 Klasifikasi teks
Klasifikasi teks adalah salah satu tugas paling umum dalam pelatihan
NLP dan guru, ketika dataset berisi dokumen teks dan label digunakan untuk melatih classifier teks.
Dari sudut pandang NLP, tugas mengklasifikasikan teks dilakukan dengan mengajar representasi di tingkat kata menggunakan embedding kata dan kemudian melatih representasi di tingkat teks yang digunakan sebagai fungsi untuk klasifikasi.
Jenis metode berbasis pengkodean mengabaikan detail kecil dan kunci untuk klasifikasi (karena representasi umum pada level teks dipelajari dengan mengompresi representasi pada level kata).
 Metode pengkodean berbasis untuk mengklasifikasikan teks dengan pencocokan tingkat teks
Metode pengkodean berbasis untuk mengklasifikasikan teks dengan pencocokan tingkat teksUJIAN - Metode Klasifikasi Teks Baru
Para peneliti dari Universitas Shandong dan Universitas Nasional Singapura telah
mengusulkan model klasifikasi teks baru yang mencakup sinyal pencocokan tingkat kata dalam tugas klasifikasi teks. Metode mereka menggunakan mekanisme interaksi untuk memperkenalkan petunjuk terperinci di tingkat kata ke dalam proses klasifikasi.
Untuk mengatasi masalah termasuk sinyal pencocokan tingkat kata yang lebih akurat, para peneliti mengusulkan
secara eksplisit menghitung perkiraan korespondensi antara kata dan kelas .
Gagasan utamanya adalah untuk menghitung matriks interaksi dari representasi tingkat kata yang akan membawa kunci yang sesuai di tingkat kata. Setiap entri dalam matriks ini adalah penilaian korespondensi antara kata dan kelas tertentu.
Struktur klasifikasi teks yang diusulkan disebut EXAM - EXplicit interAction Model (
GitHub ), berisi tiga komponen utama:
- encoder tingkat kata,
- lapisan interaksi dan
- lapisan agregasi.
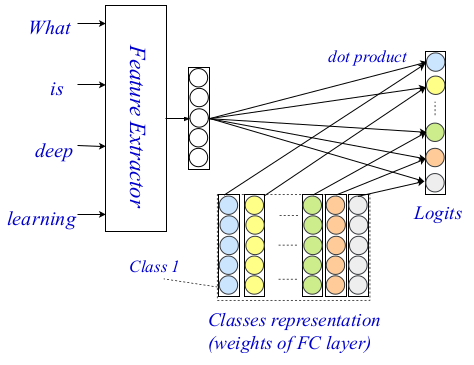
Arsitektur tiga tingkat ini memungkinkan Anda untuk menyandikan dan mengklasifikasikan teks menggunakan sinyal dan petunjuk kecil dan umum. Seluruh arsitektur ditunjukkan pada gambar di bawah ini.
 Arsitektur UJIAN
Arsitektur UJIANDi masa lalu, kata-level encoders telah diteliti secara luas di komunitas NLP, dan encoders yang sangat kuat telah muncul. Para penulis menggunakan metode sovermenny sebagai encoder di tingkat kata, dan dalam karya mereka mereka menggambarkan secara rinci dua komponen lain dari arsitektur mereka: tingkat interaksi dan agregasi.
Lapisan interaksi, kontribusi utama dan kebaruan dalam metode yang diusulkan didasarkan pada mekanisme interaksi yang terkenal. Peneliti menggunakan
matriks presentasi terlatih untuk menyandikan masing-masing kelas sehingga mereka nantinya dapat menghitung perkiraan interaksi antara kelas. Skor akhir ditempelkan menggunakan produk titik sebagai fungsi interaksi antara kata target dan setiap kelas. Fungsi yang lebih kompleks tidak dipertimbangkan karena meningkatnya kompleksitas perhitungan.
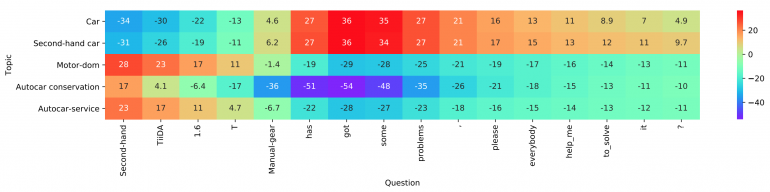 Visualisasi lapisan
Visualisasi lapisanAkhirnya, mereka menggunakan MLP dua lapisan yang sederhana, sepenuhnya terhubung sebagai lapisan agregasi. Mereka juga menyebutkan bahwa tingkat agregasi yang lebih kompleks, termasuk CNN atau LSTM, dapat digunakan di sini. MLP digunakan untuk menghitung log klasifikasi akhir menggunakan matriks interaksi dan pengkodean tingkat kata. Cross entropy digunakan sebagai fungsi kerugian untuk optimasi.
Kelas
Untuk mengevaluasi kerangka yang diusulkan untuk klasifikasi teks, para peneliti melakukan percobaan ekstensif dalam kondisi multi-kelas dan multi-tag. Mereka menunjukkan bahwa metode mereka jauh lebih unggul daripada metode modern yang relevan modern.
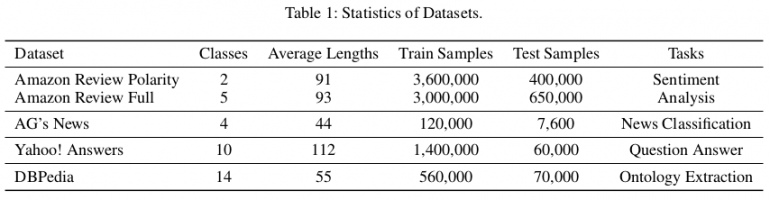 Statistik dataset yang digunakan untuk evaluasi
Statistik dataset yang digunakan untuk evaluasiUntuk evaluasi, mereka menetapkan tiga jenis model dasar yang berbeda:
- Model didasarkan pada pengembangan atribut;
- Model berbasis karakter yang mendalam
- Model berbasis kata yang mendalam.
Para penulis menggunakan dataset referensi yang tersedia untuk umum (Zhang, Zhao, dan LeCun 2015) untuk mengevaluasi metode yang diusulkan. Secara total, ada enam set data teks klasifikasi yang sesuai dengan tugas menganalisis suasana hati, mengklasifikasikan berita, pertanyaan dan jawaban, dan mengekstraksi ontologi, masing-masing. Dalam artikel tersebut, mereka menunjukkan bahwa EXAM mencapai kinerja terbaik di antara tiga set data: AG, Yah. A. dan DBP. Evaluasi dan perbandingan dengan metode lain dapat dilihat pada tabel di bawah ini.
![Test Set Accuracy [%] pada tugas klasifikasi dokumen multi-kelas dan perbandingan dengan metode lain](https://habrastorage.org/getpro/habr/post_images/de7/8d8/b60/de78d8b6017c9624c347b0fb645ae0ae.png)

Kesimpulan
Karya ini merupakan kontribusi penting untuk bidang pemrosesan bahasa alami (NLP). Ini adalah karya pertama yang memperkenalkan petunjuk pencocokan tingkat kata yang lebih akurat ke dalam klasifikasi teks dalam model jaringan saraf yang dalam. Model yang diusulkan memberikan indikator canggih untuk beberapa set data.
Terjemahan - Stanislav Litvinov