Ini adalah bagian kedua dari
Kubernet saya
di seri posting
Enterprise . Seperti yang saya sebutkan di posting terakhir saya, sangat penting ketika pindah ke
"Panduan Desain dan Implementasi" bahwa setiap orang berada pada tingkat pemahaman yang sama tentang Kubernetes (K8s).
Saya tidak ingin menggunakan pendekatan tradisional di sini untuk menjelaskan arsitektur dan teknologi Kubernetes, tapi saya akan menjelaskan semuanya melalui perbandingan dengan platform vSphere, yang Anda, sebagai pengguna VMware, kenal. Ini akan memungkinkan Anda untuk mengatasi kebingungan dan keparahan pemahaman Kubernetes. Saya menggunakan pendekatan ini di dalam VMware untuk memperkenalkan Kubernetes ke audiens pendengar yang berbeda, dan itu membuktikan bahwa itu bekerja dengan baik dan membantu orang terbiasa dengan konsep-konsep kunci lebih cepat.
Catatan penting sebelum kita mulai. Saya tidak menggunakan perbandingan ini untuk membuktikan persamaan atau perbedaan antara vSphere dan Kubernetes. Baik itu, dan yang lain, pada dasarnya, adalah sistem terdistribusi, dan, oleh karena itu, harus memiliki kesamaan dengan sistem serupa lainnya. Oleh karena itu, pada akhirnya, saya mencoba untuk memperkenalkan teknologi yang luar biasa seperti Kubernetes kepada komunitas penggunanya yang luas.

Sedikit sejarah
Membaca posting ini melibatkan mengenal wadah. Saya tidak akan menjelaskan konsep dasar wadah, karena ada banyak sumber daya yang membicarakan hal ini. Sangat sering berbicara dengan pelanggan, saya melihat mereka tidak dapat memahami mengapa kontainer menangkap industri kami dan menjadi sangat populer dalam waktu singkat. Untuk menjawab pertanyaan ini, saya akan berbicara tentang pengalaman praktis saya dalam memahami perubahan yang terjadi di industri kami.
Sebelum menjelajahi dunia telekomunikasi, saya adalah seorang pengembang Web (2003).
Ini adalah pekerjaan bergaji kedua saya setelah saya bekerja sebagai insinyur jaringan / administrator (saya tahu bahwa saya adalah dongkrak dari semua perdagangan). Saya mengembangkan PHP. Saya mengembangkan semua jenis aplikasi, mulai dari yang kecil yang digunakan majikan saya, berakhir dengan aplikasi pemungutan suara profesional untuk program televisi, dan bahkan aplikasi telekomunikasi yang berinteraksi dengan hub VSAT dan sistem satelit. Hidup itu hebat, dengan pengecualian satu rintangan utama yang diketahui setiap pengembang, itu kecanduan.
Pada awalnya saya mengembangkan aplikasi di laptop saya, menggunakan sesuatu seperti tumpukan LAMP, ketika itu bekerja dengan baik di laptop saya, saya mengunduh kode sumber ke server host (semua orang ingat RackShack?) Atau ke server pribadi pelanggan. Anda dapat membayangkan bahwa begitu saya melakukan ini, aplikasi macet dan tidak berfungsi di server ini. Alasan untuk ini adalah kecanduan. Server memiliki versi lain dari perangkat lunak (Apache, PHP, MySQL, dll.) Daripada yang digunakan oleh saya di laptop. Jadi saya perlu menemukan cara untuk memperbarui versi perangkat lunak pada server jauh (ide buruk) atau menulis ulang kode pada laptop saya untuk mencocokkan versi pada server jauh (ide terburuk). Itu adalah mimpi buruk, kadang-kadang aku membenci diriku sendiri dan bertanya-tanya mengapa ini adalah bagaimana aku mencari nafkah.
10 tahun telah berlalu, perusahaan Docker muncul. Sebagai konsultan VMware di Professional Services (2013), saya mendengar tentang Docker, dan izinkan saya mengatakan bahwa saya tidak dapat memahami teknologi ini pada masa itu. Saya terus mengatakan sesuatu seperti: mengapa menggunakan wadah jika ada mesin virtual. Mengapa menyerah teknologi penting seperti vSphere HA, DRS, atau vMotion karena keunggulan aneh seperti peluncuran kontainer instan atau menghilangkan overhead hypervisor. Bagaimanapun, semua orang bekerja dengan mesin virtual dan bekerja dengan sempurna. Singkatnya, saya melihatnya dari segi infrastruktur.
Tapi kemudian saya mulai melihat dari dekat dan saya sadar. Segala sesuatu yang terkait dengan Docker terkait dengan pengembang. Baru mulai berpikir sebagai pengembang, saya segera menyadari bahwa jika saya memiliki teknologi ini pada tahun 2003, saya dapat mengemas semua dependensi saya. Aplikasi Web saya bisa berfungsi terlepas dari server yang digunakan. Selain itu, tidak perlu mengunduh kode sumber atau mengkonfigurasi sesuatu. Anda cukup "mengemas" aplikasi saya ke dalam gambar dan meminta pelanggan mengunduh dan menjalankan gambar ini. Ini adalah impian pengembang Web!
Semua ini bagus. Docker memecahkan masalah interaksi dan pengemasan yang sangat besar, tetapi bagaimana selanjutnya? Bisakah saya, sebagai klien korporat, mengelola aplikasi ini saat melakukan penskalaan? Saya masih ingin menggunakan HA, DRS, vMotion dan DR. Docker memecahkan masalah pengembang saya dan menciptakan sejumlah masalah bagi administrator saya (tim DevOps). Mereka membutuhkan platform untuk meluncurkan kontainer, sama seperti yang untuk meluncurkan mesin virtual. Dan kami kembali lagi ke awal.
Tapi kemudian Google muncul, memberi tahu dunia tentang penggunaan kontainer selama bertahun-tahun (pada kenyataannya, kontainer diciptakan oleh Google: cgroups) dan metode yang benar untuk menggunakannya, melalui platform yang mereka sebut Kubernetes. Kemudian mereka membuka kode sumber untuk Kubernetes. Disajikan ke komunitas Kubernetes. Dan itu mengubah segalanya lagi.
Memahami Kubernet versus vSphere
Jadi, apa itu Kubernet? Sederhananya, Kubernetes untuk wadah sama dengan vSphere untuk mesin virtual di pusat data modern. Jika Anda menggunakan VMware Workstation di awal tahun 2000-an, Anda tahu bahwa solusi ini dianggap serius sebagai solusi untuk pusat data. Ketika VI / vSphere dengan host vCenter dan ESXi muncul, dunia mesin virtual berubah secara dramatis. Kubernetes melakukan hal yang sama hari ini dengan dunia kontainer, menghadirkan kemampuan untuk meluncurkan dan mengelola kontainer dalam produksi. Dan itulah sebabnya kami akan mulai membandingkan vSphere berdampingan dengan Kubernetes untuk menjelaskan perincian sistem terdistribusi ini untuk memahami fungsi dan teknologinya.

Tinjauan Sistem
Seperti di vSphere ada host vCenter dan ESXi dalam konsep Kubernet ada Master dan Node. Dalam konteks ini, Master di K8s adalah setara dengan vCenter, dalam arti bahwa itu adalah Management Plane dari sistem terdistribusi. Ini juga merupakan titik masuk untuk API yang berinteraksi dengan Anda ketika mengelola beban kerja Anda. Dengan cara yang sama, K8s Nodes bekerja sebagai sumber daya komputasi, mirip dengan host ESXi. Ini pada mereka bahwa Anda menjalankan beban kerja (dalam kasus K8, kami menyebutnya Pods). Node dapat berupa mesin virtual atau server fisik. Tentu saja, dengan vSphere ESXi, host harus selalu bersifat fisik.

Anda dapat melihat bahwa K8 memiliki toko nilai kunci yang disebut "etcd". Penyimpanan ini mirip dengan database vCenter, tempat Anda menyimpan konfigurasi kluster yang diinginkan yang ingin Anda patuhi.
Adapun perbedaan: pada Master K8 Anda juga dapat menjalankan beban kerja, tetapi pada vCenter Anda tidak bisa. vCenter adalah Alat Virtual yang didedikasikan untuk manajemen saja. Dalam kasus K8, Master dianggap sebagai sumber daya komputasi, tetapi menjalankan aplikasi Enterprise di atasnya bukan ide yang baik.
Jadi bagaimana itu akan terlihat dalam kenyataan? Anda terutama akan menggunakan CLI untuk berinteraksi dengan Kubernetes (tetapi GUI masih merupakan opsi yang sangat layak). Tangkapan layar di bawah ini menunjukkan bahwa saya menggunakan mesin Windows untuk terhubung ke cluster Kubernetes saya melalui baris perintah (saya menggunakan cmder jika Anda tertarik). Dalam tangkapan layar saya memiliki satu simpul Master dan 4 simpul. Mereka bekerja di bawah kendali K8s v1.6.5, dan sistem operasi (OS) Ubuntu 16.04 diinstal pada node. Pada saat menulis posting ini, kami terutama tinggal di dunia Linux, di mana Master dan Node selalu menjalankan distribusi Linux.
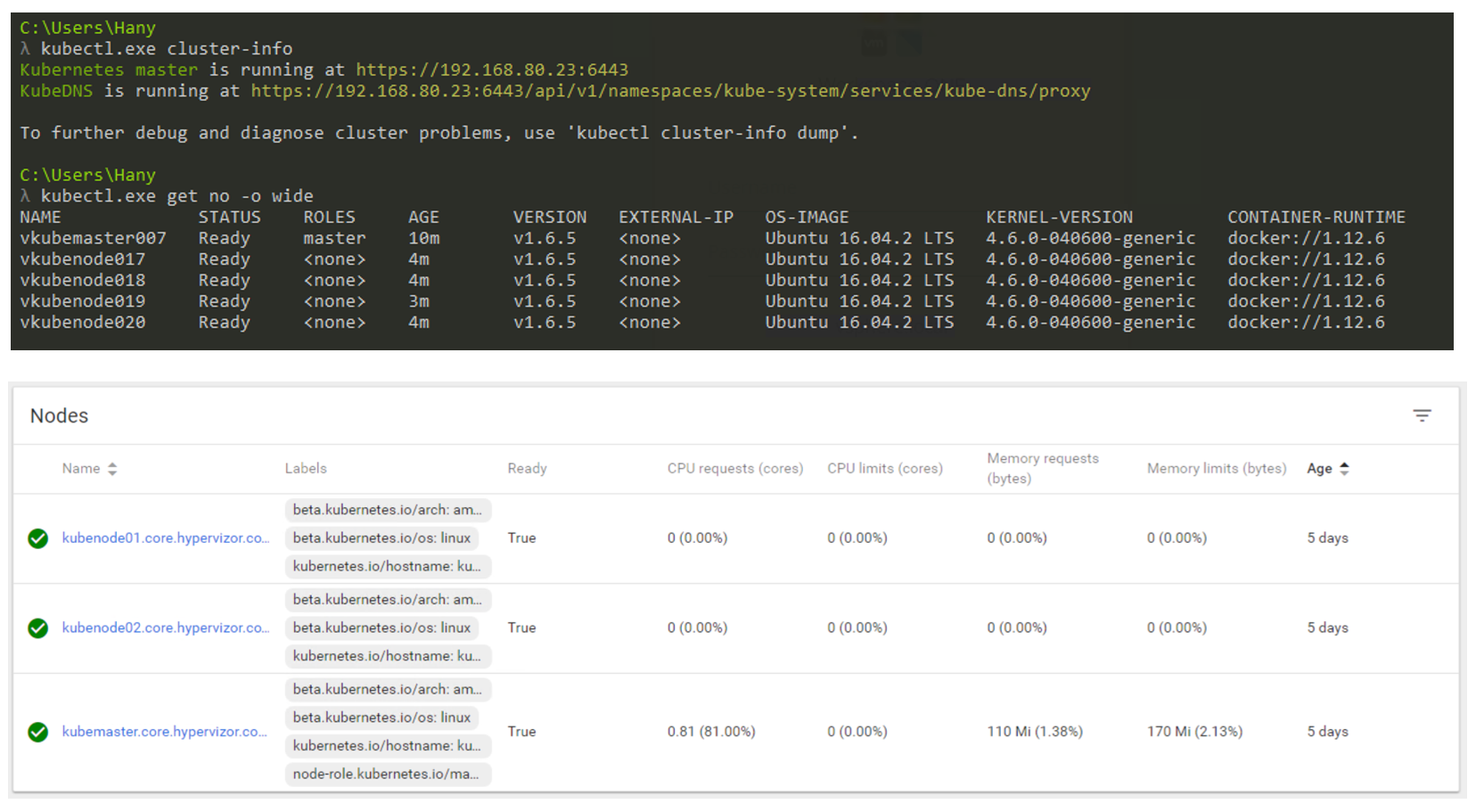 Manajemen cluster K8 melalui CLI dan GUI.
Manajemen cluster K8 melalui CLI dan GUI.Faktor Bentuk Beban Kerja
Di vSphere, mesin virtual adalah batas logis dari sistem operasi. Di Kubernetes, Pods adalah batas kontainer, seperti host ESXi, yang dapat menjalankan beberapa mesin virtual secara bersamaan. Setiap Node dapat menjalankan beberapa Pod. Setiap Pod menerima alamat IP yang dapat dirutekan, seperti mesin virtual, agar Pods dapat saling berkomunikasi.
Di vSphere, aplikasi berjalan di dalam OS, dan di Kubernetes, aplikasi berjalan di dalam wadah. Mesin virtual hanya dapat bekerja dengan satu OS pada satu waktu, dan Pod dapat menjalankan beberapa wadah.
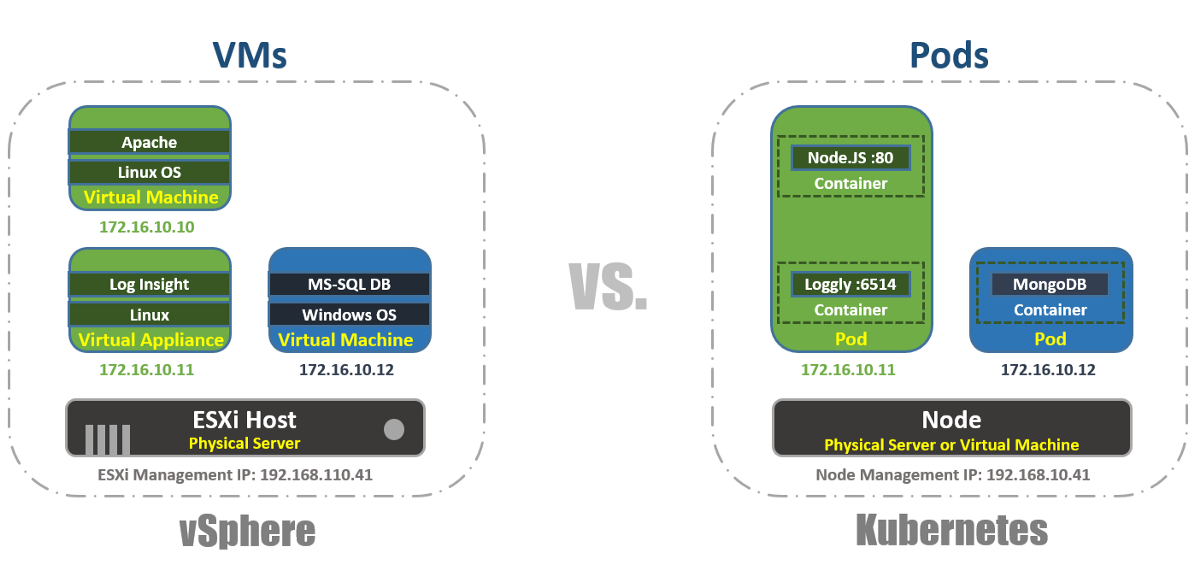
Ini adalah bagaimana Anda dapat membuat daftar Pods di dalam cluster K8s menggunakan alat kubectl melalui CLI, memeriksa fungsionalitas Pods, usia mereka, alamat IP dan Node yang sedang mereka kerjakan.

Manajemen
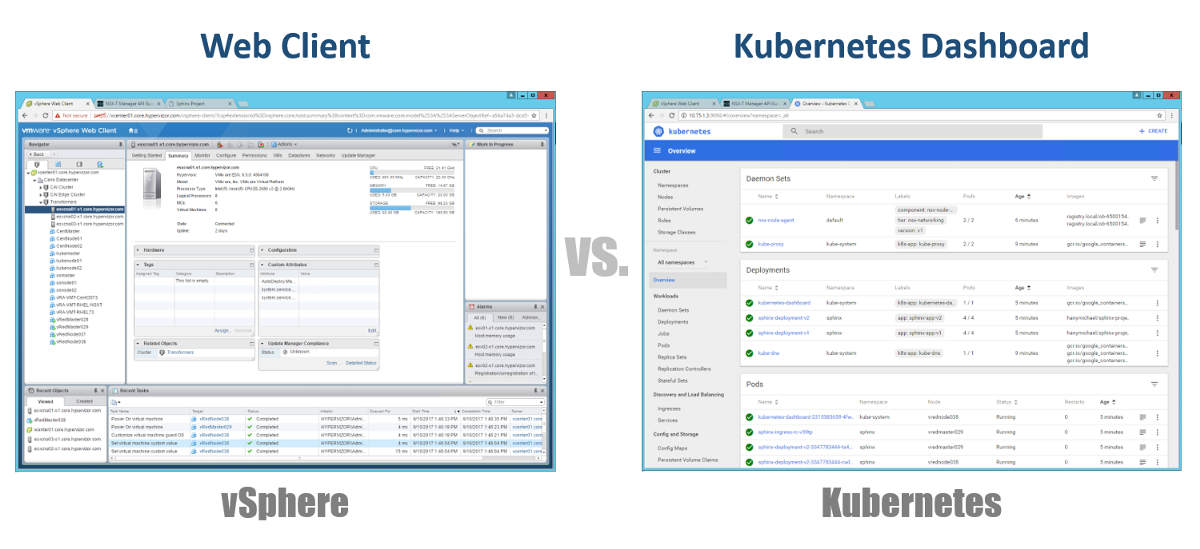
Jadi, bagaimana kita mengelola Master, Nodes, dan Pods kita? Di vSphere, kami menggunakan klien Web untuk mengelola sebagian besar (jika tidak semua) komponen infrastruktur virtual kami. Untuk Kubernetes, sama halnya, menggunakan Dashboard. Ini adalah portal Web berbasis GUI yang baik yang dapat Anda akses melalui browser Anda dengan cara yang sama seperti dengan klien Web vSphere. Dari bagian sebelumnya, Anda dapat melihat bahwa Anda dapat mengelola kluster K8s Anda menggunakan perintah kubeclt dari CLI. Itu selalu bisa diperdebatkan di mana Anda akan menghabiskan sebagian besar waktu Anda di CLI atau di Dashboard grafis. Karena yang terakhir ini menjadi alat yang semakin kuat setiap hari (Anda dapat melihat video ini dengan pasti). Secara pribadi, saya berpikir bahwa Dashboard sangat mudah untuk memantau status dengan cepat atau menampilkan rincian berbagai komponen K8, tanpa harus memasukkan perintah panjang di CLI. Anda akan menemukan keseimbangan di antara mereka secara alami.
Konfigurasi
Salah satu konsep yang sangat penting di Kubernetes adalah kondisi konfigurasi yang diinginkan. Anda menyatakan apa yang Anda inginkan untuk hampir semua komponen Kubernetes melalui file YAML, dan Anda membuat semua ini menggunakan kubectl (atau melalui Dashboard grafis) sebagai keadaan yang Anda inginkan. Mulai sekarang, Kubernetes akan selalu berusaha untuk menjaga lingkungan Anda dalam kondisi operasional tertentu. Misalnya, jika Anda ingin memiliki 4 replika satu Pod, K8 akan terus memantau Pod ini, dan jika salah satu dari mereka meninggal atau Node yang berfungsi bermasalah, K8 akan pulih sendiri dan secara otomatis membuat ini. Pod di tempat lain.
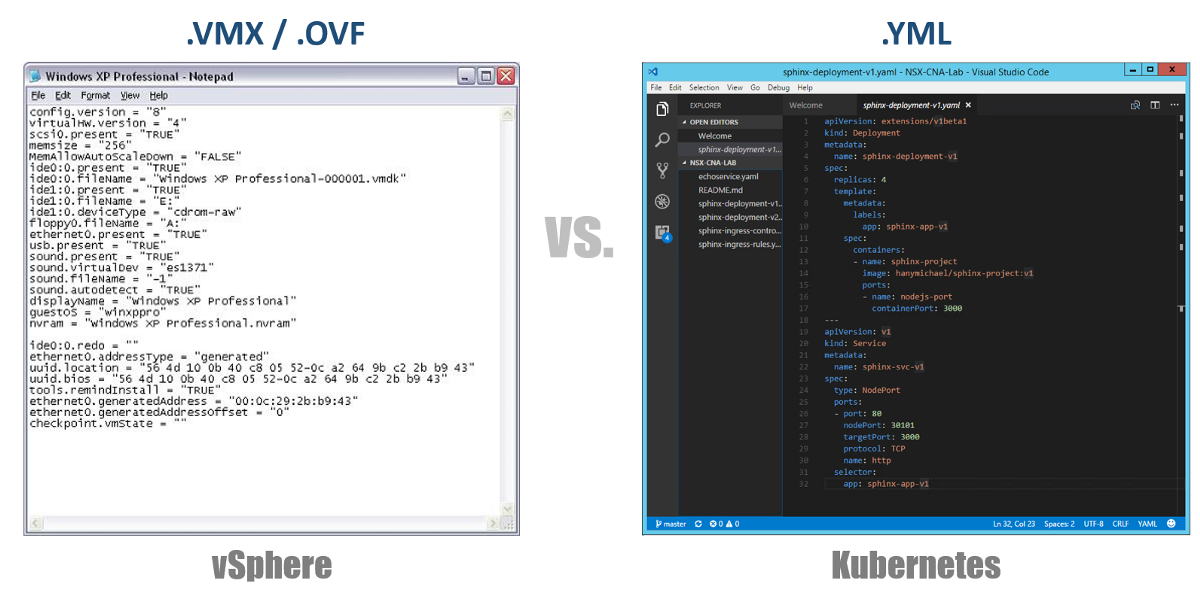
Kembali ke file konfigurasi YAML kami, Anda dapat menganggapnya sebagai file .VMX untuk mesin virtual atau deskriptor .OVF untuk Peralatan Virtual yang ingin Anda gunakan ke vSphere. File-file ini menentukan konfigurasi dari beban kerja / komponen yang ingin Anda jalankan. Tidak seperti file VMX / OVF, yang eksklusif untuk VMs / Peralatan virtual, file konfigurasi YAML digunakan untuk mendefinisikan komponen K8, seperti ReplicaSets, Layanan, Penyebaran, dll. Pertimbangkan ini di bagian berikut.
Cluster virtual
Di vSphere, kami memiliki host ESXi fisik yang secara logis dikelompokkan ke dalam kelompok. Cluster ini dapat dibagi menjadi cluster virtual lainnya yang disebut "Resource Pools". “Kelompok” ini terutama digunakan untuk membatasi sumber daya. Di Kubernetes, kami memiliki sesuatu yang sangat mirip. Kami menyebutnya "Namespaces", mereka juga dapat digunakan untuk memberikan batas sumber daya, yang akan tercermin pada bagian selanjutnya. Namun, paling sering "Ruang nama" digunakan sebagai alat multi-tenancy untuk aplikasi (atau pengguna, jika Anda menggunakan kluster K8 yang umum). Ini juga salah satu opsi yang dapat digunakan untuk melakukan segmentasi jaringan menggunakan NSX-T. Pertimbangkan ini dalam publikasi berikut.
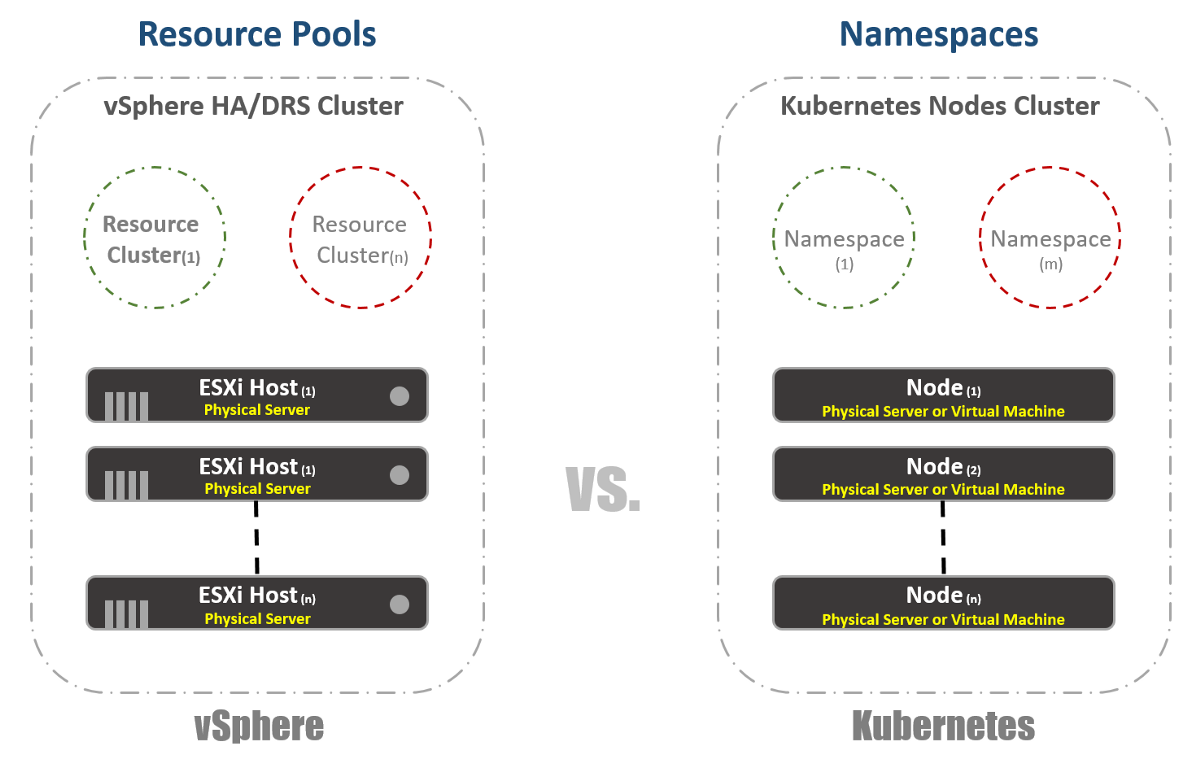
Manajemen sumber daya
Seperti yang saya sebutkan di bagian sebelumnya, Namespace di Kubernetes umumnya digunakan sebagai sarana segmentasi. Penggunaan Namespaces lainnya adalah alokasi sumber daya. Opsi ini disebut "Sumber Daya Kuota". Sebagai berikut dari bagian sebelumnya, definisi ini terjadi dalam konfigurasi file YAML, di mana status yang diinginkan dideklarasikan. Di vSphere, seperti yang dapat dilihat pada tangkapan layar di bawah ini, kami menentukan ini dari pengaturan Resource Pools.

Identifikasi beban kerja
Ini cukup sederhana dan hampir sama untuk vSphere dan Kubernetes. Dalam kasus pertama, kami menggunakan konsep Tag untuk mendefinisikan (atau mengelompokkan) beban kerja yang serupa, dan yang kedua kami menggunakan istilah "Label". Dalam kasus Kubernetes, identifikasi beban kerja adalah wajib.

Reservasi
Sekarang benar-benar menyenangkan. Jika Anda adalah penggemar berat vSphere FT, seperti saya, Anda akan menyukai fitur ini di Kubernetes, meskipun ada beberapa perbedaan dalam kedua teknologi tersebut. Di vSphere, ini adalah mesin virtual dengan instance shadow yang berjalan pada host yang berbeda. Kami merekam instruksi pada mesin virtual utama dan memutarnya di mesin virtual shadow. Jika mesin utama berhenti bekerja, mesin virtual bayangan segera hidup. Kemudian vSphere mencoba menemukan host ESXi lain untuk membuat contoh bayangan baru dari mesin virtual untuk mempertahankan redundansi yang sama. Di Kubernetes, kami memiliki sesuatu yang sangat mirip. ReplicaSets adalah jumlah yang Anda tentukan untuk menjalankan beberapa instance Pods. Jika satu Pod gagal, instance lain tersedia untuk melayani lalu lintas. Pada saat yang sama, K8 akan mencoba meluncurkan Pod baru pada Node yang tersedia untuk mempertahankan status konfigurasi yang diinginkan. Perbedaan utama, seperti yang mungkin telah Anda perhatikan, adalah bahwa dalam kasus K8, Pod selalu berfungsi dan melayani lalu lintas. Mereka bukan beban kerja bayangan.

Load balancing
Meskipun ini mungkin bukan fungsi bawaan di vSphere, sangat, sangat sering diperlukan untuk menjalankan load balancers pada platform. Di dunia vSphere, ada penyeimbang beban virtual atau fisik untuk mendistribusikan lalu lintas jaringan antara beberapa mesin virtual. Mungkin ada banyak mode konfigurasi yang berbeda, tetapi mari kita asumsikan bahwa yang kami maksud adalah konfigurasi Satu-Bersenjata. Dalam hal ini, Anda menyeimbangkan beban lalu lintas Timur-Barat pada mesin virtual Anda.
Demikian pula, Kubernetes memiliki konsep "Layanan". Layanan dalam K8 juga dapat digunakan dalam mode konfigurasi yang berbeda. Mari kita pilih konfigurasi "ClusterIP 'untuk membandingkannya dengan Penyeimbang Beban Satu-Bersenjata. Dalam hal ini, Layanan di K8 akan memiliki alamat IP virtual (VIP), yang selalu statis dan tidak berubah. VIP ini akan mendistribusikan lalu lintas di antara beberapa Pod. Ini sangat penting di dunia Kubernetes, di mana Pods bersifat sementara, Anda kehilangan alamat IP Pod saat ia mati atau dihapus. Karena itu, Anda harus selalu memberikan VIP statis.
Seperti yang telah saya sebutkan, Layanan memiliki banyak konfigurasi lain, misalnya, “NodePort”, di mana Anda menetapkan port pada level Node dan kemudian melakukan terjemahan port-address-translation untuk Pods. Ada juga "LoadBalancer" tempat Anda menjalankan instance Load Balancer dari pihak ketiga atau penyedia cloud.

Kuberentes memiliki mekanisme penyeimbangan beban lain yang sangat penting yang disebut “Pengontrol Masuk”. Anda dapat menganggapnya sebagai penyeimbang beban aplikasi in-line. Gagasan utamanya adalah Ingress Controller (dalam bentuk Pod) akan diluncurkan dengan alamat IP yang terlihat dari luar. Alamat IP ini mungkin memiliki sesuatu seperti catatan Wildcard DNS. Ketika lalu lintas tiba di Pengontrol Ingress menggunakan alamat IP eksternal, itu memeriksa header dan menentukan menggunakan seperangkat aturan yang sebelumnya Anda atur di mana Pod nama ini milik. Sebagai contoh: sphinx-v1.esxcloud.net akan diarahkan ke Layanan sphinx-svc-1, dan sphinx-v2.esxcloud.net akan diarahkan ke Layanan sphinx-svc2, dll.

Penyimpanan dan Jaringan
Penyimpanan dan jaringan adalah topik yang sangat, sangat luas dalam hal Kubernetes. Hampir tidak mungkin untuk berbicara singkat tentang kedua topik ini di posting pengantar, tetapi saya akan segera berbicara secara rinci tentang berbagai konsep dan opsi untuk masing-masing topik ini. Sementara itu, mari kita cepat melihat bagaimana tumpukan jaringan bekerja di Kubernetes, karena kita akan membutuhkannya di bagian selanjutnya.
Kubernetes memiliki berbagai "Plugins" jaringan yang dapat Anda gunakan untuk mengonfigurasi jaringan Nodes dan Pods Anda. Salah satu plugin yang umum adalah "kubenet," yang saat ini digunakan dalam mega-cloud seperti GCP dan AWS. Di sini saya akan secara singkat berbicara tentang implementasi GCP, dan kemudian menunjukkan contoh praktis implementasi di GKE.

Pada pandangan pertama, ini mungkin terlihat terlalu rumit, tetapi saya harap Anda dapat memahami semua ini pada akhir posting ini. Pertama, kita melihat bahwa kita memiliki dua Kubernetes Node: Node 1 dan Node (m). Setiap node memiliki antarmuka eth0, seperti mesin Linux lainnya. Antarmuka ini memiliki alamat IP untuk dunia luar, dalam kasus kami, pada subnet 10.140.0.0/24. Perangkat Hulu L3 bertindak sebagai Gerbang Default untuk merutekan lalu lintas kami. Ini bisa berupa sakelar L3 di pusat data Anda atau router VPC di cloud, seperti GCP, seperti yang akan kita lihat nanti. Apakah semuanya baik-baik saja?
Lebih jauh kita melihat bahwa kita memiliki antarmuka Jembatan cbr0 di dalam node. Antarmuka ini adalah Gateway Default untuk subnet IP 10.40.1.0/24 dalam kasus Node 1. Subnet ini ditugaskan oleh Kubernetes untuk setiap Node. Node biasanya mendapatkan subnet / 24, tetapi Anda dapat mengubahnya menggunakan NSX-T (kami akan membahasnya di posting berikut). Saat ini, subnet ini adalah dari mana kami akan mengeluarkan alamat IP untuk Pods. Dengan cara ini, sembarang Pod di dalam Node 1 akan mendapatkan alamat IP dari subnet ini. Dalam kasus kami, Pod 1 memiliki alamat IP 10.40.1.10. Namun, Anda perhatikan bahwa ada dua wadah bersarang di Pod ini. Kami telah mengatakan bahwa dalam satu Pod satu atau beberapa kontainer dapat diluncurkan, yang terkait erat satu sama lain dalam hal fungsi. Inilah yang kita lihat pada gambar. Kontainer 1 mendengarkan pada port 80, dan container 2 mendengarkan pada port 90. Kedua kontainer memiliki alamat IP yang sama 10.40.1.10, tetapi mereka tidak memiliki Networking Namespace. Oke, lalu siapa yang memiliki tumpukan jaringan ini? Sebenarnya ada wadah khusus yang disebut "Pause Container". Diagram menunjukkan bahwa alamat IP-nya adalah alamat IP Pod untuk komunikasi dengan dunia luar. Dengan demikian, Pause Container memiliki tumpukan jaringan ini, termasuk alamat IP 10.40.1.10 itu sendiri, dan, tentu saja, itu mengalihkan lalu lintas ke kontainer 1 ke port 80, dan juga mengalihkan lalu lintas ke kontainer 2 ke port 90.
Sekarang Anda harus bertanya bagaimana lalu lintas dialihkan ke dunia luar? Kami telah mengaktifkan Linux IP Forwarding untuk meneruskan lalu lintas dari cbr0 ke eth0. Ini hebat, tetapi tidak jelas bagaimana perangkat L3 dapat mempelajari cara meneruskan lalu lintas ke tujuannya? Dalam contoh khusus ini, kami tidak memiliki perutean dinamis untuk pengumuman jaringan ini. Karena itu, kita harus memiliki semacam rute statis pada perangkat L3. Untuk mencapai subnet 10.40.1.0/24, Anda perlu meneruskan lalu lintas ke alamat IP Node 1 (10.140.0.11) dan untuk mencapai subnet 10.40.2.0/24, harapan berikutnya adalah Node (m) dengan alamat IP 10.140.0.12.
Semua ini hebat, tetapi ini adalah cara yang sangat tidak praktis untuk mengelola jaringan Anda. Mendukung semua rute ini saat melakukan penskalaan kluster Anda akan menjadi mimpi buruk bagi administrator jaringan. Itulah sebabnya beberapa solusi, seperti CNI (Container Network Interface) di Kuberentes, diperlukan untuk mengelola konektivitas jaringan. NSX-T adalah salah satu solusi dengan fungsi yang sangat luas untuk interaksi dan keamanan jaringan.
Ingatlah bahwa kami telah melihat plugin kubenet, bukan CNI. Plugin kubenet adalah apa yang digunakan oleh Google Container Engine (GKE), dan cara mereka melakukannya sangat menyenangkan karena sepenuhnya ditentukan oleh perangkat lunak dan terotomatisasi di cloud mereka. , GCP. .
Apa selanjutnya
Kuberentes. ,
.
Bagian kedua.. .
.