Sedikit lebih dari setahun dengan partisipasi saya, "dialog" berikut ini terjadi:
Aplikasi .Net : Hey Entity Framework, mohon beri saya banyak data!
Kerangka Entitas : Maaf, saya tidak mengerti Anda. Apa maksudmu
Aplikasi Net : Ya, saya baru saja mendapat koleksi 100 ribu transaksi. Dan sekarang kita perlu dengan cepat memeriksa kebenaran harga sekuritas yang ditunjukkan di sana.
Kerangka Entitas : Ahh, well, mari kita coba ...
Aplikasi .Net : Berikut ini kodenya:
var query = from p in context.Prices join t in transactions on new { p.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; query.ToList();
Kerangka Entitas :

Klasik Saya pikir banyak orang yang akrab dengan situasi ini: ketika saya benar-benar ingin "cantik" dan cepat melakukan pencarian di database menggunakan GABUNG koleksi lokal dan DbSet . Biasanya pengalaman ini mengecewakan.
Dalam artikel ini (yang merupakan terjemahan bebas dari artikel saya yang lain ) saya akan melakukan serangkaian percobaan dan mencoba berbagai cara untuk mengatasi batasan ini. Akan ada kode (tidak rumit), pikiran dan sesuatu seperti akhir yang bahagia.
Pendahuluan
Semua orang tahu tentang Entity Framework , banyak yang menggunakannya setiap hari, dan ada banyak artikel bagus tentang cara memasaknya dengan benar (gunakan kueri yang lebih sederhana, gunakan parameter di Lewati dan Ambil, gunakan VIEW, minta hanya bidang yang diperlukan, pantau caching permintaan dan lainnya), namun, tema GABUNG dari koleksi lokal dan DbSet masih merupakan titik lemah.
Tantangan
Misalkan ada database dengan harga dan ada koleksi transaksi yang Anda perlu memeriksa kebenaran harga. Dan anggaplah kita memiliki kode berikut.
var localData = GetDataFromApiOrUser(); var query = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId join t in localData on new { s.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; var result = query.ToList();
Kode ini tidak berfungsi di Entity Framework 6 sama sekali. Dalam Entity Framework Core - ini berfungsi, tetapi semuanya akan dilakukan di sisi klien dan dalam kasus ketika ada jutaan catatan dalam database - ini bukan pilihan.
Seperti yang saya katakan, saya akan mencoba berbagai cara untuk mengatasi ini. Dari yang sederhana hingga yang kompleks. Untuk percobaan saya, saya menggunakan kode dari repositori berikut. Kode ini ditulis menggunakan: C # , .Net Core , EF Core dan PostgreSQL .
Saya juga memotret beberapa metrik: waktu yang dihabiskan dan konsumsi memori. Penafian: jika tes dilakukan selama lebih dari 10 menit, saya memotongnya (batasannya dari atas). Mesin uji Intel Core i5, 8 GB RAM, SSD.
Skema DB
Hanya 3 tabel: harga , surat berharga , dan sumber harga . Harga - berisi 10 juta entri.
Metode 1. Naif
Mari mulai sederhana dan gunakan kode berikut:
Kode untuk metode 1 var result = new List<Price>(); using (var context = CreateContext()) { foreach (var testElement in TestData) { result.AddRange(context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId)); } }
Idenya sederhana: dalam satu lingkaran kita membaca catatan dari database satu per satu dan menambah koleksi yang dihasilkan. Kode ini hanya memiliki satu keunggulan - kesederhanaan. Dan satu kelemahan adalah kecepatan rendah: bahkan jika ada indeks dalam database, sebagian besar waktu akan mengambil komunikasi dengan server database. Metriknya adalah sebagai berikut:
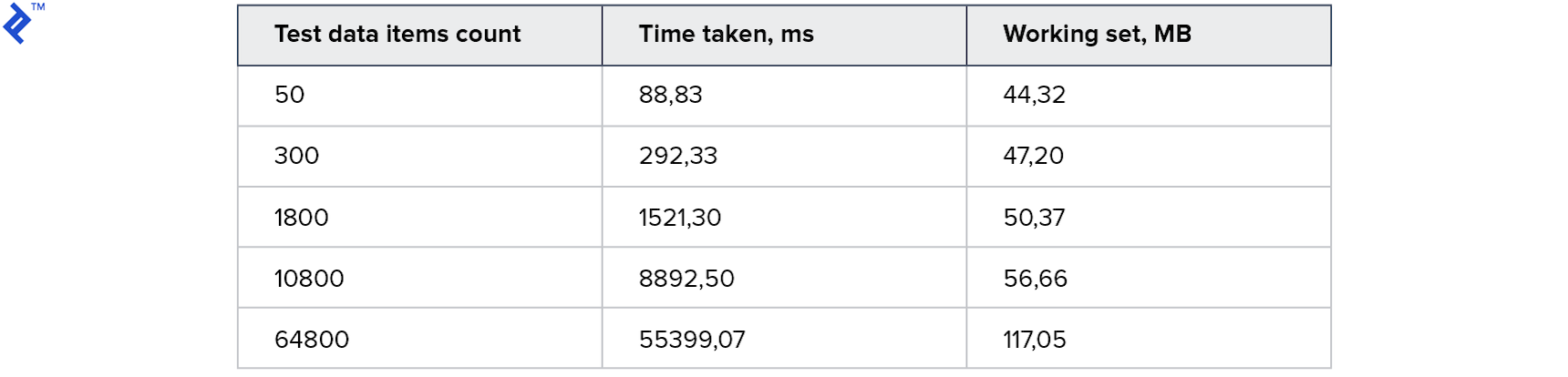
Konsumsi memori kecil. Koleksi besar membutuhkan waktu 1 menit. Sebagai permulaan, tidak buruk, tapi saya ingin lebih cepat.
Metode 2: Paralel naif
Mari kita coba tambahkan paralelisme. Idenya adalah untuk mengakses database dari banyak utas.
Kode untuk metode 2 var result = new ConcurrentBag<Price>(); var partitioner = Partitioner.Create(0, TestData.Count); Parallel.ForEach(partitioner, range => { var subList = TestData.Skip(range.Item1) .Take(range.Item2 - range.Item1) .ToList(); using (var context = CreateContext()) { foreach (var testElement in subList) { var query = context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId); foreach (var el in query) { result.Add(el); } } } });
Hasil:
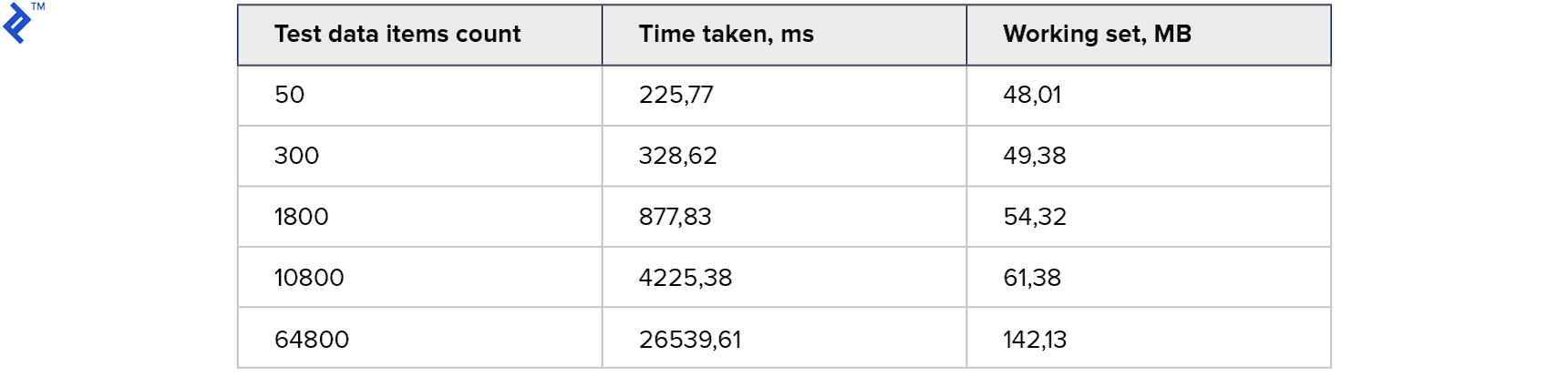
Untuk koleksi kecil, pendekatan ini bahkan lebih lambat dari metode pertama. Dan untuk yang terbesar - 2 kali lebih cepat. Menariknya, 4 utas dihasilkan di mesin saya, tetapi ini tidak menghasilkan akselerasi 4x. Ini menunjukkan bahwa overhead dalam metode ini signifikan: baik di sisi klien dan di sisi server. Konsumsi memori meningkat, tetapi tidak signifikan.
Metode 3: Berisi Banyak
Saatnya mencoba sesuatu yang lain dan mencoba mengurangi tugas menjadi satu kueri. Itu bisa dilakukan sebagai berikut:
- Siapkan 3 koleksi unik Ticker , PriceSourceId, dan Date
- Jalankan permintaan dan gunakan 3 Berisi
- Periksa kembali hasil secara lokal
Kode untuk metode 3 var result = new List<Price>(); using (var context = CreateContext()) {
Masalahnya di sini adalah bahwa waktu eksekusi dan jumlah data yang dikembalikan sangat tergantung pada data itu sendiri (baik dalam kueri dan dalam database). Artinya, satu set hanya data yang diperlukan yang dapat kembali, dan catatan tambahan dapat dikembalikan (bahkan 100 kali lebih banyak).
Ini dapat dijelaskan dengan menggunakan contoh berikut. Misalkan ada tabel berikut dengan data:

Misalkan saya membutuhkan harga untuk Ticker1 dengan TradedOn = 2018-01-01 dan untuk Ticker2 dengan TradedOn = 2018-01-02 .
Kemudian nilai unik untuk Ticker = ( Ticker1 , Ticker2 )
Dan nilai unik untuk TradedOn = ( 2018-01-01 , 2018-01-02 )
Namun, 4 catatan akan dikembalikan sebagai hasilnya, karena mereka benar-benar sesuai dengan kombinasi ini. Yang buruk adalah bahwa semakin banyak bidang yang digunakan, semakin besar peluang untuk mendapatkan catatan tambahan sebagai hasilnya.
Untuk alasan ini, data yang diperoleh dengan metode ini juga harus difilter di sisi klien. Dan ini adalah kelemahan terbesar.
Metriknya adalah sebagai berikut:
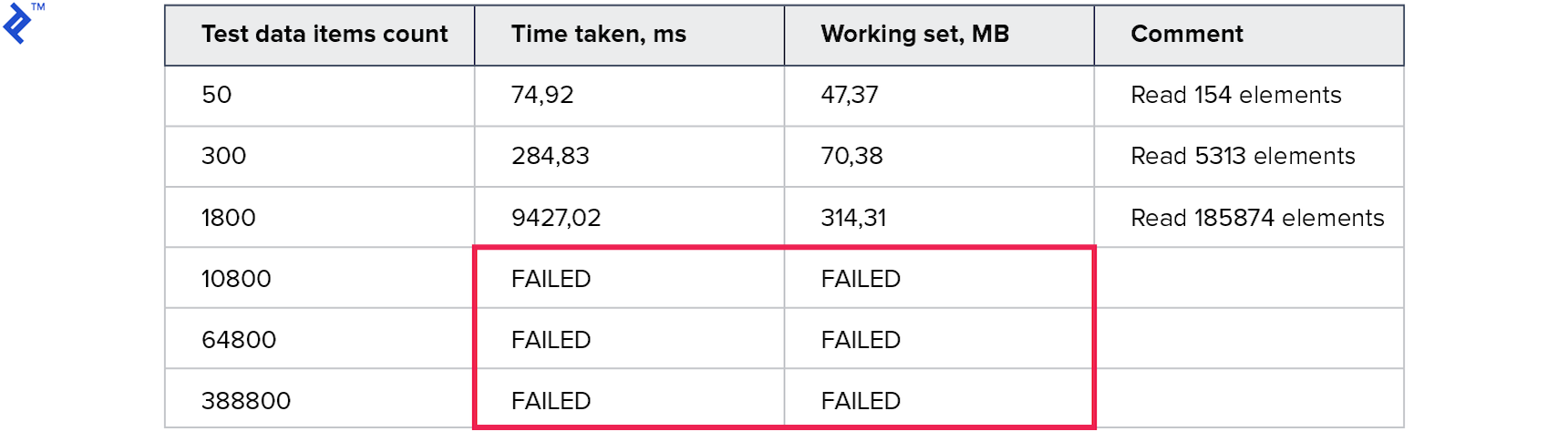
Konsumsi memori lebih buruk daripada semua metode sebelumnya. Jumlah baris yang dibaca jauh lebih besar dari jumlah yang diminta. Tes untuk koleksi besar terhenti karena mereka berjalan selama lebih dari 10 menit. Metode ini tidak baik.
Metode 4. Predicate builder
Mari kita coba di sisi lain: Ekspresi tua yang baik. Dengan menggunakannya, Anda dapat membuat 1 kueri besar dalam formulir berikut:
… (.. AND .. AND ..) OR (.. AND .. AND ..) OR (.. AND .. AND ..) …
Ini memberi harapan bahwa akan dimungkinkan untuk membangun 1 permintaan dan hanya mendapatkan data yang diperlukan untuk 1 panggilan. Kode:
Kode untuk metode 4 var result = new List<Price>(); using (var context = CreateContext()) { var baseQuery = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId select new TestData() { Ticker = s.Ticker, TradedOn = p.TradedOn, PriceSourceId = p.PriceSourceId, PriceObject = p }; var tradedOnProperty = typeof(TestData).GetProperty("TradedOn"); var priceSourceIdProperty = typeof(TestData).GetProperty("PriceSourceId"); var tickerProperty = typeof(TestData).GetProperty("Ticker"); var paramExpression = Expression.Parameter(typeof(TestData)); Expression wholeClause = null; foreach (var td in TestData) { var elementClause = Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, tradedOnProperty), Expression.Constant(td.TradedOn) ), Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, priceSourceIdProperty), Expression.Constant(td.PriceSourceId) ), Expression.Equal( Expression.MakeMemberAccess( paramExpression, tickerProperty), Expression.Constant(td.Ticker)) )); if (wholeClause == null) wholeClause = elementClause; else wholeClause = Expression.OrElse(wholeClause, elementClause); } var query = baseQuery.Where( (Expression<Func<TestData, bool>>)Expression.Lambda( wholeClause, paramExpression)).Select(x => x.PriceObject); result.AddRange(query); }
Kode tersebut ternyata lebih rumit daripada metode sebelumnya. Membangun Ekspresi secara manual bukanlah operasi yang termudah dan tercepat.
Metrik:
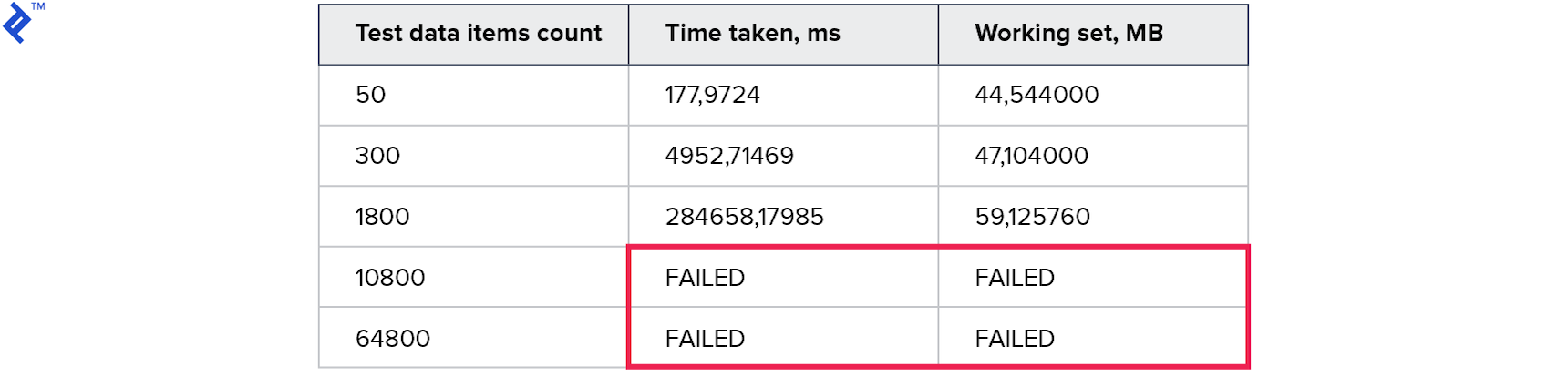
Hasil sementara bahkan lebih buruk daripada metode sebelumnya. Tampaknya overhead selama konstruksi dan ketika berjalan melalui pohon ternyata jauh lebih banyak daripada keuntungan menggunakan satu permintaan.
Metode 5: Tabel data kueri yang dibagikan
Mari kita coba opsi lain:
Saya membuat tabel baru dalam database di mana saya akan menulis data yang diperlukan untuk menyelesaikan permintaan (secara implisit saya memerlukan DbSet baru dalam konteks).
Sekarang, untuk mendapatkan hasil yang Anda butuhkan:
- Mulai transaksi
- Unggah data kueri ke tabel baru
- Jalankan kueri itu sendiri (menggunakan tabel baru)
- Kembalikan transaksi (untuk menghapus tabel data untuk kueri)
Kode ini terlihat seperti ini:
Kode untuk metode 5 var result = new List<Price>(); using (var context = CreateContext()) { context.Database.BeginTransaction(); var reducedData = TestData.Select(x => new SharedQueryModel() { PriceSourceId = x.PriceSourceId, Ticker = x.Ticker, TradedOn = x.TradedOn }).ToList();
Metrik pertama:
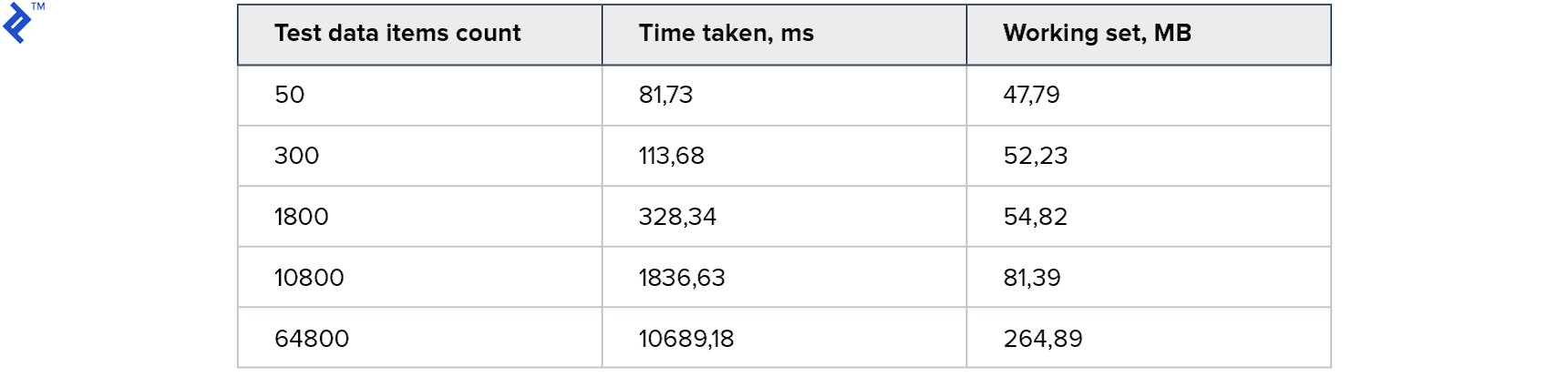
Semua tes bekerja dan bekerja dengan cepat! Konsumsi memori juga dapat diterima.
Dengan demikian, melalui penggunaan transaksi, tabel ini dapat digunakan secara bersamaan oleh beberapa proses. Dan karena ini adalah tabel nyata yang ada, semua fitur dari Entity Framework tersedia untuk kami: Anda hanya perlu memuat data ke dalam tabel, membangun kueri menggunakan GABUNG, dan jalankan. Pada pandangan pertama, inilah yang Anda butuhkan, tetapi ada kerugian signifikan:
- Anda harus membuat tabel untuk tipe kueri tertentu
- Penting untuk menggunakan transaksi (dan menyia-nyiakan sumber daya DBMS)
- Dan gagasan bahwa Anda perlu MENULIS sesuatu, ketika Anda perlu BACA, terlihat aneh. Dan pada Baca Replika, itu tidak akan berhasil.
Dan sisanya adalah solusi kerja yang lebih atau kurang yang sudah dapat digunakan.
Metode 6. Ekstensi MemoryJoin
Sekarang Anda dapat mencoba meningkatkan pendekatan sebelumnya. Pikirannya adalah:
- Alih-alih menggunakan tabel yang khusus untuk satu jenis kueri, Anda bisa menggunakan beberapa opsi umum. Yaitu, buat tabel dengan nama seperti shared_query_data , dan tambahkan beberapa bidang Guid , beberapa Long , beberapa String , dll ke dalamnya. Nama-nama sederhana dapat diambil: Guid1 , Guid2 , String1 , Long1 , Date2 , dll. Maka tabel ini dapat digunakan untuk 95% tipe kueri. Nama properti dapat "disesuaikan" nanti menggunakan perspektif Select .
- Selanjutnya Anda perlu menambahkan DbSet untuk shared_query_data .
- Tetapi bagaimana jika, alih-alih menulis data ke database, meneruskan nilai menggunakan konstruk VALUES ? Artinya, perlu bahwa dalam query SQL final, alih-alih mengakses shared_query_data, harus ada banding ke VALUES . Bagaimana cara melakukannya?
- Dalam Entity Framework Core - hanya menggunakan FromSql .
- Di Entity Framework 6 - Anda harus menggunakan DbInterception - yaitu, ubah SQL yang dihasilkan dengan menambahkan konstruksi VALUES tepat sebelum eksekusi. Ini akan menghasilkan batasan: dalam satu permintaan, tidak lebih dari satu konstruksi NILAI . Tapi itu akan berhasil!
- Karena kita tidak akan menulis ke database, maka kita mendapatkan tabel shared_query_data yang dibuat pada langkah pertama, apakah itu tidak diperlukan sama sekali? Jawab: ya, tidak diperlukan, tetapi DbSet masih diperlukan, karena Kerangka Entitas harus mengetahui skema data untuk membangun kueri. Ternyata kita membutuhkan DbSet untuk beberapa model umum yang tidak ada dalam database dan hanya digunakan untuk menginspirasi Kerangka Entitas, yang mengetahui apa yang dilakukannya.
Konversi IEnumerable ke Contoh IQueryable- Input menerima koleksi objek dari tipe berikut:
class SomeQueryData { public string Ticker {get; set;} public DateTimeTradedOn {get; set;} public int PriceSourceId {get; set;} }
- Kami memiliki DbSet yang kami miliki dengan bidang String1 , String2 , Date1 , Long1 , dll
- Biarkan Ticker disimpan di String1 , TradedOn di Date1 , dan PriceSourceId di Long1 ( int mapps in long , agar tidak membuat bidang untuk int dan terpisah lama )
- Maka FromSql + VALUES akan seperti ini:
var query = context.QuerySharedData.FromSql( "SELECT * FROM ( VALUES (1, 'Ticker1', @date1, @id1), (2, 'Ticker2', @date2, @id2) ) AS __gen_query_data__ (id, string1, date1, long1)")
- Sekarang Anda dapat membuat proyeksi dan mengembalikan IQueryable nyaman menggunakan jenis yang sama pada input:
return query.Select(x => new SomeQueryData() { Ticker = x.String1, TradedOn = x.Date1, PriceSourceId = (int)x.Long1 });
Saya berhasil menerapkan pendekatan ini dan bahkan mendesainnya sebagai paket NuGet EntityFrameworkCore.MemoryJoin ( kode ini juga tersedia). Terlepas dari kenyataan bahwa nama tersebut mengandung kata Core , Entity Framework 6 juga didukung. Saya menyebutnya MemoryJoin , tetapi sebenarnya ia mengirimkan data lokal ke DBMS dalam konstruksi VALUES dan semua pekerjaan dilakukan di sana.
Kode tersebut adalah sebagai berikut:
Kode untuk metode 6 var result = new List<Price>(); using (var context = CreateContext()) {
Metrik:
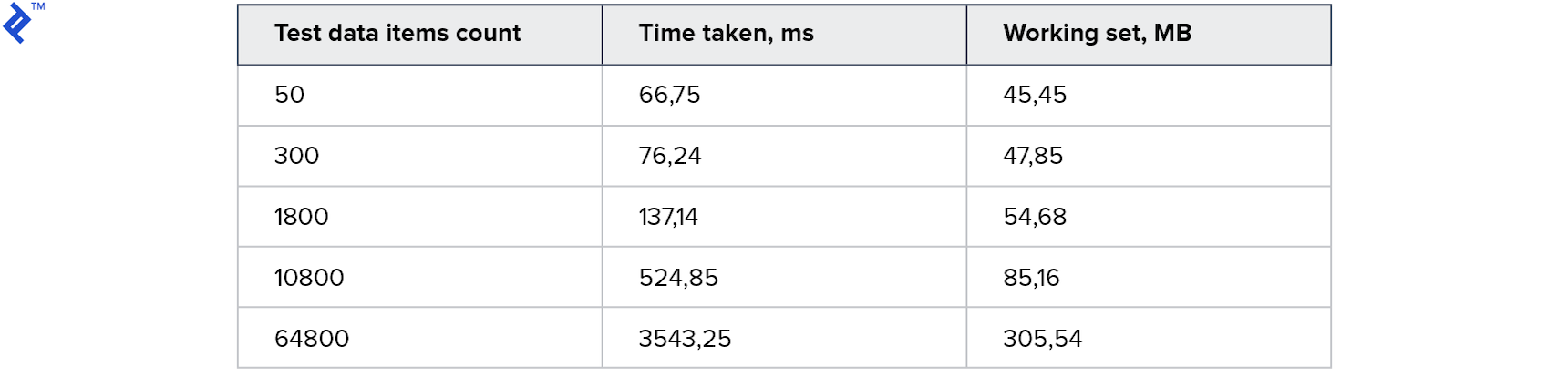
Ini adalah hasil terbaik yang pernah saya coba. Kode ini sangat sederhana dan mudah, dan pada saat yang sama berfungsi untuk Baca Replika.
Contoh permintaan yang dihasilkan untuk menerima 3 elemen SELECT "p"."PriceId", "p"."ClosePrice", "p"."OpenPrice", "p"."PriceSourceId", "p"."SecurityId", "p"."TradedOn", "t"."Ticker", "t"."TradedOn", "t"."PriceSourceId" FROM "Price" AS "p" INNER JOIN "Security" AS "s" ON "p"."SecurityId" = "s"."SecurityId" INNER JOIN ( SELECT "x"."string1" AS "Ticker", "x"."date1" AS "TradedOn", CAST("x"."long1" AS int4) AS "PriceSourceId" FROM ( SELECT * FROM ( VALUES (1, @__gen_q_p0, @__gen_q_p1, @__gen_q_p2), (2, @__gen_q_p3, @__gen_q_p4, @__gen_q_p5), (3, @__gen_q_p6, @__gen_q_p7, @__gen_q_p8) ) AS __gen_query_data__ (id, string1, date1, long1) ) AS "x" ) AS "t" ON (("s"."Ticker" = "t"."Ticker") AND ("p"."PriceSourceId" = "t"."PriceSourceId")
Di sini Anda juga dapat melihat bagaimana model umum (dengan bidang String1 , Date1 , Long1 ) menggunakan Pilih berubah menjadi salah satu yang digunakan dalam kode (dengan bidang Ticker , TradedOn , PriceSourceId ).
Semua pekerjaan dilakukan dalam 1 kueri di server SQL. Dan ini adalah akhir yang kecil, yang saya bicarakan di awal. Meskipun demikian, penggunaan metode ini membutuhkan pemahaman dan langkah-langkah berikut:
- Anda perlu menambahkan DbSet tambahan ke konteks Anda (meskipun tabel itu sendiri dapat dihilangkan )
- Dalam model umum, yang digunakan secara default, 3 bidang tipe Guid , String , Double , Long , Date , dll dideklarasikan. Itu harus cukup untuk 95% jenis permintaan. Dan jika Anda meneruskan koleksi objek dengan 20 bidang ke FromLocalList , Pengecualian akan dilempar, mengatakan bahwa objek itu terlalu kompleks. Ini adalah batasan lunak dan dapat dielakkan - Anda dapat mendeklarasikan tipe Anda dan menambahkan setidaknya 100 bidang di sana. Namun, lebih banyak bidang lebih lambat untuk berfungsi.
- Rincian teknis lainnya dijelaskan dalam artikel saya.
Kesimpulan
Dalam artikel ini, saya mempresentasikan pemikiran saya tentang topik GABUNGAN koleksi lokal dan DbSet. Tampaknya bagi saya bahwa pengembangan saya menggunakan VALUES mungkin menarik bagi masyarakat. Setidaknya saya tidak menemui pendekatan seperti itu ketika saya memecahkan masalah ini sendiri. Secara pribadi, metode ini membantu saya untuk mengatasi sejumlah masalah kinerja dalam proyek saya saat ini, mungkin itu akan membantu Anda juga.
Seseorang akan mengatakan bahwa penggunaan MemoryJoin terlalu "musykil" dan perlu dikembangkan lebih lanjut, dan sampai saat itu tidak boleh digunakan. Inilah alasan mengapa saya sangat ragu dan selama hampir satu tahun saya tidak menulis artikel ini. Saya setuju bahwa saya ingin bekerja lebih mudah (saya berharap suatu hari nanti akan), tetapi saya juga mengatakan bahwa optimasi tidak pernah menjadi tugas Juniors. Optimalisasi selalu membutuhkan pemahaman tentang cara alat bekerja. Dan jika ada kesempatan untuk mendapatkan akselerasi hingga ~ 8 kali ( Naive Parallel vs MemoryJoin ), maka saya akan menguasai 2 poin dan dokumentasi.
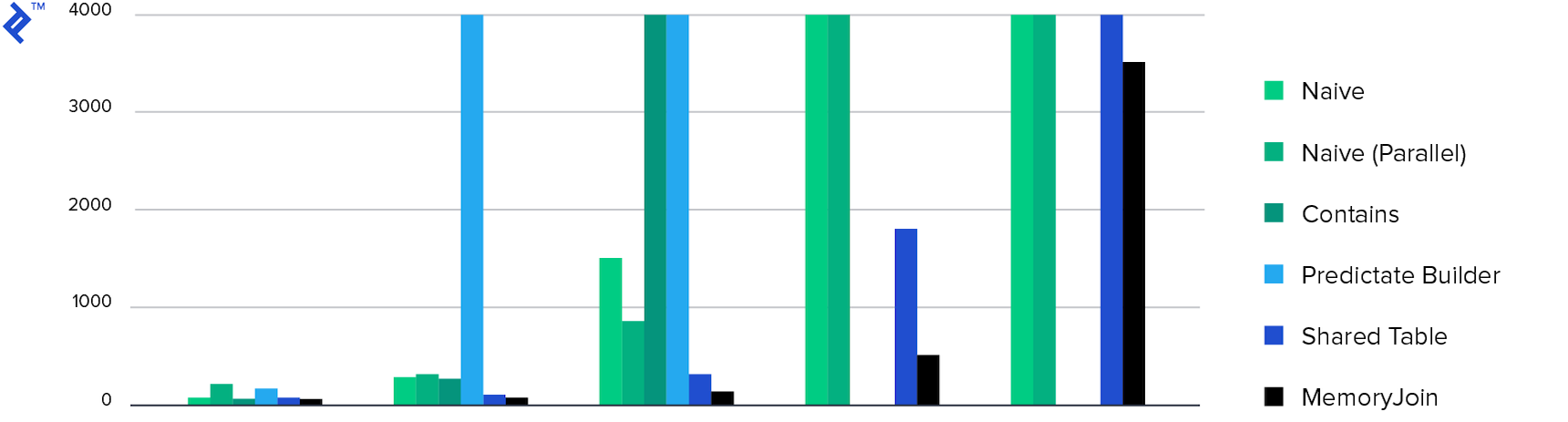
Dan akhirnya, diagram:
Waktu yang dihabiskan. Hanya 4 metode menyelesaikan tugas dalam waktu kurang dari 10 menit, dan MemoryJoin adalah satu-satunya cara yang menyelesaikan tugas dalam waktu kurang dari 10 detik.
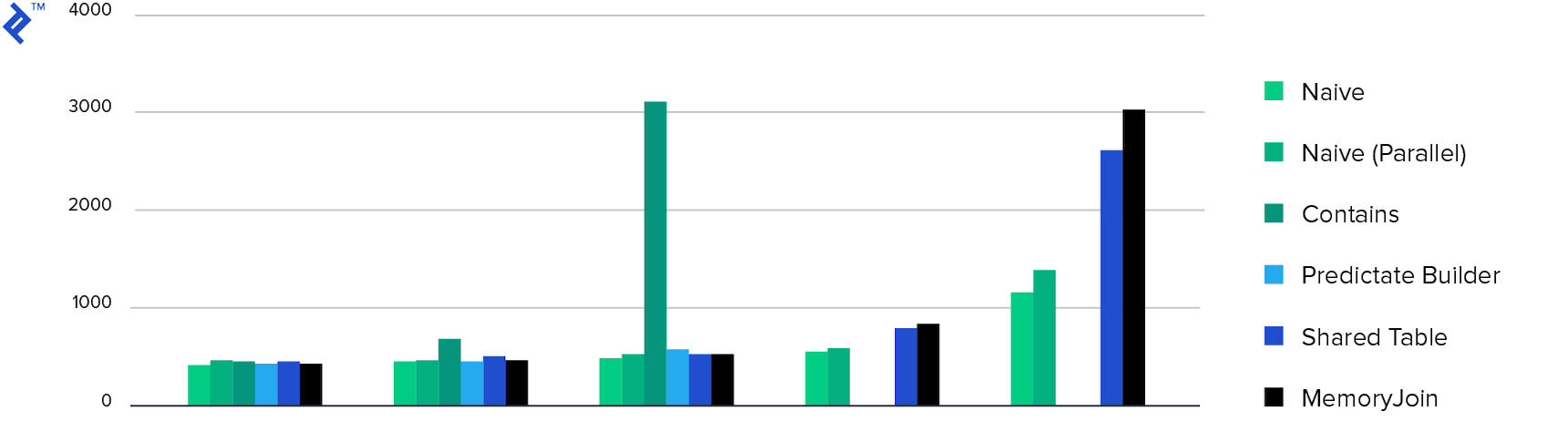
Konsumsi memori. Semua metode menunjukkan konsumsi memori yang kira-kira sama, kecuali untuk Multiple Contains . Ini karena jumlah data yang dikembalikan.
Terima kasih sudah membaca!