TL; DR: GitHub: // PastorGL / AQLSelectEx .
Sekali, bukan di musim dingin, tetapi sudah di musim dingin, dan khususnya beberapa bulan yang lalu, untuk proyek yang sedang saya kerjakan (sesuatu yang berbasis Geospasial berdasarkan Big Data), saya membutuhkan penyimpanan NoSQL / Nilai-Kunci yang cepat.
Kami mengunyah terabyte kode sumber dengan bantuan Apache Spark, tetapi hasil akhir perhitungan, runtuh ke jumlah yang konyol (hanya jutaan catatan), perlu disimpan di suatu tempat. Dan sangat diinginkan untuk menyimpan sedemikian rupa sehingga dapat dengan cepat ditemukan dan dikirim menggunakan metadata yang terkait dengan setiap baris hasil (ini adalah satu digit) (tetapi ada cukup banyak dari mereka).
Format tumpukan Khadupov dalam hal ini tidak banyak berguna, dan database relasional pada jutaan catatan melambat, dan set metadata tidak begitu tetap sehingga cocok dengan skema kaku dari RDBMS - PostgreSQL biasa dalam kasus kami. Tidak, ini biasanya mendukung JSON, tetapi masih memiliki masalah dengan indeks pada jutaan rekaman. Indeks membengkak, menjadi perlu untuk mempartisi tabel, dan kerepotan dengan administrasi dimulai nafig-nafig.
Secara historis, MongoDB digunakan sebagai NoSQL pada proyek, tetapi seiring berjalannya waktu, monga menunjukkan dirinya semakin buruk (terutama dalam hal stabilitas), sehingga secara bertahap dinonaktifkan. Pencarian cepat untuk alternatif yang lebih modern, lebih cepat, kurang buggy, dan umumnya lebih baik mengarah ke Aerospike . Banyak pria berkepala besar mendukungnya, dan saya memutuskan untuk memeriksanya.
Tes menunjukkan bahwa, pada kenyataannya, data disimpan dalam cerita langsung dari pekerjaan Spark dengan peluit, dan pencarian dalam jutaan catatan jauh lebih cepat daripada di mong. Dan dia makan lebih sedikit memori. Tapi ternyata satu "tetapi." API klien solder aero murni fungsional, dan tidak bersifat deklaratif.
Untuk merekam dalam cerita, ini tidak penting, karena semua sama, semua jenis bidang dari setiap catatan yang dihasilkan harus ditentukan secara lokal dalam pekerjaan itu sendiri - dan konteksnya tidak hilang. Gaya fungsional ada di sini, terutama karena menulis kode dengan cara yang berbeda tidak akan berhasil. Tetapi dalam moncong web, yang seharusnya mengunggah hasilnya ke dunia luar, dan merupakan aplikasi web semi biasa, akan jauh lebih logis untuk membentuk SQL SELECT standar dari formulir pengguna, yang akan penuh dengan DAN dan ATAU - yaitu predikat , - dalam klausa WHERE.
Saya akan menjelaskan perbedaannya dengan contoh sintetis:
SELECT foo, bar, baz, qux, quux FROM namespace.set WITH (baz!='a') WHERE (foo>2 AND (bar<=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)
- mudah dibaca dan relatif jelas catatan mana yang ingin diterima pelanggan. Jika Anda memasukkan permintaan seperti itu ke dalam log secara langsung, maka Anda dapat menariknya nanti untuk debugging secara manual. Yang sangat nyaman saat mengurai segala macam situasi aneh.
Sekarang mari kita lihat panggilan ke API predikat dengan gaya fungsional:
Statement reference = new Statement(); reference.setSetName("set"); reference.setNamespace("namespace"); reference.setBinNames("foo", "bar", "baz", "qux", "quux"); reference.setFillter(Filter.stringNotEqual("baz", "a")); reference.setPredExp(
Inilah dinding kode, dan bahkan dalam notasi Polandia terbalik . Tidak, saya mengerti bahwa mesin stack sederhana dan nyaman untuk implementasi dari sudut pandang programmer dari mesin itu sendiri, tetapi untuk puzzle dan menulis predikat di RPN dari aplikasi klien ... Saya pribadi tidak ingin memikirkan vendor, saya ingin saya sebagai konsumen API ini Itu nyaman. Dan predikat bahkan dengan ekstensi klien vendor (secara konsep mirip dengan Java Persistence Kriteria API) tidak nyaman untuk ditulis. Dan masih tidak ada SELECT yang dapat dibaca di log kueri.
Secara umum, SQL diciptakan untuk menulis pertanyaan berbasis kriteria di dalamnya dalam bahasa burung, dekat dengan alam. Jadi, orang bertanya-tanya, apa-apaan ini?
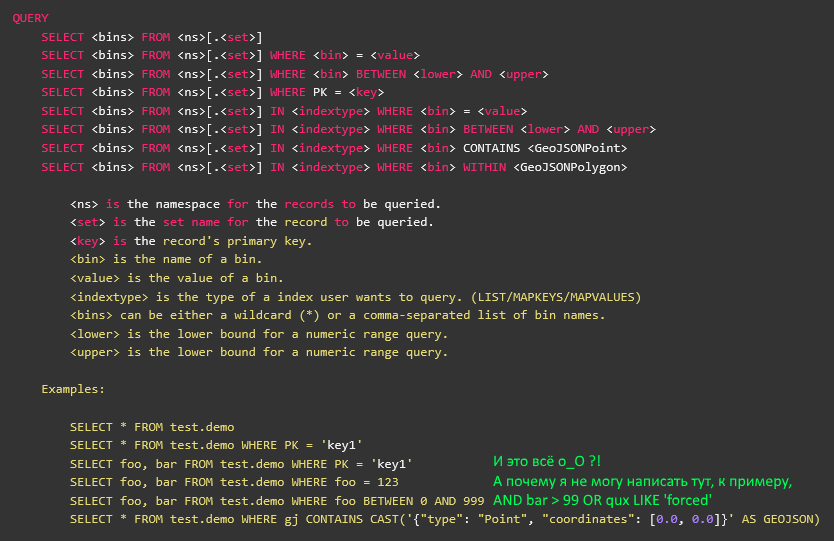
Tunggu, ada sesuatu yang tidak beres ... Pada KDPV, apakah ada tangkapan layar dari dokumentasi resmi aerosoldering, di mana SELECT dijelaskan sepenuhnya?
Ya, dijelaskan. Itu hanya AQL - ini adalah utilitas pihak ketiga yang ditulis oleh kaki kiri belakang pada malam yang gelap, dan ditinggalkan oleh vendor tiga tahun lalu selama versi aerosoldering sebelumnya. Ini tidak ada hubungannya dengan pustaka klien, meskipun ditulis pada katak - termasuk.
Versi tiga tahun lalu tidak memiliki predikat API, dan karenanya di AQL tidak ada dukungan untuk predikat, dan semua yang setelah WHERE sebenarnya adalah panggilan ke indeks (sekunder atau primer). Yaitu, lebih dekat ke ekstensi SQL seperti USE atau WITH. Artinya, Anda tidak bisa hanya mengambil sumber AQL, membongkar mereka menjadi suku cadang, dan menggunakannya dalam aplikasi Anda untuk panggilan predikat.
Selain itu, seperti yang saya katakan, itu ditulis pada malam gelap dengan kaki kiri belakang, dan tidak mungkin untuk melihat tata bahasa ANTLR4 yang AQL mem-parsing permintaan tanpa air mata. Ya, untuk seleraku. Untuk beberapa alasan, saya suka ketika definisi tata bahasa deklaratif tidak dicampur dengan potongan-potongan kode katak, dan mie yang sangat keren diseduh di sana.
Yah, untungnya, saya juga sepertinya tahu bagaimana melakukan ANTLR. Benar, untuk waktu yang lama saya tidak mengambil checker, dan terakhir kali saya menulisnya di bawah versi ketiga. Keempat - itu jauh lebih baik, karena yang ingin menulis tur AST manual, jika semuanya ditulis sebelum kita, dan ada pengunjung normal, jadi mari kita mulai.
Kami menggunakan sintaks SQLite sebagai basis, dan mencoba membuang semua yang tidak perlu. Kami hanya membutuhkan SELECT, dan tidak lebih.
grammar SQLite; simple_select_stmt : ( K_WITH K_RECURSIVE? common_table_expression ( ',' common_table_expression )* )? select_core ( K_ORDER K_BY ordering_term ( ',' ordering_term )* )? ( K_LIMIT expr ( ( K_OFFSET | ',' ) expr )? )? ; select_core : K_SELECT ( K_DISTINCT | K_ALL )? result_column ( ',' result_column )* ( K_FROM ( table_or_subquery ( ',' table_or_subquery )* | join_clause ) )? ( K_WHERE expr )? ( K_GROUP K_BY expr ( ',' expr )* ( K_HAVING expr )? )? | K_VALUES '(' expr ( ',' expr )* ')' ( ',' '(' expr ( ',' expr )* ')' )* ; expr : literal_value | BIND_PARAMETER | ( ( database_name '.' )? table_name '.' )? column_name | unary_operator expr | expr '||' expr | expr ( '*' | '/' | '%' ) expr | expr ( '+' | '-' ) expr | expr ( '<<' | '>>' | '&' | '|' ) expr | expr ( '<' | '<=' | '>' | '>=' ) expr | expr ( '=' | '==' | '!=' | '<>' | K_IS | K_IS K_NOT | K_IN | K_LIKE | K_GLOB | K_MATCH | K_REGEXP ) expr | expr K_AND expr | expr K_OR expr | function_name '(' ( K_DISTINCT? expr ( ',' expr )* | '*' )? ')' | '(' expr ')' | K_CAST '(' expr K_AS type_name ')' | expr K_COLLATE collation_name | expr K_NOT? ( K_LIKE | K_GLOB | K_REGEXP | K_MATCH ) expr ( K_ESCAPE expr )? | expr ( K_ISNULL | K_NOTNULL | K_NOT K_NULL ) | expr K_IS K_NOT? expr | expr K_NOT? K_BETWEEN expr K_AND expr | expr K_NOT? K_IN ( '(' ( select_stmt | expr ( ',' expr )* )? ')' | ( database_name '.' )? table_name ) | ( ( K_NOT )? K_EXISTS )? '(' select_stmt ')' | K_CASE expr? ( K_WHEN expr K_THEN expr )+ ( K_ELSE expr )? K_END | raise_function ;
Hmm ... Terlalu banyak untuk SELECT. Dan jika cukup mudah untuk menyingkirkan kelebihan, maka ada satu hal buruk lagi mengenai struktur solusi yang dihasilkan.
Tujuan utamanya adalah untuk menerjemahkan ke dalam predikat API dengan RPN dan mesin stack tersirat. Dan di sini expr atom tidak berkontribusi pada transformasi semacam itu dengan cara apa pun, karena itu menyiratkan analisis normal dari kiri ke kanan. Ya, dan didefinisikan secara rekursif.
Yaitu, kita bisa mendapatkan contoh sintetis kami, tetapi itu akan dibaca persis seperti yang tertulis, dari kiri ke kanan:
(foo>2 (bar<=3 foo>5) quux _ '%force%') (qux _('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}')
Ada tanda kurung yang menentukan prioritas parsing (yang berarti bahwa Anda perlu menjuntai bolak-balik di stack), dan juga beberapa operator berperilaku seperti panggilan fungsi.
Dan kita perlu urutan ini:
foo 2 > bar 3 <= foo 5 > quux ".*force.*" _ qux "{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}" _
Brr, timah, otak yang buruk untuk membaca. Tetapi tanpa tanda kurung, tidak ada kemunduran dan kesalahpahaman dengan urutan panggilan. Dan bagaimana kita menerjemahkan satu ke yang lain?
Dan kemudian di otak yang buruk, terjadi choc! - Halo, ini adalah Shunting Yard klasik dari banyak orang. prof. Dijkstra! Biasanya, dukun okolobigdatovskimi seperti saya tidak perlu algoritma, karena kami hanya mentransfer prototipe yang sudah ditulis oleh data-satanis dari python ke katak, dan kemudian untuk kinerja solusi yang lama dan membosankan yang diperoleh dengan metode rekayasa murni (== shamanistic), dan tidak ilmiah .
Tapi kemudian tiba-tiba menjadi perlu untuk mengetahui algoritma. Atau setidaknya gagasan tentang itu. Untungnya, tidak seluruh program universitas telah dilupakan selama beberapa tahun terakhir, dan karena saya ingat tentang mesin yang ditumpuk, saya juga dapat menggali sesuatu yang lain tentang algoritma terkait.
Baiklah Dalam tata bahasa yang dipertajam oleh Shunting Yard, SELECT di tingkat atas akan terlihat seperti ini:
select_stmt : K_SELECT ( STAR | column_name ( COMMA column_name )* ) ( K_FROM from_set )? ( (K_USE | K_WITH) index_expr )? ( K_WHERE where_expr )? ; where_expr : ( atomic_expr | OPEN_PAR | CLOSE_PAR | logic_op )+ ; logic_op : K_NOT | K_AND | K_OR ; atomic_expr : column_name ( equality_op | regex_op ) STRING_LITERAL | ( column_name | meta_name ) ( equality_op | comparison_op ) NUMERIC_LITERAL | column_name map_op iter_expr | column_name list_op iter_expr | column_name geo_op cast_expr ;
Artinya, token yang sesuai dengan tanda kurung adalah signifikan, dan seharusnya tidak ada expr rekursif. Sebaliknya, akan ada banyak private_expr, dan semuanya terbatas.
Dalam kode pada katak, yang mengimplementasikan pengunjung untuk pohon ini, semuanya sedikit lebih membuat ketagihan - sesuai ketat dengan algoritma, yang dengan sendirinya memproses logika_op yang menggantung dan menyeimbangkan kurung. Saya tidak akan memberikan kutipan ( lihat sendiri GC ), tetapi saya akan memberikan pertimbangan berikut.
Menjadi jelas mengapa penulis aero spike tidak repot-repot dengan dukungan predikat di AQL, dan meninggalkannya tiga tahun lalu. Karena diketik dengan ketat, dan aero spike itu sendiri disajikan sebagai cerita tanpa skema. Jadi tidak mungkin untuk mengambil dan mengeluarkan kueri dari SQL kosong tanpa skema yang telah ditentukan. Ups
Tapi kita semua hangus, dan yang paling penting, sombong. Kami membutuhkan skema dengan tipe bidang, sehingga akan ada skema dengan tipe bidang. Selain itu, perpustakaan klien sudah memiliki semua definisi yang diperlukan, mereka hanya perlu diambil. Meskipun saya harus menulis banyak kode untuk setiap jenis (lihat tautan yang sama, dari baris 56).
Sekarang inisialisasi ...
final HashMap FOO_BAR_BAZ = new HashMap() {{ put("namespace.set0", new HashMap() {{ put("foo", ParticleType.INTEGER); put("bar", ParticleType.DOUBLE); put("baz", ParticleType.STRING); put("qux", ParticleType.GEOJSON); put("quux", ParticleType.STRING); put("quuux", ParticleType.LIST); put("corge", ParticleType.MAP); put("corge.uier", ParticleType.INTEGER); }}); put("namespace.set1", new HashMap() {{ put("grault", ParticleType.INTEGER); put("garply", ParticleType.STRING); }}); }}; AQLSelectEx selectEx = AQLSelectEx.forSchema(FOO_BAR_BAZ);
... dan voila, sekarang permintaan sintetis kami dengan sederhana dan jelas tersentak dari aerosoldering:
Statement statement = selectEx.fromString("SELECT foo,bar,baz,qux,quux FROM namespace.set WITH (baz='a') WHERE (foo>2 AND (bar <=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)");
Dan untuk mengonversi formulir dari moncong web ke permintaan itu sendiri, kami mengambil satu ton kode yang telah lama ditulis di moncong web ... ketika akhirnya sampai ke proyek, jika tidak pelanggan telah meletakkannya di rak untuk saat ini. Sayang sekali, sial, aku menghabiskan waktu hampir seminggu.
Saya harap saya menghabiskannya dengan manfaat, dan perpustakaan AQLSelectEx akan bermanfaat bagi seseorang, dan pendekatan itu sendiri akan menjadi tutorial yang sedikit lebih realistis daripada artikel lain dari hub yang berurusan dengan ANTLR.