
Tugas utama layanan komersial (dan non-komersial juga) adalah untuk selalu tersedia bagi pengguna. Meskipun semua orang crash, pertanyaannya adalah apa yang tim TI lakukan untuk meminimalkan mereka. Kami menerjemahkan sebuah artikel oleh Ben Treynor, Mike Dahlin, Vivek Rau dan Betsy Beyer "Penghitungan keandalan layanan", yang memberitahu, termasuk, misalnya, Google, mengapa 100% adalah titik referensi yang salah untuk indikator keandalan, apa "aturan empat sembilan" dan bagaimana, dalam praktiknya, secara matematis memperkirakan kelayakan pemadaman besar dan kecil dari layanan dan / atau komponen kritisnya - jumlah waktu henti yang diharapkan, waktu yang dibutuhkan untuk mendeteksi kegagalan, dan waktu untuk memulihkan layanan.
Perhitungan keandalan layanan
Sistem Anda dapat diandalkan seperti komponennya
Ben Trainor, Mike Dalin, Vivec Rau, Betsy Beyer
Sebagaimana dijelaskan dalam buku " Rekayasa Keandalan Situs: Keandalan dan Keandalan seperti di Google " (selanjutnya disebut sebagai buku SRE), pengembangan produk dan layanan Google dapat mencapai kecepatan tinggi pelepasan fungsi baru, sambil mempertahankan SLO yang agresif (sasaran tingkat layanan, sasaran tingkat layanan) ) untuk memastikan keandalan yang tinggi dan respons yang cepat. SLO mengharuskan layanan hampir selalu dalam kondisi baik dan hampir selalu cepat. Selain itu, SLO juga menunjukkan nilai tepat "hampir selalu" ini untuk layanan tertentu. SLO didasarkan pada pengamatan berikut:
Dalam kasus umum, untuk layanan atau sistem perangkat lunak apa pun 100% adalah titik referensi yang salah untuk indikator keandalan, karena tidak ada pengguna yang dapat melihat perbedaan antara ketersediaan 100% dan 99,999%. Antara pengguna dan layanan ada banyak sistem lain (laptop-nya, Wi-Fi rumah, penyedia, catu daya ...), dan semua sistem ini secara agregat tidak tersedia dalam 99,999% kasus, tetapi jauh lebih jarang. Oleh karena itu, perbedaan antara 99,999% dan 100% hilang karena faktor acak yang disebabkan oleh tidak dapat diaksesnya sistem lain, dan pengguna tidak mendapatkan manfaat dari kenyataan bahwa kami menghabiskan banyak upaya dalam mencapai fraksi terakhir ini dari persentase ketersediaan sistem. Pengecualian serius terhadap aturan ini adalah rem dan alat pacu jantung anti-lock!
Untuk diskusi terperinci tentang bagaimana SLO terkait dengan SLI (indikator tingkat layanan) dan SLA (perjanjian tingkat layanan), lihat bab SRE Target Level of Service. Bab ini juga menjelaskan secara rinci cara memilih metrik yang relevan untuk layanan atau sistem tertentu, yang pada gilirannya menentukan pilihan SLO yang sesuai untuk layanan atau sistem itu.
Artikel ini memperluas topik SLO untuk fokus pada komponen layanan. Secara khusus, kami akan memeriksa bagaimana keandalan komponen kritis mempengaruhi keandalan layanan, dan bagaimana merancang sistem untuk mengurangi dampak atau mengurangi jumlah komponen penting.
Sebagian besar layanan yang ditawarkan oleh Google ditujukan untuk menyediakan 99,99 persen (kadang-kadang disebut "empat sembilan") aksesibilitas bagi pengguna. Untuk beberapa layanan, angka yang lebih rendah ditunjukkan dalam perjanjian pengguna, namun, target 99,99% disimpan di dalam perusahaan. Bilah yang lebih tinggi ini memberikan keuntungan dalam situasi di mana pengguna mengeluh tentang kinerja layanan jauh sebelum pelanggaran ketentuan perjanjian, karena tujuan nomor 1 dari tim SRE adalah untuk membuat pengguna senang dengan layanan. Untuk banyak layanan, tujuan internal 99,99% mewakili jalan tengah, yang menyeimbangkan biaya, kompleksitas dan keandalan. Untuk beberapa orang lain, khususnya layanan cloud global, target internal adalah 99,999%.
Reliabilitas 99,99%: pengamatan dan kesimpulan
Mari kita lihat beberapa pengamatan utama dan kesimpulan tentang desain dan operasi layanan dengan keandalan 99,99%, dan kemudian beralih ke praktik.
Pengamatan # 1: Penyebab Kegagalan
Kegagalan terjadi karena dua alasan utama: masalah dengan layanan itu sendiri dan masalah dengan komponen penting dari layanan. Komponen kritis adalah komponen yang, jika terjadi kegagalan, menyebabkan kegagalan terkait dalam pengoperasian seluruh layanan.
Pengamatan No. 2: Matematika Keandalan
Keandalan bergantung pada frekuensi dan durasi waktu henti. Itu diukur melalui:
- Frekuensi menganggur, atau kebalikannya: MTTF (waktu rata-rata gagal).
- Downtime, MTTR (berarti waktu untuk memperbaiki). Waktu henti ditentukan oleh waktu pengguna: dari awal kerusakan ke dimulainya kembali operasi normal dari layanan.
Dengan demikian, keandalan secara matematis didefinisikan sebagai MTTF / (MTTF + MTTR) menggunakan unit yang sesuai.
Kesimpulan # 1: Aturan Extra Nines
Suatu layanan tidak dapat lebih dapat diandalkan daripada semua komponen penting yang digabungkan. Jika layanan Anda berusaha untuk memastikan ketersediaan pada tingkat 99,99%, maka semua komponen penting harus tersedia secara signifikan lebih dari 99,99% dari waktu.
Di dalam Google, kami menggunakan aturan praktis berikut: komponen penting harus menyediakan sembilan tambahan dibandingkan dengan keandalan layanan Anda yang diklaim - dalam contoh di atas, ketersediaan 99,999 persen - karena layanan apa pun akan memiliki beberapa komponen penting, serta masalah spesifiknya sendiri. Ini disebut "aturan sembilan tambahan."
Jika Anda memiliki komponen penting yang tidak menyediakan cukup sembilan (masalah yang relatif umum!), Anda harus meminimalkan konsekuensi negatif.
Kesimpulan No. 2: Matematika frekuensi, waktu deteksi dan waktu pemulihan
Suatu layanan tidak dapat lebih dapat diandalkan daripada produk dari frekuensi insiden dan waktu deteksi dan pemulihan. Sebagai contoh, tiga total shutdown per tahun selama 20 menit masing-masing menyebabkan total 60 menit downtime. Bahkan jika layanan ini bekerja dengan baik sepanjang tahun, keandalan 99,99 persen (tidak lebih dari 53 menit downtime per tahun) tidak akan mungkin.
Ini adalah pengamatan matematis yang sederhana, tetapi seringkali diabaikan.
Kesimpulan dari kesimpulan No. 1 dan No. 2
Jika tingkat keandalan yang diandalkan layanan Anda tidak dapat dicapai, upaya harus dilakukan untuk memperbaiki situasi - baik dengan meningkatkan ketersediaan layanan, atau dengan meminimalkan konsekuensi negatif, seperti dijelaskan di atas. Menurunkan harapan (mis., Menyatakan keandalan) juga merupakan opsi, dan seringkali yang paling benar: memperjelas kepada layanan yang bergantung pada Anda bahwa ia harus membangun kembali sistemnya untuk mengkompensasi kesalahan dalam keandalan layanan Anda, atau mengurangi sasaran tingkat layanannya sendiri . Jika Anda sendiri tidak menghilangkan kesenjangan, kegagalan sistem yang cukup lama pasti akan membutuhkan penyesuaian.
Aplikasi praktis
Mari kita lihat contoh layanan dengan target keandalan 99,99% dan mencari tahu persyaratan untuk kedua komponennya dan bekerja dengan kegagalannya.
Tokoh
Misalkan layanan 99,99 persen Anda tersedia dengan karakteristik berikut:
- Satu pemadaman besar dan tiga pemadaman kecil per tahun. Kedengarannya menakutkan, tetapi perhatikan bahwa tingkat kepercayaan 99,99% menyiratkan satu downtime skala besar 20-30 menit dan beberapa shutdown parsial pendek per tahun. (Matematika menunjukkan bahwa: a) kegagalan satu segmen tidak dianggap sebagai kegagalan seluruh sistem dari sudut pandang SLO, dan b) total keandalan dihitung dengan jumlah keandalan segmen.)
- Lima komponen penting dalam bentuk layanan independen lainnya dengan keandalan 99,999%.
- Lima segmen independen yang tidak dapat gagal satu demi satu.
- Semua perubahan dilakukan secara bertahap, satu segmen pada satu waktu.
Perhitungan matematika reliabilitas adalah sebagai berikut:
Persyaratan Komponen
- Batas kesalahan total untuk tahun ini adalah 0,01 persen dari 525.600 menit per tahun, atau 53 menit (berdasarkan tahun 365 hari, dalam skenario terburuk).
- Batas yang dialokasikan untuk penutupan komponen kritis adalah lima komponen kritis independen dengan batas masing-masing 0,001% = 0,005%; 0,005% dari 525.600 menit per tahun, atau 26 menit.
- Batas kesalahan yang tersisa dari layanan Anda adalah 53-26 = 27 menit.
Persyaratan Respons Shutdown
- Downtime yang diharapkan: 4 (1 shutdown penuh dan 3 shutdown hanya memengaruhi satu segmen)
- Efek kumulatif dari pemadaman yang diharapkan: (1 × 100%) + (3 × 20%) = 1,6
- Deteksi dan pemulihan kegagalan setelahnya: 27 / 1,6 = 17 menit
- Waktu yang dialokasikan untuk pemantauan untuk mendeteksi kegagalan dan memberitahukannya: 2 menit
- Waktu yang diberikan kepada spesialis yang bertugas untuk mulai menganalisis peringatan: 5 menit. (Sistem pemantauan harus melacak pelanggaran SLO dan mengirim sinyal ke pager yang bertugas setiap kali sistem crash. Banyak layanan Google didukung oleh teknisi shift shift yang bertugas yang menjawab pertanyaan mendesak.)
- Sisa waktu untuk secara efektif meminimalkan efek buruk: 10 menit
Kesimpulan: leverage untuk meningkatkan keandalan layanan
Penting untuk secara cermat melihat angka-angka yang disajikan, karena mereka menekankan poin mendasar: ada tiga tuas utama untuk meningkatkan keandalan layanan.
- Mengurangi frekuensi pemadaman - melalui kebijakan rilis, pengujian, evaluasi berkala dari struktur proyek, dll.
- Kurangi waktu henti rata-rata Anda dengan segmentasi, isolasi geografis, degradasi bertahap, atau isolasi pelanggan.
- Kurangi waktu pemulihan - dengan pemantauan, operasi penyelamatan satu tombol (misalnya, memutar kembali ke keadaan sebelumnya atau menambah daya siaga), praktik kesiapan operasional, dll.
Anda dapat menyeimbangkan antara ketiga metode ini untuk menyederhanakan penerapan toleransi kesalahan. Misalnya, jika sulit untuk mencapai MTTR 17 menit, fokuslah untuk mengurangi downtime rata-rata. Strategi untuk meminimalkan efek buruk dan memitigasi efek komponen penting dibahas secara lebih rinci nanti dalam artikel ini.
Klarifikasi "Aturan untuk tambahan sembilan" untuk komponen bersarang
Pembaca acak dapat menyimpulkan bahwa setiap tautan tambahan dalam rantai ketergantungan memerlukan sembilan tambahan, jadi dua sembilan tambahan diperlukan untuk dependensi urutan kedua, tiga tambahan sembilan diperlukan untuk dependensi urutan ketiga, dll.
Ini kesimpulan yang salah. Ini didasarkan pada model naif dari hierarki komponen dalam bentuk pohon dengan percabangan konstan di setiap tingkat. Dalam model seperti itu, seperti yang ditunjukkan pada Gambar. 1, ada 10 komponen orde pertama yang unik, 100 komponen orde kedua yang unik, 1.000 komponen orde ketiga yang unik, dll., Menghasilkan total 1.111 layanan unik, bahkan jika arsitektur dibatasi hingga empat lapisan. Ekosistem layanan yang sangat andal dengan begitu banyak komponen kritis independen jelas tidak realistis.
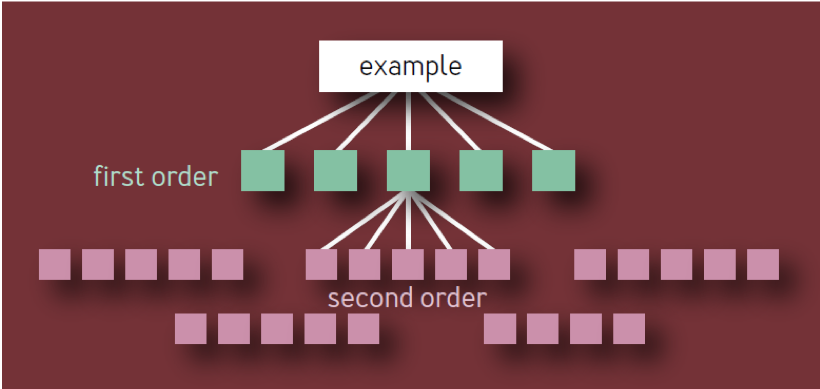
Fig. 1 - Hierarki Komponen: Model Tidak Valid
Komponen kritis itu sendiri dapat menyebabkan kegagalan seluruh layanan (atau segmen layanan), terlepas dari di mana ia berada di pohon dependensi. Oleh karena itu, jika komponen X tertentu ditampilkan sebagai ketergantungan dari beberapa komponen orde pertama, X harus dihitung hanya sekali, karena kegagalannya pada akhirnya akan menyebabkan kegagalan layanan terlepas dari berapa banyak layanan perantara juga terpengaruh.
Pembacaan aturan yang benar adalah sebagai berikut:
- Jika suatu layanan memiliki N komponen kritis yang unik, maka masing-masing dari mereka memberikan kontribusi 1 / N terhadap tidak dapat diandalkannya seluruh layanan yang disebabkan oleh komponen ini, tidak peduli seberapa rendahnya itu dalam hirarki komponen.
- Setiap komponen harus dihitung hanya sekali, bahkan jika itu muncul beberapa kali dalam hirarki komponen (dengan kata lain, hanya komponen unik yang dihitung). Misalnya, ketika menghitung komponen Layanan A pada Gambar. 2, Layanan B harus dipertimbangkan hanya sekali.
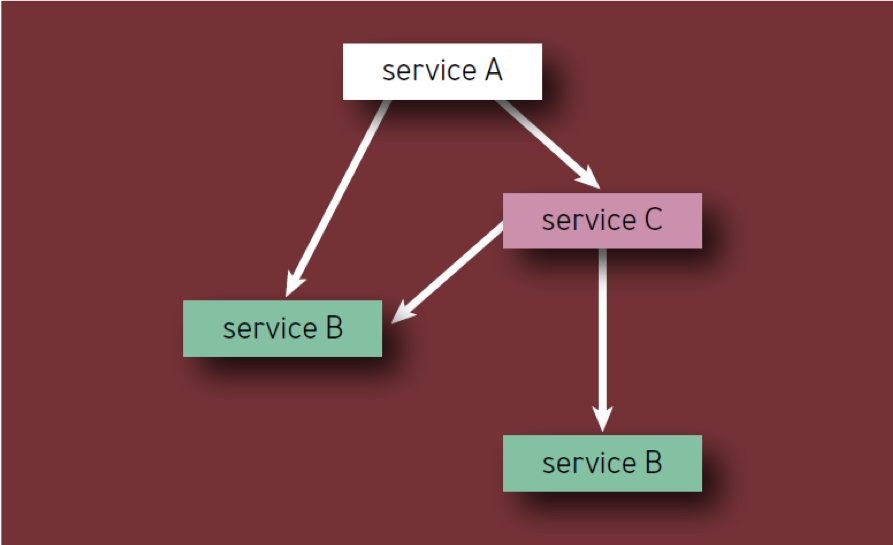
Fig. 2 - Komponen dalam hierarki
Misalnya, pertimbangkan layanan hipotetis A dengan batas kesalahan 0,01 persen. Pemilik layanan siap untuk menghabiskan setengah dari batas ini untuk kesalahan dan kerugian mereka sendiri, dan setengahnya untuk komponen penting. Jika layanan memiliki N komponen seperti itu, maka masing-masing dari mereka menerima 1 / N dari batas kesalahan yang tersisa. Layanan tipikal seringkali memiliki 5 hingga 10 komponen penting, dan oleh karena itu masing-masing hanya dapat menolak sepersepuluh atau satu dari batas kesalahan Layanan A. Oleh karena itu, sebagai suatu peraturan, bagian-bagian penting dari layanan harus memiliki sembilan keandalan tambahan.
Batas kesalahan
Konsep batas kesalahan tercakup dalam beberapa detail dalam buku SRE, tetapi di sini harus disebutkan. Insinyur Google SR menggunakan batas kesalahan untuk menyeimbangkan keandalan dan kecepatan pembaruan. Batas ini menentukan tingkat kegagalan layanan yang dapat diterima untuk periode waktu tertentu (biasanya sebulan). Batas kesalahan hanya 1 minus SLO dari layanan, sehingga layanan yang tersedia yang dibahas sebelumnya 99,99 persen memiliki "batas" 0,01% pada tidak dapat diandalkan. Sampai layanan telah menggunakan batas kesalahannya dalam sebulan, tim pengembang bebas (layaknya) untuk meluncurkan fungsi baru, pembaruan, dll.
Jika batas kesalahan habis, perubahan pada layanan ditangguhkan (kecuali untuk perbaikan keamanan yang mendesak dan perubahan yang bertujuan menyebabkan pelanggaran di tempat pertama) sampai layanan mengisi cadangan di batas kesalahan atau sampai bulan berubah. Banyak layanan di Google menggunakan metode sliding window untuk SLO sehingga batas kesalahan dikembalikan secara bertahap. Untuk layanan serius dengan SLO lebih dari 99,99%, disarankan untuk menggunakan reset triwulanan daripada nol bulanan, karena jumlah downtime yang diijinkan kecil.
Batas kesalahan menghilangkan ketegangan antara departemen yang mungkin timbul antara insinyur SR dan pengembang produk, memberi mereka alat penilaian risiko umum berbasis data untuk meluncurkan produk. Mereka juga memberi para insinyur SR dan tim pengembangan tujuan bersama untuk mengembangkan metode dan teknologi yang akan memungkinkan mereka untuk berinovasi lebih cepat dan meluncurkan produk tanpa "anggaran besar".
Strategi Pengurangan Komponen dan Strategi Mitigasi
Pada titik ini, dalam artikel ini, kami telah menetapkan apa yang bisa disebut "Aturan Emas untuk Keandalan Komponen . " Ini berarti bahwa keandalan dari setiap komponen kritis harus 10 kali lebih tinggi dari tingkat target keandalan seluruh sistem sehingga kontribusinya terhadap tidak dapat diandalkannya sistem tetap pada tingkat kesalahan. Oleh karena itu, dalam kasus ideal, tugasnya adalah membuat komponen sebanyak mungkin tanpa kritik. Ini berarti bahwa komponen dapat mematuhi tingkat keandalan yang lebih rendah, memberikan pengembang kesempatan untuk berinovasi dan mengambil risiko.
Strategi paling sederhana dan paling jelas untuk mengurangi ketergantungan kritis adalah untuk menghilangkan titik kegagalan tunggal bila memungkinkan. Sistem yang lebih besar harus dapat beroperasi dengan dapat diterima tanpa komponen yang diberikan yang tidak ketergantungan kritis atau SPOF.
Bahkan, Anda kemungkinan besar tidak dapat menghilangkan semua ketergantungan kritis; tetapi Anda dapat mengikuti beberapa pedoman desain sistem untuk mengoptimalkan keandalan. Walaupun ini tidak selalu memungkinkan, lebih mudah dan lebih efisien untuk mencapai keandalan sistem yang tinggi jika Anda meletakkan keandalan pada tahap desain dan perencanaan, dan tidak setelah sistem bekerja dan memengaruhi pengguna yang sebenarnya.
Penilaian struktur proyek
Ketika merencanakan sistem atau layanan baru, atau ketika mendesain ulang atau meningkatkan sistem atau layanan yang ada, tinjauan arsitektur atau proyek dapat mengungkapkan infrastruktur umum, serta dependensi internal dan eksternal.
Infrastruktur bersama
Jika layanan Anda menggunakan infrastruktur bersama (misalnya, layanan database utama yang digunakan oleh beberapa produk yang tersedia untuk pengguna), pertimbangkan apakah infrastruktur ini digunakan dengan benar. Identifikasi dengan jelas pemilik infrastruktur bersama sebagai peserta proyek tambahan. Juga, waspadalah terhadap kelebihan komponen - untuk melakukan ini, koordinasikan proses startup dengan hati-hati dengan pemilik komponen ini.
Ketergantungan internal dan eksternal
Terkadang suatu produk atau layanan tergantung pada faktor-faktor di luar kendali perusahaan Anda - misalnya, dari perpustakaan perangkat lunak atau layanan dan data dari pihak ketiga. Identifikasi faktor-faktor ini akan meminimalkan konsekuensi penggunaannya yang tidak terduga.
Rencanakan dan rancang sistem dengan cermat
Saat merancang sistem Anda, perhatikan prinsip-prinsip berikut:
Redundansi dan isolasi
Anda dapat mencoba mengurangi dampak komponen kritis dengan membuat beberapa contoh independennya. Misalnya, jika menyimpan data dalam satu contoh menyediakan 99,9 persen aksesibilitas data ini, menyimpan tiga salinan dalam tiga contoh yang tersebar luas akan, secara teori, tingkat ketersediaan 1 - 0,013 atau sembilan kali sembilan jika kegagalan sebuah instance independen pada nol korelasi.
Di dunia nyata, korelasinya tidak pernah nol (pertimbangkan kegagalan jaringan tulang punggung yang memengaruhi banyak sel secara bersamaan), sehingga keandalan yang sebenarnya tidak akan pernah mendekati sembilan sembilan, tetapi akan jauh melebihi tiga sembilan.
Demikian juga, mengirim RPC (panggilan prosedur jarak jauh) ke satu kumpulan server dalam satu cluster dapat memberikan 99 persen ketersediaan hasil, sementara mengirim tiga RPC bersamaan ke tiga kumpulan server yang berbeda dan menerima respons pertama akan membantu mencapai tingkat ketersediaan lebih tinggi dari tiga sembilan (lihat di atas). Strategi ini juga dapat mempersingkat ekor penundaan waktu respons jika kumpulan server berjarak sama dari pengirim RPC. (Karena biaya pengiriman tiga RPC pada saat yang sama tinggi, Google sering secara strategis mengalokasikan waktu untuk panggilan ini: sebagian besar sistem kami mengharapkan sebagian dari waktu yang diberikan sebelum mengirim RPC kedua dan sedikit lebih banyak waktu sebelum mengirim RPC ketiga.)
Cadangan dan aplikasinya
Atur peluncuran dan porting perangkat lunak sehingga sistem terus bekerja ketika setiap bagian gagal (gagal aman) dan mengisolasi diri ketika terjadi masalah. Prinsip dasar di sini adalah bahwa pada saat Anda menghubungkan orang tersebut untuk menghidupkan cadangan, Anda kemungkinan akan melebihi batas kesalahan Anda.
Sinkronisasi
Agar komponen tidak kritis, rancang asynchronous sedapat mungkin. Jika suatu layanan mengharapkan respons RPC dari salah satu bagiannya yang tidak kritis, yang menunjukkan perlambatan tajam dalam waktu respons, perlambatan ini secara tidak perlu akan menurunkan kinerja layanan induk. Menyetel RPC untuk komponen yang tidak penting ke mode asinkron akan membebaskan waktu respons dari layanan induk agar tidak terikat dengan kinerja komponen ini. Dan meskipun asinkron dapat menyulitkan kode dan infrastruktur layanan, kompromi ini tetap sepadan.
Perencanaan sumber daya
Pastikan semua komponen dilengkapi dengan semua yang Anda butuhkan. , — .
, \ .
, . . . , .
SLO. , , . , , , MTTR .
, . :
, , , . :
, : , , . — , . , , , .
, . , Google , 10 .
Kesimpulan
, , , , . , . Google , , (. SRE, B: ).