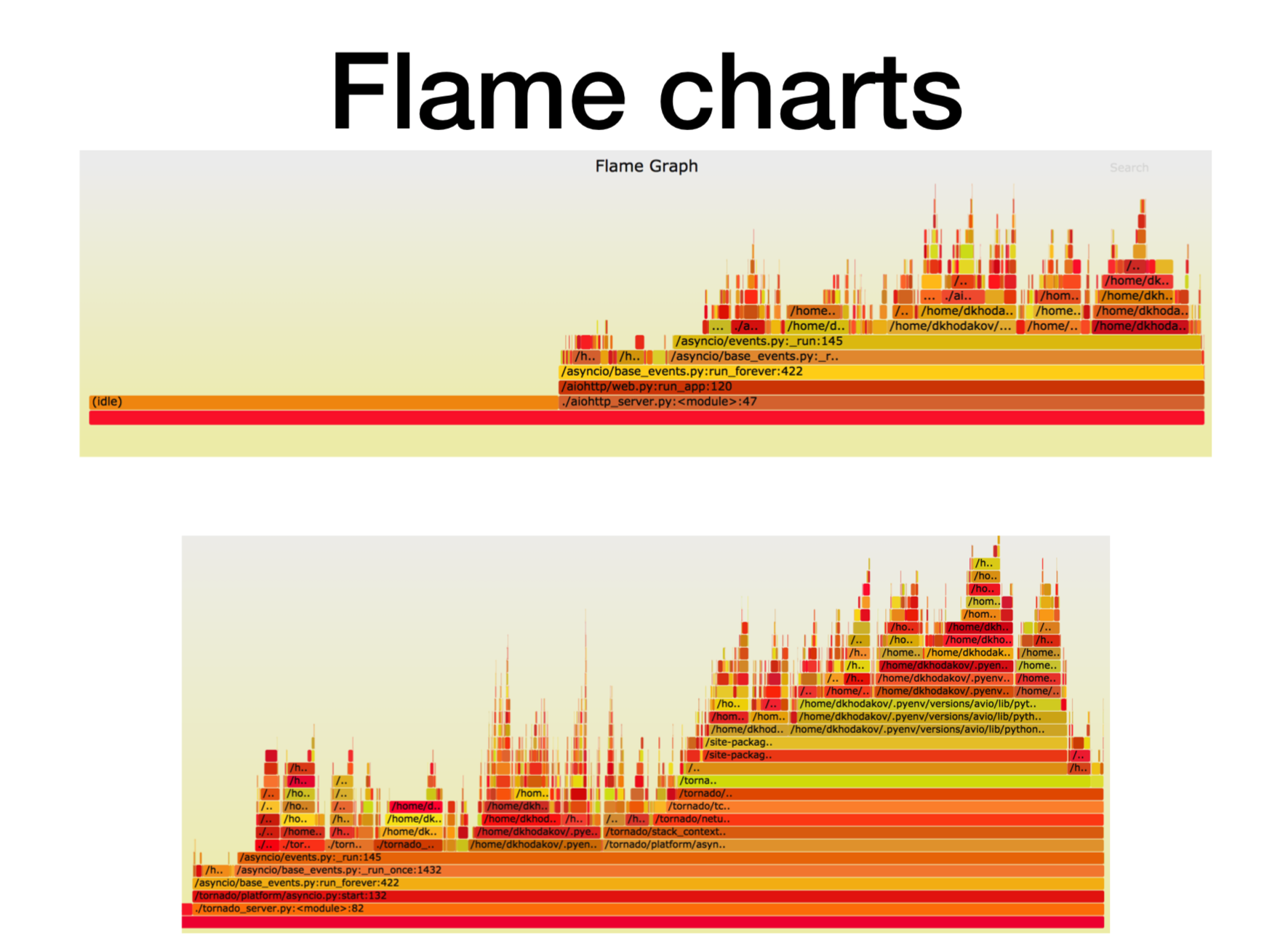
Di sini, sumbu X adalah jumlah waktu, jumlah panggilan, ketika bingkai tumpukan berada di daftar semua bingkai tumpukan Python. Ini adalah perkiraan jumlah waktu prosesor yang kami habiskan dalam kerangka tumpukan ini.
Seperti yang Anda lihat, sebagian besar waktu di aiohttp tidak digunakan. Baik: inilah yang kami inginkan dari layanan asinkron sehingga akan sering berhubungan dengan panggilan jaringan. Kedalaman tumpukan dalam hal ini adalah sekitar 15 bingkai.
Dalam Tornado (gambar kedua) dengan beban yang sama, lebih sedikit waktu yang dihabiskan untuk siaga dan kedalaman tumpukan dalam kasus ini adalah sekitar 30 frame.
Berikut ini
tautan ke svg , Anda dapat memutar sendiri.
Benchmark asinkron yang lebih kompleks
async def work():
Harapkan runtime dari 125 ms.

Tornado dengan uvloop bertahan lebih baik. Tapi Aiohttp uvloop membantu lebih banyak. Aiohttp mulai berperilaku buruk pada 2300-2400 RPS, dan dengan uvloop secara signifikan memperluas rentang beban. Satu jalur impor, dan sekarang Anda memiliki layanan yang jauh lebih produktif.
Ringkasan
Saya akan meringkas apa yang ingin saya sampaikan kepada Anda hari ini.
- Pertama, saya meluncurkan tolok ukur buatan tertentu, di mana ada coroutine panjang yang layak. Dalam pengujian kami, Aiohttp tampil lebih baik 2,5 kali dari Tornado.
- Fakta kedua. Uvloop sangat baik membantu meningkatkan kinerja Aiohttp (lebih baik daripada Tornado).
- Saya memberi tahu Anda tentang Pyflame, yang sering kami profil aplikasi secara langsung dalam produksi.
- Dan juga kita berbicara tentang hasil dari (menunggu) versus hasil.
Sebagai hasil dari tolok ukur ini, tim rekomendasi kami (dan beberapa yang lain) hampir sepenuhnya pindah ke Aiohttp dengan Tornado untuk layanan microser di Python dalam produksi.
- Untuk layanan tempur, konsumsi CPU turun lebih dari 2 kali.
- Kami mulai menghormati batas waktu untuk permintaan http.
- Layanan latensi turun 2 hingga 5 kali.
Berikut ini
tautan ke tolok ukur . Jika tertarik, Anda bisa mengulanginya. Terima kasih atas perhatiannya. Ajukan pertanyaan, saya akan mencoba menjawabnya.