Dalam artikel sebelumnya dari St. Petersburg HSE, kami menunjukkan bagaimana pembelajaran mesin dapat mencari bug dalam kode program. Dalam posting ini, kita akan berbicara tentang bagaimana kita, bersama-sama dengan JetBrains Research, sedang mencoba untuk menggunakan salah satu bagian pembelajaran mesin yang paling menarik, modern dan tumbuh cepat - pembelajaran penguatan - baik dalam masalah praktis nyata maupun dalam contoh model.

Tentang diri saya
Nama saya Nikita Sazanovich. Hingga Juni 2018, saya belajar di SPbAU selama tiga tahun, dan kemudian, bersama teman sekelas saya yang lain, dipindahkan ke HSE St. Petersburg, tempat saya sekarang menyelesaikan studi sarjana saya. Baru-baru ini, saya juga bekerja sebagai peneliti di JetBrains Research. Sebelum memasuki universitas, saya sangat menyukai pemrograman olahraga dan bermain untuk tim nasional Belarus.
Pelatihan penguatan
Pembelajaran penguatan adalah cabang pembelajaran mesin di mana agen, berinteraksi dengan lingkungan, menerima penguatan (karenanya namanya) dalam bentuk hadiah positif atau negatif. Bergantung pada permintaan ini, agen mengubah perilakunya. Tujuan akhir dari proses ini adalah untuk menerima hadiah sebesar mungkin, atau, dengan cara lain, untuk mencapai tindakan yang telah ditetapkan agen.
Agen beroperasi pada kondisi dan memilih tindakan. Misalnya, dalam masalah keluar dari labirin, negara bagian kita akan menjadi koordinat x dan y, dan tindakan akan naik / turun / kiri / kanan. Skema umum terlihat seperti ini:
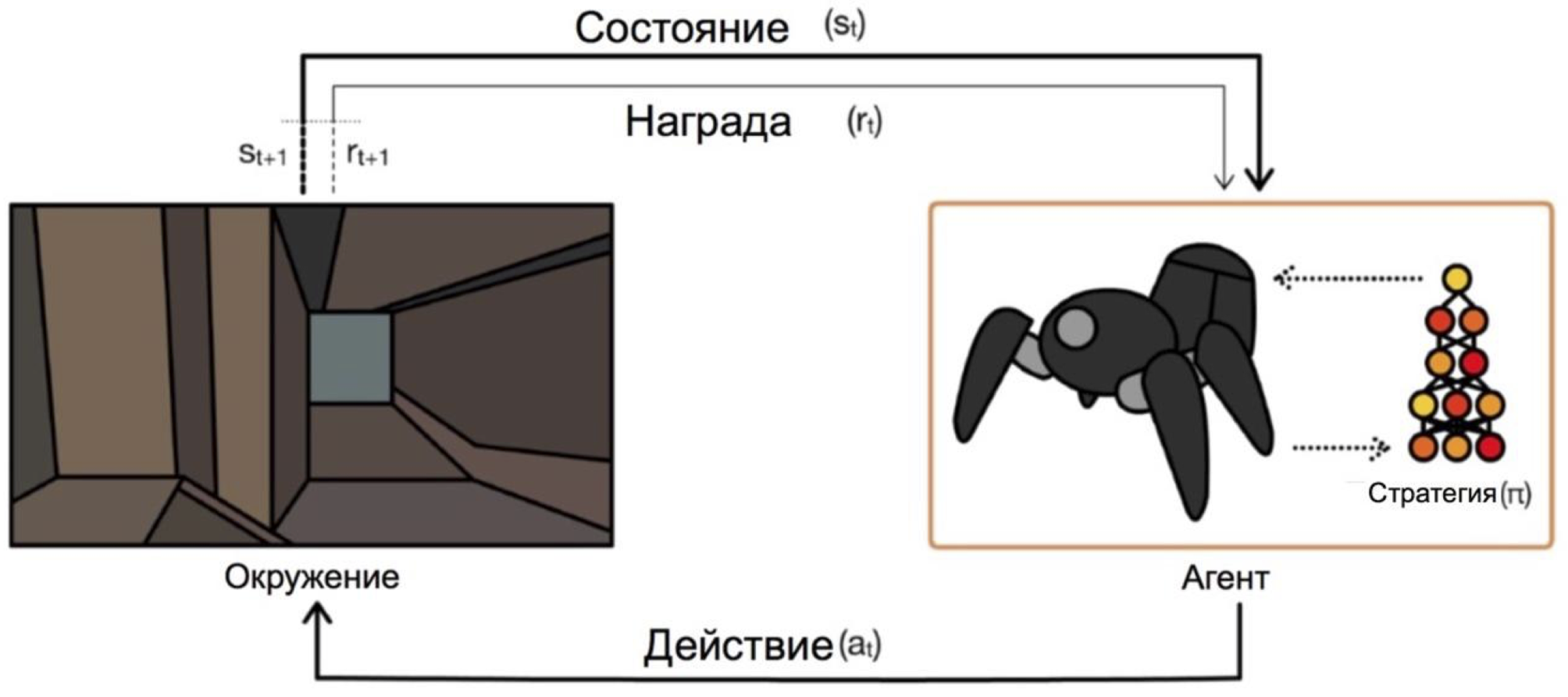
Masalah utama dalam transisi dari tugas fiksi / sederhana (seperti labirin yang sama) ke tugas nyata / praktis adalah ini: imbalan dalam tugas semacam itu biasanya sangat jarang. Jika kita ingin agen, misalnya, mengirimkan pizza di peta kota, maka dia akan mengerti bahwa dia melakukan sesuatu dengan baik, hanya dengan mengirimkan pesanan ke pintu, dan ini akan terjadi hanya jika Anda mengikuti urutan tindakan yang panjang dan benar.
Masalah ini dapat diatasi dengan memberikan agen pada contoh awal tentang bagaimana "bermain" - yang disebut demonstrasi ahli.
Tugas untuk belajar
Masalah model yang akan dibahas dalam artikel adalah Dota 2.
Dota 2 adalah gim MOBA yang populer di mana tim yang terdiri dari lima pahlawan harus mengalahkan tim lawan dengan menghancurkan "benteng" mereka. Dota 2 dianggap sebagai permainan yang agak rumit, ia memiliki esports dengan hadiah di turnamen utama seharga $ 25000000 .
Anda dapat mendengar tentang keberhasilan OpenAI baru-baru ini di Dota 2. Pertama-tama mereka menciptakan bot satu-satu dan mengalahkan pemain profesional , kemudian mereka beralih ke permainan 5x5 dan menunjukkan hasil mengesankan musim panas ini, meskipun mereka kalah dari tim profesional.

Satu-satunya masalah adalah mereka melatih agen untuk permainan satu lawan satu, menurut mereka , pada 60.000 CPU dan 256 K80 GPU di Azure cloud. Mereka, tentu saja, memiliki kesempatan untuk memesan begitu banyak kekuatan. Tetapi jika Anda memiliki daya yang lebih kecil, maka Anda harus menggunakan trik. Salah satu triknya adalah penggunaan game yang sudah dimainkan oleh orang.
Demo dalam game
Dalam kebanyakan kasus, demonstrasi direkam secara artifisial: Anda baru saja menyelesaikan tugas / bermain game dan entah bagaimana mengumpulkan tindakan yang telah Anda ambil. Jadi Anda mengumpulkan beberapa data yang dapat tertanam dalam pelatihan dengan berbagai cara. Sejauh ini saya telah melakukannya, tetapi bagaimana tepatnya - akan menjadi jelas setelah bagian tentang skema interaksi dengan klien game.
Tujuan yang lebih besar dan lebih berani adalah untuk mendapatkan lebih banyak data dari akses terbuka. Salah satu alasan ketika memilih Dota 2 untuk mempercepat pembelajaran adalah sumber daya seperti dotabuff . Ada beberapa statistik yang dikumpulkan pada permainan, tetapi yang lebih penting, ada replay penuh permainan. Dan mereka dapat disortir berdasarkan peringkat.
Sejauh ini saya belum mencoba bagaimana gigabytes data seperti itu akan sangat membantu dibandingkan dengan beberapa episode. Menyadari pengumpulan data cukup sederhana: Anda mendapatkan tautan ke game dotabuff, mengunduh game, dan menggunakan pengurai permainan Dota 2 .
Bundel dengan klien game untuk pelatihan
Kami memiliki permainan Dota 2 yang kliennya ada di bawah platform Windows, Linux, dan macOS. Namun tetap saja, biasanya pelatihan berlangsung dalam semacam skrip python, dan di dalamnya Anda menciptakan lingkungan, apakah itu labirin, mesin memanjat bukit atau sesuatu seperti itu. Tetapi tidak ada lingkungan untuk Dota 2. Karena itu, saya sendiri harus membuat bungkus ini, yang secara teknis cukup menarik. Ternyata melakukannya seperti ini:
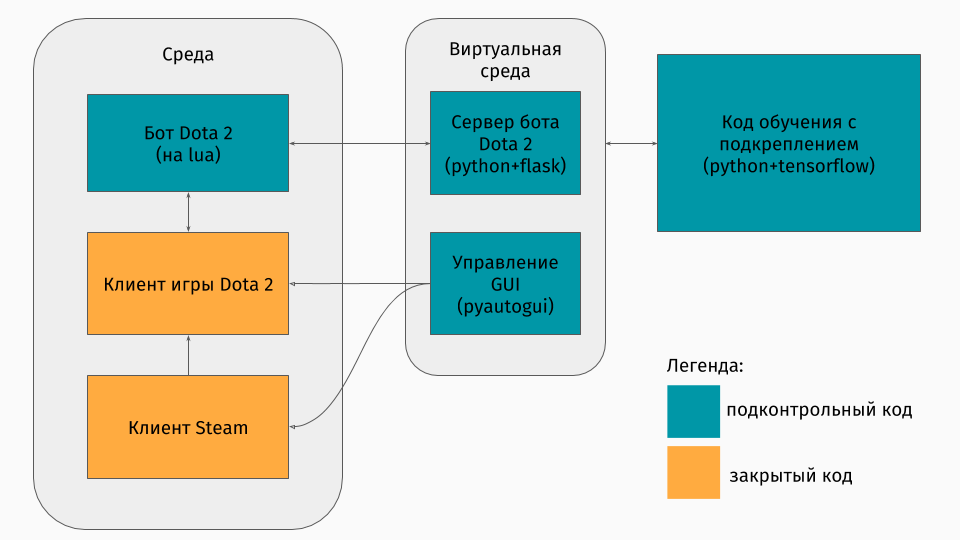
Bagian pertama adalah skrip untuk berkomunikasi dengan klien game. Untungnya, untuk Dota 2 ada API resmi untuk membuat bot: Dota Bot Scripting . Ini diimplementasikan sebagai sisipan dalam bahasa Lua, yang, ternyata, populer dalam pengembangan game. Skrip bot, berinteraksi dengan klien gim, menarik keluar pada waktu yang tepat informasi yang kami minati (misalnya, koordinat pada peta, posisi lawan) dan mengirimkan json dengannya ke server.
Bagian kedua adalah pembungkus itu sendiri. Ini dirancang sebagai server yang memproses semua logika peluncuran Steam, Dota, dan menerima json dari skrip di dalam gim. Manajemen peluncuran game dan klien diatur melalui pyautogui , dan komunikasi dengan lua-insert dalam game adalah melalui server Flask.
Bagian ketiga terdiri dari algoritma pembelajaran itu sendiri. Algoritma ini memilih tindakan, menerima status dan hadiah berikut dari server, di belakangnya semua komunikasi dengan game disembunyikan, dan meningkatkan perilakunya.
Belajar dari para ahli
Algoritme itu sendiri tidak terlalu penting dalam artikel ini, karena teknik ini dapat digunakan dengan algoritma apa pun. Kami menggunakan DQN (yang dapat Anda baca di hub ). Intinya, ini adalah jaringan syaraf yang dalam + algoritma Q-learning . Ya, ini persis DQN yang dibuat DeepMind untuk memainkan game Atari.
Lebih menarik untuk berbicara tentang cara menggunakan game sebelumnya. Saya mencoba dua pendekatan: pembentukan hadiah berbasis potensi dan saran tindakan.
Gagasan umum dari pendekatan tersebut adalah bahwa agen akan menerima hadiah tidak hanya untuk tujuan tugas (misalnya, di ujung labirin atau untuk mendaki gunung), tetapi juga selama pelatihan di setiap langkah. Hadiah tambahan ini akan menunjukkan seberapa baik agen bekerja untuk mencapai tujuan akhir. Tentu saja, saya ingin menanyakannya secara otomatis, dan tidak memilih aturan / ketentuan. Pendekatan berikut membantu mencapai ini.
Inti dari pembentukan hadiah berbasis potensi adalah bahwa beberapa negara pada awalnya bagi kami lebih menjanjikan daripada yang lain, dan berdasarkan ini kami memodifikasi imbalan nyata yang diterima algoritma. Kami melakukannya seperti ini: dimana - penghargaan yang dimodifikasi, - hadiahnya nyata, - Faktor diskon dari algoritma pembelajaran (tidak terlalu penting bagi kami), tetapi dan ada potensi kami untuk kondisi yang kami kunjungi selama . Contoh sederhana mengatasi labirin.
Misalkan ada labirin di mana kita ingin datang dari sel (0,0) ke dalam sel (5,5). Kemudian, potensi kita untuk keadaan (x, y) dapat dikurangi jarak Euclidean dari (x, y) ke target kita (5,5): . Artinya, semakin dekat kita ke garis finish, semakin besar potensi negara (misalnya, , , ) Jadi kami memotivasi agen dengan segala cara untuk mendekati tujuan.
Untuk Dota 2, idenya sama, tetapi potensinya sedikit lebih rumit:

Bayangkan kita hanya ingin melewati kondisi yang sama dengan demonstran. Kemudian semakin banyak status yang kita lewati, semakin tinggi potensinya. Kami menempatkan potensi negara dengan persentase penyelesaian replay, jika ada kondisi yang dekat dengan kita. Ini memiliki arti berbeda dalam berbagai tugas. Tetapi dalam Dota 2 inilah yang berarti bahwa pada awalnya kita ingin bot untuk mencapai pusat (setelah semua, pada awal demonstrasi hanya ada langkah-langkah ke pusat), dan kemudian keadaan pemain manusia dijaga (kesehatan besar, jarak aman ke lawan, dll. )
Metode kedua, saran tindakan, diambil dari artikel ini. Esensinya adalah bahwa sekarang kami menyarankan agen bukan kegunaan negara, tetapi kegunaan tindakan. Misalnya, dalam permainan Dota 2 kami mungkin ada saran seperti itu: jika ada antek musuh di dekat Anda, maka serang dia; jika Anda belum mencapai pusat, maka pergi ke arahnya; jika Anda kehilangan kesehatan, maka mundurlah ke menara Anda. Dan artikel ini menjelaskan metode untuk menentukan tips seperti itu tanpa dipikirkan oleh programmer sendiri - secara otomatis.
Potensi dihasilkan sesuai dengan prinsip ini: potensi tindakan bisa
meningkat dengan adanya kondisi terkait dengan sama
tindakan dalam demonstrasi. Penghargaan lebih lanjut untuk tindakan dalam diagram di atas
bervariasi seperti .
Perlu dicatat di sini bahwa kita telah menetapkan potensi untuk tindakan di negara bagian.
Hasil
Untuk mulai dengan, saya perhatikan bahwa tujuan permainan itu sedikit disederhanakan, karena saya mengajarkan semuanya di laptop saya. Tujuan agen adalah untuk menimbulkan serangan sebanyak mungkin, yang tampaknya seperti target nyata dalam beberapa perkiraan. Untuk melakukan ini, pertama-tama Anda harus pergi ke tengah peta dan kemudian menyerang lawan, berusaha untuk tidak mati. Untuk mempercepat pembelajaran, hanya beberapa (1 hingga 3) demonstrasi berdurasi dua menit yang saya rekam.
Melatih agen menggunakan salah satu pendekatan hanya membutuhkan 20 jam pada komputer pribadi (sebagian besar waktu yang dibutuhkan untuk membuat game Dota 2), dan menilai dengan grafik OpenAI, pelatihan pada server mereka membutuhkan beberapa minggu.
Eksposur singkat dari permainan saat menggunakan pendekatan pembentukan hadiah berbasis potensi:
Dan untuk pendekatan saran tindakan:
Catatan ini dibuat pada kecepatan pelatihan x10. Ketidakakuratan dalam perilaku agen ketika pindah ke pusat masih terlihat, tetapi masih perjuangan di pusat menunjukkan manuver yang dipelajari. Misalnya, mundur dalam kesehatan rendah.
Anda juga dapat melihat perbedaan dalam pendekatan: dengan pembentukan hadiah berbasis potensi, agen bergerak dengan lancar, karena “Berjalan dengan potensi”; dengan saran tindakan, bot bermain lebih agresif di tengah, karena menerima petunjuk tentang serangan itu.
Ringkasan
Saya segera mencatat bahwa beberapa poin sengaja dihilangkan: algoritma apa sebenarnya, bagaimana negara diwakili, dan apakah mungkin untuk melatih agen untuk bermain dengan pemain sungguhan, dll.
Pertama-tama, dalam artikel ini saya ingin menunjukkan bahwa dalam kasus pelatihan yang diperkuat, Anda tidak selalu harus memilih antara lingkungan yang sangat sederhana (melarikan diri dari labirin) atau biaya pelatihan yang sangat tinggi (menurut perhitungan sepintas saya, OpenAI membebankan biaya server tersebut untuk pelatihan Azure $ 4715 per jam). Ada teknik yang dapat mempercepat pembelajaran, dan saya hanya berbicara tentang satu di antaranya - penggunaan demonstrasi. Penting untuk dicatat bahwa dengan cara ini Anda tidak hanya mengulangi demonstran, tetapi hanya "mendorong" darinya. Adalah penting bahwa dengan pelatihan lebih lanjut agen memiliki kesempatan untuk melampaui para ahli.
Jika Anda tertarik dengan perinciannya, maka kode proses pelatihan dapat ditemukan di GitHub .